术语抽取方法研究
2021-12-09郑坤薛明晰纪传胤
郑坤 薛明晰 纪传胤
中国人民解放军32180部队 北京 100012
引言
术语抽取技术是信息处理中的一个很重要的课题。术语集中体现和负载了一个学科领域的核心知识,术语的变化在一定程度上反映了一个学科领域的发展变化。术语抽取应用在本体构建、机器翻译和语义检索等诸多研究领域。因此,研究出一套自动、高效和高可移植性的术语抽取方法具有十分重要的意义。
1 概述
术语是随着人类对各个研究领域的不断探索和研究而逐步形成的,用来记录或标记在此过程中积累沉淀的专业知识概念,通常表现形式为动词、形容词、介词和名词构成的词或词组(又称短语)。
1.1 术语的定义
“术语”目前还没有统一明确的定义,但是中外不少学者从语言学或者术语学角度给出了自己的观点。本文列举一些国内外比较通用的术语定义[1]。Sager认为“terms are the linguistic representation of concepts”,即“术语是概念的语言表征”。冯志伟将术语定义为“通过语音或文字来表达或限定专业概念的约定性符号”。《术语工作原则与方法》中写到“术语是专业领域中概念的语言指称”[2]。以上几种术语的定义虽然角度和内容各有不同,但我们不难看出,术语与特定领域中的概念之间存在着紧密的联系。
1.2 术语抽取效果的评价
目前还不存在统一的术语抽取效果评价方法,常见的术语抽取结果评价方法有三个,准确率(Precision)、召回率(Recall)和F值(F-Measure或F-Score)。在某个领域语料上,术语抽取结果统计信息如表1所示。

表1 术语抽取结果统计表
以上结果统计时需要参照一个标准术语表(golden standard)[3]。设标准术语表为ST,提取出的术语集合为T,则被抽取出的术语个数为:
准确率是衡量术语抽取的准确程度,计算公式为 :
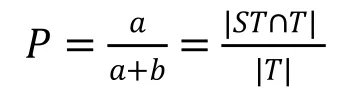
召回率是衡量术语抽取的全面程度,计算公式为:
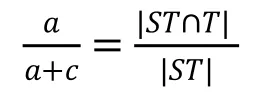
F值是综合考虑了准确率和召回率,计算公式为:
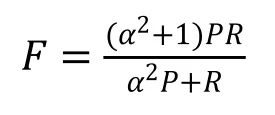
其中, 是可调节参数,常使用的值为0.5,1,2。当 时,准确率和召回率的权重相同;当时,准确率的权重较高;当 时,召回率的权重较高。
以上几种评价方法各有特点,在实际的术语抽取工作中,根据术语抽取方法的特点以及不同的应用场景会选取不同的评价方法。
2 术语抽取方法
术语自动抽取的研究已长达20多年,20世纪90年代国外就有了一批术语自动抽取系统。国内的研究则集中在近10年,主要是在国外研究基础上对已有方法进行改进。
早期的术语自动抽取中使用的大多是基于语言学知识。后来,随着统计自然语言处理技术的快速发展,术语抽取系统中逐步引入了一种或多种统计策略。而随着隐马尔可夫模型(Hidden Markov Model)、条件随机场(Conditional Random Fields)等机器学习算法在词性标注、命名实体识别等领域的使用,结合机器学习算法的方法也被引入到术语的抽取研究中。总的来说,目前术语自动抽取方法主要分为6大类[4]:①基于规则的方法;②基于统计的方法;③基于主题模型的方法;④基于深度学习的方法;⑤基于词图模型的方法;⑥基于传统机器学习的方法。
2.1 基于规则的方法
基于规则的方法主要使用术语的词语词性以及词法模式等语言知识,利用这些知识可以从语料中自动抽取出术语。
这类方法基于已有的术语集以及领域特点进行规则总结,在准确率上有一定的优势。但该类方法的可移植性很差,即不同的语言、不同的领域、不同的语料集,语言规则各不相同,需要根据具体情况制定。
2.2 基于统计的方法
基于统计的方法以统计学理论为基础,利用语料库中的分布统计属性来识别术语。经常使用到的统计方法可以分为两大类:一类衡量词或词组的领域性,如词频(Frequency)、TF-IDF值、领域相关性(Domain Relevance)和领域共识(Domain Consensus)等;一类衡量词组的单元性,如互信息(Mutual Information)、对数似然比(Log-Likehood Rate)等[5]。
2.3 基于主题模型的方法
