基于图嵌入的自适应多视降维方法
2021-11-30尹宝才张超辉胡永利孙艳丰王博岳
尹宝才,张超辉,胡永利,孙艳丰,王博岳
(1. 北京工业大学 信息学部,北京 100124; 2. 北京人工智能研究院,北京 100124)
随着摄像头、传感器以及互联网技术的快速发展,人们能够越来越便捷地获取各种各样的多视数据,例如描述人的人脸、笔迹、指纹等特征,描述图像的颜色、纹理、形状等特征。多视数据能够更全面的描述目标对象,有益于克服单视数据中常见的光照、遮挡等难题,在识别[1]、聚类[2]等多视学习任务中表现出显著优势。然而,多视数据一般维度较高[3],对其进行向量化表示时容易引发“维数灾难”问题,给传统多视学习算法带来了极大的困难。降维是数据挖掘的基础和热点问题,在克服“维数灾难”的同时还能挖掘数据中的判别信息,但其很难处理多视数据。因此,如何对多视数据进行有效的降维成为一个亟待解决的问题。
多视降维方法主要分为两类:有监督多视降维方法[4]和无监督多视降维方法[5]。有监督数据降维通过标签数据学习从高维数据到低维数据的降维模型,并利用该降维模型对新高维数据进行降维。然而,互联网上大部分数据是没有标签的,对其进行人工标注不仅效率低下且需要付出高昂的成本,因此无监督多视降维方法的研究变得更为重要。无监督多视降维方法不使用数据的标签信息,挖掘数据间联系来学习数据的低维表示。截止到目前,针对多视数据的无监督降维方法的研究,国内外都刚刚起步。
典范相关分析(canonical correlation analysis,CCA)及其变体[6-7]是研究多视图数据之间线性相关的一种有效方法。具体地,判别典型相关分析(discriminative CCA, DCCA)[8]结合了CCA和线性判别分析(linear discriminative analysis, LDA)[9],从不同的角度考虑了同一类别数据之间的相关性,以提高低维子空间的判别能力。张量典型相关分析(tensor CCA, TCCA)[10]通过分析不同视图之间的协方差张量,将CCA推广到处理多视数据,但是该方法计算成本过高限制了其应用范围。偏最小二乘(partial least squares, PLS)[11]使用回归方式将不同视的数据映射到公共线性子空间。分布式频谱嵌入(distributed spectral embedding, DSE)[12]将数据平滑地嵌入到低维空间中。基于多核学习(multiple kernel learning, MKL)[13]的方法将多核学习与图嵌入结合实现降维任务。多视联合降维(multi-view dimensionality co-reduction, MDcR)[14]使用核匹配方法挖掘多个视图之间的依存关系,从而获得每视数据的低维投影。耦合块对齐算法(coupled patch alignment, CPA)[15]将样本和其跨视角下的同类近邻以及异类近邻组成局部块,平衡跨视角类内的紧密性与类间的可分离性,并扩展成多维耦合块对齐,解决了任意数量视角的共同学习问题。
综上,现有的多视降维方法存在以下主要缺点:1) 这些方法仅关注不同视数据之间的关系,而忽略同视数据内部的关系;2) 这些方法通常仅考虑降维后的数据关系,而忽略原始数据的关联关系;3) 这些方法通常将不同视数据映射到一个公共空间,当不同视原始数据的维度不同时降维结果受影响较大。针对这些问题,本文提出的基于图嵌入的自适应多视降维(MVDR-GE)方法在考虑每视内数据关联性的基础上,自适应地学习相似矩阵来探索不同视之间数据的关联关系,获得各视数据的正交投影矩阵实现多视降维任务。
1 相关工作
1.1 图嵌入降维




通过式(2)可求得高维数据X的投影矩阵P∈K×V。
令Z=PX,式(2)可以写成图正则化表示:

1.2 自适应局部结构学习
自适应局部结构学习旨在通过度量样本之间的欧氏距离来自适应地学习样本间的相似度,从而获得样本的局部结构信息。对于每个样本xi和样本xj,sij为衡量两个样本之间相似性的值。则自适应学习相似性矩阵S可通过下面优化问题求得[17]:

