3D Head Pose Estimation through Facial Features and Deep Convolutional Neural Networks
2021-12-15KhalilKhanJehadAliKashifAhmadAsmaGulGhulamSarwarSahibKhanQuiThanhHoaiTaTaeSunChungandMuhammadAttique
Khalil Khan,Jehad Ali, Kashif Ahmad, Asma Gul, Ghulam Sarwar,Sahib Khan,Qui Thanh Hoai Ta,Tae-Sun Chung and Muhammad Attique
1Department of Computer Science and Software Engineering, Pak-Austria Fachhochschule:Institute of Applied Sciences and Technology, Haripur-KPK, Pakistan
2Department of Computer Engineering and Department of AI Convergence Network,Ajou University,Suwon,16499,South Korea
3Hamad Bin Khalifa University, Doha,Qatar
4Department of Statistics, Shaheed Benazir Bhutto Women University, Peshawar, Pakistan
5Department of Software Engineering, University of Azad Jammu and Kashmir, Pakistan
6Department of Electronics and Telecommunications, Politecnico di Torino, Torino, 10129,Italy
7Institute of Research and Development, Duy Tan University, Danang, 550000, Vietnam
8Department of Computer Engineering, Ajou University, Suwon, 16499,Korea
9Department of Software, Sejong University, Seoul,05006, South Korea
Abstract:Face image analysis is one among several important cues in computer vision.Over the last five decades, methods for face analysis have received immense attention due to large scale applications in various face analysis tasks.Face parsing strongly benefits various human face image analysis tasks inducing face pose estimation.In this paper we propose a 3D head pose estimation framework developed through a prior end to end deep face parsing model.We have developed an end to end face parts segmentation framework through deep convolutional neural networks (DCNNs).For training a deep face parts parsing model,we label face images for seven different classes,including eyes,brows,nose,hair,mouth, skin, and back.We extract features from gray scale images by using DCNNs.We train a classifier using the extracted features.We use the probabilistic classification method to produce gray scale images in the form of probability maps for each dense semantic class.We use a next stage of DCNNs and extract features from grayscale images created as probability maps during the segmentation phase.We assess the performance of our newly proposed model on four standard head pose datasets, including Pointing’04, Annotated Facial Landmarks in the Wild (AFLW), Boston University (BU), and ICT-3DHP, obtaining superior results as compared to previous results.
Keywords: Face image analysis;face parsing;face pose estimation
1 Introduction
Face pose estimation,also known as head pose estimation is a challenging task in the field of computer vision.Head pose estimation plays an important role in many real-world applications, including gaze estimation[1],human computer interaction[2],and augmented reality[3].However,face pose estimation is still a difficult task for various reasons such as variations in facial appearance,complex and unconstrained background, and different facial expressions.Head pose estimation is particularly confronted with problems in the uncontrolled and wild conditions.Some of the applications that rely heavily on an accurate head pose estimation system are human behavior analysis, safety during driving, surveillance applications,and targeted advertisements.
Head pose estimation is linked with gaze estimation; it is confirmed by the research conducted in the 19th century [4].The relationship between head pose estimation and gaze prediction is also confirmed by later stage in research [5].The research conducted in Langton et al.[5] suggests that gaze estimation comes from both eyes and head pose direction.Apart from eyes, this mutual relationship between various face parts and head pose is also confirmed by Huang et al.[6].The work proposed by Huang et al.[6]suggests that relationship between face parts can be exploited for several mid-level vision tasks along with head pose estimation.Our work is also impressed by this idea of mutual relationship.
The face parsing method proposed in Khan et al.[7],segments a face image into face classes including,mouth, nose, hair, skin, back, and eyes.We also use face parts information by first developing a face segmentation framework.As can be seen these days, a shift in state-of-the-art methods from traditional machine learning algorithms towards recently introduced deep learning methods is prevalent.We also develop a DCCNs based face parsing method for seven different classes.
Our work is inspired from Huang et al.’s[6]idea.We argue that all face analysis tasks are related and can assist each other in specific applications.The performance of the face pose prediction can be improved if a prior efficiently parsed image having information about various face features is provided as input.The same fact is also confirmed by psychology literature,for example,[8,9].In a nutshell,the performance of the face pose estimation can be improved if the information from various face features is extracted from a segmented image and given as input to the face pose estimation framework.
Face pose estimation is already being predicted through various face parts information in literature[10,11].These methods involve landmarks localization before face pose estimation.However, the performance of the system in such cases depends on this method [12,13], which is itself another challenge.The landmarks localization algorithms are greatly affected in certain cases such as complicated facial expressions, changes in face rotation and lighting conditions, occlusions, and far field imagery conditions.All these factors make this method a rather challenging task, which ultimately drops the performance of the face pose estimation system; if it depends on it.Unlike the landmarks localization method, we introduce a face pose estimation method which does not need landmarks information but rather depends on various face parts information.
