PM2RA: A Framework for Detecting and Quantifying Relationship Alterations in Microbial Community
2021-12-03ZhiLiuKaiMiZhenjiangZechXuQiankunZhangXingyinLiu1
Zhi Liu, Kai Mi, Zhenjiang Zech Xu, Qiankun Zhang,Xingyin Liu1,,5,*
1 State Key Laboratory of Reproductive Medicine, Center of Global Health, Nanjing Medical University, Nanjing 211166, China
2 Department of Pathogen Biology-Microbiology Division, Key Laboratory of Pathogen Biology of Jiangsu Province,Nanjing Medical University, Nanjing 211166, China
3 Key Laboratory of Human Functional Genomics of Jiangsu Province, Nanjing Medical University, Nanjing 211166, China
4 School of Food and Technology State, Key Laboratory of Food Science and Technology, Nanchang University, Nanchang 330031, China
5 Key Laboratory of Holistic Integrative Enterology, Second Affiliated Hospital of Nanjing Medical University, Nanjing 210003, China
KEYWORDS
Abstract The dysbiosis of gut microbiota is associated with the pathogenesis of human diseases.However, observing shifts in the microbe abundance cannot fully reveal underlying perturbations.Examining the relationship alterations(RAs)in the microbiome between health and disease statuses provides additional hints about the pathogenesis of human diseases,but no methods were designed to detect and quantify the RAs between different conditions directly. Here, we present profile monitoring for microbial relationship alteration (PM2RA), an analysis framework to identify and quantify the microbial RAs. The performance of PM2RA was evaluated with synthetic data, and it showed higher specificity and sensitivity than the co-occurrence-based methods. Analyses of real microbial datasets showed that PM2RA was robust for quantifying microbial RAs across different datasets in several diseases.By applying PM2RA,we identified several novel or previously reported microbes implicated in multiple diseases. PM2RA is now implemented as a web-based application available at http://www.pm2ra-xingyinliulab.cn/.
Introduction
The gut microbiome is considered as the second genome of human body and is linked to many human diseases [1–3].The central goal of human microbiome studies is to identify microbes associated with diseases. The identified bacteria can provide insights into disease etiology and be potential biomarkers for disease diagnosis and prevention. Furthermore,they could be therapeutic targets if verified as causal factors for certain diseases.
The development of next-generation sequencing technologies enables culture-independent investigations of the human microbiome’s role in health and disease via direct DNA sequencing. Both 16S rRNA sequencing and metagenomic sequencing have been used to study the human microbiome,allowing the creation of a table for the differential abundance analysis of microbes under various biological conditions[4–6]. Differential abundances of certain microbes may contribute toward conferring a specific trait in a given situation.However, focusing on individual microbe alterations while ignoring potential relationship alterations (RAs) limits reflection on the real perturbation of ecological networks under phenotype changes.
The human microbiome is a complex bacterial community in which sub-communities are formed based on shared niche specializations and specific interactions between individual microbes. The mutual associations within the residing microbial communities play an important role in the maintenance of eubiosis [7–9]. Bacteria can interact with each other in numerous ways, such as commensalism, mutualism, and competition, which can have neutral, beneficial, and detrimental effects on the microbes involved, respectively. Commensalism refers to situations where some constituent microbes of an ecosystem derive benefits from other members without helping or harming them. Mutualism describes interactions that benefit all organisms involved [8]. A bacterium might also directly compete with another one for the same nutrition source,thereby creating a competition [7,10]. These kinds of functional relationships are referred to as profiles,which can be linear,polynomial,nonlinear,or a waveform[11].The disruption of these relationships can lead to disorders in the microbial community structure, furthering dysbiosis.
Many studies have modeled microbiome profiles with a linear correlation between two types of microbes [12–14],and co-occurrence networks are constructed to describe the whole microbial communities. Based on these co-occurrence networks, alignment-based [15–18] or alignment-free [19–21]methods have been proposed to visualize the RAs between different conditions, such as health vs. disease. The alignment-free network comparison methods aimed to quantify the overall topological difference between networks, irrespective of node mappings between the networks and without identifying any conserved edges or subgraphs. The alignment-based methods aimed to find a mapping between the nodes of two networks that preserves many edges and a large subgraph between the networks. These strategies can neither quantify the association changes in a specific group of microbes nor pinpoint the exact nodes that contribute to the community differences between two conditions.
Applying the concept of profile monitoring,which is widely used to monitor the relationship consistency between variables in the food-production, manufacturing, and healthcare industries [22], we developed an innovative analysis framework called profile monitoring for microbial relationship alteration(PM2RA) to detect and quantify the profile alterations within microbial communities under various conditions. To our knowledge,PM2RA is the first method to make direct comparisons of microbial associations between conditions without initially constructing co-occurrence networks. By testing both synthetic and real datasets, we demonstrate that PM2RA is high in sensitivity and specificity,and identifies both previously identified and novel microbes involved in multiple diseases.Moreover, PM2RA is robust in identifying important microbes in datasets obtained from different cohorts and different sequencing strategies. A web-based implementation of PM2RA is available at http://www.pm2ra-xingyinliulab.cn/.
Method
PM2RA framework
The human microbiome is a complex bacterial community where the relationships between microbes play important roles in the maintenance of eubiosis (Figure 1A). Examining the RAs in the microbiome between health and disease conditions provides additional insights into the pathogenesis of human diseases (Figure 1B). PM2RA is specifically designed to quantify the RA(s)involving two or more microbes under different conditions.The basic idea of PM2RA analysis is to project the abundance data of two or more microbes under two conditions into the same space via Hotelling’s T2statistic, and compare the difference in the distribution of T2statistics to represent the RAs between two conditions.We developed a new scoring scheme called PM (profile monitoring) score to quantify the RA of each sub-community under different conditions in five steps(Figure 1C).The more the sub-community alters,the bigger the PM score is. Next, we built an RA network in which edges denote the corresponding PM scores (Figure 1C). The framework comprises the following steps.
Compose the sub-communities
In a microbiota profile,every two microbes and the interaction between them are defined as a sub-community.PM2RA quantifies all possible sub-community RAs and outputs the RA network.
