结合BERT 词嵌入与注意力机制的宋词自动生成
2021-11-28胡智喻杨婉霞杨泰康王巧珍徐明杰
胡智喻,杨婉霞,杨泰康,王巧珍,徐明杰
(甘肃农业大学机电工程学院,甘肃兰州 730070)
0 引言
古诗词作为滋养中华文脉的酣醇“养分”,在中华民族的“根”和“魂”中源远流长,其重要地位更是不言而喻。古诗词中,诗是中国古老而又独具文化特色的文学形式,兴盛于唐代;词是中国数千年历史文化宝库中重要的文学精髓,起源于隋唐时期,宋代达到鼎盛,著名的“唐诗宋词”由此而来。与句式整齐、结构严谨、韵律和谐的唐诗相比,宋词行文风格更加灵活多变,用字用韵也各不相同。
宋词虽已有千年历史,然其对当今文化依然大有裨益。学习、研究、创作诗词不仅能深入了解中华优秀传统文化,还能提高汉字的审美内蕴、提升语言的优雅水平。中国是诗词国度,无论在娱乐和教育领域,亦或是文化和信息方面,诗词都能发挥其独特作用。把古诗词与现代信息技术相结合,将其融入当下最为热门的人工智能,既能引发国内外研究者对中国古诗词的讨论与关注,也能让更多的人领略到中华优秀传统文化的独特魅力。本文选择宋词作为研究对象,不仅在于宋词拥有巨大的开发潜力,还在于宋词与唐诗等生成任务相比更具挑战性:①宋词句式多样,对其结构、用韵、平仄要求更为复杂;②词体更长,在生成时对主题、语义的约束更为困难;③总体数量较少,模型训练的语料不够充分。正因如此,宋词自动生成领域的专业研究可谓凤毛麟角。
随着深度学习的迅猛发展,自动生成领域获得了长足进步,从神经元模型[1]的首次提出,到有记忆功能的循环神经网络(Recurrent Neural Network,RNN)[2]雏形;从解决梯度消失梯度爆炸等问题的长短期记忆网络(Long Short-Term Memory,LSTM)[3]出现,到有更长记忆能力的双向网络(Bi-directional LSTM,BiLSTM)[4]应用;从广泛使用的序列(Sequence-to-Sequence,Seq2Seq)模型[5-6],到加入能增强语义关联性的Attention 机制[7],都为其提供了强大的技术支持。以上深度学习方法的出现,使自动生成的宋词在主题一致性和语义连贯性等方面有了一定提升。
本文在上述研究基础上,创新地提出一种基于BERT(Bidirectional Encoder Representations from Transformers,BERT)词嵌入结合注意力机制的编解码(Encoder-Decod⁃er)模型以自动生成宋词,其特点如下:①利用主题词索引解决仅使用首句索引生成宋词主题偏移问题;②应用最新BERT 词嵌入技术来提升语义表达的多样性;③运用BiL⁃STM 最大程度缓解快速遗忘问题,让模型学习到更长的句子间语义信息;④通过Attention 机制为生成宋词过程提供细粒度监管以及句式结构控制。实验结果表明:该方式生成的宋词在句子相关性和主题一致性方面效果显著。
1 相关工作
