多特征融合的道路场景语义分割算法
2021-12-02谷湘煜刘晓熠周仁彬
谷湘煜,刘晓熠,周仁彬
(深圳市朗驰欣创科技股份有限公司成都分公司,成都 610000)
图像语义分割是模式识别及计算机视觉领域中的一个极为重要的研究课题,是计算机场景理解的核心技术之一[1]。所谓语义分割是根据图像中的各个像素所表达语义含义的不同来进行区分,将图像划分成不同的语义对象,即将图像中各个像素进行分类[2]。而随着近几年深度学习在计算机视觉领域的不断突破,语义分割技术被广泛地应用于各个领域,如自动驾驶[3]、机器人自主导航[4]、医学影像分析[5]等。对于自动驾驶和机器人导航定位而言,基于道路场景的语义分割技术是实现自主行驶的重要辅助手段,通过对图像中道路、行人、建筑等相关目标进行精确分割,为自动驾驶汽车或机器人提供可靠的路况信息,进而保障其能够安全行驶。而在现实道路场景中,由于图像中目标相似性、场景复杂性以及图像获取质量等因素都极大地限制了图像分割的效果,无法较好地落地实际应用中。由此可见,如何提高语义分割技术在道路场景中的应用效果对于自动驾驶以及机器人自主导航都是极具挑战的研究课题,具有十分重要的研究意义以及实用价值。
为有效提升道路场景语义分割的效果,研究人员从不同角度进行了大量的工作,并取得了不错的效果。根据语义分割技术发展演变历程来看,这些工作可以大致分为传统语义分割算法和基于深度学习的语义分割算法。传统的语义分割算法主要根据图像红绿蓝(red-green-blue,RGB)颜色、纹理、灰度、几何形状等特征信息将图像分割成各个不同区域。Zhang等[6]提出了一种基于随机森林语义分割算法,利用图像局部特征直方图探索语义上下文的相关性进行建模,并通过利用随机森林进行分类加权构建语义分割结果。Pont-Tuest等[7]通过将轮廓检测方法与分离器结合,提出了修正共轭梯度(modified conjugate gradient,MCG)算法,利用轮廓检测算法将图像分割成多个块状再利用随机分类器进一步分割,实现图像语义分割。传统分割方法的结果相对粗糙,精度不高,但效率较高且实现较为简单。而基于深度学习的方法主要利用自主学习方式来提取图像特征,通过不断训练实现对图像像素分类。Badrinarayanan等[8]提出基于编码-解码方式SegNet网络,通过对图像卷积编码得到稀疏特征图后再反卷积恢复成稠密分割图。Xue等[9]提出了一种基于多层次函数、多尺度的生成对抗图像分割网络模型,通过利用判别器深入学习图像分割过程中的局部属性以及全局结构,进而获取像素间的相对关系,实现像素分类。基于深度学习的语义分割算法其分割精度与模型复杂度基本成正比,因此,相对于传统方法尽管其精度较高,但模型效率以及可解释性较差,这也一定程度限制了基于深度学习的语义分割方法落地。