Calculate the T2statistics
Hotelling’s T2statistic is one of the most popular statistics for monitoring the variables of a multivariate process [23]. This statistic considers both the mean value and covariance matrix,which makes it suitable for reducing two-dimensional (2D) or high-dimensional (HD) microbial data into one-dimensional data containing both abundance and relationship information.The T2statistic is the multivariate counterpart of the t statistic and is widely used in multivariate processes for consistency monitoring in both industry and biology [24,25]. It can be viewed as the generalized distance between the observed vectorand the mean vector μ weighted by the inversion of the covariance matrix,Since both μ and ∑are involved in the calculation,T2statistic is sensitive to both relative abundance change and relationship change.
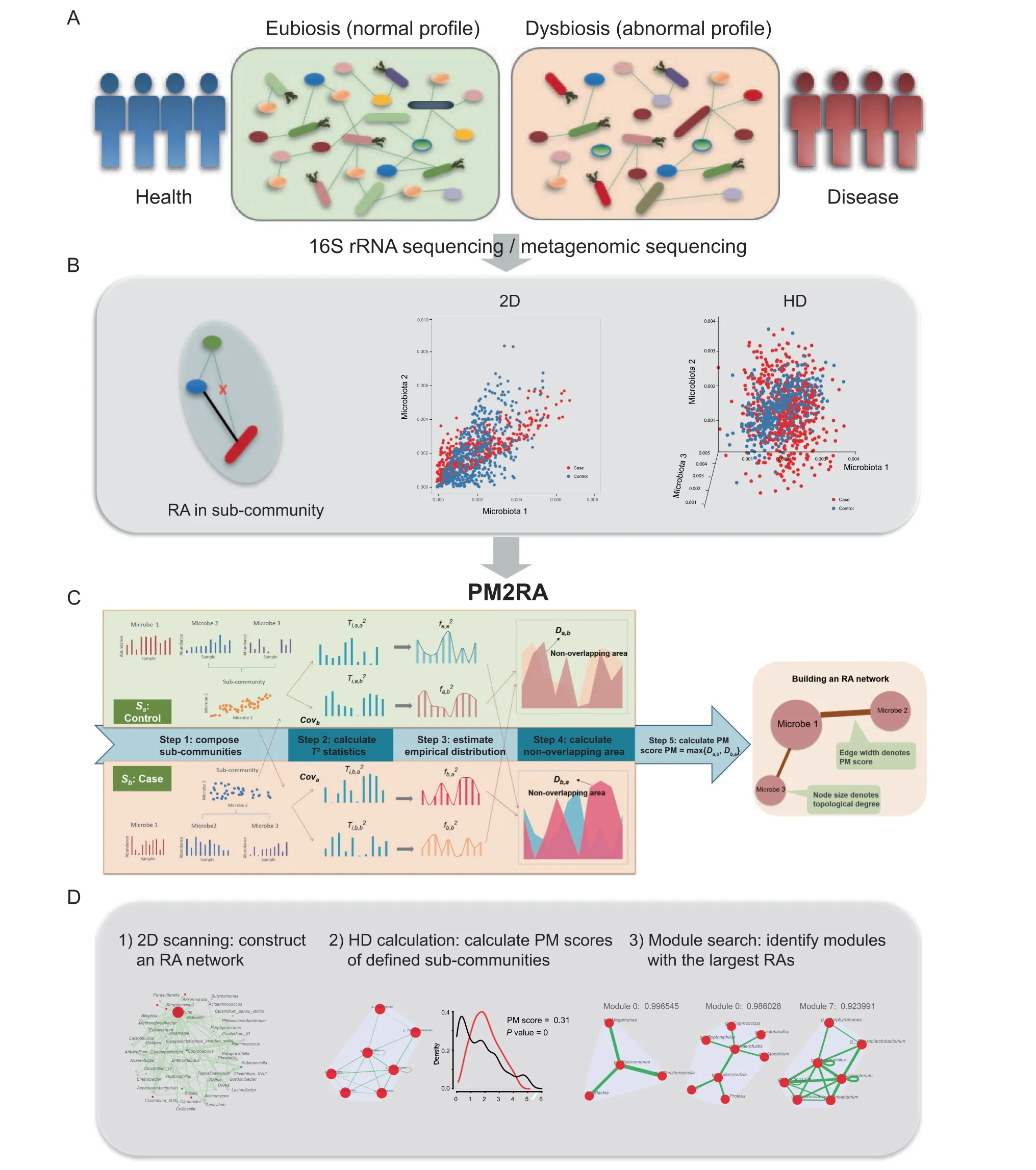
Figure 1 Overview of the PM2RA methodA. Dysbiosis of gut microbiota involves disturbed microbe relationships under human disease conditions. B. A relationship change can involve two or more microbes in a 2D or HD level. C. The PM2RA methodology framework. First, compose the sub-communities each consisting of two microbes.Second,calculate the T2 statistic for each sub-community.Third,estimate the empirical distribution of the T2 statistics. Fourth, calculate the non-overlapping area between distributions. Finally, calculate the PM score for each sub-community. D.The PM2RA has developed with three methods: 1) 2D scanning for pairwise RAs among the microbial community between two conditions,2)HD calculation by which the PM score of any defined sub-community with two or more microbes could be calculated,and 3) module search based on the HD calculation. PM2RA, profile monitoring for microbial relationship alteration; 2D, two-dimensional;HD, high-dimensional; PM, profile monitoring; RA, relationship alteration.

Xa,Xband COVa,COVbare the mean relative abundance vectors and the covariance matrices of microbes under conditions Saand Sb, respectively. xi,aand xi,bdenote the relative microbial abundance of the ithsample under Saand Sb,respectively.
In the pairwise RA analysis,the number of microbes is two,and the sample size is usually much larger than that. In this case, the possibility of strict collinearity between two microbes is low,so we can assume that the covariance matrix is nonsingular.
