基于注意力机制的实例分割算法
2021-12-02张声传喻松林纪荣嵘
张声传,喻松林,纪荣嵘
(厦门大学信息学院,厦门 361005)
0 引言
计算机视觉(Computer Vision,CV)是人工智能领域的研究热点,自2012年AlexNet[1]网络问世以来,CV经历了从简单的图像分类到更为精细的语义分割、实例分割等任务的发展。伴随深度学习和卷积神经网络(Convolutional Neural Networks,CNN)的发展,CV在识别精度和速度上取得了长足进步,十年来涌现了大量的理论与方法,在诸多领域取得了丰硕的成果。实例分割的任务是输入一张图像,输出图像中每个物体的类别,同时为每个物体生成像素级别的实例掩码[2]。图像分类、目标检测、语义分割和实例分割四类CV任务难度递增,图像分类只需要指出图像中有哪些物体类别;目标检测在图像分类的基础上同时需要输出物体的边界框;语义分割需要预测图像上每一个像素点属于哪个类别;实例分割在语义分割的基础上还需要区分同一类别的不同实例。
以Mask R-CNN[3]为代表的双阶段实例分割方案遵循先检测后分割的理念,通常会先由区域候选网络[4](Region Proposal Network,RPN)提出候选区域,然后针对兴趣区域(Region of Interest,ROI)进行池化和对齐操作,最后将特征送入后续网络进行分类和掩码生成。双阶段分割方案掩码生成是基于候选区域特征进行的,避免了图像其他位置对掩码生成的干扰,一般分割精度较高。双阶段分割方案的主要问题在于存在大量的负样本候选区域,计算耗时。为了解决这个问题,以实时实例分割(Real-time Instance Se-gmentation,YOLACT)[5]和基于位置的实例分割(Segmenting Objects by Locations,SOLO)[6]等为代表的单阶段分割方案产生,相比双阶段分割,这类方案放弃了提出候选区域的操作,转而利用全卷积在全图范围进行卷积操作,一步到位同时实现物体种类预测和掩码生成,免去了RPN结构,提高了分割速率。但是全图卷积在掩码生成过程中无法避免背景影响,难以区分同一种类的不同实例,导致精度有所下降。
为了提高单阶段分割精度,本文秉持通过增加不同实例特征区分度,以降低掩码生成过程背景干扰的基本思想,针对全图卷积的固有缺点,提出了在特征图上添加注意力机制的方法。该方法在特征图每个位置的特征向量上进行点积运算,例如位置(i,j) 用向量[1,0,0]表示,位置(m,n) 用向量[0,1,0]表示,这样(i,j)位置和(m,n)位置的特征向量在与自己点积后结果为1,相互点积后结果为0,以达到区分的目的。同一位置特征向量点积后结果变大,不同位置特征向量点积后结果变小,这样便能提高不同实例间区分度,利于掩码生成,提高了分割精度。
1 相关工作
1.1 特征金字塔
