失聪学生阅读中的词汇加工特点:消失文本证据*
2021-11-30刘志方曾台燊陈朝阳
刘志方 曾台燊 柴 林 陈朝阳 仝 文
(1 杭州师范大学心理学系,杭州 311121) (2 宁波特殊教育中心学校,宁波 315211)(3 宁波大学心理学系,宁波 315211) (4 山西师范大学心理学系,临汾 041000)
1 引言
词汇是各类语言材料的重要语义单元。中文的基本书写单元是汉字,汉字数量繁多,字形结构复杂,每个汉字往往包含丰富的语义信息。约72%的中文词汇由两个汉字组成,故针对双字词汇的研究结果最具有代表性。研究表明,健听学生阅读时,单字加工是实现双字词汇识别的必要环节(Yan, Tian, Bai, & Rayner, 2006)。有观点认为,中国读者基于汉字单元知觉和编码视觉信息进行识别(Chen, Song, Lau, Wong, & Tang,2003)。还有研究表明,读者能够基于整词通达路径激活、识别双字词汇(Liu & Peng, 1997; Shen, Li, &Pollatsek, 2018)。张学新等人(2012)也发现,双字词汇重复出现会导致N200波幅增大,它可以反映整词词形的加工。
以往研究发现,健听人群识别多字词汇时,涉及单字加工与词的加工两个阶段(Li, Rayner, &Cave, 2009; Ma, Li, & Rayner, 2015)。有研究采用消失文本范式,探讨双字词汇的加工过程,结果发现,词n+1上汉字消失影响健听学生总阅读时间的程度与消失汉字的数量有关,词n+1上单个汉字消失影响总阅读时间的程度小于整个词n+1消失条件;而词n上汉字消失对健听学生句子总阅读时间的影响与消失汉字数量、位置没有关系,词n上单个汉字消失与词n整词消失在相同程度上影响句子总阅读时间;研究者据此推测,健听读者会在预视中执行字的加工,在注视中执行词的加工(刘志方, 张智君, 潘运, 仝文, 苏衡, 2017)。
失聪学生阅读中的词汇加工是否也需要经历单字加工与词的加工两个阶段呢?探讨这个问题有利于澄清中文词汇识别的普遍性加工机制。失聪学生学习阅读时无法使用口语参照,其语言理解加工主要依赖视觉信息(Bélanger, Baum, &Mayberry, 2012)。相对于健听学生,他们具有预视词汇编码优势(刘璐, 闫国利, 2018)。英语与中文阅读研究也一致表明,失聪学生的阅读知觉广度大于健听学生(乔静芝, 张兰兰, 闫国利, 2011;Bélanger, Slattery, Mayberry, & Rayner, 2012)。本研究拟探讨失聪学生阅读中的词汇加工过程是否不同于健听学生。
研究拟观察失聪学生与健听对照组阅读消失文本时的差异,探讨失聪学生阅读中的词汇加工的过程特点。研究包含两项实验,实验1操控词n+1呈现方式,以探究失聪学生的预视词汇加工过程特点;实验2操控词n呈现方式,以探究失聪学生的注视词汇加工过程特点。研究选择阅读能力匹配组、年龄匹配组作为失聪学生的对照组。理由如下:首先,阅读能力影响词汇加工,成年失聪学生的阅读能力仅与小学三年级学生相当(Holt,1994),因此选择小学三年级学生作为能力匹配组;其次,为排除眼动控制系统成熟度的影响,选择了年龄匹配组。
