基于大数据的智能电网用电量异常检测
2021-12-09何建剑王磊苗光尧周玫于柯
何建剑, 王磊, 苗光尧, 周玫, 于柯
(国网宁夏电力有限公司电力科学研究院 客户服务中心, 宁夏 银川 750002)
0 引言
为保证未来电网(智慧电网)的电能质量和可靠性,及时可靠的电网测量数据起着重要作用[1]。多年来,成千上万的电能质量和智能电表安装在电网的不同点上,而且数量一直在增加。因此,所有这些测量设备收集的数据量不断增长。然而,并不是所有的数据都被保存下来,原因之一是缺乏分析数据并从中提取完整信息的方法[2]。例如,收集的数据包含有关电力系统性能的有用信息以及有关事件潜在原因的信息。同时,这些数据包含了一些复杂性,使得数据分析和信息提取变得困难。为更好地通过数据给电网运营商提供一系列相关问题的信息,如异常检测方法可检测功耗异常行为[3-4]、错误数据注入攻击[5]、有效能源管理的负载预测[6]等。本文主要将功耗数据异常作为应用场景进行研究,处理从智能电表收集的能耗跟踪中识别异常模式。实现对公用事业的帮助,例如基于确定的能源模式进行负载优化用法[7]。最终目标是定义和评估用于功耗异常检测的大数据平台。
1 平台的提出
为了对智能电表功耗进行异常检测,所以提出了一个大数据平台。该平台的目标是处理来自智能电表和天气信息源的大量数据,以检测用户侧的异常行为。这样的分析可以进一步创建客户配置文件,用于根据用户的功耗行为对其进行聚类[8],如图1所示。这方面的4个V来自以下方面[9]。体积:智能仪表生成的大量信息记录道乘以用户数;速度:对不断生成的此类记录道进行实时分析的需要;种类:涉及多个数据源,无论是结构化的还是非结构化的,主要是关于电力消耗和天气数据;准确性:测量误差可能带来许多问题,如智能电表的损坏或丢失数据。同时,还需要考虑价值,即分析可以为公用事业带来的附加价值,可以创建用户配置文件以优化电力生产和整个电网的平衡[10]。

图1 智慧电网大数据的4V复杂度
2 平台的介绍
在此将提出的架构映射到Pääkkönen和Pakkala的参考架构[11]。大数据系统的参考体系结构是独立于技术的,并基于对几个大数据用例的已发布实现体系结构的分析,如图2所示。该图为参考体系结构图,提出的平台方案中包含的所有功能、数据存储和数据流都映射到参考体系结构图上,以便与其他平台进行比较。
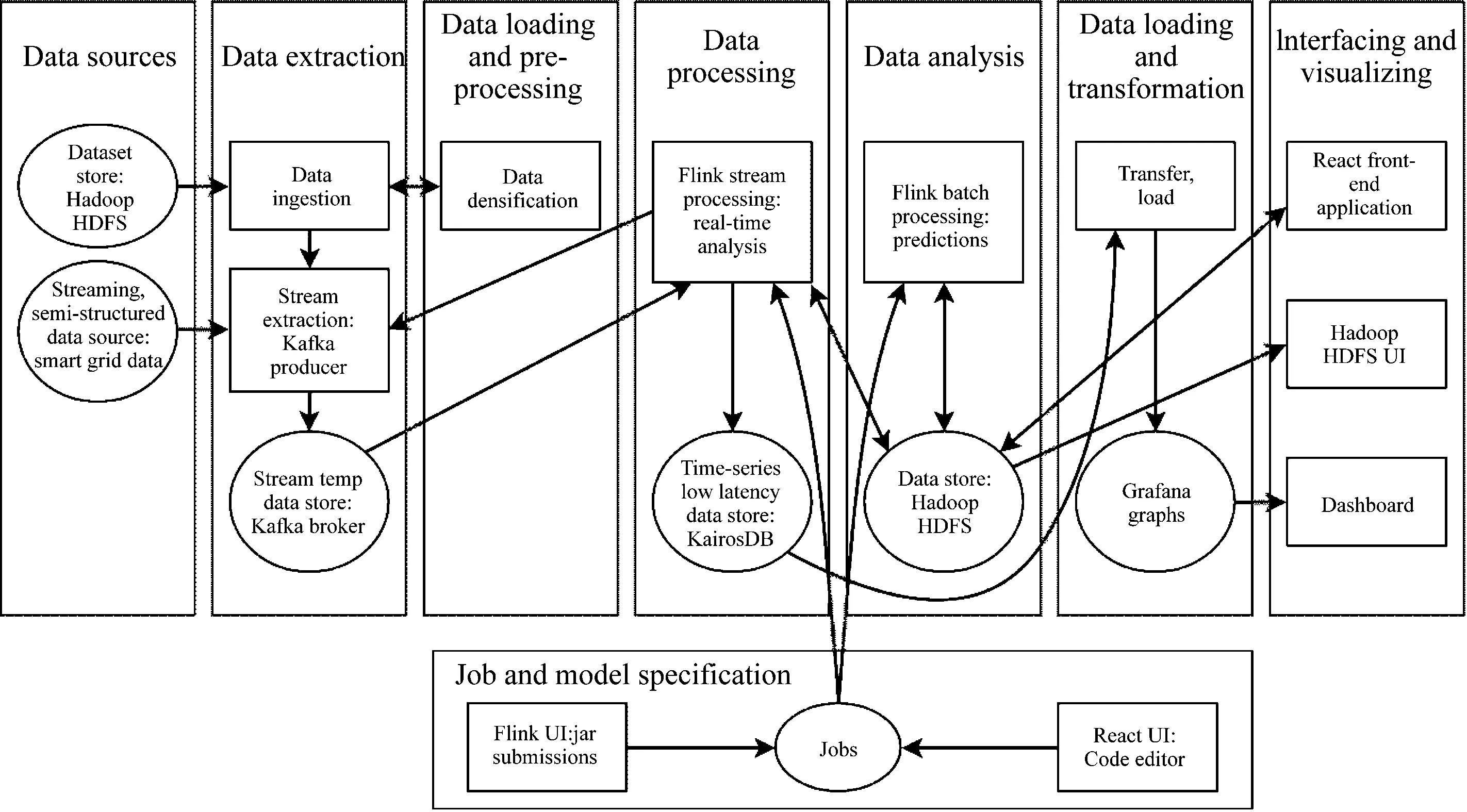
图2 架构示意图
3 能耗异常检测展示
3.1 平台架构
