Artificial Intelligence-Based Semantic Segmentation of Ocular Regions for Biometrics and Healthcare Applications
2021-12-14RizwanAliNaqviDildarHussainandWoongKeeLoh
Rizwan Ali Naqvi,Dildar Hussain and Woong-Kee Loh
1Department of Unmanned Vehicle Engineering,Sejong University,Seoul,05006,Korea
2School of Computational Science,Korea Institute for Advanced Study(KIAS),Seoul,02455,Korea
3Department of Software,Gachon University,Seongnam,13120,Korea
Abstract:Multiple ocular region segmentation plays an important role in different applications such as biometrics,liveness detection,healthcare,and gaze estimation.Typically,segmentation techniques focus on a single region of the eye at a time.Despite the number of obvious advantages,very limited research has focused on multiple regions of the eye.Similarly,accurate segmentation of multiple eye regions is necessary in challenging scenarios involving blur,ghost effects low resolution,off-angles,and unusual glints.Currently,the available segmentation methods cannot address these constraints.In this paper,to address the accurate segmentation of multiple eye regions in unconstrainted scenarios,a lightweight outer residual encoder-decoder network suitable for various sensor images is proposed.The proposed method can determine the true boundaries of the eye regions from inferior-quality images using the high-frequency information flow from the outer residual encoder-decoder deep convolutional neural network(called ORED-Net).Moreover,the proposed ORED-Net model does not improve the performance based on the complexity,number of parameters or network depth.The proposed network is considerably lighter than previous state-of-theart models.Comprehensive experiments were performed,and optimal performance was achieved using SBVPI and UBIRIS.v2 datasets containing images of the eye region.The simulation results obtained using the proposed OREDNet,with the mean intersection over union score(mIoU)of 89.25 and 85.12 on the challenging SBVPI and UBIRIS.v2 datasets,respectively.
Keywords:Semantic segmentation;ocular regions;biometric for healthcare;sensors;deep learning
1 Introduction
In the last few decades,researchers have made significant contributions to biometrics,liveness detection,and gaze estimation systems that rely on traits such as the iris,sclera,pupil,or other periocular regions[1].Interest in these traits is increasing each day because of the considerable importance of ocular region applications and their significant market potential.Biometric technology has become a vital part of our daily life,as unlike conventional methods,these approaches do not require an individual to memorize or carry any information,such as pins,passwords,or IDs[2].Iris segmentation has drawn significant attention from the research community owing to the rich and unique textures of the iris,such as:rings,crypts,furrows,freckles,and ridges[3].While ocular traits other than the iris are less frequently studied,researchers have been actively investigating other periocular regions,such as the sclera and retina,to collect identity cues that might be useful for stand-alone recognition systems or to supplement the information generally used for iris recognition[4].
A majority of previous research studies on eye region segmentation were restricted to a single ocular region at a time,for e.g.,focusing only on the iris,pupil,sclera,or retina.In multi-class segmentation,more than one eye region is segmented from the given input image using a single segmentation network.Inexplicably,very few researchers have developed multi-class segmentation techniques for the eye regions,despite several advantages in different applications.Namely,under challenging conditions,the segmentation performance can be maintained or sometimes be even enhanced when using multiple region segmentation,as the targeted region can provide useful contextual information about other neighboring regions[5].For example,boundary of iris region can provide useful information about the boundary of the sclera and pupil region.Similarly,the eyelash area presents a constraint for the sclera region[6].Another potential advantage is that multi-biometric systems can be introduced without cost and computation overheads,which can work efficiently work for the segmentation of multiple target classes using a single approach[7].
In this work,we attempt to address the research gaps in the segmentation of multiple eye regions using a single network,as shown in Fig.1.The proposed network can segment the input eye image into four main classes corresponding to the iris,sclera,pupil,and background region using a single model.Over the last few years,deep learning convolutional neural network(CNN)models witnessed rapid development,to be an influential method for image processing tasks.CNNs have outperformed conventional methods in a wide range of applications,such as in medical and satellite image analysis.The proposed method is based on deep learning models for semantic segmentation in images,specifically on convolutional encoder-decoder networks.This design approach is based on the recently introduced SegNet architecture[8].ORED-Net was developed based on the outer residual encoder-decoder network.The proposed network achieves a higher accuracy with reduced network depth and fewer number of parameters and layers by implementing only non-identity outer residual paths from the encoder to the decoder.
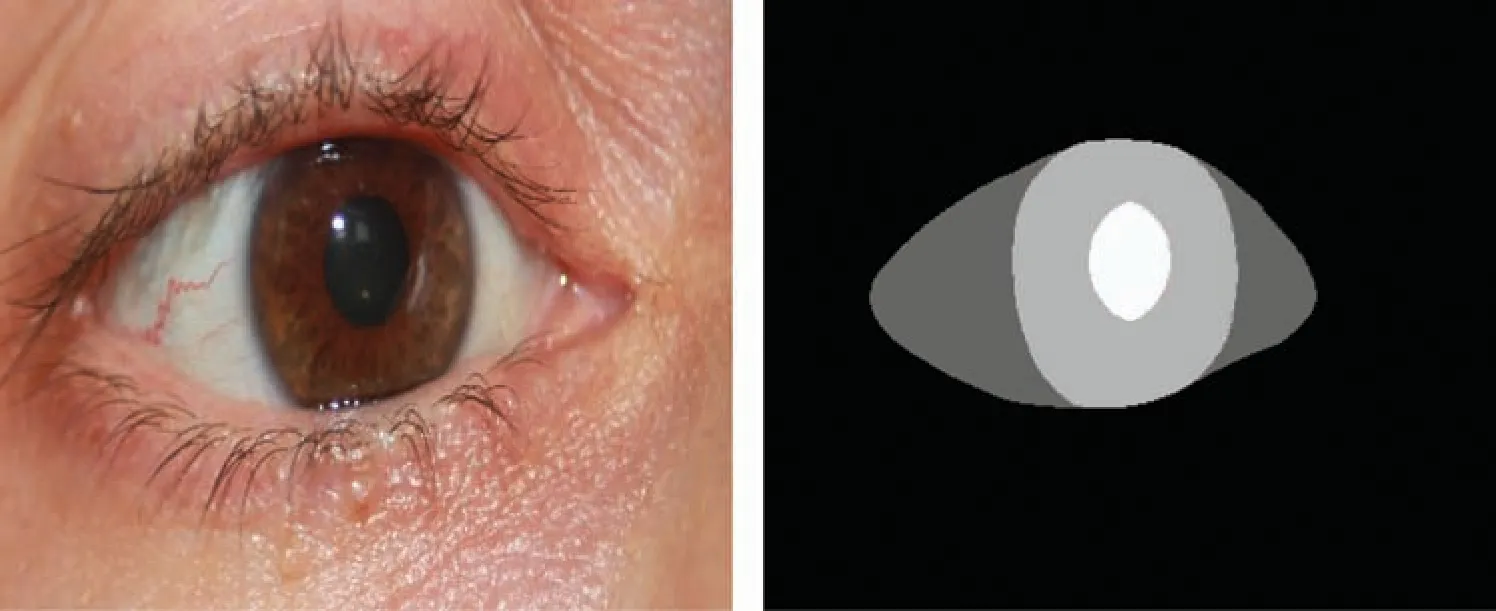
Figure 1:Sample images of multi-class eye segmentation,illustrating the input eye image(left),ground truth image(right).Each color shade represents a different eye region
ORED-Net is novel in the following four ways:
•ORED-Net is a semantic segmentation network without a preprocessing overhead and does not employ conventional image processing schemes.
