基于交通路网状态感知的交通信号配时优化技术
2021-11-28胡小光胡晓杰
胡小光 胡晓杰
摘 要:本文提出多通道的3D卷积预测网络结合Double-DQN的配时控制策略,并将其与Deep-Q-learning、Q-learning进行对比分析,进行仿真实验。结果表明,多通道的3D卷积预测网络结合Double-DQN的控制策略明显优于Q-learning和Deep-Q-learning。
关键词:智能交通信号配时;3D卷积;深度强化学习;多通道矩阵;Double-DQN
中图分类号:U491.54文献标识码:A文章编号:1003-5168(2021)16-0018-04
Abstract: In this paper, a multi-channel 3D convolution prediction network combined with Double-DQN timing control strategy was proposed, which was compared with Deep-Q-Learning and Q-Learning. The results show that the control strategy of multi-channel 3D convolution prediction network combined with Double-DQN timing control strategy is obviously better than Q-learning and Deep-Q-learning.
Keywords: traffic signal timing control;3D convolution neural network;deep reinforcement learning;multilevel network;Double-DQN
智能交通信號配时是一种缓解交通拥堵的有效手段。智能交通系统(Intelligent Transportation System,ITS)产生于20世纪60年代末70年代初。由于交通状况是随机的,可变性以及不确定性强,因此,很难训练出适合的模型对交通信号进行控制。强化学习的常见模型是标准的马尔可夫决策过程(Markov Decision Process,MDP)。强化学习是一类重要的机器学习技术,它通过与环境的交互来学习最优的控制决策[1]。交通信号控制领域很早就开始运用强化学习方法来解决交通控制问题。随着深度学习和强化学习的发展,它们被结合为深度强化学习用来估计[Q]值以代替复杂的[Q]值表。DeepMind团队将最新的AlphaGo论文发布在Nature上,使得深度强化学习算法受到多数研究人员的关注[2]。随着交通路网的扩大,道路信息变得复杂,对智能信号控制模型进行优化是探索智能交通的必经之路。
1 控制模型