本节展示了该平台在功耗异常检测方面的应用。如前一节所述,研究用户的异常消费行为和发现意外模式是与智能电网领域中智能计量设备的使用相关的重要课题。
在此背景下,提出了一个场景来展示提出的平台,并研究流媒体部分3种不同框架的性能:基于批处理(Spark)、基于流(Storm)和混合(Flink)。由于速度层是平台性能的关键部分,因此选择最佳的框架是一个重要的决策。
3.2 场景定义
实验场景中使用了3种不同的大数据处理框架(Spark,Storm,Flink),并包含同一算法的3种实现。为了实现相同的用例,可以通过测量同一数据集的处理时间来轻松比较每个框架的性能。
3.2.1 数据集与方案设置
第一个数据集包括从一栋建筑物中的公寓收集的功耗数据,采样率为15分钟。公寓数据集(id,时间戳,耗电量/kW)包含2017—2019年期间114个单户公寓的数据。第二个数据集包含天气数据(时间戳、温度、湿度、压力、风速等),采样率为一小时。公寓数据集的大小为2.1 GB,包含6 400万条记录。为了使场景更好地代表大数据环境,将每条记录复制了8次。为此,使用了平台的摄入管理器部分(采用乘法致密化方法)。测试数据集的结果大小为512百万个CSV格式的记录。
该场景由3个服务器节点运行:1个主节点和2个工作节点,如图3所示。
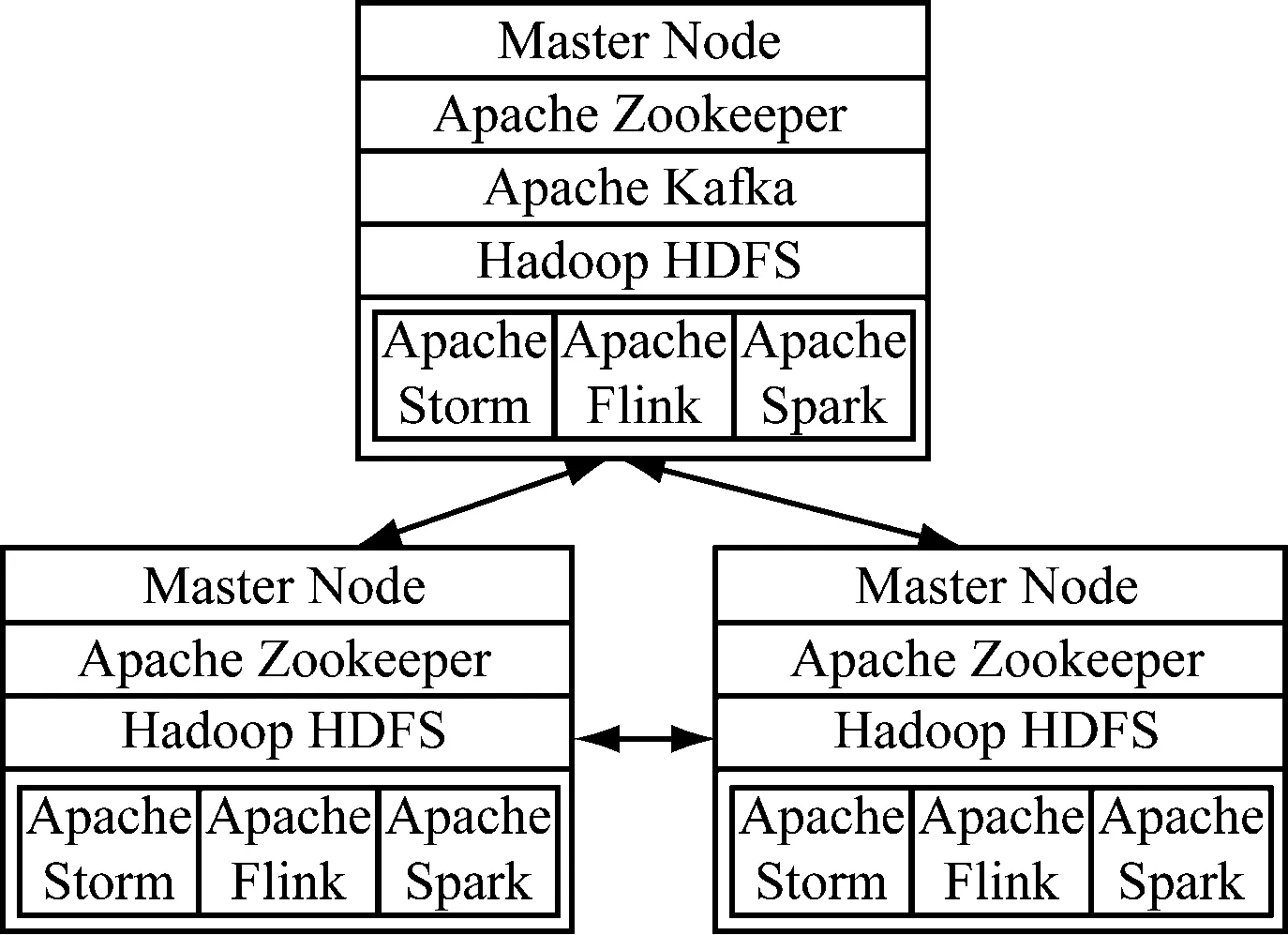
图3 实验中节点的设置
除了Kafka,每种技术都在所有3个节点上的集群中运行。 Kafka仅在主节点上运行,因为认为它可以无延迟地服务于所有其他节点。为了使Kafka能够运行,需要Apache Zookeeper来管理集群。由于Apache Storm也使用Zookeeper进行集群管理,因此决定在所有3个节点上安装Zookeeper。每个节点都配置了Intel Xeon E3(2.4 GHz,4核),8 GB RAM,运行在Ubuntu 16.04 LTS 64位Linux 4.4.0内核上。在运行功耗异常检测方案时,使用了以下框架版本:Apache Zookeeper 3.4.12, Apache Kafka 2.0.0, Apache Hadoop 2.8.5, Apache Flink 1.7.1, Apache Spark 2.4.1, Apache Storm 1.2.2, Scala 2.12, Java JDK 1.8.0201。
3.2.2 异常检测算法的实现