研究首先澄清失聪学生阅读对预视加工、注视加工的依赖程度与健听学生间的差异,对此研究假设:若组别与呈现条件交互作用显著,说明失聪组与健听组读者之间存在差异,否则说明失聪组与健听组读者之间没有差异。其次,厘清失聪学生阅读对字的加工、词的加工的依赖性特点,研究假设:倘若失聪学生识别复合词汇侧重于依赖单字加工,那么两个实验中单个汉字消失条件影响其消失文本总阅读时间的程度都小于整词消失条件;倘若失聪学生识别复合词汇侧重于依赖词的加工,那么两个实验中单个汉字消失条件影响失聪学生的消失文本总阅读时间的程度与整词消失条件差异不显著。
2 实验1:失聪学生加工词n+1的过程特点
2.1 被试
三组被试共计104人参与实验。其中失聪学生组被试32名,均为浙江省内两所特殊教育学校的高年级学生。参照阅读流畅性测验和正字法意识测验选择能力匹配组被试(刘璐, 闫国利, 2018),在浙江省内某小学三年级学生中选取了36名阅读能力匹配组被试。年龄匹配组的36名被试为浙江省某高校大一新生。失聪学生组平均年龄为18.3±1.7岁;年龄匹配组平均年龄为18.5±1.2岁;能力匹配组平均年龄为9.2±0.6岁。失聪学生组和年龄匹配组在年龄上差异不显著[t(66)=−0.51,p=0.66],失聪学生组的平均年龄显著大于能力匹配组[t(66)=30.17,p<0.001]。失聪学生组、能力匹配组和年龄匹配组阅读流畅性测验成绩均值分别为:207字/分钟,222字/分钟,471字/分钟,失聪学生组与能力匹配组差异不显著[t(66)=−0.51,p>0.05],但小于年龄匹配组 [t(66)=−30.17,p<0.001]。三组被试在正字法意识测验上的分数均值分别为:38.37,37.00和45.64,其中失聪学生组与能力匹配组差异不显著[t(66)=0.65,p>0.05],但显著小于年龄匹配组[t(66)=−2.77,p<0.001]。失聪学生被试均为重度失聪人员(听力≥90dB),其他两组被试听力均正常,所有被试的视力或矫正视力正常,之前均未参加过任何类似实验,实验结束后获得一定报酬。
2.2 实验材料
实验句子均完全由双字词构建而成,每个句子由7或8个双字词组成。未参与实验的10名本科生、10名失聪学生和10名小学三年级学生分别对实验材料进行难度评定(5点评定,分值越高表示句子难度越低),选取的80个实验句子的平均难度差异不显著(p>0.05)。其中有20个句子带有问题,以筛选被试是否认真阅读句子。
2.3 实验设计
实验采用3(组别:失聪学生组、能力匹配组、年龄匹配组)×4(呈现方式:控制条件、词n+1首字消失、词n+1尾字消失、词n+1消失)混合设计,其中组别为被试间变量,呈现方式为被试内变量。各种消失条件的举例见图1。正在被注视的词汇被称为“词n”,词n+1上首字消失条件是指在当注视点落在词n时,词n+1上首字消失;词n+1上尾字消失是指在当注视点落在词n上时词n+1上尾字消失;词n+1消失是指在当注视点落在词n上时整个词n+1(两个汉字)消失。

图1 实验1各呈现条件举例
2.4 实验仪器