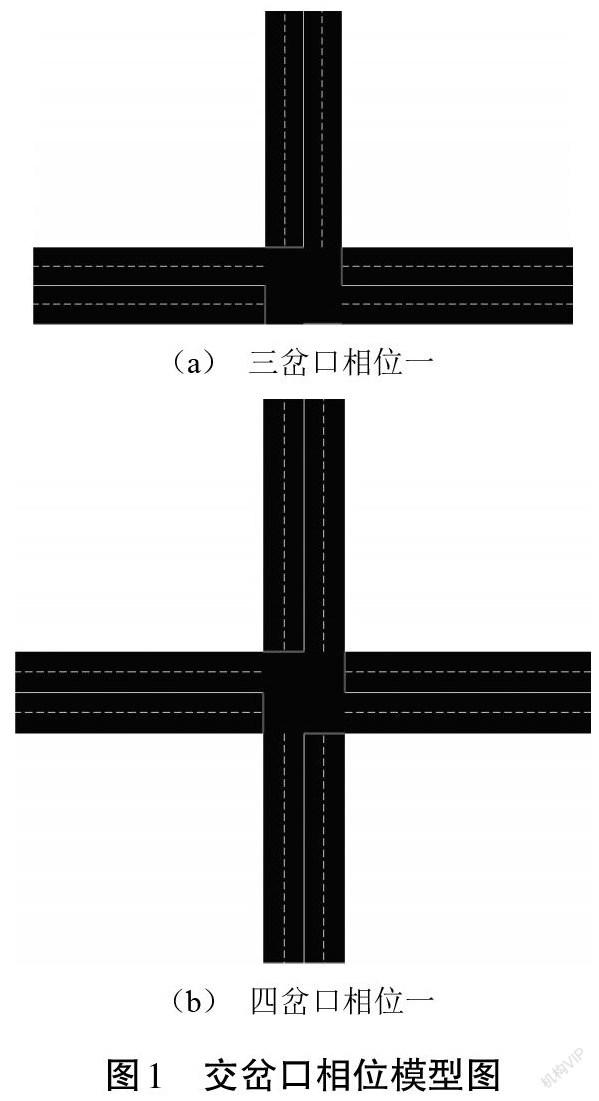
1.1 相位
相位是对交通信号控制的简单描述。一般情况下,相位越大,交通越容易拥堵。相位一代表南北方向允许通行(南北方向绿灯),东西方向等待(东西方向红灯);相位二则与相位一相反。图1是一个三岔口和一个四岔口的相位模型的相位一(三岔口可以右转、四岔口南北方向绿灯)。信号时长[g]是固定的,指相位持续的时间。当前,相位信号时长[g]结束后下一个相位自适应选择合适相位执行下个信号时长[g]。信号时长[g]可以根据不同大小的仿真交通地图更改,从而得到合适的信号时长[g]。
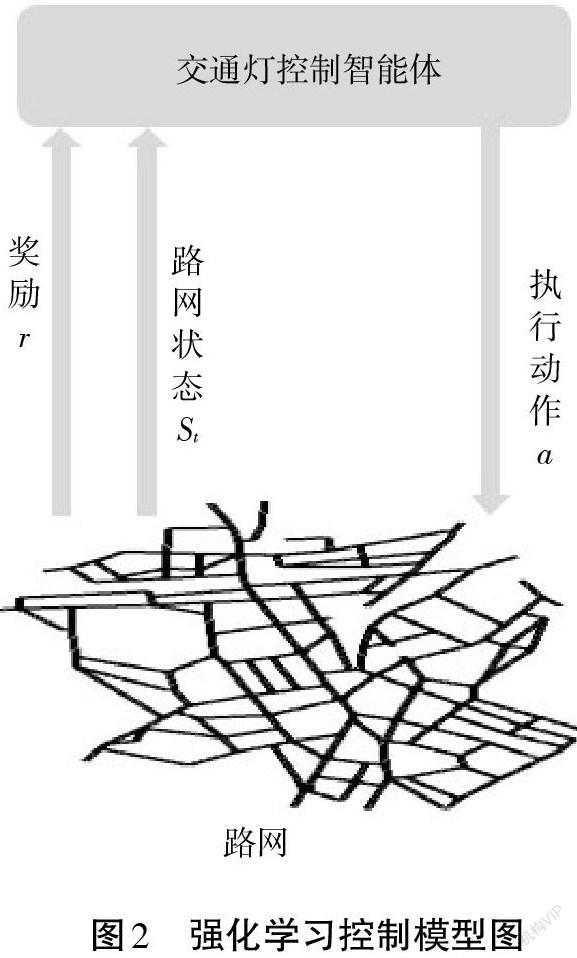
1.2 强化学习控制模型
强化学习控制模型如图2所示。交通灯控制智能体(Agent)通过实时地与环境进行交互,在每个时间步[t],控制智能体(Agent)获取到路网的状态[St]和奖励[r],同时返回给路网一个最优控制命令。
1.3 Double-DQN
在智能交通信号配时中,随着时间的推动,Q-learning中建立复杂的[Q]值表变得尤其烦琐。因此,需要训练一个价值神经网络Vnet来实时计算出预测[Q]值,在训练神经网络时,路网的状态[St]、动作[a]和奖励[r]作为输入。
为解决DQN中[Q]值过高估计的问题,在Double-DQN里,不再是直接在目标Q网络里找各个动作中最大值,而是先在当前Q网络中找出最大[Q]值对应的动作,然后利用这个选择出来的动作amax(S′j,w)在目标网络里面计算目标[Q]值。研究结果表明:Q-learning、DQN两种算法[3]在应用过程中都有可能得到不符合实际情况的高动作值。Double-DQN算法通过下列基本原理解决这一问题:不再是直接在目标Q网络里面找各个动作中最大[Q]值,而是先在当前Q网络中先找出最大[Q]值对应的动作。
2 基于Double-DQN的交通信号控制算法
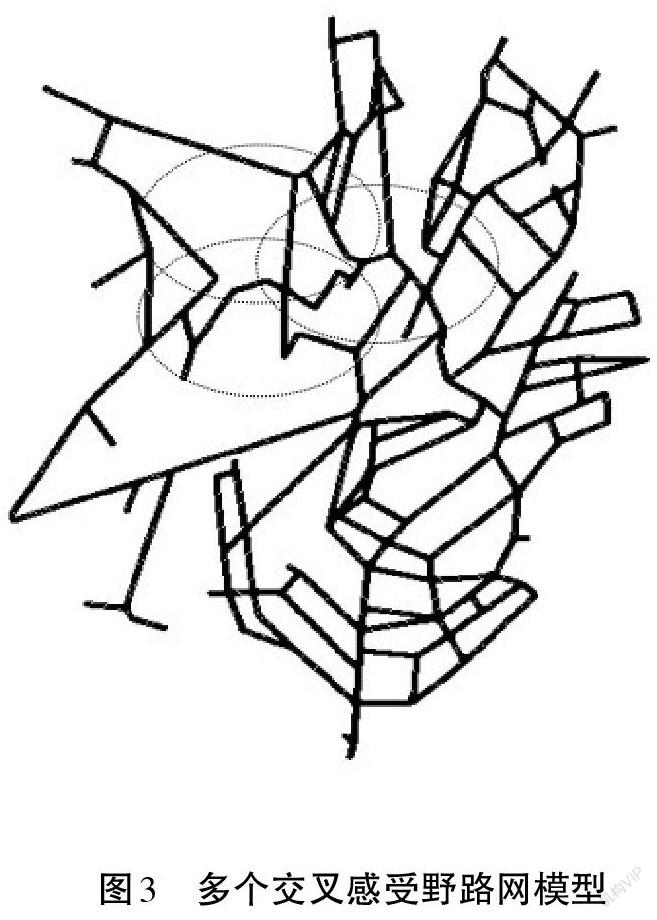
2.1 建立多个交叉感受野的路网模型
卷积神经网络仿造生物的视知觉机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化特征,例如,像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程要求。本研究采用卷积神经网络对路网进行特征提取[4]。
因为神经网络的输入是矩阵,所以研究者把收集到的路网状态信息转变为矩阵的形式,作为预测神经网络的输入,在收集道路信息时按照空间顺序进行移动来收集道路特征。如图3所示,将路网划分成多个相互重叠的区域,不仅保证了不同区域之间的关联性,并且保证了对路网感知的全局性。
2.2 路网状态获取