• ORED-Net is a standalone network for the multi-class segmentation of ocular regions.
•ORED-Net uses residual skip connections from the encoder to the decoder to reduce information loss,which allows the flow of high-frequency information through the model,thus achieving higher accuracy with a few layers.
• The performance of the proposed ORED-Net model was tested on public datasets collected under various environments.
In this study,the results obtained with the SBVPI[9]and UBIRIS.v2[10]datasets for the iris,sclera,pupil,and background classes are reported.In addition,the proposed model is compared with state-ofthe-art techniques from the literature.The results demonstrate that the proposed method is the most suitable technique for ocular segmentation,which can be incorporated in recognition procedures.
The rest of the paper is structured as follows.In Section 2,a brief overview of related literature is provided.In Section 3,the proposed approach and working procedure are described.The results of the evaluation and analysis are discussed in Section 4.Finally,conclusion and future work are presented in Section 5.
2 Literature Review
Very few studies have focused on multi-class eye segmentation,particularly for segmenting multiple eye regions from the given images using a single segmentation model.Recently,Rot et al.[7]reported the segmentation of multi-class eye regions based on the well-known convolutional encoder-decoder network SegNet.They studied the segmentation of multiple eye regions such as the iris,sclera,pupil,eyelashes,medial canthus,and periocular region.This study required post-processing through thresholding strategy on probability maps and an atrous CNN with the conditional random field detailed in Luo et al.[11].The results were extracted using the Multi-Angle Sclera Database(MASD).Naqvi et al.proposed the Ocular-Net CNN for the segmentation of multiple eye regions,including the iris and sclera.This network consists of non-identity residual paths in a lighter version of both the encoder and decoder.Residual shortcut connections were employed with increasing network depth to enhance the performance of the model[12].In addition,the iris and sclera were evaluated on different databases.Hassan et al.proposed the SIP-SegNet CNN for joint semantic segmentation of the iris,sclera,and pupil.A denoising CNN(DnCNN)was used to denoise the original image.In SIP-SegNet,after denoising with DnCNN,reflection removal and image enhancement were performed based on contrast limited adaptive histogram equalization(CLAHE).Then,the periocular information was extracted using adaptive thresholding,and this information was suppressed using the fuzzy filtering technique.Finally,a densely connected fully convolutional encoder-decoder network was used for semantic segmentation of multiple eye regions[13].Various metrics were used to evaluate the proposed method that was tested on the CASIA sub-datasets.
The Eye Segmentation challenge for the segmentation of key eye regions was organized by Facebook Research with the purpose to developing a generalized model with the condition of least complexity in terms of the model parameters.Experiments were conducted on the OpenEDS dataset which is a large-scale dataset of eye images captured by a head-mounted display with two synchronized eye facing cameras[14].To address the challenge concerning the semantic segmentation of eye regions,Kansal et al.[15]proposed Eyenet,Attention-based Convolutional Encoder-Decoder Network for accurate segmentation of four different eye regions,namely the iris,sclera,pupil and background.Eyenet is based on non-identity mapping based residual connections in both the encoder and decoder.Two types of attention units and multiscale supervision were proposed to obtain accurate and sharp boundary eye regions.Eye segmentation using a lightweight model was demonstrated by Huynh et al.Their approach involved the conversion of the input image to grayscale,segmentation of the eye regions with a deep network model,and removal of the incorrect areas using heuristic filters.A heuristic filter was used to reduce the false positive in the output of the model[16].
Tab.1 presents a comparison of the proposed method with other methods for the multi-class segmentation of ocular regions along with their strengths and weaknesses.
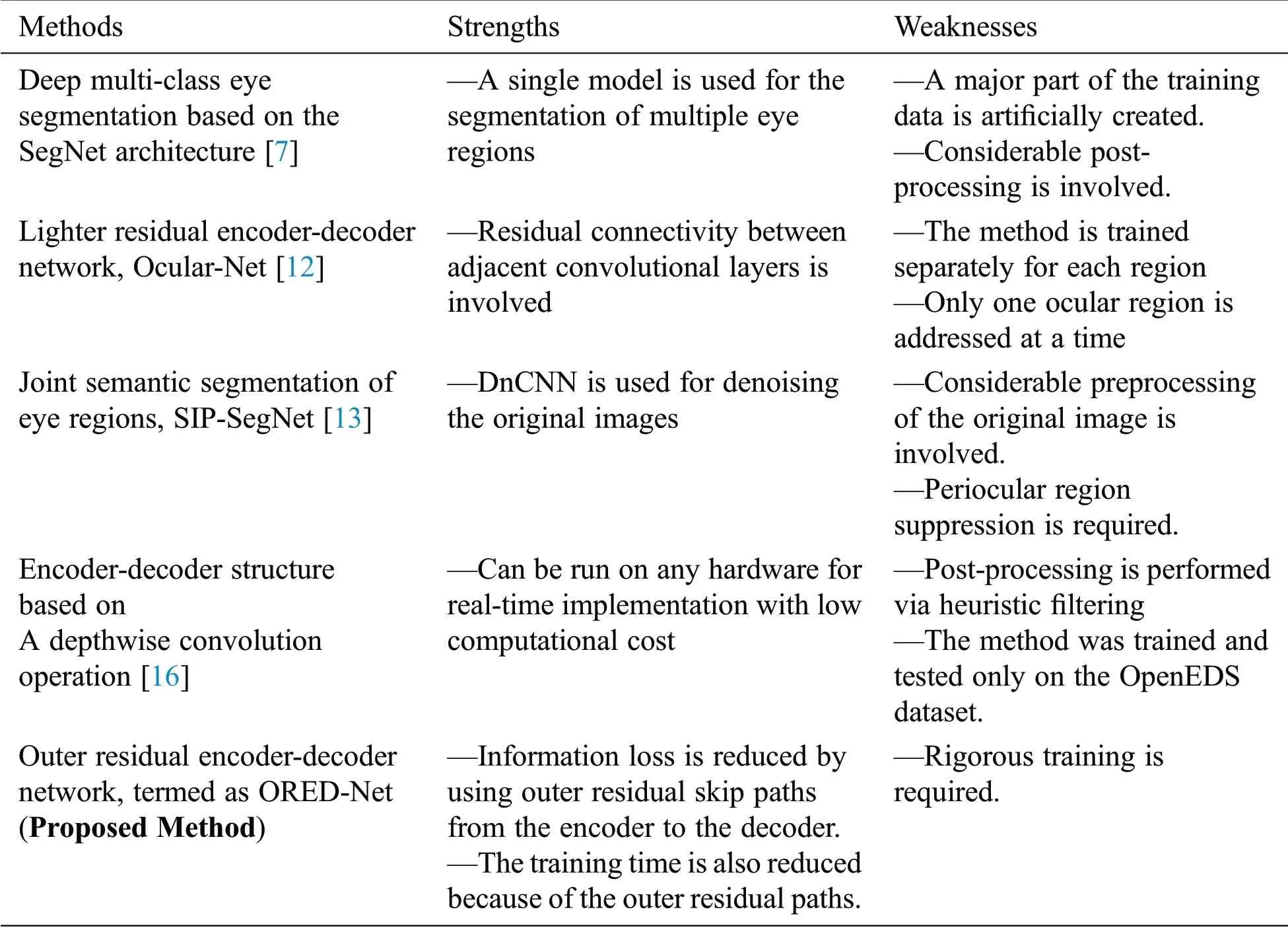
Table 1:Comparison of the proposed method with other multi-class segmentation methods
3 Proposed Method for Eye Region Segmentation
3.1 Overview of the Proposed Model
The flowchart of the proposed ORED-Net for semantic segmentation of multiple eye regions is shown in Fig.2.The proposed network is a fully convolutional network based on non-identity residual connections from the encoder network to the decoder network.The input image is fed into the convolutional network without an initial preprocessing overhead.An encoder and decoder are incorporated in the proposed ORED-Net for multi-class segmentation of the full input eye images.The functionality of the encoder is to downsample the given input image until it can be represented in terms of very small features,whereas the decoder performs the reverse operation.The decoder upsamples the image back to its original dimensions using the small features produced by the encoder.In addition to the reverse process of downsampling,the decoder plays another very important role of predicting multiple classes,namely the iris,sclera,pupil,and background.The prediction task is performed using the Softmax loss function and a pixel classification layer.The class of each pixel in the image is predicted by the pixel classification layer,and the designated label is assigned.
