混合动力汽车行驶工况的在线识别
2021-11-30牛礼民徐瑞康朱奋田邓末芝徐家义
牛礼民,徐瑞康,朱奋田,邓末芝,徐家义
(1.安徽工业大学机械工程学院,安徽马鞍山 243032;2.苏州大学机电工程学院,江苏苏州 215137;3.湖南大学机械与运载工程学院,湖南长沙 410082)
随着节能减排要求的不断提高,混合动力汽车以其较低的排放与较高的可靠性逐渐成为汽车行业关注的新星。混合动力汽车的控制策略主要包括能量管理策略和转矩分配策略,能量管理策略是控制策略的重中之重,目的是解决两个动力源产生的工作模式切换问题,并对整车系统能量进行合理分配。目前,实车中大规模运用的多是基于规则的能量管理策略,该策略的制定是依据设计人员的工程实践经验,具有极大的随意性。汽车行驶工况指在特定环境下某类型汽车的行驶速度与时间的数据点,是一组基于时间变化的时间序列。整车在实际行驶过程中行驶工况是不断变化的,因此使能量管理策略能够适应这种变化,将有利于提高增程式电动汽车的自适应能力,改善燃油经济性。
针对上述问题,已有学者开展了将工况识别与整车控制策略相结合的研究,如Murphey 等从车速中提取14 个变量,通过BP(back propagation)神经算法实现了行驶工况的识别与预测,仿真结果表明在工况识别的帮助下,整车的燃油经济性有所提高;邓涛等采用聚类分析方法完成工况分类,计算各典型工况对应的最优等效因子,将其作为当前优化输入,提出了一种基于工况识别的自适应等效燃油最低控制策略;蒋通选取19 种典型工况中的5 种作为标准工况,采用BP 神经网络算法完成对工况类型的识别,使用粒子群算法对神经网络的初始权阈值进行预处理,实现了对工况识别效果的优化。但这些方法计算量偏大,无法与车辆模型完全结合,不适宜在实车中运用。鉴于此,结合能量管理优化设计的要求,提出一种可在线识别、可整体嵌入整车仿真模型的混合动力汽车工况识别方法,搭建整车的在线工况识别模块验证该方法的可行性,以期为混合动力汽车控制策略优化提供新思路。
1 工况识别标准的制定
1.1 样本工况的选取
在线工况的识别需制定相应标准,该标准应根据已有的样本工况确定,样本的选取包含两部分内容:选取参与分类的具体工况,样本工况需有一定的数量,工况数过少则不能够完全表现出特定种类下工况的特征,过多则会使工况分类计算量急剧上升;选择具有较高辨识度的工况特征参数,将其作为工况分类计算的重要参考量。文中选取美国可再生能源实验室开发的ADVⅠSOR 软件工况文件库中的32 个工况为样本工况,选取最高速度v
、平均速度v
、平均加速度a
与减速段平均加速度a
4 个辨识度高的参数为工况特征参数。1.2 基于聚类分析的工况分类