We propose a face segmentation method based on deep learning that segments a face image into seven different classes.For building a face parsing framework, we labeled 200 face images from each database through image editing software.The deep learning-based model extracts features through Convolutional Neural Networks (CNNs) and build a Soft-Max classifier.When a testing image is provided as input to the face parsing framework, it is segmented into seven face classes.We use a probabilistic classification method and create probability maps (PMAPS) along with segmentation results.We use five different face features and extract information through CNNs to build another Soft-Max classifier.To summarize,contributions of this paper are:
• We propose a face parsing method that segments a face image into seven different classes.The face parsing method is based on DCNNs.
• We develop a new face pose estimation algorithm.The proposed face pose estimation method is based on a prior face parsing method.
• We conduct experiments on state-of-the-art (SOA) datasets for face pose estimation and obtained much better results compared to previous results.
The structure of the paper is as follows:Section 2 presents related work for head pose estimation.Several datasets are reported by previous literature for head pose estimation.The datasets used in this paper are presented in Section 3.The face segmentation part is presented in Section 4, whereas the proposed head pose estimation algorithm is discussed in Section 5.The obtained results are discussed and then a comparison with SOA is shown in Section 6.We summarize the article with future directions in Section 7.
2 Related Work
2.1 Genetic Algorithm (GA)
Face parsing algorithms can be categorized into local and global based parsing methods.These methods are described in the following paragraphs.
Local methods:Local methods adopt a specific strategy of coarse-to-fine.Local based methods consider both local precision and global consistency.In local-based algorithms, separate models are trained for various face components, e.g., mouth, nose, eyes, etc.A method proposed by Luo et al.[14]trains a model that segments each face part individually.Zhou et al.[15] propose an interlinked CNNs based model after localizing face parts.The interlinked based method passes information bidirectionally,i.e., coarse and fine levels.The computational cost and memory consumption of the proposed method is large due to the bidirectional level information exchange.Another approach [16] combines the CNNs with Recurrent Neural Networks(RNNs)in two successive stages achieving SOA results on challenging.
Global methods:Global based methods treat different face parts information globally.Accuracy of these algorithms is less, as single face parts are not targeted.These methods estimate a label for each pixel over the entire face image.Some earlier works represent the spatial relationship between face parts through different models, for example, [17] and exemplar-based model [18].The CNNs structure and loss function were processed by Liu et al.[16], which encodes the underlying layouts of the face image.This method integrates conditional random fields with CNNs, which the authors named Multi-Objective learning method.Jackson et al.[19] integrated CNNs with boundary cue to confine face regions.This method utilizes facial landmarks in the first step.Super-pixel information, Conditional Random Fields(CRFs), and CNNs are combined by Zhou et al.[20].The method proposed in Zhou et al.[20] employs fully convolutional networks, therein obtaining better performance compared to SOA.The method proposed by Wei et al.[21] regulates receptive fields in a face parsing network.To achieve good performance on real time scenario, Saito et al.[22] propose another algorithm.The computational cost of this method is much lower than other methods.
2.2 Face Pose Estimation
Before describing the proposed face pose estimation model, we review related work on face pose estimation algorithms in this Section of the paper.A rich literature already exists for head pose estimation; however, in this Section of the article, we will try to provide maximum information about the recently introduced algorithms for face pose estimation.
Face pose can be classified into three categories, including yaw, roll, and pitch.The horizontal orientation is represented with yaw, vertical orientation with pitch, and the image plane by roll angle.We evaluate our proposed face pose estimation method with four large scale datasets, including Pointing’04 [23], AFLW [24], ICT-3DHPE [25], and Boston University (BU) [26] datasets.We classify the face pose estimation methods into three categories, including holistic approaches, geometric, and deep learning-based methods.These methods are described below.
2.2.1 Holistic Methods
In holistic approaches, the face image is considered as one-dimension vector, and certain features are extracted.Holistic methods assume a certain relationship between 2D face image properties and their 3D pose.A large number of face images are used for training purposes,and various statistical learning methods are exploited with different classification tools.The trained model then differentiates between various face poses.Some methods which used holistic approaches to address head pose estimation can be explored in[27-30].
Holistic methods show some advantages over its competitive methods.These approaches are comparatively simple and easy to implement.These methods are fit both for high- and low-resolution images.Moreover, no negative training data is needed in the training stage.Extension of the template models is also easy and can be extended any time without doing sufficient changes in the architecture.
