ACLSTM:A Novel Method for CQA Answer Quality Prediction Based on Question-Answer Joint Learning
2021-12-14WeifengMaJiaoLouCaotingJiandLaibinMa
Weifeng Ma,Jiao Lou,Caoting Ji and Laibin Ma
School of Information and Electronic Engineering,Zhejiang University of Science and Technology,Hangzhou,310023,China
Abstract:Given the limitations of the community question answering(CQA)answer quality prediction method in measuring the semantic information of the answer text,this paper proposes an answer quality prediction model based on the question-answer joint learning(ACLSTM).The attention mechanism is used to obtain the dependency relationship between the Question-and-Answer(Q&A)pairs.Convolutional Neural Network(CNN)and Long Short-term Memory Network(LSTM)are used to extract semantic features of Q&A pairs and calculate their matching degree.Besides,answer semantic representation is combined with other effective extended features as the input representation of the fully connected layer.Compared with other quality prediction models,the ACLSTM model can effectively improve the prediction effect of answer quality.In particular,the mediumquality answer prediction,and its prediction effect is improved after adding effective extended features.Experiments prove that after the ACLSTM model learning,the Q&A pairs can better measure the semantic match between each other,fully re ecting the model’s superior performance in the semantic information processing of the answer text.
Keywords:Answer quality;semantic matching;attention mechanism;community question answering
1 Introduction
People used to rely on traditional search engines to acquire knowledge.With the explosive growth of information nowadays,it is clear that the traditional search engines have many shortcomings,such as:With excessive numbers of search results,it is difficult to quickly locate the required information;it relies solely on keyword matching technology and does not involve semantics,resulting in poor retrieval,etc.Consequently,a new mode of information sharing—community question answering(CQA)emerged.In particular,the emergence of vertical domain CQA such as Stack Over ow,Brainly,and Auto Home not only satisfies the specific information needs of users,but also promotes the dissemination of high-quality information.The CQA launched by Auto Home is a professional automobile communication platform.Users have put forward a substantial number of real and effective questions and answers with increased user activities.However,the content edited by responders varies greatly,and the quality of the answers is uneven.Auto Home has introduced an automatic Q&A service,but it fails to analyze customized issues and address user needs,so the user experience is undermined.Besides,CQA answer quality analysis indicates that about more than 30% of the answers were worthless[1].Therefore,the basis for CQA success is how to detect high-quality answers from the content edited by the responder.In response to these problems,this paper proposes an answer quality prediction model based on question-answer joint learning with the use of attention mechanism and question text,together with the semantic representation of Q&A pairs in joint learning to filter out high-quality answers that fit the question.
2 Related Work
Mining the effective factors that affect the quality of answers is one of the keys to predict high-quality answers.Fu et al.[2]found that reviews and user features among non-textual features are the most effective indicators for evaluating high-quality answers,while the validity of textual features varies across different knowledge domains.Shah et al.[3]found that the responder’s personal information and reciprocal ranking of answers to a given question could significantly predict high-quality answers.Calefato et al.[4]found that answers with links to external resources are positively related to the integrity of their content,and the timeliness of the answers,the responder’s emotions,and the responder’s reputation score are all factors that in uence the acceptance of the answer.Liu et al.[5]found that the quality of the question is also an important factor affecting the quality of the answer.Low-quality answers induce by low-quality questions.On the contrary,high-quality questions contribute to high-quality answers.The quality of the question to some extent determines the quality of the answer.Combining the quantitative and time difference characteristics of answers,Xu et al.[6]proposed to use the relative positional sequence characteristics of the answers to make quality predictions of the answers.The results show that this feature can significantly improve the effect of answer quality prediction.
The key to predict high-quality answers is not only to explore the effective factors that affect the quality of answers,but also to choose the appropriate model.Machine learning methods are widely used in classification and prediction tasks,such as Random Forest classification model[7],Latent Dirichlet Allocation(LDA)model[8],Support Vector Machines(SVM)[9–10],ensemble learning[11],etc.Because of the advantages in processing structured data,machine learning methods are also widely used in answer quality prediction.Alternate Decision Tree(ADT)classification model and multi-dimensional features extracted were used to predict the quality of answers,which has achieved good results[12–13].By using textual features,non-textual features and the combination of the two,Li et al.[14]established a binary classification model with logical regression.It is found that the discriminant performance of the model for high-quality answers is higher than that for low-quality answers.Wang et al.[15]found that the Random Forest classification model including user social attributes has better classification performance after comparing the classification performance of logistic regression,Support Vector Machine and Random Forest.Wu et al.[16]proposed a new unsupervised classification model to detect low-quality answers.Studies have shown that testing multiple answers under the same question can improve the detection of low-quality answers.Machine learning has achieved remarkable results in the prediction of answer quality.However,most of them take advantage of structural features,so they have a low utilization rate of the text and cannot capture the semantic information of the text.
