中国撤回论文的分布、原因与影响(2012-2018)
2021-12-09张约翰
张约翰
1 背景
撤稿通常在学术不端或错误损害研究的有效性、可靠性或完整性时发生,被撤回文章的数据、结论或方法不应继续被其他学者引用[1]。撤稿可帮助研究者识别存在问题的论文,节省科研试错成本。每年被撤回文章的数量呈增加趋势,对出版商和研究者提出了巨大挑战,引起学术界的极大关注[2-3]。2013-2015年在Retraction Watch数据库中记录的撤回文章源自15个国家,包括科研强国美、德、英、法。但仅考虑撤稿总量不够,还应考虑各个国家出版文章的总量[4]。若根据Scimago提供的2013-2015年各国文章总量对撤稿量进行加权,大多数科研强国并不是撤稿的主要贡献源[5]。
撤稿的原因包括错误、欺诈、政治或道德问题、违反出版道德规范等[5-6]。大部分撤稿是由于包括抄袭和重复在内的学术不端行为[4,7]。有关中国学术不端行为和撤稿问题的舆论事件表明我们社会比以往更加关注这一领域。由中国学者撰写的学术出版物数量有所增加,被撤回的出版物数量也有所增加[7-13]。从2011-2017年3月15日发表的文献看,中国学术不端行为比率(撤稿量与发表文章总量之比)排名第一[10]。尽管Scimago上记录的中国文献总量很庞大,从2011年395,431篇增加到2017年534,879篇,这仍然是一个可怕的结论。中国作者大量撤稿引起全球关注,来自中国的研究成果开始被很多人质疑[14-15]。
国内学者对中国作者撤稿的研究有相当一部分聚焦于医学领域。卜今根据PubMed数据库收录的中国作者撤稿声明,描述了中国作者在生物医学领域科技文献的失败情况以及出版不伦理行为[16];付晓霞等、郝秀原等、彭妍捷等从原因和对策两方面对2015年3月BioMedical Central大规模撤稿在内的多次撤稿事件进行反思[17-19];包靖玲等基于Scopus数据库调查2015-2017年医学领域国际期刊的撤稿声明,发现撤稿文章数量最多的为中国[20]。对中文学术期刊撤稿的研究也有一定成果。张晴等基于CNKI数据库回溯92篇撤销论文,指出学术不端引起的撤稿占67.4%,主要分布于医药卫生、工业技术和自然科学领域[21];丁媛媛根据中文科技期刊数据库、中国知网、中国数字图书馆、万方数据、中国医药数字化期刊群和中华医学会数字化期刊数据库等分析国内学术期刊刊登撤稿声明,董敏则依据万方和中国知网数据库对2013-2018年的中文科技论文进行统计描述,周志新基于中国知网数据库对中文科技期刊被撤销论文进行特征分析[22-24]。