聚类分析是一种非监督式学习,其把相似的对象通过静态方法分成不同的组别或子集,在同一个子集中的成员对象有相似的一些属性。目前常用的聚类算法包括K
-Means 聚类算法、凝聚型层次聚类算法、神经网络聚类算法与模糊聚类的FCM 算法等。K
-Means 算法计算效率高,在大型数据聚类分析中应用广泛,文中使用K
-Means 算法对样本工况进行分类,将p
个含有m
维参考量的数据转化为在m
维空间中的p
个点,再随机地在该空间中选定k
个初始聚类中心点。在每个计算步中,先计算各点与聚类中心点间的欧式距离,按距离聚类中心点最近的原则将数据点分为k
类,分类后在各类数据点包络的空间中随机选择聚类中心点,进入下一个聚类计算步;经多次迭代优化,当聚类中心点收敛为明确点时算法结束。K
-Means算法流程图如图1。
图1 K-Means算法流程图Fig.1 K-Means algorithm flow chart
由于K
-Means 算法在工程实践中的广泛应用,MATLAB开发了基于K
-Means算法的函数。输入已知条件后,MATLAB将自行完成聚类分析,如式(1)。
x
为p
维列向量,表示各数据点所属组别的代号;C
为k
×m
矩阵,表示各聚类中心点的空间坐标;s
为k
维列向量,表示分类后各数据点到其所属组别聚类中心点距离之和;D
为p
×k
矩阵,表示各数据点到聚类中心点的距离;X
为p
×m
矩阵,表示输入函数的初始表数据。文中将样本工况数据分为3类,即取k
=3,把样本工况特征参数按要求输入MATLAB的“kmeans”函数运行程序,得到样本工况分类结果如表1。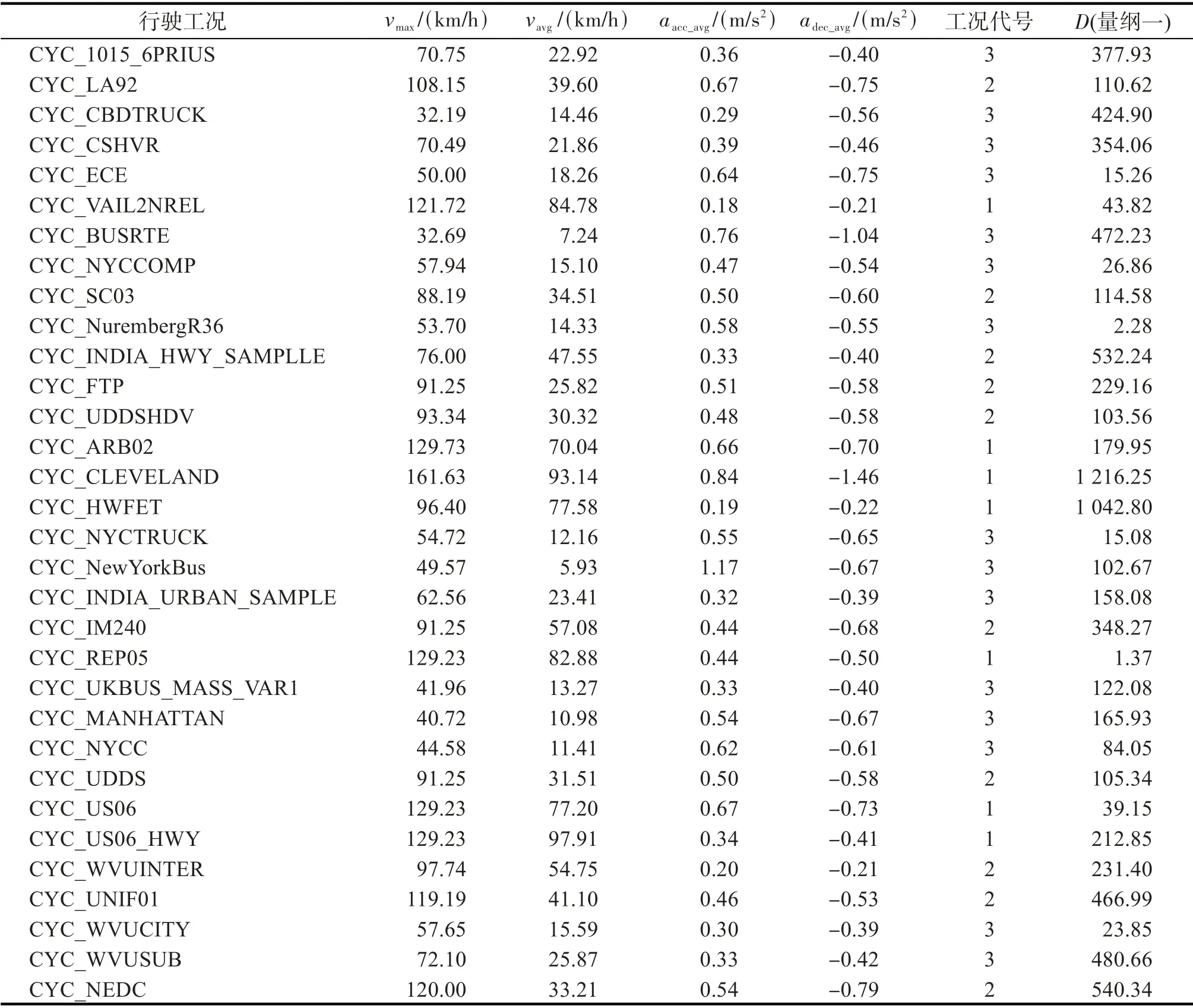
表1 样本工况的特征参数与分类结果Tab.1 Characteristic parameter and classification result of sample working condition
“kmeans”函数给出的分类结果仅是数据点所属组别的代号,需对分类后的工况种类代号的实际意义进行讨论。从表1可看出:工况1的最高速度在100 km/h以上;工况2的最大速度多在70~100 km/h之间;工况3的速度最低,平均速度基本小于20 km/h。参考文献[9-10]的分类方法,将工况1,2,3 分别命名为高速工况、郊区工况与城市工况。为制定用于在线工况识别模块的工况分类标准,根据表1 中的工况分类结果归纳各工况类别的特征参数区间,出于减小特征参数区间重合度的考量,剔除每类工况中距离聚类中心最远的2个数据,得到的行驶工况类别及特征参数区间如表2。

表2 行驶工况类别及其特征参数区间Tab.2 Category and characteristic parameter interval of driving condition