With the development of deep learning,the neural network has achieved tremendous success in Computer Vision[17],Signal Processing[18–19]and Natural Language Processing.The neural network can be used to capture text semantic information,and how to better measure the semantic information of the answer has been gradually in the spotlight.Sun et al.[20]used the topic model to extract the keywords of the answer,extend it with context and synonyms,and then train the model with CNN.The results show that the model can effectively improve the accuracy of answer quality prediction.Suggu et al.[21]proposed two different DFFN(Deep Feature Fusion Network)answer quality prediction frameworks to model the Q&A pairs with CNN and Bi-directional Long Short-term Memory Network(Bi-LSTM)with neural attention respectively,and extended features through leveraging various external resources.Experiments show that this method has better performance in answer quality prediction tasks than other general deep learning models.Zhou et al.[22]combined CNN with Recurrent Neural Network(RNN)to capture both the matching semantics of the Q&A pairs and the semantic association between the answers.Considering the interdependence of sentence pairs,Yin et al.[23]studied the dependency semantic relationship between sentence pairs through the attention mechanism and CNN.The results show that this method can better measure the semantic relationship between pairs of sentences than modeling sentences separately.
3 Method
Fig.1 shows the architecture of answer quality prediction model based on question-answer joint learning.First,Q&A pairs of Auto Home CQA is used to jointly construct attention text representation and learn the dependency relationship between Q&A pairs;Second,input the attention text representation into parallel CNN to extract the local features of Q&A pairs;Third,input the Q&A pairs after CNN into parallel LSTM to extract long-distance dependent features;Next,calculate the semantic matching degree between the question representation and the answer representation,combine with deep answer semantic representation and other effective extended features as the input representation of the fully connected layer;Finally,the SoftMax classifier is used to predict the quality of the corresponding answers to a given question.
3.1 Input Layer
First,for given Q&A pair,the question text and the answer text need to be filled with 0 to equal length,that is,the length of the text iss;where question text sq={v1,v2,…,vi,…,vs},vi∈Rd;and answer text sa={w1,w2,…,wj,…,ws},wj∈Rd.Word2vec model is used to pre-train the word vector to indicate that the word is d-dimensional[24],vq,i={x1,x2,…,xk,…,xd},wherexkrepresents the value of the word vector of thei-th word of the question text sqin thek-th dimension;wa,j={y1,y2,…,yk,…,yd},whereykrepresents the value of the word vector of thej-th word of the question text sain thek-th dimension.Finally,the question text and the answer text are expressed as the word vector matrix.
3.2 Convolution Layer Based on Attention
The attention matrix A ∈Rs×sis introduced to weight the semantic similarity between the question text and the answer text.In the attention matrix A,thei-th line value represents the attention distribution of thei-th word of the question text sqrelative to the answer text sa,andj-th column value represents the distribution of attention of thej-th word of the answer text sarelative to the question text sq.The specific calculation of attention matrix A is as follows:

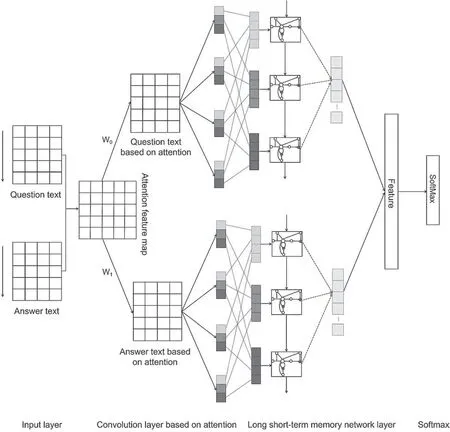
Figure 1:The architecture of model
Given the above attention matrix,the attention feature maps with consistent dimensions for the original question text sqand answer text saneed to be generated:

where W0∈Rs×d,W1∈Rs×dare weight matrices,which need to learn and update in model training.
Input question text attention representation Sq,tand the answer text attention representation Sa,tinto parallel CNN,respectively,the local features of attention representation are captured through CNN,and new feature representations are obtained as Sq,cand Sa,c.The specific calculation method of convolution operation for attention representation of question text is as follows,answer text is the same:

wherewrepresents sliding window size;represents subsequence composed of convolution kernel ofw×ddimension size at the position ofiin Sq,t=(z1,z2,…,zi,…,zs);represents the convolution parameter matrix,whered1represents the final dimension size after convolution output;represents the bias;frepresents the non-linear activation function.Here,ReLu is used as the activation function;andrepresents the convoluted final feature representation sequence at the positioni.
3.3 Long Short-Term Memory Network Layer
CNN has limitations in dealing with time series-related tasks.The RNN can compensate for this deficiency.Compared with the traditional RNN,LSTM as a variant of RNN,can use its unique gating units to learn the long-distance dependence of text sequence.Therefore,this paper inputs feature representation of Sq,cand Sa,cinto parallel LSTM through the convolution layer to extract context semantic features,as well as to obtain long-distance dependence features Sq,land Sa,lof question and answer texts with the reference of Hochreiter’s LSTM structure[25].The specific calculation formula for the long-distance dependency features of the question text is as follows,answer text is the same:

wherextrepresents input information of time sequencet(0 <tsw+1);ht1represents the output information of last time sequence;it,ft,otandgtrepresent the input gate,forget gate,output gate and candidate memory information of the time sequencet;ctandhtrepresent the memory state and hidden state of time sequencet;W represents the weight matrix to be learned;b represents the bias;and σ represents the non-linear activation function Sigmoid.
3.4 Output Layer
In this paper,the above fusion feature representation is input into the SoftMax classifier for answer quality prediction.For givenwhere quality category labely(i)∈ 1,…,K{}(Kis the number of quality category labels).After entering the SoftMax classifier,the prediction probability distribution of answer quality category corresponding to characteristic F is obtained,as shown in formula(13):

where Wsrepresents weight parameter matrix;bsrepresents the bias.