一个良好的特征表示是实例分割的基础步骤,为后续准确地分类和分割提供了必要保障。深度学习兴起后,特征提取的工作基本由深度网络来完成。利用深度网络提取图像特征能够免去繁琐的人工运算,并且在效果上相较于传统方法也有较大提升。深度网络的浅层含有比较丰富的图像细节信息,语义信息较少;而深层有更大的感受野,以及更丰富的语义信息,但图像细节丢失严重。为了综合深度网络深层和浅层的优势,特征金字塔[7](Feature Pyramid Network,FPN)是一种被广泛采纳的方案。FPN结构包括自下而上、自上而下和横向连接三部分。自下而上路径是用于特征提取的常规卷积网络,随着层数加深,感受野变大,空间分辨率降低,检测到更多上下文信息,逐层语义信息递增。自上而下路径采用上采样方式,提高了图像分辨率,同时还原了更多细节信息。横向连接是对自上而下路径的补充,将原始的高分辨率特征融合到自上而下的路径中,更好地还原了图像细节。
1.2 全卷积网络
全卷积网络[8](Fully Convolution Network,FCN)能对图像进行像素级别分类,与经典CNN在卷积后使用全连接层进行类别预测不同,FCN没有全连接层,取而代之的是对最后一个卷积层的特征图进行上采样,使它恢复到与输入图像相同的尺寸,从而对输入图像每一个像素点进行分类。理论上,全卷积能对任意尺寸的图像进行处理,广泛应用于语义分割和实例分割中。
1.3 单阶段实例分割
单阶段实例分割以快速著称,相较于双阶段实例分割其模型更加紧凑。一般而言,整体网络分为特征提取、分类和掩码生成三部分[9-10]。以SOLO算法为例,其基本思想是根据实例的位置和大小信息进行区分。具体而言,将图像分割成S×S个格子,坐标(i,j)对应图像中第i行第j列位置的格子。对于某个实例,如果该实例的几何中心落在了(i,j)格子内,那么该格子将负责预测这个实例的类别和掩码生成。网络结构一体化不需要ROI操作,所有卷积都是全图卷积,不对特征图进行裁剪,凭借这些特性,单阶段实例分割速度快。然而当图像中出现同一种类的不同实例时,全图卷积固有弊端显现,同一种类提取到的特征相似,而在掩码生成过程中要求同一种类不同实例的掩码单独生成,全图卷积难以区分,导致精度下降。针对该问题,本文提出了注意力模型,能够提高同一种类不同实例特征的差异,方便全图卷积区分,从而提高分割精度。
2 基于注意力机制的实例分割方案
2.1 问题描述
总体上,本文是以SOLO算法为框架进行改进。前文提到,SOLO算法将图像分割成S×S个格子,对于每一个格子,预测几何中心落在该格子的实例属于C个类别的概率,其中C为数据集中实例的种类数。在分类网络中,每一个格子对应输出空间为一个C维向量,由于图像被分割成S×S个格子,因此分类网络输出空间为C×S×S。
