东亚人群族源推断SNP Panel分析
2021-12-07贾振军高春芳钱尊磊刘卓汤强苑美青
贾振军,高春芳,钱尊磊,刘卓,汤强,苑美青
1.中国人民公安大学侦查学院,北京 100038;2.中国人民公安大学警体战训学院,北京 100038;3.公安部物证鉴定中心 法医学遗传学公安部重点实验室,北京 100038
目前,族源推断研究是人类遗传学和法医学的研究热点[1-6]。在法医学领域,犯罪现场重要生物物证的族源推断信息可以为警方提供生物样本来源的群体信息。此外,对于痕量的脱落细胞及腐败降解的生物样本,SNP 试剂盒比STR 试剂盒具有更好的识别能力[6-15]。目前,根据国内外学者的研究,全球人口可以被分为5~10 个族群,其中包括亚洲人群[7-10]。公安部物证鉴定中心李彩霞团队进一步把亚洲人群分为3 个亚群,分别是北亚、东南亚和东亚人群[13]。此外,复旦大学金力、李士林团队[5,14]对东亚人群及族源推断方法进行了研究;四川大学侯一平、王正团队[15-16]在东亚人群研究中不断加入少数民族数据。东亚具有16亿人口,占全球人口的四分之一。为了更好地区分东亚人群,本课题组收集了国内外包含东亚人群的参考文献,并查询各大基因库,获得SNP 位点及人群数据。经过分析,发现耶鲁大学KIDD 教授的55 SNPs试剂盒[10,12]和加利福尼亚大学戴维斯分校SELDIN 教授的128 SNPs 试剂盒[17]在亚洲人群中的应用最为广泛。故本研究主要以这两个试剂盒中的170 个SNP位点(170 SNP Panel)为基础收集数据,对东亚人群进行初步研究,分析东亚人群细分亚群数量以及每个SNP 位点在东亚人群中的识别能力。此外,本研究在170 SNP Panel的基础上,精简SNP位点数量,以建立兼具东亚人群族源推断功能和个体识别能力的SNP Panel,同时检测拉萨藏族、南方汉族、北方汉族人群的SNP位点数据,验证新的Panel分群的准确性。
1 数据与方法
1.1 数据收集
在170 SNP Panel的基础上收集东亚人群的检测数据[18]。东亚人群数据来自三部分:(1)耶鲁大学KIDD教授建立的法医基因数据库(The redesigned Foren⁃sic Research/Reference on Genetics-knowledge base,FROG-kb)[19];(2)千人基因组计划项目(1 000 Genomes Project,1KGP)[20];(3)文献数据[5-19]。数据信息见附表1。最终本研究获得了包含1 922 个个体、30 个人群的170 SNP Panel的分型数据。
1.2 SNP位点的筛选方法
经过本课题组前期对170 SNP Panel 在东亚人群中的初步分析,发现一些SNP位点在东亚人群的识别能力较差或群体间遗传分化指数(Fst)较小,甚至有些SNP 位点在东亚人群中没有多态性。为了获得一个在东亚人群中既可以进行族群分析,又可以进行个体识别的SNP Panel,本研究按照以下3 个步骤进行筛选:首先,根据附表1中170 SNP Panel在东亚人群中的遗传学参数,筛选出个体识别率(discrimination power,DP)大于0.5的位点。第二,筛选在东亚人群中具有较好的亚群间差异性的SNP位点,为了更好地反映群体间差异,首先对30个人群的170 SNP Panel用斯坦福大学Pritchard 实验室开发的STRUCTURE 软件进行分析,30 个人群被很好地分为5 个亚群,计算5 个亚群间的Fst值(附表2),筛选出Fst值>0.02 的SNP位点。经过上述两步筛选,得到52 个SNP 位点。最后,使用R 3.0.1 软件对52 个SNP 位点进行聚类分析,删除提供重复信息的SNP 位点,最终获得45 个SNP位点(45 SNP Panel)用于后续研究。
