数据挖掘的大学毕业生就业预测研究
2021-12-09黄博宇
黄博宇
(西安工程大学 服装与艺术设计学院, 陕西 西安 710048)
0 引言
随着大学不断的扩招,大学生的数量急剧增加,这给大学毕业生就业带来了一定的困难[1-2]。而大学毕业就业率对于社会稳定、大学的发展都起着举足轻重的作用。因此,大学毕业生就业预测研究成为当前的热点问题[2]。
近十多年来,国内一些学者和专家以及一些研究机构对大学毕业生就业问题进行了一系列的分析,提出了许多有效的大学毕业生就业预测模型[4-6],如线性回归模型、灰色理论的GM(1,1)模型、神经网络、支持向量机等,其中线性回归模型、灰色理论的GM(1,1)模型只能描述大学毕业生就业的线性变化特点,使得大学毕业生就业预测误差相当大,无法满足大学的发展要求。神经网络虽然有比较好的非线性建模能力,但是其要求大学毕业生就业的历史数据多,使得大学毕业生就业成本高,而且大学毕业生就业历史样本实际很少,而且神经网络本身的结构比较复杂,使得大学毕业生就业预测结果不稳定[7-9]。支持向量机的大学毕业生就业预测效果要优于其他方法,是一种大数据分析技术,但是其参数影响大学毕业生就业预测结果,如何确定最优参数是关键[10]。
针对当前大学毕业生就业预测精度低、效率低等缺陷,为了获取更优的大学毕业生就业预测结果,提出基于数据挖掘的大学毕业生就业预测模型,在MATLAB 2019的平台下对大学毕业生就业预测模型的性能进行了仿真对比测试,验证了本文模型的优越性。
1 基于数据挖掘的大学毕业生就业预测模型设计
1.1 基于数据挖掘的大学毕业生就业预测模型工作原理
数据挖掘的大学毕业生就业预测模型工作原理为:首先对一个大学毕业生就业的历史数据进行收集,然后采用ACO算法确定SVM的相关参数最优值,最后SVM根据参数的最优值建立大学毕业生就业预测模型,并对将来一段时间的大学毕业生就业进行估计,如图1所示。
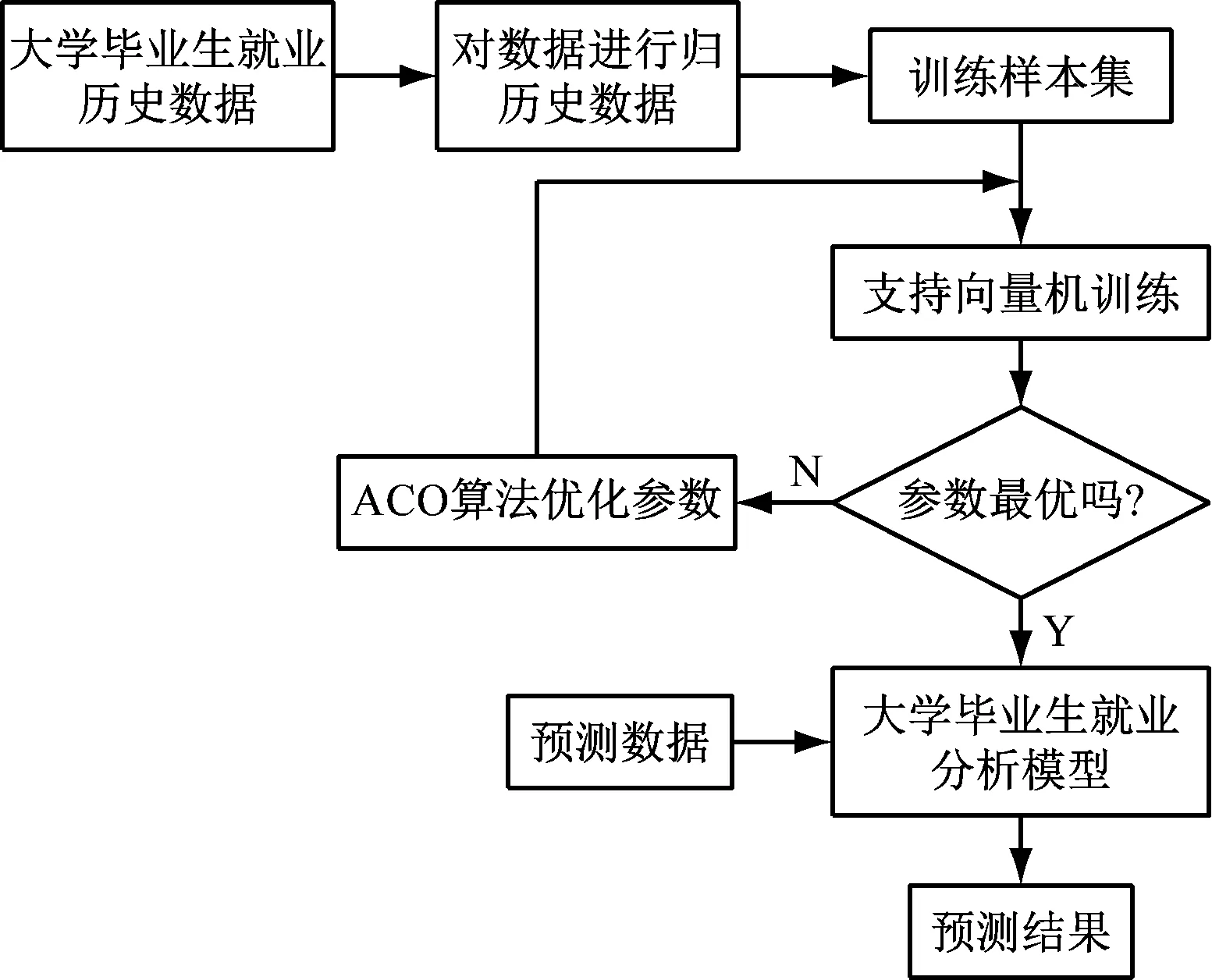
图1 大学毕业生就业预测模型工作原理
1.2 支持向量机
f(x)=ωTφ(x)+b
(1)
对式(1)进行转换,得到一个带约束的优化形式,如式(2)。
(2)
式中,C为惩罚参数;n表示历史数据的数量;ξ表示松弛因子。
引入拉格朗日乘子αi建立式(2)的对偶形式,从而建立拉格朗日方程,具体如式(3)。
(3)
将式(3)转成对偶形式,即有式(4)。
(4)
这样得到支持向量的回归估计函数为式(5)。
(5)
采用核函数k(xi,x)代替(φ(xi),φ(x)),式(5)变为式(6)。
(6)
k(xi,x)定义如式(7)。
