基于1D CNN与XGBoost的恶意代码纹理检测
2021-12-13袁启平孙沂昆王天翔
黄 科,袁启平,董 薇,孙沂昆,亢 勇,王天翔
(北京特种工程设计研究院,北京 100028)
0 引言
随着信息技术的发展,恶意代码也呈爆炸式增长,对互联网安全的方方面面都产生了威胁。在对恶意软件的防范中,对恶意代码的检测显得十分重要。目前,恶意代码检测方式有静态检测和动态检测两种。静态检测一般是依据代码的结构、逻辑,通过代码走查、数据流分析、控制流分析和信息流分析等方法分析代码特征,从而判断软件是否为恶意软件。动态检测可以通过调试器运行被检测的软件的某项功能,动态监测程序调用来判断程序是否属于恶意软件。
加密、代码混淆技术的使用和恶意代码检测对抗等方法的发展,在一定程度上增大了动态分析和静态分析检测的困难。因此,无论是在检测的精确性还是对计算机硬件的损耗上,传统恶意软件检测技术都具有局限性。L.NATARAJ等人[1]提出了将恶意软件的可执行文件转化为灰度图的方法,在灰度图中可以明显分类出有特定含义的片段,如.data、.text等,并且恶意代码家族内部的图像纹理具有相似性。恶意软件转化为图片的本质是将一段线性代码按照某种转化方式投放至二维空间中,将代码的特征转化为图像纹理的特征。但这种方式弱化了恶意代码的线性特征。恶意软件文件转化成的像素点进行排布后,图像多出了像素点上下间的空间相关性,而这样的相关性是原文件不具有的。
在CUI等人[2]的论文中,将恶意代码二进制文件转换成十进制一维数组后,根据文件的大小设定宽度,将一维数组转换成多维度的矩阵,从而形成灰度图片并压缩到同一大小;通过倾斜图像等数据增强的方法增加样本数量,之后输入到神经网络中进行识别。但是,这个过程有以下几个问题。
(1)灰度图像的纹理来源于恶意代码的二进制文件的组合,如L.NATARAJ[1]针对图像不同部分拆分为.text段、.data段一样,其相邻像素点之间是有逻辑关联的。因此,对恶意代码的灰度图像纹理的分析,不仅仅要分析图像,还要考虑纹理间的逻辑关联。在二维卷积神经网络(2 Dimention Convolutional Neural Networks,2D CNN)中,卷积核是一个多维矩阵,提取图像特征时,提取的是方形像素块,而像素块内的像素点之间是跨行的,提取的特征未考虑像素点间的逻辑关联。
(2)在对恶意代码的图像进行压缩时,由于各个恶意软件的大小不同,导致图像的长宽比不同,压缩成同一大小的正方形矩阵后,会导致不同图像长宽压缩比例不同,图像特征损失差距较大。