文本自动生成是自然语言处理的重要组成部分,而宋词自动生成是文本自动生成的主要形式之一。目前对于宋词自动生成的研究较少,但从诗词生成的角度则该领域已经有数十年的发展历程,相关研究可分为以下几个阶段:
(1)初代研究者主要使用基于规则和模板的方法生成诗词,文献[8]首次建立诗生成体系,但该体系只能根据语法规则随机显示单词;通过构建词汇、句子、韵律等语料库的方式极大丰富了此方法自动生成诗的内容,如文献[9]建立散文到诗的半自动生成系统(ASPERA),通过从大量已定义的结构、诗集、词表模板中预选组合生成诗;文献[10]建立了基于规则的日文俳句诗生成系统(Haiku sys⁃tem),即从6 种不同词库中随机选取关联词生成诗。基于规则和模板方式生成的结果能满足诗词结构形式要求,但生成过程需要定义大量诗体结构、分类诗集、标注词库以实现约束,且生成的诗可读性不足。
20 世纪末,统计机器学习的方法开始应用于诗词生成。文献[11]通过定义宋词句法、语义、平仄的适应度函数、选择策略、交叉因子和变异算子来生成宋词;使用自动文本摘要的方式,文献[12]将诗的生成转换为从所有古诗词语料库中进行摘要的过程。这类方法优化了选词,在保证结构形式要求的同时提高了生成诗词的可读性,但没有兼顾句子之间的主题和语义相关性。而后,研究者探索出统计机器翻译(Statistical Machine Translation,SMT)方法[13],即使用3 个不同的SMT 模型,从主题分类诗库中选择词语生成诗的后三句,效果良好。相比统计机器学习方法,此方法在语义相关性方面有了显著提升,但其首句仍然需要通过模板方式生成。
随着深度学习的再次崛起,该领域迈入了神经网络实现阶段。文献[14-15]首次将优化的RNN 和卷积网络结合生成能满足形式要求的诗,但句子的主题和语义仍有待提升;利用Seq2Seq 模型,文献[16-18]设计了主题规划方式,通过在生成的每个句子中加入相近关键词约束,巧妙解决了主题偏移问题,但其生成的诗语义多样性不足;结合At⁃tention 机制,有研究者利用Seq2Seq 模型生成了较好的集句诗[19-21];文献[22-25]对已有诗生成模型进行改进,提升了生成质量,但模型针对性强,移植能力较差;文献[26]首次采用GPT 预训练语言模型,提升了诗的生成效果,验证了预训练语言模型应用于自动生成的可行性。综上所述,基于神经网络的诗词生成方法已成为主流,该方式在生成诗词的形式多样性、主题一致性和语义相关性方面均有明显改善,但从实际效果来看在语义相关性等方面仍有待提升。
本文在前人探索的基础上,采用主流且效果更好的深度学习方式,进行了如下重要改进:①将主题索引方法运用于宋词生成,解决生成更长句式的主题偏移问题;②将最新的BERT 词嵌入技术用于宋词生成,以提升词句的语义多样性和上下句子间的相关性;③使用BiLSTM+Atten⁃tion 机制为生成宋词过程提供细粒度监管并对句式结构进行控制,以保证生成宋词声调的和谐性。
2 词生成方法