1.3 45 SNP Panel在东亚人群族源分析中的效能验证
分别根据45 SNP Panel 与170 SNP Panel 在东亚30 个人群中的数据,使用STRUCTURE 2.3.4 软件分析族源关系,基于45 SNP Panal 的群体数据采用热图及主成分分析(principal component analysis,PCA)分析族源关系。基于不同人群中的基因频率,采用R 3.0.1软件pheatmap包进行热图分析,采用SPSS 20软件(美国IBM 公司)[21]进行PCA 分析,抽取第一、二、三主成分,3 个主成分采用Minitab 16 软件(美国Minitab 公司)进行绘图。STRUCTURE 软件分析的参数设置为10 000 burnins和10 000 MCMC,混合模型,K值设置为3~10。
1.4 45 SNP Panel验证族源关系
采用基于荧光标记单碱基延伸的分型技术——SNaPshot 技术,检测50 个拉萨藏族样本的45 SNP Panel 的分型。选择5 个北京汉族样本和5 个拉萨藏族样本作为测试样本,检测45 SNP位点的基因型,并计算10个样本在5个亚群中的似然率[13]。
2 结果
2.1 遗传学参数
170 SNP Panel 在30 个人群中的遗传学参数见附表1。根据附表1,170 SNP Panel 的DP 值最小为0.001 1,最大为0.661 6,平均值为0.472 1;45 SNP Panel 的DP 值最小为0.503 7,最大为0.661 6,平均值为0.5956。170 SNP Panel的父权指数(paternity index,PI)值最小为0.500 0,最大为1.061 3,平均值为0.773 7;45 SNP Panel 的PI 值最小为0.706 3,最大为0.991 6,平均值为0.868 8。
2.2 族源信息
2.2.1 STRUCTURE分析
如图1 所示,SELDIN 教授的128 SNPs 试剂盒和KIDD 教授的55 SNPs 试剂盒包含的170 SNP Panel把30 个东亚人群分为5 个亚群,分别是:亚群1,哈萨克族(KAZ)、维吾尔族1(UIG)、维吾尔族2(XJU)、青海藏族(QTB)、蒙古查腾族(TSA)、蒙古国人群(OMG)、内蒙古人群(IMG);亚群2,日本人群(JPN)、东京日本人群(JPT)、韩国人群(KOR)、北京汉族(CHB)、旧金山中国人群(HCS)、南方汉族(CHS)、台湾汉族(CHT)、客家人群(HKA)和新加坡汉族(HNS);亚群3,宁夏回族(NXH)、成都藏族(CTB)、凉山藏族(LTB)、康巴藏族(KHG)、羌族(QMR)、白马藏族(BQY)和凉山州彝族(LYI);亚群4,云南傣族(CDX)、越南人群(KHV)、老挝人群(LAO)、柬埔寨人群(CBD)和新加坡马来西亚人群(MLS);亚群5,台湾雅美族(AMI)和台湾泰雅族(ATL)。

图1 170 SNP Panel在30个东亚人群中的STRUCTURE分析图谱Fig.1 The STRUCTURE plot of 170 SNP Panel of 30 East Asian populations
45 SNP Panel对30个东亚人群的分组信息(图2)与170 SNP Panel的分组信息基本一致。

图2 45 SNP Panel在30个东亚人群中的STRUCTURE分析图谱Fig.2 The STRUCTURE plot of 45 SNP Panel of 30 East Asian populations