In model training,use cross-entropy as the loss function to measure the model loss,and use regularization to prevent overfitting,as shown in formula(14).The ultimate goal of model training is to minimize the cross-entropy.

whereirepresents the number of samples;jrepresents the answer quality category;yijrepresents the correct quality category of the answer text;represents the predicted quality category;is the L2 regularization;θ is the model parameter.
4 Feature Construction and Selection
By obtaining relevant data from the Auto Home CQA,this paper constructs a feature system for extended features,and evaluates the feature system with multiple indicators,and selects effective features as the extended features of answer quality prediction.
4.1 Feature Construction
(1)Structural Features
Structural features are features after direct statistics,including question length(que_length),answer length(ans_length),number of question words(que_words_num),number of answer words(ans_words_num),number of question characters(que_ch_num),number of answer characters(que_ch_num),answer time interval(time_interval),whether the answer is adopted(is_adopt),whether the question contains a picture(has_picture)and whether the answer includes external links(has_link).
(2)User Attribute
User attributes can re ect the activity and authority of users,including the number of answers(ans_num),number of adopted answers(adopt_num),and number of helpful answers(help_num).
(3)Textual Features
Textual features refer to the features that are contained in the text but cannot be counted directly.This paper calculates the cosine similarity between the average word vector representation of the question text and the average word vector representation of the answer text as an indicator of the semantic match between the question text and the answer text(similarity).
4.2 Feature Selection
In order to make the model have better performance,data is usually processed by the following strategies:feature selection[26],dictionary learning,compressed sensing[27–28],etc.Considering the characters of data,this paper uses feature selection method to obtain high-quality features.Various features are different in unit and dimension and cannot be compared directly.It is therefore necessary to first have dimensionless processing of features,so the features of different attributes are comparable.This paper evaluates the above features with Pearson correlation coefficient(Corr.),L1 regularization(Lasso),L2 regularization(Ridge),maximal information coefficient(MIC),random forest mean decrease impurity(MDI)and recursive feature elimination(RFE),and normalizes the final score.Tab.1 shows the detailed evaluation of various features.
It requires conducting feature screening to obtain more stable features[29].This paper uses the mean value combined with the threshold method for feature selection[30].Based on the evaluation,it can be known that the length of question/answer,number of words and characters of questions/answers can re ect the richness of the text content of questions/answers,which all belong to redundant features.Chinese sentences are composed of successive single character,a word could consist of a single character or more.Compared with character,words can better measure whether the Chinese sentences are misspelled[31].Therefore,the number of questions/answers is selected as the feature.In other features,whether the question includes pictures and whether the answers include external links has little impact on the model.Therefore,the threshold value is set at 0.12.Finally,the feature of average score above threshold is selected as the adopted feature,including the following eight:Number of question words,number of answer words,answer time interval,whether the answer is adopted,matching degree,number of answers,number of adopted answers and number of helpful answers are selected as the final extended features.