(3)恶意软件的各个家族内样本数量不同,比例差异较大,产生了数据不平衡的情况。数据不平衡会导致深度学习模型的泛化性下降,也会在训练过程中产生过拟合。
为了解决上述问题,本文提供如下解决方法:
(1)将恶意代码二进制文件转化为范围为0~255的十进制一维数组,每个数充当像素点,形成像素向量,将图像纹理的分析转化成为对一段向量明暗变化的研究;
(2)基于这种变换方式,引入一维卷积神经网络(1 Dimention Convolutional Neural Networks,1D CNN),以提取向量明暗变化的特征;
(3)为了解决恶意代码家族之间样本数量的不平衡,引入近年来在分类问题上表现良好的XGBoost模型,将1D CNN提取的特征输入到该模型中进行分类的预测。
实验结果表明,本文提出的方法能够达到97%的精确度,并且大大减轻了数据不平衡带来的 问题。
1 相关工作
本节介绍检测恶意软件的相关研究。一般情况下,针对恶意代码的检测主要分为启发式检测和基于特征码的检测[3]。启发式的恶意代码检测方法主要利用系统上层信息以及内核文件系统来识别恶意代码的隐藏信息等,比较依赖人员的经验,且误报率较高。基于特征码的检测方法主要通过比较识别恶意代码的显性特征,一般对特征进行伪装变形便能绕过检测。下面将重点介绍恶意代码可视化、基于深度学习的恶意软件检测以及分类器的选择等方面的内容。
1.1 恶意软件可视化
利用文本编辑器和二进制编辑器就可以将二进制数据可视化,已经有诸多研究人员对恶意软件可视化做出了深入的研究。YOO等人[4]利用自组织映射方法实现恶意代码的检测识别和可视化呈现。QUIST等人[5]开发了一套可视化框架用来逆向恶意代码,他们提出利用节点和链接的可视化方法实现对恶意代码的功能、混淆区域的有效识别。TRINIUS等人[6]分别利用树形拓扑图和线程图两种图方法来分别表示恶意代码的操作分布和操作序列,实现对恶意代码的检测。CONTI等人[7]实现文本、图像、视频等非结构化数据以及C++源代码等原始二进制数据段,通过可视化技术转化为图像,实现对恶意特征的识别。KANCHERLA等人[8]通过将恶意代码可执行文件转化为字节图特征,并利用支持向量机(Support Vector Machine,SVM)分类器进行识别,实现对2.5万恶意代码语料库的分类。GOODALL等人[9]开发了可视化分析环境,该环境不仅可以帮助程序员更好地理解代码,还可以将程序中的漏洞可视化,以便更好地发现和解决漏洞。HAN等人[10]提出一种基于纹理指纹的恶意代码特征提取及检测方法,通过结合图像分析技术与恶意代码变种检测技术,将恶意代码映射为无压缩灰阶图片,并采用加权综合多分段纹理指纹相似性匹配方法检测恶意代码变种和未知恶意代码。