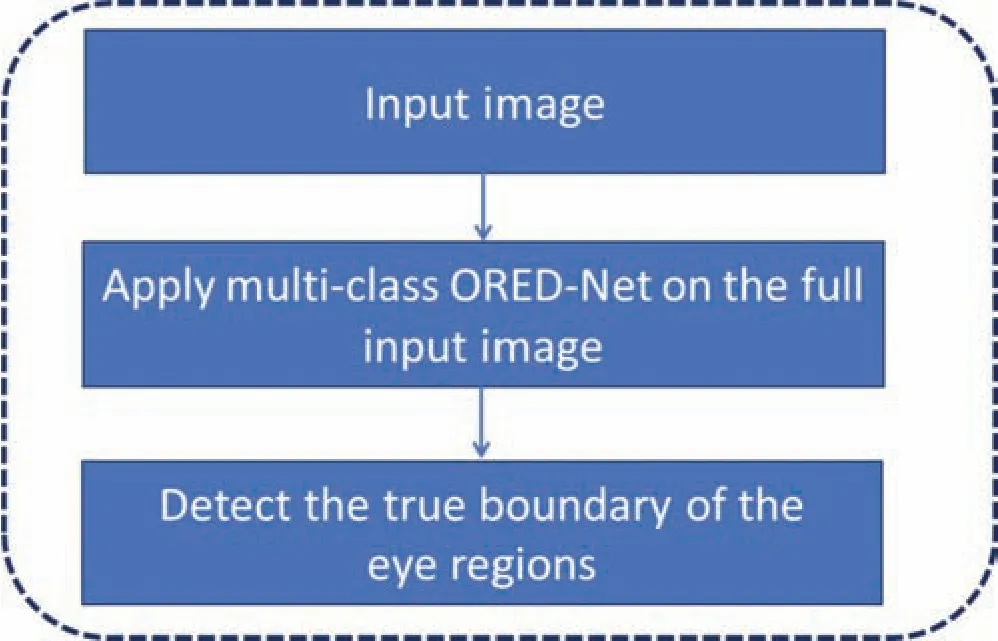
Figure 2:Flowchart of the proposed method for eye regions segmentation
3.2 Segmentation of Multiple Eye Regions Using ORED-Net
The image in typical encoder-decoder networks is downsampled and represented by very small features,which basically degrades the high-frequency contextual information.This results in the vanishing gradient problem for the classification of image pixels as the image is broken down into 7×7 sized patches[17].The vanishing gradient problem was addressed by introducing identity and non-identity mapping residual blocks.When a residual block is introduced in a CNN,the accuracy achieved is higher than that of simple CNNs such as VGGNet[18].Typically,residual building blocks(RBBs)are based on identity and non-identity mapping.In identity mapping,the features are directly provided for element-wise addition to perform the residual operation.In contrast,in the case of non-identity mapping,a 1 × 1 convolution is performed in each RBB before the features are subject to the element-wise addition.Identity mapping is not considered in the proposed network.Instead,non-identity mapping is performed by a 1 × 1 convolution layer through outer residual paths from the encoder to the decoder,as shown in Fig.3.

Figure 3:Residual building block(RBB)used in the proposed method
The proposed ORED-Net is executed via different developmental stages to perform the multi-class segmentation task with good accuracy,as compared with the basic encoder-decoder networks.In the first stage,a well-known network for segmentation i.e.,SegNet-Basic is employed[8].SegNet-Basic consists of 13 convolutional layers in both the encoder and decoder parts.This network is reduced to its simplest possible form by removing 5 convolutional layers from both the encoder and decoder parts of the network.Hence,the proposed network has only 8 convolutional layers in the encoder and decoder parts.In addition,each group in the encoder and decoder architectures consists of two convolutional layers,resulting in a lightweight encoder and decoder convolutional network.ORED-Net ensures the empowerment of the high-frequency features.In the next preparation stage of the proposed OREDNetwork,non-identity residual connections are introduced from the layers on the encoder side to the corresponding layers on the decoder side through the outer residual paths,as schematically shown in Fig.4.Hence,the residual connectivity introduced in ORED-Net is different from that of the original ResNet[19]and previously proposed residual-based networks such as Sclera-Net[4].Tab.2 highlights the main differences between the proposed network and previously reported networks such as ResNet[19]and Sclera-Net[4].

Table 2:Key architectural differences between ORED-Net and other residual based methods
The overall structure of ORED-Net is shown in Fig.4.Here,four non-identity outer residual paths(Outer-Residual-Path-1,ORED-P-1 to Outer-Residual-Path-4,ORED-P-4)from the encoder to the decoder are illustrated.The group containing a convolutional layer of size 3 × 3 and batch normalization layers is represented as Conv + BN,the activation layer,i.e.,rectified linear unit is represented as ReLU,the combination of a convolution layer of size 1 × 1 and batch normalization layers is represented as 1 × 1 Conv + BN,the max pooling layer is represented as Max-pool,and the reverse of the max pooling layer,i.e.,the max unpooling layer,is represented as Max-unpool.There are four convolutional groups in the encoder,with each group consisting of two convolutional layers before each Max-pool,i.e.,E-Conv-X and E-Conv-Y.Similarly,in the decoder,there are four convolutional groups,with each decoder group also consisting of two convolutional layers after each Max-unpool layer,i.e.,D-Conv-X and D-Conv-Y.Therefore,the 1st convolutional layer of the i-th encoder of the convolutional group is represented as E-Conv-Xi,and the 2nd convolutional layer of the i-th encoder of the convolutional group is represented as E-Conv-Yi.Similarly,the 1st convolutional layer of the j-th decoder of the convolutional group is represented as D-Conv-Xj,and the 2nd convolutional layer of the j-th decoder of the convolutional group is represented as D-Conv-Yj.Here,the values of i and j are in the range of 1–4.The 1st encoder-decoder convolutional groups located at the extreme left and right sides of the network are connected through ORED-Path-1.Similarly,the 2nd convolutional groups located 2nd from the left and right sides of the convolutional group are connected through ORED-Path-2,as shown in Fig.4.
