云数据中心网络多用户多业务并发性算法
2021-12-02陈小龙
陈小龙
(锐捷网络股份有限公司,福建 福州 350000)
1 概述
随着Web2.0 时代的到来,基于互联网的网上交易应用迅猛发展,尤其出现类似每年的“双十一”等可以说是购物的狂欢节,随之而来的就是网络数据量的爆炸式增长,为了保障数据服务的稳定运行,在实现云数据中心运营平台产品上线前的能模拟百亿级别访问量的情景再现,设计基于RDMA 技术的云数据中心网络多用户多业务算法,模拟多用户多条业务流,实现仿真多用户多条业务流测目的,本文通过基于RDMA 技术的云数据中心网络进行数据建模,设计Parallel Matrix Multiplication 算法实现RDMA Ib_write 源端口变化,解决了当前无法仿真多用户多条业务流测试瓶颈,为应对百亿级数量访问量的数据中心的稳定运行提供运营前的测试保障。
2 研究背景及相关工作
2.1 数据中心网络拓扑结构
基于云的数据中心计算网络集群常见有两类架构。传统情况下云计算网络架构会分为三层:接入层、汇聚层和核心层。如图1。
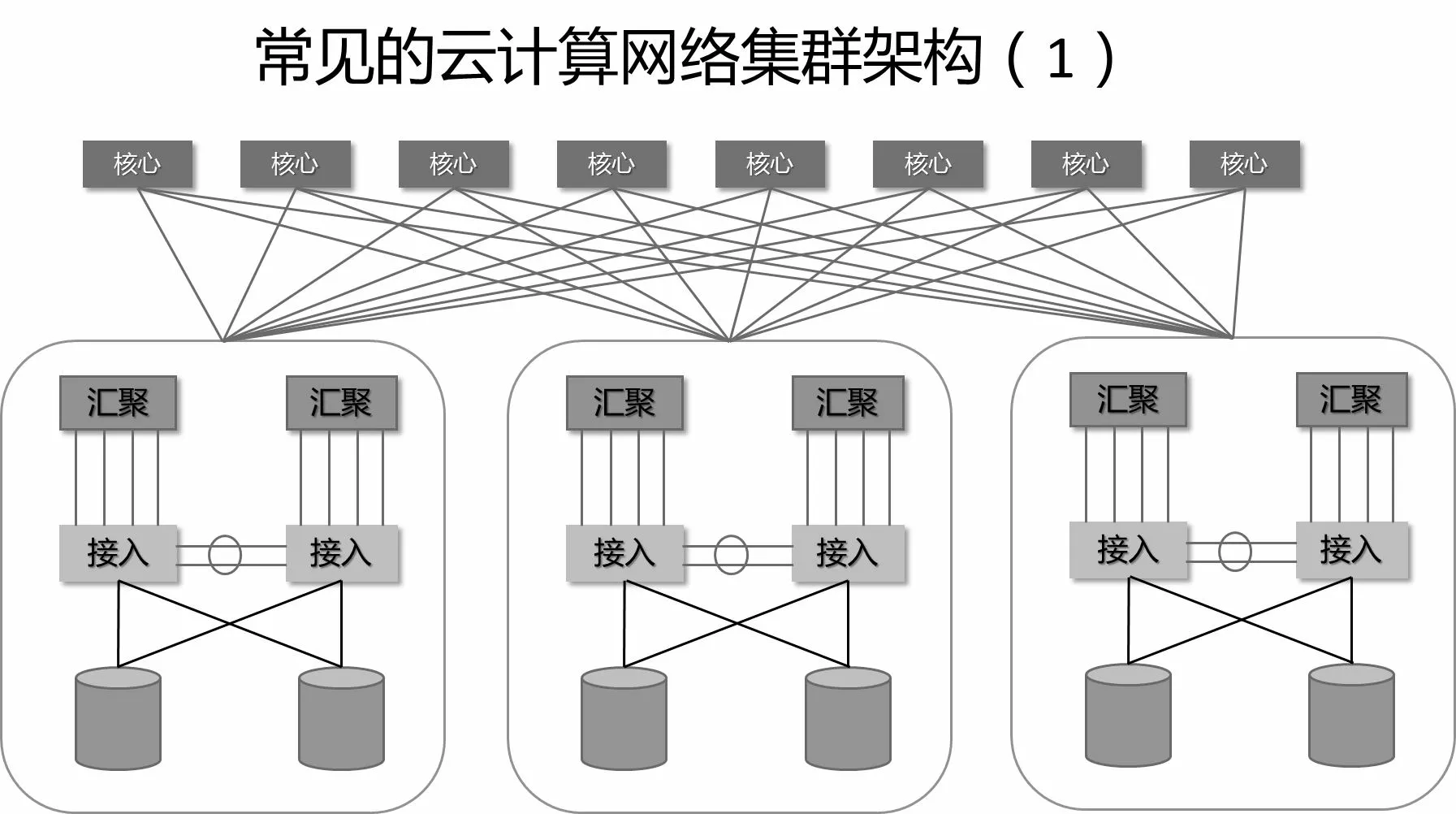
图1
另外一种比较常见的云计算网络集群架构,在Spine 节点和Leaf 节点之间可能会存在三层连接,而Spine 节点和Core 节点之间也可能会存在三层连接,这种网络架构相比于前面提到的架构而言,其扩展粒度要更细,可以细化到一组或者多组进行接入(图2)。
2.2 数据中心网内数据分派机制
无论选用那种数据中心网络集群架构,海量的业务流数据在传输中往往会出现延迟、丢包等现象,但单用户性能测试无法实现多用户多业务流并发性的检测,为了能实时了解数据中心网络多用户多业务并发性数据的传输过程,发现数据传输过程中影响带宽、产生延迟、丢包现象的形成因素,解决了当前无法仿真多用户多条业务流测试瓶颈,解决不需增设服务器的情况下多用户并发性问题。