针对上述情况,现借鉴传统的图像分割中特征提取技术与深度学习算法相结合,设计出一种多特征融合的道路场景语义分割网络模型。该模型通过颜色空间转化、灰度均衡、边缘检测、图像锐化等传统机器视觉处理方法来增强图像关键信息,再利用深度可分离卷积提取目标特征,同时结合边缘检测支路来细化图像中各个目标边界,进而实现高效分割。通过在公开标准道路场景数据集和实际变电站道路场景上的测试,有效验证所提模型的可行性以及实用性。
1 道路场景语义分割网络
1.1 网络整体框架
所设计的道路场景语义分割网络模型整体结构如图1所示。该模型主要分为3个模块:图像特征增强模块、语义分割子模块以及边缘检测融合模块。图像特征增强模块主要利用传统计算机视觉图像处理方法对原始图像分别进行颜色空间转化、直方图均衡化、边缘检测等操作,使输入图像中目标信息更突出、边界更清晰,并降低噪声以及光照等因素的影响。语义分割子模块主要利用卷积编码结合跳层上采样方式获取初步语义分割结果。卷积编码结构采用深度可分离卷积对增强后的图像进行特征提取,保证网络效率;而跳层上采样通过逐步上采样操作将深层特征与浅层融合,保障目标准确分割。边缘检测融合模块则是通过学习各个目标边缘信息,再与初步分割结果图融合,细化各目标边界信息,实现更精确的分割。

图1 网络结构框图Fig.1 The structure diagram of network
1.2 特征增强模块
图像特征增强模块主要是对图像进行预处理,传统的针对深度学习的图像预处理大多是对图像进行裁剪、旋转、平移、模糊处理、高斯噪声等操作,通过对图像中的目标进行一定程度的破坏或引入噪声的方式来模拟现实场景中摄像机可能采集到的图像情况,同时也扩充了数据集,进而提升网络识别精度以及泛化能力。而所设计的图像特征增强模块与上述传统深度学习图像预处理思路相悖,该模块核心在于增强图像中各个目标特征信息,提高后续语义分割网络对有效信息的获取,并降低图像噪声对网络的影响,从而提升对目标的识别准确率,模块结构如图2所示。该模块主要在图像颜色空间、边缘信息、对比度3个方面进行增强,颜色空间除了RGB原图外还引入了色调-饱和度-明度(hue-saturation-value,HSV)颜色空间,使网络能从红、绿、蓝、色调、饱和度、明度6个颜色通道获取目标信息,使获取的特征维度更高;边缘信息通过边缘检测以及图像锐化的方式进行提升,考虑到算法检测效率,采用Canny边缘检测和Laplacian图像锐化算法;图像对比度增强主要是利用灰度图像直方图均衡化算法,通过调整图像各像素灰度来增强动态范围较小的图像对比度,在一定程度上降低光照对图像的影响。

