基于改进YOLOV3的自然环境下绿色柑橘的识别算法*
2021-12-06宋中山刘越郑禄帖军汪进
宋中山,刘越,郑禄,帖军,汪进
(1.中南民族大学计算机科学学院,武汉市,430074;2.湖北省制造企业智能管理工程技术研究中心,武汉市,430074)
0 引言
随着我国乡村振兴战略的深入实施,农业向着高质量、高产量方向的发展成为关键,这促使农产品的信息采集,尤其是产量信息的获取显得尤为重要。柑橘作为我国消费量最大的水果之一,对果树进行早期估产有助于种植者提前进行相关收获规划,而目前柑橘园估产主要是在柑橘成熟变黄以后以人工清点、目测预估等传统方式进行,这存在耗时长、工作强度大等缺点,且此时成熟的柑橘已经不能通过人工干预的方式来提高产量[1]。在成熟期前对未成熟的绿色柑橘进行早期的产量预测有助于种植者提前确定果树的产量情况,这不仅可以帮助种植者在种植过程中科学规划水肥投入量,同时帮助种植者在早期果园销售时提供商业参考[2]。
国内外关于水果检测方向多在非近景色果实识别上进行相关研究[3-10]。在近景色果实的研究方面,目前有较多的研究利用深度学习技术开展,如绿色柑橘、青苹果、绿番茄和猕猴桃等果实识别。近景色水果果实与背景的叶子颜色相近,使得识别难度较大,识别准确率较低。
目前在水果识别的研究方向上,Kurtulmus等[11]提出使用三个不同尺度的移动子窗口扫描整个图像,每个子窗口分别用强度分量的特征值法、饱和度分量的特征值法和圆形Gabor纹理进行三次分类,最后通过多数投票来确定子窗口分类器的结果。Sengupta等[12]提出由霍夫圆检测,基于SVM的纹理分类和尺度不变特征变换等技术集成的算法用于检测自然户外照明条件下的绿色柑橘,算法达到80.4%的正确识别率。Zhao等[13]提出基于纹理特征分析和绝对变换差和算法的块匹配模型来检测绿色柑橘,模型达到83%的正确检测精度。以上对果实的识别方法主要是利用图像处理技术结合颜色、纹理、形状等基本特征来进行识别。
随着机器学习的深入研究,学者开始利用目标检测算法实现果实的自动识别。Gan等[14]提出一种新的彩色—热联合概率算法,有效地融合彩色图像和热图像的信息,再利用Faster-RCNN算法进行实时的检测,提高识别的准确率。熊俊涛等[15]利用Faster-RCNN方法进行树上绿色柑橘的视觉检测研究,通过试验对超参数进行调优,使用优化后的超参数对模型进行训练,最终模型在测试集上的平均精度为85.49%。吕石磊等[16]提出一种基于改进YOLOV3-LITE轻量级神经网络的柑橘识别方法,该方法通过引入GIoU边框回归损失函数来提高果实识别回归框准确率。
