Anomaly Classi cation Using Genetic Algorithm-Based Random Forest Model for Network Attack Detection
2021-12-14AdelAssiri
Adel Assiri
Management Information Systems Department,College of Business,King Khalid University,Abha,61421,Saudi Arabia
Abstract:Anomaly classification based on network traffic features is an important task to monitor and detect network intrusion attacks.Network-based intrusion detection systems(NIDSs)using machine learning(ML)methods are effective tools for protecting network infrastructures and services from unpredictable and unseen attacks.Among several ML methods,random forest(RF)is a robust method that can be used in ML-based network intrusion detection solutions.However,the minimum number of instances for each split and the number of trees in the forest are two key parameters of RF that can affect classification accuracy.Therefore,optimal parameter selection is a real problem in RF-based anomaly classification of intrusion detection systems.In this paper,we propose to use the genetic algorithm(GA)for selecting the appropriate values of these two parameters,optimizing the RF classifier and improving the classification accuracy of normal and abnormal network traffics.To validate the proposed GA-based RF model,a number of experiments is conducted on two public datasets and evaluated using a set of performance evaluation measures.In these experiments,the accuracy result is compared with the accuracies of baseline ML classifiers in the recent works.Experimental results reveal that the proposed model can avert the uncertainty in selection the values of RF’s parameters,improving the accuracy of anomaly classification in NIDSs without incurring excessive time.
Keywords:Network-based intrusion detection system(NIDS);random forest classifier;genetic algorithm;KDD99;UNSW-NB15
1 Introduction
Network-based intrusion detection system(NIDS)is a network security tool that works together with popular data encryption algorithms and firewalls to protect network resources and services[1].The work to develop an effective NIDS to detect malicious activities and network intrusion attacks is still the motivation for developers and researchers.In the literature of intrusion detection system(IDS),a number of methods and models have been proposed to prevent the networks from malicious threats and attacks.For instance,Song et al.[2],Gong et al.[3],and Murugesan et al.[4]offered several techniques to trace back the IP address.Nguyen et al.[5],Crotti et al.[6],and Callado et al.[7]introduced a number of methods to classify IP traffics of the networks.Dharmapurikar et al.[8],Zhou et al.[9],Chen et al.[10],Hu et al.[11],Das et al.[12],and Mabu et al.[13]developed many techniques for intrusion detection in the networks and explained the performance,the advantages,and disadvantages of these developed techniques.Hadlington[14]presented a study summaries the human causes that leads to some cyber security violation issues.Alternatively,the machine learning(ML)methods can be a suitable and adaptive approach for detecting abnormal network traffics due to the continuous changes of attacks patterns.
Recently,ML methods have been used for solving many problems in different applications[15,16].The ML-based data analysis is utilized as a tool for automatic classification[17–19],decision making[20],and prediction[21,22].For network attacks detections,threats,and malicious executables,supervised and unsupervised learning technique has been achieved a promising result[23–26].ML learning approach is capable to give the networks devices the ability to learn attacks patterns from past data traffics and detect the unknown and new attacks[27–29].
In previous works,numerous studies have been proposed using ML methods for network intrusion detection.The work introduced by Solanki et al.[30]has computed the accuracy of decision tree(C4.5)and support vector machine(SVM)methods to detect intrusion attacks.The two methods were tested on a public dataset contains four attacks.The authors reported that the accuracy of SVM was less than the accuracy of C4.5 method.The authors in[31]offered a work based on a number of ML classifiers to detect the common attacks in the networks and determining the best.They determined the suitable classifier for each of attack and reported that the most classifiers have achieved a high accuracy result to detect the denial of service attacks.
Gao et al.[32]developed a technique to analyze the normal and abnormal data traffics using hidden Markov model.The authors did a set of experiments and achieved 63.2% accuracy result.Gomez et al.[33]proposed a study for network-based IDS based on fuzzy logic.The authors in[9]introduced an approach for classifying periodic patterns of network traffics and detecting normal or abnormal behaviors using Fourier transform method.
An audit technique based on the frequency happened in the data traffics of the networks has proposed by Ye et al.[34].However,the data used for testing in this study was simple,pure and did not reflect the real states of network traffics.Additionally,a Chi-square test is used by Goonatilake et al.[35]for detecting abnormal network traffics in IDS.The study in[36]has compared and analyzed the performance of five architectures of artificial neural networks for IDS.The study shows that the quasi-Newton and conjugate gradient descent attained improved accuracy results.The works in[37,38]have developed some models for detecting network intrusion attacks using ML methods with swarm intelligence algorithm.