尽管sij可以自适应地学习两个样本的相似度,但是式(4)不能避免S的对角线为1这种平凡解,故引入正则化约束:

式(5)是面向单视数据的自适应局部结构学习的公式,将其扩展到多视数据后可得:

2 基于图嵌入的自适应多视降维
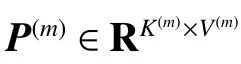
基于模型式(3)的思路,通过多视共享相似性矩阵可以很有效地探索视与视数据间的关系,则多视图嵌入降维模型为

式中P(m)P(m)T=I的目的是避免平凡解。
对式(7)进行分解,则:

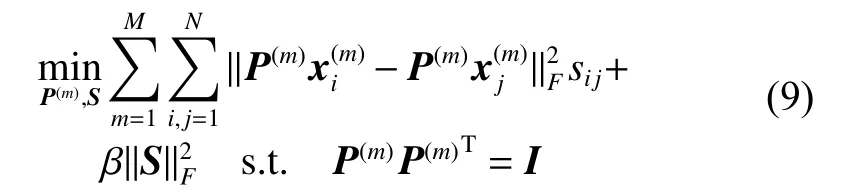
式(9)中的相似度矩阵S只关注降维后数据关联关系,忽略了原始数据间的结构关系,从而不能保证降维后的数据保留原始数据的结构。因此,引入对原始数据的约束后,则:
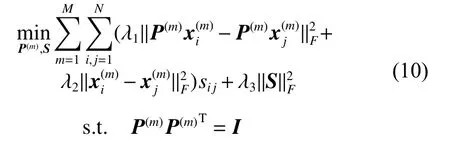
式中 λ1、 λ2和 λ3是平衡各个模块重要性的参数。此外,为了避免降维后数据丢失信息严重,引入约束视内数据重构误差项:


3 算法优化
目标函数式(12)是典型非凸优化问题,本文通过迭代更新的方法,求解P(m)和S。
3.1 固定 S 更 新P(m)


通过特征值分解得方法,可以求得投影矩阵P(m)并可指定其目标维度。
3.2 固定 P(m)更 新S
当固定投影矩阵P(m)时,重构误差项不参与更新,目标函数式(12)变为

将式(14)中的低维数据和原始数据之间的距离设为dij:
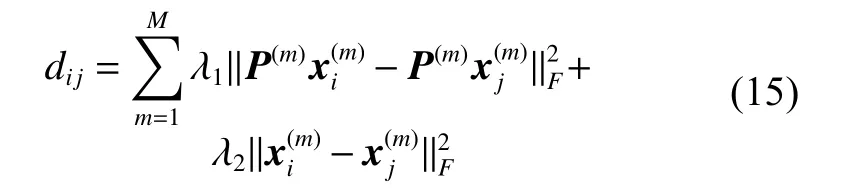
则式(14)可简化为

将式(16)变换为最小二乘形式:

综上所述,通过不断的迭代更新,最终得到各视的投影矩阵P(m),实现多视降维任务。
该模型的算法如下:
算法1 基于图嵌入的自适应多视降维方法(MVDR-GE)。
输入 多视数据 {X(1),X(2),···,X(M)};每视维度降至 {K(1),K(2),···,K(M)} ;参数λ1、λ2和λ3。