使用预先计算的消耗量预测模型(见算法1),实施了一种简单的算法来发现消耗量异常。为了计算异常检测,使用Java编程语言实现了Spark批处理程序。并且没有使用其他大数据处理框架来实现此算法,因为主要重点是测量流处理的性能。为了确定当前的耗电量项目是否异常,分析了前三天的耗电量。将一天中的每个小时作为一个季节,即t=[0,23],并使用时间t的前3天消耗量来计算预测。同时,还需要考虑外部天气,因为它与功耗高度相关:在冬季,由于加热而导致的功耗较高;而在夏季,由于制冷设备起作用而导致的功耗较高。对于每套公寓,预测都是单独制定的,因为客户有不同的生活习惯,并且无法将能耗预测推广到所有公寓。
Algorithm 1 Anomaly DetectionModel
s=season, n=day, C=avg power consumption, XT=outside temp variables
Input:C,T▷ Consumption and Temperature Datasets
Output:P▷Anomaly Detection Model
Function: CreateAnomalyDetectionModel(C,T):
P←Ø▷ Initialize Anomaly Detection Model
foreachd∈days(2017—2019) do
foreachs∈[0,23] do
foreachid∈apartment_IDsdo
C1 ←Make_Average(Get_Consumptions(d-1,s,id))
XT1 ←
Compute_XT(Get_Outside_Temperature(d-1,s))
C2 ←Make_Average(Get_Consumptions(d-2,s,id))
XT2 ←
Compute_XT(Get_Outside_Temperature(d-2,s))
C3 ←Make_Average(Get_Consumptions(d-3,s,id))
XT3 ←
Compute_XT(Get_Outside_Temperature(d-3,s))
Prediction ←
(C1*XT1+C2*XT2+C3*XT3)/3+7P.insert(d,s,id, Prediction)
end
end
end
returnP
接下来,需要在速度层对框架的性能进行评估,Lambda实现的速度层利用了预先计算的模型,如算法1所示,在此模型下,可以检测输入功耗数据的异常情况。首先,从数据存储中加载异常检测模型,然后将智能电表读数与此模型进行比较。如果新的消耗值超过模型中的值,就将其视为异常,具体算法如算法2所示。