Some comparative studies on ML methods have been proposed for network defense[39]and botnet attack detection[40,41].However,the performance of ML methods for anomaly classification in NIDSs still needs more improvements in terms of time cost and accuracy.Recently,Khan et al.[42]introduced a comparative study on ML methods for NIDS.They have mentioned that the accuracy results of random forest(RF)is better than the other ML methods.
In this study,a genetic-based RF model is proposed and compared with the baseline ML methods for network intrusion detection in the state-of-the-arts.The experiment is conducted on two available public datasets,namely,KDD99[43]and UNSW-NB15[44].The main contribution of the study is to apply the genetic algorithm(GA)to select the appropriate values of RF classifier for improving its accuracy result for network intrusion detection.Moreover,another contribution of the work is to present a comparative study on ML methods for anomaly classification in NIDS using a set of evaluation measures.
The rest of the paper is structured as follows:Section 2 describes the research methods and the main steps of the proposed IDS model.The experiments and discussion on the used datasets are given in Section 3.Finally,Section 4 summarizes the conclusion of the work.
2 Research Methods
2.1 GA
GAwas presented initially by Holland[45].It is a form of inductive learning strategy to provide another method to conventional optimization methods based on adaptive search techniques.GA can find the nearoptimal solution for problems that need complex optimization.It is a stochastic method depends on some natural phenomena based on natural selection and genetic inheritance.GA is the most common class of EA[46].GA works on a population of individuals or chromosomes that represent the candidate solutions for a given problem.Each individual compete with others to reproduce based on Darwin’s principle(survival of the fittest)in each generation of evolution.
All the individuals are evaluated by a fitness function that expresses the importance of the individual as a solution.Then select the best parent individuals and apply the crossover and mutation operator to produce the new individuals(offspring)for the next generation.Crossover operator combines the features of two selected parents to create two offspring.Mutation operator changes one or more components of the selected individual in order to prevent any stagnation that may occur during the search process.After a number of generations in evolution when the stopping criterion is met,the individuals that survived in the population are considered the optimal solutions[29].Algorithm 1 summarizes the main steps of GA.

Algorithm 1:Genetic algorithm(GA)
2.2 RF Classifier
The RF classifier is a powerful ML tool that can be used for solving classification and regression problems.RF is one of the ensemble learning methods that can build a number of decision trees[47].For building trained RF model,two steps of randomness are used:
●Individually and randomly,each decision tree is constructed using different samples of the training dataset.
●During the construction of each tree,a part ofmsamples is randomly selected from the training dataset.The split point of thesemsamples is used as best split.In a case of new samplec,the RF can classify or predictcby aggregated decision trees.For RF that hasndecision trees,the output is the probability of the class labelyfor the samplecgiven a feature vectorx.The equation of RF ensemble learning can be computed as follows:

In other words,the RF can average the probability of decision trees obtained using different random samples of the original dataset[47].Fig.1 visualizes the construction process of RF according to ensemble learning concept.
