滚动轴承多分类故障诊断技术研究
2021-11-29刘琦
刘 琦
(92493部队60分队,辽宁 葫芦岛 125000)
0 引言
滚动轴承是在机械设备中非常重要的关键部件之一。据统计,超过50%的旋转机器故障与轴承故障有关,实施滚动轴承状态监测与故障诊断具有非常重要的意义。
在当今工业现场,应用最多的是基于信号分析的故障诊断技术,其主要判据是故障特征频率和特征图谱。这种诊断方法要求技术人员熟悉设备的故障机理,了解设备的机械结构,储备大量的先验知识,但其诊断效率和准确度不高,难以适应日益复杂的机械设备系统。随着大数据时代的到来与人工智能技术的突破,机器学习显示出了巨大的潜力,智能诊断方法在故障诊断中显示出了充分的可行性和优越性[1]。在机电大数据时代,如何有效利用海量生产制造数据并发挥出数据的价值,越来越成为工业转型的研究热点和重要突破口。
1 轴承数据的预处理与挖掘分析
1.1 数据获取
滚动轴承出现损坏故障的原因是复杂多样的。大体上,可以将轴承的故障主要划分为以下3种:外圈故障、内圈故障、滚珠故障。本文轴承故障数据来源于DC竞赛开源数据的真实轴承振动信号数据集,数据集提供了792个数据样本。通过按时间序列连续采样,数值范围为1~6000,得到振动信号能量值。采用的轴承具有3种直径(直径1,直径2,直径3),结合3种故障状态,将轴承的故障类别定义为9类,外加正常的工作状态,共将轴承的工作状态定义为10类。标签数据代表轴承的工作状态,用数字0~9表示,轴承的工作状态类别见表1。
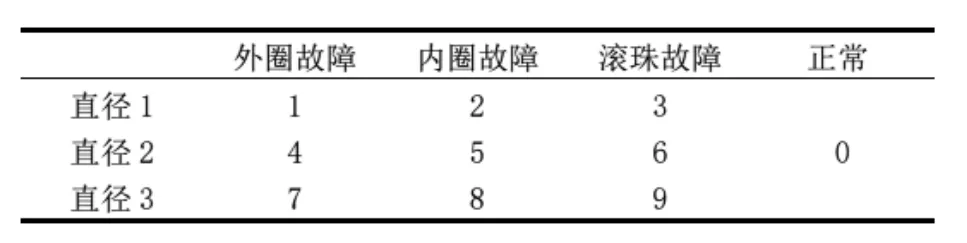
表1 轴承的工作状态类别Table 1 Working state category of bearing
1.2 数据预处理
因数据集是轴承采集的真实数据,且数据质量很高,本实验不需对异常值进行处理。因此,本实验数据的数据清洗工作主要为缺失值的处理,本文采取填补法处理缺失值。考虑到实验数据为时序数据,针对空值取其前后各10组数据的平均值作为估计值。
1.3 特征分析