朱大明、张新庆、游苏宁、胡金富、叶方寅等通过定性经验对重大撤稿事件和撤稿现象发表讨论[25-29];范姝婕等对中国作者科学引文索引扩展版(SCI-E)收录论文的撤稿情况进行文献计量学分析[30]。综上所述,国内学者采用文献计量学方法对撤稿的研究相对聚焦于医学领域,关于中文学术期刊撤稿的研究较多;相当部分与撤稿有关的论文并非基于计量数据而是基于定性经验的;存在一些采用文献计量学方法对英文期刊撤稿情况的研究,但聚焦于中国作者在英文期刊撤稿的研究较少,缺乏系统的概述。因此,本文基于Retraction Watch网站数据库(http://retractiondatabase.org/RetractionSearch.aspx),采用文献计量法对2012-2018年间与中国有关联的撤回论文进行分析。
Retraction Watch(RW)成立于2010年8月,是一个跟踪撤稿事件、旨在帮助公众关注科学不端行为及其纠正过程的在线数据库,包含1.8万多篇可以追溯到1970年代的撤销论文或摘要[31-33]。RW涵盖面广、规模大,可以看作是记录英文撤稿的最流行和最有用的来源之一。虽然撤稿是防范学术不端的重要方法,我国还没有专业的反学术不端网站,构建已发表论文跟踪系统、发挥读者监督作用十分必要[34]。本文采用Retraction Watch数据库作为数据源,一方面可以基于其规模和涵盖面保证数据选取科学性,对中国作者在国际期刊上的撤稿情况做准确系统的揭示,一方面也期待更多基于RW这类专业撤稿记录平台的研究可以提高国内学界对专业反学术不端网站的重视,鼓励构建专业的网站或平台,打破国内外撤稿记录的信息差,促进形成健康的学术生态。
2 数据和方法
本文将RW中记录的2012-2018年撤回文章作为原始数据。2017年Retraction Watch管理员宣布:“我们的个人电子邮件提示有14,000个订阅者,日常电子邮件有1,000个订阅者。”(http://retractionw atch.com/2017/08/03/happy-birthday-retraction-watch-7-update-database/)该网站是“世界上最大的撤回文章数据库”(https://retractionwatch.com/2019/12/31/a-look-back-at-retraction-w atch-in-2019-and-forward-to-our-10th-anniversary/#more-118665)。数据集的筛选标准包括:必须是完整的撤稿;必须是源自中国的撤稿;必须是科学文献,严格地说是研究论文;所撤回文章的原发表日期应在01/01/2012和12/31/2018之间。
