基于改进卷积神经网络的非合作无人机检测应用
2021-12-02赵宗扬柴兴华
叶 涛,赵宗扬,柴兴华,张 俊
(1.中国矿业大学(北京)机电与信息工程学院,北京 100083;2.中国电子科技集团公司第五十四研究所,石家庄 050081)
无人机由于具有在增加国防力量[1-2]的同时还可以进行自然灾害的监测与救援、代替人类执行高危任务并供人们进行拍摄和娱乐等优点,已迅速应用于国家和社会生活的不同方面。但无人机在为人们提供极大便利的同时,一些侵犯人们隐私、影响人们的日常生活的“黑飞”的无人机经常进入大众的视野,对公民的隐私及个人及公共安全造成了严重威胁,甚至还会有非法分子通过无人机携带危险物品来实施恐怖袭击。因此研究一种能够快速准确地检测无人机目标的理论和方法非常有必要,可以为无人机行动的防护压制提供精准依据以降低“黑飞”现象,进而保护公民隐私并维护公众的生命和财产安全,具有很现实的意义。
许多学者对无人机检测算法进行了大量的研究,无人机检测算法分为传统的无人机检测算法和基于深度学习的无人机检测算法。传统的无人机检测算法通常使用方向梯度直方图(histogram of oriented gradient,HOG)[3]与支持向量机(support vector machine,SVM)[4]等分类方法的组合实现特征的提取和目标类别的检测。然而,传统的特征提取方法存在着提取手工特征较为复杂、过于依赖设计者经验等问题,且不能自适应提取特征,迁移到其他场景的能力也差。而基于深度学习的目标检测算法可以通过卷积神经网络[5-7]自适应的提取特征且检测速度和精度都较高,近年来涌现出的单级多框预测(single shot multibox detector,SSD)[8]、YOLO(you only live once)[9-12]系列等性能优良的框架被广泛应用在目标检测中。李秋珍等[13]提出了两种基于SSD算法的实时无人机识别方法,一种是基于SSD获取视频流中的无人机位置,另一种方法是将SSD检测到的无人机目标图像进行微调,相比之下第二种方法的准确性较高,但对于在真实应用场景下无人机的识别率比较低、区分无人机种类的能力差,无人机的识别准确率仍有待提高。陈亚晨等[14]通过缩减YOLOv3的网络层数以提升检测速度,但算法的检测精度却有待提高,对小目标的检测能力也有待验证。马旗等[15]通过优化YOLOv3的残差网络及多尺度融合的方式提高了对低空无人机目标的检测精度,但其数据集的类别较为有限导致其检测性能受限且对处于夜间或较为昏暗的光线条件下的小目标无人机检测识别仍有待改进。陶磊等[16]采用改进的YOLOv3 模型检测视频帧中是否存在无人机,可以实现对无人机的实时检测,但其检测精度仍有较大的提升空间,且对小目标无人机的研究尚浅。综上所述,无人机目标检测算法的精度和实时性的平衡以及实现小目标准确高效的检测往往是算法难以解决的重点问题。