本实验数据是轴承在一段时间内的振动信号数值及其故障类别,振动信号数值已经说明,时间序列的同列取值不相关,甚至可以认为每一组数据时间序列数目也不一样,所以必须对时序数据提取特征。本文提取了平均值、标准差、方差、最小值、最大值、中位数、偏度、峰度等8个时序数据特征值。
2 模型应用与训练
故障诊断可以视作一个模式识别问题,正常运行状态与各种故障状态都可以看作是一种特定的模式,可以根据提取出的特征进行分类识别。
2.1 多分类诊断模型
如果预测的是离散值,例如“好西瓜”“坏西瓜”,那么此类学习任务称为“分类”。当分类任务只包含两个类别时,称为“二分类”任务,例如判断一个水果是不是西瓜,只会得到“是”或“不是”两种输出;当分类任务包含多个类别时,称为“多分类”任务,例如判断一个水果是西瓜、苹果、菠萝还是橙子等多个水果中的哪一种。
对于N个类别而言,多分类学习的基本思路是“拆解法”,即将多分类任务拆解为若干个二分类任务。具体而言,首先选定合适的拆分策略对问题进行拆解,然后针对每个拆解出来的二分类任务训练一个分类器,最终通过某些策略对分类器的结果进行集成即可得到最终的多分类结果。
2.2 基于随机森林的轴承故障诊断
随机森林是一种采用决策树为基础模型的Bagging扩展变体,进一步在决策树的训练过程中引入了随机属性选择,在稳定性和准确性上取得了良好效果,得到了广泛的应用。
简单来说,随机森林就是独立取出训练样本生成决策树,通过建立多棵决策树进而组成一片“森林”。与单棵的决策树进行比较,随机森林采用合适的策略将多棵决策树的结果进行结合,分类结果由多棵决策树共同决定,弥补了决策树存在过拟合情况的缺陷,分类精度更高。
2.3 基于LightGBM的轴承故障诊断
为了解决梯度提升决策树(GBDT)在海量数据中遇到的问题,2017年微软在GBDT的基础上推出了LightGBM算法,在模型训练速度和内存方面进行了一定的优化,取得了不错的应用表现。
under the new global economic and trade situation.(209)很明显“顺应全球经贸发展趋势”在汉语是谓语,但在英语译文中是状语;“积极主动”是定语修饰“开放战略”,但是英语中更适合作状语 actively promote the opening--up strategy。实际上汉语应该这样表达“更加积极主动地实行开放战略,所以有的极个别汉语表达是具有迷惑性的,无意中会引起翻译的困难。