Estimate the empirical distribution of the T2statistics
The probability density function is an informative, descriptive tool and can reflect the mean, standard deviation, and other statistical properties of the dataset. A straightforward way to calculate alterations between two datasets is to compare their probability density functions. The T2statistic follows a scaled chi-squared distribution under the assumption that samples have a normal distribution,although this assumption is usually violated in the microbiota abundance context. Researchers believe that the normal distribution is not a good descriptor of the microbiota sequencing data. Instead, zero-inflated negative binomial models are usually recommended for handling excessive zeros in such data[27].The T2statistic of the microbe community certainly does not follow the chi-squared distribution.Thus,PM2RA uses a kernel distribution to represent the probability density of the T2statistics derived for each subcommunity. The estimated kernel distribution produces a non-parametric, smooth, continuous probability curve that adapts itself to the data, rather than selecting a density with a particular parametric form (e.g., a chi-squared distribution)and estimating the parameters. More straightforwardly, the kernel density estimation method imposes no parametric assumptions on the underlying distribution function. In this step, the kernel estimation method proposed by Scott [28] is applied to Ti,a,a2,Ti,b,a2,Ti,a,b2,and Ti,b,b2.The estimated empirical probability density functions are denoted as fa,a2,fb,a2,,and fb,b2, respectively. Outliers were removed from Ti,a,a2,Ti,b,a2, Ti,a,b2, and Ti,b,b2for a robust estimation.
Calculate the non-overlapping area between distributions
The non-overlapping area of two probability distribution functions is used to describe the difference between two sets of T2statistics.
The non-overlapping area of fa,a2,is
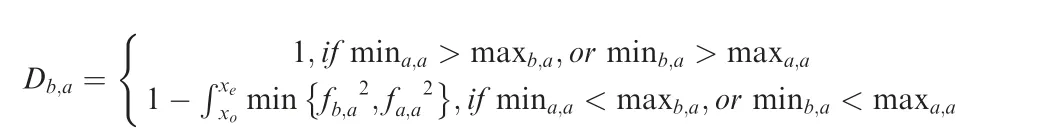
where where
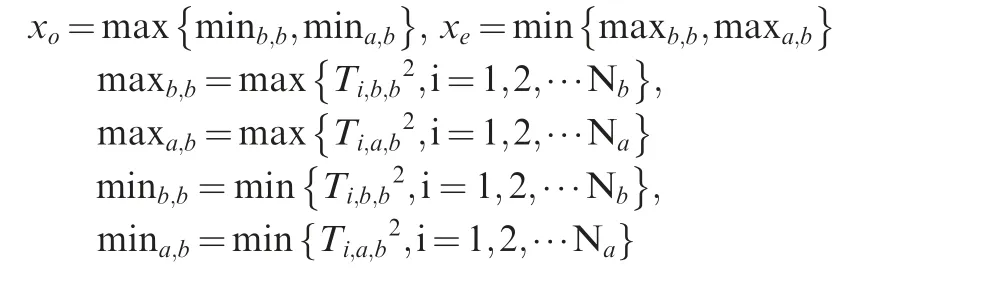
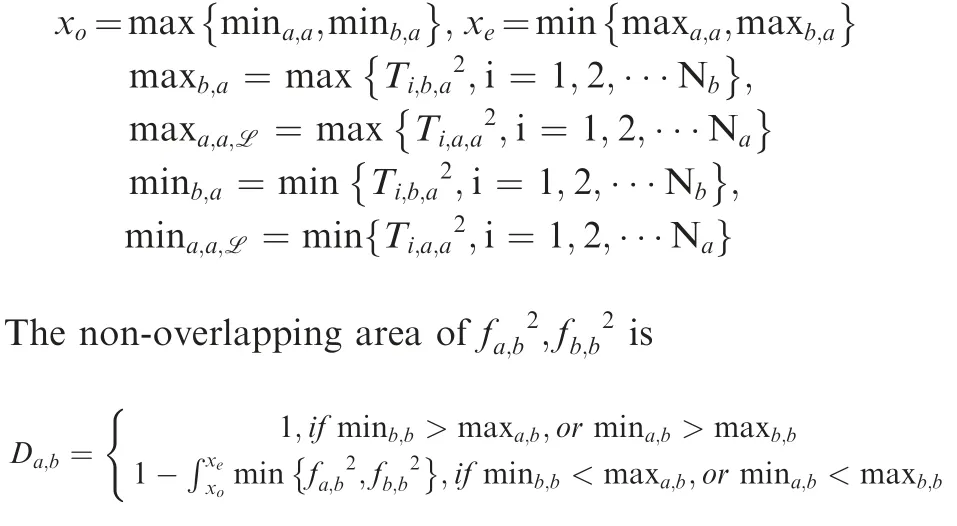
Calculate the PM score
The PM score is defined as max {Da,b,Db,a}. Compared to other non-parametric distance measures, such as Kullback–Leibler divergence, the PM score has several advantages.The profile change measure is designed under symmetry.The PM score has finite domain ranges from 0 to 1. A Kolmogorov-Smirnov test is applied to the T2statistics to determine whether a statistically significant difference exists between conditions.
PM2RA applications
The PM score of any defined sub-community that is referring to two or more microbes can be calculated with PM2RA. We proposed two main functions of PM2RA (Figure 1D).
Constructing the RA network via 2D scanning
Every two microbes constitute a sub-community. After traversing all sub-communities, a weighted network is built to visualize the overall RAs. In the RA network G=(V, E),V is the set of nodes representing microbes and E is the set of edges denoting the RAs between the two conditions. The edge width and node size denote the PM score and topological degree, respectively. In this pairwise network, hub microbes,which have extensively altered associations between two compared conditions, can be identified.
Module search
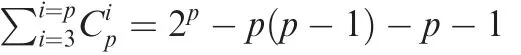
Step 1, profile changes for all sub-communities of exactly two microbes are calculated. Step 2, N sub-communities with the top PM scores and no overlapping microbes are selected and marked as seed communities. Step 3, a new subcommunity set is created and able to be searched. New subcommunities are generated by adding a new microbe to a seed community, whose dimension is the dimension of the seed community plus 1, and by combining two seed communities,whose dimension is twice those of the original seed communities. Step 4, the PM scores of all sub-communities newly generated in step 3 are calculated. Step 5, all the calculated PM scores resulting from steps 1 and 4 are ranked. Step 6, N sub-communities with the top PM scores and no overlapping microbes with each other are selected based on the data list in step 5, and marked as new seed communities. Loop into step 3 and start the iteration. Finally, when the iteration time exceeds the pre-set threshold, or the results of two iterations converge, searching is stopped and N microbe modules are found.