RW还包含大量“表示担忧”等其他记录,筛选标准可以将数据集微调到撤回的研究论文上。RW检索界面只会返回最新600条记录,提示“您的搜索返回了大量结果,仅显示600条,缩小搜索范围以查看所有结果”。因此,文章根据发布年份缩小时间间隔,通过多次检索获取并下载RW提供的HTML页面,作为计量的原始数据。一旦撤稿记录满足筛选标准,就可以通过Python标准库、csv库、re库和bs4库解析HTML页面来提取元数据信息作进一步分析,具体包括:撤回文章的标题、撤回文章的主题、出版商、出版杂志、撤稿的机构、撤稿的原因、撤回文章的作者、原始文章的DOI、是否有付费墙、文章类型、国家。
3 结果和讨论
3.1 撤稿基本情况
(1)年度趋势。2012-2018年RW数据集中,应用筛选标准之前有关中国撤稿信息的条目数为2,044,剔除“更正”等类别后共得到1,881条有关“撤回”的记录,在此基础上进一步筛选出1,553篇撤稿文章。其中,每年撤稿量的平均值是222次,与2018年的发现一致[35],即中国是撤稿数最多的国家之一。在1,881条“撤回”记录中,2012年次数最少,小于170次;2015年最多,超过350次;2014年和2015年共有约700次撤回,占37%,年度撤稿数量形成凸曲线。每年的撤回次数在变化,很难通过波动找到明确的趋势,详见图1。但如果将早期预探索中发现的年度撤稿量计算在内(2009年在800次以上,2010年在4,000次以上,2011年在2,000次以上,2012年为167次),则可以看到下降趋势非常明显。急剧下降的原因尚未可知,需要进一步探索。
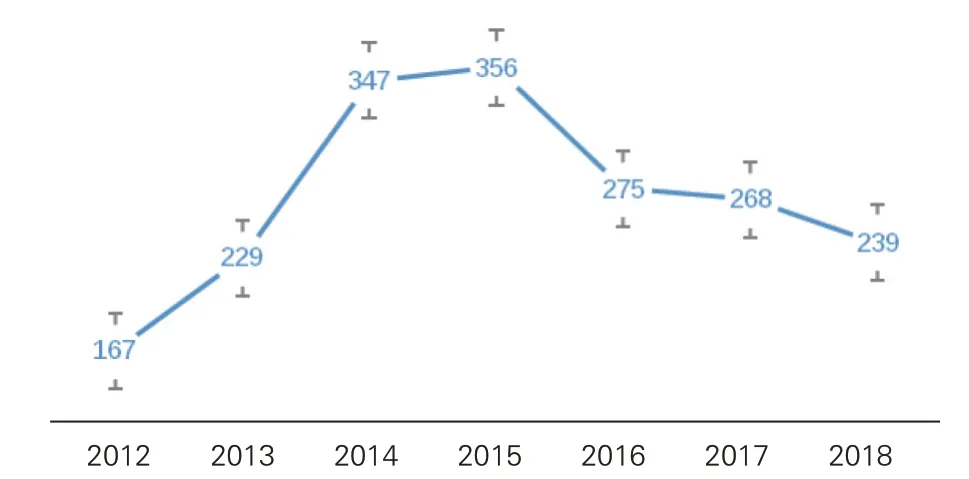
图1 中国研究人员撰写或合著文章被撤回及其有关信息的数量(2012-2018)
(2)“付费墙”文章的撤稿频率。付费墙是对在线内容实行付费阅读的模式,在学术出版领域,研究论文的阅读、下载普遍需要付费,研究者一般通过机构图书馆付费统一订阅来获取论文,若没有统一订阅则需要为单篇文章付费才能获取原文。随着开放获取期刊越来越多,无需付费、向所有人开放的无付费墙文章数量不断增加。除付费墙字段N/A(不可用)的记录以外,付费墙文章数为25篇,而非付费墙文章为691篇(占96.1%)。早期探索中的付费墙文章数量为698篇,文章总数为9,083篇,所占比例同样很小。如果撤回意味着原文章不具发表价值,开放获取论文的质量可能需要被审视。在科研共同体与Elsevier和Springer等大型出版商竞争中,这并不是好消息,只有质量不再受质疑,开放获取运动才能迈向更高的层次。