面对海量数据,GBDT算法处理起来相对复杂,计算开销非常大,难以兼顾精度和效率。而LightGBM模型的提出,主要在基于梯度的单边采样(GOSS)和互斥特征绑定(EFB)两个方面做出了改进,大大降低了计算复杂度,在提升了模型计算效率的同时,还可以保证较高的准确率。
2.4 基于XGBoost的轴承故障诊断
极限提升树算法(XGBoost),是陈天奇提出的基于Boosting思想的一种梯度提升改进方法。XGBoost能够利用CPU进行多线程并行计算,具有较高的运行效率;同时XGBoost在传统GBDT算法的基础上,对代价函数实现二阶泰勒级数展开,把树模型复杂度作为正则项加到优化目标中,减少了过拟合的可能性,使学习到的模型泛化能力更高,加快了收敛速度[3]。XGBoost以其灵活、高速、稳健等众多优点,使其在机器学习和数据挖掘等科研领域广受关注,目前多被用于构建故障诊断预测模型。
2.5 基于CNN的轴承故障诊断
卷积神经网络(CNN)是一种经常用来处理具有类似于网格结构的数据的神经网络,是目前主流深度学习算法之一[4]。
卷积神经网络是典型的层叠结构,其网络基本结构包括输入层、卷积层、池化层、全连接层和输出层,示意图如图1所示。
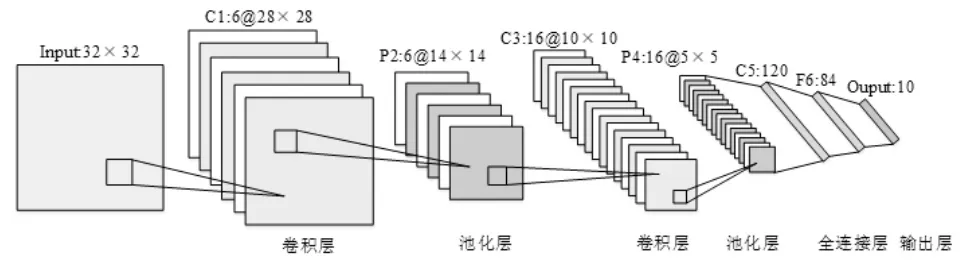
图1 典型卷积网络结构示意图Fig.1 Schematic diagram of a typical convolutional network structure
2.6 评价指标
在经过数据预处理、特征处理与分析等流程之后,就可以开始构建模型了。一般地,会基于已有数据构建多个模型,从中选出与数据最为匹配的模型。此时,就需要利用评价指标衡量模型的效果。结合本文的研究任务,选取查准率、召回率、F1-Score、ROC曲线和AUC作为模型评价指标。
2.6.1 查准率
查准率(Precision)的定义是模型判为正例的所有样本中有多少是真正的正样本,其定义如式(1)所示:

2.6.2 召回率
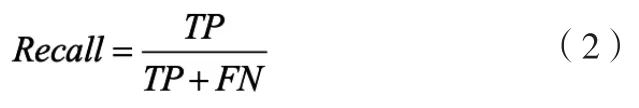