采用加拿大SR公司生产的Eye Link 1000型眼动仪(桌面式)记录被试的眼动。该型设备采样频率为1000 Hz,空间分辨率小于0.01°。采用液晶屏呈现刺激材料,其属性如下:刷新频率为60 Hz,屏幕19英寸,分辨率1024×768像素。被试距离呈现实验材料屏幕为58 cm,句子以20号宋体形式呈现,单个汉字视角为1.02°。液晶屏刷新频率导致文字消失约有17 ms的延迟,这个时间不足以支持读者识别消失汉字(Liversedge et al., 2004)。
2.5 实验程序
首先对被试进行阅读流畅性测验和正字法意识测验,随后开始眼动实验。给被试戴好头盔并固定头部,在电脑上呈现指导语,主试向被试口头解释一遍,失聪学生组被试则由其老师采用手语解释指导语,被试完全理解指导语后,再对眼动仪器进行校准。随后呈现练习句,然后进入正式实验。此外,当注视偏差大于0.5°时进行重新校准。整个实验过程大约持续25分钟。80个实验句子以拉丁方的方式在4个呈现条件内平衡。80个实验句子(无论以何种方式消失)都是按照随机顺序被呈现,其中有20个句子带有问题,要求被试通过按键回答问题。
2.6 数据分析
删除实验过程中被试错误按键导致句子呈现中断的数据,删除数据约3.95%。句子总阅读时间是消失文本研究中最重要的因变量指标(Liversedge et al., 2004)。采用R软件基于lme4包构建线性混合模型分析问题正确率和总阅读时间,正确率作为两分变量采用GLMMS模型进行分析,总阅读时间是连续性变量采用LMMS模型进行分析(Bates,Mächler, Bolker, & Walker, 2015)。分析模型中包含2个组别对比(失聪学生组分别与其他两组被试比较),控制条件与3个消失条件间对比及其这些对比间的6个交互作用项;除了上述固定因子外,还包含被试误差和项目误差两个误差项。结果报告回归系数b、标准误SE,t/z和p值。
2.7 结果
问题正确率。失聪学生组显著低于其他两组,失聪学生组正确率为0.72±0.45,能力匹配组正确率为0.84±0.37,年龄匹配组正确率为0.87±0.34,ps<0.05。失聪学生组与能力匹配组对比,b=0.91,SE=0.24,z=3.88,p<0.001,与年龄匹配组对比,b=1.25,SE=0.24,z=5.12,p<0.001。其他对比与交互效应都不显著(|z|s<1.45,ps>0.05),说明该指标对研究问题的检验不够敏感。
总阅读时间。由表1和图2可知,失聪学生显著少于能力匹配组,但其与年龄匹配组间差异不显著。各消失条件均显著大于控制条件。交互作用是最为重要的统计结果。统计结果中包含6个交互作用项,这代表检验研究假设6次,多次检验同一假设会增加“获得假阳性结果”的可能,参照Bonferroni校正标准,应该将显著性标准设置为0.0083(0.05/6≈0.0083)(Von Der Malsburg &Angele, 2017)。由表1可知,2项交互作用结果的显著性达到标准,说明失聪学生预视加工词n+1与健听学生不同。交互作用的简单效应分析显示,词n+1消失消极影响失聪学生总阅读时间的程度小于其对能力匹配组的影响程度(330 ms vs.616 ms);词n+1首字消失条件不影响失聪学生的总阅读时间(p>0.05),却导致能力匹配组总阅读时间显著增多(b=496,SE=104,t=4.78,p<0.001);词 n+1 尾字消失条件不影响失聪学生的总阅读时间(p>0.05),却导致能力匹配组总阅读时间增多(b=431,SE=104,t=4.16,p<0.001)。

