定制芯片行列“新人”:脸书自研机器学习芯片,用于内容推荐及视频转码
2021-12-07
近年来,不少科技公司开始自主研发计算机芯片,旨在节省服务器成本,并提高机器学习模型的处理和训练效率。
据悉,脸书也加入了这一行列,并正在为其数据中心自主开发一套定制芯片。
其中,一个芯片处理器用于优化视频转码,或进一步提升其用户观看视频的体验;而另一个芯片处理器将用于内容推荐等机器学习任务。
这样一来,脸书将逐渐减少对外部芯片制造商的依赖,比如英特尔、高通和博通等;另一方面,由于脸书数据中心的碳足迹处于不断增长的趋势,转向定制芯片可以有效帮助其减少碳足迹。
此外,脸书并不打算让自研芯片完全取代原本的芯片处理器,新芯片将与其目前正在使用的第三方处理器一起运行。
定制芯片并不是一个新命题,比如,自2016年以来,谷歌一直拥有用于机器学习的TPU(Tensor Processing Unit)定制芯片。该芯片正在为Google的许多应用程序提供支持,包括用于提高搜索结果和街景相关性的人工智能系统RankBrain,进一步提高了谷歌地图导航的准确性和质量。
值得一提的是,在与围棋世界冠军李世石的对弈中,由TPU提供支持的谷歌DeepMind AI程序以4:1的总比分获胜。
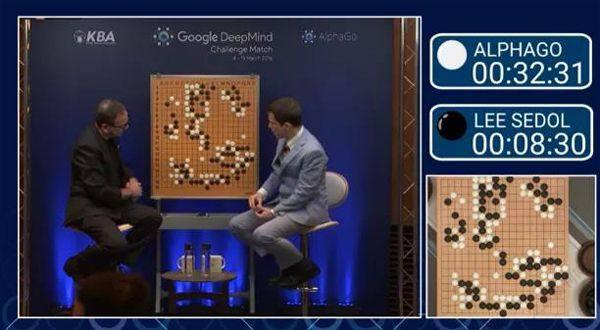

2020年12月,据外媒报道,微软也在为其Surface设备和云基础设施开发内部的ARM芯片处理器,并开始自研用于数据中心的芯片。
一直以来,微软的Azure云服务都是使用英特尔的处理器来驱动。虽然Surface设备在PC市场中所占的份额相对较小,但微软开始自研芯片的这一举动仍对英特尔造成一定打击,致使其股价在该日收盘前下跌约6.3%。
脸书表示,他们一直在与芯片合作伙伴共同探索提高计算性能和能效水平的方法。关于未来的计划,目前尚未有更多可公布的新讯息。
事实上,对脸书来说,涉足定制芯片并不是一件容易的事,不过此前该公司已经进入半定制芯片领域。
2019年,脸书宣布正在开发一种用于视频转码和推理工作的专用集成电路(ASIC)。
据了解,脸书每月需为超过27亿用户提供应用和服务。为支持如此庞大的用户量,该公司设计并构建了先进且高效的系统来扩展其基础设施。
然而,随着工作负载的增长,仅由传统的通用处理器为用户提供服务已远远不够。在脸书看来,或许只有开发新的专用加速器和整体系统级解决方案,才能进一步提高系统的性能、功率和效率。
因此,脸书与其他公司合作开发了分别面向人工智能推理优化、人工智能模型培训和视频转码的解决方案。
2019年3月14日,脸书宣布推出用于AI模型培训的“Zion”平台、用于AI推理优化的专用集成电路“Kings Canyon”以及用于视频转码的“Mount Shasta”。
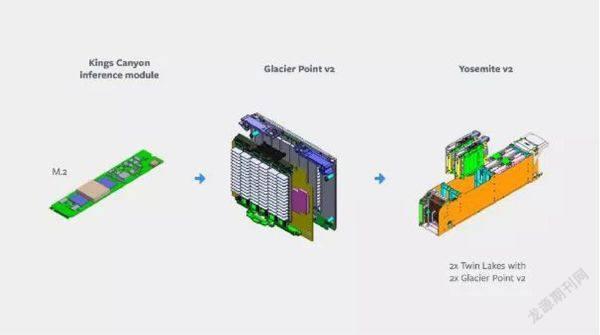
脸书用于人工智能推理解决方案的构建块
其中,作为脸书的下一代训练硬件平台,“Zion”平台具有强大的计算能力。在进行AI模型培训的过程中,不仅能够有效处理CNN、LSTM和SparseNN等一系列神经网络,而且可提供高内存容量、高带宽以及灵活的高速互连,以支持脸书的关键工作负载。
需要注意的是,在脸书训练工作负载增加的同时,其推理工作负载也在不断增加。而脸书当前使用的标准CPU服务器由于很难继续扩展,因此并不能跟上人工智能推理优化的进程。基于此,脸书与多个合作伙伴合作开发了可在其基础设施中部署和扩展的推理ASIC。
据了解,该推ASIC拥有四个主要组成部分,分别为国王峡谷推理M.2模块、双湖单路服务器、Glacier Point v2载卡、优胜美地v2机箱。这些组成部分利用已经发布到OCP(Open Compute Project,开放计算项目)
的现有构建块,加快了开发时间且依靠其通用性降低了风险。
据统计,脸书的平均直播数量每年都在翻倍增长。尤其自2018年8月在全球推出以来,Facebook Watch服務的月观众人数已超过4亿,每天约有7500万人使用。
针对观众不同的可用互联网连接,脸书生成了多种输出质量和分辨率(或比特率)来优化视频观看,这一过程称为转码。要完成此转码过程需要大量密集型的计算,而通用CPU的效率远远不及脸书视频扩展基础设施的增长速率。
因此,脸书与其芯片供应商Broadcom和Verisilicon合作设计了针对转码工作负载进行优化的定制ASIC。这其中包含用于转码工作流程每个阶段的专用芯片,能够支持分布在不同数据中心位置的异构硬件设备,平衡视频转码的工作负载。
自研芯片的势头正逐渐扩大,整个科技行业的芯片布局是否会因此发生变化?目前仍需继续观望。(摘自美《深科技》) (编辑/克珂)