PM2RA implementation
In the PM2RA framework,we considered several characteristics of the microbiome sequencing data. In the microbiome dataprocessing procedure, the most common strategy to manage zero inflation is filtering out taxa with relatively low presence,such as features present in less than 5%,10%,or even 50%of samples [29,30]. In our analysis pipeline, microbes detected in less than 10%of samples were removed.Also,in the application of the PM2RA web server and R script, users could set a selfdefined prevalence filter to remove microbes with inflated zeros.A false discovery rate(FDR)of less than 0.05 was used as a cutoff to filter significant RAs. The average computation time of PM2RA for a dataset containing 100 features(No.of calculations:) is 30 min (R with parallel computing on CentOS Linux release 7.6.1810 with E5-2680 v4,eight cores).
PM2RA performance evaluation
Several types of datasets were downloaded to evaluate the performance of PM2RA.The 16S rRNA sequencing data for colorectal carcinoma (CRC), overweight, and obesity samples were downloaded from MicrobiomeHD [31]. The metagenomic sequencing data for CRC were downloaded from the published dataset [5]. The original dataset contained four cohorts from China, Austria, the United States (US), and France/Germany, respectively. Because samples in the US dataset were collected more than 20 years ago and had no significant RA being detected (Table S1), this dataset was excluded from the following analysis. Two diabetes datasets were downloaded from the published datasets [32].
The performance of PM2RA was compared with that of other relevant methods using artificial datasets generated based on the COMBO dataset[33].This dataset contains operational taxonomic units (OTUs) from 100 samples. To evaluate the false positive rate (FPR) of PM2RA, we randomly separated samples into two groups with an even sample size of 50, where it is assumed that the relationship between any two OTUs does not change between the two groups.This process was repeated 100 times to generate 100 matched artificial case and control datasets. PM2RA and other methods were applied to these datasets, and the FPRs were calculated and compared. To evaluate the false negative rate (FNR) of PM2RA, we interchanged the abundances of any two OTUs each time (e.g., A and B), which were not detected to be correlated by both SparCC and SPIEC-EASI,to generate the case datasets. It is assumed that the relationship between A/B and other intact OTUs will change in such a synthetic case dataset,which is defined as the ‘‘true positive”. The control dataset is the intact one. PM2RA and other methods were applied to these datasets, and the FNRs were calculated and compared.
A two-step strategy was applied to all the synthetic datasets. First, the co-occurrence networks for each synthetic case and control datasets were constructed using the SPIEC-EASI and SparCC methods implemented in the R package SpiecEasi.The co-occurrence network was represented by a matrix consisting of 1(correlated)and 0(not correlated).Second,the case and control co-occurrence networks of each simulation were compared to obtain the changed association pairs. After these two steps,the sensitivity and specificity of these methods were compared with those of PM2RA.
The RAs detected by PM2RA could be used as features to discriminate between different conditions. We compared the feature extraction performance by the area under curve(AUC)between NetShift and PM2RA.The AUC was also calculated by directly using the whole microbe abundance data without feature extraction. This comparison was done by a random forest (RF) model (R 3.5.1, randomForest package,pROC package), and the one-sided P value of AUC was assigned by bootstrapping (N = 2000).
Results
PM2RA identified key microbes involved in human diseases
CRC is a key example of the complex diseases associated with the dysbiosis of gut microbiota. An RA network of 97 bacterial genera and 607 significantly altered associations was built(Figure 2A) for a published CRC dataset [31]. Thirtheen genera with abundance changes were found to be involved in the RA network. The hub genera with the five largest degrees of topology were identified as Porphyromonas, Parvimonas,
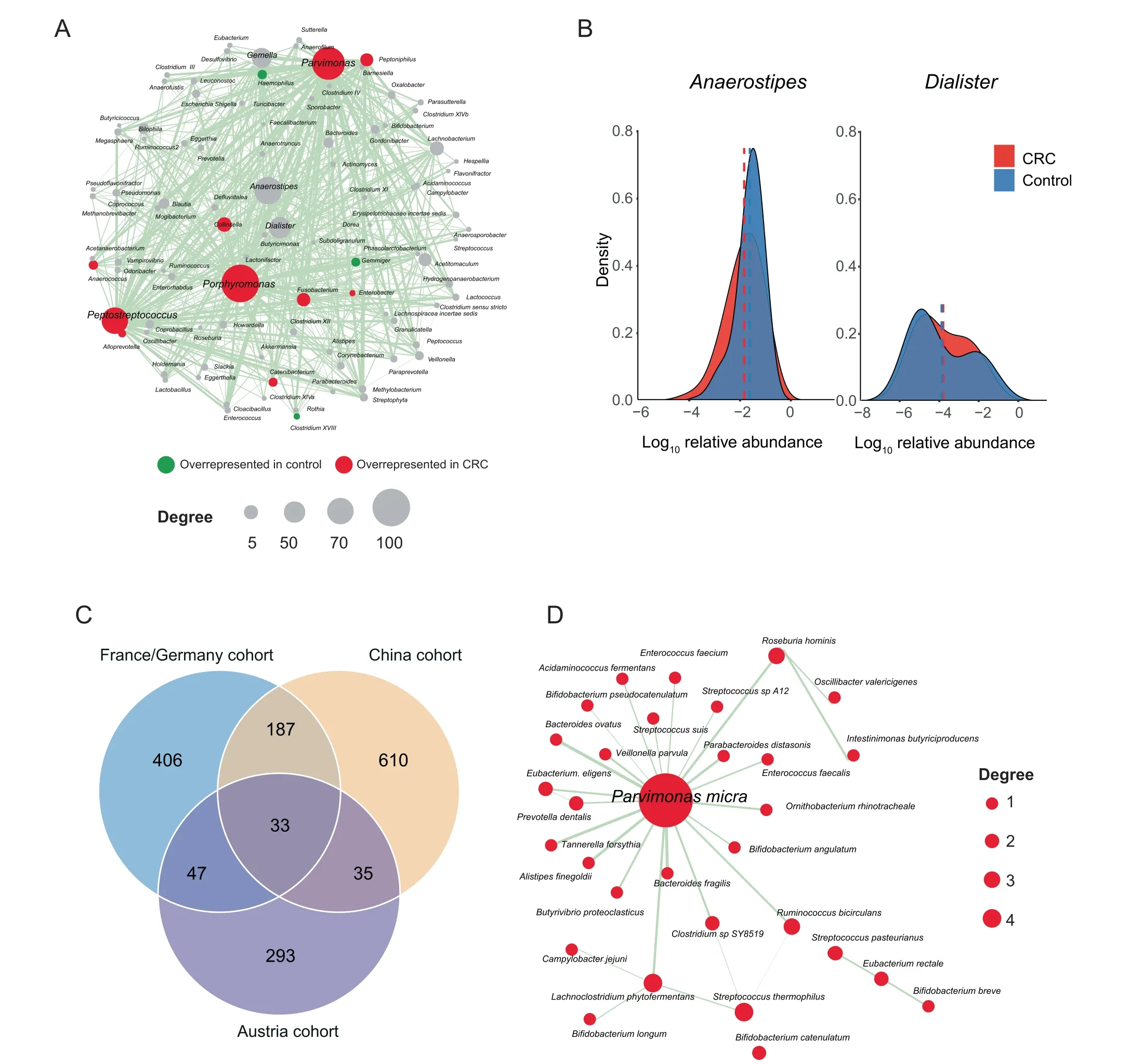
Figure 2 PM2RA detected common RAs in different CRC cohortsA.The RA network for a CRC cohort(case=120,control=172).The node color represents the abundance difference between the case and control samples: red for microbes overrepresented in the CRC samples, green for microbes overrepresented in the control, and gray for microbes not differentially represented. The node size is proportional to the topological degree in the network, and the edge width is proportional to the value of PM score.B.No abundance difference between CRC and control samples for Anaerostipes and Dialister.C.Thirty-three common RAs across the three CRC cohorts from Austria(case=46,control=63),China(case=73,control=92),and France/Germany (case = 88, control = 64). D. The common RA network among the three CRC cohorts. CRC, colorectal carcinoma.