主题模型是以无监督学习方式对文本集合的隐含语义进行聚类的概率模型,旨在根据主题描述文本,确定每个文本与哪些主题相关以及每个主题由哪些单词(或短语)构成。事实上,每个主题可以表示为一组经常出现的单词(或短语)集合,该组单词按照对主题的相关程度降序排列。
基于主题模型自动抽取方法的理论基础:大多数术语可以表示成特定领域子主题相关的概念,最新研究结果表明,在文档集合中划分主题,然后根据主题抽取术语,可以提高自动术语抽取的质量。基于主题模型的术语抽取的基本步骤如下:①使用主题建模技术(例如聚类,LDA)将目标语料库映射到由多个主题组成的语义空间;②词的主题概率分布来对术语候选词进行评分。
2.4 基于深度学习的方法
基于深度学习的自动术语抽取方法主要结合最新的深度学习技术来进行自动术语的抽取,是一种数据表示的特殊机器学习方法,可解决抽取术语中人工挑选最佳特征工程的问题。其基本思想是:通常将候选术语或整个句子的词嵌入表示(word embedding representation)作为输入,喂给特定的深度学习模型(例如深层神经网络DNNs、深层信念网络DBNs、递归神经网络RNNs、深层递归神经网络DRNNs),然后由多个处理层组成的深度计算模型学习出具有多个抽象级别的候选术语表示,最后对该表示进行术语类别划分[6]。
近年来,深度学习技术为各种NLP任务提供了多种解决方案以及接近专家水平的准确率。因此,深度学习模型在自动术语抽取任务中得到了应用。
基于深度学习的术语抽取步骤:
获取文本关键词数据库,文本关键词数据库中包含若干组文本和其对应的关键词;
使用word2vec将每组文本和其对应的关键词转化为词向量;
使用词向量形式的文本和其对应的关键词来训练循环神经网络:
循环后,对于新的文本,利用训练后的循环神经网络来进行关键词的提取神经网络训练完成。
基于深度学习的自动术语抽取方法主要利用深度学习模型来抽取术语。该方法无须人工筛选术语特征,减少了昂贵的人工成本,并有助于将候选术语和上下文信息结合起来,以词嵌入向量表示融合更多类型的特征,从而达到较好的术语抽取效果,尤其适合超大文档集合。但该方法的缺点也很明显,依赖于复杂的深度学习模型,需要非常大量的标注数据或标注句子(对应序列标注方法)以及较长的训练时间,且模型的跨领域泛化能力较弱。
2.5 基于词图模型的TextRank算法
基于图的自动术语抽取方法是最近几年开始在术语领域流行的一类无监督抽取方法。该类方法的灵感来源于PageRank中网页重要度的排序方。2004年,Mihalcea等人最先将 PageRank思想应用于自然语言处理领域,提出可以抽取关键单词的TextRank方法。它利用一篇文档内部的词语间的共现信息(语义)便可以抽取关键词,它能够从一个给定的文本中抽取出该文本的关键词、关键词组,并使用抽取式的自动文摘方法抽取出该文本的关键句。关键字的抽取就是从文本种确定一些能够描述文档含义的术语的过程。
2.6 基于传统机器学习的方法
基于传统机器学习的方法包括了SVM、朴素贝叶斯等有监督学习方法,以及K-means、层次聚类等无监督学习方法。在此类方法中,模型的好坏取决于特征提取,而深度学习正是特征提取的一种有效方式。由Google推出的Word2Vec词向量模型,是自然语言领域中具有代表性的学习工具。它在训练语言模型的过程中将词典映射到一个更抽象的向量空间中,每一个词语通过高维向量表示,该向量空间中两点之间的距离就对应两个词语的相似程度。
Word2Vec词聚类文本关键词抽取方法的主要思路是对于用词向量表示的文本词语,通过K-Means算法对文章中的词进行聚类,选择聚类中心作为文章的一个主要关键词,计算其他词与聚类中心的距离即相似度,选择topN个距离聚类中心最近的词作为文本关键词,而这个词间相似度可用Word2Vec生成的向量计算得到。
3 结束语
随着网络空间中所蕴含的文本数据量呈指数级增长,从大型文本集合中抽取出描述某一特定领域(例如科技文献、社交推文等领域)的术语是文本挖掘和信息抽取的首要步骤,也是本体构建、文本分类、文本摘要、机器翻译、知识图谱等领域的关键基础问题和研究热点。总体看来,现有的术语抽取方法相比于研究早期已经有了很大的进步,其中部分方法已经取得了不错的效果,有一定实际应用价值。但是,现有术语自动抽取技术还不够成熟,未来的术语抽取研究工作可以进一步完善术语抽取的理论体系,在现有的方法基础上进行改进,借鉴其他领域的成功经验,不断探索和研究新的方法,针对具体的应用领域或场景进行针对性的研究。