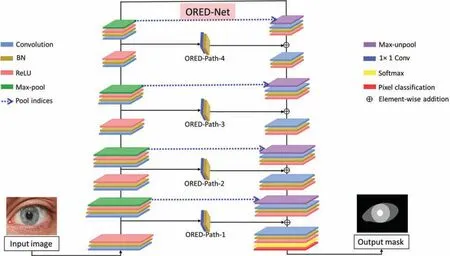
Figure 4:Deep learning-based eye region segmentation system with light-residual encoder and decoder network
Based on Fig.4,it can be observed that at the decoder part,the 2nd convolutional layer in the 1st convolutional group receives the element-to-element addition of the residual featuresand,wherein these features are from the 1st convolutional layer in the encoder convolutional-group-1(E-Conv-X1)after the ReLU and the 1st convolution layer in the 1st decoder convolutional group-1(D-Conv-X1)after the ReLU,respectively,via ORED-Path-1.This can be described by the following equation:

Here,A1is the residual feature with element-to-element addition input to D-Conv-Y1 through OREDPath-1.Typically,the outer residual block shown in Fig.3 can be represented by the following equation:

whereAiis the sum of the features presented to D-Conv-Yj by the outer residual connection,represents the residual features from the 1st convolutional layer of the i-th convolutional group(E-Conv-Xi)after the ReLU at the encoder part,andrepresents the residual features obtained from the 1st convolutional layer of the j-th convolutional group(D-Conv-Xj)after the ReLU on the decoder side.Furthermore,the values of i and j are between 1 and 4.Thus,to enhance the ability of the network for robust segmentation,each of the four outer residual paths(ORED-P-1 to ORED-P-4)provides the residual featuresfrom each of the convolutional groups from the encoder side to the decoder side.This direct path of the spatial edge information from the encoder side empowers the residual features of the decoder side,i.e.,thefeatures.
3.2.1 ORED-Net Encoder
It can be seen from Fig.4 that the encoder consists of 4 convolutional groups,with each group containing two convolutional layers along with the batch normalization and ReLU activation layers.The core and exclusive characteristic of the ORED-Net encoder is that the spatial information is input to the subsequent decoder group by the residual paths.These outer residual paths originate after each ReLU layer on the encoder side.Due to the outer residual connections,better results can be achieved with a lighter network compared with other networks used for a similar purpose.In ORED-Net,the important features are downsampled through the Max-pool layers,which also provide pooling indices to the decoder side.The pooling indices contain the index information and feature map size,which are required on the decoder side.
The encoder structure of ORED-Net is presented in Tab.3.It can be observed that there are 4 outer residual encoder-decoder paths that connect the encoder with the decoder through the non-identity residual connection shown in Fig.4.These outer residual encoder-decoder non-identity residual connections achieve feature empowerment through the spatial information of the preceding layers.The outer residual encoder-decoder connections originate after the ReLU activation layer on the encoder side and end next to the ReLU activation layer on the decoder side.The proposed network uses pre-activation because summation is performed after each ReLU layer on the decoder side.In every convolutional group on the encoder and decoder sides,an equal number of convolutional layers are present i.e.,two convolutional layers,which makes ORED-Net a balanced network.

Table 3:The ORED-Net encoder based on outer residual encoder decoder paths
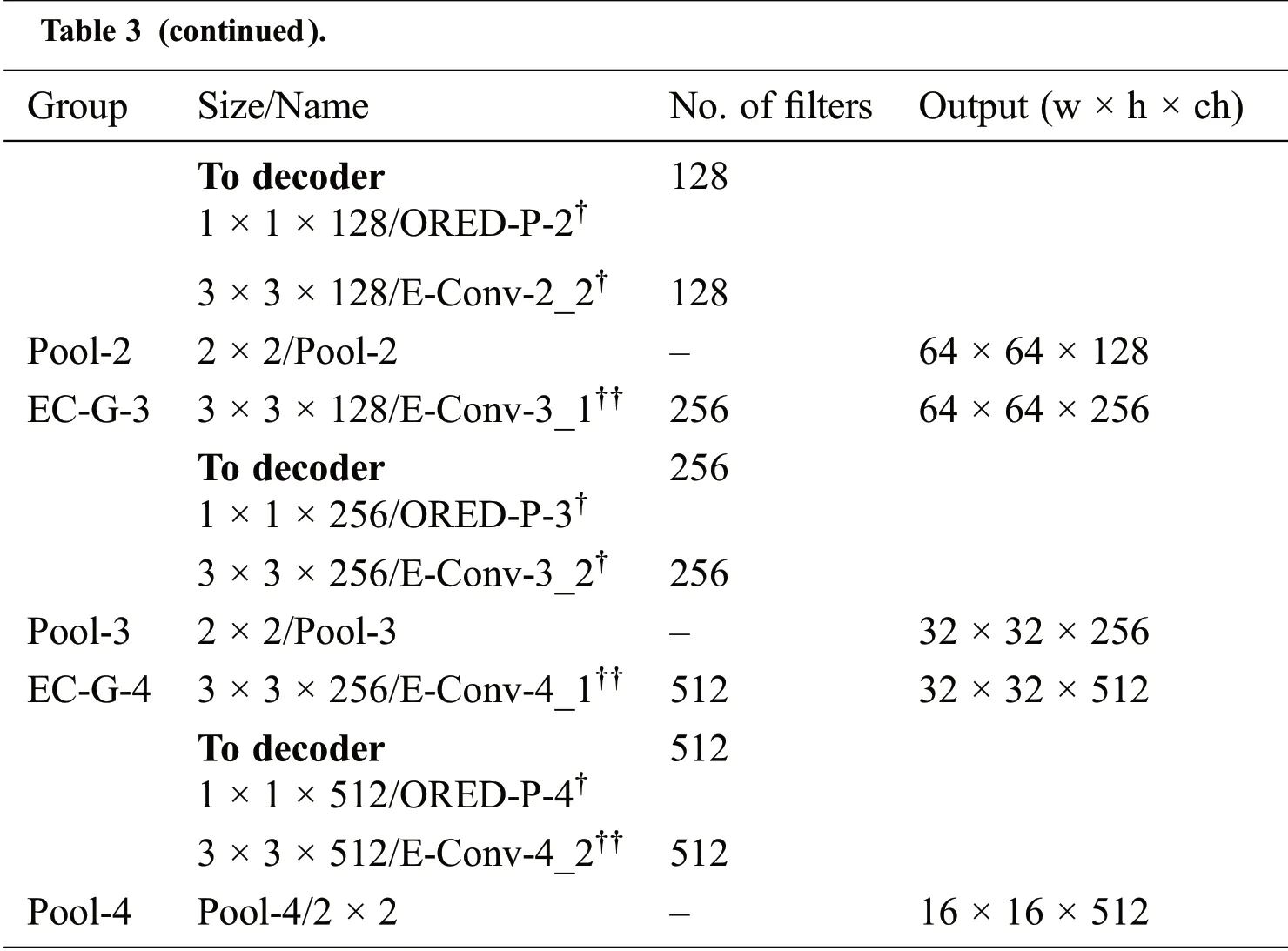
Table 3(continued).GroupSize/NameNo.of filters Output(w ×h ×ch)To decoder 1 ×1 ×128/ORED-P-2†128 3 ×3 ×128/E-Conv-2_2†128 Pool-22 ×2/Pool-2–64×64× 128 EC-G-3 3 ×3 ×128/E-Conv-3_1†† 25664×64× 256 To decoder 1 ×1 ×256/ORED-P-3†256 3 ×3 ×256/E-Conv-3_2†256 Pool-32 ×2/Pool-3–32×32× 256 EC-G-4 3 ×3 ×256/E-Conv-4_1†† 51232×32× 512 To decoder 1 ×1 ×512/ORED-P-4†512 3 ×3 ×512/E-Conv-4_2†† 512 Pool-4Pool-4/2 ×2–16×16× 512
Tab.3 presents the ORED-Net encoder with outer residual paths based on an image with size 224×224× 3.Here,E-Conv,ORED-P,and Pool represents the encoder convolution layers,outer residual encoderdecoder paths,and pooling layers,respectively.The convolutional layers in the encoder,represented by the symbol “††”,include both the ReLU activation and batch normalization(BN)layers,while the convolution layers represented by “†” include only the BN layer.The outer residual encoder-decoder skip paths,denoted by ORED-P-1 to ORED-P-4,start from the encoder and carry edge information to the decoder.As the proposed model includes pre-activation,the ReLU activation layer is used prior to the element-wise addition.