表1 实验1包含组间对比、控制条件与消失条件对比的混合线性模型统计分析结果

图2 实验1各呈现条件下总阅读时间的均值和标准误差
重新构建模型,进一步探究消失条件间对比的组别差异。模型中包含2个组别对比和2个消失条件对比(词n+1消失分别与其他两个消失条件对比),及其4个交互作用项。由表2可见,仅一项交互作用的p值低于0.05。参照Bonferroni校正标准,应该将显著性标准设置为0.0125(0.05/4=0.0125),因此表2的结果不足以支撑阳性结果。贝叶斯检验计算包含交互作用项全模型和不包含交互作用项模型之间的比值,得到贝叶斯因子为0.031,实验结果倾向于支持组别与消失条件交互作用不显著。

表2 实验1包含组间对比和消失条件间对比的混合线性模型统计分析结果
2.8 讨论
实验1操控词n+1呈现方式,考察失聪学生预视加工词汇的过程特点。有如下发现:首先,失聪学生阅读时间少,正确率低。已有研究表明,阅读速度快的读者未必是阅读理解正确的读者(Perfetti, 2007)。失聪学生阅读过程(或者策略)不同于健听学生,其特点是阅读(眼动)速度快,加工深度浅,不够准确(贺荟中, 贺利中,2007)。其次,所有消失条件均影响能力匹配的总阅读时间;仅词n+1消失条件影响失聪学生的总阅读时间,而词n+1首字消失和词n+1尾字消失条件都不会增加其总阅读时间,表明失聪学生阅读对词n+1预视加工的依赖程度低于能力匹配组学生。最后,消失条件对比与组别交互作用不显著,说明失聪学生预视加工词n+1与健听学生无本质差异。
3 实验2:失聪学生注视加工词汇的特点
3.1 被试
被试选择标准与实验1相同。三组被试(失聪学生组36名,能力匹配组与年龄匹配组各32名)共计100人参与实验。失聪学生组平均年龄为18.5±1.3岁;年龄匹配组平均年龄为18.9±1.3岁;能力匹配组平均年龄为9.1±0.7岁。失聪学生组和年龄匹配组在年龄上差异不显著[t(66)=−1.29,p=0.20],失聪学生组的平均年龄显著大于能力匹配组[t(66)=37.08,p<0.001]。阅读流畅性测验显示,三组被试得分的均值分别为:216字/分钟,225字/分钟,470字/分钟,失聪学生组与能力匹配组差异不显著[t(66)=0.32,p>0.05],失聪学生组显著小于年龄匹配组[t(66)=−6.83,p<0.001];三组被试在正字法意识测验上得分的均值分别为:39.97,37.22和46.09,其中失聪学生组与能力匹配组差异不显著[t(66)=1.32,p>0.05],失聪学生组显著小于年龄匹配组[t(66)=−2.33,p<0.05]。所有被试的视力或矫正视力正常,之前均未参加过任何类似眼动实验,实验结束后可获得一定报酬。
3.2 实验材料、实验仪器和实验程序
实验材料、实验仪器和实验程序同实验1。
3.3 实验设计
实验采用3(组别:失聪学生组、能力匹配组、年龄匹配组)×4(呈现方式:控制条件、词n首字消失、词n尾字消失、词n消失)混合设计,其中组别为被试间变量,呈现方式为被试内变量。各种呈现条件的举例见图3。词n首字消失条件是指在当注视点落在词n时,词n上的首字消失。词n尾字消失条件是指在当注视点落在词n时,词n上尾字消失。词n消失条件是指在当注视点落在词n上时,整个词n消失。以上消失条件中,对词n的再注视不会导致消失的汉字重现。实验材料与实验条件间的平衡方式与实验1相同。