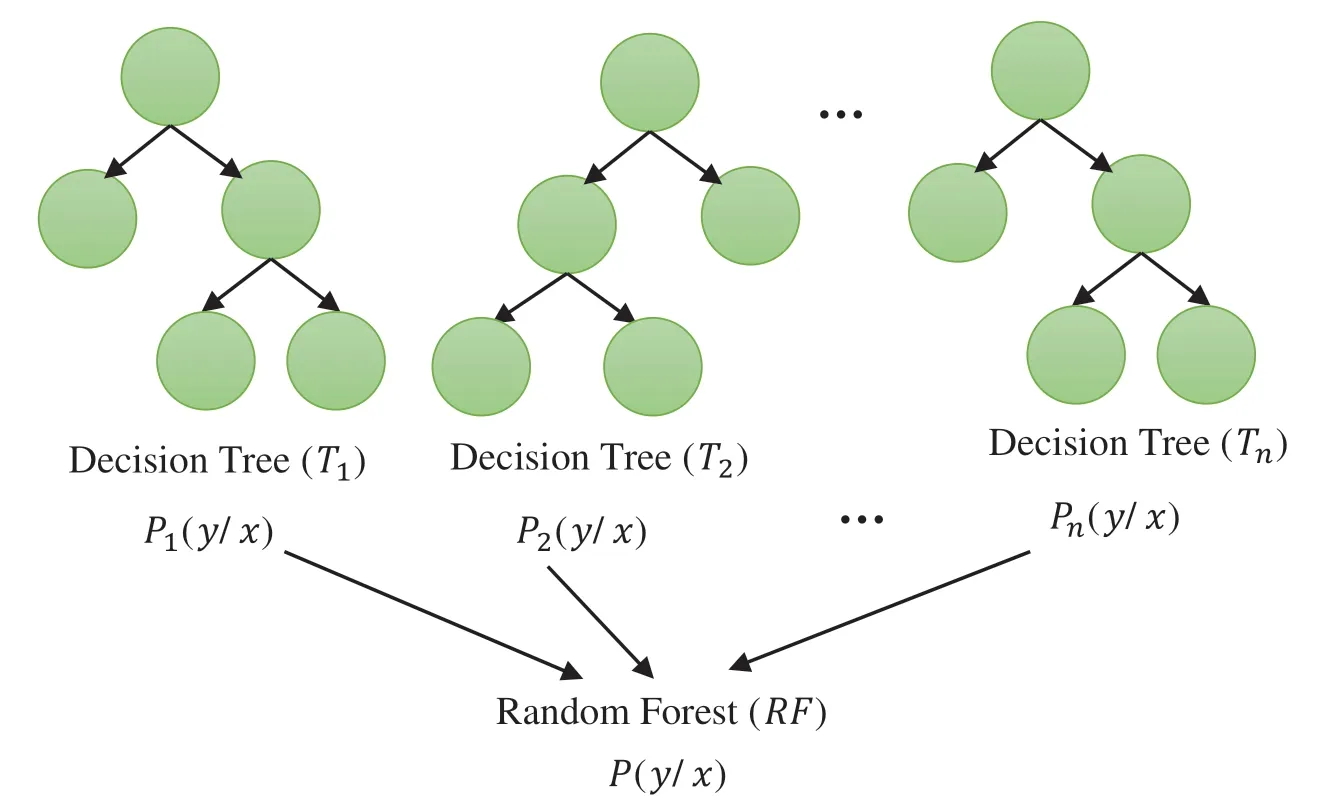
Figure 1:Construction process of random forest(RF)according to ensemble learning concept
The RF classifier has been used in a wide range of applications,such as image classification[48],network intrusion detection[49],and neuroimaging[50].Algorithm 2 defines the RF steps.

Algorithm 2:Random forest(RF)pseudo-code
In this research,we explore the application of GA-based RF for detecting intrusion attack throughout the features of network data traffic.
2.3 GA-Based RF Model for IDS
The idea behind the GA-based RF model is to optimize the RF classifier by selecting the appropriate parameters’ values and improve the detection rate of NIDS by using the optimized RF.The GA can generate random values for the specific parameters of RF and build a new decision boundary that has a highest value of GA fitness function.In detail,the datasets for training and testing the GA-based RF model are prepared from the network data traffics.The decision boundary of GA-based RF model is trained using training set and GA.After that,the trained GA-based RF model with the appropriate parameters’ values is tested to detect normal and abnormal class label of samples in the testing set.Fig.2 illustrates the main steps to build GA-based RF model for IDS.
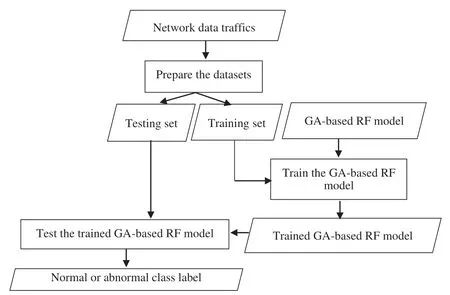
Figure 2:The main steps to build genetic algorithm(GA)-based random forest(RF)model for intrusion detection system(IDS)
3 Experiments and Discussion
The study experiments are conducted on a laptop has a CPU processor Intel Core i7-4510U with 2.0 GHz,8 GB RAM,and a 64 bit Windows 10 operating system.Python programming language is used to implement the experiments.Two public datasets,namely,KDD99 and UNSW-NB15 are employed to evaluate and compare the proposed model.