2) 当不满足收敛条件时:
Form=1:M
根据式(13)计算各式投影矩阵P(m);
End for
根据式(17)计算相似度矩阵S;
End
输出 各视降维矩阵 {P(1),P(2),···,P(M)}。
4 实验及结果分析
为了验证本文所提出的多视降维方法的有效性,在多个公开数据集上进行了验证实验。
4.1 数据集描述
IXMAS[18]数据集是由5个不同视角拍摄的视频组成的多视视频数据集,包含10个人的11种日常行为:看手表、抱胳膊、抓头、坐下、起来、转身、走、挥手、拳击、踢、捡。本文为每个视角提取177维视频特征。
ORL数据集由40个人、每人10幅不同的人脸照片构成。每个人拍摄照片的时间不同,光照和面部表情不同,本文调整图像大小为64×64,并提取图像的光照强度(intensity)、局部二值模式(local binary pattern, LBP)[19]和Gabor[19]特征构造多视数据,维度分别是4 096、3 304和6 750。
PIE数据集包含从68个人中采集的共1 428张人脸图像,该数据集提取特征的方法跟ORL数据集相同。
MSRCV1[21]数据集包含240张图片,这些图片属于9个类别,本文实验选取其中的树、建筑物、飞机、牛、人脸、汽车和自行车等7个类别共210张图片。分别提取每张图片的CENT(1 302维)、COLOR(48维)、GIST(512维)、LBP(256维)4种特征作为此数据集的多视数据。
Notting-Hill[22]诺丁山数据集来源于电影《诺丁山》,收集了5个角色的多张人脸照片。本文调整图像大小为64×64并提取跟ORL数据集相同的特征,维度分别为2 000、3 304和6 750。
4.2 实验及结果
为了验证方法的有效性,与以下几个经典降维方法做了实验结果对比。
主成分分析(principal component analysis,PCA)[23]:该方法是经典的无监督线性降维方法,通过将原始数据投影到线性子空间中对数据进行降维。
朴素多视降维(naive multi-view dimension reduction, NaMDR)[14]:此方法独立地减小了每个视图的维度,而没有约束不同的视图。
多视联合降维(multi-view dimensionality co-reduction, MDcR)[14]:该方法利用核匹配方法挖掘多个视图之间的依存关系,并获得每视数据的低维投影。
对于不同的数据集,特征的维数也不相同,本文统一将数据的目标特征维度设置为10维。为了进一步验证多视学习的有效性,本文对比了不同单视数据的最好性能和多视联合的性能,其中不同单视数据的最好性能在表格中用single表示,多视联合的性能在表格中用multiple表示。具体地说,在得到降维数据后,本文进行了聚类/识别实验从而间接对降维性能进行了评估。全部实验是在Window 10、64位操作系统、Inter Corei5-6500 3.20 GHz和20 G RAM的工作站上实现的,软件环境为Matlab 2018a。
4.2.1 聚类实验
在聚类实验中,采用3个评价指标度量聚类性能:准确性(accuracy, ACC)、归一化互信息(normalized mutual information, NMI)和纯度(Purity)。这些指标越高代表聚类表现越好。在获得不同降维方法的降维数据后,本文使用自动加权多图(auto-weighted multi-view learning, AMGL)[23]聚类方法对其进行聚类。由于此方法最后一步是执行K-means操作,所以本文进行30次实验取均值和标准差作为最终的实验结果。最后的实验结果为平均值±标准差的形式。本文在IXMAS、PIE、Notting-Hill 3个数据集上进行了聚类实验,实验结果如表1~3所示。
本文用加粗的字体表示最好的实验结果。从表1~3中可以看出,本文提出的多视降维方法无论在单视特征还是多视特征上都取得了最好的聚类表现。其他降维方法在ACC、NMI和Purity指标上,都不能取得一个令人满意的结果。由于本文提出的多视降维方法利用一个融合多视数据相似度的矩阵去辅助生成投影矩阵,使得用投影矩阵和原始数据运算得到的每视的低维数据能够融合其他视数据的信息,并且本文不同视数据的相似度矩阵S是自适应学习得到的,所以在拥有很强的灵活性的同时又能保证多视数据相互融合之后的低维数据具有代表高维数据的判别性信息,最终对多视低维数据进行聚类时获得一个令人满意的表现。同时,对比单视低维数据聚类也能获得最好的结果,表明本文提出的多视降维方法已经很好地融合了多视数据。
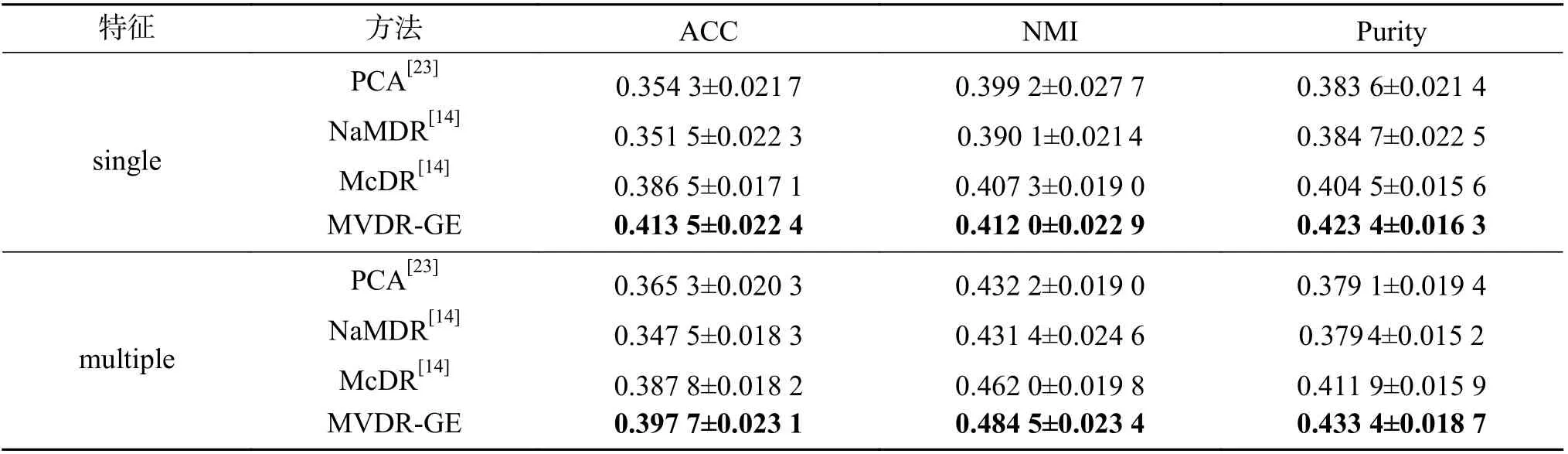
表1 IXMAS数据集聚类实验结果Table 1 Clustering experiment results of IXMAS dataset