2 在线工况识别模块的搭建
2.1 在线工况识别方法
参考表1 中工况分类结果,提出一种在线工况识别方法:在整车运行过程中,选定固定的时长作为计算周期,每个周期由计算时间与提取时间组成,计算时间内,实时计算行驶工况特征参数数据;提取时间内,将其与表2的特征参数区间进行匹配,确定整车所处的实时行驶工况,而后将工况数据清零。在线工况识别模块的搭建应遵循以下原则:周期性数据清零在每个周期的计算时间开始前需将上一个周期的所有工况特征参数清零;提取时间内数据保持为保证计算数据与特征参数区间成功匹配,使计算数据在提取时间内维持其在计算时间最后一刻的值不变。
需要指出的是,由于整车行驶数据产生与特征参数计算在逻辑上的先后关系,在工况识别模块工作的过程中,本计算周期的行驶工况识别结果在下一个计算周期开始时才会解出。也就是说,在后续利用工况识别进行能量管理策略优化时,在线工况识别模块输出给控制系统的工况类别信号会延迟一个计算周期。这在数学上并不严谨,但在工程实践中是可以接受的。实际行驶中,一般地,在一个较短的时间周期内(如几分钟),整车所处的工况类别会维持相对稳定;在整个行驶过程中,整车所处的工况类别的变化次数远小于经历的时间周期数,因此即使工况识别系统有一定的延迟,在多数时间内其仍可正确判断整车所处工况类别。
按上述原则要求,确定计算周期的时长与周期内时间的划分。计算周期的确定应考虑两方面因素:一方面需足够的时长,使在线工况识别模块计算出的特征参数值在一定时间范围内保持稳定,能反映出整车行驶的实际状态;另一方面过长的计算周期不可避免地延长了在线工况识别模块对实际工况改变的响应时间。参考文献[12]的方法,将计算周期定为60 s:每个计算周期内0~1 s,59~60 s 为提取时间,1~59 s 为提取时间;每个时间周期的第60 s进行特征参数匹配。具体计算周期的时间划分如图2。
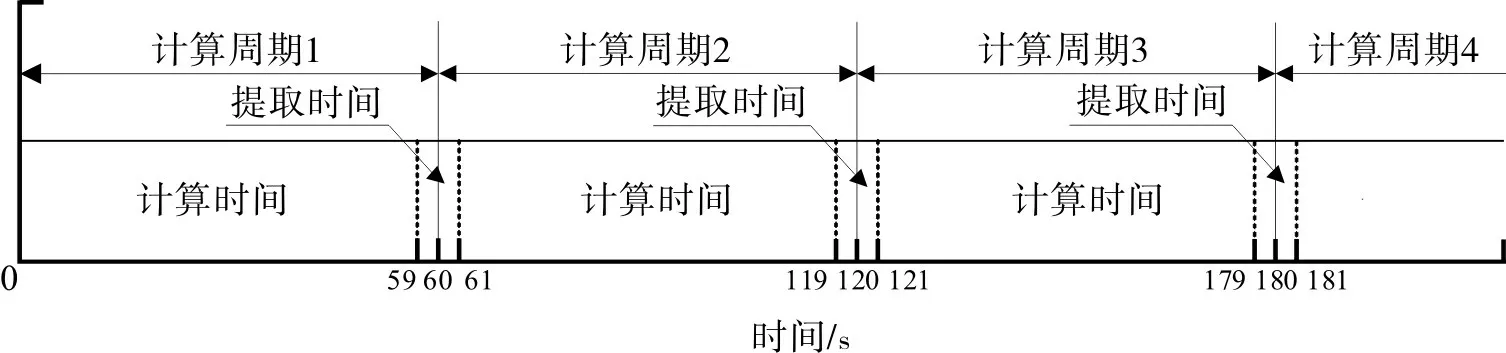
图2 计算周期的时间划分Fig.2 Time division of the calculation period
2.2 在线工况识别模块
根据上节确定的方法,将在线工况识别模块分为3 个部分:重置信号发生器、特征参数计算器与特征参数比较器。选取某型串联式混合动力汽车,其动力系统参数如表3,在该车的Simulink 仿真模型中搭建在线工况识别模块。

表3 某型HEV动力系统部分参数Tab.3 Some parameter of the HEV powertrain
2.2.1 重置信号发生器