3 云数据中心多业务并发性算法
3.1 问题描述
当今时代存在数据大爆炸的特征。信息的高速增长要求领域技术和软件工具处理大量的数据。为了应对云数据中心的多业务大数据挑战,一些分布式内存的并行执行模型已经被提出:MapReduce, 迭代MapReduce,图处理和数据流图处理并行执行模型。MapReduce 编程模型已经应用到很大范围的计算应用,因为它能提供简单的使用和处理大规模数据时的效率。但是MapReduce 有其局限性。比如MapReduce 处理多个相关的异构数据集合时的效率不高。MPI 是一个开放的通讯协议,用于编写并行程序。MPI 的目标是高性能、大规模及可移植性。
3.2 MPI 计算架构
mpirun 是MPI 程序的启动脚本程序,它提供简化了并行程序的启动,隐藏了底层的实现细节,为用户提供了一个通用的MPI 处理机。Mpirun 在执行并行程序时,参数-np 指明了需要并行运行的进程个数。mpirun 首先在本地机器上启动一个进程,然后根据machines 文件中所列出的主机,为每个主机启动一个进程。一般会给每个节点分一个固定的标号,类似于身份ID,在消息通信中会用到。
3.3 多业务并发性算法
我们选择并行矩阵乘法程序来评估多用户多任务算法的性能,因为并行矩阵乘法有着良好的通信和计算开销模式。
矩阵乘矩阵的性能模型已经被研究了好几十年。并行矩阵乘法的计算复杂度以N 的立方增长,而它的内存开销以N 的平方增长。并行矩阵乘法的工作量已经被分为许多同构的子任务并且被并行执行。并行矩阵乘法良好的计算和通信模式使它成为研究多任务多用户算法程序的良好应用。我们提出了一个精确的分析模型来分析MPI 并行矩阵乘法。我们的多用户多任务的并行矩阵乘法的算法开销为:
MPI 并行矩阵乘法算法代码如下:int main(int argc, char* argv[]) {