Algorithm 2 Anomaly Detection Streaming Process
Input:M,C▷ Anomaly Detection Model and New Consumptions
Output:A▷Anomalies
function Anomaly_Detection(M,C):
A←Ø▷ Initialize Anomalies
foreachc∈Cdo
P←M.get(c.day, c.season, c.id)
if c.value>Pthen
A.insert(c.day, c.season, c.id, P)
end
end
returnA
使用每种框架(Spark,Storm,Flink)在Java中实现了流处理部分。每个实现都包含特定于框架的分布式操作,如MAP,Filter,Foreach。
3.2.3 异常检测的处理流程
在这种情况下,异常检测的处理流程如下。功耗数据集以及天气数据集均存储在HDFS中。首先,Spark将数据集加载到内存中,并在分布式环境中执行操作,如图4所示。以使用算法1生成预测模型,如图4中的步骤1—2。Spark的输出存储回HDFS,如图4中的步骤3。
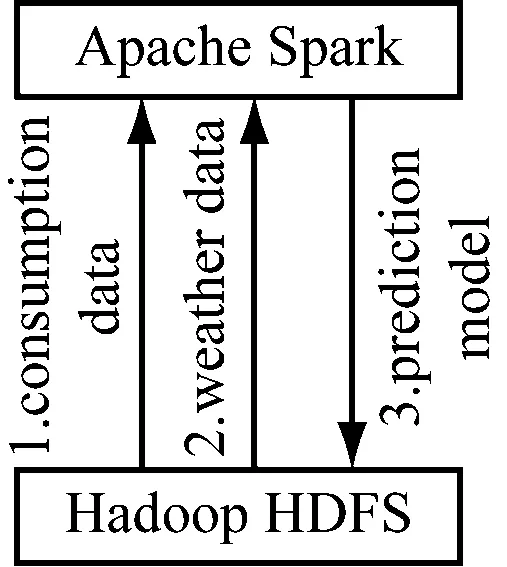
图4 异常检测模型数据流
3.2.4 实时异常检测数据流
实时异常检测的数据流如图5所示。

图5 实时检测数据流
如步骤1所示,首先将预测模型从HDFS加载到内存中。初始化并准备好使用中的大数据处理框架(Spark,Storm,Flink)后,可以开始将数据流式传输到Kafka中。这是使用摄取管理器完成的。摄入管理器从HDFS读取消耗数据,并将每条记录多次发送到Kafka,在这种情况下,使用乘法加密方法8次,如步骤2—3。大数据处理框架订阅消费主题,并进行第四步,在新数据到达后立即开始处理。将所有发现的异常发送到Kafka主题“异常”,如第五步。
因此,可以从3个框架中的每一个作为速度层来运行平台获得一些结论,总结如表1所示。
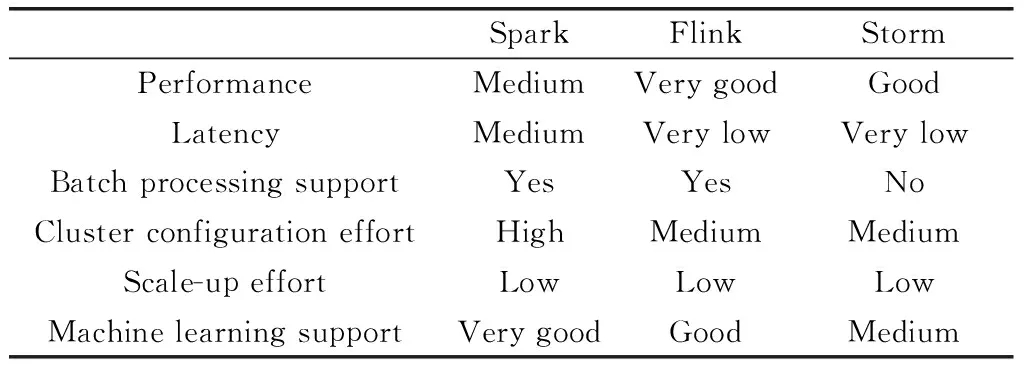
表1 速度层框架比较结果
3.2.5 吞吐量
每秒处理的记录,如图6所示。

图6 吞吐量示意图
Storm(每秒约37.8万条记录)和Flink(每秒约43.8万条记录)显著快于Spark Streaming(每秒约168k记录)。对于该场景中使用的功耗数据集(5.12亿条记录),这意味着Flink的平均时间约为20分钟,Storm的平均时间约为25分钟,Spark的平均时间约50分钟。如果吞吐量很重要,则Flink似乎能提供最佳结果。