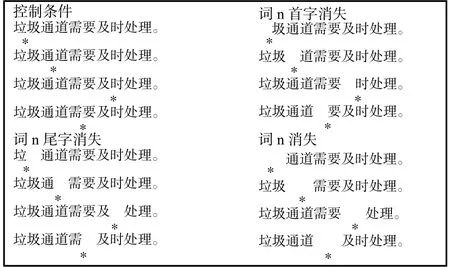
图3 实验2各呈现条件举例
3.4 数据分析
数据剔除标准都与实验1相同,总计3.02%的原始数据被剔除。句子总阅读时间和问题回答正确率处理方式与实验1相同。
3.5 结果
问题正确率。失聪学生组显著小于其他两组,失聪学生组正确率为0.72±0.45,能力匹配组正确率为0.82±0.38,年龄匹配组正确率为0.87±0.34,ps<0.05;失聪学生组与能力匹配组对比,b=0.78,SE=0.22,z=3.51,p<0.001;失聪学生组与年龄匹配组对比,b=1.23,SE=0.23,z=5.30,p<0.001。其他效应都不显著(|z|s<1.53,ps>0.05)。
总阅读时间。失聪学生组显著少于能力匹配组,失聪学生组与年龄匹配组间差异不显著。各消失条件都显著大于控制条件。各项交互作用均不显著。贝叶斯检验计算包含交互作用项全模型和不包含交互作用项模型之间的比值,得出贝叶斯因子为0.0002。实验结果更加倾向于支持组别与呈现条件对比交互作用不显著(具体见表3和图4)。
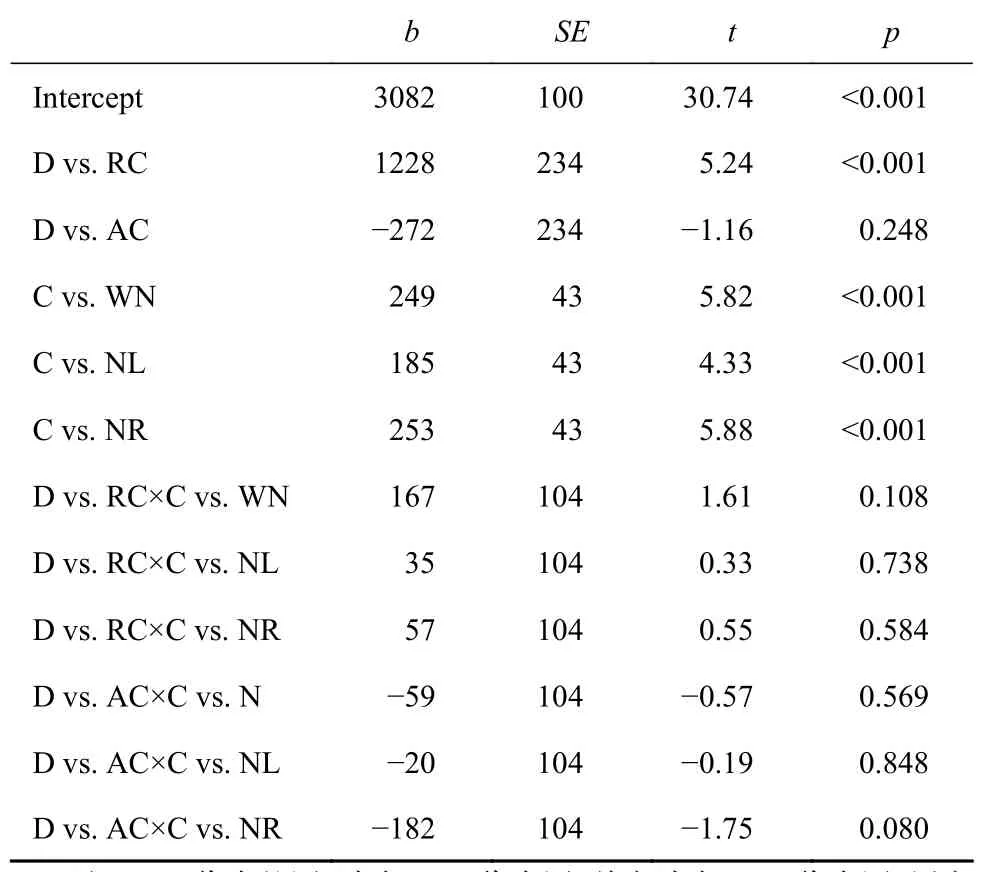
表3 实验2包含组间对比、控制条件与消失条件对比的混合线性模型统计分析结果
图4 实验2各呈现条件下总阅读时间的均值和标准误差
研究重新构建模型,进一步探究消失条件间对比的组别差异。模型中包含2个组别对比和2个消失条件对比(词n消失分别与其他两个消失条件对比),及其4个交互作用项。结果发现,交互作用均不显著(见表4)。贝叶斯检验计算包含交互作用项全模型和不包含交互作用项模型之间的比值,得出贝叶斯因子为0.00001;可见本实验结果提供极强的证据支持虚无假设,即各组读者在各消失条件总阅读时间上的差异不显著。

表4 实验2包含组间对比和消失条件间对比的混合线性模型统计分析结果
3.6 讨论
实验2操控词n呈现方式,探讨失聪学生加工注视词汇的过程特点。有如下发现:首先,总阅读时间和正确率的组别差异上,与实验1结果一致。其次,各消失条件在相同程度地影响各组读者的句子总阅读时间,结合贝叶斯因子分析结果可知,失聪学生的阅读对注视词汇加工的依赖程度与健听读者基本一致。最后,词n上单个汉字消失和整个词n消失在相同程度上影响各组读者的总阅读时间,由此可知,失聪学生也需要在注视中执行词的加工。
4 总讨论
本研究拟观察字词加工与失聪状态之间的交互模式,以了解失聪学生阅读中词汇加工过程的特点。根据以往研究可知,汉字加工(包括字形视觉分析、字形知觉和语义激活等)和词的加工都是识别复合词汇的必要环节(Li et al., 2009)。本研究基于消失文本实验,探讨失聪学生阅读字词加工过程特点。有两项主要发现:(1)词n+1上汉字消失影响失聪学生总阅读时间的程度小于两个健听学生组;消失条件影响各组读者总阅读时间的程度与消失汉字数量有关,词n+1上单个汉字消失并不影响失聪学生总阅读时间。(2)词n上单个汉字消失和两个汉字消失在相同程度上影响各组读者总阅读时间。实验1消失条件影响能力匹配组总阅读时间的模式与其影响年龄匹配组总阅读时间的模式一致;实验2消失条件影响能力匹配组总阅读时间的模式与其影响年龄匹配组总阅读时间的模式也一致。通过这两个一致结果可以排除眼动控制系统成熟度影响结果的可能性。