1.2 基于深度学习的恶意代码检测
研究人员也利用深度学习去检测恶意软件,TOBIYAMA等人[11]提出一种基于进程行为进行恶意进程检测的方法,利用长短时记忆网络(Long Short-Term Memory,LSTM)进行特征提取,用卷积神经网络(Convolutional Neural Networks,CNN)进行特征分类,特征是从转化为含有本地特征的图片的进程行为日志文件中提取的,这些本地特征表示进程活动。然而这些分析方式是基于软件行为进行的检测,仍受到代码混淆等的干扰。如上文所述,若将对恶意软件的研究转化为对图像纹理的研究,会绕开程序行为的干扰。鉴于1D CNN在如文本、一维信号等序列数据上的良好效果,采用1D CNN对恶意软件转化成的像素序列进行特征提取,而对恶意软件的分析转化成对一条像素条带明暗变化的分析。
1.3 深度学习时数据集不平衡问题的处理
CNN深度学习会遇到一个广泛存在的问题,即数据集不平衡带来的过拟合。HUANG等人[12]提出使用CNN模型从不平衡数据集中学习得到每个样本的embedding向量,然后使用改进的k近邻分类算法对其分类。TANG等人[13]提出使用SVM分类器去解决数据不平衡的情况。而近年来由CHEN等人[14]开发的XGBoost系统在许多比赛上能出色地完成分类任务,利用CART回归树模型,每学习一个新特征,就拟合上一次预测的残差,从而分裂出一棵新的树,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值。利用贪婪算法,遍历所有特征的所有特征划分点,找到最优解。
2 恶意软件二进制文件转化成像素矢量
文章尝试了一种新的恶意代码的可视化方式。基于恶意代码01比特流之间具有逻辑相关性以及家族内恶意软件可视化图片的纹理相似性,家族间恶意软件可视化图片纹理相差性,以二进制读入恶意软件可执行文件,得到一串01比特串,每八个为一组,组合成一个8位二进制的数字,将其转化为一个范围为0~255的无符号10进制数,得到一组10进制数组,每一个数组代表一个像素点,输出一个条纹向量图。可视化操作的具体转化过程算法如下:

利用上述算法对恶意代码家族Agent.FYI、Lolyda.AA3、Yuner.A进行转化。转换后,各个代码家族的条纹特征分别如图1、图2及图3所示。