根据路网道路的车辆密度和车辆平均通过速度来刻画状态[St]。先将整个路网分成若干个相互重叠的区域,按照每个区域对路网进行遍历和规范化,规范化后得到多通道的矩阵[C]。
2.3 车辆密度和车辆平均行驶速度计算
2.3.1 道路车辆密度[d]计算。假定在交通路网中各边道路共计[q]条,各车道长[long],有车辆[m]台,汽车长设定为[vehicle_long],则路网车辆密度[d]计算公式为:
2.3.2 车辆平均行驶速度[ave_v]计算。假定在某一条道路上,道路长度为[long],[tm]时间段内通过此道路的车辆数为[m]台,则在时间段[tm]内车辆的平均行驶速度计算公式为:
2.4 多通道的3D卷积预测网络结合Double-DQN
3D卷积神经网络的输入是通过堆叠多个连续的帧组成一个立方体,然后在立方体中运用3D卷积核。与2D卷积神经网络相比,3D卷积神经网络更适合用于对时空特征的提取方面,这主要是因为3D卷积神经网络模型能更有效地建立时间相关数据模型[5]。本研究在收集路网状态信息时,收集3個连续的时间片段,且每一个时间片段均对路网进行宽度优先遍历,分别收集每条道路中的四个交通状态特征:流出车辆的密度、流入车辆的密度、流入道路车辆通过速度、流出道路车辆通过速度。这样就可以得到12个道路状态矩阵,如图4所示,从而作为预测神经网络的输入,在融合时间特征的基础上收集多个通道的道路状态特征,为神经网络的输入做了重要的数据贡献。
2.5 Inception模型在预测网络中的应用
受Inception V1、V2模型启发,在3D卷积神经网络中引进了Inception V1、V2模型,引入1×1卷积核,以降低卷积运算量,同时增加了网络层数,用多个小的卷积核代替某一个或多个大的卷积核,大大节省了网络训练参数的个数。
2.5.1 Inception V2网络模型。借鉴Inception V2模型,以感受野尺寸25为例,用两个3×3的卷积核代替之前5×5的卷积核,拥有相同的感受野,可以节省网络训练的参数个数。
之前的训练参数:
式中:[C1]是输入矩阵通道数;[C2]是卷积核个数。
改进后训练参数:
式中:[C1]是输入矩阵通道数;[C2]是卷积核个数。
改进后的网络训练参数明显减少,网络深度加深,网络的非线性映射和网络的拟合能力增强。但是,Inception V2模型的缺点也很明显,由于神经网络用两个3×3的卷积核代替之前5×5的卷积核,使得卷积运算量变大,加入Inception V2模型后卷积运算量变大为3.6万。
2.5.2 解决预测神经网络卷积运算量过大问题。为了解决因引入Inception V2模型使得卷积运算量变大这一问题,考虑在预测神经网络中加入1×1卷积核。1×1卷积核有跨通道特征整合、特征通道的升维降维、降低卷积运算量的作用。在本试验中以感受野尺寸25为例,在引入Inception V2模型的基础上每两层神经网络中间加入6个1×1卷积核后使得原来的卷计算量由3.6万降低为2.5万,在加深了网络深度的基础上尽可能地降低卷积运算量。预测神经网络的设计如表1所示,共有8层神经网络(Conv1—Conv8)。