3.2 作者和来源
(1)国际合作与分布。与中国撤回文章作者合作的国家和地区分布相当广泛。合作文章数美国位居第一(140次撤回),其次是日本、巴基斯坦、英国,再次是澳大利亚(13次)、加拿大(12次)、意大利(11次)和德国(10次)。美国占比最高不足为奇,根据Scimago排名数据,美国是科研实力最强的国家,有超过68万篇文献,H指数超过2,200。但是,国际合作分布很不均衡,排名前十的国家或地区占比高达96%。Sci2 Tool的NAT(网络分析工具包)提供的原始网络摘要显示:42个节点,11个孤立节点;65条边,无自环或平行边;平均权重1.415;13个弱连通子图(11个为孤立点),最大的连通子图由23个节点组成。具体细节可以从Pajek图表中看出:荷兰、奥地利、加纳、阿鲁巴、爱尔兰、新西兰、巴西、开曼群岛、泰国、亚美尼亚和沙特阿拉伯是孤立的;一些国家组成一些小社区,如由马来西亚、巴基斯坦、埃及、西班牙和伊朗组成的社区。原网络并不是弱连通的,为了使可视化简洁且易于理解,可通过Sci2工具提取最大连通子图。
图2展示各个国家或地区的协作分布。图中的节点代表国家或地区,每个节点的面积与国家或地区出现频率相对应,连接线的粗细代表共现的频率(国际协作),每个节点的颜色表示Louvain算法划分的社区。社区内部的国家或地区具有更多的相似性和更强的协作意愿,而不同社区中的国家或地区之间存在更多的差异和较弱的关系。图2显示了在RW撤回数据集中与中国合作的国家或地区之间的关系,同一社区中的国家或地区联系更紧密。这种联系表现出的地理特征是:与中国合作的国家或地区倾向于与地理距离较近的国家或地区合作,如瑞士、德国和意大利在一个社区内;挪威和瑞典在同一社区;英国和法国,约旦、南非和土耳其在同一社区。此外,澳大利亚与法国也在同一社区,表明经济和历史因素也可能影响了社区分布。
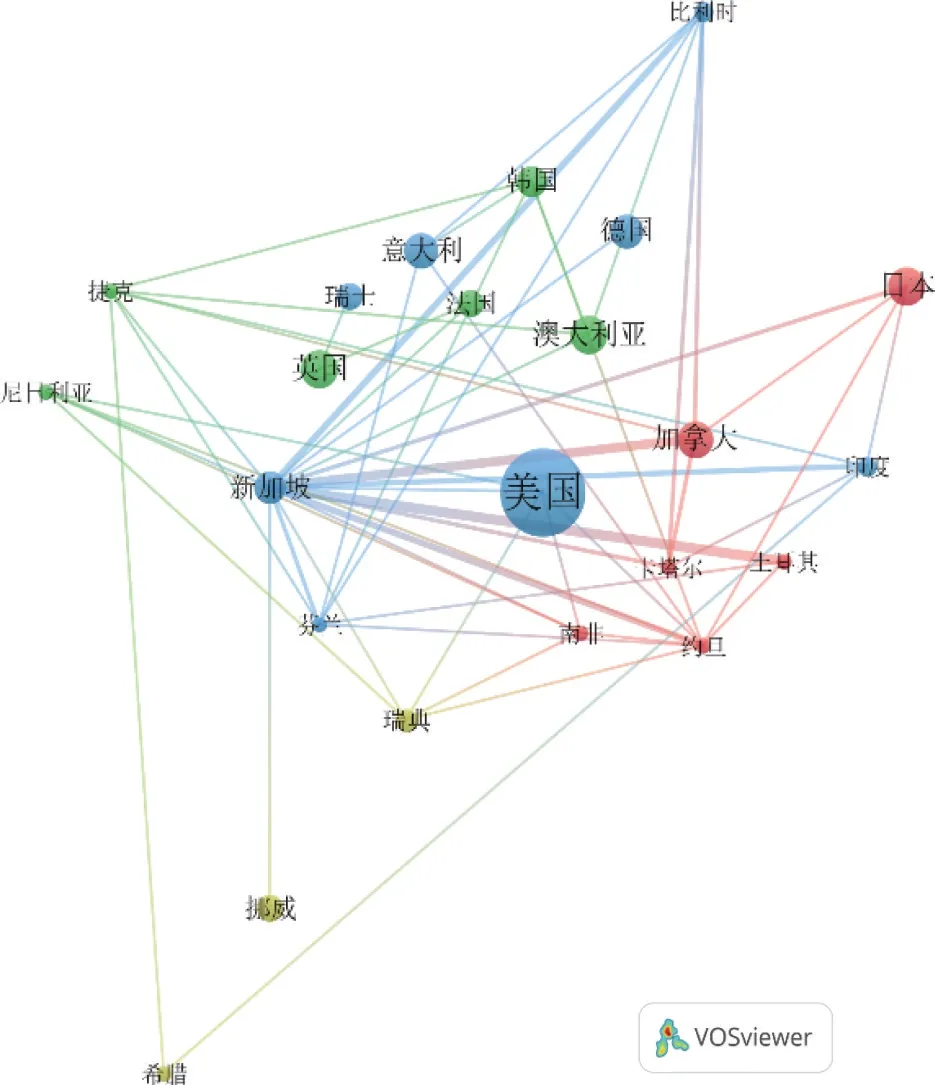
图2 中国科学论文撤稿的国际合作网络