目标检测作为计算机视觉的一个热门研究方向,现已被广泛应用于机器人导航、智能视频监控、水果自动识别等诸多领域[17]。本文在采集大量的柑橘园绿色柑橘图像基础上,提出一种基于改进YOLOV3的自然环境下绿色柑橘的识别算法,利用DenseNet的密集连接机制替换YOLOV3网络中的特征提取网络Darknet53中的后三个下采样层,加强特征的传播,实现特征的复用。通过该算法可实现自然环境下近景色柑橘的快速有效识别,为近景色水果的早期测产提供技术支持。
1 材料与方法
1.1 数据集采集
柑橘图像数据采集于桂林市灵川县九屋镇的果园,共532幅。拍摄工具为三星S10手机,在自然光背景下将手机相机调整为“自动聚焦”模式,在不使用闪光灯和缩放的情况下进行拍摄,所拍摄的图像像素为4 032像素×3 024像素(大小约3.9 M);考虑到现实情况的多变性,拍摄场景选择阴天和晴天,拍摄时间选择下午2点和下午5点,拍摄距离选择距离树干1.0 m 和0.5 m。数据集具体分类如表1所示。

表1 数据集具体类别Tab.1 Specific categories of data set
1.2 数据集预处理
为增强数据集的丰富性对数据集进行预处理。首先对图像分别以左上、左下、右上、右下和中心为基准,将一幅图像裁剪成5幅图像以降低分辨率,且只保留下含有果实的图像,处理后共获得2 000幅图像,每幅图像的分辨率为512像素×512像素。图像裁剪如图1所示。其次利用OpenCV库对图像进行预处理,其中分别使用色彩平衡、亮度变换、旋转变换、高斯模糊、中值模糊和高斯噪声各处理300幅图像,使用椒盐噪声处理200幅图像。最后以7:3的比例将数据集划分为训练集和测试集,使用1 400幅图像训练网络模型,600幅图像作为测试集验证模型的检测性能。预处理后图像如图2所示。

(a)原始图像

(a)原始图像
2 自然环境下的绿色柑橘识别方法
2.1 YOLOV3模型
YOLOV3[18]网络由YOLO[19]和YOLOV2[20]网络演变而来,它将检测问题转换为回归问题,通过回归生成边界框坐标和每个类的概率。与Faster-RCNN相比,这使得检测速度大幅提升。YOLOV3采用称为Darknet53的特征提取网络结构,它借鉴残差网络的思路,在一些层之间设置快捷链路,可以有效缓解反向传播中的梯度消失问题。为降低池化带来的梯度负面效果,使用步长为2的卷积操作来实现降采样。YOLOV3使用特征图金字塔网络的多尺度预测方法和融合做法以提高算法对小目标检测的精确度。
2.2 DenseNet模型