图2 特征增强结构Fig.2 Feature enhancement structure
1.3 语义分割子模块
目前,基于监督学习的典型语义分割网络大致分为以下几类:基于扩大感受野的网络结构(如DeepLab[10])、基于概率图模型的网络结构(SegModel[11]、DFCN-DCRF[12])、基于特征融合的网络结构(如FCN[13],ICNet[14],APCNet[15])、基于编码器-解码器的网络结构(如SegNet[8],UNet[16])、基于循环神经网络的网络结构(如CRFasRNN[17])以及基于生成对抗网络的网络结构(如Segan[9])等。尽管网络结构不同,但其核心设计思路相似,即准确获取全局目标类别和局部目标边缘特征信息并通过一定策略进行融合。基于此设计思路,搭建的道路场景的语义分割网络采用多层卷积结合跳层上采样的结构来构建。由于特征增强模块增强了目标间差异并细化目标边缘,因此语义分割子网络关键在于尽量准确获取各目标全局和局部信息。同时,考虑到网络效率,网络卷积部分采用深度可分离卷积对特征增强后的图像进行分层卷积再融合,对融合后的特征图再由具体到抽象进行逐层卷积操作,可以在保证效率的同时较好的获取目标特征;而跳层上采样结构则是通过上采样的方式将深层次的目标类别信息与浅层目标边界信息融合,从而实现语义分割。
语义分割子网络主要分为卷积部分和上采样部分,卷积部分由init结构和多个stage模块串联构成;上采样部分由多个upsample跳层卷积构成,如图3所示。init结构如图3(a)所示,由卷积和池化两条支路并列组成,卷积支路采用3×3深度卷积对特征增强后的图像特征分别提取;池化支路采用2×2的最大池化操作提取目标显著信息。由于特征模块增强模块已经对图像进行预处理,所以init结构两支路的操作皆设置步长为2,使其在提取有效特征的同时尽可能提高网络效率。stage模块由多个子模块堆叠而成,每个子模块也由两条支路组成,主要以深度可分离卷积为基础,如图3(b)所示。通过channel split操作将输入特征图均分成两部分,其中一部分利用1×1卷积结合深度可分离卷积提取目标信息;而另一部分特征图不做任何操作与卷积后的特征进行拼接,最后再利用channel shuffle操作混合特征之间信息,加强特征多样性。对于stage与stage之间的连接则调整深度卷积步长为2,并在无操作支路新增步长为2的最大池化,如图3(b)中虚线部分。上采样部分如图3(c)所示,主要通过将深层次的抽象类别信息逐步上采样与相对浅层的边缘信息融合。为了避免浅层信息噪声的干扰,只融合了stage5~stage2的最后一层,保证关键信息的充分利用,同时,该方式也降低了网络计算量,保证了网络效率。可以看出,整个语义分割子网络都是以高效率的卷积操作和设计结构为基础,降低网络对冗余信息的提取,保障整个语义分割网络的整体效率。网络具体结构如表1所示。