Peptostreptococcus, Anaerostipes, and Dialister (Figure 2A).Accumulating evidence has shown that Peptostreptococcus,Porphyromonas, and Parvimonas are overrepresented in CRC and promote the progression of oral cancer and other cancers of the upper digestive tract [34,35]. Although the other two hub genera, Anaerostipes and Dialister, showed no difference in average abundance between the control and CRC groups(Figure 2B),their associations with many other microbes were significantly altered (Figure 2A, Figure S1). Anaerostipes species (e.g., Anaerostipes butyraticus, Anaerostipes caccae, and Anaerostipes hadrus) are butyrate-producing bacterial species that play a key role in the maintenance of gut barrier functions [36]. Dialister is reported to be overrepresented in oral cancer[37].Therefore,this result implicated that PM2RA can help find bacteria that affect CRC progression more accurately by searching for the RAs between microbes.
The gut microbiome is highly dynamic and can be influenced by cohort-specific noise. Thus, the results from differential abundance analysis may not be reproducible across different populations [38]. To investigate the robustness of PM2RA, we applied it to the metagenomic sequencing data of CRC patients and control subjects from Austria, China,and Franch/Germany cohorts [5] (Figure S2A–C).Thirty-three common RAs were observed across the three cohorts (Figure 2C). Consistent with the results obtained from 16S rRNA sequencing data, Parvimonas micra was identified as the top hub in the common RA network(Figure 2D). For example, the associations involving Parvimonas micra were extensively altered in the CRC group compared with the normal controls across the population.However, when measured by differential abundance, only three bacterial species were commonly detected in all three cohorts (Figure S2D), indicating that PM2RA methodology is robust in identifying RAs.
We further assessed the robustness of PM2RA by investigating whether a common RA network can be observed in related diseases. PM2RA was applied to three closely linked metabolic disorders:overweight,obesity,and diabetes.No significant RAs or differential microbes were identified in the overweight cohort [normal: body mass index (BMI) < 25;overweight: 25 < BMI < 30], indicating that BMI is not an informative index to assess a person’s disease state as has been previously reported[39].In the obesity dataset(BMI>30),an RA network of 85 altered associations and 97 bacterial genera was observed, with Roseburia having the most extensively altered associations among all the genera (Figure 3A). Moreover, in diabetes cohorts A and B [40], there were 49 and 45 association changes involving Roseburia spp., respectively. In diabetes cohort A, Roseburia intestinalis dominated the RA network (Figure 3B), while in diabetes cohort B, Bifidobacterium longum was the top hub species(Figure 3C).The clinical information showed comparable BMIs but indicated a lower severity of dyslipidemia in diabetes cohort B. Studies have reported that Bifidobacterium spp. have anti-obesogenic or anti-diabetic potential [41]. The activated association changes with Bifidobacterium longum in diabetes cohort B may, therefore,be one explanation for the observed difference in dyslipidemia. By combining the three datasets, common association changes between Roseburia spp. and Ruminococcus spp. were identified, as well as changes between Roseburia spp. and Bilophila spp. (Figure 3D). Roseburia is a major butyrateproducing genus, and the modification in Roseburia spp. may affect various metabolic pathways [42]. In agreement with the PM2RA analysis, animal experiments have demonstrated that Roseburia spp. can regulate the host immune system and reduce intestinal inflammation, which is also a marker of obesity and metabolic dysfunctions [43,44].
Taken together, the consistent results obtained in datasets using different sequencing strategies and different cohorts indicate the robustness of PM2RA in identifying RA networks in various diseases.
HD PM2RA analysis complements to 2D scanning
Associations between microbes are not necessarily structured in a paired way,and multiple microbes can form closely interacting sub-communities. The ability of PM2RA to quantify RAs involving multiple microbes makes it applicable to identifying RAs in such communities. We, therefore, tested the performance of PM2RA in HD microbial communities in the datasets mentioned above. By applying the greedy algorithm,HD RAs (FDR < 0.05, PM score > 0.6) were identified in all datasets except for the obesity and overweight datasets(Table S2).Most modules contained more than two microbes,indicating potential associations among multiple bacteria.Furthermore, many HD RAs contained microbe pairs that were not significantly altered at the 2D level (Figure 4A and B),illustrating the great ability of PM2RA to detect weak change signals in HD microbial communities under different conditions, which have usually been ignored by 2D scanning(Figure 4C). These results suggested that PM2RA is a promising method to quantify 2D and HD microbial RAs.