3.1 Datasets Description
As mentioned above,the datasets used in the experiments are KDD99[43]and UNSW-NB15[44]datasets.The KDD99 dataset is divided into two sets:A training set contains 145,586 samples and testing set includes 73,269 samples.The UNSW-NB15 dataset is also separated into two sets:a training set consists of 175,341 samples and a testing set has 82,332 samples.These datasets are processed and normalized to be suitable for training and testing the models.Figs.3 and 4 display the distribution of samples in the training and testing sets according to normal and abnormal network traffics.
To evaluate the proposed GA-based RF and other baseline classifiers,the training samples of two sets are used first to train these classifiers and build trained models;then,these trained models are tested on the two testing sets.
3.2 Performance Evaluation Measures
The results of experiments are assessed based on three measures.These measures are accuracy,sensitivity,and precision,computed as follows:

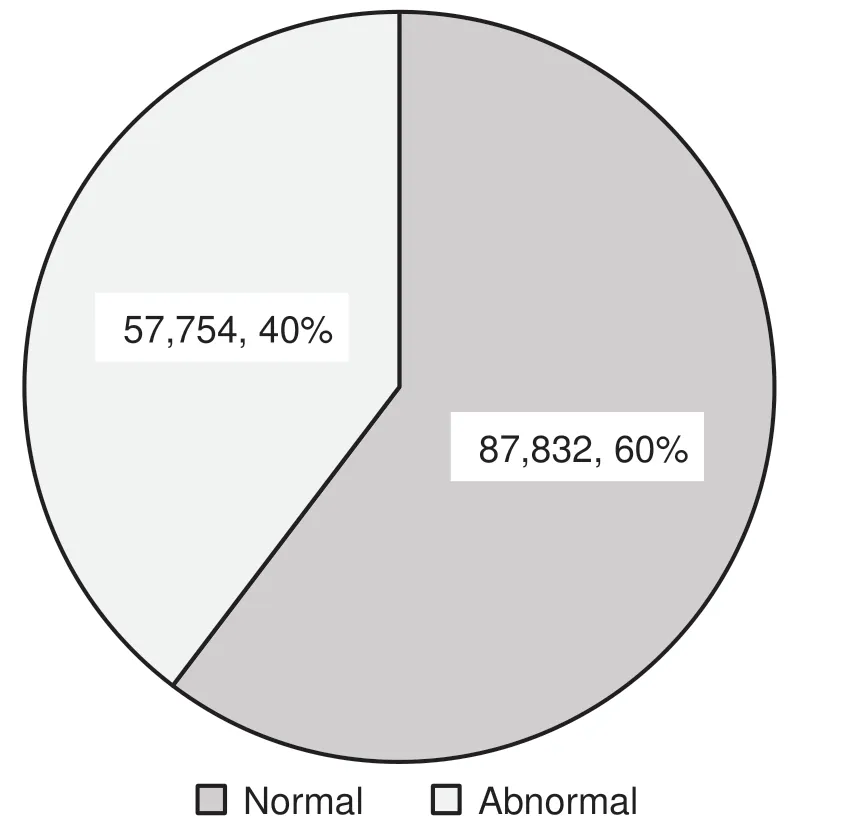
Figure 3:The number of normal or abnormal samples in the KDD99 training set
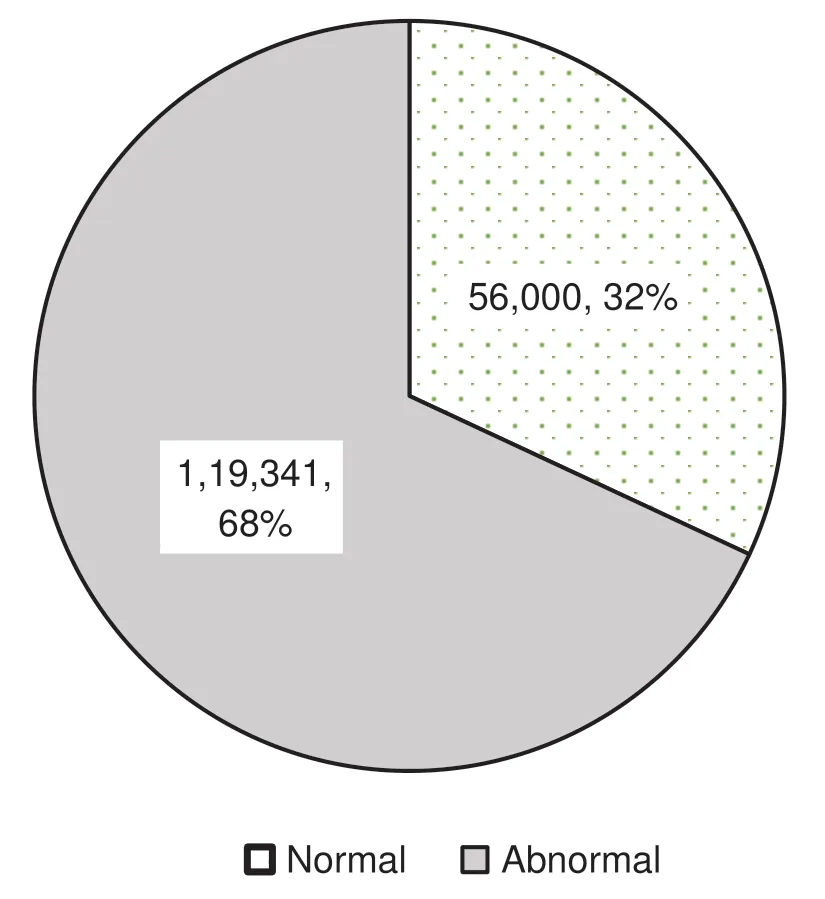
Figure 4:The number of normal and abnormal samples in the UNSW-NB15 training set

FP and FN are the number of false positives and negatives.TP and TN are the number of true positives and negatives.