2.6.3 F1-Score
F1-Score的定义是精确率和召回率的调和平均值,其定义如式(3)所示:
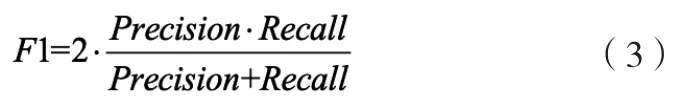
2.6.4 ROC曲线和AUC
ROC(Receiver Operating Characteristic) 曲 线 和 AUC(Area Under Curve)常用来评价分类器的优劣。ROC曲线的横轴为假正例率(FPR),即反例被误判为正例的比率;纵轴是真正例率(TPR),即正例被判断正确的比率。通常,ROC曲线越接近左上角,分类器的性能越好。
AUC是ROC曲线下的面积,面积越大意味着分类器效果越好。
在实际的数据集中,测试数据中的正负样本的分布很可能随着时间变化,而ROC曲线具有一个特性,即在正负样本的分布变化时ROC曲线仍然能够保持不变。因此,ROC和AUC在众多评价标准中深受研究人员喜爱。
2.6.5 损失函数
损失函数(loss function)是用来估量模型的预测值与真实值的不一致程度,通过使损失函数最小化,使模型达到收敛状态,减少模型预测值的误差。
3 诊断预测结果与分析
3.1 实验结果
3.1.1 随机森林模型分类实验结果
随机森林模型实验同样取全部数据样本的70%作为训练集,30%作为测试集。使用随机森林模型后,轴承故障诊断预测分类结果如图2所示。
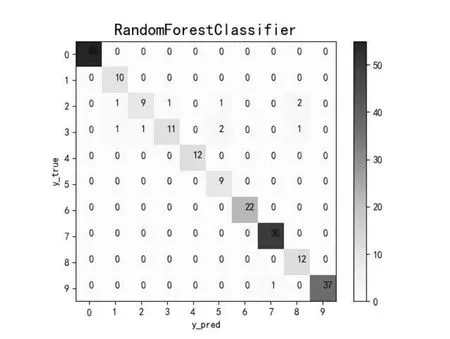
图2 随机森林分类实验结果Fig.2 Random forest classification experiment results
随机森林模型的总体分类准确率为0.95378。由图2中可知,有11个故障样本的故障类型被误判,占全部样本4.6%。在误判的故障类型中,有10个误判样本均来自于故障2(内圈故障)或故障3(滚珠故障)。这是因为外圈故障振动信号周期性冲击特性明显,故障特性明显,而内圈故障和滚珠故障因其结构和工作特性故障特征不太明显,因此容易产生误判。同时,可以观察到,故障2(内圈故障)或故障3(滚珠故障)均属于直径1的轴承,可以理解为故障结果误判与轴承直径也存在一定关系。