3.2.2 ORED-Net Decoder
The architecture of the ORED-Net decoder shown in Fig.4 is such that it mirrors the encoder and performs a similar convolutional operation as that performed by the encoder.The pooling layers of the encoder provide the size information and indices to the decoder,which are used to maintain the size of the feature map.In addition,the decoder features are upsampled to ensure that the size of the network output is the same as that of the input image.Furthermore,the outer residual paths input the features to the ORED-Net decoder.All the 4 outer residual encoder-decoder paths,i.e.,ORED-P-1 to ORED-P-4,originate from the encoder side and end on the decoder side.Element-to-element addition between the ORED-P and previous convolution is performed in the addition layers(Add-4 to Add-1),resulting in features that are useful to the convolutional layers in the next group,as shown in Fig.4.In this work,as four classes namely the iris,sclera,pupil,and background,are evaluated for segmentation task,the decoder produces four masks corresponding to these classes,i.e.,the number of filters for the last convolutional layer in the decoder.The pixel classification and Softmax layers facilitate the pixel-wise prediction of the network.To implement post activation in the decoder,the outer residual path is terminated immediately after each ReLU activation layer.For each class,the output of ORED-Net is a mask,which outputs “0” for the BG class,“100” for the sclera class,“180” for the iris class,“250” for the pupil class.
4 Results and Discussion
In this work,two-fold cross-validation was performed for training and testing the proposed model.To this end,two subsets were created from the available images by randomly dividing the collected database.From the images of 55 participants,two subsets were created,where the data from 28 participants were used for training and that from 27 participants were used for testing.To avoid overfitting issues,data augmentation of the training data was performed.To train and test ORED-Net,a desktop computer with an Intel®Core™(Santa Clara,CA,USA)i7-8700 CPU @3.20 GHz,16 GB memory,and an NVIDIA GeForce RTX 2060 Super(2176 CUDA cores and 8 GB GDDR6 memory)graphics card were employed.The above-mentioned experiments were conducted using MATLAB R2019b.
4.1 Training of ORED-Net
ORED-Net is based on outer residual paths from the encoder to the decoder for transferring spatial information from the encoder side to the decoder side.Therefore,high frequency information travels through the convolutional network that empowers training of this information without a preprocessing overhead.To train ORED-Net,original images without any enhancement or preprocessing were employed,and a classical stochastic gradient descent(SGD)method was used as an optimizer.SGD minimizes the difference between the actual and predicted outputs.During network training,the proposed model executed the entire dataset 25 times,i.e.,25 epochs,and a mini-batch size of 5 was selected for the ORED-Net design owing to its low memory requirement.The mini-batch size was determined by the size of the database.Once training was performed with the entire dataset,one epoch was counted,as shown in Eqs.(3)and(4).

The ORED-Net model converges very quickly because of the outer residual connections from the encoder to the decoder.Therefore,the ORED-Net model was only trained for 25 epochs.The mini-batch size was kept to 5 images during 25 epochs of training with shuffling after each epoch.Here,the training loss was calculated based on the image pixels in the mini-batch using the cross-entropy loss reported[8].The loss calculation was based on the cross-entropy loss over all the pixels accessible in the candidate mini-batch based on the iris,sclera,pupil,or background classes.Moreover,the network convergence and accuracy were affected due to a higher difference between the number of pixels in different classes and bias of the network towards learning the dominant class,as described in Arsalan et al.[20].During class training,the imbalance among the classes can be removed by assigning an inverse frequency weighting approach,as defined in Eqs.(5)and(6).


Here,Pixels(i)is the total number of pixels belonging to class ð in the training data.In this study,ð =4 represents the four classes namely the iris,sclera,pupil,and background.
4.2 Testing of ORED-Net
4.2.1 Evaluation Metrics
To validate and compare ORED-Net with previous models,the average segmentation error(Erravg),mean Intersection over Union(mIoU),Precision(P),Recall(R),and F1-score(F)were adopted as evaluation protocols.

Here,Trepresents the total number of images with aMNspatial resolution.G(i,j)and O(i,j)are the pixels of the mask or ground truth and the predicted labels,respectively.
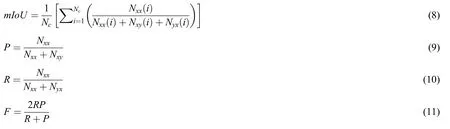
HereNcrepresents the total number of classes,andNxxis defined as the true positive where the number of pixels predicted asxalso belong to classx.Similarly,the other terms are defined as the true negativesNyy,false positivesNxy,and false negativesNyx.
4.2.2 Eye Regions Segmentation Results Obtained with ORED-Net
In Figs.5 and 6,the correct and incorrect results of multi-class eye region segmentation of eye images obtained with ORED-Net for the SBVPI dataset are illustrated.These pictorial representations follow the convention ofFP(shown in black for each class),FN(shown in yellow for each class),andTP(shown in green,blue,and red for the iris,sclera,and pupil classes respectively).
4.2.3 Comparison of ORED-Net with Other Methods
The segmentation performance of ORED-Net was compared with previous methods in terms of theErravg,mIoU,P,R,and F described in Section 4.4.1.Tab.4 presents a comparison of the segmentation performance of existing methods with that achieved by ORED-Net for the SBVPI dataset.The results demonstrate the superior performance of ORED-Net for eye region segmentation compared with the current methods,based on the values ofErravg,mIoU,P,R,and F.Comparisons are presented for the iris,sclera,pupil,and background regions with the current state-of-the-art methods in Tab.4.Additionally,the results of mIoU,P,R,and F in Tab.4 are presented through bar graphs in Fig.7.