3.2.6 延时
在内部,Spark Streaming接收来自各种来源的实时数据,并将其分为批次(微批次),然后由Spark引擎进行处理以生成结果流。因此,它不被视为本机流,但是通过这种方式,它也可以有效地支持对大数据流的处理。但是,Spark流在很大程度上取决于批处理间隔,该间隔可能在数百毫秒的范围内。在方案运行期间,Flink和Storm的延迟都较低(以毫秒为单位),而Spark的延迟则以秒为单位。但是,选择取决于批处理层(或微批处理)对于特定情况的重要性。对于当前在速度层使用预先计算(批处理级别)模型或在线学习算法的场景,考虑到延迟,Flink和Storm可能比Spark更好。
3.2.7 有效性风险
在测试结果中需要对有效性进行风险对比。为了内部有效性,框架的配置可能会对结果产生影响。因此,尝试根据节点配置和可用资源(主要在内存管理,并行性和处理器设置级别)配置每个框架,以实现最佳效率,但是穷举搜索所有最佳配置是不可行的。关于功耗异常检测,提出的方案更具探索性。完整的实验需要考虑到参数的更改以及对性能的影响。例如,仅部署节点的数量会对每个考虑的框架产生不同的影响。在此处,只保留了一个相当简单的节点拓扑,但是对于更复杂的拓扑,结果可能会有所不同。每个平台上算法的实现差异也给有效性带来了另一个内部威胁。每个框架都提供不同的抽象来开发应用程序,并且不可能同等地实现该算法,尽管认为由于用于Benchmark测试的简单异常检测算法限制了这种风险。另一个风险与构造有效性有关,该方案旨在通用数据处理上下文中比较框架,而不是一个要进行很多因素变化(例如每个框架所分布的节点数)的完整实验。另一个风险与泛化有关,结果适用于讨论的特定场景以展示平台,其他场景可能有其他需求并导致不同的结果。
4 总结
智能网格环境中的大数据处理具有许多需要实时操作和流处理的应用程序。在本文中,提供了一个大数据平台,用于从功耗数据中进行异常检测。该平台基于具有数据密度的摄取层,Apache Flink是速度层的一部分,HDFS/KairosDB是数据存储。将主要组件映射到Pääkkönen和Pakkala提出的参考体系结构,并提供了基于功耗异常检测的方案结果,以评估不同框架的适用性:基于批处理(Spark),基于流(Storm)和混合(Flink)。总体而言,在平台的速度层采用了Flink,因为它为流处理提供了最佳性能,并满足了实验场景中对功耗数据集异常检测的要求。