表2 PIE数据集聚类实验结果Table 2 Clustering experiment results of PIE dataset

表3 Notting-Hill数据集聚类实验结果Table 3 Clustering experiment results of Notting-Hill dataset
4.2.2 识别实验
本文在ORL、Notting-Hill和MSRCV1数据集上进行了识别实验,采用最近邻分类器作为识别方法,采用识别准确度作为评价指标。由于在Notting-Hill和MSRCV1数据集上每类的样本不相同,本文从每类所有的样本中选取了M个样本进行训练,记作Gm,其余的样本进行测试。本文实验设置为随机选取30次训练集进行训练和测试,并报告平均识别结果。最后的实验结果为平均值±标准差的形式。
实验结果如表4~6所示,本文提出的方法在绝大多数情况上获得了最好的识别效果。由于本文提出的多视降维方法能够很好地融合多视数据的特征,使得降维后的低维数据能充分表示高维数据且具有更强的判别性,因此本文的方法能在识别实验中得到一个比较高的准确度,这也验证了本文的方法相较于其他对比方法,能够更好地对不同视角数据进行融合,使降维后的低维数据更有利于进行识别。在ORL人脸数据集和Notting-Hill数据集上,本文提出的方法虽然在单视数据和多视数据上均获得最好的实验结果,单视实验结果整体略优于多视实验结果,其他方法也同样出现了该问题。这一现象的原因在于两个数据集提取的LBP特征能够很好地反应图像的特征,在拼接多视数据进行识别时,本文选用的识别方法不能很好地融合多视数据进行识别。

表4 ORL数据集识别实验结果Table 4 Recognition experiment results of ORL dataset

表5 Notting-Hill数据集识别实验结果Table 5 Recognition experiment results of Notting-Hill dataset

表6 MSRCV1数据集识别实验结果Table 6 Recognition experiment results of MSRCV1 dataset
5 结束语
本文提出了一种基于图嵌入的自适应多视降维方法。通过图嵌入的方法能够将高维数据嵌入到一个低维的子空间,并使得到的低维数据能够具有高维数据的特点。通过自适应学习一个多视数据共享的相似性矩阵,能够对不同视的数据在降维的过程中进行融合,使得降维后的每个视之间的数据都包含其它视特征的信息。实验结果证明,本文提出的方法在多视数据降维的同时能够促进多视数据的融合,并且能够提高后续聚类/识别任务的实验效果。虽然本文提出的方法能获得了令人满意的多视降维表现,但降维过程比较耗时,今后的研究将致力于如何降低算法的复杂度。