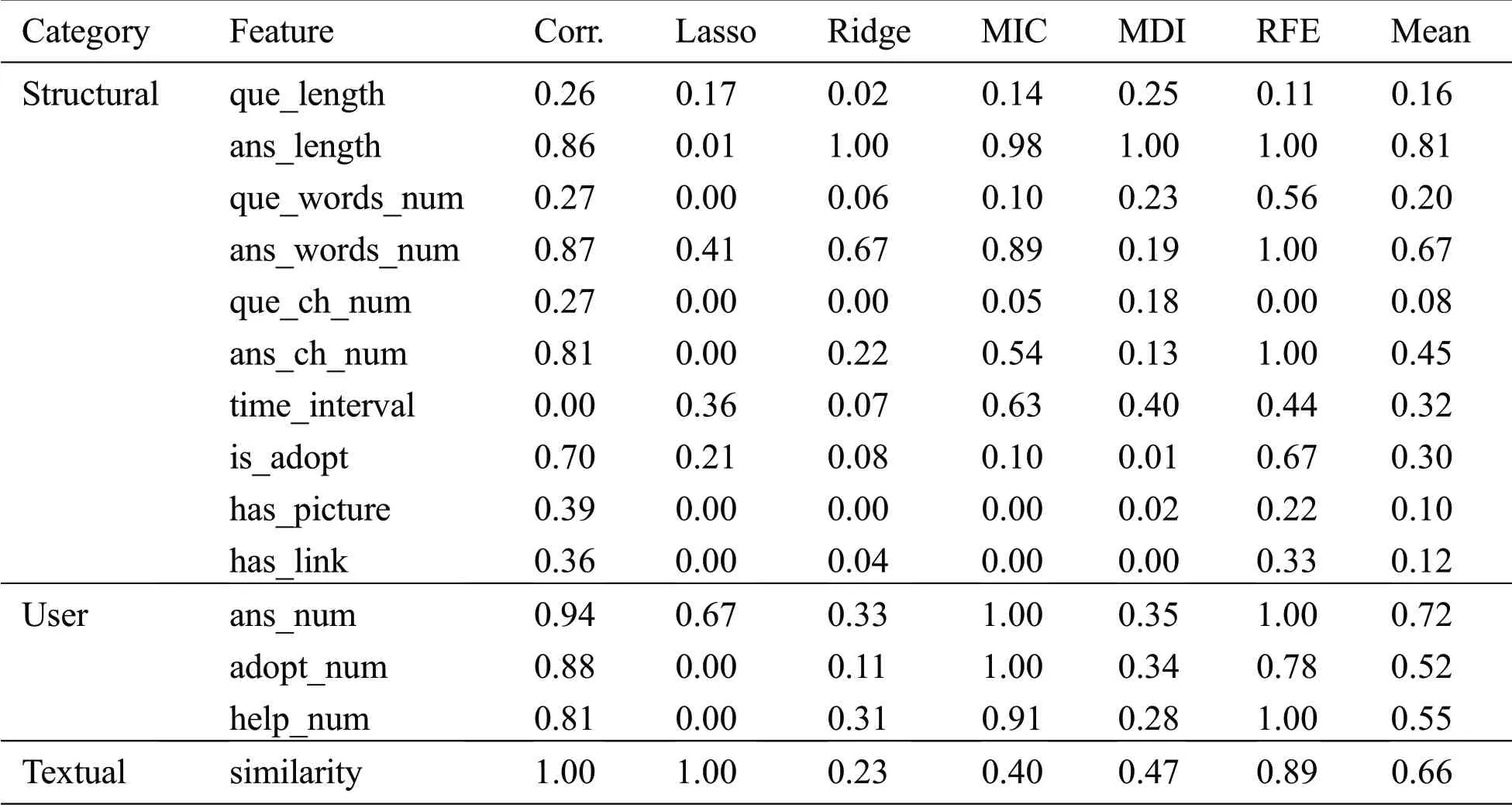
Table 1:Feature evaluation
5 Experiments
5.1 Data Set
In this paper,the dataset used is a customized benchmark dataset,and sourced from Auto Home CQA.The dataset contains a total of 7,853 questions and 48,815 Q&A pairs,with a time span from April 25,2012 to December 9,2019.The user took only 4.25%out of 48,815 answers.The reason that users did not adopt the answers is not because of their low-quality,but because the questioner did nothing to make his answer stand out,resultantly the majority of the answers were not adopted.Therefore,only taking whether the answer is adopted as an assessment criterion of the quality of the answer is unreliable.Based on the literature[15],this paper evaluates the quality of the answer from 13 dimensions and artificially labels the answer quality as low,medium,and high.
To verify the validity of the algorithm model proposed,this paper randomly takes 20% of the total sample as a test data set,and randomly selects 10% as the validation data set and the rest as training data set in the remaining 80%of the data.Tab.2 shows the specific statistics after dividing the dataset.
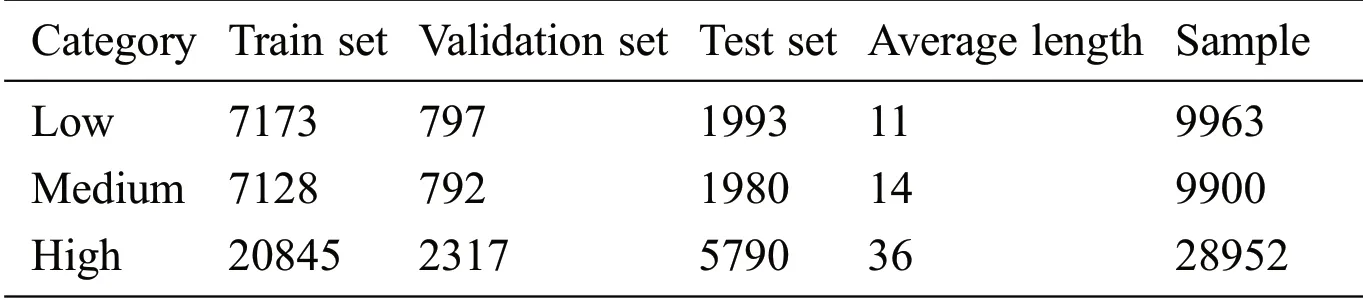
Table 2:Dataset statistics
5.2 Evaluation Indicators
This paper takes precision(P),recall(R),F1 score,macro average precision,macro average recall,macro averageF1-score as evaluation indexes of answer quality with the following calculation formula:

whereTPrepresents the number of samples actually positive and predicted positive;FPrepresents the number of samples actually negative but predicted positive;FNrepresents the number of samples actually positive but predicted negative;andirepresents the sample size of the test set.
5.3 Comparative Experiment Selection
This paper uses customized data sets to compare different models to verify the validity of the proposed models.The Skip-gram mode of Word2vec is used to obtain better word vectors.The context window is set to 5,and the word vector dimension is set to 100,and the question text and answer text of Auto Home CQA are jointly trained to finally obtain the word vector representation of question/answer text pre-training.The comparative experiments include:
1.SVM.This paper obtains the average word vector representation of the answer text from the pretraining word vector,and predicts its quality with SVM.
2.Random Forest.This paper obtains the average word vector representation of the answer text from the pre-training word vector,and predicts its quality with Random Forest.
3.CNN.With the reference of model architecture of literature[32],this paper uses CNN to learn the vector representation of the given question text and the answer text and predicts its quality.
4.ABCNN.With the reference of model architecture of literature[23],this paper uses the attention mechanism to consider the interaction between question and answer,and integrates it into the CNN to learn the vector representation of the answer text and predicts its quality.
5.LSTM.This paper uses LSTM to learn the vector representation of the given question text and the answer text and predicts the quality of the answer.
6.ACLSTM.The proposed model in this paper uses attention mechanism to respectively weight the answer/question text with the question/answer text,and inputs the weighted text representation into CNN and LSTM to learn the deep semantic representation of question/answer texts and predicts its quality.