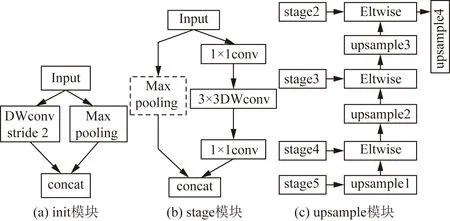
图3 特征提取模块Fig.3 Feature extraction module
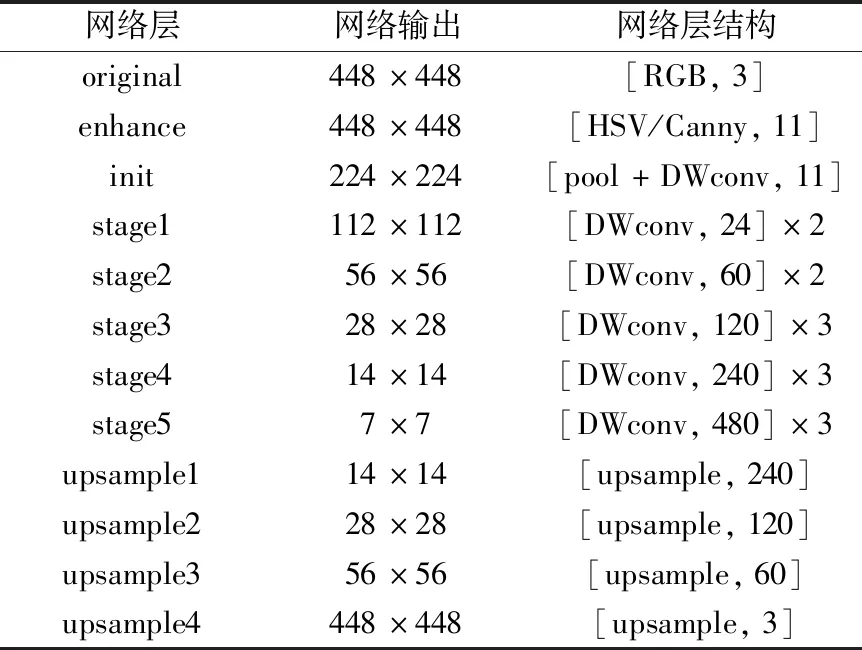
表1 语义分割子结构Table 1 Semantic segmentation sub-structure
1.4 边缘检测融合模块
通常,对于语义分割网络而言,网络对图像中各目标类别的识别相对准确,而不同语义分割网络之间精度的差距在于对各个目标边界的识别,准确的边缘信息可以很大程度提升分割精度。虽然特征增强模块中引入了锐化和Canny边缘检测,但该操作不仅对目标间的边缘信息进行了增强,也增强了目标内的边界,同时随着卷积操作的叠加,边缘信息也存在不断弱化的情况。基于此,设计了边缘检测融合模块,如图4所示。该模块分为边缘检测和边缘融合两部分,边缘检测可以看作是语义分割子网络的一个扩展分支,用于识别目标边界,其详细结构如图4(a)所示,首先提取特征增强模块中Canny边缘检测图像以及语义分割子网络中各个阶段的最后一层,利用点卷积进行特征融合;然后,利用上采样操作将不同维度的特征图恢复至原图大小,最后再通过点卷积融合各阶段的特征信息。边缘融合结构如图4(b)所示,主要是将边缘检测结果和语义分割子网络的分割结果相融合,细化目标边界的同时也优化目标边缘处各像素分类类别,进而提升各目标分割精度。具体融合过程首先利用concat操作对边缘和分割结果进行拼接;然后,采用3×3的多层卷积对两路特征进行融合,由于此时输入图像相对简单,为避免计算量过大,多次卷积特征图的个数分别为8、16、32和64;最后再通过softmax函数对各个像素分类,得到最终的语义分割结果。
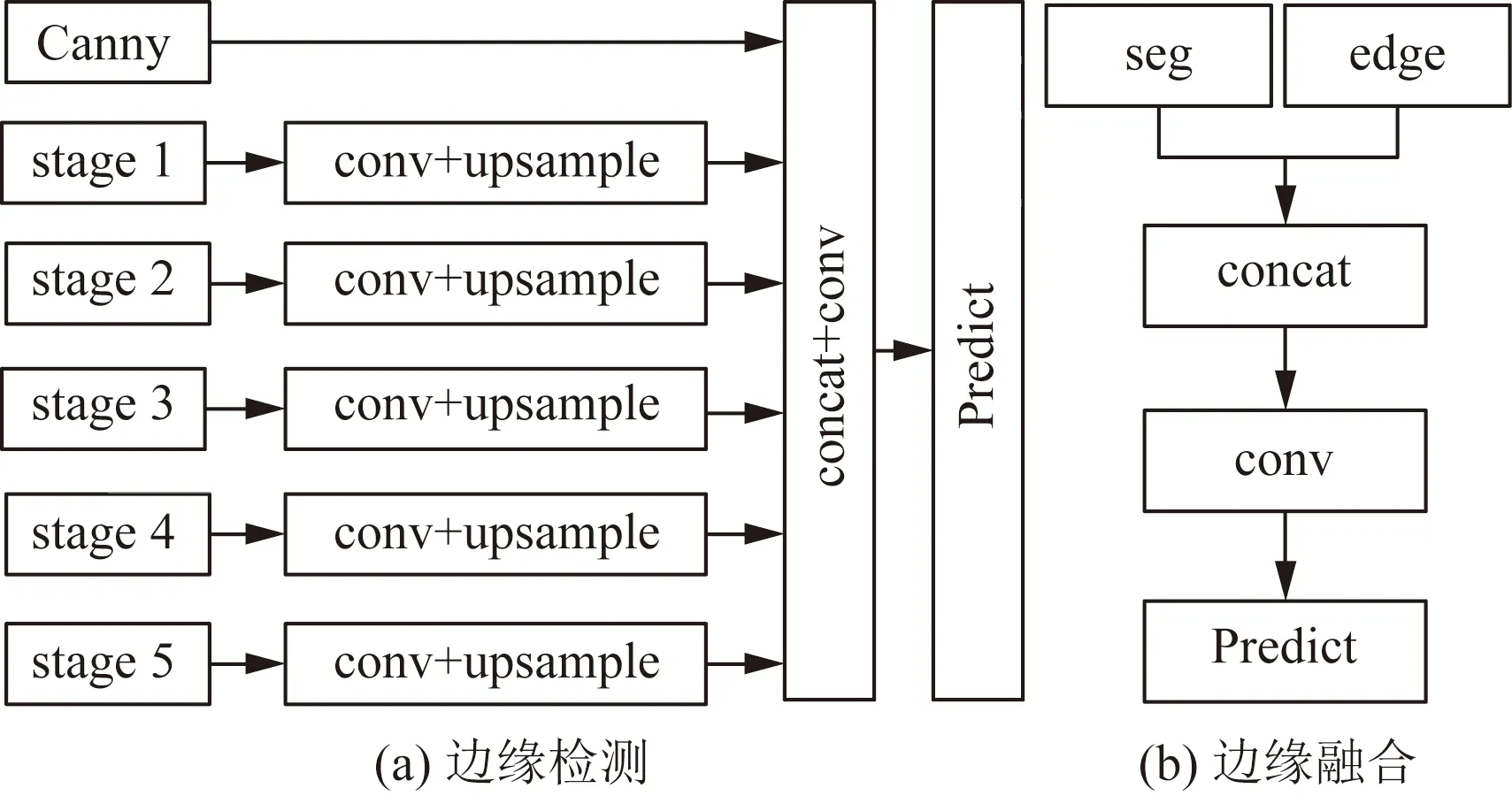
图4 边缘检测融合模块Fig.4 Edge detection fusion module
2 实验与结果分析
为验证所设计网络的有效性,采用CamVid和Cityscapes公开标准城市道路场景数据集以及实际变电站机器人巡检道路场景数据集,分别在搭载NVIDIA Tian Xp的台式机以及搭载NVIDIA Jetson TX2嵌入式平台的变电站巡检机器人上进行测试验证。实验环境采用Ubuntu16.04操作系统,通过Caffe深度学习框架搭建本文所提的网络结构,为了较好地与同类网络进行对比,网络训练时的超参数主要参考文献[8、18-20]中的参超设置。