(2)期刊来源。撤回文章来自717种期刊,其中大量期刊(495种)仅发布1份撤回通知。Tumor Biology(Tumour Biology)-Official Journal of the International Society of Oncology and Bio-Markers(ISOBM)有88篇撤回文献,占5.7%,其次是PLoSOne、Multimedia Tools and Applications和Biochemical and Biophysical Research。在撤稿最多的期刊中,没有一种是中国出版的,这与Chen等的结论一致[8]。至少撤回9篇文章的期刊有23种,发布的撤回通知约占总数30%。排名第一的期刊Tumour Biology由Springer出版。通常顶级期刊每年都会发表很多文章,包括传播和生物学方面的文章,这可能会影响它们在撤稿名单上的排名。
(3)出版商。表1列出中国作者撤稿的主要出版商,排名前三的是Elsevier、Springer和Wiley。Elsevier和Springer撤回文章量占撤稿总量的40%以上,侧面显示出其在科学出版领域的重要地位。从科学研究平等权利的角度来看,这是负面的,但在处理撤回文章方面,大型出版商可能会发挥更重要作用,其数据库足够大,也可以影响大多数存储库。
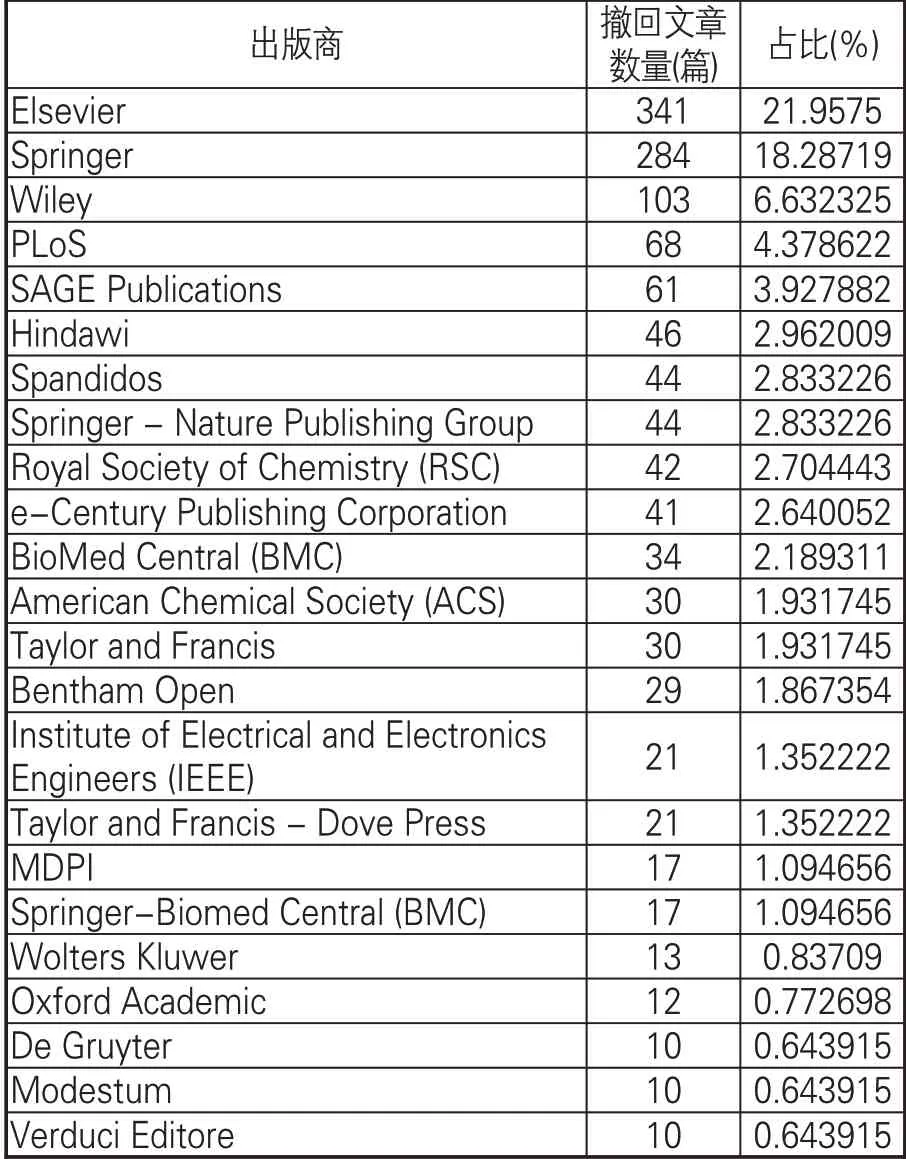
表1 撤回中国作者文章较多的出版商
(4)作者。单个作者最高撤回次数为15次,仅有两位作者的撤稿达到15次,撤稿次数大于等于10次的仅有7人,大于等于9次的仅有15人。撤稿与文章的可靠性有关,撤稿最多的作者被揭露时可能会感到不适,其科研质量也受到质疑。不过,如果不同时比较撤稿原因,这个数字也不能说明太多信息,有待进一步探讨。
(5)机构。表2列出中国作者撤回论文较多的机构,有73个机构有1篇以上的撤稿。大多数机构(1,716个)只有1份撤回通知。没有某个机构撤回的文章很多,撤回的数量很大程度上取决于中国发表文章的总量。
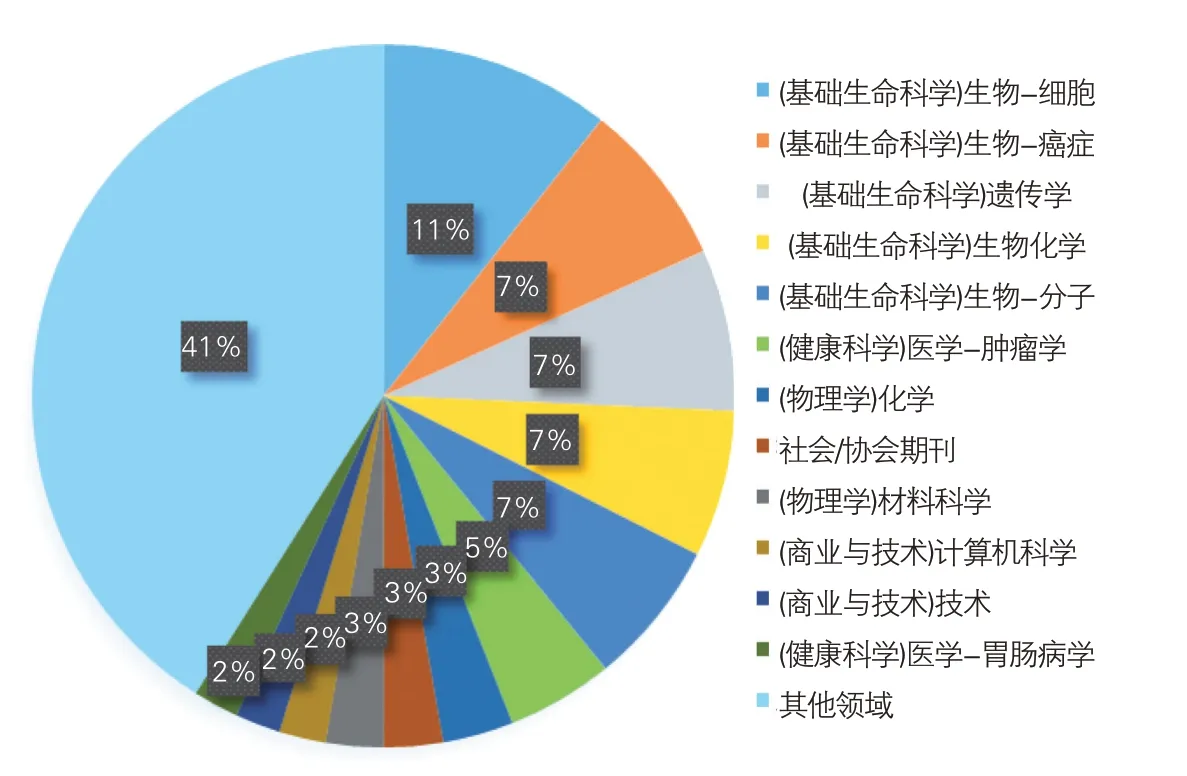
图3 各领域的撤回总数分布
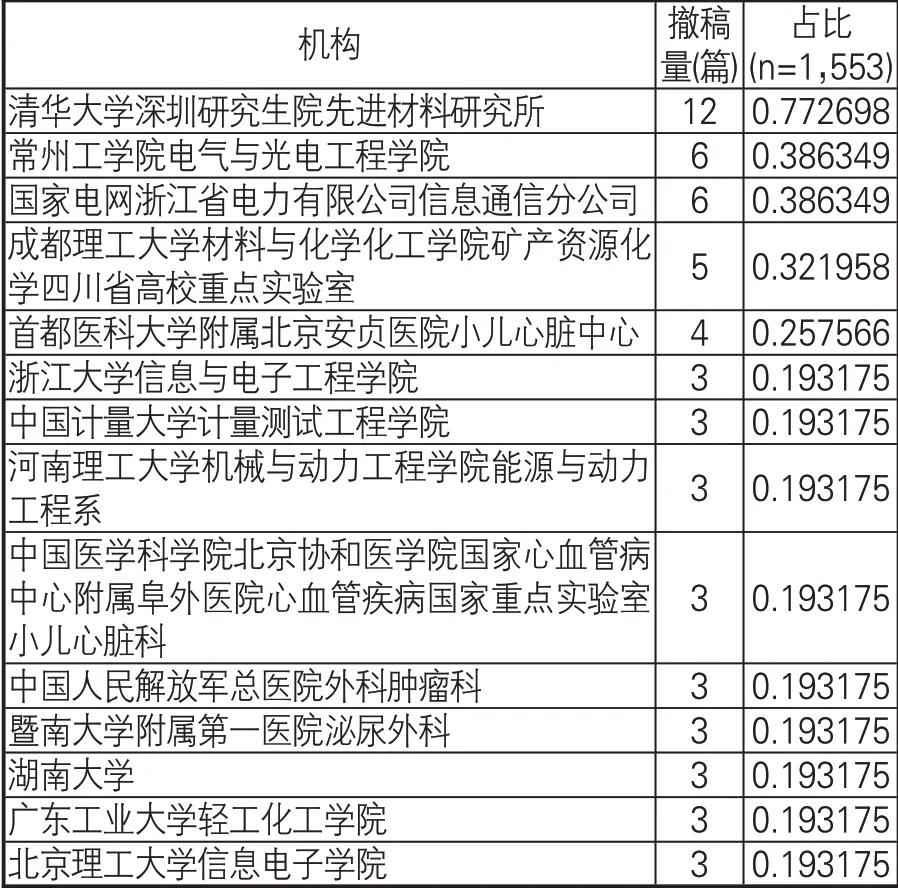
表2 撤稿较多的机构
3.3 领域
RW数据集可以识别来自不同科学领域的撤稿。生物-细胞、生物-癌症、遗传学、生物化学、生物-分子、医学-肿瘤学、化学、社会/协会期刊、材料科学、计算机科学、技术、医学-胃肠病学,这12个领域的撤稿数约占撤回总数60%(见图3)。考虑到Scimago记录的发表文章总数,这部分归因于这些领域的出版物总量很大。