DenseNet[21]的密集连接机制是每层接受其前面所有层作为额外的输入。ResNet[22]的机制是每层与前面的某层以元素级相加的形式短路连接在一起。在DenseNet中,每层都会与前面所有层以通道维度上连接在一起,并作为下层的输入。因此传统的L层卷积神经网络中存在L个连接,而DenseNet结构中存在L(L+1)/2个连接。由于DenseNet直接连接来自不同层的特征图,这可以实现特征重用,提升效率,提高网络性能。
传统的卷积神经网络中,第L层的输出如式(1)所示。
xL=HL(xL-1)
(1)
DenseNet中,第L层的输出如式(2)所示。
xL=HL([x0,x1,…,xL-1])
(2)
式中:x0——密集连接块的输入特征图;
xL——第L层的输出;
HL(·)——层间非线性转化函数,是包括批量归一化函数(Batch normalization,BN),线性整流函数(Leaky ReLu)和卷积(Conv)的组合操作;
[x0,x1,…,xL-1]——与第L层的特征图尺寸相同的前面若干层所生成的特征图集合。
2.3 改进YOLOV3模型
深层网络中梯度信息会随着网络的加深消失或过度膨胀。卷积神经网络中浅层主要提取局部特征,比如颜色特征,边缘特征等,深层主要提取语义特征,所以深层特征更接近人对事物的现实认知。YOLOV3作为经典深度卷积神经网络,图像输入后进行卷积操作时,若丢失重要语义特征,会影响模型的检测效果。而DenseNet模型的密集连接机制可以将前面层提取到的特征信息更为有效地为后面层所复用,进而使得网络随着层数的增加,在原已得到的全局特征信息的基础上不断增加新的后面层所产生的特征信息。因此,为了提高YOLOV3模型对深层语义特征的利用,减少语义信息的丢失,本文借鉴DenseNet网络的密集连接机制对YOLOV3模型做出改进。
Dense Block内部为了减少计算量,提升计算效率而采用瓶颈层,即在原结构中增加1×1Conv,Hl(·)变成BN+ReLu+1×1Conv+BN+ReLu+3×3Conv。
Darknet53网络中共有5个步长为2的下采样层,将后三个下采样层替换成Dense Block结构,因为后三个下采样层紧靠YOLOV3中3个尺度的输出特征,且在网络中处于可以提取到更多语义信息的深层,将这三处的特征加强传播,实现特征重用,有利于获得的输出特征得到丰富的内容,进而优化检测效果。将此改进得到的算法结构命名为D-YOLOV3算法,该算法的架构图如图3所示。改进后的Darknet53网络可以更有效的提取特征信息,缓解了由于层数过多而导致的梯度消失问题,由于Dense Block中的每一层都接收前面的所有层作为输入,因此特征更加多样化,并且倾向于有更丰富的模式。