网络训练过程中,采用SGD优化器调整网络参数;以step模式调整学习率,初始学习率设置为0.01,迭代3万次之后每迭代10 000次学习率下降10倍;优化算法采用Momentum动量法,参数设置为0.9;权值衰减系数weight_decay设置为0.000 5。由于网络中引入了边缘检测支路,因此,网络训练时的损失为语义分割和边缘检测损失之和,损失函数都采用交叉熵损失函数进行计算,区别在于边缘检测中图像像素目标类别只有两类,即边缘和背景;而语义分割则是实际图像标注的各目标进行分类。损失函数公式为
山洪灾害防御涉及社会的各个方面、各个部门,需要社会各部门通力协作。在统一规划的基础上逐步实现山洪灾害的综合治理。水利部门要依法加强河道管理,加强水土保持、小河流治理,做好河道的清障划界等工作。国土部门要指导居民主动避灾建房,做好山洪地质灾害的监测预报等工作。气象、水文、广电等部门要利用现代先进的设备,对每次暴雨信息在短时间内及时通报,如遇灾害性暴雨,所在地区通过应急系统 (如警报器)等设备通知当地政府和群众。

(1)

(2)
Lall=Ledge+Lseg
(3)
式中:aj为像素属于第j类的概率;T为类别数,边缘检测T为2,语义分割T为标注目标数;Sj为计算softmax值;yj为标签值;Ledge为边缘检测损失;Lseg为语义分割损失。
对于网络评价指标,主要采用全局精度(G)、平均精度(C)、平均交并比(mIoU)以及网络每秒处理帧数(FPS)来对网络性能进行度量。其计算公式为
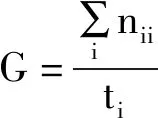
(4)

(5)
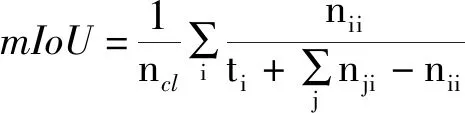
(6)
(7)
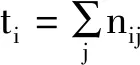
2.1 标准数据集
CamVid数据集是由剑桥大学从驾驶汽车的角度采集的不同时间段的城市街道道路数据集。该数据集共有701张图像,其中训练图像有367张,验证图像有101张,测试图像有233张,标注的目标包含了道路、树木、行人、车辆、建筑等11个类别,图像大小为480×360。该数据集数量及图像尺寸相对较小,可以快速验证网络设计过程中各设计策略对网络性能的影响。
Cityscapes数据集是另一个在语义分割领域广泛使用的城市道路场景数据集,包含了多个城市不同季节、背景、场景的街景,涵盖了现实城市街道中的各种复杂情况。该数据集包含5 000张高质量标注数据集,共19类目标,将其中2 975张用于训练,500张用于验证,剩下的用于测试,图像尺寸归一化为512×256。该数据集与CamVid类似,但场景更为复杂,可以较好地验证所提网络的泛化能力。