Holistic methods also face some serious weaknesses.Like other methods,these algorithms also suffer from the limitation that the system must detect the face part.The system accuracy also degrades drastically with localization errors.Holistic methods become unreliable with variations in face appearance,changing in lighting conditions, and occlusions.A significant problem faced by these methods is pair wise similarity,which is the faulty assumption of the images of the same candidate in two different positions.
2.2.2 Geometric Methods
Geometric methods are also known as model-based methods.These methods require the localization of certain facial key points such as eyebrow,eyes,nose,the tip of the nose,lips,etc.A single feature vector is extracted from the located facial key points, and then the desired pose is predicted based on the relative position of the extracted key points.These methods are almost similar to how the human brain estimates the head pose of a face image.
The literature reports different face features in different combinations for head pose estimation.The intraocular distance and eyes are commonly used for head pose discrimination due to their easy detection[31].In some cases, the mouth is also used, but mouth detection is comparatively difficult if the facial expressions are complicated.The tip of the nose and hair is another discriminative cue which is used for modeling of an efficient head pose estimation system.
Geometric methods are very fast,as very few features are needed for modeling.However,if the number of features is increased,the computational cost also raises;for example,Cootes et al.[32]uses a combination of fifteen different feature points around the mouth,eyes,and nose regions.Another main advantage noted for these methods is; the extracted points are robust to rotation and translation changes.
For different key points localization Active Shape Modeling(ASM)[33]is frequently used.However,ASM fails drastically in some critical conditions,for example,changing in lighting conditions,complicated facial expressions, and occlusions.If ASM does not perform well, the performance of the head pose estimation drops significantly.Some methods which use geometric based methods can be explored in references[34-36].
2.2.3 Deep Learning Methods
The performance of various visual recognition tasks has been greatly improved with deep learning architecture.Some very complex scenarios of computer vision tasks are improved with these deep learning methods.Major weaknesses of the conventional machine learning techniques are mitigated with this transition of deep learning architecture.The same is the case with face pose estimation.
Ruiz et al.[37] propose a deep learning-based method that does not depend on prior landmarks estimation.Some hybrid models are proposed in [38-40], which address head pose estimation along with other face image analysis tasks such as gender and race classification, face recognition, and detection, etc.Similarly, Hsu et al.[41] propose a method that combines regression-based function with deep learning modules.The lastly proposed method is named QuatNet (Quaternions) by the authors.A new deep learning-based method is proposed by Lee et al.[42], which is evaluated with Pointing’04.The method proposed in Lee et al.[42] is fast and comparatively robust to certain environmental factors; therefore,presents a better choice for the datasets collected in the wild conditions.
The performance of conventional machine learning methods is satisfactory on the datasets collected in constrained conditions.However, when these traditional machine learning methods are exposed to such unconstrained datasets, performance drops drastically.Unlike conventional machine learning methods,deep learning methods show much improvement with the challenging database.In a nutshell, some research work on face pose estimation already exists, but still, face pose estimation is an open challenge for researchers.
3 Databases
We evaluate our face pose estimation framework with five datasets,including Pointing’04,BU,AFLW,and ICT-3DHPE.This Section presents details about the databases used in our proposed work.
•Pointing’04:Images in the Pointing’04 are manually annotated.Although it is an old dataset,it is still used by researchers[43-45]due to the diversity in the images and its challenging nature.The database consists of fifteen sets of low-resolution images.Each individual set has a further two subsets having 93 face images for every subject in different orientations.The age of all participants in the dataset is between 20-40 years.Some participants in the datasets also include facial hair and some wearing glasses.The head pose of a subject is determined with the pan and tilt angle.Each participant is asked to look into 93 different markers marked on a wall in a measurement room.Each point represents a specific head pose.Due to manual labeling, the given face localization may not be accurate in some cases.The head orientation varies between -90oto +90ofor yaw pose.The step size between two consecutive poses is 15.Similarly, for pitch, the top poses are represented with positive values and bottom poses with negative values.The difference between the two poses for pitch is 30o.
•AFLW:These images are collected in the unconstrained condition with large variations in lighting conditions, facial expression, appearance, and some environmental factors.All images in AFLW are collected from the Internet.These images are collected in 9 different lighting conditions.The total number of face images is 13,000, whereas the number of participants is 5,749.The head pose is manually annotated in AFLW, where the yaw angle varies between ±120oand pitch and roll in the range±90o.