为满足数据计算、清零与保持的要求,引出一个重置信号对这3个动作进行联合控制。从图2可看出,每个时间周期计算时间58 s、提取时间2 s,此外每段提取时间都被均分到2个计算周期内。为简化重置信号输出,保证系统稳定性与可靠性,将重置信号输出的坐标整体相对于图2 向左平移1 s,即重置信号在每个计算周期内0~58 s输出计算信号,58~60 s输出提取信号;而后于工况特征参数的输出阶段再整体延时1 s,实现工况的准确识别。
根据上述思路在Simulink中搭建重置信号发生模型,如图3。采用数值为1的常数模块与上出发清零积分模块完成计算周期计时,Simulink 积分模块的自变量为输入值,积分区间为0 到积分模块的工作时间,因此随仿真时间的推进,积分模块输出值为仿真时间;上触发清零功能输入接口接入积分模块输出值与数值60 之差,当积分模块输出值超过60 时,接口输入值从负数上跳为正数,积分模块输出与计时清零,完成重置,进入下一个60 s计算周期的计时。
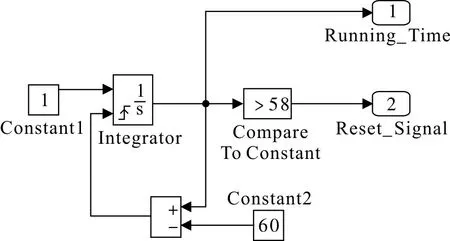
图3 重置信号发生器Fig.3 Reset signal generator
积分模块输出值还会进入数值为58 的常数比较模块:在每个计算周期的0~58 s 内,输入值小于58,模块输出值为0;在每个计算周期的58~60 s 内,输入值大于58,模块输出值为1,将常数比较模块输出的值0和1作为重置信号。
2.2.2 特征参数计算器
特征参数计算器接收设备系统计算出的车辆行驶速度与加速度,在重置信号的控制下计算整车行驶特征参数。在上一节中搭建的重置信号发生器输出的信号仅保证了计算时间与提取时间的时长,还需在特征参数计算器的每个输出量后添加一个延迟模块,使特征参数的输出整体延时1 s。按以下计算公式搭建特征参数计算器。

v
与v
分别为当前计算步与上一计算步的整车行驶速度;t
为各计算周期的开始时间;t
为截止到当前计算步已经历的仿真时间;a
为整车的正向加速度;t
与t
为计算时间内各加速区间的开始时间与运行时间;a
为与整车减速时的反向加速度;t
与t
为计算时间内各减速区间的开始时间与运行时间;i
与j
为特征参数的计算步(i
,j
=1,2,…,n
)。搭建的各特征参数计算器的模型如图4。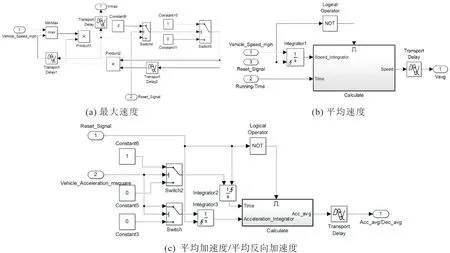
图4 特征参数计算器Fig.4 Characteristic parameter calculator
由图4(a)可知,计算最大速度时,将当前计算步的整车行驶速度与经Transprot Delay1模块延迟1个计算步的速度输入max取大模块,得到计算周期内的最大速度。为保证下一个计算周期开始前输出数据清零,引入两个开关模块:当重置信号为提取信号时,Reset_Signal 输入由0 转为1,Switch4 模块开关接到下方,与输出最大速度相接,由于速度值必不为负数,触发Switch5模块开关接到下方,向max取大模块与最大速度输出数值0。计算步长时间为0.001 s,远小于提取时间的时长,因此在下一个计算周期开始前,max 取大模块的2个输入值都将为0,实现了清零功能。