实验首先利用CamVid数据集在搭载Titan Xp的台式机上测试了特征增强结构中各个预处理操作以及边缘检测支路对网络精度的影响,实验结果如表2所示。由表2可以看出,通过引入图像增强模块和边缘检测模块对网络精度都有较大的提升,而两模块结合后的网络精度提升度最高,有效的验证了本文所提网络的可行性。由于CamVid数据集中,图像是基本为白天和傍晚采集,图像光照强度差别较大,因此在引入直方图均衡化操作后,降低了光照影响,网络精度提升较为明显;HSV颜色空间转化的引入相当于从另一个角度获取图像特征,主要是对RGB原图的扩充,尽管对网络精度有一定提升,但提升较少;锐化和Canny边缘检测虽然引入了部分目标内边界信息,但并不影响对整个图像的分割精度的提升,而边缘检测支路则会弱化目标内的边界而相对增强目标间的边界,对特征增强后的分割结果进一步优化处理,达到最优分割效果。由实验结果也看出3种增强边缘信息的策略并非冗余,而是相互之间特征互补。

表2 增强结构测试结果Table 2 Feature enhancement structures test results
为更好地验证所提网络的有效性,分别与多个同类型道路场景语义分割网络进行对比,对比结果如表3所示。

表3 CamVid数据集测试结果对比Table 3 CamVid dataset test results comparison
根据对比结果可以看出,本文网络相对于传统语义分割网络(SegNet),在精度与效率上都有较大提升,与当前高精度和高效率网络相比(ShuffleSeg/BiSiNet),网络以较小的时间代价,获得了更高的精度,整个网络有效地平衡了精度与效率之间的关系,使网络能更好地落地实际应用。
尽管所提网络在CamVid数据集上有较好的表现,但该数据集相对简单,为了进一步验证网络在复杂场景中的性能,实验利用Cityscapes数据集对网络的泛化能力进行了验证,实验结果如表4所示。同时,网络在CamVid和Cityscapes数据集上的分割效果如图5所示。
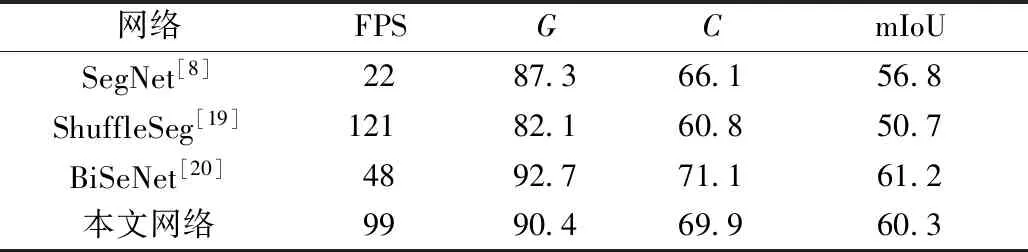
表4 Cityscapes数据集测试结果对比Table 4 Cityscapes dataset test results comparison
根据图5的测试结果可以看出,由于测试图像的道路场景复杂度提高,使网络的整体精度有所下降,但与其他网络相比,本文网络精度下降率相对较低,由此可见,本文网络具有更好的泛化性能,可以更好地应用于不同的道路场景中。
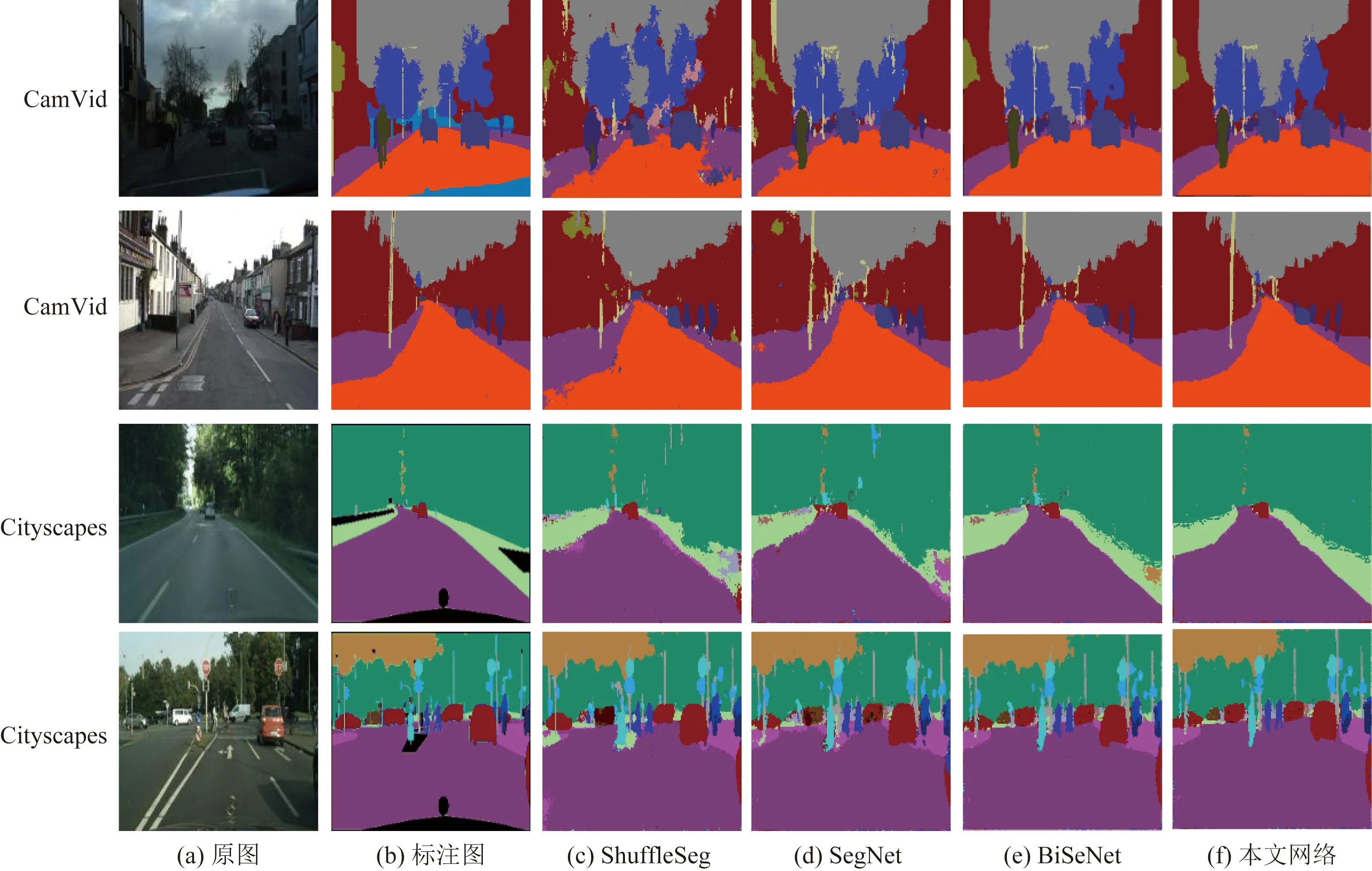
