可解释深度知识追踪模型
2021-12-14刘坤佳李欣奕唐九阳
刘坤佳 李欣奕 唐九阳 赵 翔
(国防科技大学信息系统工程重点实验室 长沙 410073)
随着智能辅导系统(intelligent tutoring system)和大规模在线开放课程(massive open online course)等在线学习平台的发展,在线教育得到广泛关注与应用.在线教育系统通过收集用户的行为数据并记录其学习轨迹,实现更为智能的个性化资源推荐与教辅.这个过程的关键就在于知识追踪(knowledge tracing, KT),即通过用户不同时刻的习题作答情况来跟踪其认知状态,进而预测其下一时刻的答题情况,实现对用户知识掌握程度的智能评估.
知识追踪任务可以形式化表示为一个有监督的序列学习任务.如图1所示,用户在在线学习过程中,与包含不同知识点的习题交互,产生一个习题作答交互记录.知识追踪的目标是通过建模用户答题情况,评估其认知状态,从而预测其在下一个时刻的答题情况.另外,对于可解释知识追踪任务,不仅要预测用户作答表现,还要对预测结果提供解释.
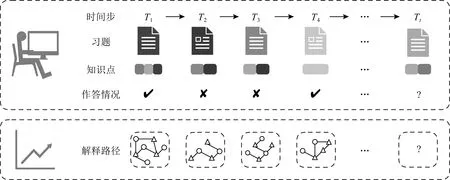
Fig.1 Illustration of interpretable knowledge tracing
当前知识追踪领域的研究主要分为基于传统机器学习方法和基于深度学习的方法2类.Corbett等人[1]首次提出知识追踪的概念,并提出用贝叶斯网络建模用户的学习过程.随后的工作分别将学习因素分析、性能因素分析、项目反应理论应用于知识追踪.Piech等人[2]首先将循环神经网络(recurrent neural network, RNN)引入知识追踪领域,开启了深度知识追踪方法的序幕.相比于传统非深度模型,深度学习方法预测能力取得明显提升.
当前深度知识追踪方法多针对习题对应的知识点建模,而忽视了题目本身蕴含的丰富信息.例如,考察同一知识点的不同题目可能由于难度设置不同而导致不同的作答结果.另外,目前的方法假设学生认知水平变化程度相同,忽视了学生认知状态与习题表示的个性化交互,因此无法建模学生知识状态变化的个体差异.再者,基于深度学习的方法预测过程和结果缺乏可解释性.在实际应用中,尤其是在线教育领域,可解释的预测结果不仅可以提升系统透明度,还能提高用户对系统的信任和对预测结果的接受程度.当前的研究对预测结果的可解释性多集中在为认知状态变化过程提供可视化展示[3-4],但是并未给出得到当前预测结果所依据的推理路径,因此不能直接为预测结果提供解释.
针对以上问题,本文提出可解释的深度知识追踪模型(interpretable deep knowledge tracing, IDKT).首先,通过引入习题的上下文信息、扩充了习题-知识点关系图,得到更有表征能力的习题与知识点表示,缓解数据稀疏问题;接着,基于用户知识状态学习注意力权重,得到习题-知识点关系图中用户对不同邻居节点的关注程度并聚合邻居节点,得到当前预测习题基于用户知识状态的个性化表示.值得注意的是,为了捕捉用户不同语义下的关注重点,我们设计了多头注意力机制稳定学习过程.然后,该个性化习题表示与用户认知状态共同用于预测用户最终的作答表现;最后,对于预测结果,我们在习题-知识点图中依据前述基于用户知识状态的注意力值选择一条推理路径作为解释.
本文的主要贡献包括4个方面:
1)利用习题与知识点的上下文信息挖掘其间隐含关系,丰富习题-知识点图关系类型,缓解数据稀疏问题;
2)基于用户认知状态学习个性化注意力权重,得到习题-知识点关系图中用户对不同邻居节点的关注程度,充分考虑用户知识状态差异,实现习题个性化表示;
3)提供一种可解释框架,通过个性化注意力机制,在习题-知识点关系图中选择推理路径,实现对知识追踪结果的可解释;
4)在多个知识追踪数据集上对提出的IDKT模型进行广泛验证,均取得最佳预测表现,有力验证了所提模型的有效性.
1 相关工作
现有知识追踪方法可以大致分为2类:基于传统机器学习的方法和基于深度学习的方法.其中基于传统机器学习的方法可以进一步分为贝叶斯模型和回归模型[5].
1.1 传统方法
基于贝叶斯的方法典型代表是贝叶斯知识追踪(bayesian knowledge tracing, BKT)[1].BKT基于隐马尔可夫模型(hidden Markov model, HMM)建模用户的认知状态变化,在每一次用户交互后,BKT根据其答题情况基于HMM更新用户掌握知识点的概率.然而,BKT忽略了知识点之间的相互联系,难以处理较复杂的知识体系,且在实际应用中难以模拟较长的交互序列.
回归模型则从历史数据中学习特定参数从而对答题情况进行预测.项目反应理论(item response theory, IRT)模型[6]从交互数据中训练用户能力和习题难度2个参数.多维项目反应理论(multi-item response theory)[7]对用户能力的考察从单一维度扩展到多维度.广义分部评分模型(generalized partial credit model)[8]进一步细化对习题回答情况的评价,引入分部计分方式.表现因子分析(performance factors analysis)[9]考虑用户对知识点的正面和负面回应情况.知识追踪机(knowledge tracing machine)[10]利用矩阵分解将习题和用户的边信息编码到参数模型中.
回归模型得到的结果有着天然的可解释性,但是难以自动拓展到不同的数据中.另外,由于模型本身的表示能力有限,因此预测性能不佳.