•BU Data-set:This dataset has two sequences; images exposed to changing lighting conditions and those collected in controlled and uniform lighting conditions.The database consists of both RGB and depth images.We use only RGB images in our experiments.We consider all three rotation angles, i.e., pitch, yaw, and roll.The number of participants in the database is only five.To collect ground truth data,magnetic trackers are attached to every subject’s head.
•ICT-3DHPE:These images are collected through Kinect sensor.Both RGB and depth images are included; however, we use only RGB for our experiments.The total number of participants in the dataset is ten, with six male and four females.The ground truth data, in this case, is also accurate as again magnetic tracker is attached to each subject’s head.
4 Proposed Face Parsing Framework
The face parsing module of the proposed framework is presented in this Section of the paper.We make this face parsing model for each dataset separately.Some of the datasets do not provide cropped face images;we apply a face detection method in the initial phase.As face detection is a mature research area,we use a face detection algorithm already proposed in Wei et al.[46]to each image.We re-scaled each face image to a fixed size of 227 × 227 after face detection.The proposed DCNNs based face segmentation model and its architecture is presented in Tab.1.The Fig.1 shows the proposed face parsing module.
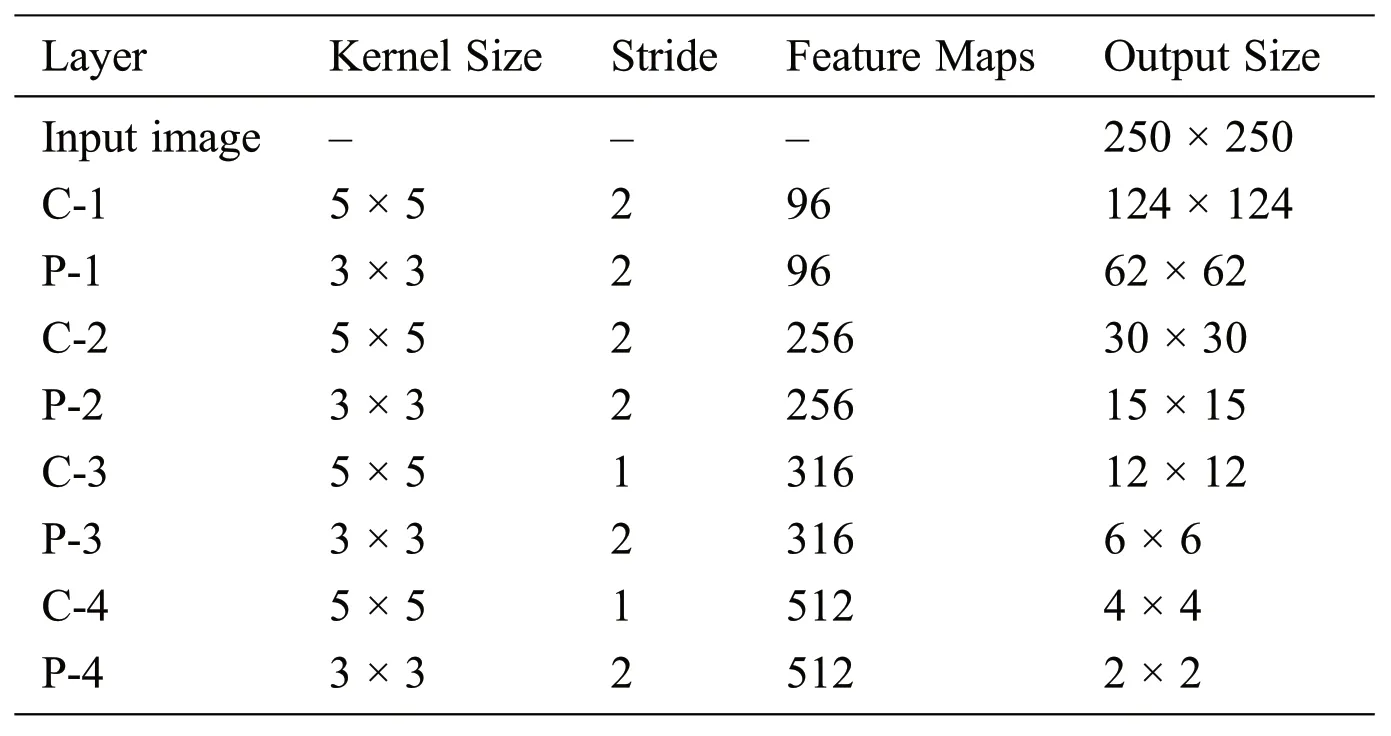
Table 1:Information about each CNNs layer

Figure 1:Proposed deep CNNs face parsing framework
Architecture:There are some parameters that greatly affect the performance of the DCNNs based model.For example, the size of the kernel used for CNNs and the pooling layer, the number of layers used for convolution, and the number of filters in every layer.In our face parsing module, we use four sets of convolutional layers (C1-C4), followed by maximum pooling layers (P1-P4) and, at the end, two fully connected layers.We fix the size of the kernel in convolutional as 5 × 5.We also fix the down sampling stride, as can be seen in Tab.1.Details about the convolutional layer, feature map, and kernel size are shown in Tab.1.Some other parameters of the proposed DCNNs are presented in Tab.2.