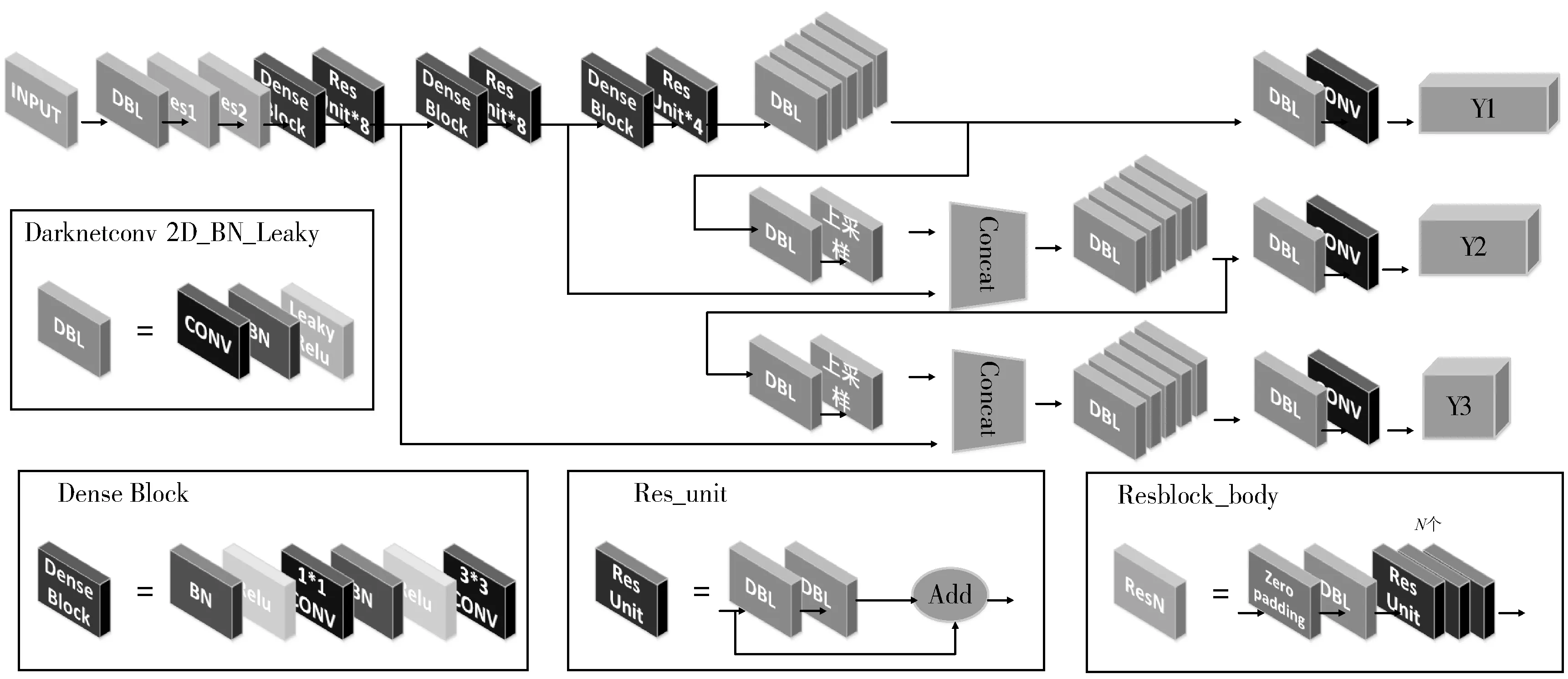
图3 D-YOLOV3算法架构图Fig.3 Network structure of D-YOLOV3 algorithm
D-YOLOV3模型的具体参数如图4所示。为了配合数据集的分辨率,将输入的图像的大小设置为512像素×512像素,位于12、37和62层的下采样层替换为有密集连接机制的Dense Block模块。
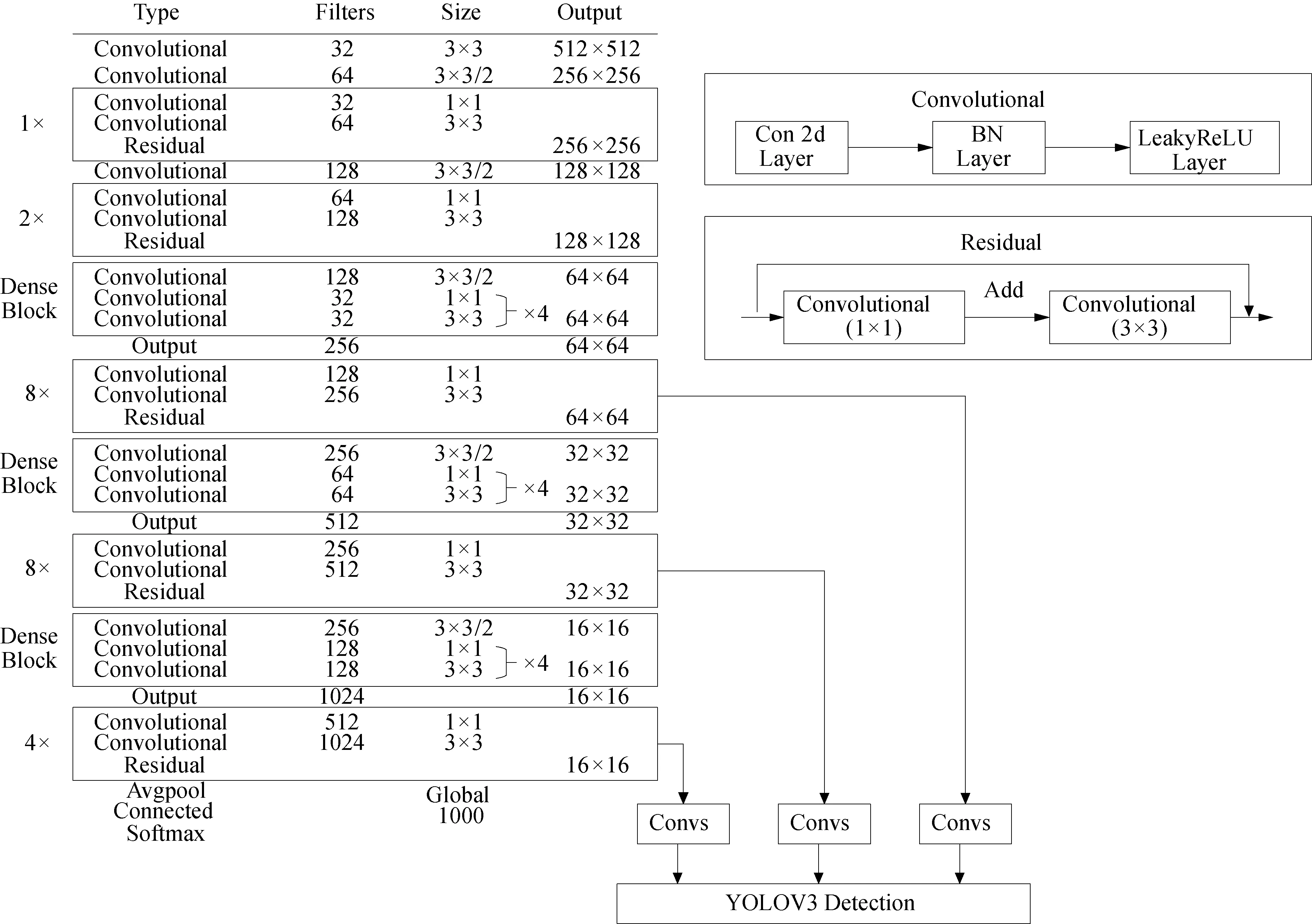
图4 D-YOLOV3模型具体参数Fig.4 Specific parameters of D-YOLOV3 algorithm3
以62层的结构为例,H1先对x0应用BN+ReLU+1×1Conv非线性运算,然后对结果执行BN+ReLU+3×3Conv运算,之后H2对由[x0,x1]形成的特征图应用相同的操作,再将x2和[x0,x1]拼接成[x0,x1,x2]并用作H3的输入,x3和[x0,x1,x2]被拼接为[x0,x1,x2,x3],作为H4的输入,最后特征层被拼接成16×16×1 024并向前传播。12层和37层同理进行处理。
3 结果与分析
3.1 试验评价指标
评估神经网络模型有效性的相关指标主要有精确率(Precision)、召回率(Recall)、F1得分、PR(Precision-Recall)曲线和IoU值(交并比)。针对二分类问题,一般根据样本的真实类别和预测类别进行分类。具体有四种分类:真阳性(TP),假阳性(FP),真阴性(TN)和假阴性(FN)。
精确率表示预测为正的样本中有多少实际为正,召回率表示实际为正的样本中有多少预测为正,F1分数为精确率和召回率的调和平均值,一般F1分数越大,模型越稳定,鲁棒性越高。IoU值为图像中存在的对象的预测区域和地面实况区域之间的相似性。
(3)
(4)
(5)
本研究在Windows10环境下通过Pycharm软件完成模型的训练和测试,计算机内存为8 G,CPU为InterCorei7-6700 3.40 GHz。
3.2 算法性能对比试验
为了验证本文提出的模型的性能,用绿色柑橘图像训练集来训练D-YOLOV3模型和YOLOV3模型,并将它们在训练过程中的Loss图进行对比。
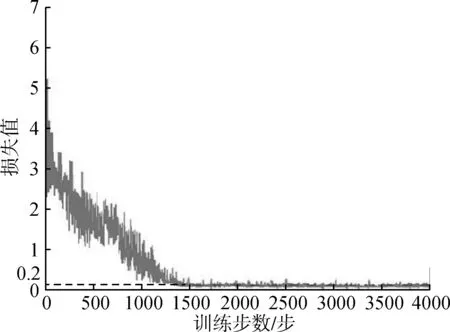
(a)D-YOLOV3模型Loss图
