基于不足气象要素时间序列的小时界限值提取
2021-12-02廖顺宝刘广虎
马 欢,郭 越,廖顺宝,刘 晓,刘广虎
(1.防灾科技学院地球科学学院,三河 065201;2.河北省地震动力学重点实验室,三河 065201;3.防灾科技学院电子科学与控制工程学院,三河 065201;4.防灾科技学院生态环境学院,三河 065201;5.南昌工程学院水利与生态工程学院,南昌 330099)
气象数据广泛应用于交通运输[1-3]、气象及农业气象灾害[4-7]、地球物理[8-9]、环境[10]、投资[11]、疾病和健康[12-13]和基础设施服务[14-15]等领域。尤其是大数据时代的到来,气象数据在其中扮演的角色越来越重要。随着这些行业的不断发展,对气象数据准确性的要求也在逐渐提高。因此,在利用气象数据的前期,对气象数据进行质量控制的重要性和必要性显而易见。中外众多学者从20 世纪末就开展了各项气象要素质量控制的相关研究[16-24],质量控制内容主要包括界限值检查、内部一致性检查、时间和空间异常值检查和缺失值检查等。
在气象数据质量控制过程中,一般首先执行极值检查,众多学者对气象要素的界限值的选取采取了不同方案,尤其是气温要素。例如,Feng等[18]、Kubecka[25]采取全球可能记录地温最高值93.9 ℃作为气温上界限值进行中国地区的极值检查,但是由于中国地区的历史气温极值没有达到93.9 ℃的先例,而且该界限值的空间和时间尺度过大,在质量控制中发挥的作用较小;窦以文等[26]和金莉莉等[27]选用研究地区站点的历史记录最大值和最小值作为界限值对历史数据进行检查,相比将全球可能记录地温最大值作为界限值来说,该界限值的空间尺度有所减小,时间尺度较大,在数据质量控制中十分有效。任芝花等[28]、鲁奕岑等[29]根据不同季节设定气象站气温界限值,该方法将气象站点的界限值时间尺度缩至季度,在中国地区和浙江省气温质量控制研究中避免了界限值范围过大。郭昌松等[30]利用福建省各站点各月气温极值加上(减去)某个统计值作为该站点各月的极限值,进一步将界限值时间尺度减小至月份。
由此可见,虽然极值检查作为气象数据质量控制中较为粗糙的一个环节,但是有效的界限值能够从基本面上清洗出不合格的数据,为后续质量控制打好坚实的基础。然而,逐小时气象数据的质量控制常常为局部地区的天气预报[31]、不同晴空指数下气温随时间变化的情况[32]、农作物生育期影响[33]等提供数据支撑。若使用上述全球历史极值、站点历史极值、站点季节性历史极值或站点各月份历史极值作为质量控制中的界限值,会弱化界限值检查的效果。为了提升气象数据质量控制中的界限值检查效果,开展更为精细时间尺度的气象数据界限值研究十分必要。
基于界限值时间尺度的思考,本研究结合站点历史值,通过统计学手段,将界限值时间尺度缩小至每小时,确定各站点一年每小时数据的界限值,从而更精细、有效地进行气象数据质量控制,以便更有效的服务于局部地区的天气预报、农作物耕种等领域。另外,通过统计学方法来确定逐小时气象数据的界限值,需要一定量的统计样本,且气象要素要在时间尺度上具有一定规律。因此,现选择气象站点的气温、气压和相对湿度3个气象要素数据。气象站主要分布在中国东北、华北、长江中下游地区,包含13 个省,4 个直辖市和1 个自治区,共计1 942 个气象站。由于气象站数量多,会有大量的统计样本用于确定逐小时气象数据界限值。因此,使用MySQL数据库(特点:快速、有效安全的处理大量数据)存储所有气象数据,再利用Python语言的Pandas工具强大的分组功能,在海量气象数据中抽取统计样本,计算逐小时气象数据界限值,进而实现一套用于快速、有效的计算气温、气压和相对湿度气象要素逐小时界限值的算法。