1.2 深度方法
基于深度学习的方法由于具有强大的表征能力,因而在知识追踪任务取得了很好的预测结果,逐步受到广泛的重视.其中,深度知识追踪(deep knowledge tracing, DKT)和动态键值记忆网络(dynamic key-value memory network, DKVMN)在预测用户未来答题情况中都表现出了强大的预测能力,成为后续基于深度学习方法的比较基准.
DKT以RNN为基础结构,用户的学习交互记录通过one-hot编码或压缩感知转换为输入向量.RNN的隐层状态即为用户对知识点掌握情况的表征,通常被称为知识状态(knowledge state).与DKT将用户知识状态表示为一个向量不同,DKVMN维持一个静态外部矩阵存储所有知识点的表示,然后动态更新用户对知识点的掌握程度.
此后,一些工作通过建模知识点之间的相互关系、引入习题和知识点的辅助信息、挖掘用户的交互特点等方式进一步提高模型预测能力.引入习题的知识追踪方法(exercise-aware knowledge tracing)[11]利用注意力机制聚合用户历史认知状态,图交互知识追踪(graph-based interaction knowledge tracing, GIKT)[12-14]利用图神经网络学习知识点间的潜在关系,并以此更新用户知识状态.有辅助信息的深度知识追踪(deep knowledge tracing with side information)模型[13]通过挖掘习题之间的相关关系(side relations),整合习题之间关系的特征信息,得到更加丰富的特征.有约束的先决关系驱动下的深度知识追踪(prerequisite-driven deep knowledge tracing with constraint modeling)模型[14]将知识点之间的先决关系作为模型约束扩充特征信息.Zhang等人[15]将用户的反应时间、尝试次数等辅助信息引入DKT模型.此外还有工作通过整合交互序列中特定的用户行为信息并分别建模其遗忘行为[16]实现个性化.个性化评估知识追踪(individual estimation knowledge tracing, IEKT)[17]在RNN序列中引入评估用户个性化认知状态和知识获取敏感度的模块,根据答题序列将用户分入不同类别,实现了一定程度的个性化知识追踪.
1.3 可解释的深度方法
由于深度学习采用端到端的学习过程,模型训练过程和最终结果往往不具有可解释性.在DKT中得到的隐知识状态是一个高度抽象的向量,不具有可解释性.DKVMN通过学习当前输入习题与各个知识点之间的相关关系,自动选择与当前输入习题相关的知识概念,因而可以一定程度上为用户在各个知识点上的状态变化提供解释.但是DKVMN并不直接对知识点建模知识状态,而是通过定义一个低维隐向量间接更新其知识表示,虽然可以将知识状态变化过程进行可视化展现,但是不能提供推理路径层面的可解释性.
为实现可解释的知识追踪,习题辅助的RNN模型(exercise-enhanced RNN)[18]利用余弦相似度计算习题之间的相似性,以此作为知识状态的权重,提高预测能力的同时也为结果提供可解释性.基于深度信息反应理论(deep item response theory)的模型[19]将DKT与IRT结合,保留了深度学习的预测能力,同时参照IRT理论,从习题难度和用户个人能力2方面为预测结果提供解释.上下文感知的注意力知识追踪(context-aware attentive knowledge tracing, AKT)模型[20]通过引入上下文信息并结合IRT模型,增强嵌入的表征能力,通过注意力机制为结果提供解释.图知识追踪(graph knowledge tracing, GKT)模型[4]在预测过程中同步学习知识点之间的隐关系,每次仅更新与当前习题相关的知识状态,实现了知识点级别的可解释性.注意力深度知识追踪(attention deep knowledge tracing)[21]通过计算知识点之间的注意力权重为结果提供可解释性.
这些方法或通过记录知识状态变化过程,或通过与逻辑回归模型结合提供可解释性,但是忽略了在解释中引入知识与习题间的关联性.本文提出的可解释知识追踪方法根据用户知识状态从习题-知识点图中构建推理路径提供解释.本文是首个提出以推理路径为知识追踪任务提供解释的工作.
2 问题定义与总框架
本节主要给出知识追踪任务的形式化定义、介绍相关预备知识,并说明可解释知识追踪模型基本框架.
2.1 基本定义
在智慧教育系统中,假设每个用户独立完成习题,记录某一用户的习题作答情况为Xt.其中,某时间步下习题作答交互通常表达为一个习题-作答元组xt=(qt,at),即用户在时刻t回答了习题qt,作答情况为at,at一般为1/0二元取值,如果该用户在时刻t正确回答习题qt,则at=1,反之at=0.
知识追踪任务可以建模为一个有监督的序列学习任务,如图1所示.已知用户的习题作答交互记录Xt={x1,x2,…,xt},通过建模其答题情况,从交互历史中提取用户的隐式知识状态,并跟踪该知识状态随时间的变化情况.由于对知识状态的评估无法外显量化,因此现有的知识追踪任务预测用户在下一时间步答对习题的概率P(at+1=1|qt+1,Xt),从而间接反映对用户知识状态的评估.
通常,每个习题qt会对应考察一个或多个知识点,习题qt考察了知识点si与sj,则认为qt与si,sj之间存在对应关系.值得注意的是,某习题可能考察了若干个知识点,某知识点可能被若干习题考察,即习题与知识点之间的对应关系为多对多.该关系由矩阵Q表示.若习题与知识点间存在对应关系,则矩阵Q中对应位置值为1,否则为0.在本文中,矩阵Q将进一步转换为习题-知识点之间的单一关系二部图.
2.2 可解释知识追踪模型框架
本文提出一个基于图注意力网络的可解释深度知识追踪框架,通过引入习题的上下文信息扩充习题-知识点关系图,然后利用RNN网络对答题序列建模得到用户当前的知识状态.最后基于用户知识状态学习注意力权重,得到当前预测习题基于用户知识状态的个性化表示,并为预测结果生成推理路径作为解释.模型由4个模块组成,分别为认知状态模块、基于用户知识状态的个性化习题表示模块、作答表现预测模块和解释路径生成模块.