图1 家族Agent.FYI的条纹特征

图2 家族Lolyda.AA3的条纹特征

图3 家族Yuner.A的条纹特征
家族之内的恶意代码条纹有着非常高的相似性,而家族之间的恶意软件条纹差距较大。因此可以通过这些像素条带的明暗变化特征对恶意软件进行检测并判断其家族归属。
3 基于1D CNN的特征提取
卷积神经网络有稀疏权重、参数共享及等变表示等特点,可以先学习局部的特征,再将局部特征组合起来形成更复杂和抽象的特征,这使得卷积神经网络在存储大小和统计效率方面极大地优于传统的使用矩阵乘法的神经网络。1D CNN广泛应用于自然语言处理、传感器数据的时间序列分析以及具有固定长度周期的信号数据的分析等多种场景。
根据1D CNN对一维序列数据的处理产出的良好表现,可以采用一维卷积神经网络对像素向量进行特征提取。用于像素向量识别的CNN的结构组成如图4所示。具体过程如下。
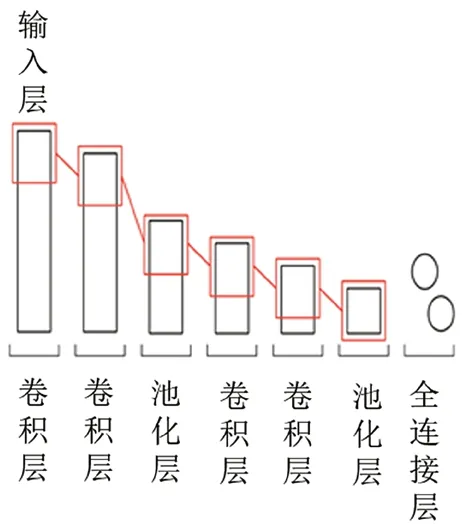
图4 用于像素向量识别的CNN的结构组成
(1)将像素向量压缩成相同的大小,以便输入神经网络。
(2)进入卷积层,卷积层实际上是卷积核与像素向量之间的运算,使用一维卷积对像素向量进行特征提取。一维卷积是取向量的点积,因此点积后会得到一个新的序列。
(3)进入池化层,池化层提供了很强的鲁棒性,并且减少了参数的数量。算法采用MaxPooling和Global Average Pooling。MaxPooling提取区域中的最大值,因此若此区域中的其他值略有变化或者存在平移,pooling后的结果仍不变,可以防止过拟合。Global Average Pooling将最后一层特征图针对整张图进行均值池化,形成一个特征点并起到全连接的作用,将这些特征点组成最后的特征向量输入softmax进行处理。
(4)输入softmax前,需要利用Dropout层丢弃一些信息。在每个训练批次中随机地隐藏网络中一部分隐藏神经元,输入输出神经元保持不变。之后将输入节点通过修改后的网络前向传播,得到的损失结果通过修改的网络反向传播,从而防止过 拟合。
(5)利用softmax将输出映射为0-1的数字,产生一个初步分类的结果。分类器根据其特征将恶意软件图像识别并分类为不同的系列。