图5 标准数据集测试结果Fig.5 Standard data set test results
2.2 变电站道路场景
通过公开标准数据集,可以较好地从理论角度对本文网络进行验证。为了进一步测试网络在现实场景中的落地情况,以变电站道路场景为实验环境,将网络移植于搭载Jetson TX2的巡检机器人平台上,对机器人实际巡检过程中的道路场景进行语义分割。实验通过机器人搭载的相机获取不同时间、光照、天气的道路场景图像约5 000张,利用labelme标注工具将图像中的目标进行人工标注,主要包含道路、碎石、草、围栏等6类目标,并将图像尺寸统一为480×360大小,最后以7∶1∶2的比例将数据分为训练集、验证集和测试集,构建变电站道路场景数据集。利用该数据集对网络进行迭代训练,将收敛后的网络应用于巡检机器人,在实际巡检过程中进行测试,测试结果如表5和图6所示。

表5 变电站道路测试结果对比Table 5 Substation road test results comparison

图6 变电站道路检测效果Fig.6 Substation road detection results
根据上述实验结果可以看出,本文网络可以有效地应用于变电站场景中,而且由于变电站道路场景相对于城市街景较为简单,网络的分割精度与当前主流高精度网络的分割精度不相上下。在效率方面,尽管受限于Jetson TX2嵌入式平台性能,网络处理效率降低,但对于巡检速度相对较慢的变电站机器人而言,本文网络也基本满足其对实时性的需求,可以准确高效地实现道路场景语义分割。
3 结论
针对目前道路场景语义分割领域存在的问题与挑战,将传统图像处理方法与深度学习结合,提出了一种融合多特征的道路场景语义分割网络。该网络采用多种传统图像处理算法对原图中的重要特征信息进行提取和增强,保证后续特征提取的有效性和多样性;然后,利用基于深度可分离卷积的高效率特征提取结构对多维特征信息进行提取融合,并通过跳层上采样融合方式恢复目标信息,保障了网络的整体效率;同时,针对目标边缘特征引入了边缘检测网络支路,细化目标边界的分割结果,进一步提升网络分割精度。通过在公开道路场景数据集测试结果表明,本文网络以较小的计算代价最大化了分割精度,较好地平衡了网络精度与效率。同时,在实际变电站巡检机器人中,该网络也能实现高效的道路场景语义分割,为机器人提供可靠的场景信息。
尽管本文网络在道路场景语义分割取得了较好的结果,但仍有一些需要继续研究的地方。在之后的工作中,将继续探索如何以更少的计算量来获取图像多维特征;其次,将进一步发掘传统图像算法与深度学习的结合点,将不同方法进行优势互补,使网络能应用于更多的实际场景中。