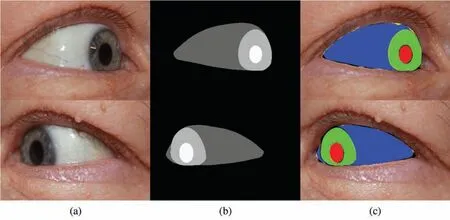
Figure 5:Examples of good eye region segmentation by ORED-Net for the SBVPI dataset:(a)Original image,(b)Ground-truth mask,and(c)Predicted mask result obtained with ORED-Net
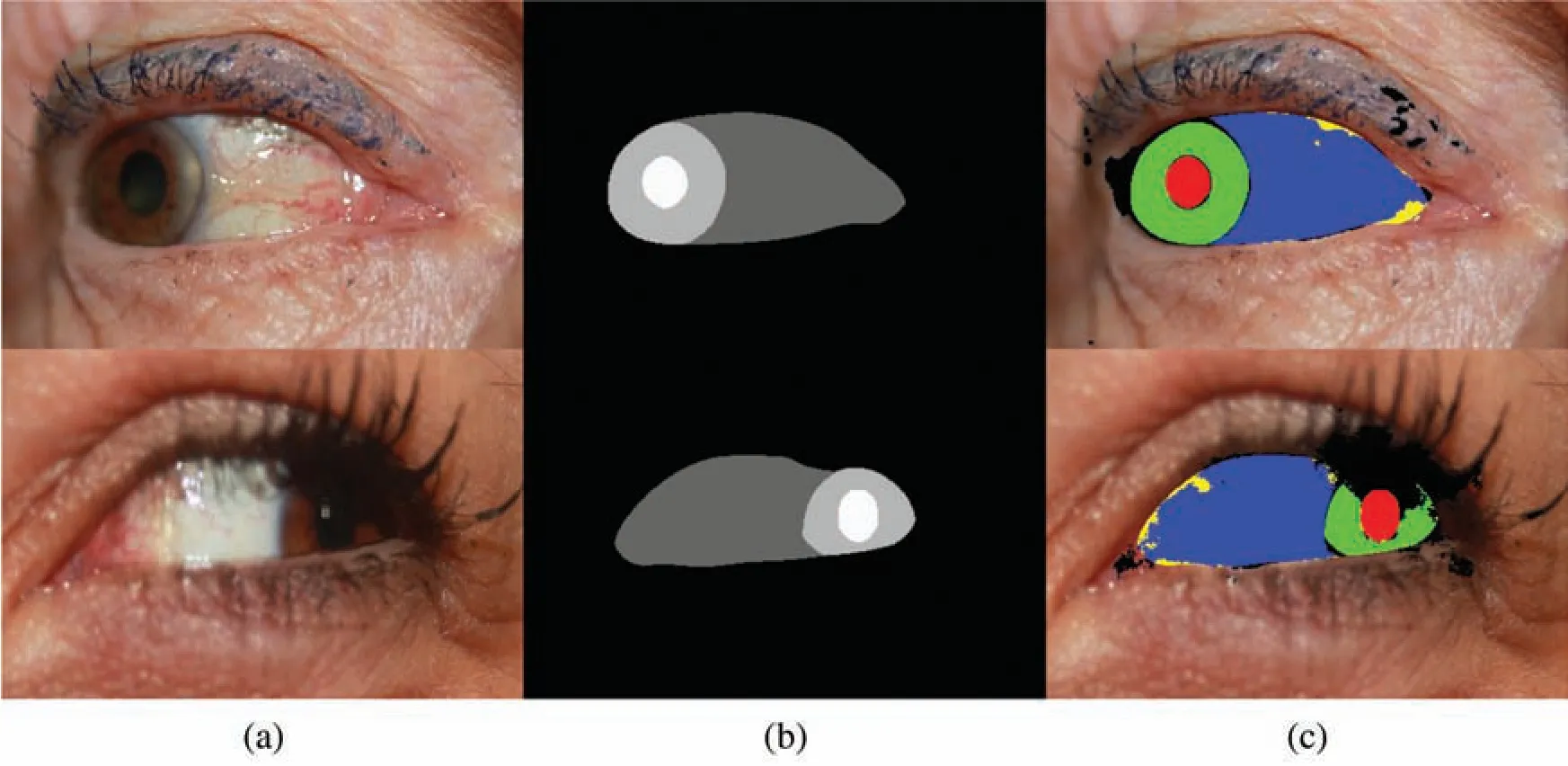
Figure 6:Examples of bad eye region segmentation by ORED-Net for the SBVPI dataset:(a)Original image,(b)Ground-truth mask,and(c)Predicted mask result obtained with ORED-Net
4.2.4 Eye Region Segmentation with Other Open Datasets Using ORED-Net
To evaluate the segmentation performance of ORED-Net under different image acquisition conditions,experiments with another publicly available datasets for eye region segmentation,i.e.,UBIRIS.v2 dataset,were included in this study[10].In previous studies,masks for the iris and sclera were provided for only 300 images[21].The ground truth images of the iris and sclera were merged and the ground truths for the pupil were designed to evaluate the proposed ORED-Net model on the iris,sclera and pupil using the UBIRIS.v2 dataset.Of the 300 images considered in the UBIRIS.v2 dataset,50% of the images(150)were used for training,while the remaining 50%(150)were used for testing with two-fold cross-validation.To train ORED-Net with the UBIRIS.v2 dataset,similar data augmentation as that used for the SBVPI dataset was employed.

Table 4:Comparison of the proposed method with existing methods for the SBVPI dataset(unit:%)
In Figs.8 and 9,the correct and incorrect results of multi-class eye region segmentation of eye images obtained with ORED-Net for the UBIRIS.v2 dataset are illustrated.This pictorial representation follows the convention ofFP(shown in black for each class),FN(shown in yellow for each class),andTP(shown in green,blue,and red for the iris,sclera,and pupil classes,respectively).As ORED-Net is powered by outer residual paths,there are no significant errors in the segmentation of multiple eye region from a challenging dataset like UBIRIS.v2.
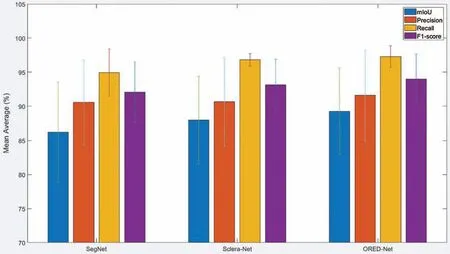
Figure 7:Mean and standard deviation of the proposed method and existing alternatives in terms of mean intersection over union,precision,recall and F1-score based on SBVPI database
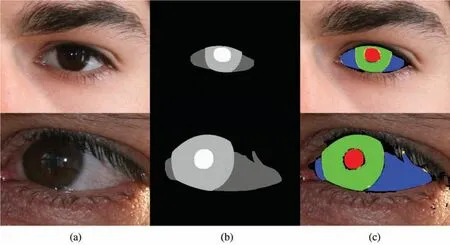
Figure 8:Examples of good eye region segmentation by ORED-Net for the UBIRIS.v2 dataset:(a)Original image,(b)Ground-truth mask,and(c)Predicted mask result obtained with ORED-Net