Table 2:CNNs Parameters setting for training
We use a rectified linear unit for activation function.We embed the maximum pooling layer after each convolutional layer.Our proposed DCNNs face parsing model has main three parts, i.e., convolutional layers, maximum pooling layers, and two fully connected layers.We represent the convolutional layer kernel byN*M*C.Where height and width of the kernel is represented byNandMand the channel byC.The maximum pooling layer kernel is represented byP*Q, wherePare representing height andQwidth of the kernel.The fully connected layer performs the task of classification.For optimization of the deep learning architecture and more details,Goodfellow et al.[47]can be explored further.The overview of the face parsing module is summarized in Tab.1.We train a face parsing module for each database individually.
5 Proposed Features Based Face Pose Estimation Algorithm
Our proposed face pose estimation model is summarized in Algorithm 1.Initially, we develop a face segmentation model through DCNNs.The face parsing model outputs the most likely class for each pixel in a face image.We created PMAPS during the segmentation phase, which we further use for face pose estimation.We investigate different combinations of these PMAPS to know which face parts help face pose differentiation.We represent these PMAPS as:PMAPSnose, PMAPSback, PMAPSeyes,PMAPSeyebrows, PMAPSskin, PMAPSmouth, and PMAPShair.Fig.1 shows some face images from Pointing’04 along with PMAPS for all five face classes, which we use in our face pose prediction model.PMAPS are grey scale images where higher intensity shows more probability of estimation for a face class and vice versa.
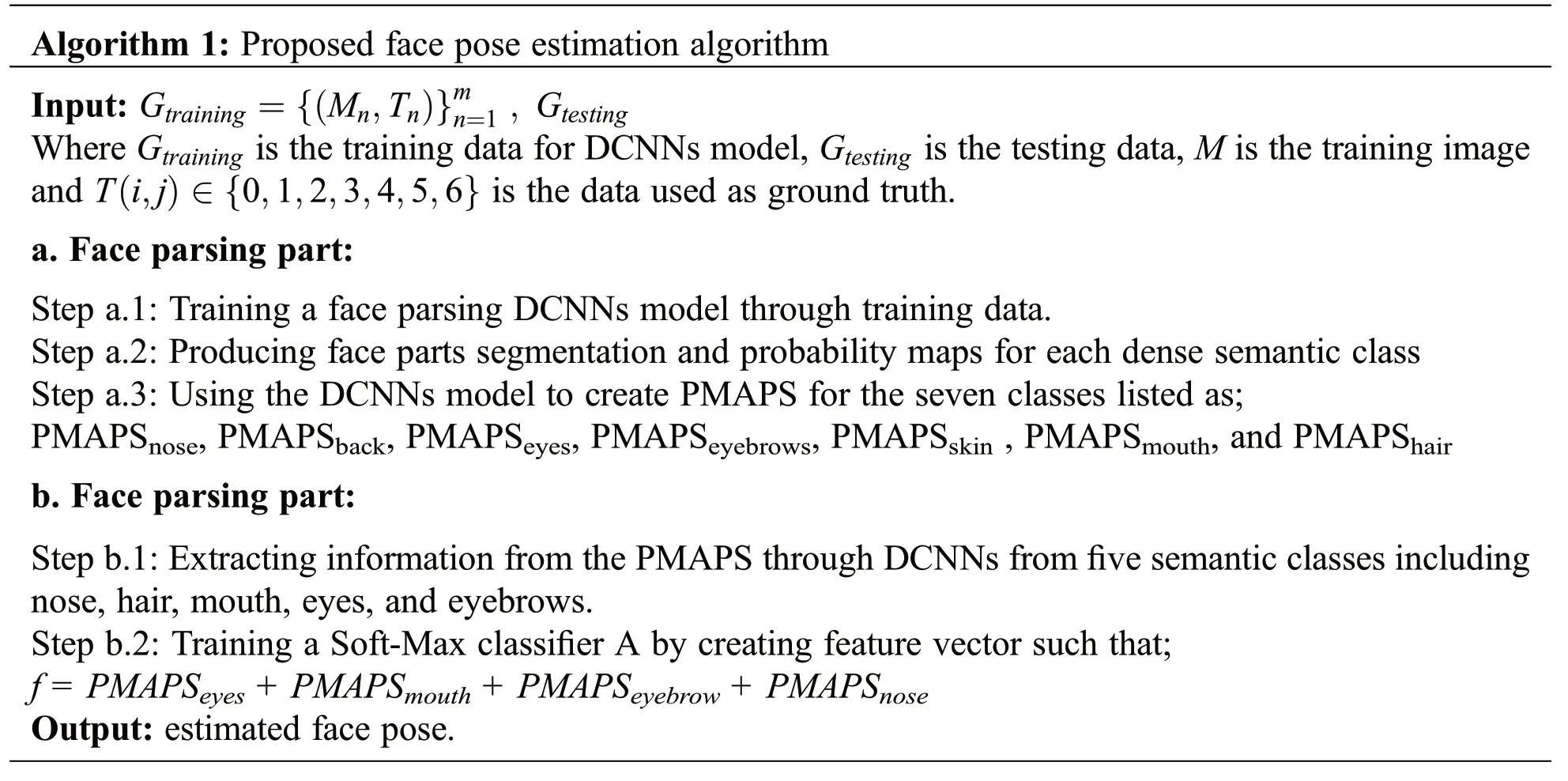
Algorithm 1:Proposed face pose estimation algorithm Input: Gtraining = Mn,Tn ( ){ }m n=1 , Gtesting Where Gtraining is the training data for DCNNs model,Gtesting is the testing data,M is the training image and T i,j( )∈ 0,1,2,3,4,5,6{}is the data used as ground truth.a.Face parsing part:Step a.1:Training a face parsing DCNNs model through training data.Step a.2:Producing face parts segmentation and probability maps for each dense semantic class Step a.3:Using the DCNNs model to create PMAPS for the seven classes listed as;PMAPSnose,PMAPSback,PMAPSeyes,PMAPSeyebrows,PMAPSskin ,PMAPSmouth,and PMAPShair b.Face parsing part:Step b.1:Extracting information from the PMAPS through DCNNs from five semantic classes including nose,hair,mouth,eyes,and eyebrows.Step b.2:Training a Soft-Max classifier A by creating feature vector such that;f =PMAPSeyes +PMAPSmouth +PMAPSeyebrow+ PMAPSnose Output:estimated face pose.