3.1.2 LightGBM模型分类实验结果
LightGBM模型实验同样取全部数据样本的70%作为训练集,30%作为测试集。使用LightGBM模型后,轴承故障诊断预测分类结果如图3所示。
LightGBM模型的总体分类准确率为0.95798。由图3中可知,有10个故障样本的故障类型被误判,占全部样本4.2%。在误判的故障类型中,有5个误判样本来自于故障2,占所有误判结果的一半,造成这种误判现象的原因很可能是内圈故障信号波形周期性冲击特性较为不明显,故障表现的较为微弱,容易产生误判。同时,故障2的样本数相比于其他样本较少,也可能因此无法达到理想的训练效果,从而影响实验结果。
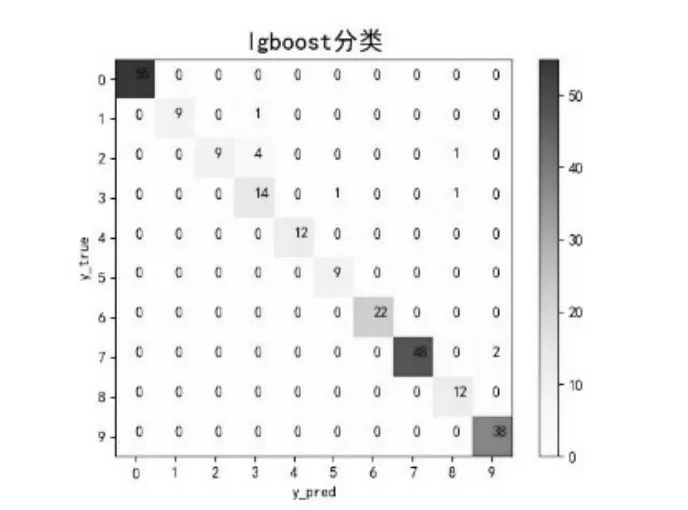
图3 LightGBM分类实验结果Fig.3 LightGBM classification experiment results
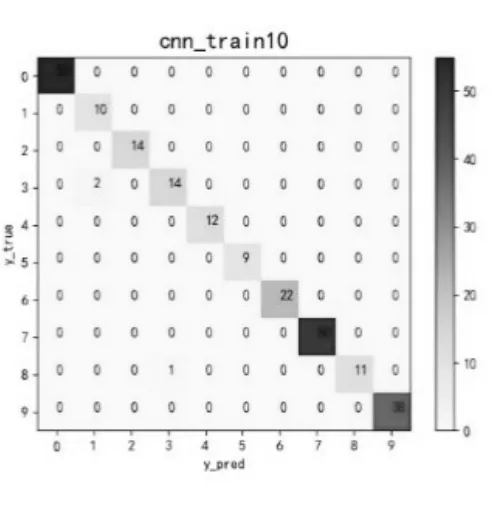
图6 10次训练Fig.6 10 times training
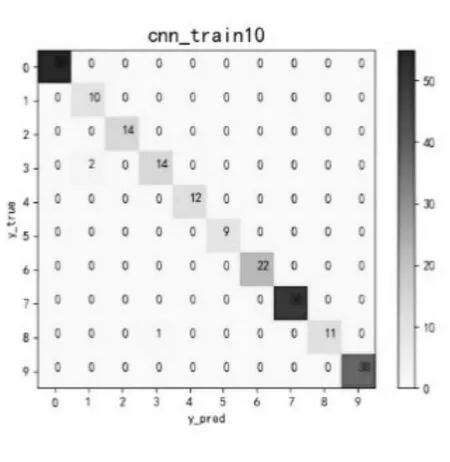
图7 20次训练Fig.7 20 times training
3.1.3 XgBoost模型分类实验结果
XgBoost模型实验同样取全部数据样本的70%作为训练集,30%作为测试集。使用XgBoost模型后,轴承故障诊断预测分类结果如图4所示。
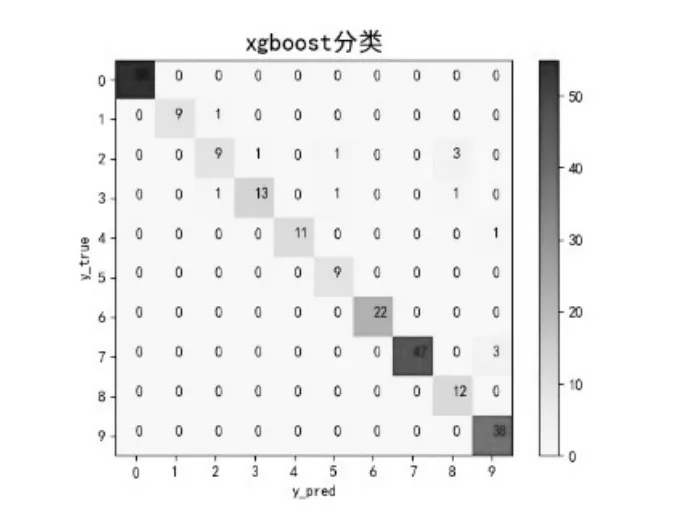
图4 XgBoost分类实验结果Fig.4 XgBoost classification experiment results
XgBoost模型的总体分类准确率为0.94537。由图4可知,有13个故障样本的故障类型被误判,占全部样本5.4%。在误判的故障类型中,有8个误判样本均来自于故障2或故障3,造成这种误判现象的原因很可能与随机森林模型结果误判原因相同。
3.1.4 CNN模型分类实验结果
CNN模型实验同样取全部数据样本的70%作为训练集,30%作为测试集。使用CNN模型进行训练后,轴承故障诊断预测分类结果如图5~图8所示。