当底板最外缘拉应力达到235 MPa时底板的剪力滞系数分布图如图13所示。此时,塑性阶段的剪力滞系数是通过数值计算的结果除以屈服应力235 MPa得到。从ANSYS中提取固端正应力结果后,此时底板最外侧几个点的正应力已经超过屈服应力235 MPa,其他大部分点均未达到屈服应力,说明在这种均布荷载作用下各点的剪力滞系数与弹性阶段剪力滞系数分布都差不多,同时截面的应力分布还处于弹性阶段的状态,模型的塑性变形不明显,主要是弹性阶段的变形。
(7)
式中,σ为核宽度。
参数σ和C对SVM的大学毕业就业分析时,它们影响大学毕业就业分析效果,采用蚁群算法对参数σ和C进行优化。
1.3 蚁群算法(ACO)
蚂蚁初始位置为Xi(xi1,xi2,…,xid),第i只蚂蚁的初始信息素计算式为式(8)。
Δτ(i)=exp(-f′(xi))
(8)
当f(xi)无限大时,信息素浓度会向零靠近,所以f(xi)进行相应的修正,具体如式(9)。
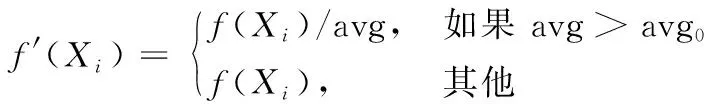
(9)
式中,avg为f(xi)的均值。
当一只蚂蚁在完成一次搜索后,根据移动规则进行下一次搜索,具体为:选择p个蚂蚁,计算它们的信息素浓度,将信息素浓度最大个体作为目标如式(10)。

(10)
式中,Xbest为上次搜索过程中的最优解。
由于信息素浓度越大,吸引程度越大,所以第i只蚂蚁向目标蚂蚁位置移动。当整个蚁群完成一次搜索后,对信息素进行更新操作,具体如式(11)。
τ(i)=(1-ρ)τ(i)+Δτ(i)
(11)
式中,ρ为信息素的挥发因子。
1.4 数据挖掘的大学毕业生就业预测步骤
Step1:选择多个大学作为毕业就业状况预测对象,并对其大学毕业就业历史数据进行采集。
Step2:大学毕业生就业与多种因素相关,如大学本身的层次、大学专业、大学所处的地理位置等,使各个大学毕业就业历史数据的值差异比较大,如果直接输入到SVM进行学习,使得SVM的训练效率低,因此对其进行归一化操作,具体为式(12)。
(12)
式中,yi,j表示第i个大学第j年的就业历史数据值;max和min分别表示整个大学毕业就业数据的最大值和最小值。
Step3:选择一部分大学毕业就业历史数据,将它们组合在一起形成大学毕业就业分析的训练样本,用于确定SVM的参数值。
Step4:将校毕业就业分析的训练样本输入到SVM,采用ACO算法确定SVM的参数最优值。
Step5:根据参数最优值,SVM重新对校毕业就业分析的训练样本学习,建立大学毕业就业分析模型,并可以对将来几年的大学毕业就业状态进行预测和分析。
2 大学毕业生就业预测的实例分析