由图4(b)可知,计算平均速度与平均加速度/平均反向加速度时,引入使能子系统实现由重置信号直接控制的数据清零。将特征参数计算模块放入使能子系统,当重置信号为计算信号时,Reset_Signal输入值为0,经“非”模块转变为1,触发使能子系统工作;当重置信号为提取信号时,使能子系统不工作,特征参数输出为0,直到下一个计算时间开始。
此外应当注意,不能直接使用重置信号发生器输出的时间计算平均加速度/平均反向加速度。这是由于整车在各计算周期内不是时刻在加速或减速的,计算时输入积分模块的时间应是计算时间中加速/减速的时间,需用Ⅰntegrator2上触发清零模块另行搭建专用计时器,如图4(c)。
2.2.3 特征参数比较器
基于精确逻辑门限值,使用Simulink 中的有限状态机(finite-state machine,FSM)搭建特征参数比较器模型,如图5。Stateflow 模块根据特征参数计算器计算出的实时值与表2 中各工况类别的特征参数区间,每间隔60 s 判断一次整车所处的工况类别。由于车辆实际行驶一般从低速工况开始,设定特征参数比较器初始工况类别输出为城市工况代号,当计算周期的判断时刻,Stateflow模块输入特征参数处于郊区工况或高速工况的特征参数区间时,特征参数比较器相应输出郊区工况或高速工况代号,否则维持输出城市工况代号。

图5 在线工况识别系统Fig.5 Online condition identification system
3 在线工况识别功能验证
为验证在线工况识别模块功能的有效性,将搭建的在线工况识别模块接入车辆模型的控制子系统(如图6),对修改后的车辆模型进行在线仿真。文中选用第3 级全球轻型车辆统一测试循环(worldwide harmonized light vehicles test cycle,WLTC)作为随机行驶工况,该工况不属于ADVⅠSOR 文件库工况,是我国新采用的国六标准对接的国际标准——全球轻型车辆测试规程的标准工况,其中包含约55%的城市道路、26%的郊区道路以及19%的高速公路驾驶循环。
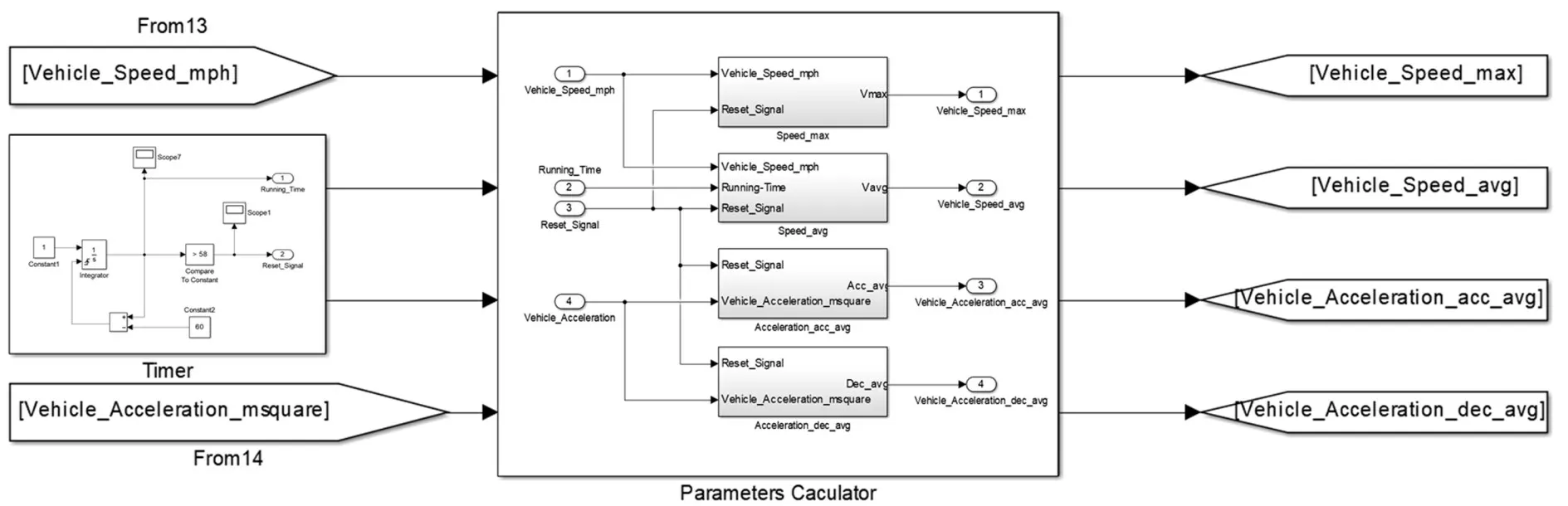
图6 在线工况识别系统Fig.6 Online condition identification system
图7为车辆仿真过程中的速度跟随情况。由图7可看出,车辆实际车速与期望车速基本重合,速度跟随状况良好,动力学性能满足实际行驶要求。说明在线工况识别模块的嵌入不影响车辆模型的正常仿真过程,可满足联合仿真的要求。