4 讨论
我们实现了支持多用户用任务的MPI 并行矩阵乘法算法程序。使用分析模型精确的分析了这一算法程序的通信开销和计算开销。该分析模型使我们能够实时了解数据中心网络多用户多业务并发性数据的传输过程,发现数据传输过程中影响带宽、产生延迟、丢包现象的形成因素。
5 仿真实验
5.1 实验环境设计

5.2 实验过程。
5.2.1 软件工具
软件方面,OEM 厂商Dell 将Mellanox 网卡固件程序升级至最新版本:Network_Firmware_TPTR3_LN_14.20.18.20_01.BIN;以确保支持RDMA 源端口变化等高级特性。此外MPI 驱动程序采用 的 是 Mellanox 原 厂 驱 动 :MLNX_MPI_LINUX-4.2-1.0.0.0-rhel7.4-x86_64。
(1)确认系统装有网络适配器(HCA/NIC),采用下面的命令可以显示Mellanox HCA 的安装信息:

5.2.2 硬件工具
测试使用的RDMA 和RoCE 协议中,以太网交换机需要支持PFC, ECN, ETS 功能;网卡需要支持RoCE 协议。网卡主要使用了Mellanox ConnectX-4 LX 系列双25Gpbs 网口网卡。在测试中,主要测试了锐捷S6500-4C 交换机,在部分测试中也有使用到S6510 交换机。
5.2.3 测试过程
(1)以root 权限登陆到系统。
(2)运行安装脚本 #./mlnxMPIinstall;运行前如果安装过程中需要升级网络适配器固件ConnectX-3/ConnectX-3 Pro - 重启 驱 动、ConnectX-4/ConnectX-4 Lx - 重 启 系 统 、ConnectX-5/ConnectX-5 Ex - 重启系统;否则重启驱动#/etc/init.d/openibd restart。
(3)运行hca_self_test.MPI 实用程序来验证InfiniBand 链接是否up。该实用程序还检查和显示额外的信息,例如:HCA 固件版本、内核体系结构、驱动程序版本、与它们的状态一起活动的HCA 端口的数量、节点GUID 等信息。如需了解有关hca_self_test. MPI 的 更 多 细 节 , 查 看 文 件 :docs/readme_and_user_manual/hca_self_test. readme。
(4)安装完成后,运行命令/ etc/infiniband/ info 来获取关于安装的Mellanox 的信息,例如前缀、内核版本和安装参数,在启动后自动加载的模块列表可以在/ etc/infiniband/ openib. conf文件中找到。
(5)端口设置
创建一个包含信息(源端口、目的端口、源IP、目的IP、协议)的五元组,利用Parallel Matrix Multiplication 算法实现RDMA Ib_write 源端口变化,实现多用户、多业务端口变化的目的,达成亿级的用户量和数据量。设置过程如下:
Step1:五元组信息(源端口、目的端口、源IP、目的IP、协议)初始化。
(1)源mac 无变化(24:8a:07:9a:28:83)目的mac 无变化(58:69:6c:14:ca:01)。
(2)源ip 无变化(10.10.10.177)目的ip 无变化(30.0.0.182)。
(3)源端口变化随机,目的端口随机。
(4)协议:RoCE。
(5)报文长度:1082。
Step 2:利用Parallel Matrix Multiplication 算法实现RDMA MPI 源端口变化,根据用户五元组中的源端口的变化,确定业务服务数量;当业务服务数量小于预设阈值3000 时,不进行任何处理,当业务服务数量大于预设阈值3000 时,转到Step 3 执行。从而实现多用户、多业务端口变化的目的,达成亿级的用户量和数据量。
Step 3:在MPI 业务下,从接收的用户多类业务请求中获取MPI 矩阵乘法链路带宽等参数信息,根据这些信息给链路分配带宽,实现链路负载均衡。当矩阵的行和列较大时,如行,列都大于1024,此时矩阵直接相乘会导致内存空间不够,并出现多次读取的问题。把整个矩阵乘法的动作,切割成很多局部小矩阵的乘法,这样就可以把两个小矩阵加载到共享内存中,小矩阵本身的乘法就不需要再加载其它数据到内存了。把大的整体矩阵A、B 分成小的局部矩阵时,矩阵C=A*B,A、B、C 分别为M*K、K*N、M*N 的矩阵,其中,M = wp,N =hq,K =kr。具体分割是将某些连续行和某些连续列的交叉部分划分为一块。确保每个元素都在唯一一个局部矩阵里。将矩阵A 和B 分割成A 和B的子矩阵。从而达到优化程序,节约缓存的目的。具体为:
(1)定义MPI 矩阵行和列的数据结构,分别是MPI_Comm row_comm 和MPI_Comm col_comm;The BLAS matrix*matrix multiply 算法,当M>1024,N>1024 情况下,启动Parallel Matrix Multiplication 算法(并行矩阵),并开启多线程调用。
(2)从接收的用户业务请求中获取MPI 矩阵乘法的参数信息,将矩阵分成局部小矩阵,并给局部要相乘的矩阵分配内存,分配具体方法如下:
1 首先将矩阵分块,将矩阵C 分解为p × q 的分块矩阵Cij,每个Cij=(A × B)ij是一个w × h 的小矩阵,A 分解成为p × k 个分块矩阵Aij,每个Aij是一个w × r 的局部矩阵,B 分解成为k × q 的分块矩阵Bij,每个Bij是一个r × h 的局部矩阵。则分块矩阵乘法的定义为:

2 mpi_bcast 行块,本地矩阵块乘法。

3 mpi_send_receive 列块,mpi_bcast, mpi_send_receive, 使用mpi rdma ucx 通信库,实现源端口变化发送和接受行和块数据。
Step 4:根据矩阵BMR(broadcast-multiply-roll algorithm)算法结果,计算出运行时间,最终输出用户数量,线程数量,计算出网络延迟和带宽。
5.3 实验结果
根据上文中所述的方案及实验过程,经测试得到如下的实验结果。图4 是MPI 矩阵乘法并行开销。MPI 矩阵乘法的并行开销定义如下:

图4 MPI 矩阵乘法并行开销
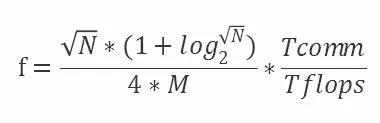

6 结论
本论文设计了云数据中心网络多用户多业务并发性算法,并行矩阵乘法的加速比呈线性增长模式,解决了当前无法仿真多用户多条业务流测试瓶颈,同时通过矩阵乘法解决业务性能仿真无法实现问题。