1 原理方法
1.1 选取统计样本方法
本研究收集近两年(2019 年和2020 年)各站点每小时的气温,气压和相对湿度数据,由于每个站点的这3类气象要素相邻时间的小时数据具有相似性和规律性。每天中午的气温最高,夜晚最低。气压与海拔、气温和大气密度相关,对于同一站点而言,其年变化规律大致为夏季低,冬季高。相对湿度表现为夜晚高,白天低。因此,以当前数据的时间为中心,挑选临近时间点的数据进行统计,通过式(1)得到统计的平均值和标准差,进一步获得界限值标准。
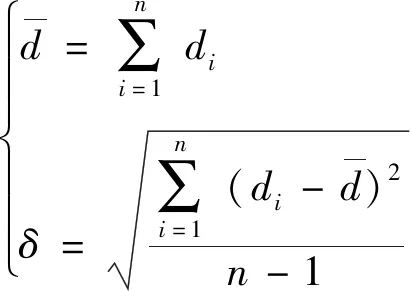
(1)
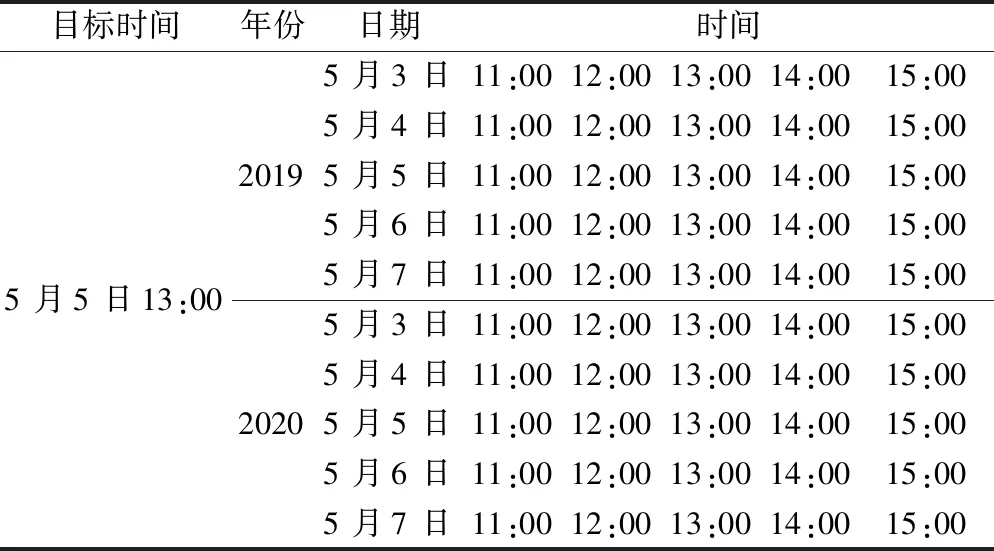
表1 统计样本时间Table 1 Statistical sample time
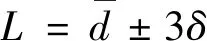
(2)
另外,如果按照上述时间样本选取规则和样本数量(50个样本)要求,在两年(2019 年和2020 年)数据中,有两类特殊时间段不满足50个样本,其处理方式如下。
(1)位于时间列表边界的时刻。当某时刻位于时间列表边界时(2019 年1 月1 日0:00—2019 年1 月3 日1:00,2020 年12 月29 日22:00—2020 年12 月31 日23:00),统计样本将达不到50个,这样达不到应有的统计效果。为此,在计算时间列表边界处的界限值时,要纳入2018 年12 月底和2021 年1 月初的部分数据至统计样本中,以满足均值和标准差的样本数量需求。
(2)2020 年2 月29 日的所有时间。当某时刻在2020年2月29日时,统计样本同样达不到50个,由于每4年出现一次,在此不计算2020年2月29日的界限值。在数据的质量控制中,若存在2月29日的数据,则利用2月28日和3月1日的界限值的范围较大者作为2月29日的界限值。
1.2 数据处理
2019年和2020年一个台站的每小时数据量为17 520个(24×365×2=17 520),所选站点共有1 942 个,数据量为34 023 840 个(17 520×1 942=34 023 840)。对于界限值而言,要统计一年每小时数据的界限值,因此界限值个数为数据量的一半,即17 011 920个。由此可见,数据量十分庞大,更为困难的是每个界限值需要50 个样本计算均值和标准差,不仅需要很大的计算机内存空间,而且由于数据量大引起的数据遍历时间长,效率低,在普通电脑上将是一个耗时费力的工作。为此,使用Python Pandas模块中的groupby函数,对庞大的数据体进行分组运算,以达到提高计算效率的目的。
1.2.1 数据处理流程
界限值计算流程如图1所示,主要步骤如下。