1)认知状态序列模块.用于在用户交互序列中建模其知识状态,捕捉知识点间粗粒度的依赖关系.将序列最终时间步对应的隐藏状态作为当前用户状态表征,包含了用户对习题与对应知识点的掌握状态.
2)基于用户知识状态的个性化习题表示模块.本模块首先根据矩阵Q构建知识点与习题之间关系的二部图,然后从所有用户交互信息中进一步建模知识点之间的联系、习题之间的共现关系等.这些上下文信息将用于扩展二部图,将知识点与习题之间的单一关系扩展为包含知识点间、习题间相关关系的图.然后对该图应用注意力图神经网络算法,由认知状态模块中获得的用户当前知识状态得到注意力值,据此聚合邻居节点信息,得到当前预测习题基于用户知识状态的表示.随后,该注意力加权的习题表示将与用户认知状态一道送入预测模块,预测用户作答表现.值得注意的是,基于用户认知状态的个性化权值将为预测结果提供解释.若预测结果为用户将答错此题,由注意力值得到的路径将帮助定位出用户知识掌握中的薄弱环节.
3)作答表现预测模块. 本模块根据之前得到的用户知识状态与个性化习题表示,输出用户在下一个时间步正确回答目标习题的概率.
4)解释路径生成模块.本模块在得到当前作答表现预测后,为预测结果提供可解释性.基于用户认知状态的个性化注意力可以使得用户关注的邻居节点得到更高的注意力值,因而对预测结果产生更大影响.由此,可利用该注意力值在图中为预测结果展示出一条推理路径.在每一跳邻居中选择最大注意力值的节点添加到解释路径内,直至达到预定的跳数,就在习题-知识点图中生成了一条解释路径,直观展示当前预测结果的产生原因.IDKT模型整体结构如图2所示:
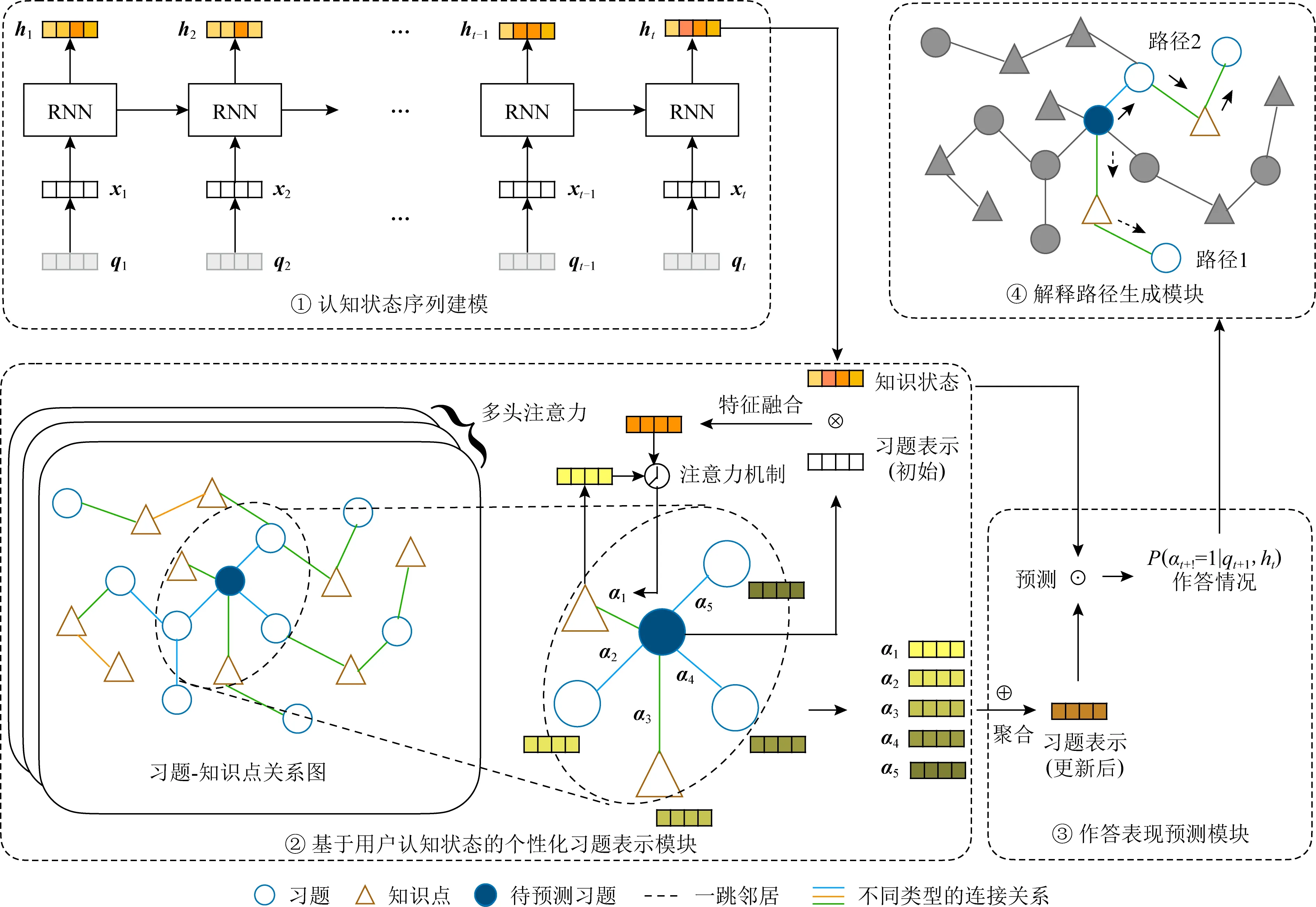
Fig.2 Framework of our model
3 可解释知识追踪模型
本节主要介绍可解释知识追踪模型的各个模块,包括用户认知状态序列建模、基于用户认知状态的个性化习题表示模块、作答表现预测模块、解释路径生成模块以及模型训练方法.