同时,每一个格子将负责几何中心落在该格子内实例的掩码生成,掩码生成网络输出空间为S2×2h×2w,第k个通道对应(i,j)位置格子的生成掩码,满足条件:k=i×S+j,图1所示为网络输出空间。本文提出了添加注意力机制的掩码生成网络结构,如图2所示。所提方法主要分为特征提取、预测头网络结构、注意力机制、添加注意力机制的网络结构和损失函数这五部分,下面分别进行详细介绍。
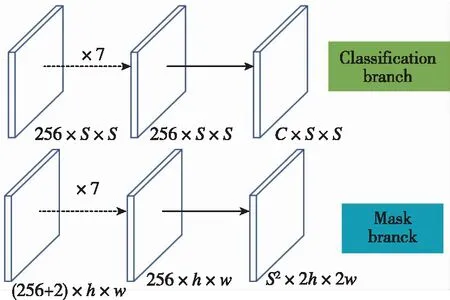
图1 分类分支和掩码分支输出空间Fig.1 Classification branch and mask branch output space
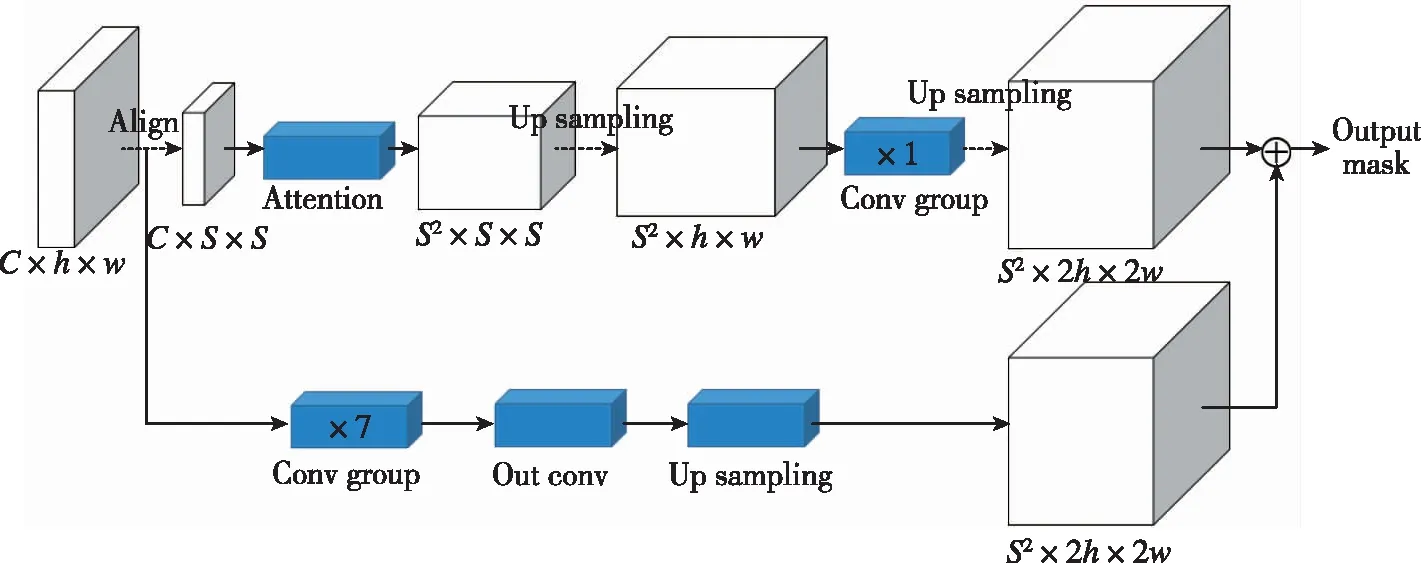
图2 添加注意力机制的掩码生成网络结构Fig.2 Mask generation network structure with attention mechanism
2.2 特征提取
特征提取使用了ResNet-FPN结构。具体而言,输入图像经过ResNet-50[11]前向计算,输出4个特征层,该过程对应FPN结构中自下而上计算。然后每个特征层经过1个1×1卷积横向连接,将特征通道规整到256,同时与自上而下特征层上采样后的结果相加,最后经过1个3×3卷积输出。提取特征自下而上分辨率逐层降低,语义信息逐层丰富。低层特征用于小物体分割,高层特征用于大物体分割。各层分辨率和通道数如表1所示。
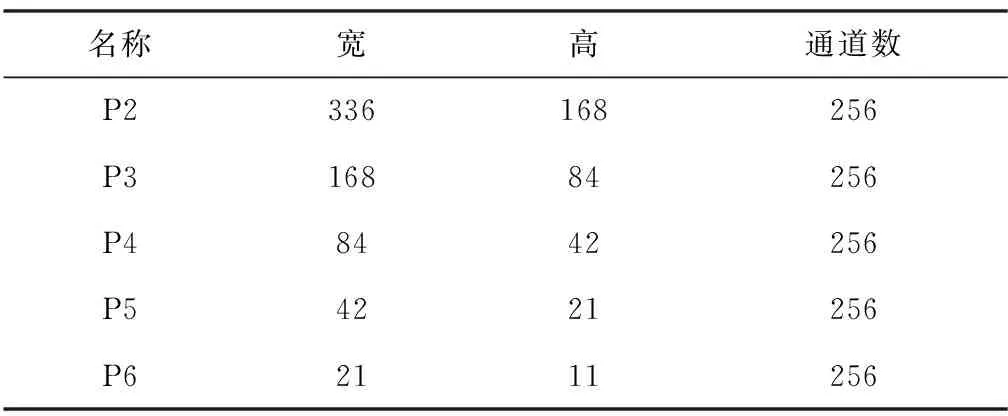
表1 ResNet-FPN提取各特征层详细信息
2.3 预测头网络结构
预测头网络由2个分支组成,一个分支负责类别预测,另一个分支负责掩码生成。分类分支首先将提取到的各特征层分割成S×S个格子,不同特征层S取值如表2所示。
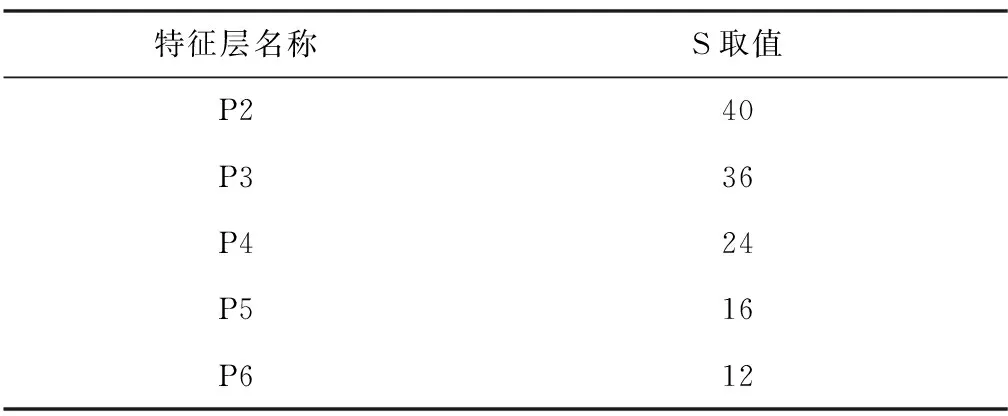
表2 各特征层S取值
将各层特征图分割为不同的格子后,输入到分类网络进行类别预测。分类网络由7个卷积组和1个输出卷积组成。每个卷积组由1个3×3卷积层、1个GN(Group Normalization)层[12]和1个ReLU激活层[13]组成。输出卷积核大小为3×3,步长和填充均为1,输出通道为类别数量。类似地,掩码生成网络也由7个卷积组和1个输出卷积组成。不同于分类分支,掩码生成网络不需要将特征分割成S×S个格子,而是为特征层添加2个坐标通道,以区分同一种类的不同实例。对于位置(i,j)添加的x、y坐标信息,计算方式如下
(1)
其中,w和h分别表示特征图的宽和高。然后将添加坐标信息的特征送入掩码分支进行掩码生成。
2.4 注意力机制