PM2RA outperforms other methods in the RA network inference
In a traditional workflow(Figure 5A,left panel),the microbial co-occurrence networks are constructed from the pairwise correlation, inverse covariance, or other statistics based on the microbial abundances in the case and control samples, respectively. The networks are then further compared by alignmentbased or alignment-free methods. There are three drawbacks inherent in this pipeline. First, it is based on the pairwise correlation network, but it is unclear whether the correlation is a proper measure of association. Second, the association of microbiota is not necessarily dual. For example, multiple bacteria could form a tight community with weaker associations between any two members within it. Thus, the pairwise relationship analysis might ignore some functional associations consisting of multiple microbes. Third, this comparison can neither quantify the association changes between conditions nor quantify the degree of association changes. But rather,as shown in Figure 5A (right panel), PM2RA directly compares the RA(s) among two or more microbes between conditions,does not need to build a co-occurrence network like that of the traditional methods, and quantifies the RA as a PM score.
To evaluate the performance of PM2RA with realistic synthetic microbiome data, we generated the artificial datasets based on a real microbiome dataset (see the Method section for details). PM2RA and the other two methods, which were widely used to infer co-occurrence networks (i.e.,SPIEC-EASI [45] and SparCC [46]), were applied to these datasets. The average FPR of PM2RA was significantly lower than those of the co-occurrence-based methods [PM2RA:0.1%; SPIEC-EASI (mb-based): 2.1%; SPIEC-EASI (glassobased):2.0%;SparCC:7.3%](Figure 5B;Table S3),indicating its high specificity. Additionally, PM2RA showed a significantly lower FNR than the co-occurrence-based strategies[PM2RA: 33.5%; SPIEC-EASI (mb-based): 87.6%;SPIEC-EASI (glasso-based): 87.3%; SparCC: 82.1%](Figure 5C; Table S4). The FNR of PM2RA is dumbbellshaped (Figure 5C), suggesting that it is affected by the effectiveness of the case datasets,and is sensitive to the correlations missed by SPIEC-EASI and SparCC (see the Discussion section for details).
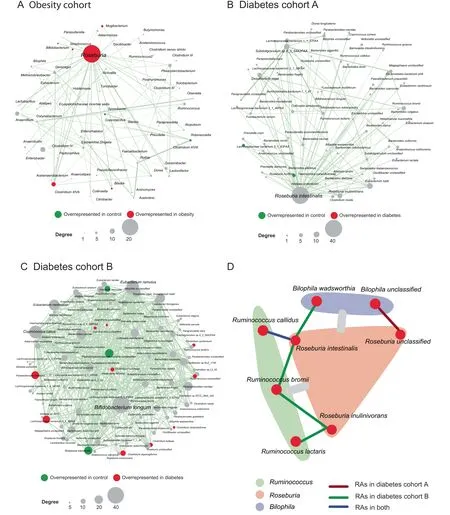
Figure 3 PM2RA detected common RAs in multiple metabolic diseasesA.The RA network for obesity(case=193,control=451).B.and C.The RA networks for diabetes cohorts A(case=57,control=79)and B (case = 99, control = 99), respectively. D. The common RAs observed in obesity and diabetes datasets. The gray bars between Roseburia (colored as a pink module) and Ruminococus (colored as a green module) and between Roseburia and Bilophila (colored as a purple module) represent the common association changes observed across the obesity and diabetes datasets at the genus level. The red,green, and blue lines between species represent the association changes observed in diabetes cohort A, B, and both, respectively.
Figure 4 The HD PM2RA analysis is complementary to 2D scanningA.and B.Examples of HD RAs.The lines between microbes represent the RAs detected with 2D scanning,and the PM score denotes the RA value for the module consisting of the presented microbes.C.The distribution of the T2 statistics for 2D scanning(Erysipelotrichaceae incertae sedis and Dialister)and HD module shown in(B)in the case and control samples.The non-overlapping area(PM score)is larger in the HD module.
The compositional data is widely used in microbiome data analysis. However, it has been proposed that it could produce superior results in correlation analysis [47]. Therefore, to test the effect of compositional data on PM2RA performance, a centered-log-ratio (clr) transformation [47] was applied to the abovementioned artificial datasets. A similar FPR(P = 0.11) was observed when applying PM2RA to the compositional and clr-transformed data(Figure 5B).However,the FNR of PM2RA on the compositional data was significantly lower than that of the clr-transformed data (33.5% vs.43.4%;P=3.852E–08)(Figure 5C).Taken together,the analysis showed that the compositional data were preferred in PM2RA to the clr-transformed data.
NetShift is a co-occurrence-based method developed to quantify rewiring and community changes in microbial association networks between health and disease states [48]. It was designed to produce a score that identifies important microbial taxa that serve as ‘‘drivers” from the first state to the second.NetShift was applied to the datasets of CRC (Figure S3A–D)and metabolism disorders(Figure S4A–D)as mentioned above.Two common driver species were identified across the three CRC cohorts from Austria,China,and France/Germany(Figure S3E),that is Butyrivibrio proteoclasticus and Streptococcus pyogenes.However,the previously identified microbes involved in the disease, such as Bacteroides fragilis, Fusobacterium nucleatum, Porphyromonasa saccharolytica, Parvimonas micra,Prevotellaintermedia,Alistipes finegoldii,and Thermanaerovibrio acidaminovorans[5],were not captured.On the other hand,five out of the seven previously identified species were commonly detected across three CRC datasets by PM2RA (Figure 2D).More than 40% of the NetShift-identified drivers were shared by the obesity and overweight samples (Figure S4E), and four drivers were shared by the two diabetes datasets(Figure S4F),
i.e., Alistipes shahii, Anaerotruncus colihominis, Eubacterium hallii, and Eubacterium ventriosum. However, few of these drivers are associated with metabolism disorders.For example,the oft-reported species, Ruminococcus. spp. and Roseburia.spp.,were detected by PM2RA(Figure 3D)but not recognized as drivers by NetShift.