3.3 Results and Comparisons
In this section,the results of the experiments are presented and compared with the results of recent related work.After building the GA-based RF model using the KDD99 training set,the best values of the minimum number of instances for each split and the number of trees in the RF are selected to be 17 and 2,respectively.For the UNSW-NB15 training set,the value of the minimum number of instances for each split is 4 and the value of the number of trees in the forest is also 2.The other parameters of RF are fixed to have the default values.Tabs.1 and 2 demonstrate the results of confusion matrices for testing the model on the KDD99 and UNSW-NB15 testing sets.

Table 1:Results of confusion matrix for normal and abnormal classification of the KDD99 testing set

Table 2:Results of confusion matrix for normal and abnormal classification of the UNSW-NB15 testing set
From the results of confusion matrices,the performance evaluation measures are computed and shown in Tabs.3 and 4.As seen in the Tab.3,the GA-based RF achieves 97.2%of the accuracy and 97.0%for the weighted average of precision and recall on the KDD99 testing set.In addition,it obtains 86.7% of the accuracy and 87.0% for the weighted average of precision and recall on the UNSW-NB15 testing,which is noisy and more complex.
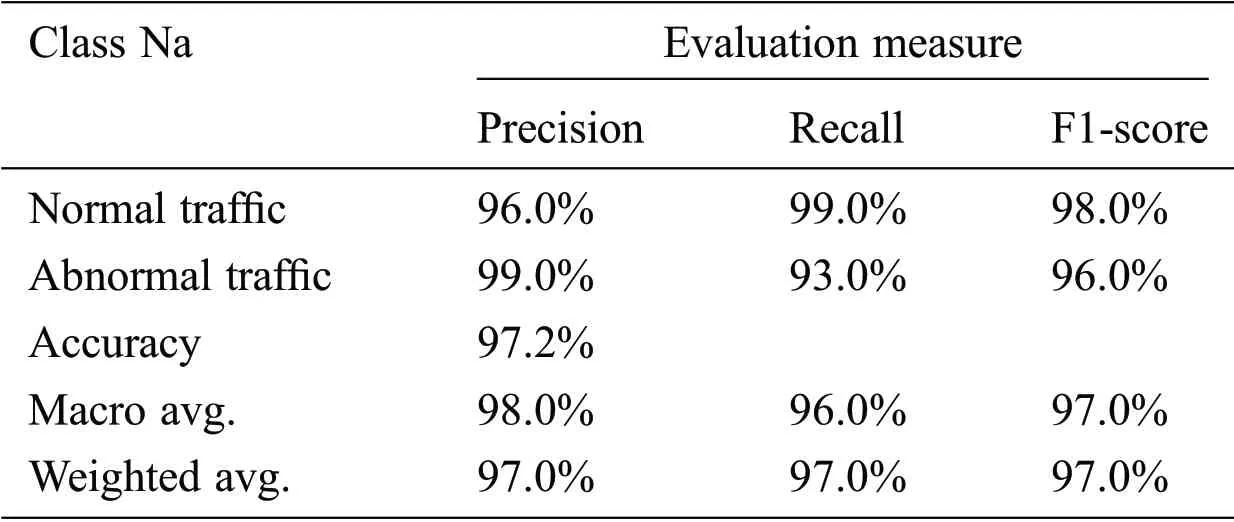
Table 3:The performance evaluation results for anomaly classification of the KDD99 testing set
To compare the accuracy results of optimized RF classifier to classify anomalies with the traditional RF and other baseline classifiers in the recent work[42],Tabs.5 and 6 show the accuracy results on the same testing sets of KDD99 and UNSW-NB15.