3.4 原因
本文将RW标记的撤稿原因作为原因类别划分依据,每篇撤回文章至少拥有1个原因标记。与其他相关研究中含原因的撤稿记录比例相比,如Aspura等的27%[36],情况尚令人满意。最常见的原因是文章重复和图像重复(也称为“自我抄袭”),这并不奇怪,社交媒体上有关撤稿的新闻往往是关于中国文章的重复现象。中国是发展中国家,仍在追赶美国等先进国家。但是,当下数量导向的科学评估体系和寻求快速成功的社会氛围不能被忽略。
“有关数据的担忧或问题”“不当行为-官方调查”“作者不当行为”三者的比例相同。当对合法的作者权利主张存在疑问、争议或争议时,使用“关于数据的担忧或问题”;在公司法人或政府机构调查后发现不当行为时,使用“不当行为-官方调查”;当期刊、出版商、公司、机构、政府机构或作者本人声明研究犯有不当行为时,则使用“作者不当行为”。由于对数据或不当行为的担忧而撤回的文章超过四分之一,因此应重视伪造或剽窃等问题。
关于剽窃,Chaddah提出另一种观点,他称为“结果剽窃”[37]。他认为,研究人员重复已经发表的实验并获得有效数据是科学研究的共同特征。这似乎很合理:现代科学的主要特点之一是具有实证主义背景。重复实验不仅是可接受的,而且应当期待重复实验的出现以验证先前结果,这有利于科学发展。
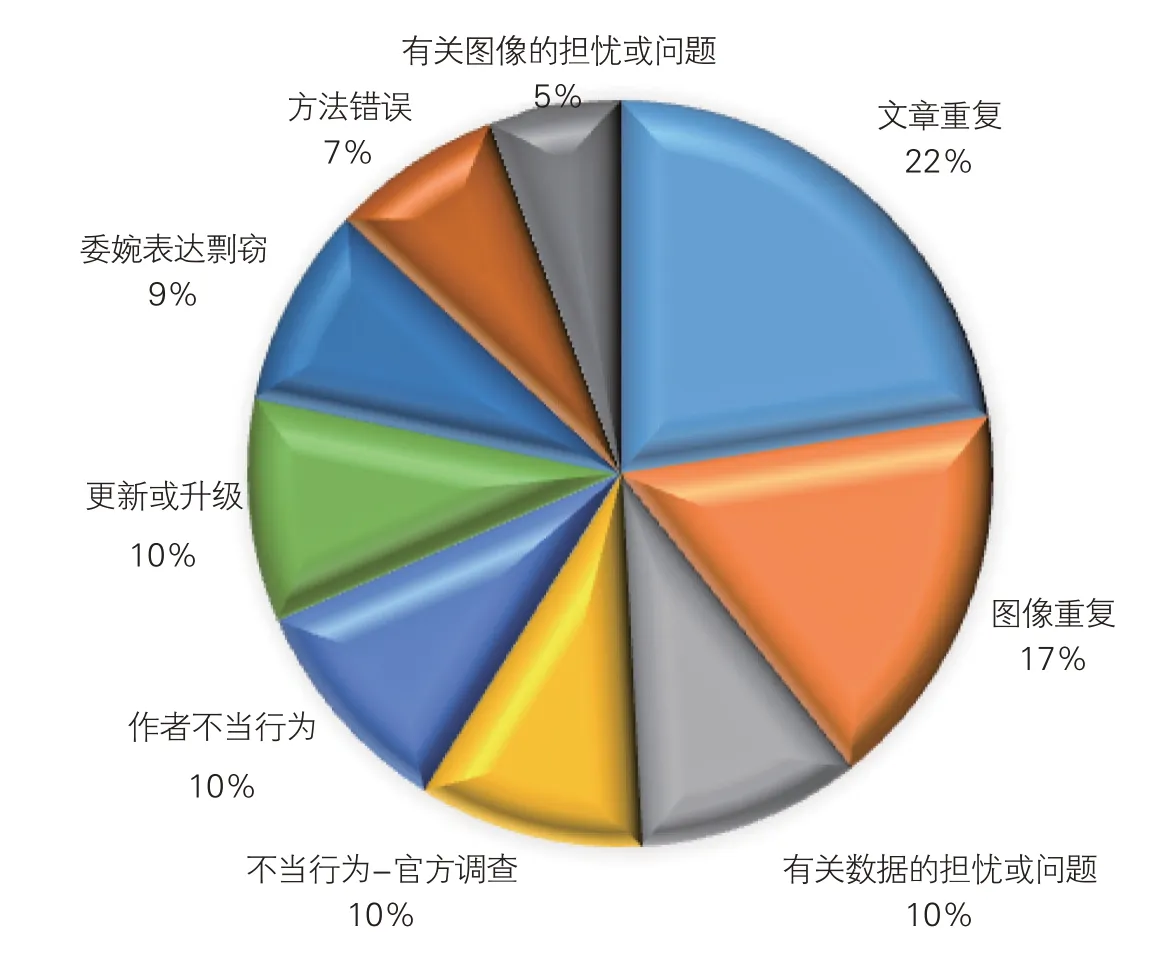
图4 中国撤回文章的各种原因
检测软件不仅可以避免剽窃,也易于检测重复度。此外,随着机器学习的快速发展,检测图像的重复变得更准确、方便和快速。人工智能可以提高软件性能,并增加欺诈难度。由于不当行为而导致的撤稿影响广泛,社会已经注意到有必要重建科学规范。这呼唤更多的研究来揭示这些问题在科研共同体中的重要性,而本研究是回应之一,详见图4。
从占比较高、统计意义更显著的“(基础生命科学)生物化学”“(基础生命科学)生物-癌症”“(基础生命科学)生物-细胞”“(物理学)化学”4个领域看,出现比例最高的撤稿原因是“文章重复”,其在生物-癌症领域占比最高(44%)。“委婉表达剽窃”在生物化学领域和化学领域占比较高,分别为18%和15%,明显高于在生物-癌症、生物-细胞领域的占比(分别为3%、8%)。生物-癌症领域占比第二高的撤稿原因是“图像重复”,占27%,而“图像重复”在其他3个领域的占比仅为16%左右。“有关数据的担忧或问题”在生物化学、生物-细胞和化学领域均在15%上下浮动,但在生物-癌症领域的占比格外低,仅为7%。“有关图像的担忧或问题”与“方法错误”两原因在4个领域撤稿中的占比差距不大。在文章所分析的4个领域中,撤稿原因具有一定的相似性,内部却有较为明显的差异,相较而言生物-癌症领域的“图像重复”撤稿原因十分突出。