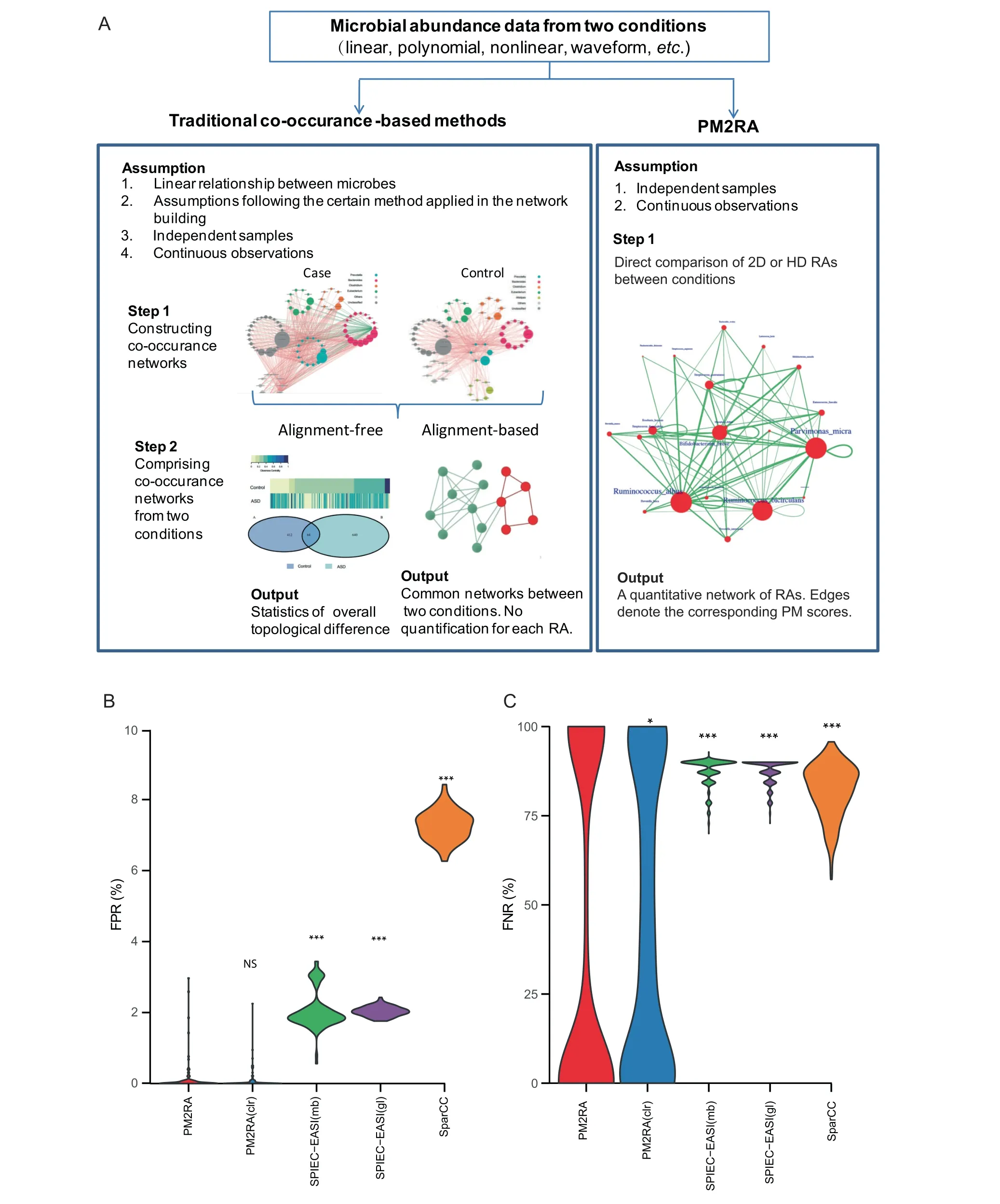
Figure 5 Comparisons between PM2RA and the co-occurrence-based methodsA.The difference and advantage of PM2RA comparing to traditional co-occurrence-based methods.B.and C.Comparison of the FPRs(B)and FNRs(C)of different methods in detecting RAs.PM2RA indicates PM2RA applied to compositional data;PM2RA(clr)indicates PM2RA applied to centered-log-ratio transformed data; SPIEC-EASI(mb) indicates SPIEC-EASI with the neighborhood selection method mb; SPIEC-EASI(gl) indicates SPIEC-EASI with the covariance selection method glasso. The difference was compared between PM2RA and other methods using the Mann–Whitney U test.*,P<0.05;**,P<0.01;***,P<0.001;NS,not significant.FPR,false positive rate; FNR, false negative rate.
PM2RA is a good feature extraction tool in distinguishing case and control samples
To test whether the microbial relationship represented in PM2RA (by Hotelling’s T2statistics) captured important information that distinguished case samples from control samples, we generated RF models using multiple types of inputs from the abovementioned datasets: the total microbe abundance (RF-A), microbe abundance of drivers detected by NetShift (RF-N), and the Hotelling’s T2statistics of paired microbes (RF-P). The RF-P model achieved higher AUC values on the ROC curves than the RF-A model in two of the seven datasets (Figure 6). In the comparison of RF-P and RF-N models,significantly higher AUC values were observed in the six of the seven datasets (Figure 6), indicating that the RA revealed more information than the abundance shift of drivers identified by the co-occurrence-based method in the pathogenesis of these diseases.Besides,the hub microbes in the RA network were highly overlapped with the microbes with the highest importance scores in the RF-A model(Figures S5 and S6).In the 16SrRNA CRC dataset,the top three hub microbes (i.e., Porphyromonas, Parvimonas, and

Figure 6 The RF model of PM2RA distinguished case and control samplesp and P denote the P values for comparison between Hotelling’s T2 statistics (RF-P) with total microbe abundance (RF-A)and microbe abundance of drivers detected by NetShift (RF-N), respectively. RF, random forest.