图5 5次训练Fig.5 5 times training
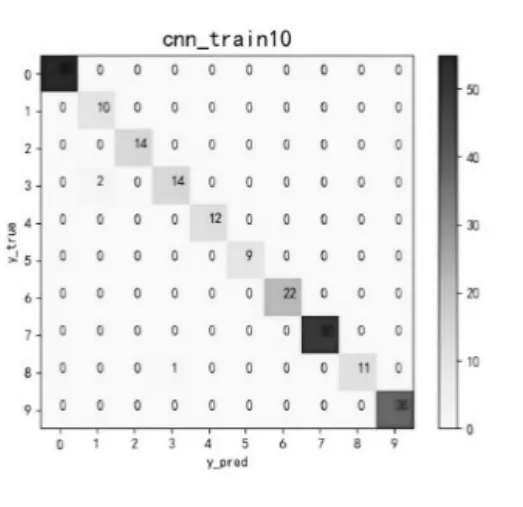
图8 30次训练Fig.8 30 times training
可以看出,经历了5次训练后的CNN模型总体分类准确率较低,仅为0.64285,有29个有故障样本被判为无故障,此外还有大量的有故障样本的故障类型被误判;经历了10次训练后的CNN模型总体分类准确率大幅提升为0.98739;经历了20次训练后的CNN模型仅有1个样本的故障类型被误判;最终,经历30次训练后,CNN模型的训练结果已经达到了1.00000,达到了轴承故障诊断与预测的最佳预期效果。
3.2 评价指标结果
ROC和AUC评价指标结果如图9~图11所示。
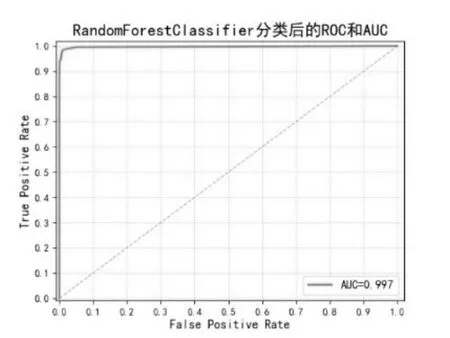
图9 随机森林分类后的ROC曲线和AOCFig.9 ROC curve and AOC after random forest classification
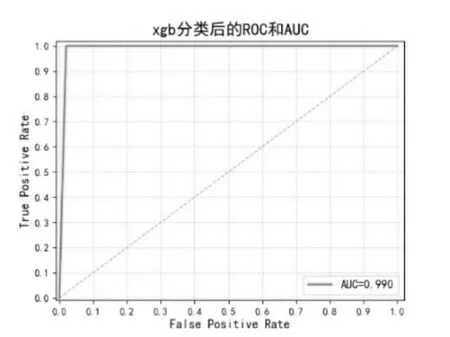
图11 XgBoost分类后的ROC曲线和AOCFig.11 ROC curve and AOC after XgBoost classification
使用CNN模型进行多次训练后,查准率、召回率、F1-score、损失函数评价指标的变化如图12~图15所示。
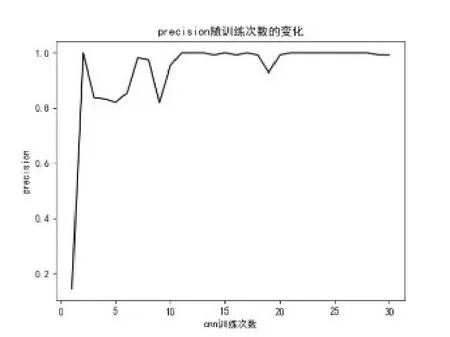
图12 精确率随训练次数变化Fig.12 The accuracy rate varies with the number of training sessions
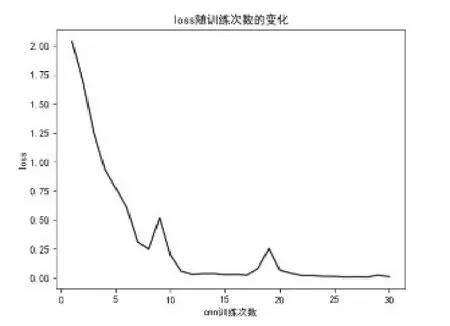
图15 损失函数随训练次数变化Fig.15 The loss function changes with the number of training
由以上图表可以看到,在训练20次时,模型训练结果已经趋近最优;在训练30次时,可以认为达到了最佳的训练效果。