3.5 撤回文章的影响
撤回文章通常由于其撤稿而价值不高,使用引文分析法对其进行评估可能局限性比较明显,为此本文尝试使用一种基于公众关注的方法作进一步研究。Altmetrics是与传统基于引用的度量互补的计量方法和定性数据。来自网络的Altmetrics数据源可以显示全世界讨论和使用学术成果的频率。它是一种对注意力的记录,也是评估影响的指标(https://www.altmetric.com/about- altmetrics/whatare-altmetrics/)。Altmetrics详细信息页面为用户提供了注意力分数,以表示该文档被提及的频率。本文使用Altmetric Details Page API来获取基于DOI的撤回文章注意力得分,以评估撤回文章的影响力。
大部分撤稿的注意力得分是不可用的(770篇),小部分文章(77篇)的注意力得分超过10。如表3所示,3篇最具影响力的文章是《世界范围内宗教与儿童利他主义之间的消极关联》《大气中O2和CO2组成变化对海洋热量吸收的量化》《完全锁定状态下基于脑机接口的通信》,注意力得分超过2,000。高注意力得分的撤回文章会带来恶劣影响:《柳叶刀》刊登Andrew Wakefield撰写的有关自闭症和MMR(麻疹、流行性腮腺炎和风疹)疫苗的文章(https://www.thelancet.com/journals/lancet/article/PIIS0140 673697110960/fulltext),注意力得分超过4,000,损害了公众对该疫苗的信心。文章发表后,MMR疫苗的接种率显著下降,文章撤回后接种率也没有反弹。基于数据实证的Altmetrics能够解决传统计量方法时间滞后的问题,可以用来检测具有重大影响力的撤回文章,使研究人员和政府官员可以有针对性地进行处理。本研究中高注意力得分的文章数量不多,未来研究中也需要使用更多定性方法。宗教与儿童、气候变化、脑机通信和基因编辑等主题受到公众更多关注,这些领域撤回文章的负面影响更大。科学文献在学术共同体内具有学术影响力,但社会影响力也不可忽视。