本文使用主题约束+BERT 词嵌入+BiLSTM+Attention方法生成宋词。首先从创作思想出发,使用用户喜欢的句子或词语作为输入,并根据用户输入的信息提取或扩展相应主题词;然后通过BERT 词嵌入,将主题词及已有句子转换为具有动态语义的词向量表示;最后利用主题词约束方式生成宋词的第一句,使用主题词+已生成句子共同生成词的下一句。其中句子的生成模型引入BiLSTM 和Atten⁃tion 机制提升宋词的格式、韵律和语义效果。生成流程如图1 所示。
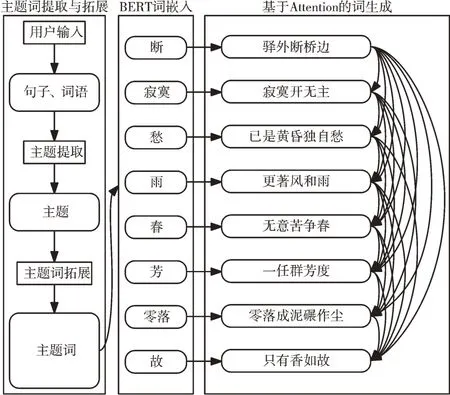
Fig.1 Generating process of Song Ci图1 词生成过程
2.1 主题词提取与拓展
2.1.1 主题词提取
古人作词讲究“意境”二字,即意象和境界,在后来的宋词鉴赏中又被称之为“主题”。意象是作者将内在思想通过外在的事物表达,境界则能将词表达的思想上升为读者的普遍感情。近代在宋词的鉴赏中,读者渐渐引用“主题”一词来概括意境。在词的创作过程中,主题和意境一样,是作词人在记事表意、言情述志、发表主张或反应生活现象时,通过作品内容所表达出来的基本观点和中心思想,是词的“灵魂”和“统帅”,一首词只能有一个主题。为了将作者的创作意图在宋词中准确展现,本文从作者的输入信息中提取最符合中心思想的一个主题词,将其用于统领整首宋词的生成。
主题词提取分为以下两个步骤:①将作者输入的诗词、句子、短语等进行分词处理;②对分词后的词语进行重要性排序,以得到最符合中心思想的词。本文分词处理采用基于统计的隐马尔可夫模型(Hidden Markov Model,HMM),其原理是:对于需分词的句子,通过查询词典生成所有可能的切分,并采用动态规划查得最大概率进而获得基于统计词频的切分,而后使用HMM 模型和维特比(Viter⁃bi)算法,对标记词(BEMS 状态序列)切分。该方法相比单纯基于词典的各种分词方法,其分词结果更为高效精确。对于词语重要性排序(即主题词的查找),本文采用基于无监督的TextRank 算法筛选出候选词,主要思想是构建词图和词间的共现信息(Co-occurrence),根据词间的共现信息设置权重,并使用公式(1)迭代各节点的权重直至收敛,最后对节点权重进行排序,从而得到主题词。
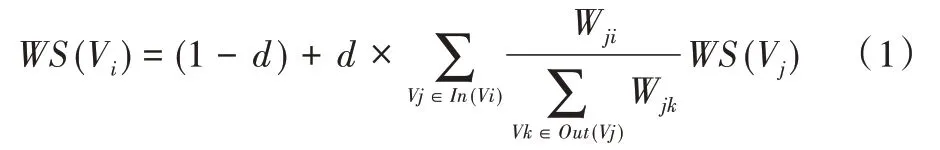
其中,WS(Vi)表示句子i的权重,求和表示每个相邻句子的贡献程度,Wji表示两个句子的相似度,Wjk表示上次迭代句子j的权重,d是阻尼系数。该公式中增加了权重项Wji用来获取两词间的重要程度。相比基于有监督的方法,它不需要大量的标注词库,使用效果更准确、快速。
2.1.2 主题词拓展
由于深度学习方法自动生成宋词采用以字符为单位的预测方式,加之宋词属于长句式(一般为八句及以上),仅由单个主题控制生成后续所有词句的方法会使远离主题的句子更偏离主题,加剧生成词的主题发散问题。为了使生成宋词的每一句遵循相同主题,本文引入主题词约束方法,以上一步提取的主题词为基准,拓展与之相似的主题词,用于控制后续每个句子的生成。