对于测序得到的序列信息,首先根据PE reads之间的Overlap关系,将Hiseq测序得到的双端序列数据进行拼接以获得完整的一条序列Tags,同时对Reads的质量和拼接的效果进行质控过滤。之后利用不同软件进行数据分析,如QIIME软件进行OTU划分,基于Silva和UNITE分类学数据库对OTU进行分类学注释分析、利用MEGAN软件分析样品中所有微生物的进化关系和丰度差异,利用Mothur软件对样品进行Alpha多样性指数评估等。
输入到CNN中的数据集需要统一大小,因此需要对向量进行压缩。根据压缩比例不同,向量特征的保留程度也不同。如图5所示,三种比例的压缩都能保持像素向量的基本特征。
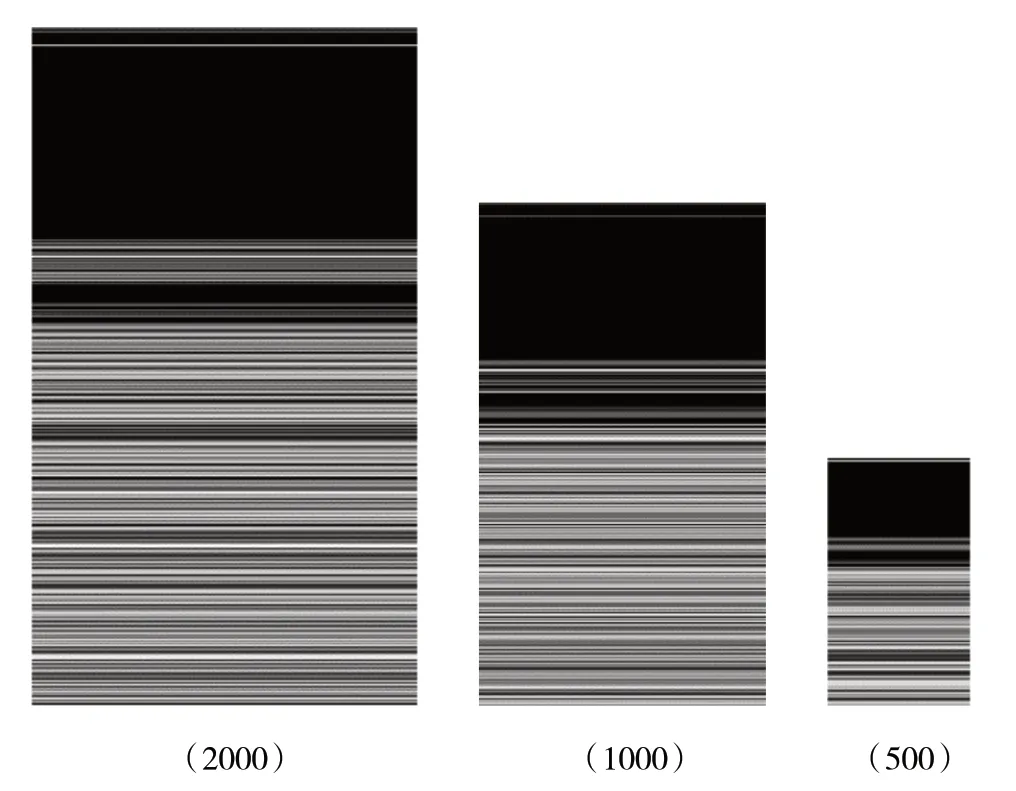
图5 家族Agent.FYI在三种压缩比例下的条纹特征
4 使用XGBoost解决数据不平衡问题
利用上述CNN模型将图片导入神经网络进行训练,但训练的结果与训练数据集的质量关系非常大。当样本出现数据不平衡的情况时,会出现过拟合、低准确率、低鲁棒性的现象。然而由于代码形成的像素向量之间有逻辑关系,因此不应使用目前常用的旋转、倾斜、切割、拼接等数据增强方法。本文引用近年来在分类问题上表现良好的XGBoost,通过对样本特征的权重增强来防止过拟合的情况,以提高分类准确率。
XGBoost算法的思想是不断地进行特征分裂来生长一棵树,每次添加一个树,其实是学习一个新函数,去掉拟合上次预测的残差。当训练完成得到k棵树,要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中对应到一个叶子节点,每个叶子节点对应一个分数,最后只需将每棵树对应的分数加起来,就是该样本的预测值。
5 结果评价方式
对于XGBoost的分类结果评估,实验使用Accuracy、Precision、Recall、F1(F1-score)四 个不同方向的值进行评估精确度。

式中:是预测值,i样本yi对应的真实值。
精度是分类器不将阴性样本标记为阳性的 能力。
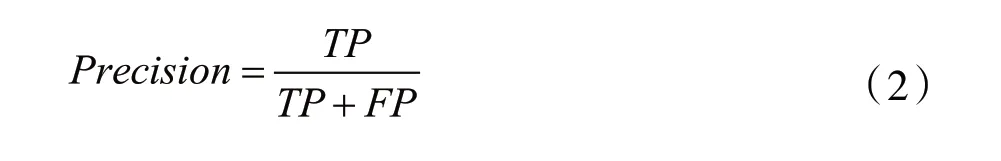
式中:TP是真实肯定的数目,FP是错误否定的 数目。
召回是分类器查找所有阳性样本的能力:

式中:TP是真实的阳性数,FN是错误的阳性数。
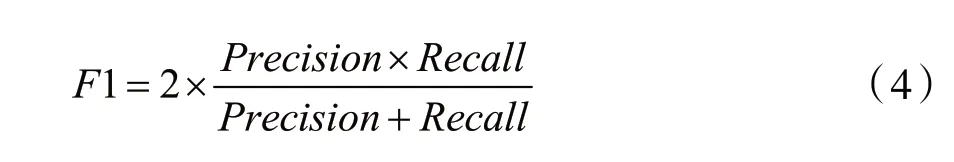
6 实验过程
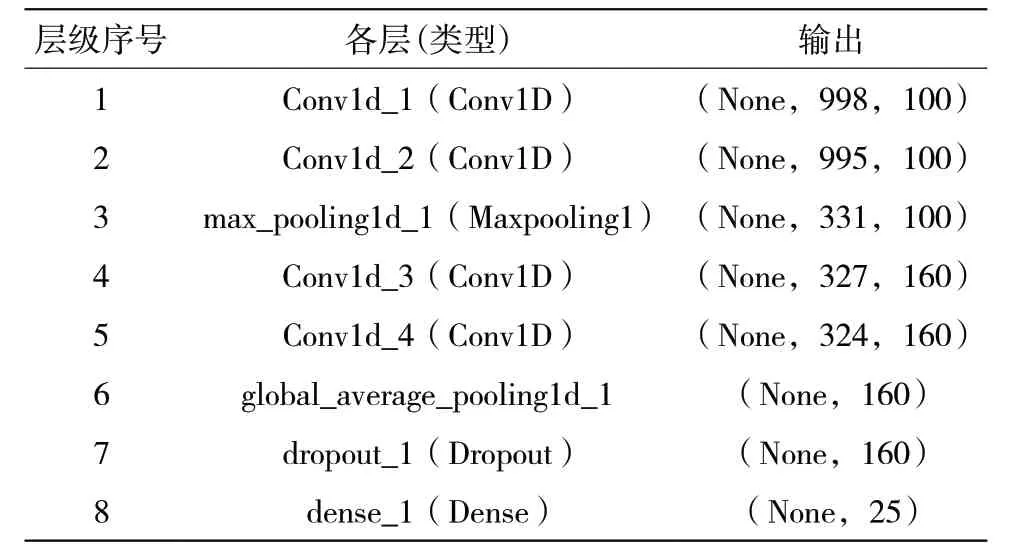
表1 CNN结构
各层功能及设定如下。
(1)第一1D CNN层。具有ReLU函数的卷积层,输入已经预处理的数据,即输入长度为1000的平面向量。此层使用了100个维度为3的过滤器,输出结果为卷积后尺寸998×100。