图1 计算每小时界限值流程图Fig.1 Flow chart for calculating the hourly extreme value
步骤1将2019年和2020年的每小时数据以每个月数据为一个表存入MySQL数据库中,共24个数据表。
步骤2通过Python Pandas模块链接MySQL数据库读取数据。
步骤3通过Python Pandas模块中的groupby函数分组,并获得样本均值和标准差。
步骤4通过式(2)得到每小时界限值。
由于在读取数据库中的每小时数据时,可能存在特征值,如表2所示,所以在计算样本的均值和标准差时,若样本中存在特征值,则舍弃这些特征值后,计算剩余样本的均值和标准差。
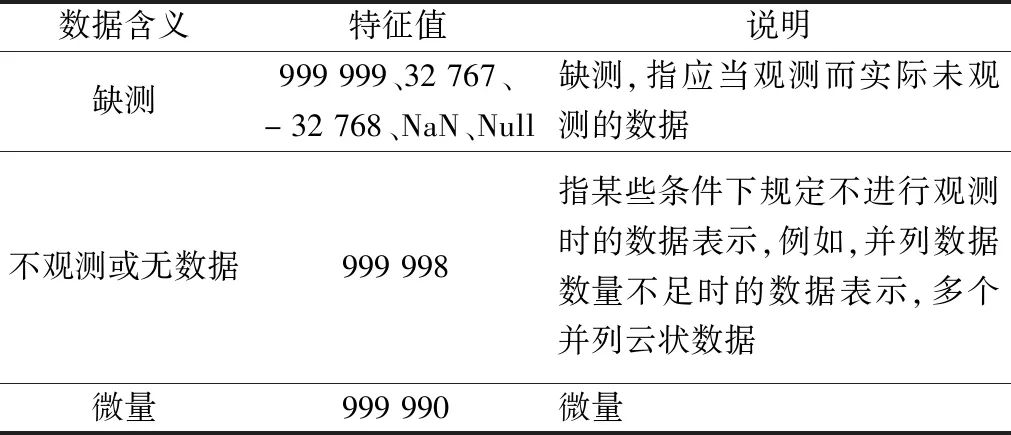
表2 气象要素特征值Table 2 Eigenvalues of meteorological elements
1.2.2 数据处理算法
如图2所示的伪代码,在进行数据处理时,面对两个选择:一是按气象站遍历;二是按时间遍历。

图2 算法伪代码图Fig.2 Algorithm pseudo code diagram
首先,通过遍历气象站求得界限值,其循环次数为1 942次(1 942个气象站)。在遍历过程中,每个站点利用groupby函数按照不同时间分成8 760组,每一组收集50个样本计算均值和标准差。
其次,通过遍历时间求得界限值,循环次数为8 760 次(365×24=8 760)。在遍历过程中,利用groupby函数按照不同站点分成1 942组,每组收集50个样本计算均值和标准差。
从循环次数上看,似乎遍历气象站的方式循环次数少,能够有效减少运算时间,但是这种方案需要提前准备8 760组的统计样本,每组50个样本所在时间各不相同,从算法实现的角度来看,较为麻烦。
第二种算法虽然循环次数较多,但是在1 942 组中,每组的样本所在时间相同,不需要前期准备,这使得算法简单易懂,便于实现。因此,采用算法二计算了1 942个气象站的全年每小时界限值8 760个,程序运行18 h 30 min。经测试,若不使用groupby函数分组,利用遍历统计样本的方式,运行时将增长约4 倍。
2 界限值分析
经过上述计算可确定全年各气象站的气温、气压和相对湿度每小时界限值。101011200 号气象站的全年气温界限值如图3(a)所示,在-14.6~45.1 ℃范围,由于全年每小时数据量庞大,故使用每天中午12:00 的均值、上下界限值来绘制曲线(以下气压和相对湿度曲线也参考该方法)。从总体趋势来看,该站点气温均值6 月和7 月最高,逐渐向两端减小。由于界限值过多,不易发现规律。于是选取8 月的界限值(以下气压和相对湿度要素也选取8月数据),如图3(b)所示,气温界限值和统计样本均值的规律与每天的气温变化规律相似,都表现为夜晚气温低,白天气温高。峰值和最小值各31个,代表每天气温均值和界限值的最高气温、最低气温。另外,该气象站8 月份气温数据统计样本的标准差表现为气温高时,标准差高,气温低时,标准差小,如图3(b)红色曲线所示。呈现这样的曲线形态的主要原因是:白天中午温度梯度较大,统计样本在平均气温附近的波动较大;相反,夜晚凌晨气温梯度较小,统计样本在平均气温附近波动较小。总的来说,该气象站气温界限值和统计样本标准差都符合正常气温变化规律,气温界限值具备有效性,能够用于进一步气温质量控制。这也从侧面验证了样本统计方法确定每小时界限值算法也是有效的。