2.2.2 PCA结果
通过对30个东亚人群中45 SNP Panel的频率进行PCA,分析结果见图3。根据3个主成分,30个人群可以分为5组。第1组:哈萨克族、维吾尔族1、维吾尔族2、青海藏族、蒙古查腾族、蒙古国人群、内蒙古人群聚集在一起,其中内蒙古、蒙古国人群与其他5 个人群相距较远;第2组:日本人群、东京日本人群、韩国人群、北京汉族、旧金山中国人群、南方汉族、台湾汉族、客家人群和新加坡汉族聚在一起;第3 组:宁夏回族、成都藏族、凉山藏族、康巴藏族、羌族、白马藏族和凉山州彝族聚在一起;第4 组:云南傣族、越南人群、老挝人群、柬埔寨人群和新加坡马来西亚人群聚集在一起;第5组:台湾雅美族和台湾泰雅族聚集在一起。

图3 45 SNP Panel在30个东亚人群中的PCA图谱Fig.3 The PCA plot of 45 SNP Panel of 30 East Asian populations
2.2.3 热图分析结果
通过对30个东亚人群的45 SNP Panel进行热图分析,结果见图4。北京汉族、旧金山中国人群、南方汉族、台湾汉族、客家人群和新加坡汉族聚在一起后,又与两个日本人群和韩国人群聚在一起。云南傣族、越南人群、老挝人群聚在一起后又与柬埔寨人群和新加坡马来西亚人群聚集在一起。宁夏回族、成都藏族、凉山藏族、康巴藏族、羌族、白马藏族和凉山州彝族聚在一起后,又与内蒙古人群、蒙古国人群聚在一起。哈萨克族、维吾尔族1、维吾尔族2、青海藏族4个人群聚在一起后又与蒙古查腾族聚在一起。台湾雅美族和台湾泰雅族聚集在一起。
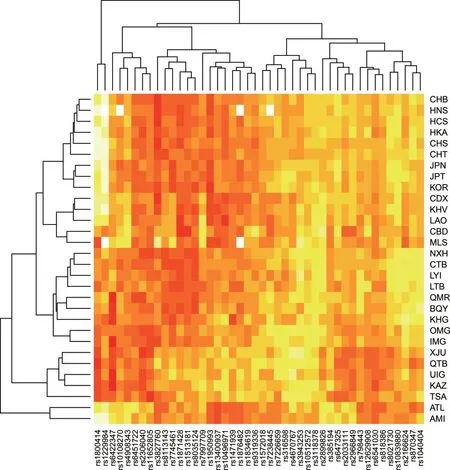
图4 45 SNP Panel在30个东亚人群中的热图分析Fig.4 The heatmap analysis of 45 SNP Panel of 30 East Asian populations
2.3 45 SNP Panel的验证结果
2.3.1 50个拉萨藏族样本族源信息的验证结果
经过对50 个拉萨藏族样本(LST)与其他30 个人群的STRUCTURE、热图和PCA 分析(图5~7),拉萨藏族与宁夏回族、成都藏族、凉山藏族、康巴藏族、羌族、白马藏族和凉山州彝族聚在一起。

图5 45 SNP Panel在50个拉萨藏族样本中的STRUCTURE分析图谱Fig.5 The STRUCTURE plot of 45 SNP Panel of 50 Lhasa Tibetan samples

图6 45 SNP Panel在50个拉萨藏族样本中的热图分析Fig.6 The heatmap analysis of 45 SNP Panel of 50 Lhasa Tibetan samples
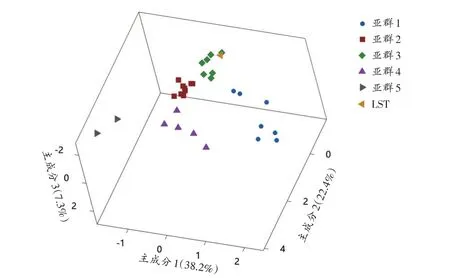
图7 45 SNP Panel在50个拉萨藏族样本中的PCA图谱Fig.7 The PCA plot of 45 SNP Panel of 50 Lhasa Tibetan samples
2.3.2 10个测试样本的族源推断结果
选择5个北京汉族样本和5个拉萨藏族样本作为测试样本,检测45 SNP Panel的基因型,并计算10个样本在5个亚群中的似然率,结果见表1。5个北京汉族样本中,3 个样本的最高似然率人群是亚群2,2 个样本的第二高似然率人群是亚群2。5 个拉萨藏族样本中,3 个样本的最高似然率人群是亚群3,2 个样本的第二高似然率人群是亚群3。