For head pose estimation, we used extracted features from PMAPS images through CNNs.After extracting the features, we train another Soft-Max classifier for each dataset.
We manually labeled 200 face images from each dataset for seven face classes.The manually labeled images are used to build a face parsing model.For all images of every dataset, the PMAPS are generated.When a testing image is provided as input, the face parsing model creates the PMAPS for seven face classes.We conduct detailed experiments to investigate which face features can help face pose estimation.
After detailed analyses, we decided to use PMAPS for five classes, including the eyes, nose, mouth,eyebrow, and hair.After extracting features through CNNs we concatenate five feature vectors with each other to build a single unique feature vector.We trained another Soft-Max classifier using the feature vector.To validate our model more precisely, we use ten-fold cross-validation experiments.However, we exclude those 200 images which we previously used to build our classifier.The PMAPS of a subject from Pointing’04 can be seen in Fig.2.From Fig.2, it can be noticed that changes in PMAPS are occurring as we move from one pose to another.

Figure 2:Segmentation results and probability maps from images of Pointing’04 dataset,where pose varies from-90°to+90°with 15°difference between two adjacent poses.The images are in the order where:row 1:original testing images,row 2:segmentation results with proposed face parsing module,row 3:probability maps for hair,row 4:probability maps for mouth,row 5:probability maps for nose,row 6:probability maps for eyes,and row 7:probability maps for eye brows
We investigate some interesting points during our experiments.We came to know that minor classes have more contribution towards face pose estimation system as compared to major classes (except hair).Hence, we use PMAPS of the four small classes (nose, eyes, brow, and mouth) and one major class hair.We ignore two major classes, skin and back.It can be seen from Fig.2, that PMAPS for minor classes highly differs from one pose to another.For example, considering the fifth row (i.e., PMAPS for the nose), in frontal face images, the nose is more exposed to the camera, and as a result, the nose is almost in the middle of the face image.As pose of the image changes from the center to left (0oto -90o) and right profile (0oto +90o), the PMAPS of the nose also moves accordingly.We use this information as a feature and encode it in a unique feature vector.