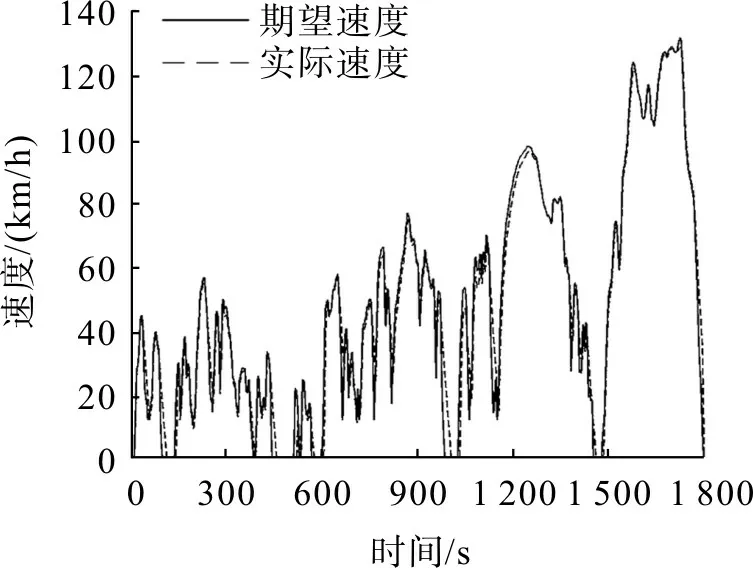
图7 速度跟随效果Fig.7 Following effect of speed
图8 为随机工况的区间划分与工况识别结果。由图8 可看出:在线工况识别模块可在车辆模型中工作,且较准确地反映了整车实时行驶工况;当车辆行驶在城市道路时,模块输出城市工况对应代号,当车辆行驶在郊区道路与高速道路时,模块输出郊区工况与高速工况的对应代号。以工况正确识别时长为表征的识别精度达86%以上,总体满足了设计要求。

图8 在线工况识别结果Fig.8 Identification result of online condition
基于在线工况识别方法提出一种混合动力汽车多点控制优化策略,该策略利用整车运行过程中的在线工况识别结果,自适应优化相应控制参数以减少燃油消耗量。搭建基于WLTC 工况改造的组合工况,该工况的主要参数为行驶距离46.53 km、最大速度131.3 km/h、最大加速度1.678 m/s,减速段最大反向加速度-1.5 m/s。采用优化策略与传统电能消耗(charge depleting, CD)控制策略的整车模型分别进行模拟仿真,得到的等效燃油消耗曲线如图9。由图9 可看出,相比于CD 策略,优化策略减少了整车行驶过程中10.74%的等效燃油消耗量,验证了引入文中所提方法对混合动力汽车控制策略优化的有效性。
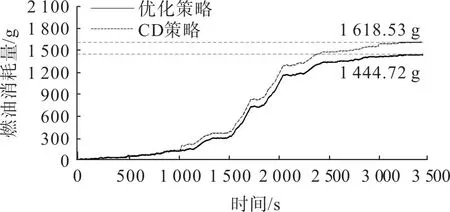
图9 不同控制策略的等效燃油消耗曲线Fig.9 Equivalent fuel consumption curves of different control strategies
4 结论
以选定标准工况特征参数为研究对象,使用聚类分析K
-Means 算法求出不同工况类别的特征参数区间,提出一种在线工况识别方法,通过搭建在线工况识别模块并嵌入混合动力汽车模型中验证所提方法的正确性,得到以下主要结论:1)在线工况识别模块可在选定的混合动力汽车仿真模型中按设计要求工作,嵌入模块后的模型仍能实现车辆实际速度对期望速度的跟随,满足车辆各项动力学设计要求。
2)在线工况识别模块可在线周期性地识别行驶工况的类别并输出相应代号,工况识别精度高,对实际工况变化的响应时间短;基于在线工况识别方法提出的混合动力汽车优化控制策略能较大幅度地提高整车燃油经济性,验证了本文提出在线工况识别方法的实时性和有效性。
下一步将开展工况识别特征参数区间的硬件在线仿真试验,并基于该工况识别方法研究各工况类别下车辆的需求功率特点,对混合动力汽车控制策略进行深层次优化。