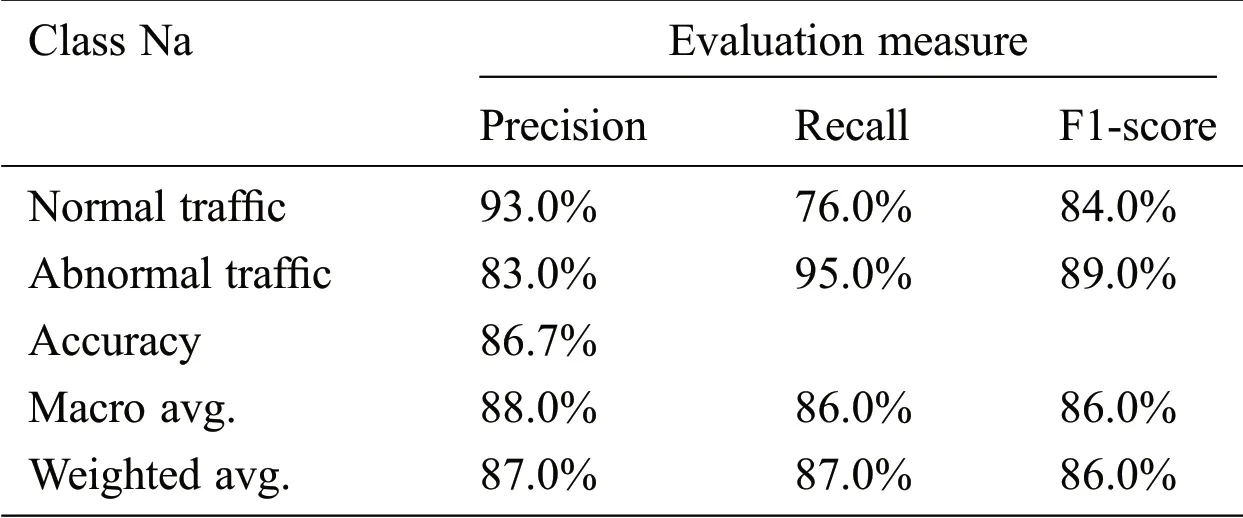
Table 4:The performance evaluation results for anomaly classification of the UNSW-NB15 testing set
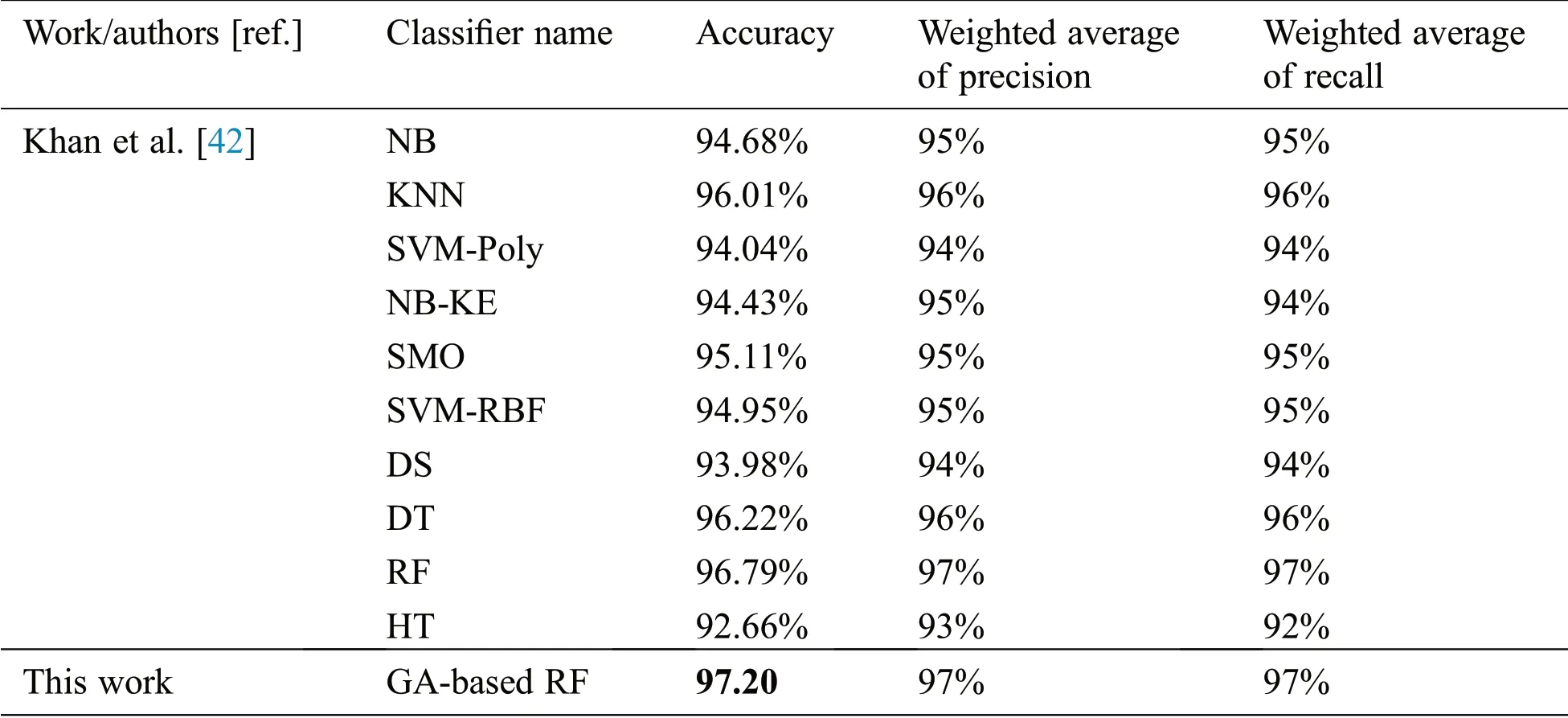
Table 5:The accuracy results of the GA-based RF model compared with the baseline classifiers in recent work[42]using KDD99 testing set
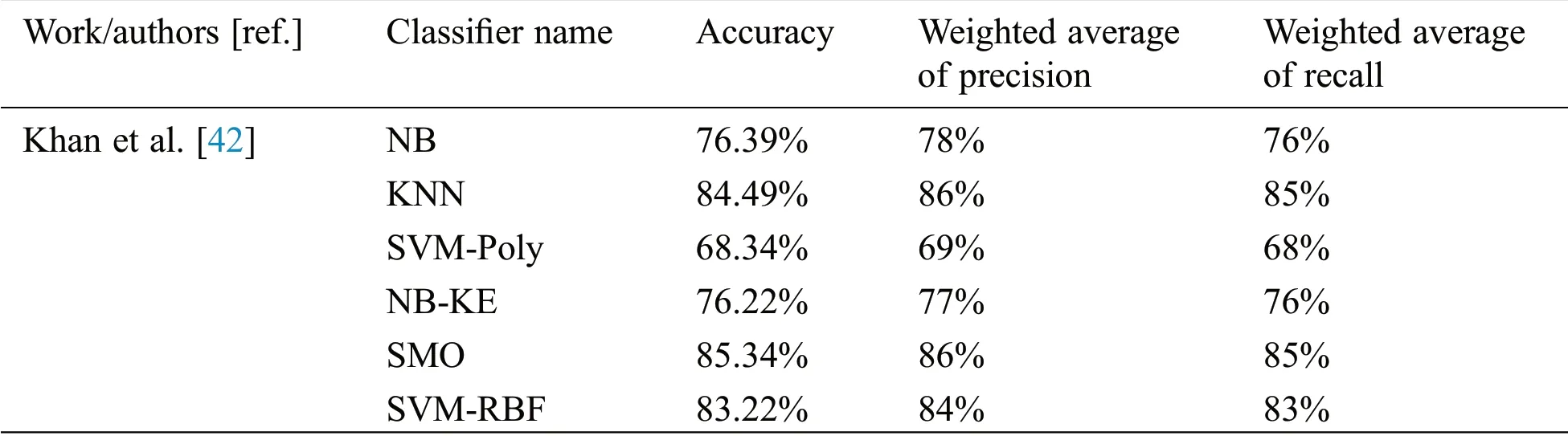
Table 6:The accuracy results of the GA-based RF model compared with the baseline classifiers in recent work[42]using UNSW-NB15 testing set
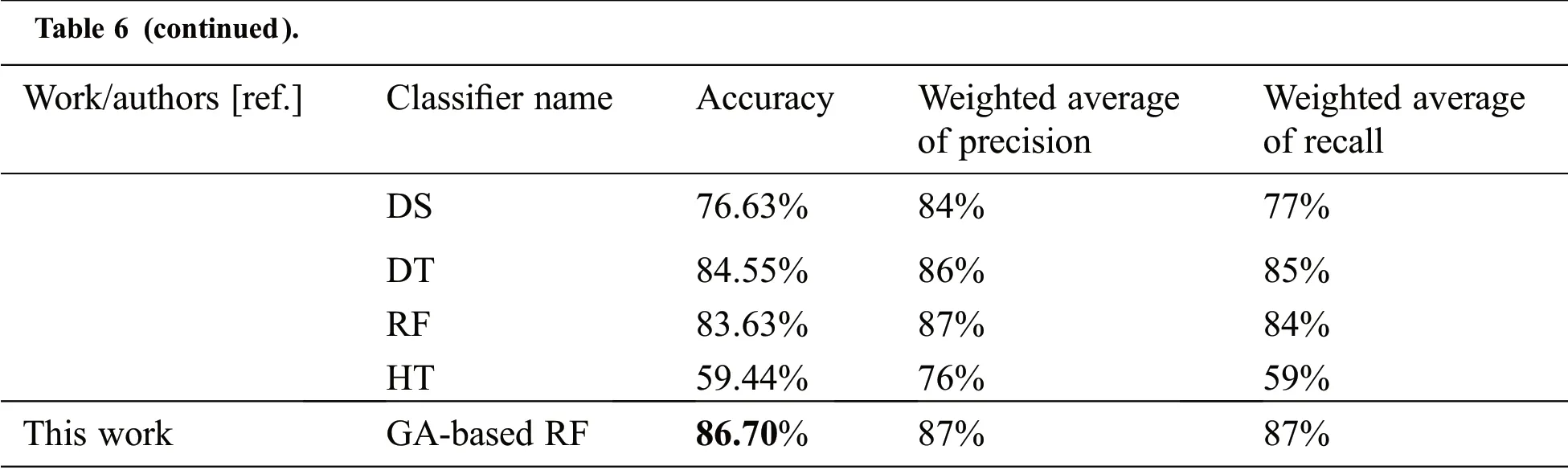
Note.SVM,support vector machine;RF,random forest;GA,genetic algorithm.
As shown in the Tabs.5 and 6,the accuracy results highlighted in the boldface font clarify that the GAbased RF improves the accuracy of the RF due to selecting the best values of its parameters and outperforms the other ML baseline classifiers.
4 Conclusion and Future Work