图3 101011200 号气象站气温界限值及统计样本标准差Fig.3 Temperature extreme values and statistical sample standard deviation of weather station 101011200
101011200 号气象站7—11月的每小时气压界限值如图4(a)所示,在980~1 050 hPa区间范围。由于气压与海拔、气温和大气密度相关,与气温相比,显得规律性差,而且由于该气象站存在大量气压值缺测现象,所以1—6月以及12月的界限值无法通过统计手段获取,这使得曲线被分成两段。由于每一段曲线两端只有少数有效统计样本,即50个样本中存在大量的特征值,如表2所示,所以头部和尾部上下界限值与均值趋于交汇。虽然只有5 个月气压数据,但是也能够观察出气压的大致年变化规律。7—11月气压逐渐升高,即冬天比夏天气压高,这符合大陆型气压年变化规律,但是若观察1 个月的气压界限值、均值和标准差数据,其并不呈现规律性变化,如图4(b)所示,只能通过其统计样本的标准差得知统计样本的波动程度。例如,8 月22 日和8 月23 日的统计样本气压起伏较大,使得这两天的上下界限值范围较大。
101011200号气象站的全年每小时相对湿度界限值如图5(a)所示,在0~100%区间范围。从总体趋势来看,该站点全年相对湿度均值并无明显规律。8月的界限值如图5(b)所示,相对湿度统计样本均值(绿色曲线)的规律与每天的气温变化规律相反,表现为夜晚相对湿度高,白天相对湿度低。峰值和最小值各31个,代表统计样本的相对湿度均值的最高值和最低值。该气象站8月数据统计样本的标准差表现为白天相对湿度低时,标准差高,夜晚相对湿度高时,标准差小,如图5(b)红色曲线所示。这与相对湿度的日变化规律相符。另外,由于相对湿度的变化范围一定是0~100%,所以在界限值计算过程中,如果式(2)的计算值大于100%或小于0,则直接将界限值设为100%或0。
3 讨论与结论
以2019年和2020年的实时气温、气压和相对湿度气象要素数据和统计方法为基础,本研究利用Python语言实现了一套快速、有效的计算气温、气压和相对湿度的每小时界限值算法,该算法为使用每小时界限值有效的进行质量控制打下坚实基础,有助于气象、农业等领域相关工作。
在计算的每小时界限值中,气温界限值规律与日气温变化规律一致;气压界限值规律与大陆型气压的年变化规律一致;相对湿度界限值虽然与其日变化规律一致,但是每小时界限值大多还是集中在0和100%,因此相对湿度数据若在0~100%范围外,则采用0和100%作为其界限值;若在0~100%范围内,则采用相对湿度每小时界限值。另外,研究也存在不足之处:研究只利用2019 年和2020 年的气象数据进行界限值计算,想要获得更具有统计规律的界限值,还需要在现有50 个样本的基础上扩充统计样本数量。这在后续研究中需要加以改进,已经列为下一步研究工作重点,以此提升界限值精确度,保证质量控制效果。