2.1 数据来源
数据挖掘的大学毕业生就业预测模型(ACO-SVM)的性能,对其进行仿真测试,首先设置仿真测试环境,包括硬件环境和软件,在相同测试环境下,选择蚁群算法优化BP神经网络(ACO-BPNN)、传统支持向量机(SVM)、深度学习算法中的卷积神经网络(CNN)进行对比测试,以验证本文模型的优越性。采用大学毕业生就业预测精度以及建模时间作为性能评估标准。
为了使大学毕业生就业预测结果具有较强的说服力,选择全国4类大学作为测试数据,收集它们毕业就业数据,4类大学分别为985、211大学、一本大学、二本学院和大专,它们历史数据具体如表1所示。

表1 毕业就业状况预测的实验数据
没有列出影响因素,训练样本数量和测试样本数的比例为5∶1。
2.2 大学毕业生就业预测精度对比
采用4种大学毕业生就业预测模型对表1的实验数据进行建模与分析,得到4类大学的毕业就业状况预测精度如图2所示。

图2 大学毕业生就业预测精度对比
对图2的大学毕业生就业预测精度分析,可得以下结论。
(1) ACO-BPNN的大学毕业生就业预测精度最低,说明ACO-BPNN无法准确描述大学毕业生就业变化特点,导致分析误差最大。
(2) SVM的大学毕业生就业预测精度要高于ACO-BPNN,主要是因为SVM的泛化能力要强于BP神经网络,没有BP神经网络建模的限制条件,减少了大学毕业生就业预测误差。
(3) CNN的就业预测精度要优于SVM以及ACO-BPNN,因为其属于当前流行的深度学习算法,具有较好的拟合和建模能力,但是其预测效果也要差于ACO-SVM,这是因为CNN同样也存在参数优化问题,这是下一阶段要解决的问题。
(4) ACO-SVM的大学毕业生就业预测精度要大幅度高于对比模型,这表明ACO-SVM较好的克服了当前模型存在大学毕业生就业预测误差大,很好地描述了大学毕业生就业变化特点,验证了ACO-SVM的优越性。
2.3 大学毕业生就业预测效率对比
ACO-SVM的大学毕业生就业预测模型与对比模型的训练时间和测试时间如表2所示。
由表2可以看出,SVM的大学毕业生就业预测总时间最长,大学毕业生就业预测效率最低,其次为ACO-BPNN,这是因为BP神经网络的收敛速度慢,建模效率较低,大学毕业生就业预测效率最高者为ACO-SVM,加快了大学毕业生就业预测速度。

表2 预测模型的训练和测试时间对比
3 总结
为了获取更优的大学毕业生就业预测结果,提出基于数据挖掘的大学毕业生就业预测模型。对比测试结果表明,数据挖掘大学毕业生就业预测精度达到了90%以上,减少了大学毕业生就业预测误差,大学毕业生就业预测时间短,获得理想的大学毕业生就业预测结果。