针对上述问题,为了在平衡算法的检测速度和精度的同时提高对小目标无人机的检测精度,现基于YOLOv3提出多尺度目标检测网络(multi-scale object detection network,MS-Net),实现检测精度和检测速度的良好平衡。该网络通过K-均值(K-means)聚类重新生成锚值更加精确的预测目标区域的位置,在特征提取部分插入空间金字塔池化(spatial pyramid pooling,SSP)[17]模块将局部特征和全局特征进行融合,实现多尺度图像特征提取的同时提升了分类精度;在检测部分提出增强压缩和激活(enhanced sequeeze and excitation,ESE)通道注意力增强方法重新分配权重,在基本不影响检测速度的同时提高模型的多尺度目标检测精度,在由无人机、风筝、鸟等组成的数据集上检测精度为91.39%,比YOLOv3提升了6.42%。检测速度为51 FPS,对实际应用中对低空无人机等“低慢小”目标的高精度实时性检测,为实现后续的防护压制提供重要依据。
1 模型设计
1.1 网络总体设计
多尺度目标检测网络借鉴了 YOLO 系列目标检测算法仅需要一次前向卷积运算就可以得到目标边界框和类别预测可能性,实现模型端到端训练的思想。图1阐述了多尺度目标检测网络模型的总体结构,该模型首先利用尺度缩放将输入图像缩放到固定分辨率(416×416),然后通过K-means聚类所得到的最优锚值和主干网络中的SPP模块对输入特征图像进行更为丰富精确的图像特征提取,进而产生不同大小的特征图,并利用ESE注意力增强机制和多尺度特征融合操作将不同特征图进行融合来进行目标分类与回归。
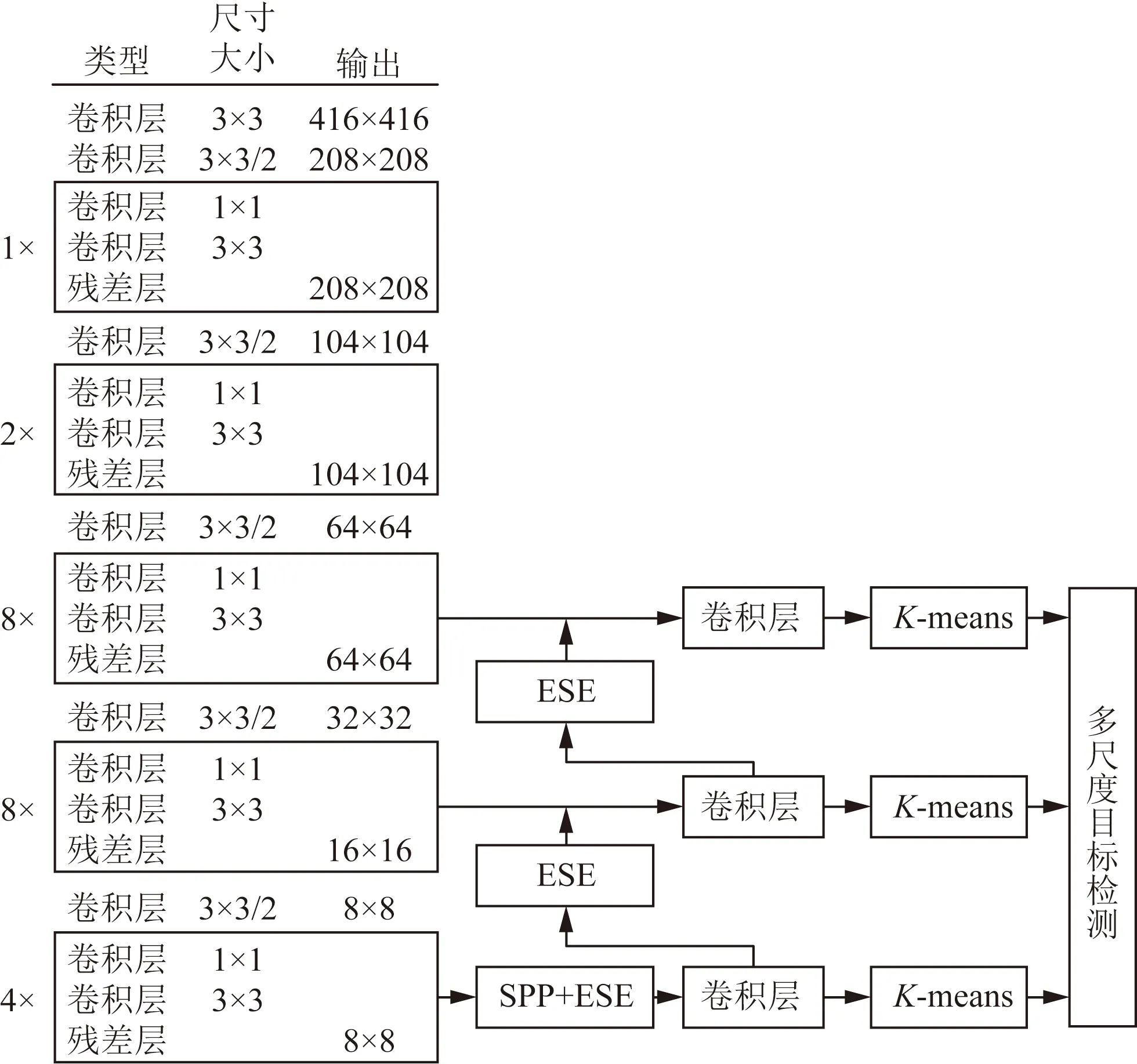
图1 MS-Net总体结构图Fig.1 The overall structure diagram of MS-Net
1.2 特征提取
1.2.1K-means聚类得到最优锚值
YOLOv3 会在每个网格单元上预测出3个锚盒,每个锚盒预测3个边界框,每个边界框会预测出4个值,分别为tx、ty、tw、th,若目标中心在单元格相对于图像左上角有偏移(cx,cy),如图2所示,则进行修正,其公式为