3.1 认知状态序列建模
由于用户的作答交互序列存在时序,而且不同习题之间可能存在依赖性,因此本模块通过建模作答序列,捕捉用户状态的变化并自动学习习题之间的潜在关系.本模块结构设计如图2中①的部分所示,参照DKT[2]使用长短时记忆网络(long-short term memory, LSTM)从用户交互序列中学习其当前知识状态.
(1)
其中,xt为习题表示与用户作答情况的拼接向量,变量ht,ct,it,ft,ot分别代表隐藏层状态、单元状态、输入门、遗忘门、输出门.该认知状态序列模块可以捕捉知识点间粗粒度的依赖关系,此处将序列最终时间步对应的隐藏状态向量ht作为当前用户状态表征,其中包含了用户对习题与对应知识点的掌握状态.
3.2 基于认知状态的个性化习题表示模块
所提模型的核心是基于用户知识状态的个性化习题表示模块,主要分为2部分.
首先,为缓解数据稀疏性问题,在由矩阵Q构建的知识点与习题二部图基础上,从所有用户交互信息中进一步建模知识点之间的联系、习题之间的共现关系等上下文信息,利用得到的知识点间、习题间相关关系将二部图扩展为包含多种关系类型的异质图结构.然后在此异质图基础上,应用注意力图神经网络聚合邻居节点,得到当前预测习题更加丰富的节点表示.其中,用户当前时刻的知识状态将与习题节点表示一道,共同得到注意力值作为聚合邻居节点的依据.由于用户知识状态不同,所以在图中对邻居节点的关注程度也不同,因此,通过利用用户当前知识状态可以学到个性化的习题表示.
1)基于上下文的习题-知识点图构建.根据每道习题所考察的知识点,很自然地就可以构建出知识点-习题二部图.然而,知识点之间的关联关系、先序关系,习题之间的相关关系并不能通过该二部图体现.为了得到信息更加丰富的习题-知识点关系图,我们提出融合上下文信息,扩展习题之间、知识点之间的关系,将单一关系的二部图扩展为展示习题、知识点间丰富联系的异构图.
① 习题-知识点关系构建.通过2.1节中介绍的矩阵Q可以得到习题与知识点间的对应考察关系.例如图3(b)中,若习题q1考察了知识点s1,s2,s3,则认为在习题-知识点二部图中q1与s1,s2,s3存在连接,即:
(2)
注意,习题考察知识点关系是研究知识追踪的基础信息,支持知识追踪问题研究的数据均直接提供该类信息,因此建模时无需做额外处理.如图3(a)所示.
② 习题-习题关系构建.在习题与知识点之间的考察关系中不难看出,若某些习题共同考察了相同的知识点,该习题之间存在较强的相关关系.以图3为例,若习题q1考察了知识点s1,s2,s3,习题q2考察了知识点s2,s3,习题q3考察了知识点s3,s4,习题q4考察了知识点s5,则可将其关系表示为如图3(c)所示.
q1与q3的共同考察的知识点最多,因此相关度最高,q1与q4考察不同的知识点,因此相关度最低.因此采用习题之间的知识点共现作为习题相关程度的衡量指标之一.
另外,通过挖掘用户的答题序列发现,某些习题会呈现出固定的共现模式.例如两习题经常在用户答题序列中伴随出现,则可推测其间存在一定关联,例如习题有相似的题型,关联的考点等.在图3中的例子为q3与q4.我们统计序列中习题共现的频繁模式与非共现频次的比值,选择其中大于一定阈值的共现模式,其形式化表述:
(3)
其中,freq(qi,qj)表示习题qi,qj共现的频次,freq(qi),freq(qj)分别表示习题qi,qj单独出现的频次.
此外,考察相同知识点的问题因为难度设置不同,从而会导致不同的作答表现.对此我们统计习题被所有用户作答的正确率来表征该习题的难度系数,若用户整体正确率高说明习题相对简单,反之说明题目本身难度较大.
③ 知识点-知识点关系构建.知识点之间也存在着关联关系、先修关系、上下位关系等.比如知识点s1,s2,s3共同被习题q1考察,说明知识点s1,s2,s3之间存在关联关系或上下位关系.另外,如果在用户答题序列中,知识点s1总是先于知识点s5被考察,说明知识点s1可能是知识点s5的先修知识点,即掌握知识点s1是掌握知识点s5的前提,如图3(d)所示.基于以上2条假设,通过挖掘所有用户的答题序列和作答情况,可以构建知识点之间的关联关系和先修关系.
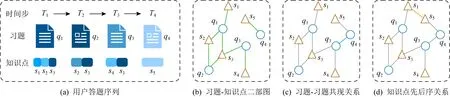
Fig.3 Inter-relations between questions and skills
2)基于用户知识状态的个性化习题表示.通过结合上下文信息得到习题-知识点间的异质图后,为了对习题-知识点图的丰富信息进行建模,模型用注意力图神经网络聚合邻居节点,得到当前待预测习题更加丰富的节点表示.
① 基于用户知识状态的注意力机制.对于同一习题,知识状态不同的用户关注的考察重点不同,影响用户作答表现的考点也不同.基于这一考虑,我们提出将用户知识状态纳入图神经网络的节点表示学习过程.
假设当前习题-知识点图中所有节点的嵌入向量集合为Ω={n1,n2,…,nN},ni∈F,其中N为节点数,F为每个节点的特征维度.首先,为了获取特征之间的高阶联系,需要对节点进行线性变换.本文对图中节点共享线性变换矩阵W∈F′×F,F为每个节点特征的初始维度,F′为线性变换后节点特征维度.
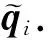
(4)
输出eij经过softmax激活函数映射αij=σ(eij)即得到节点j对节点i重要程度的表征.