2020年11月发表在Nature Communications上的The association between early career informal mentorship in academic collaborations and junior author performance分析导师和男性学生一起工作比和女生学生一起工作获益更多(https://www.nature.com/articles/s41467-020-19723-8),引发广泛讨论,许多女性科学家表示强烈反对,该文章最终在12月被撤回。为跟踪热点领域文章的社会影响力,研究机构可以大规模监测注意力得分变化曲线,在文章撤回或引发广泛讨论时做出针对性的释疑或处理,尽可能及时有效地消减其负面影响。

表3 Altmetrics注意力得分最高的文章(超过100)
4 结语
本文研究学术出版界与撤稿相关的几种现象。从Retraction Watch检索的数据集来看,2012-2018年的中国的撤稿数量变化不大,呈现先增后减趋势,2015年达到356篇峰值。与中国研究人员数量和每年大量的出版物相比,撤稿量看起来较少,但当涉及“撤稿”这不应发生的情况,这些数字值得注意。同时,在可用的统计样本中大多数的撤稿都是没有付费墙的文章,对开放获取来说此现象令人担忧,是未来重要的研究课题。
机构和作者方面的撤稿分布相对均匀,而国家、期刊和出版商方面则相反。撤稿协作网络显示出一定的地理特征。随着撤稿引起国内外广泛关注,科研共同体应予以重视,尤其是撤稿所占比例较大的生物、化学和医学领域。此外,科研评估体系需要改革。就目前的度量标准而言,存在“出版或灭亡”事实,只有注重质量的评估系统才能解决过量撤稿之类的问题,而步调适中也可以方便研究人员寻求长期成果和更深入的研究。
根据Altmetrics数据,尽管大部分撤回文章的注意力得分较低,但注意力得分很高的文章警告:研究文章不仅意味着“报告一个结果”或“个人文章总量加一”,在快速沟通的时代,撤回一篇不值得出版的文章会造成很多麻烦。
本研究存在一定局限性:一是时间粒度较粗,仅提取年份参数,未提取月份日期信息;二是没有分析从文章发表到撤稿所跨的时长,仅收集原始论文的发表年份;三是数据源的覆盖范围有限,仅使用RetractionWatch数据库,Grieneisen和Zhang的研究涵盖JSTOR、Pubmed、Google Scholar和RW等42个数据库[38];四是在作者分析过程中,使用名称作为识别符,存在潜在的重名问题。名称重复项应给予消歧以确保关键字可以代表确切实体,进一步的研究可以尝试使用ORCID和基于深度学习的方法来解决该问题。此外,还应该通过添加年龄和性别信息等来丰富对作者的分析,更详实地描绘作者画像。