前文提到,对于同一种类的不同实例,分类网络要求输出相同的物体类别,掩码生成网络要求输出不同的实例掩码,为了实现这个目的,需要对特征图进行一定处理。本文提出了一种注意力机制,在经过ResNet-FPN特征提取后,由输出特征图每个位置的c个通道组成一个c维向量表示该位置实例的特征,对于同一种类不同实例,在经过注意力操作后应当具备区分能力。本文提出的注意力机制是基于向量点积的一种操作,要求某一位置的c维向量与其他位置的c维向量点积后结果最小化,而与自己点积后结果最大化,以达到区分不同实例的目的。具体而言,首先对特征位置进行编号,编号方式如下
num=i×S+j
(2)
新特征与原特征对应关系如下
Fnew(c,i,j)=Vnum=c⊗Vnum=i×S+j
(3)
其中,Fnew(c,i,j)表示新特征第c个通道(i,j)位置的特征值;Vnum=c表示编号为c的特征向量;Vnum=i×S+j表示编号为i×S+j的特征向量。图3详细说明了该过程。

图3 注意力机制图解(以编号为1、7、15的特征向量示例)Fig.3 Illustration of attention mechanism(take the index 1, 7, 15 as examples)
2.5 添加注意力机制的网络结构
SOLO算法掩码分支保留了特征图h×w的大小,而注意力机制需要将特征图分割成S×S的大小,不同格子对应图像中的不同实例。经过注意力机制后,特征空间变为S2×S×S。受到ResNet网络结构启发,将注意力机制单独作为一个分支,该分支的输出直接按位置加到原SOLO算法掩码生成分支。因此,最后的掩码将由两部分构成:原SOLO掩码分支生成的掩码和注意力分支生成的掩码。
2.6 损失函数
本文沿用SOLO算法损失函数,定义为
L=Lcate+λLmask
(4)
其中,Lcate为Focal Loss[14];Lmask为掩码损失,详细参阅文献[6]。
3 实验验证
3.1 数据集
实例分割常用数据集为微软发布的环境常见对象(Common Objects in Context, COCO)数据集[15],包含80个类别。然而COCO数据集较大,需要较高的算力。限于实验设备,本文实验过程中采用的数据集为CityScapes部分数据集,并将其标注转化为COCO格式。构造的数据集包含450张训练图像和50张验证图像,共5个类别,分别为person、rider、car、truck和bus。图4所示为一个训练数据集示例。

图4 训练数据集示例Fig.4 Training data examples
3.2 实验结果
实验中将去除坐标通道的SOLO算法作为基准,对比了去除坐标信息的SOLO算法、原SOLO算法和添加注意力机制三种方法的分割效果。图5所示为3个样本的分割效果。在样本1中,SOLO算法对于画面中央的汽车生成的掩码不准确,去除坐标信息的SOLO算法对于画面径深的汽车没有生成掩码,而注意力机制则对这些问题有所改善。在样本2中,画面右侧多名行人重叠,SOLO算法和去除坐标信息的SOLO算法无法将重叠行人进行区分,而注意力机制区分效果明显更好。在样本3中,由于图像较为空旷且实例面积小,SOLO算法和去除坐标信息的SOLO算法几乎无法生成掩码,而注意力机制能对行人生成掩码。本文对比了三种方法的准确率,结果如表3所示。