此外,为了捕获用户知识状态与节点表示的多语义下的特征交互,模型引入了多头注意力机制(multi-head attention),即采用相同的注意力机制,但是对于每一头注意力学习不同的权值矩阵W,以实现当前节点与用户知识状态进行更加全面的交互.在传播过程将多头注意力得到的结果拼接,在输出层求和平均,得到最终的节点表示.
② 聚合邻居节点.得到了目标节点与周围邻居节点基于用户认知状态的注意力向量后,邻居节点的表示将根据该注意力值进行加权求和,此即为单头注意力的聚合过程.
(5)
我们将得到的多头注意力进行拼接,
(6)
通过重复这样的过程,更多跳的邻居节点表示被聚合到中心节点.值得注意的是,在输出层,由于输出向量维度限制,上述的拼接操作将不再适用,此时可以将多头注意力机制得到的节点表示进行平均,得到最终基于用户知识状态的个性化节点.
(7)
3.3 作答表现预测与损失函数
本模块根据用户知识状态与个性化习题表示,输出用户在下一个时间步正确回答目标习题的概率.该过程可形式化地表示为
(8)
其中,σ(·)为激活函数,fp为预测函数,ht为认知状态模块得到的用户当前知识状态表示向量,ni为习题表示模块经过多头注意力聚合邻居节点得到的个性化习题表示向量.激活函数与预测函数可根据不同数据特点选择.在本模型中,fp为内积函数,σ(·)为sigmoid函数.
最后,采用随机梯度下降通过最小化预测概率与标签结果的交叉熵损失的方式更新模型参数.其中ai为用户实际作答情况,正确为1,错误为0.pi为预测用户作答正确的概率,pi∈[0,1].
(9)
3.4 基于用户知识状态的解释路径生成
基于用户认知状态的注意力值不仅用于聚合邻居节点得到个性化的习题表示,也将在得到当前作答表现预测后,为预测结果提供可解释性.
在注意力图神经网络聚合表示的过程中,对每一跳邻居都会学习一组归一化的权值.该个性化注意力可以直观地理解为在用户当前的认知状态下更关注哪个邻居节点.用户更加关注的邻居会得到更高的注意力值,因此在聚合得到中心节点表示时会发挥更大的作用,所以很自然地,会对预测结果有更直接的影响.基于这样的认识,我们可以利用该注意力值在图中为预测结果展示出一条推理路径.如图2中④的部分所示.在每一跳邻居中选择最大注意力值的节点添加到解释路径内,直至达到预定的跳数,这样,我们就在习题-知识点图中生成了一条解释路径,直观展示当前预测结果的产生原因.
4 实验与结果
本节首先介绍实验的基本设置,包括参数设置、度量指标、数据集和对比方法.接着展示本模型和各对比方法在各个数据集中的预测表现.随后进行消融实验以验证个性化注意力机制和融合上下文信息习题-知识点关系图构建2个模块的有效性.最后通过案例分析,展示基于注意力的推理路径的生成结果.
4.1 参数设置与度量指标
本实验在随机梯度下降中使用的学习速率r∈{0.0001,0.001,0.01},嵌入维度k∈{50,100,200},训练批量大小B∈{50,100,200,400},RNN层数l∈{1,2,3},隐藏状态层数h∈{32,64,128},随机采样邻居节点数n∈{2,4,8},聚合范围为m∈{1,2,3,4}跳内邻居.最优参数通过网格搜索由验证集确定.本实验中所有数据集的迭代次数均设为1 000.习题、知识点嵌入维度均设为100,嵌入矩阵在随机初始化后随训练过程动态更新.知识状态建模部分的RNN算法采用LSTM,包含2个隐藏状态层,隐藏层维度均设为64,最终输出的用户知识状态向量维度为100.利用习题-知识点图进行嵌入更新的过程中,每一跳随机采样的邻居节点数设为4,最远聚合3跳以内的邻居节点.模型的参数优化采用随机梯度下降,学习率设置为0.001,批大小为100.
参照大多数认知跟踪模型研究工作,本实验采用ROC 曲线下方的面积大小(area under the curve, AUC)和预测结果准确率(accuracy, ACC)作为评价指标.AUC与ACC越大表示模型预测性能越好.
4.2 数据集与对比方法
本实验在3个公开的知识追踪数据集上验证模型有效性:ASSIST09,ASSIST12,EdNet.3个数据集均从用户的答题交互日志中抽取,表1显示了各个数据集的统计信息.每个数据集中,80%数据用于训练与验证,20%用于测试,交互序列最大长度设为200.我们从各个数据集中选择习题,习题考察的知识,和用户的作答情况作为知识追踪任务的基本数据.此外我们统计了每个题目在平台内总体正确率,不同题目之间的共现关系,习题考察知识点的对应关系,以此作为扩充习题-知识点关系图的上下文信息.在以上3个数据集中,我们去掉未标注考察知识点的答题记录,过滤了交互次数小于10的用户.