The same difference can be noticed from Fig.2 for four other PMAPS,including eyes,mouth,eyebrows,and hair.In extreme left and right profile images in some cases, the class information is entirely missing.This also clearly shows that our feature-based face pose estimation method highly depends on accurate face parts segmentation.
Hair class has a very complex geometry that varies from person to person.Our proposed face parsing part reports excellent labeling accuracy for hair.From the segmentation results in Fig.2, it can be observed how efficiently our face parsing module segments a hair class.The borderline for hair is detected by our face segmentation part in a much better way.
For face pose estimation,we label 200 images from each dataset.We build a face parsing model for each database using 200 manually labeled images.We train a Soft-Max classifier for face parsing.When a test face image is given to the face parsing module,segmentation results are produced,as some of these are shown in Fig.2.We use the probabilistic classification strategy and created PMAPS for each face class.We concatenate the five face classes’ information by first extracting information through CNNs and create a unique feature vector, with which we again train a Soft-Max classifier.In experiments, we adapt 10-fold cross-validation experiments and report average results in the paper.
6 Results and Discussion
6.1 Experimental Setup
We use the Intel i7 CPU for our experiments.We use 16G RAM with NVIDIA 840 M graphical processing unit.We use Tensor flow and Keras as experimental tools.We train our model for 40 Epochs and batch size 150.We keep this setting for all face parsing models developed for all four datasets.
6.2 Face Segmentation Results
Some remarks for face parsing results are summarized in the following paragraphs:
Some qualitative results are shown in Fig.2.The results show that face segmentation is better for the frontal poses as compared to profile.In contrast, labeling accuracy drops as the pose moves to right or left profile, which was expected as well, as minimal information are provided for training in case of extreme profile face images.
We also observe that as the pose moves to the right or left,labeling accuracy drops particularly for minor classes(nose,brow,eyes,and mouth).For extreme right or left profile face images,in some cases,the minor classes in some cases are completely missing.This can be seen from the images in Fig.2.In such cases,the PMAPS produced are also unclear and the segmentation part provides minimal information.
The performance of the face parsing part also highly depends on image quality.For example, for low quality images (AFLW), comparatively poor results are reported by our proposed method.While for images from high quality datasets, such as Pointing’04 we obtained better results and also surpassed previously reported results.
We labeled all face images through image editing software.We used the manually labeled images to build a face parsing model.We used no automatic segmentation tool in all this process.This kind of labeling strictly depends on the subjective perception of a single human involved in manual labeling.To provide accurate face labels to face images with such type of labeling is very difficult.Differentiating boundary regions of face parts in such cases is very difficult; for example, explicitly drawing a boundary region between skin and nose is not accurate.And lastly, this labeling method is very tedious and timeconsuming task.To label large number of images,sufficient time is needed.
6.3 Face Pose Estimation
To investigate which face features contribute significantly towards face pose estimation,we exploit the feature importance measure as reported in Pedregosa et al.[48].It is a Random Forest implementation that calculates how certain features contribute to a specific task.Fig.3 shows the importance of each face feature in face pose estimation.From Fig.3,it can be seen that the maximum contribution to face pose estimation is provided by five classes,including eyes,hair,nose,mouth,and brows.Therefore,we use PMAPS of only five features as feature descriptors and discarded the remaining two classes.
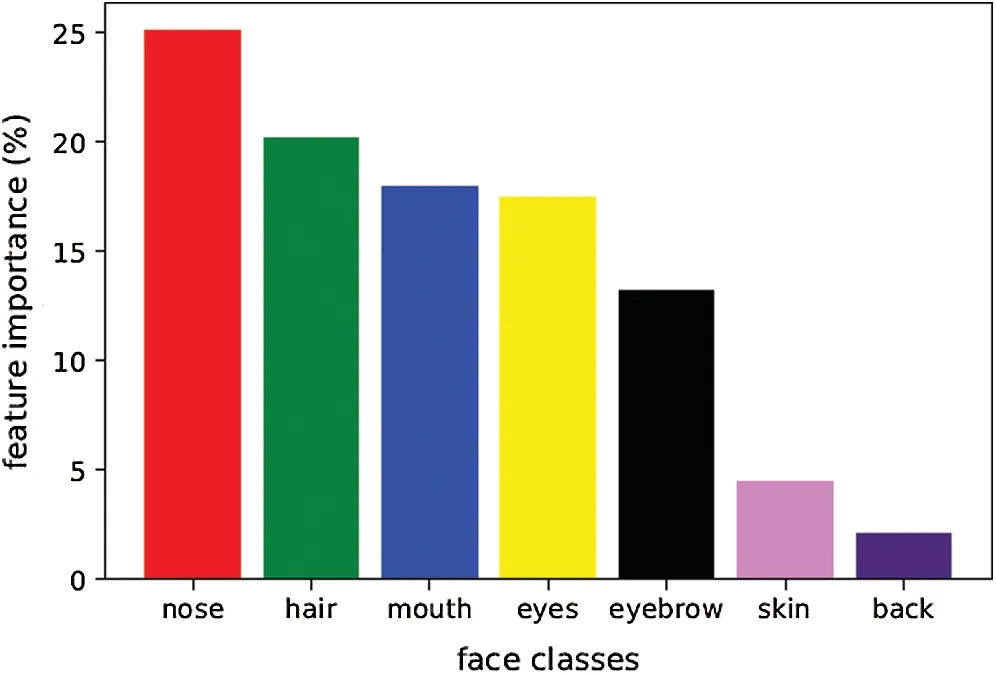
Figure 3:Feature importance of all the seven face classes including nose,hair,mouth,eyes,eyebrow,skin,and back mouth,and nose for face pose estimation
We evaluate our propose face pose estimation framework with two metrics,mean absolute error(MAE)and pose estimation accuracy (PEA).The MAE is a regression and PEA classification measures.MAE calculates the error between the estimated and actual pose, whereas PEA estimates how accurately a trained model estimates a pose.