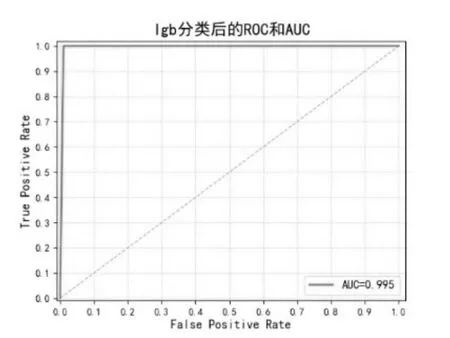
图10 LightGBM分类后的ROC曲线和AOCFig.10 ROC curve and AOC after LightGBM classification
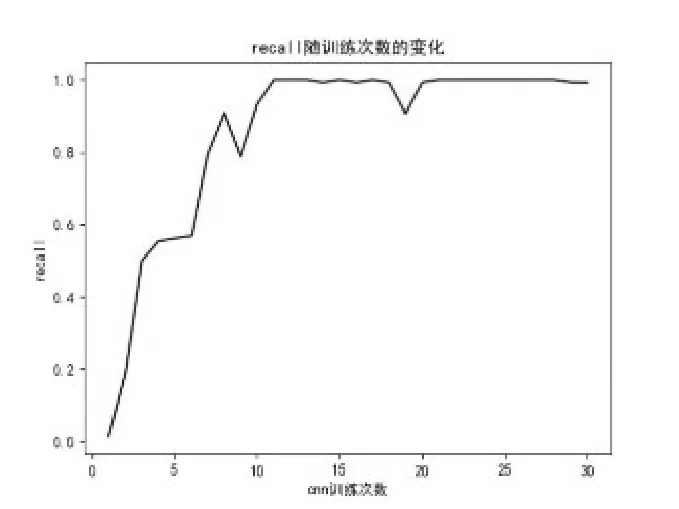
图13 召回率随训练次数变化Fig.13 The recall rate varies with the number of training sessions
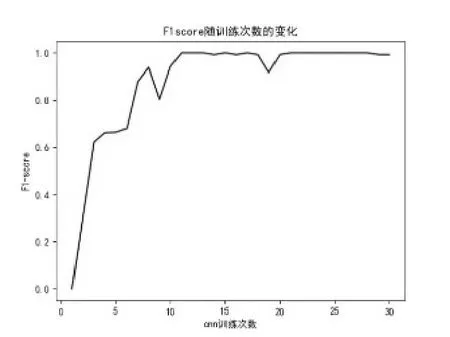
图14 F1-score随训练次数变化Fig.14 F1-score Changes with the number of training
3.3 性能对比与分析
对比随机森林、LightGBM、XgBoost以及CNN模型(训练30次)的评价结果,汇总见表2,绘制柱状图如图16所示。
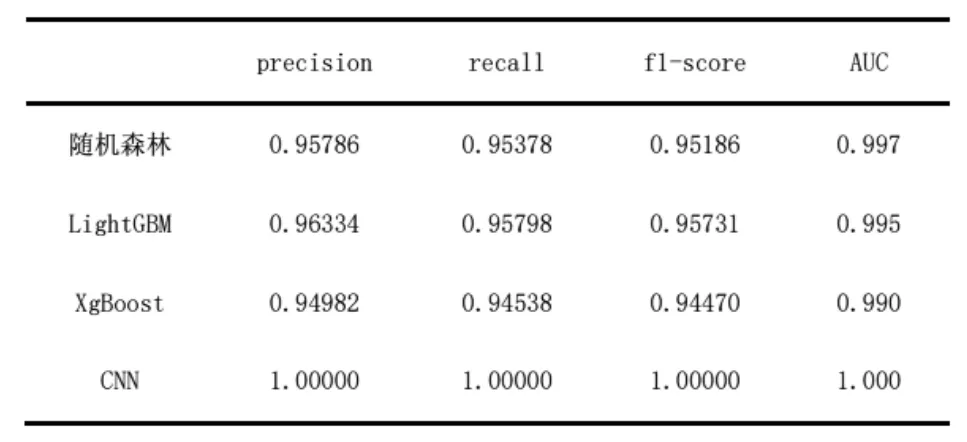
表2 模型评价结果对比Table 2 Comparison of model evaluation results
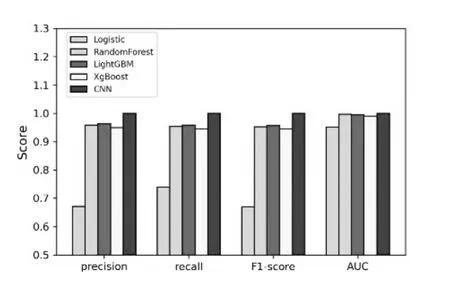
图16 模型评价结果对比Fig.16 Comparison of model evaluation results
从表2和图16中可以看出,在机器学习的4个模型中,对比查准率、召回率和F1分数这3个评价指标,LightGBM模型均获得最高的评价结果,但是随机森林模型取得了最高的AUC分数,为0.997,比LightGBM模型的0.995得分还要高出0.002。AUC代表的是分类或者排序能力,与分类阈值无关,因此查准率高的模型其AUC指标也是可能出现较低值的。在本实验中,CNN模型展现了其非常优秀的分类能力,经过30次迭代训练,其各项指标已经达到最优。
4 总结
本文以滚动轴承为研究对象,对滚动轴承多分类故障诊断技术进行了研究,卷积神经网络分类速度快、精度高,展现出优异的分类能力,可在其基础上进行扩展优化,获得更优的分类结果。