(2)第二1D CNN层。具有ReLU函数的卷积层,以第一层的输出结果作为输入。此层定义100个维度为4的过滤器,输出结果为卷积后的尺寸995×100。
(3)最大池化层。设置参数选择3,即池化核长度为3,步长为3,池化后数据长度为331,输出为331×100,降低输出的复杂性。
(4)第三1D CNN层。具有ReLU函数的卷积层,此层使用100个维度为5的过滤器,输出尺寸为327×160。
(5)第四1D CNN层。具有ReLU函数的卷积层,此层使用了100个维度为4的过滤器,输出尺寸为324×160。
(6)平均池化层。为避免再次过度拟合,每个特征检测器在这一层的神经网络中仅剩一个权重,输出160个数值。
(7)dropout层。在此层将比例设定为0.5,因此有一半的神经元的权重为零,输出160个数值。
(8)全连接层。具有softmax激活函数的全连接,输出为25个数值,代表25个家族中每个家族的概率。
如图6所示,实验设定了60轮(Epoch)的学习,学习结果为损失值达到0.16,精确度达到0.95。实验中,观察每个家族下的混淆矩阵,发现第6个家族、第13个家族准确率极低,这是数据不平衡带来的过拟合现象,因为机器将少量的数据判断到错误的家族,整体准确率不会受到非常大的影响。
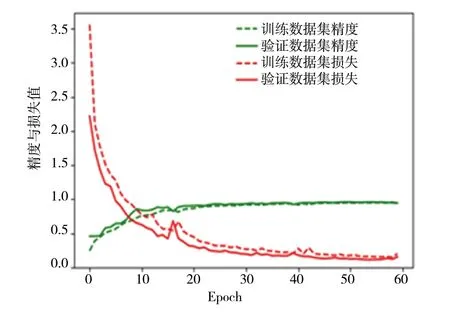
图6 模型精度与损失
实验使用了3种方式对特征进行分类,首先利用softmax函数对特征进行映射分类,其次将CNN提取的特征输入SVM分类器进行分类,最后将CNN提取的特征输入XGBoost分类器中分类。其中,XGBoost模型的参数设置为:

分类结果的混淆矩阵以及F1-score结果如图7所示。
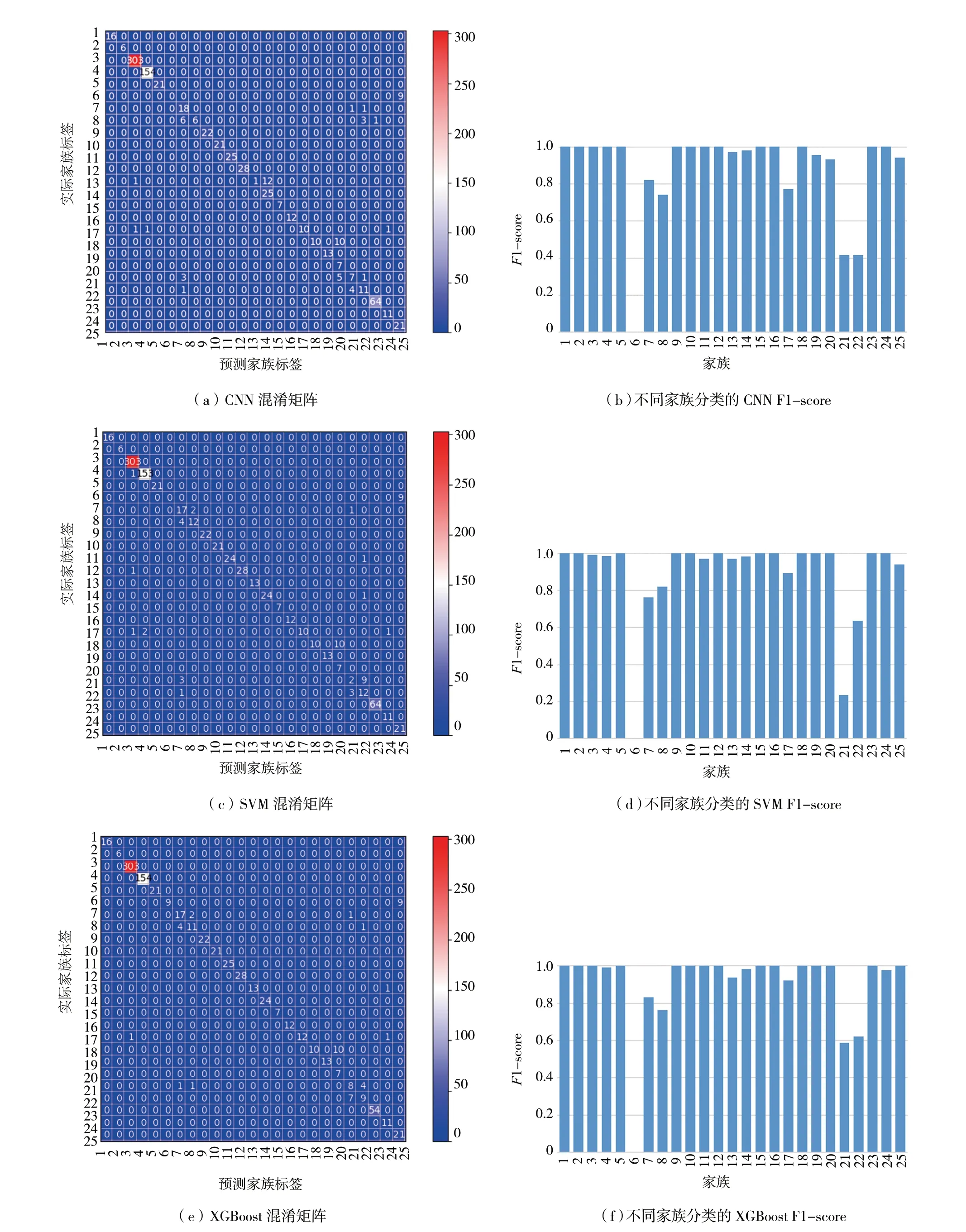
图7 分类结果的混淆矩阵以及F1-score结果
通过数据比对可见,XGBoost表现明显优于另外两种分类方式,准确率提升到了97%的同时,数据集不平衡带来的过拟合现象有较大的缓解,较少的几个家族的预测率有所提高。
7 结语
恶意代码可视化使得对恶意软件特征的分析转换为对图像纹理特征的分析,而线性恶意代码可视化既保留了恶意软件的图像的特征,又兼顾了条纹间的逻辑关联,在使用CNN+XGBoost模型联合分类检测下能达到97%的准确率,为以后网络安全相关工作人员对恶意代码的检测提供了更广阔的可能性。