从图5可知D-YOLOV3模型在训练过程中具有比YOLOV3模型更好的收敛效果。YOLOV3模型的最终损失稳定在0.3,而D-YOLOV3模型的损失稳定在0.2,这表明所提出模型的性能得到一定的改善。两个模型的收敛速度相似,经过1 000个训练步骤后,两个模型的loss曲线都开始收敛,在1 500个训练步骤此后不再减少。为了进一步验证模型的性能,在测试集上对改进前后的YOLO模型、文献15中的Faster-RCNN模型的精确率、召回率、F1分数、IoU值、处理时间和MAP上进行比较。文献15使用Faster-RCNN的中型网络作为预训练网络,设置初始学习速率为0.01,批处理为128,动量系数为0.9。从表2可知,D-YOLOV3模型相较于YOLOV3模型而言,精确率提升6.57%,召回率提升2.75%,F1分数提升4.41%,IOU值提升6.13%,表明模型在提高检测效果的同时,模型的稳定性也得到提高。Faster-RCNN模型的性能相对YOLOV3模型也有一定的提升,而D-YOLOV3模型的性能相对来说更好。

表2 各模型评价指标对比Tab.2 Comparison of evaluation indexes of each model
3.3 不同试验数据量影响试验
在本节中,主要分析图像数据集的大小对D-YOLOV3模型的影响。在数据集中随机选择100、500、800、1 000、1 400、1 700张图像以形成训练集,在不同大小的训练集情况下,模型的F1分数变化情况如图6所示。

图6 不同训练图像数量下D-YOLOV3模型的F1分数Fig.6 F1 scores of D-YOLOV3 model under different training images
从图6可知,D-YOLOV3模型的性能随训练集大小的增加而提高。如果训练集包含少于800张图像,则随着训练集的增长,性能会迅速提高。当训练集的大小超过1 000时,增强速度会随着图像数量的增加而逐渐降低。当图像数量超过1 250时,训练集的大小不会对模型的性能产生更大的影响,这表明模型已经拟合,不再需要更多的图像进行训练。
3.4 不同数据预处理影响试验
在数据预处理部分,本研究主要使用色彩平衡、亮度变换、旋转变换、模糊处理和噪声处理用于增强图像,使算法的鲁棒性更好。为了验证这五种数据增强方法对训练模型的影响,在3.3试验的同一数据集中,使用控制变量方法每次删除一种数据增强方法,观察模型的F1分数变化。模型的PR曲线变化如图7所示。