图5 分割效果示例Fig.5 Segmentation examples
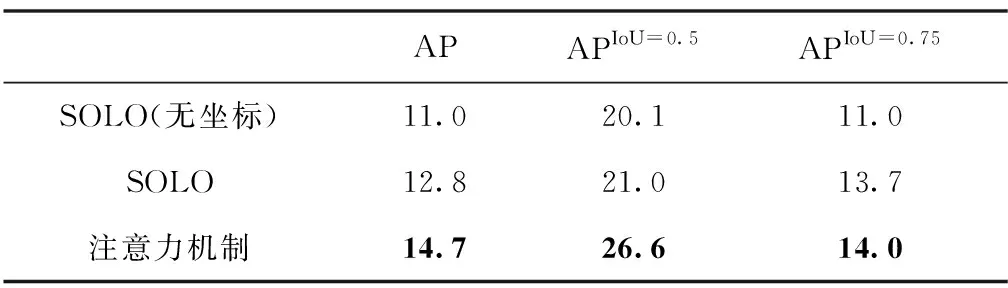
表3 各算法分割精度对比
对比去除坐标通道的SOLO算法和原始SOLO算法发现,仅仅添加2个通道的坐标信息就能将平均准确率(Average Precision,AP)提高1.8%,足见差异化信息在实例分割中起到了举足轻重的作用。对比SOLO算法和注意力机制,在添加了注意力机制后AP提高了1.9%,可见注意力机制提供了更为丰富的差异化信息,增强了不同实例的区分度,进而更利于生成准确的掩码。
同时本文对比了不同算法对小、中和大物体的分割效果。仔细观察图5可以发现,在样本1中较大的汽车生成的掩码比较小的行人生成的掩码更准确。在样本2中,画面前方较大的行人相比画面后方较小的行人生成的掩码更精确。在样本3中,对于较小的行人SOLO算法甚至无法生成掩码。本文对比了SOLO算法和注意力机制对不同面积实例的分割精度,结果如表4所示。

表4 不同大小的实例分割精度对比
结果显示,不管哪类算法在对小物体的分割上精度都欠佳,而对大物体的分割则表现良好。小物体分割依旧是实例分割领域的瓶颈,有待未来突破。
4 结论
本文针对单阶段目标检测全图卷积的固有缺点提出了一种注意力机制,该机制能增强不同实例间的区分度,从而提高分割精度。实验结果表明,注意力机制相比简单的坐标信息能提供更丰富的差异化信息,这也为提高单阶段实例分割精度的后续研究提供了一种思路。CV领域有诸多不同的注意力机制,本文提出的注意力机制主要有以下优点:
1)基本思想区别。不同于其他注意力机制关注特定信息的理念,本文注意力机制的目的是增加不同实例间的区分度,以提高各类实例的分割精度。
2)思路清晰,运算简便。本文的注意力机制不需要求相似度,直接在原算法基础上添加向量点积操作便可实现。
但是点积需要遍历特征图所有位置,运算复杂且耗时有所增加。此外,实例分割虽然取得了一系列进步,但也存在诸多挑战:
1)小物体分割精度低。网络层数增加,感受野变大,但分辨率降低,这对小物体的分割是一种灾难。目前的分割方案普遍对于大物体有更好的分割效果,而对小物体则欠佳。
2)实时性、高精度的分割算法有待研究。在无人驾驶领域,不仅对识别的时效性有很高的要求,同时对精度也有很高要求。目前的实例分割方案应对该领域还有些吃力,如何在保证高精度的前提下快速分割也是未来研究的重要方向。
3)三维图像分割研究较少。目前主流方案都是针对平面图像分割,然而三维点云应用广泛,且包含更多平面图像无法表达的信息。因此实现对三维点云图的分割,将极大程度丰富实例分割的应用场景。