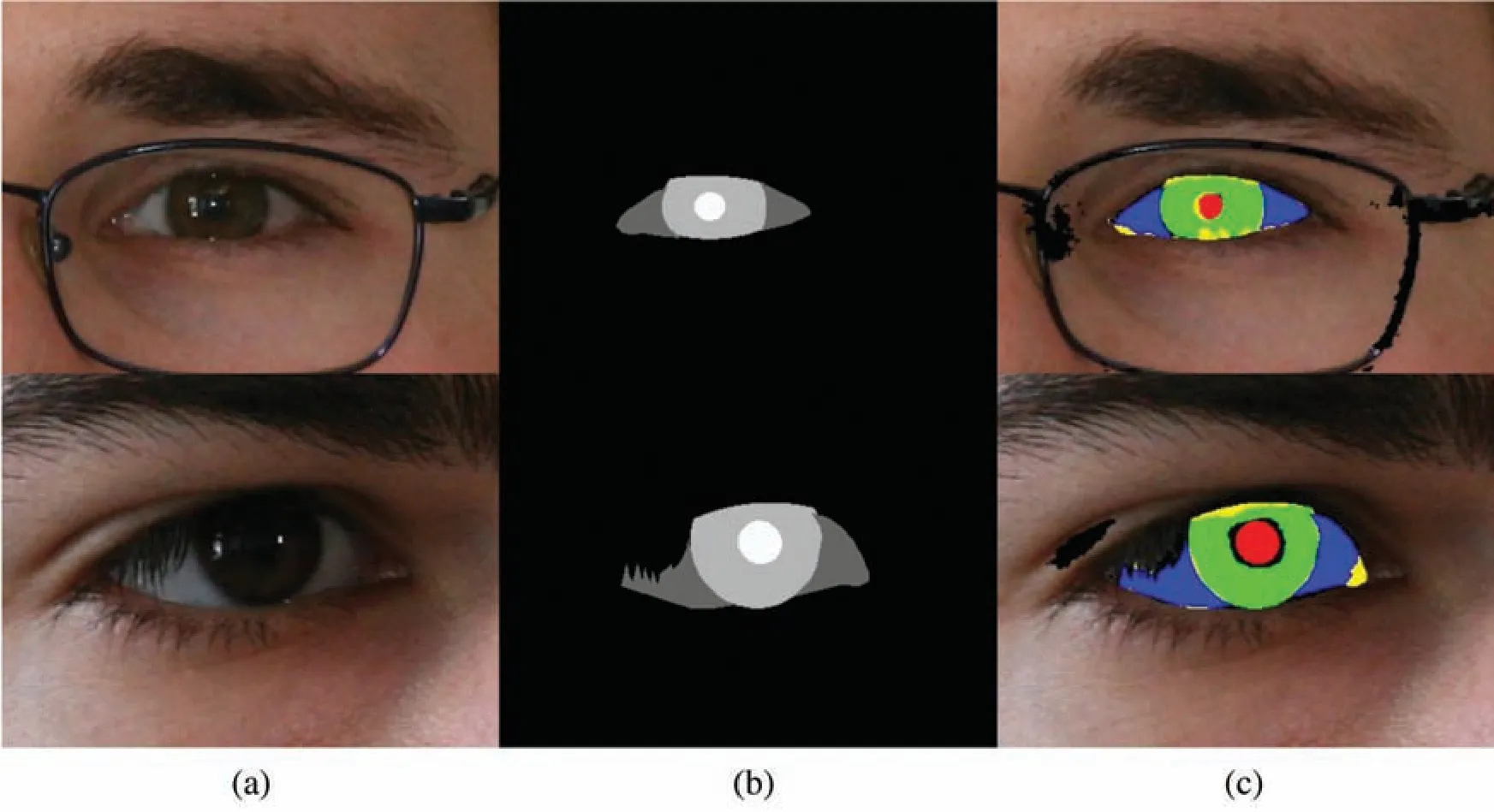
Figure 9:Examples of bad eye region segmentation by ORED-Net for the UBIRIS.v2 dataset:(a)Original image,(b)Ground-truth mask,and(c)Predicted mask result obtained with ORED-Net
Tab.5 presents a comparison of the segmentation performance of existing methods with that of OREDNet for the UBIRIS.v2 dataset.Additionally,the results of mIoU,P,R,and F in Tab.5 are presented through bar graphs in Fig.10.
Based on the results presented in Tabs.4 and 5(Figs.7 and 10),it can be concluded that the performance of the proposed ORED-Net framework is consistent with that of state-of-the-art algorithms.A noteworthy point is that ORED-Net is a novel method that performs multi-class semantic segmentation of different eye regions such as iris,sclera,and pupil simultaneously,unlike all other existing algorithms that only address one or two eye region at a time.In addition,the performance of the ORED-Net model was evaluated on different publicly available datasets for comparisons with other methods,as shown in Tabs.4 and 5(Figs.7 and 10).

Table 5:Comparison of the proposed ORED-Net method with existing methods for the UBIRIS.v2 dataset(unit:%)
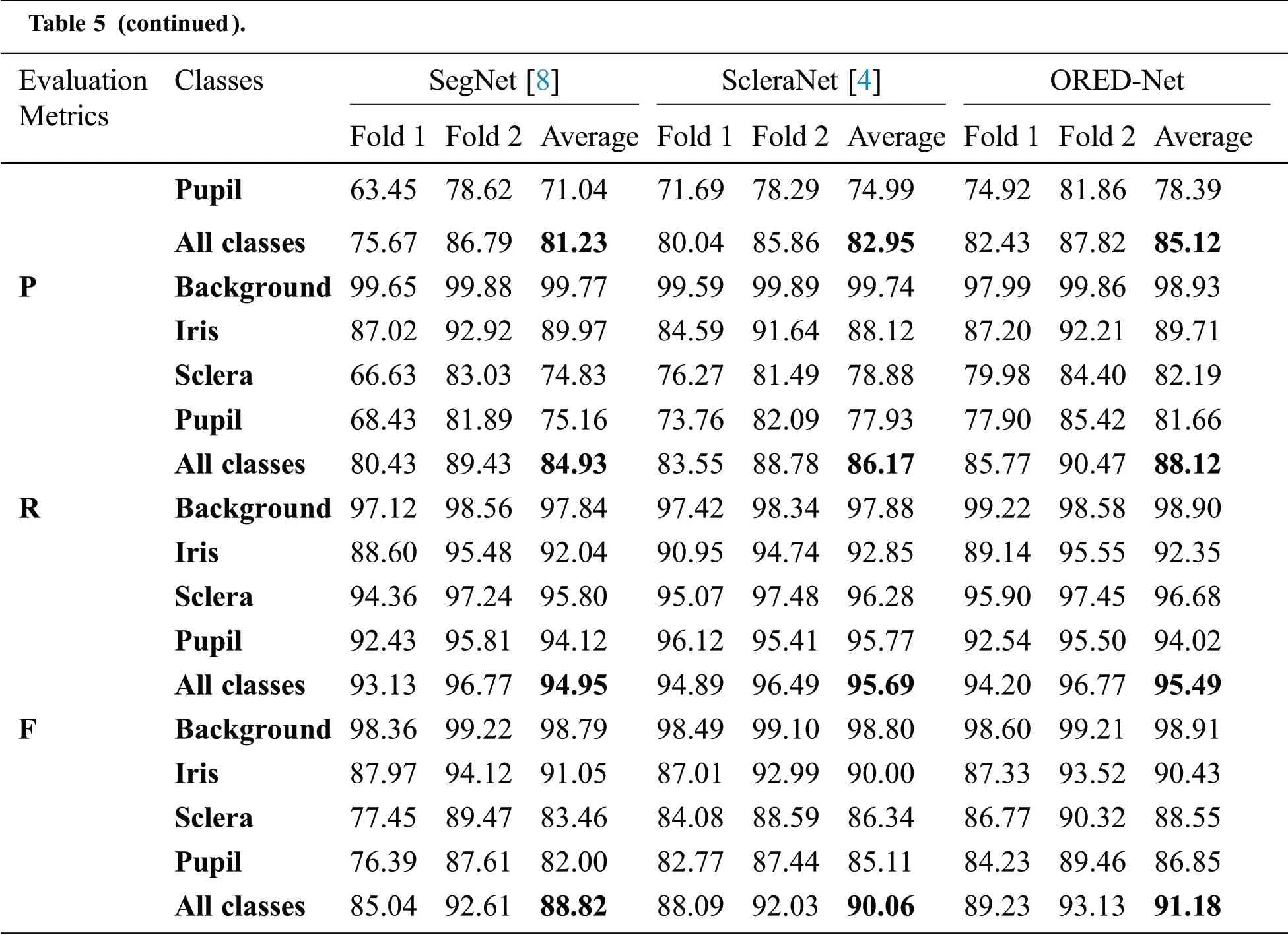
Table 5(continued).Evaluation Metrics ClassesSegNet[8]ScleraNet[4]ORED-Net Fold 1 Fold 2 Average Fold 1 Fold 2 Average Fold 1 Fold 2 Average Pupil63.45 78.62 71.0471.69 78.29 74.9974.92 81.86 78.39 All classes 75.67 86.79 81.2380.04 85.86 82.9582.43 87.82 85.12 P Background 99.65 99.88 99.7799.59 99.89 99.7497.99 99.86 98.93 Iris87.02 92.92 89.9784.59 91.64 88.1287.20 92.21 89.71 Sclera66.63 83.03 74.8376.27 81.49 78.8879.98 84.40 82.19 Pupil68.43 81.89 75.1673.76 82.09 77.9377.90 85.42 81.66 All classes 80.43 89.43 84.9383.55 88.78 86.1785.77 90.47 88.12 R Background 97.12 98.56 97.8497.42 98.34 97.8899.22 98.58 98.90 Iris88.60 95.48 92.0490.95 94.74 92.8589.14 95.55 92.35 Sclera94.36 97.24 95.8095.07 97.48 96.2895.90 97.45 96.68 Pupil92.43 95.81 94.1296.12 95.41 95.7792.54 95.50 94.02 All classes 93.13 96.77 94.9594.89 96.49 95.6994.20 96.77 95.49 F Background 98.36 99.22 98.7998.49 99.10 98.8098.60 99.21 98.91 Iris87.97 94.12 91.0587.01 92.99 90.0087.33 93.52 90.43 Sclera77.45 89.47 83.4684.08 88.59 86.3486.77 90.32 88.55 Pupil76.39 87.61 82.0082.77 87.44 85.1184.23 89.46 86.85 All classes 85.04 92.61 88.8288.09 92.03 90.0689.23 93.13 91.18
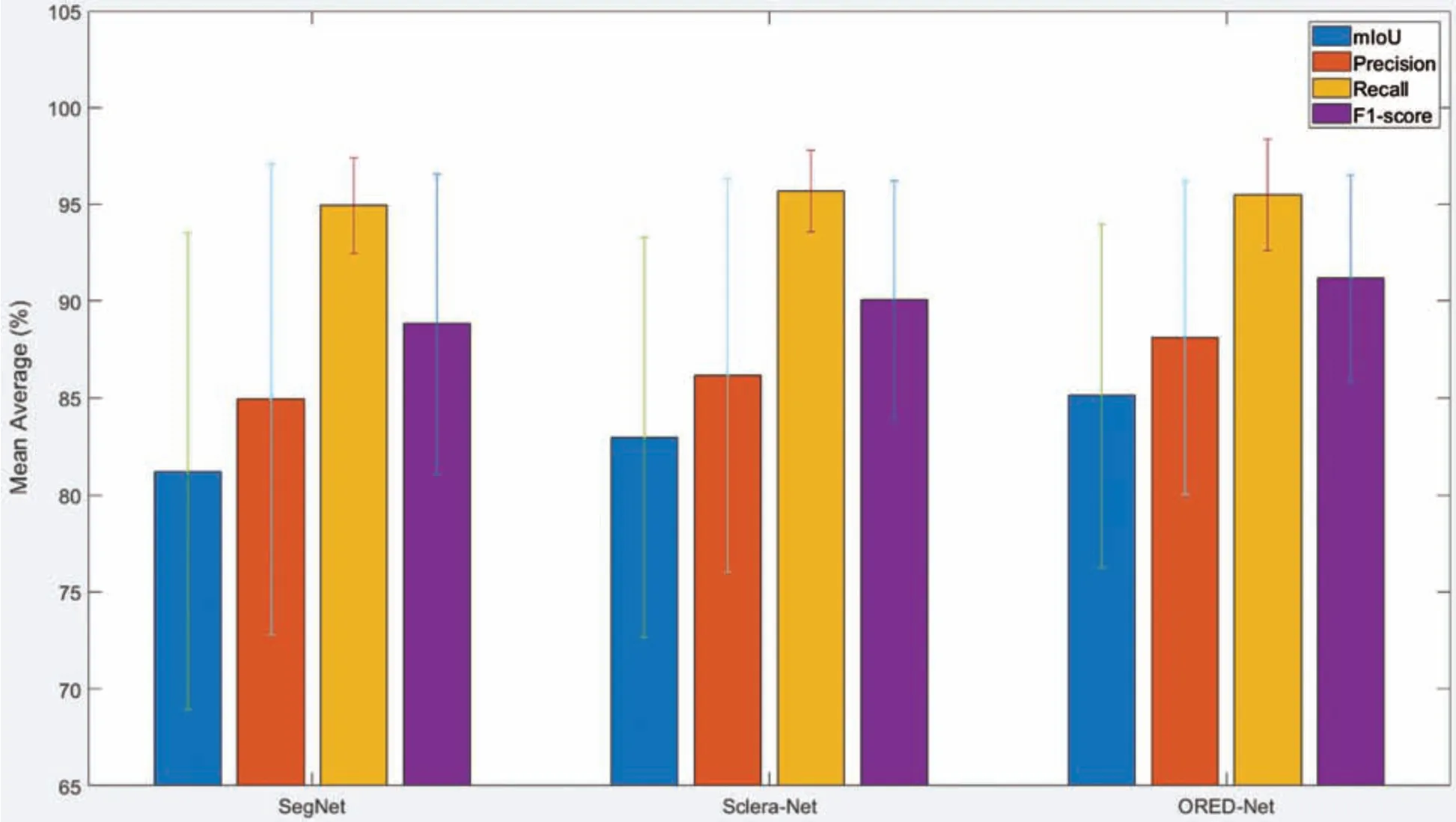