This paper not only uses different models to learn answer text representation for quality prediction,but also take structural features,user attribute features and textual features as extended features,and add them to the text representation of the answers after different model training step by step,so as to compare the in uence of different extended features on the quality prediction of the answers.
5.4 Results and Analysis
The important issue for this research is whether the models proposed in this paper performs better in semantic match and achieves answer quality prediction.In the next sub-sections,we will discuss the advantages of the model and the task specific set up.
5.4.1 Evaluation and Comparison
Tab.3 shows the evaluation values of different models compared with the models proposed in this paper.From the evaluation values of Tab.3,it can be known that the machine learning model SVM and Random Forest do not have the advantage in capturing text semantics,while the mainstream deep learning model has significant advantages.Compared with the mainstream deep learning model,the model proposed in this paper has a better performance in the prediction of the answer quality in the Auto Home CQA.It verified the validity of the proposed model.Experiments show that the introduction of attention mechanism can effectively measure the semantic match between Q&A pairs and capture the deep semantic representation of text.In addition,the predictive power of the model has improved significantly after adding extended features step by step.It indicates that the extended features,as the supplementary features of the answer text,contribute greatly to the answer quality prediction task.
Fig.2 is the comparison of F1 score among different answer quality categories with SVM,Random Forest,CNN,ABCNN,LSTM and the model proposed in this paper.From the figure,it can be seen that SVM and Random Forest have no advantage in capturing the text semantics of the answers compared to the deep learning model.CNN,ABCNN,LSTM,and the model proposed in this paper have comparable predictive ability to low,high-quality answers,and generally low prediction ability for medium-quality answers.However,compared with other models,the model presented in this paper shows better predictive ability in predicting medium-quality answers,which is significantly better than other models.It shows that attention mechanism can learn the semantic information between Q&A,by integrating the question text with the semantic information covered by the answer text,the model can better distinguish between medium-quality answers whose features are not significant but are consistent with the text of the question.
5.4.2 The Choice of Different Sources of Q&A Pairs
To better measure the semantic matching between Q&A pairs and the validity of the model,this paper uses three different sources of Q&A pairs of vector representation to calculate cosine similarity of the two,as a supplementary extended feature:
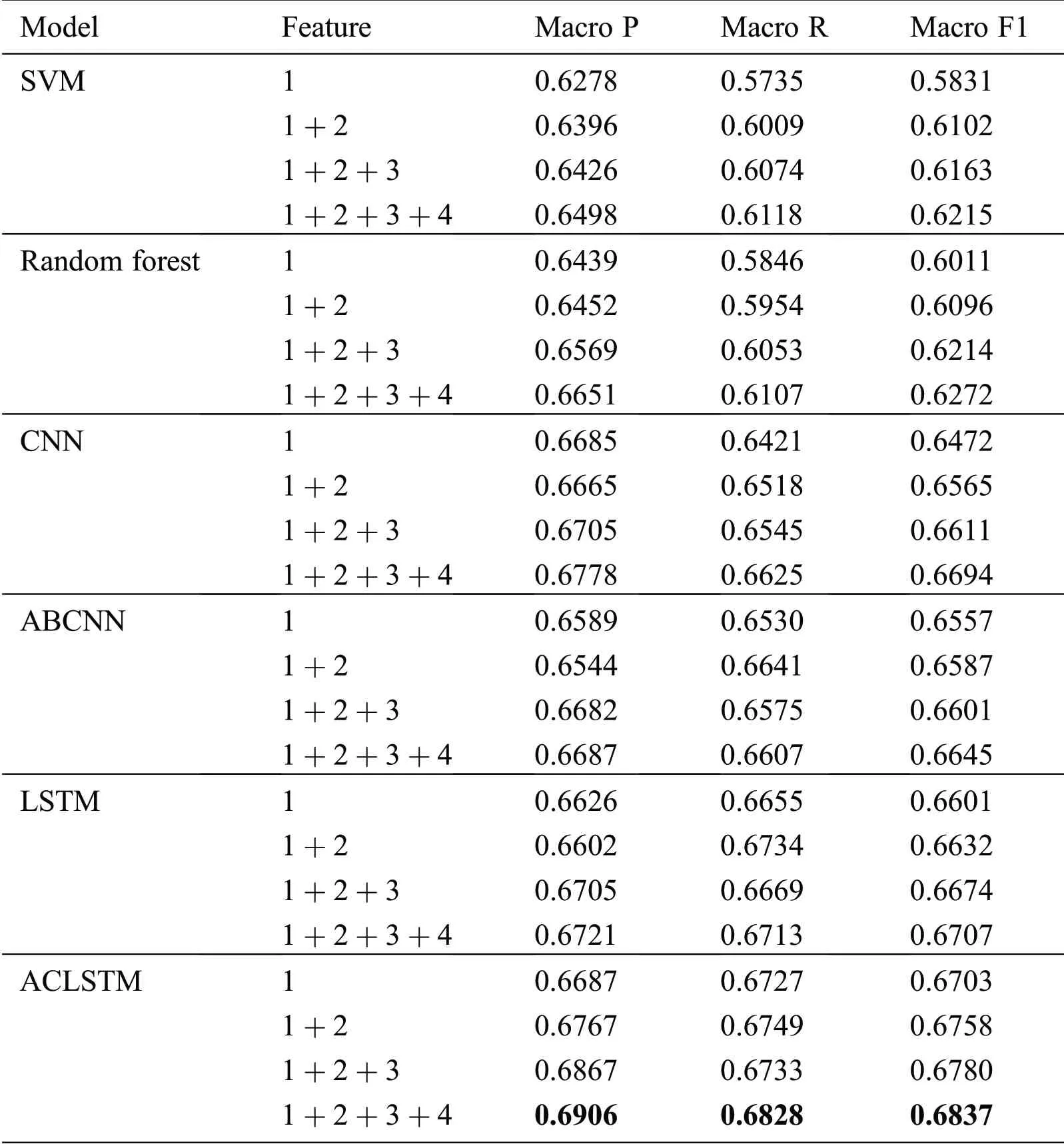
Table 3:Evaluation value of comparative experiment
1.Sim1.Same as Section 4.1 textual features,by using the average word vector of Q&A pairs,calculate the cosine similarity of the two.