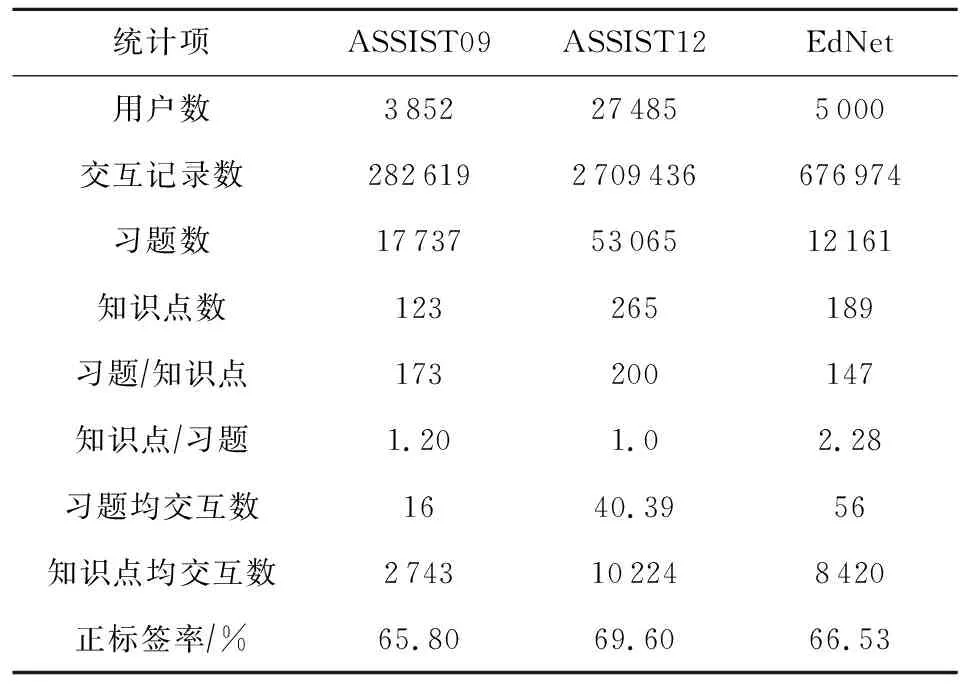
Table 1 Statistics of Datasets
ASSIST09[22]是2009—2010年间从 ASSIST 在线教育平台(上标加网址)收集的用户交互答题序列.我们在“技能构建者(skill builder)”数据集上进行实验.数据集包含3 852名用户,123个知识点,17 737个问题和 282 619次交互练习.
ASSIST12[22]是2012—2013年间ASSIST 在线教育平台收集的数据.和ASSIST09不同,ASSIST12数据集中每个问题只考查单一知识点.我们采取与ASSIST09相同的预处理方式.
EdNet[23]由人工智能在线辅导平台Santa收集提供,包含131 441 538条交互记录,涉及784 309个用户.由于数据量过大,本实验随机选择5 000名用户的学习记录,其中包含189个知识点、12 161个习题和676 974条交互记录.
为了验证所提模型在预测用户作答表现上的有效性,我们选取7个典型基准模型.
传统模型通过非深度方法,人工定义影响用户作答表现的因素,并根据用户交互序列拟合参数,文中选取2个:贝叶斯知识追踪(BKT)[1]以二元参数表示用户知识状态,应用贝叶斯网络学习影响用户作答表现的参数,如学习概率、失误概率、猜测概率等.知识追踪机(KTM)[10]引入人工建模的习题和知识点特征,并应用因子分解机预测作答表现.为了与其他基准模型保持一致,本实验仅采用习题ID,知识点ID和作答情况作为输入.
深度模型通过将作答表现预测问题建模为序列预测问题,应用循环神经网络方法建模用户知识状态,预测答题表现,文中选取2个:深度知识追踪(DKT)[2]用RNN建模学习交互序列,学习一个隐状态表征用户的知识状态,以此预测答题表现.动态键值记忆网络(DKVMN)[3]用记忆网络存储不同的知识状态,并学习知识点之间的隐含关系,以此预测作答表现.