图7 不同数据预处理下D-YOLOV3模型的PR曲线Fig.7 PR curve of D-YOLOV3 model under different data preprocessing
从表3可知,模糊处理对模型的性能影响最大,去掉模糊处理后,模型的F1分数下降6.51%;其次是亮度变换和噪声,亮度变换模拟的是在自然背景下的自然光照效果,对模型的性能有较大的影响;旋转变换对模型的影响最小。通过对数据集进行多种预处理可以增加样本的多样性,模拟现实中的多种情况,这使模型的鲁棒性更好。

表3 不同数据预处理下D-YOLOV3模型的F1分数Tab.3 F1 scores of D-YOLOV3 model under different data preprocessing
3.5 不同果实数量的对比试验
在自然环境下,柑橘树的果实在果树上的分布往往是成片式的,随着拍摄角度的选取以及拍摄距离的改变,图像中出现的果实数量是不相同的,尤其对于未成熟的绿色柑橘,此时果实体积较小且互相遮挡,使得检测的难度更大。在自然环境下拍摄包含果实数量1~5个,5~10个,10个以上的图像各100幅,对比测试D-YOLOV3模型、YOLOV3模型和Faster-RCNN模型的检测效果。识别效果如图8所示。

(a)1~5 D-YOLOV3
从表4可知,改进后模型的整体识别效果相对于YOLOV3模型和Faster-RCNN模型更好,尤其是识别10个以上果实的图像,D-YOLOV3模型比改进前模型的精确度高7.65%,比Faster-RCNN模型的精确度高4.43%。对于多果实图像,D-YOLOV3模型可以识别出更多的果实,而在现实场景下,多果实的情况是很普遍的,这表明D-YOLOV3模型在实际场景中对多目标果实的识别更有优势。

表4 不同果实数量下各模型精确率对比Tab.4 Accuracy of each model under different fruit numbers
4 结论
1)提出一种基于改进的YOLOV3算法对自然背景下的未成熟的绿色柑橘进行识别检测,通过构建绿色柑橘数据集以及一系列数据集预处理操作,提高了神经网络的泛化能力;利用DenseNet的密集连接机制改进了YOLOV3网络的结构,使特征在网络中更好的传播。最终训练得到的模型在测试集上的精确率为83.01%,相对YOLOV3模型提高6.57%,表明模型可以识别出更多的果实以达到产量预估的目的。
2)为进一步验证此方法的有效性和可行性,设计了3个试验,分别是不同果实数量试验、不同数据量试验和不同数据预处理影响试验,通过试验结果可知,本文提出的算法有较高的泛化性能和检测精度,展示出对多目标果实识别的有效性。