2.Sim2.In the representation layer of the model,the cosine similarity is calculated by using the maxpooling word vector representation of Q&A pairs.
3.Sim3.Calculate the cosine similarity by using the vector representation of Q&A pairs after model learning.
Tab.4 shows the comparative experimental results of CNN,ABCNN,LSTM and the model proposed in this paper with different similarity degrees based on the existing extended features.The results show that the model with Sim3 has the best performance,and followed by Sim1,and Sim2 is relatively poor.It indicates that vector representation of Q&A pairs without model learning covers less semantic information,while vector representation of Q&A pairs with model learning has deeper semantic information.Particularly,the model proposed in this paper is optimal.It can combine the semantic information covered by the question text with the answer text to better measure the match between the Q&A pair.In addition,the matching of Q&A pairs measured by average word vectors is better than the max-pooling.
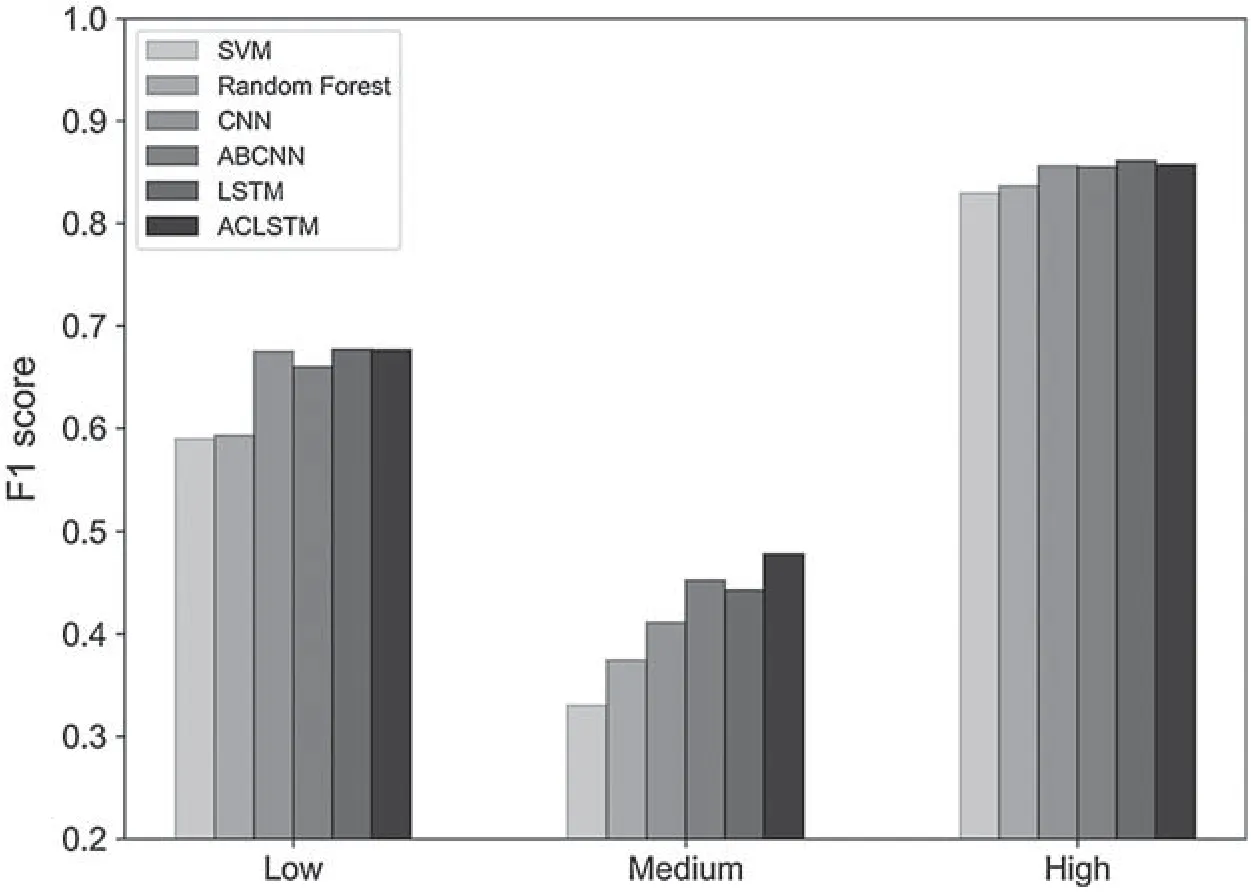
Figure 2:Comparison of F1 score among different answer quality categories
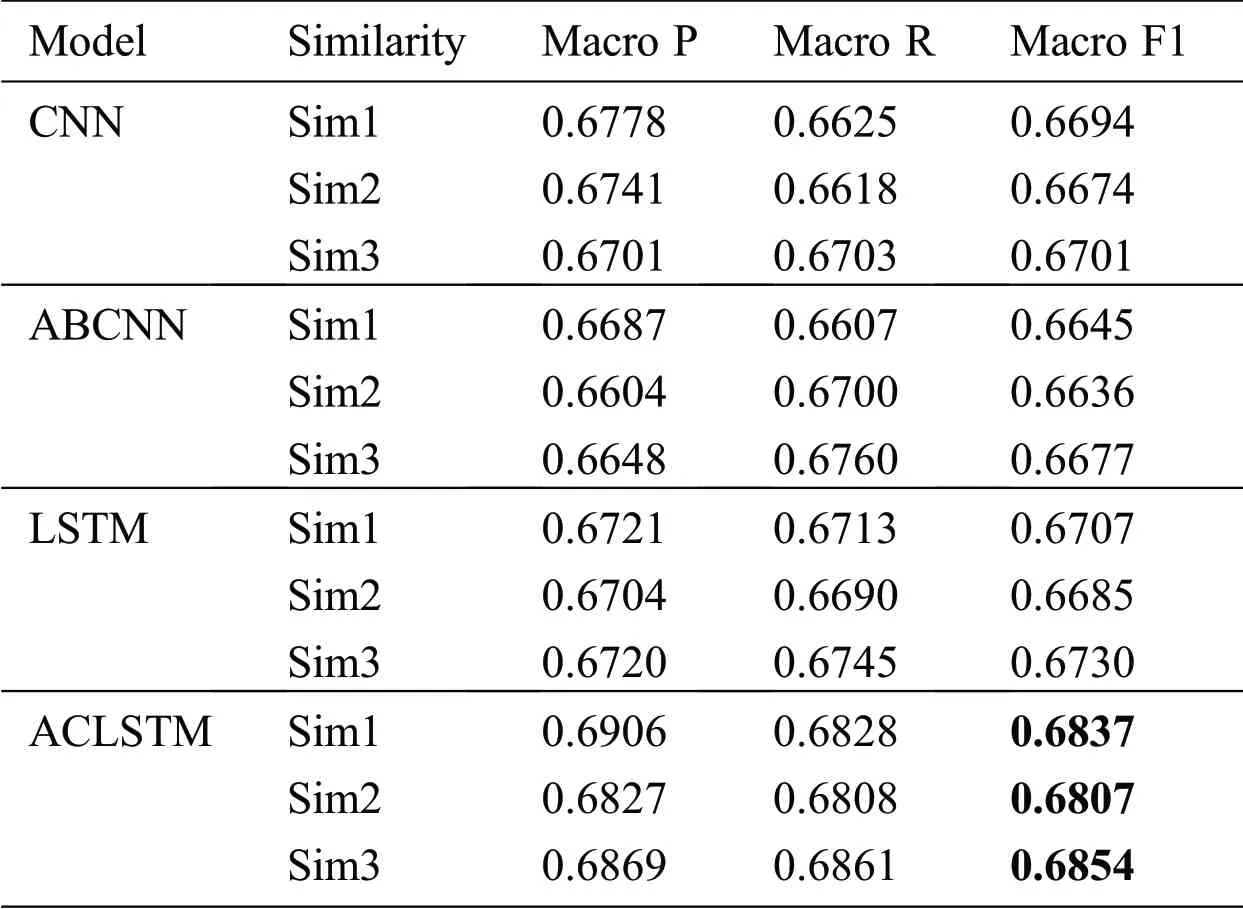
Table 4:Experimental results of different similarity
5.4.3 The Effect of Different Length of Answer Text
This paper also discusses the effect of different lengths of answer text on the model to reduce computational complexity.The histogram in Fig.3 shows the text length distribution of the answer text after word segmenting for all samples.Based on Fig.3,it can be seen that answers with text length less than 300 account for about 99.25% of the total sample.Therefore,answers with text lengths of 10,50,100,200 and 300 are selected for comparative experiments.Since Samples with answer text lengths less than 1000 account for about 99.98%of the total sample,comparison experiment with a text length of 1000 was also added.When the answer text length is less than the fixed length,it is filled with zero.On the contrary,the answer text is truncated when its length is greater than the fixed length.Fig.4 shows the effect of different lengths of answer text on the model.As can be seen from Fig.4,when the text length of the answer is 10 to 300,the evaluation values gradually rise;when the answer text length is greater than 300,the evaluation values tend to level off.Therefore,the text fixed length is set to be 300.