图2 锚盒修正Fig.2 Modification of anchor box
bx=σ(tx)+cx
(1)
by=σ(ty)+cy
(2)
bw=pwetw
(3)
bh=pheth
(4)
式中:pw和ph为网格对应锚盒的宽。
但YOLOv3中anchor值是根据COCO等开源数据集设定的,故使用了K-means聚类方法重新分析自己所制作的包含鸟、风筝、无人机三类检测目标数据集中真值框宽高、尺寸比例分布,根据式(5)不断迭代质心后找到合适的候选框种类组合重新确定anchor值,使得候选框的宽高维度对目标的轮廓形状具有更好、更有代表性的先验信息,从而在之后的回归计算对目标区域的位置的预测更加准确。锚盒的具体大小及分配情况如表1所示。

表1 改进后锚盒的尺寸Table 1 The sizes of the improved anchor boxes
d(box,centroid)=1-IOU(box,centroid)
(5)
式(5)中:box为数据集中的边框尺寸样本;centroid为每一类簇的中心尺寸数值。
1.2.2 SPP特征融合提升分类精度
为使全连接层的输入图像的尺寸固定,在对不同大小图像的预处理操作中会造成一定程度的图像失真。通过图3所示的SPP模块使用固定分块的池化操作,对不同尺寸的输入实现相同大小的输出,避免了图像失真,实现局部特征和全局特征融合并丰富最终特征图的表达能力,从而实现了检测精度的提高。

CBL表示Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成图3 SPP结构示意图Fig.3 Schematic diagram of SPP structure
1.3 多尺度目标检测部分
YOLOv3算法因计算速度快可以实现实际场景下的实时检测,但其在对整张图片进行特征提取和目标框的回归时易受到复杂背景的影响导致检测性能下降出现漏检和错检现象。针对这一问题,MS-Net中加入了ESE通道注意力模块,通过通道注意力[18]对卷积网络提取的特征进行选择,降低了复杂背景对检测结果的影响和漏检率,在基本不影响检测速度的同时提升了算法的小目标识别能力。
ESE模块如图4所示,将输入通道分为平均分为两个分支,分支一使用3×3的卷积进行特征提取,分支二使用5×5的卷积提取特征获得更大的感受野,最后将取得不同感受野的特征图进行融合,建立全局上下文关系,并建模通道之间的相互依赖关系,自适应地重新校准通道的特征响应,筛选出了针对通道的注意力,增加了极小的计算量,但提升了检测精度。ESE注意力机制模块的计算过程为
s1=g(F)
(5)
s2=ReLU(W1s1)
(6)
s3=Sigmoid(W2s2)
(7)
F=s3F
(8)
式中:F∈RC×H×W为输入特征图;函数g为平均池化操作;s1∈RC×1×1为平均池化后的输出;W1∈RC/16×C为全连接层FC1的参数,s2∈RC/16×1×1为经过FC1和ReLU函数处理后的输出;W2∈RC×C/16为经过全连接层FC2的参数;s3∈RC×1×1为FC2和Sigmoid函数处理后的输出。
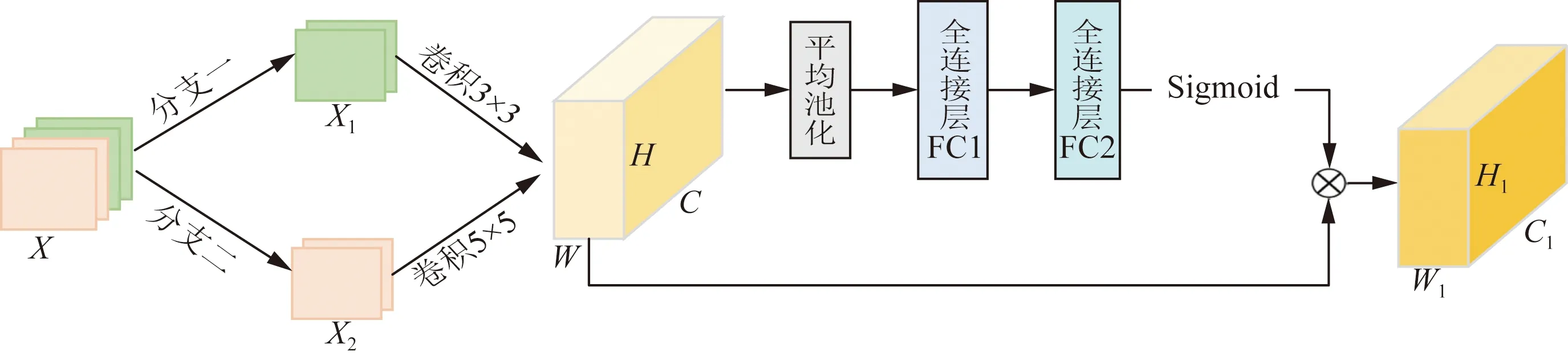
C、H、W分别为输入图像的通道数、高和宽;C1、H1、W1分别为输出特征图的通道数、高和宽图4 ESE模块结构图Fig.4 ESE module structure diagram
2 试验结果和性能分析
为了评估该目标检测模型的有效性,在包含无人机、风筝、鸟三类“低慢小”目标的数据集上进行了实验,并在多场景下进行测试。训练用服务器使用Intel© CoreTM i7-6950X CPU处理器,配备四块NVIDIA GeForce GTX 1080TI显卡,每块显卡内存11 G。实验在基于Ubuntu18.04操作系统下的Pytorch1.7.0深度学习框架上实现,采用GPU (GTX1080Ti)进行训练和测试。
2.1 数据采集
为评估SCS-Net对于“低慢小”目标检测的性能,建立了私有数据集。该数据集是通过采集真实场景中的视频和图像来获取的,包含了不同天气、光照和复杂背景的图像;然后利用视频抽帧方法生成了6 904张图片,将收集到的图像分为三类进行标注:无人机、鸟、风筝。将该数据集的70%图像用来进行训练和验证,30%图像用于测试。
2.2 实验结果分析
检测模型的主干网络是Darknet-53,测试图像的输入尺寸为416×416,采用尺寸为52×52、26×26、13×13的特征图来检测多尺度的物体。图像批处理量大小为32,优化方法为SGD,动量为0.9,初始学习率为0.001,所有实验的最大迭代次数为105。将SCS-Net的检测结果与SSD、YOLOv3-tiny和YOLOv3模型的检测结果作对比,使用平均精度(mean average precision,mAP)来评估模型的有效性并将最好的结果突出显示,实验结果如表2所示。