健听读者主要是在预视中执行单字加工,在注视中执行词的加工并完成词汇语义通达(刘志方等, 2017; Ma et al., 2015)。实验1发现,失聪学生阅读对词n+1加工的依赖程度低于健听学生。有两个可能的原因导致这个结果:第一,失聪学生阅读知觉广度内词汇的数量多于健听学生(乔静芝等, 2011; Bélanger, Slattery et al., 2012),这导致其阅读过程对识别加工具体词汇(例如,词n+1)的依赖程度低于健听学生。第二,失聪学生预视加工词n+1的深度浅于健听学生(贺荟中, 贺利中,2007)。这两种原因都说明,失聪学生的预视加工词汇的过程不同于健听学生。然而,从各消失条件影响总阅读时间程度的差异来看,失聪学生的消失文本阅读时间与消失汉字的数量有关,可见失聪学生的词汇语义通达也依赖于字的加工。
有观点认为,读者基于汉字单元知觉和编码视觉信息,复合词的识别加工涉及汉字组合过程(Chen et al., 2003);但也有观点认为,复合词汇加工涉及词形激活与整词通达(张学新等, 2012;Liu & Peng, 1997)。本研究发现,失聪学生和健听学生阅读中识别双字词汇都不能回避“字的加工”,这有悖于整词通达原则。Shen等人(2018)利用边界范式发现,青年学生以整词通达的方式识别双字词汇,该研究将边界设置在注视词汇(词n)的中间,其研究结果说明注视词汇(词n)的识别是基于整词通达路径。实验2发现,词n上汉字消失条件对影响总阅读时间的程度与消失汉字数量无关,这个差异模式在各组别完全一致,由此可知,失聪学生的阅读也依赖于词的加工,但他们与健听学生一样,主要在注视中执行词的加工。综合两项实验的结果可知,失聪学生阅读并非只依赖于字的加工或者词的加工,其对多字词汇的加工也可被大致分为单字加工和词的加工两个环节。
阅读中,注视位置的任何微小改变都会导致映入脑区的视觉信息发生变化,视觉信息被及时转换成为稳定视觉编码方能保证词汇识别。拼音文字阅读研究发现,读者首先及时地将视觉信息转换成为稳定视觉编码(约需要50 ms),然后基于这一视觉编码完成词汇识别(Liversedge et al.,2004)。中文阅读研究显示,青年健听读者可以及时完成词n+1上汉字的视觉编码,还需要在注视中依赖视觉信息完成整词视觉编码,表明中文词汇识别依赖视觉信息的程度较重(刘志方等,2017)。失聪学生主要利用视觉线索识别词汇(Bélanger, Baum et al., 2012),中文的这一语言特殊性虽然与失聪学生认知特点相互契合;但本研究发现失聪学生仍会在注视中执行整词加工。由此可见,失聪学生虽具有视觉加工优势,但也不能超越词汇加工的阶段性,词的加工是整词识别和文本理解的必要环节,这个规律在各类人群内具有普适性。
5 结论
失聪学生的阅读对词n+1预视的依赖程度低于健听学生;双字词汇识别需要先后经历字的加工和词的加工两个环节,这个过程适用于失聪学生。