深度知识追踪模型有许多扩展工作,此处选取3个与本文所提模型有共通之处的典型代表.图交互知识追踪模型(GIKT)[12]利用图卷积神经网络挖掘习题-知识点之间的隐含关系.通过泛化待预测习题与知识状态的交互,提高模型预测能力.个性化评估知识追踪(IEKT)[17]通过个性化方法评估用户的认知状态和知识获取状态,提高模型预测能力.上下文感知的注意力知识追踪(AKT)[20]通过引入上下文信息并结合IRT模型,增强嵌入的表征能力,通过注意力机制为结果提供解释.
4.3 实验结果
实验结果如表2所示,其中黑体数字表示该数据集中取得最优预测效果的算法表现.分析表中数据可以得到4个结论:
1)针对数据稀疏性和建模个性化认知的扩展模型进一步提高了深度学习类方法的预测能力,证明为深度学习方法引入更多辅助信息和考虑个性化因素均是提升模型指标的有效途径.
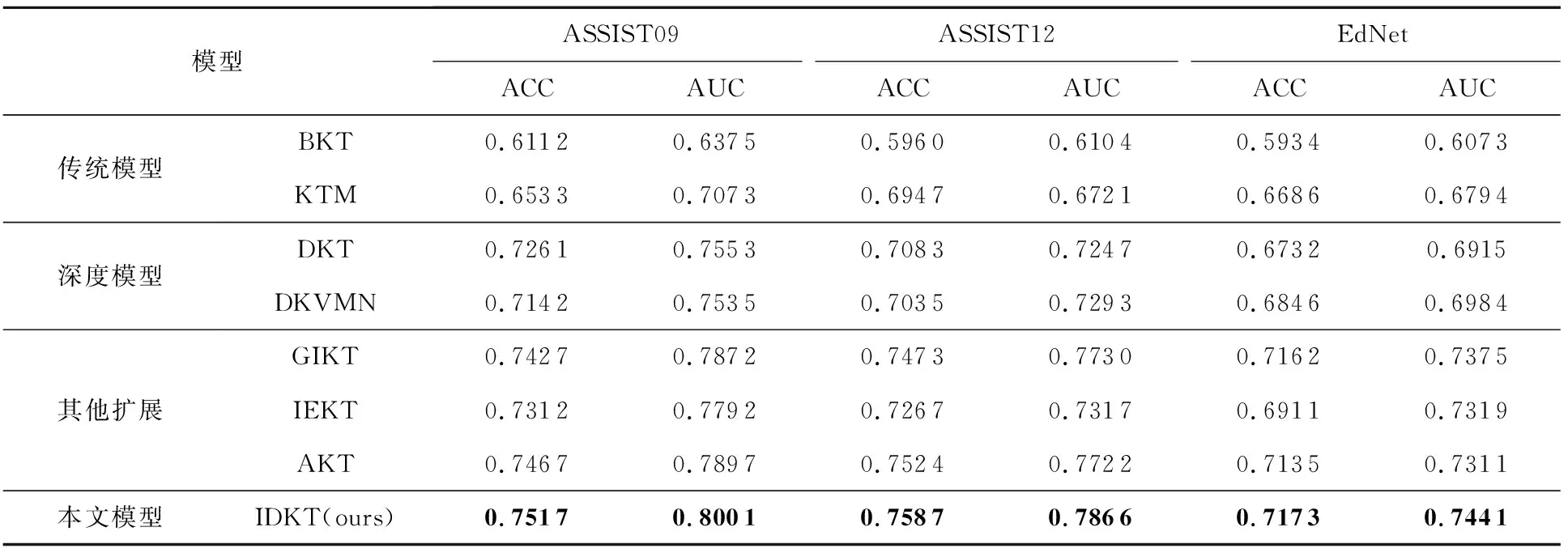
Table 2 The Predicted Results of Different Methods on Knowledge Tracing
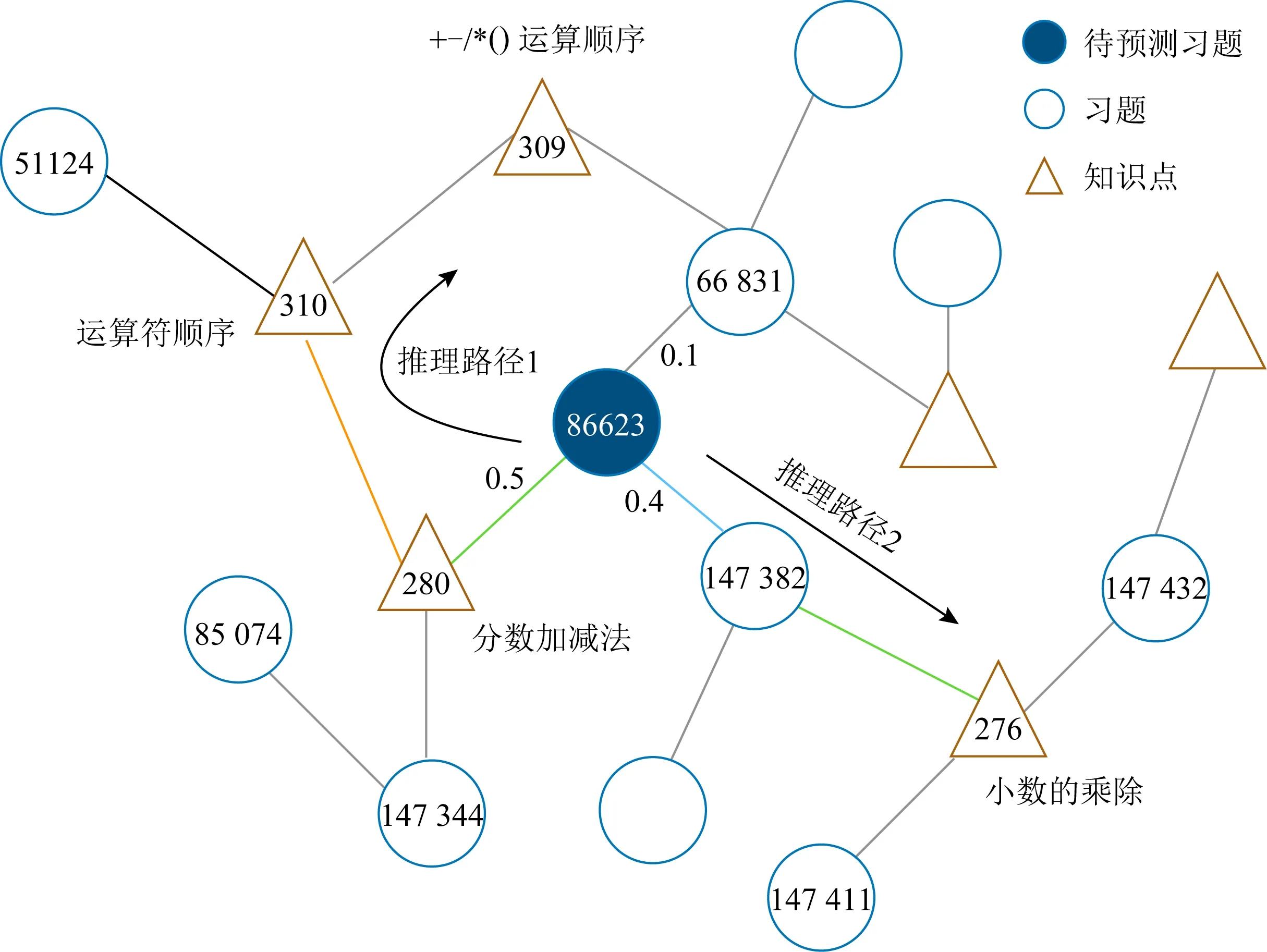
Fig.4 Generating inference path for interpretable prediction
2)和利用习题-知识点二部图挖掘隐含联系的GIKT模型相比,IDKT利用上下文信息挖掘习题-知识点之间更加丰富的联系,AUC指标在ASSIST09,ASSIST12,EdNet数据上分别提高1.64%,1.76%,0.89%,说明充分挖掘上下文扩展习题-知识点关系对缓解数据稀疏问题的有效性.
3)IDKT设计的个性化嵌入对比IEKT的泛个性化方法,AUC分别取得了2.68%,6.98%,1.64%的提升,证明了个性化建模的有效性.
4)IDKT设计的基于知识状态的注意力节点表示聚合机制对比AKT的指数衰减注意力方法,AUC分别取得了1.32%,1.86%,1.78%的提升,证明了基于知识状态的注意力机制的有效性.