3 仿真试验
3.1 SUMO仿真试验
为了对Deep-Q-learning、Q-learning以及多通道的3D卷积结合Double-DQN配时控制策略性能进行对比,研究者将三种控制策略同时分配在城市交通仿真系统(Simulation of Urban Mobility,SUMO)中,用SUMO系统模拟交通车辆的行驶,并记录需要进行对比的性能指标,从而得出结论。仿真试验的路网设定交叉口总计160个,共有123个交叉口有红绿灯,15个出车点,15个收车点。试验分为2.5 s和5 s两个流量级别,0 s自起点出发,经过特定间隔依序出发去向终点,出车总时长20 000 s。
3.2 仿真试验结果分析
本试验使用两个指标用来衡量Q-learning、Deep-Q-learning以及多通道的3D卷积结合Double-DQN三种不同控制策略的性能。其中,指标一是车辆在10 s内的平均等待时间,指标二是当前时刻全路网中的车辆总数,这两个衡量指标都是越小代表控制策略性能越优秀。图6是在SUMO仿真环境下设置1、2级流量,Q-learning、Deep-Q-learning以及多通道的3D卷积结合Double-DQN三种不同控制策略的两种性能指标结果分析图。
根据试验结果分析图可知,多通道的3D卷积结合Double-DQN的控制策略明显优于Q-learning和Deep-Q-learning这两种控制策略。
参考文献:
[1]SUTTON R S,BATO A G.Reinforcement learning: an introduction[J]. IEEE Transactions on Neural Networks,1998(5):1054.
[2]高思琦.基于深度强化学习的多智能体城市道路交叉口交通流优化控制研究[D].福州:福建工程学院,2019.
[3]MNIH V,KAVUKCUOGLU K, SILVER D,et al. Human-level control through deep reinforcement learning[J]. Nature,2015(7540):529-533.
[4]尹璐.基于深度强化学习的交通灯配时优化技术的研究[D].沈阳:沈阳理工大学,2020.
[5]DU T, BOURDEV L, FERGUS R, et al. Learning Spatiotemporal Features with 3D Convolutional Networks[C]//International Conference on Computer Vision. IEEE Computer Society,2015:4489-4497.