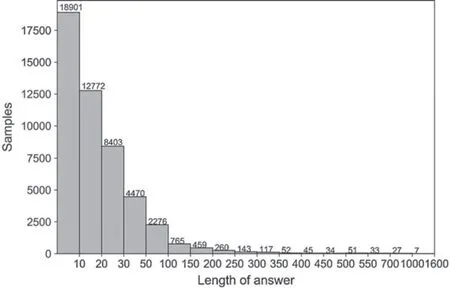
Figure 3:Answer text histogram of different length
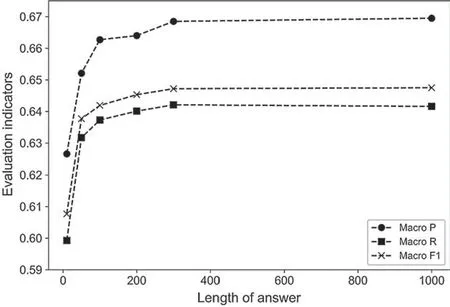
Figure 4:The effect of different lengths of answer text on the model
5.4.4 Visualization
Fig.5 is a visual display of the attention matrix of a test sample.Tab.5 is the text representation for the attention-based Q&A.Based on Fig.5 and Tab.5,the model can well capture the part related to the semantic meaning of “peculiar smell,” such as “charcoal package,” “grapefruit peel,” “open the window” and“ventilation.” It further clearly shows that the answer quality prediction model proposed in this paper can better learn the dependence between the Q&A pair and better measure the semantic match between them.
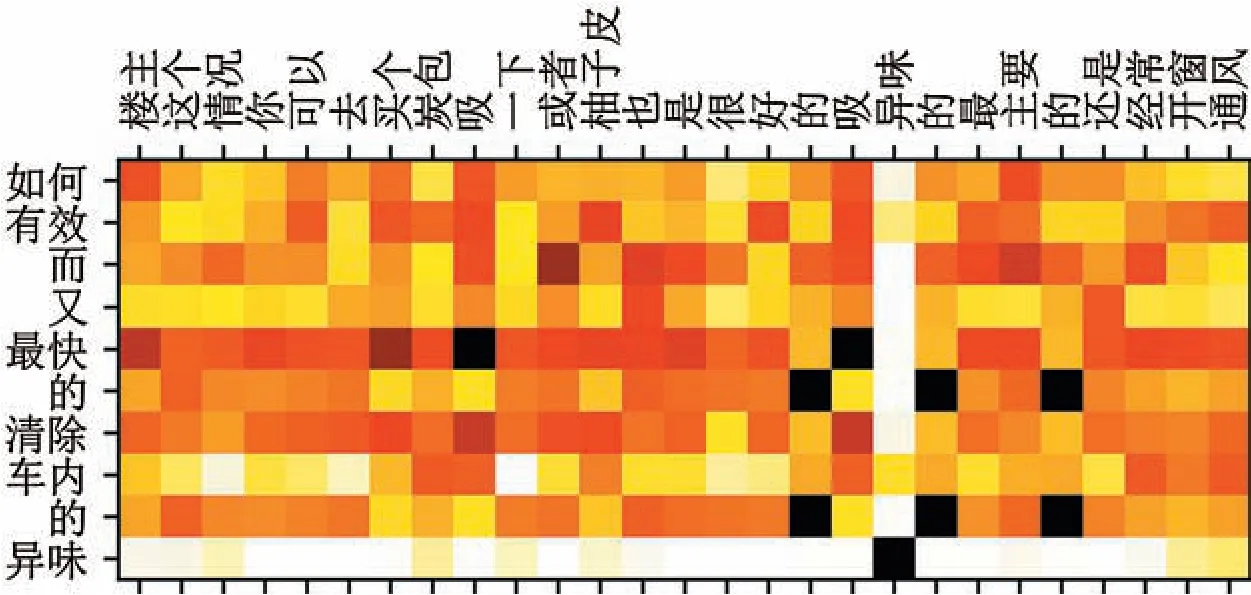
Figure 5:Attention matrix visualization

Table 5:Attention-based text representation visualization
6 Conclusions
Aiming at the existing problems such as the quality of the answers is uneven,the automatic question answering service is unable to specifically analyzed questions and address individualized user needs,user experience is undermined,etc.,this paper takes the Auto Home CQA as the research object,proposes an answer quality prediction model based on question-answer joint learning to filter out high-quality answers that fit the question from the content edited by the respondent.This paper uses CNN based on attention mechanism to learn semantic information of Q&A pairs and extract the local joint features of Q&A pairs,and uses LSTM to extract long-term dependence features of Q&A pairs.The vector representation of obtained Q&A pairs has deep semantic information and can better measure the match between the Q&A pairs.The prediction performance of the model can be further improved by constructing multiple valid extended features.
However,there are still limitations in this paper:the extended feature constructed based on Auto Home CQA is not universal.In the future study,we will further consider the introduction of multiple generic extended features,such as relative position order of the answers,emotional polarity of question /answer texts,etc.Moreover,the prediction ability of the model for medium-quality answers still needs to be further improved.
Acknowledgement:The authors are thankful to their colleagues,especially Z.Chen,Y.L.Zhang and Y.F.Cen who provided expertise that greatly during the research.
Funding Statement:This research was supported by the Zhejiang Provincial Natural Science Foundation of China under Grant No.LGF18F020011.
Conflicts of Interest:The authors declare that they have no con icts of interest to report regarding the present study.
杂志排行

Computers Materials&Continua的其它文章
- Design of Authoring Tool for Static and Dynamic Projection Mapping
- Detecting Lumbar Implant and Diagnosing Scoliosis from Vietnamese X-Ray Imaging Using the Pre-Trained API Models and Transfer Learning
- Design of a Compact Monopole Antenna for UWB Applications
- A Smart Wellness Service Platform and Its Practical Implementation
- Fingerprint-Based Millimeter-Wave Beam Selection for Interference Mitigation in Beamspace Multi-User MIMO Communications
- Multilayer Self-Defense System to Protect Enterprise Cloud