4.4 解释路径生成案例分析
本节通过案例分析展示由个性化注意力权重生成推理路径的过程.以ASSIST09数据集为例,图4显示了以id为96295的用户的案例分析,预测该用户在id为86633习题作答情况为错误的情况下,为解释预测结果生成推理路径的过程,此处仅展示单头注意力结果,多头注意力推理过程以此类推.
根据个性化注意力权值,当前习题聚合一跳内邻居的注意力权值分别为0.5,0.4,0.1.因此我们将id为280的知识点和id为147382的习题分别加入推理序列中.重复以上过程,就可以在每一层邻居中选择注意力权值高的节点加入推理路径.由此,对于用户在当前习题的作答预测,如图4所示,IDKT生成了2条推理路径:86623-280-310-309和86623-147382-276.对照id的实际含义,就可以对所得推理路径进行解释.以推理路径1为例,模型预测用户未正确作答id为86623的习题可能因为其考察了id为280的知识点.而知识点280与知识点310相关,由此得出的解释路径是,用户在知识点310存在薄弱环节导致当前习题没有回答正确.
通过以上过程,IDKT将个性化注意力权值转化为推理路径,为结果提供可解释性.该解释可以指导用户找出学习过程的薄弱知识点,也可以为后续个性化学习资源推荐、智能问答等提供依据.
4.5 消融实验
本模型的核心部分是将用户知识状态引入图神经网络的注意力学习过程,学习用户个性化的习题表示.我们推测个性化的习题表示不仅为结果提供了推理路径级别的可解释性,也提高了模型预测能力.为了验证这一设计的有效性,将针对个性化注意力机制进行消融实验,观察其对模型预测性能的改善作用.
变种1.为了得到语义更加丰富的聚合邻居表示我们采用多头注意力机制.为了验证多头注意力机制的有效性,此处将多头注意力简化为单头注意力机制,简写为IDKT-s head.
变种2.聚合邻居表示的过程中,计算注意力权值仅考虑目标节点与邻居节点,即退化为注意力图神经网络的表示学习方法,简写为IDKT-w/o ks.
变种3.聚合邻居表示的过程中,不考虑计算注意力权值,对邻居节点的表示加和求平均更新目标节点的表示,简写为IDKT-w/o att.
3个变种的实验参数均按照4.1节描述设置,与本文模型保持一致.由于数据集ASSIST12为单知识点习题数据集,而在实际的智能教育系统中,一个习题可能会考察多个知识点,因此在消融实验阶段我们不考虑ASSIST12,仅展示模型与变体在考察多知识点的ASSIST09与EdNet数据集中的结果.表3展示了本文模型与3个变种的预测结果.从实验结果看,在ASSIST09数据集中,本文所题模型的ACC比3个变种分别高了 0.11%,0.67%,1.13%;AUC分别高了0.24%,1.15%,1.50%.在EdNet数据集中,ACC比3个变种分别高了 0.39%,2.01%,1.11%,AUC分别高了0.39%,0.77%,1.14%.说明基于知识状态的多头个性化注意力机制中,多头注意力、个性化注意力和注意力机制本身均对模型预测能力有提升作用.
对于变种1,将多头注意力退化为单头注意力,对用户知识状态挖掘的能力减弱,模型预测性能有小幅度下降.对于变种2,在聚合邻居节点表示时,未引入用户当前认知状态,相当于将个性化注意力机制退化为基础注意力机制,模型预测AUC在两数据集上下降最大,证明了个性化注意力机制不仅为模型提供可解释性,对模型预测能力提升也发挥了重要作用.对于变种3,聚合邻居表示时直接采用直接加和平均的方式,模型预测能力有大幅度下降,证明了注意力机制的有效性.
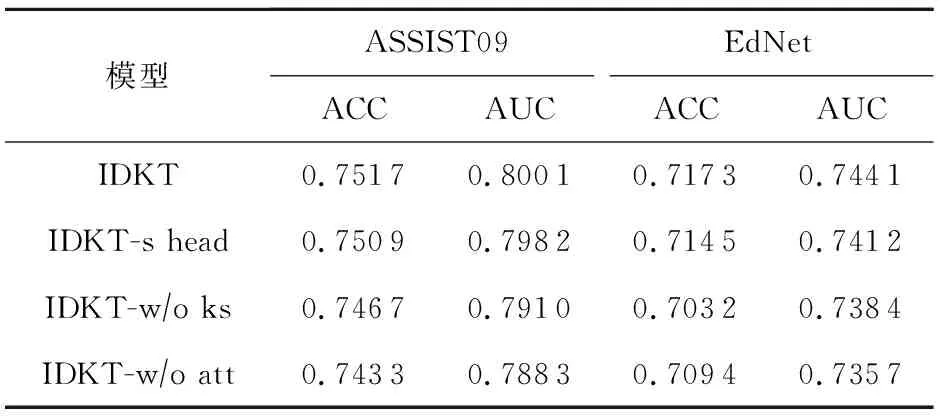
Table 3 The Predicted Results of Our Model and Its Variants on the Knowledge Tracing Task
5 结论和进一步工作
本文主要提出了一个可解释深度知识追踪模型,通过对用户答题序列建模获得其知识状态,然后基于该知识状态学习注意力权重,得到习题-知识点关系图中用户对不同邻居节点的关注程度,并以此聚合邻居节点,得到当前预测习题基于用户知识状态的个性化表示,提高了知识追踪模型预测性能.对于预测结果,提出在习题-知识点图中依据用户个性化注意力值选择推理路径作为对预测结果的解释.
后续工作将主要研究引入更丰富上下文知识的方法,将习题-知识点图扩展为有向带权图,以此有效刻画知识之间先修关系的方向性和节点之间的关联程度差别.
作者贡献声明:刘坤佳设计了初步的模型框架、实现了本文的所有实验并撰写论文初稿;李欣奕参与了论文框架设计、实验设计,对论文初稿进行了细致修改;唐九阳对论文修改提出建设性意见,并审核同意发表;赵翔对模型框架和实验设计提出了建设性意见.