Figure 10:Mean and standard deviation of the proposed method and existing alternatives in terms of mean intersection over union,precision,recall and F1-score based on UBIRIS.v2 database
5 Conclusions
In this paper,a novel multi-class semantic segmentation network called ORED-Net was proposed for the segmentation of eye regions such as the iris,sclera,pupil,and background.ORED-Net is based on the concept of outer residual connections for transferring spatial edge information directly from the initial layers of the encoder to the decoder layers.This framework enhances the performance of the network in the case of bad quality images.ORED-Net has fewer layers,which reduces the number parameters along with the computation time.The most notable aspects of the proposed ORED-Network are that it achieves a high accuracy with a lighter network and converges in considerably fewer number of epochs with direct flow of edge information,resulting in faster training.In ORED-Net,the original image is used for both training and testing,as no extra overhead is required in the form of preprocessing.ORED-Net is the first network of its kind that simultaneously segments three important eye regions,namely iris,sclera,and pupil,without any preprocessing overhead.The robustness and effectiveness of the proposed method were tested on various publicly available databases for eye region segmentation,including the SBVPI and UBIRIS.v2 datasets.In future studies,this work will be extended to a robust multimodal biometric identification system based on multiple eye regions.
Funding Statement:This work was supported by the National Research Foundation of Korea(NRF,www.nrf.re.kr)grant funded by the Korean government(MSIT,www.msit.go.kr)(No.2018R1A2B6009188)(received by W.K.Loh).
Conflicts of Interest:The authors declare that they have no conflicts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- Design of Authoring Tool for Static and Dynamic Projection Mapping
- Detecting Lumbar Implant and Diagnosing Scoliosis from Vietnamese X-Ray Imaging Using the Pre-Trained API Models and Transfer Learning
- Design of a Compact Monopole Antenna for UWB Applications
- A Smart Wellness Service Platform and Its Practical Implementation
- Fingerprint-Based Millimeter-Wave Beam Selection for Interference Mitigation in Beamspace Multi-User MIMO Communications
- Multilayer Self-Defense System to Protect Enterprise Cloud