Peptostreptococcus) (Figure 2A) were ranked as three of the top four important features in the RF-A model (Figure S5A).Parvimonas micra, the most notable hub microbe commonly detected in multiple CRC datasets(Figure 2D),was among the top five most important species in three CRC cohorts from Austria, China, and France/Germany (Figure S5B–D). The Roseburia and Bilophila species,which were commonly detected in obesity and diabetes cohorts by PM2RA (Figure 3D), were identified by the RF-A model as top features(Figure S6A–C).However, the Ruminococcus species identified by PM2RA was not recognized as a top feature in the RF-A model,which may represent the additional information captured by PM2RA that contributed to its higher classification power.These results suggested that the Hotelling’s T2statistic transformation in PM2RA not only preserves the most important feature that distinguishes health and disease statues but also provides extra information underlying the pathogenesis of human diseases.
Discussion
Microbial association analysis is an important complement to the differential abundance analysis in the study of gut microbiota dysbiosis in diseases. In the current study, we developed an innovative analysis method to detect and quantify microbial RAs. PM2RA measures the RAs of microbial subcommunities, without initially constructing a co-occurrence network for each condition. We demonstrated that PM2RA has higher sensitivity and specificity than the traditional cooccurrence-based methods. The RF analysis revealed that the microbial RA represented by PM2RA distinguishes disease and health statuses more robustly than the abundance shift of driver microbes identified by co-occurrence-based methods.Furthermore, the applications of PM2RA in several disease datasets demonstrate the robustness of PM2RA.
In our applications, PM2RA showed biologicalreproducible results in datasets with sample size ranging from tens to hundreds.However,since PM2RA calculates RAs based on the projection distributions, the larger the sample size, the more precise the distribution estimation.We recommend applying it to datasets with more than 30 samples for each of the compared conditions.It is hard to define the true positive RA when evaluating the sensitivity of PM2RA,due to the lack of statistical methods to define and quantify RAs.We used SPIEC-EASI and SparCC to define ‘‘uncorrelated” microbes and interchanged the abundances of any two uncorrelated microbes to generate the case datasets.However,some types of correlations can still be neglected,thus rendering the exchange not fully effective.Therefore,the results might have shown an underestimated sensitivity. The FNR of PM2RA is dumbbell-shaped (Figure 5C),suggesting that the FNR of PM2RA is affected by the effectiveness of the case datasets.A low FNR will be observed when the exchanged OTUs are independent of each other;otherwise, PM2RA recognizes the relationships between them and most other species as similar, resulting in a high FNR. These results also indicated that PM2RA is sensitive to the correlations missed by SparCC and SPIEC-EASI.
The abundance of microbial OTUs from amplicon-based datasets is usually compositional,where counts are normalized to the total number of counts in the sample. Applying traditional correlation analysis to such data may produce spurious results [47]. Because PM2RA detects RAs without constructing co-occurrence networks, the influence of compositional data on its results is small.Therefore,a comparable specificity was observed when applying PM2RA to the compositional data and clr-transformed data of the synthetic datasets. However, the sensitivity of PM2RA with the clr-transformed data was significantly lower than that with the compositional data.This result might be due to the alteration of the abundance baseline caused by transformation and the subsequent impact on the relationships inherited by the raw abundance data.
Notably, we considered no environmental factors that could lead to possible overdispersion of the microbiome data in PM2RA. Since the purpose of PM2RA is to compare relationships of microbes between two conditions,generally,given the experimental designs of most of the case-control studies,the samples sequenced in each condition were similar in other factors, such as distributions of age and gender and environmental factors, except for the designed factor. Therefore, in the detection of RAs,the effects of other factors on the differential correlation between two conditions were ignored.Mathematically, we simply removed the outliers when calculating the PM scores. However, considering the overdispersion caused by the environmental factors that might be ignored or not well-balanced in the experimental designs may be a way to improve the performance of PM2RA further.
In conclusion, PM2RA is a novel method for identifying and directly quantifying RAs in microbial communities.It circumvents the drawbacks of the co-occurrence-based methods.Applying PM2RA to multiple human diseases reveals biologically significant results. The ability of PM2RA to detect community-level dysbiosis may make PM2RA a useful tool for exploring the functional alterations of microbes as a whole in a variety of diseases or biological conditions, to provide additional hints about the pathogenesis of human diseases.
Code availability
The source code of PM2RA and additional codes and datasets used in this work are available at https://github.com/Xingyinliu-Lab/PM2RA. A web-based PM2RA service is available at http://www.pm2ra-xingyinliulab.cn/.
CRediT author statement
Zhi Liu: Investigation, Validation, Formal analysis, Writing -original draft,Writing-review&editing.Kai Mi:Conceptualization, Methodology, Software, Investigation, Writing - original draft, Writing - review & editing. Zhenjiang Zech Xu:Validation, Writing - review & editing. Qiankun Zhang: Validation. Xingyin Liu: Conceptualization, Project administration, Investigation, Writing - review & editing, Supervision,Validation, Funding acquisition. All authors read and approved the final manuscript.
Competing interests
The authors declare that they have no conflict of interest.
Acknowledgments
This work was supported by the National Natural Science Foundation of China (Grant Nos. 81671983 and 81871628),the Natural Science Funding from Jiangsu province, China(Grant No. BK20161572), the starting package from Nanjing Medical University, China, and the starting funding for the team of gut microbiota research in Nanjing Medical University, China.
Supplementary material
Supplementary data to this article can be found online at https://doi.org/10.1016/j.gpb.2020.07.005.
ORCID
0000-0001-9785-9150 (Zhi Liu)
0000-0002-2497-0314 (Kai Mi)
0000-0003-1080-024X (Zhenjiang Zech Xu)
0000-0002-2956-4446 (Qiankun Zhang)
0000-0001-8770-3494 (Xingyin Liu)
杂志排行

Genomics,Proteomics & Bioinformatics的其它文章
- Global Profiling of the Lysine Crotonylome in Different Pluripotent States
- Gigantic Genomes Provide Empirical Tests of Transposable Element Dynamics Models
- Acknowledgments to Reviewers 2020
- Quantitative Secretome Analysis Reveals Clinical Values of Carbonic Anhydrase II in Hepatocellular Carcinoma
- Chinese Glioma Genome Atlas (CGGA):A Comprehensive Resource with Functional Genomic Data from Chinese Glioma Patients
- An Integrated Systems Biology Approach Identifies the Proteasome as A Critical Host Machinery for ZIKV and DENV Replication