The results obtained with the proposed face pose estimation framework on Poinitng’04 and its comparison with previous results are shown in Tab.3.From Tab.3, it can be seen that better results are obtained with the proposed model as compared to previous results.We explore all combinations of facial features and conclude to use just five classes.We obtain the best results as can be noticed from Tab.3.Some of the previous techniques in Tab.3 may use different validation protocols; for example, some methods use five-fold cross-validation during their experiments, whereas we perform our experiments with ten-fold cross-validation, which is more frequently used in the literature.
For AFLW, BU, and ICT-3DHPE results are reported only for MAE values.For a fair and exact comparison, we also report MAE values only.A complete summary of the results and then comparison with SOA is shown in Tab.3.The results reveal that we have better results for two datasets BU and ICT-3DHPE.AFLW images are collected from the internet with a very complex background.Most of these images are in wild conditions with poor resolution as well.Our reported results for AFLW are less as compared to previous results.From the segmentation results, we note that face parsing results of the face segmentation module are weak for these complex images.One possible reason for poor results for AFLW,is comparatively poor performance of the face segmentation part.
The other two datasets,BU and ICT-3DHPE are also collected in real-world conditions.However,the quality of the images is comparatively better,and the background scenario is also not much complex.As a result, we obtain better results as compared to results reported in the literature.

Table 3:Head pose estimation results with proposed method and its comparison with SOA
7 Conclusion
In the proposed work we introduced an end to end face parsing algorithm which tries to address a challenging problem of face pose estimation.We train a face parsing model through DCNNs by extracting useful information from different face parts.The face parsing model provides a class label for each pixel in a face image.We use a probabilistic classification technique and create PMAPS in the form of grey scale images for each face class.We perform a series of experiments to know which face feature helps in face pose estimation and conclude to use only five classes.We evaluate our proposed face pose estimation method with four datasets, including Pointing’04, BU, AFLW, and ICT-3DHPE obtaining better and competitive results.
Optimization of the face parsing part is one scenario to be addressed in the future.An important point to improve the performance of the face parsing system is by applying carefully well-managed engineering methods.For example,data augmentation[2]and foveated architecture[59]are some possible options to be adapted.Secondly,sufficient information is provided by the face segmentation part to address different visual recognition problems relating to the face.We provide a simple route towards some other complicated face analysis tasks, for example, gesture recognition,face beautification, and many more.
Funding Statement:This work was partially supported by Institute of Information & communications Technology Planning & Evaluation (IITP) grant funded by the Korea government (MSIT) (2020-0-01592) and Basic Science Research Program through the National Research Foundation of Korea(NRF) funded by the Ministry of Education under Grant (2019R1F1A1058548) and Grant(2020R1G1A1013221).
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- Understanding the Language of ISIS:An Empirical Approach to Detect Radical Content on Twitter Using Machine Learning
- A Self-Learning Data-Driven Development of Failure Criteria of Unknown Anisotropic Ductile Materials with Deep Learning Neural Network
- An Effective Numerical Method for the Solution of a Stochastic Coronavirus(2019-nCovid) Pandemic Model
- A Novel Approach to Data Encryption Based on Matrix Computations
- Fuzzy Based Decision Making Approach for Evaluating the Severity of COVID-19 Pandemic in Cities of Kingdom of Saudi Arabia
- Industry 4.0:Architecture and Equipment Revolution