表2 模型试验结果对比Table 2 Comparison of model test results
实验结果表明:MS-Net在检测精度的性能明显优于其他模型,尤其针对风筝这一类其他模型识别精度较低的目标的识别能力很明显有着巨大的提升。而且还将MS-Net与不同的检测方法对比进行消融实验,实验结果如表3所示。结果表明:在检测精度方面,MS-Net相比于其他所有检测模型和方法在所检测的三类目标中都取得了最佳成绩,检测精度较其他模型有着显著的提高;在检测速度方面,由于MS-Net的网络层数较深,所以检测速度略有降低,但仍可以保证实时检测,符合工业现场的应用要求。

表3 消融试验结果对比Table 3 Comparison of ablation test results
将所提出的方法与不同模型进行比较,图 5显示了几种不同模型的对比结果。所有模型均在同一数据集上进行训练和测试。从左到右,每列分别表示YOLOv3、YOLOv3+SPP、YOLOv3+SPP+CBAM 和 MS-Net的检测结果。第一行中的目标较为清晰,此时4种网络模型都能对其进行准确地检测,但MS-Net具有最高的检测精度;第二行中的目标尺寸变化显著,且存在被遮挡的小目标,YOLOv3模型存在漏检现象,而MS-Net可以很好地检测出被遮挡的小目标,且精度较高;最后一行所检测的都是小目标物体,从检测结果可以看出,MS-Net对于小目标的检测能力较其他模型有着很大幅度的提升。实验结果表明,MS-Net能够有效地检测出各类目标的位置,具有较高的鲁棒性,特别是在多尺度或小目标的情况下。

图5 不同模型的检测结果Fig.5 Detection results of different models
2.3 不同场景的鲁棒性检验
该模型在不同环境下的鲁棒性分析如图6所示。图6(a)中由于光照较暗并存在着背景干扰,图像成像质量较差,而MS-Net仍可以很好地检测出无人机目标,且精度较高,即使是在图6(b)中阴暗环境检测目标较小时也能保证较高的识别精度。实验结果表明,MS-Net能够有效地检测出目标的位置,实现不同场景下的目标检测,并具有较高的鲁棒性,即便是昏暗环境下或存在背景干扰及多目标检测中,仍有着极强的小目标识别能力,在满足实际应用中实时性检测要求的同时有着较高的检测精度。

图6 不同场景的鲁棒性测试Fig.6 The robustness test in different scenario
3 结论
针对“黑飞”无人机侵犯公民隐私、危害个人及公共安全,而现有的无人机检测算法难以平衡检测速度和精度且对小目标的检测精度较低等问题,提出了一种基于 YOLOv3 的无人机目标检测算法MS-Net,经过理论分析和实验验证,得到以下结论。
(1)使用SPP将局部特征和整体特征相融合,提升网络的特征提取能力,并使用K-means聚类生成最优锚值在之后的检测中更加精确的预测目标区域,提高检测精度。
(2)提出了ESE通道注意力机制,使用不同尺寸的卷积建立全局上下文关系,并建模通道之间的相互依赖关系,自适应地重新校准通道的特征响应,在保证检测速度的同时提升了检测精度。
(3)MS-Net在低空数据集上以 21 ms 检测每张图片取得了91.39%的检测精度,检测精度比 YOLOv3 网络提高了6.42%,特别是在无人机目标上的检测精度提升了7.42%,检测性能更强,并能够满足实际场景下的实时性检测要求,为实现后续对“黑飞”无人机的精准压制提供了重要依据,具有较高的理论价值和实际应用前景。