In this paper,a GA-based RF model is proposed to classify normal and abnormal networks traffics for IDS.The GA is used for selecting the appropriate values for two parameters of RF.These parameters are the minimum number of instances for each split and the number of trees in the forest,optimizing the RF classifier and improving the accuracy of anomaly classification and intrusion detection.A set of experiments were conducted on two public dataset and evaluated using a set of performance evaluation measures.The experimental results revealed that the selection of suitable values of RF classifier has improved the accuracy of network anomaly classification compared to the RF with default values.Moreover,the proposed GA-based RF model outperforms the ML models with high detection rates of 97.20% for KDD99 test set and 86.70% for UNSW-NB15 test set.In the future work,the proposed model will be used with feature selection methods to detect the types of attacks in the abnormal network traffic and enhance the network-based IDS.
Acknowledgement:The author would like to express his gratitude to King Khalid University,Saudi Arabia for providing administrative and technical support.
Funding Statement:The authors received no specific funding for this study.
Conflicts of Interest:The author declares that he have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- Design of Authoring Tool for Static and Dynamic Projection Mapping
- Detecting Lumbar Implant and Diagnosing Scoliosis from Vietnamese X-Ray Imaging Using the Pre-Trained API Models and Transfer Learning
- Design of a Compact Monopole Antenna for UWB Applications
- A Smart Wellness Service Platform and Its Practical Implementation
- Fingerprint-Based Millimeter-Wave Beam Selection for Interference Mitigation in Beamspace Multi-User MIMO Communications
- Multilayer Self-Defense System to Protect Enterprise Cloud