表1 10个测试样本在东亚5个亚群中的似然率Tab.1 The likelihood ratio of 10 test samples in 5 subgroups of East Asia
3 讨论
3.1 45 SNP Panel的个体识别能力
与170 SNP Panel 相比,45 SNP Panel 中DP 值的平均值为0.595 6,高于170 SNP Panel 的0.472 1;45 SNP Panel 中PI 值的平均值为0.868 8,高于170 SNP Panel 的0.773 7。此外,基因多样性、多态信息含量、匹配概率、非父排除率等信息中,45 SNP Panel的SNP位点信息量平均值高于170 SNP Panel中SNP位点的信息量,即45 SNP Panel 在东亚人群中的法医学个体识别性能是比较高的。
3.2 45 SNP Panel的族源推断能力
通过图1~2 可以看出,170 SNP Panel 把30 个东亚人群分成5 个亚群,45 SNP Panel 也同样把东亚人群分为5 个亚群,分群结果与170 SNP Panel 完全一致。通过PCA和热图分析,也支持将30个东亚人群分为5个亚群。同时,通过对10个已知样本的检测并计算其在各亚群中的似然率,60%样本的似然率最高值出现在其所属亚群中,40%样本的似然率第二高值出现在其所属亚群中。从以上分析可以看出,45 SNP Panel具有较强的族源分析和推断能力。
3.3 亚群1中内蒙古与蒙古国人群的族源信息分析
亚群1中的哈萨克族、维吾尔族1、维吾尔族2、青海藏族、内蒙古人群均生活在中国的西北部及北部,蒙古查腾族和蒙古国人群生活在中国的北部,与内蒙古相连。由图1~2可见,通过STRUCTURE分析,蒙古国人群与内蒙古人群图谱相近,而与其他5 个人群具有较为明显的区别,在45 SNP Panel 的PCA 中,亚群1中蒙古国人群与内蒙古人群明显与其他5个人群具有一定距离,与亚群3 具有较近的距离。而在热图分析中,蒙古国人群与内蒙古人群聚在一起后,又与亚群3汇聚,再与亚群1汇合在一起。
3.4 亚群2 中日本、韩国人群与中国人群的族源信息分析
在图1中,6个中国人群,无论是南方汉族还是北方汉族,无论是台湾汉族人群还是来自国外的旧金山、新加坡等地区的汉族人群,均聚集在一起,这也说明分布于不同地区的汉族人群都属于一个分支,在遗传信息上较为相似。2 个日本人群和韩国人群与汉族人群间具有一定差异。从PCA 结果可见,中国人群、南方汉族、台湾汉族、客家人群和新加坡汉族聚在一起。
3.5 亚群4中柬埔寨人群和新加坡马来西亚人群与其他3个民族之间的族源信息分析
云南傣族与越南人群、老挝人群、柬埔寨人群和新加坡马来西亚人群聚在一起,说明云南傣族与其他4 个人群具有较近的族源关系。在图1~2 中,柬埔寨人群和新加坡马来西亚人群聚在一起与其他3 个民族具有一定的差异。在PCA 中,柬埔寨人群与新加坡马来西亚人群与亚群3 中的其他人群具有一定距离。在热图分析中,柬埔寨人群首先与新加坡马来西亚人群聚在一起后再与其他3 个人群聚在一起。中国云南省与老挝和越南接壤,傣族人群与老挝、越南人群之间的遗传差距较小,而柬埔寨、新加坡及马来西亚与我国具有一定距离,遗传距离较远。
3.6 结论
在族源推断信息上,45 SNP Panel 可以替代170 SNP Panel,达到相同的族源分析及推断能力。而在遗传学参数上,在东亚人群中45 SNP Panel 明显优于170 SNP Panel。此外,目前对于东亚人群内族源推断的有效SNP位点数量还不足,后期研究需要更多分析和人群数据验证,进一步优化可用于东亚人群内族源推断的遗传标记体系。