主题词拓展思路为:首先训练一个全宋词语料向量表征模型,用以准确计算词之间的相似度关系,然后依据词的相似度,拓展与中心思想相近的主题词。训练向量表征模型原理是:利用给定词,预测其前后出现的N 个词,训练并建立向量表征模型,代价函数如下:
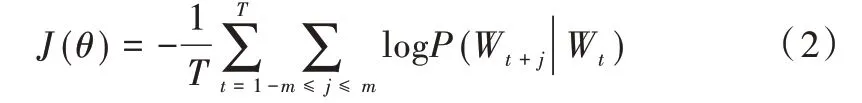
其中,J(θ) 为最小化的代价函数,Wt表示t时刻主题,θ是待优化变量。
使用余弦相似度(Cosine)公式(3)计算两个词向量间夹角的余弦值衡量其相似性,最后得到需要拓展的N 个主题词,为后续生成句子打下基础。
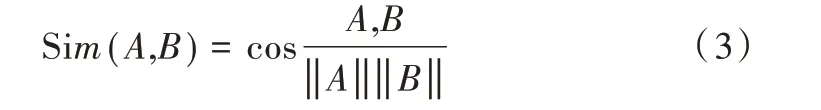
2.2 BERT 词嵌入
在自然语言处理(NLP)相关任务中,原始语料是一系列符号的集合,无法使用计算机处理,因此需要将集合的粗粒度符号映射到新的多维空间,并用向量形式表征其中的字或词,即词嵌入(Word Embedding)。词嵌入方法包括人工神经网络、矩阵降维、概率模型以及上下文的显式表示等,他们遵从一个基本原理,都是将相似的词表征为相似的向量形式。这些传统的向量表征方式虽然简单高效,但表达单一固定,对于同字不同意的词不能完全区分,即存在无法表征字或词的多义性。最新的BERT 词嵌入预训练语言模型通过添加字的上下文位置信息,很好解决了难以表达一词多义的语义关系问题。因此,本文采用BERT预训练作为生成词模型的语义向量转换输入部分,其结构由输入、编码、输出3 个部分组成。
(1)输入部分。结构如图2 所示。通过使用分词器(Tokenizer)与宋词词表(Vocabulary)查询,得到对应输入序列(Input ids)的一维字嵌入(Token Embeddings),并根据每个id 在句子中的不同位置对应加入一维的段嵌入(Seg⁃ment Embeddings)和位置嵌入(Position Embeddings)。
BERT 输入部分生成过程如下:


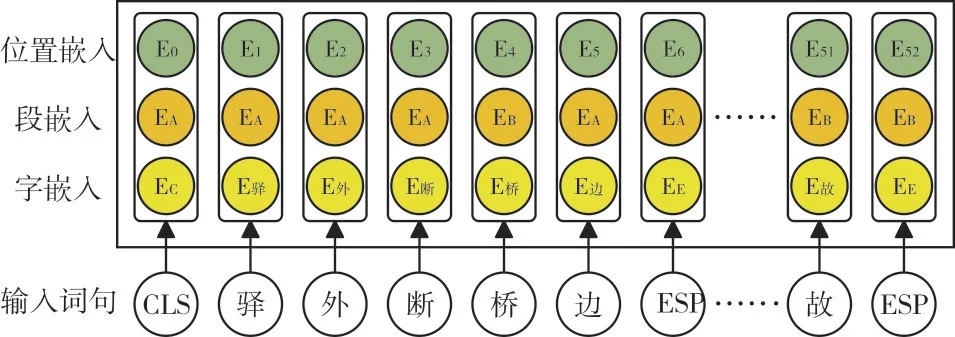
Fig.2 BERT input part图2 BERT 输入部分
(2)编码部分。使用深度双向Transformer 对宋词进行特征抽取,如图3 所示,其原理是由h 个自注意力机制(Self-Attention)堆叠的多头注意力机制(Multi-Head Atten⁃tion),将输入的上下文信息转化为相应的向量表示,然后整合成为前馈神经网络(Feed Forward)输入。
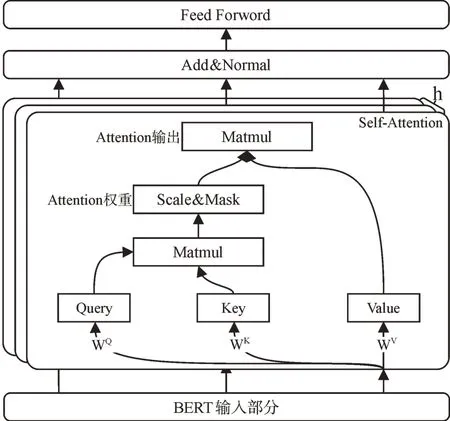
Fig.3 BERT encoder part图3 BERT 编码部分
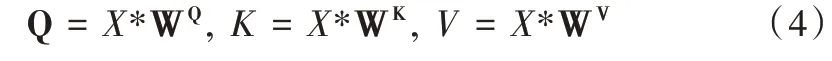
结合缩放点积(Scaled Dot-Product)算法进行多维深层特征抽取,原理是:将转换后的空间向量Q 和K 相乘,得到输入的相似度信息,利用缩放因子dk将其控制在合理范围内,最后经过softmax() 函数归一化,得到概率分布,从而获取嵌入信息的全部权重矩阵表示,其计算公式如下:
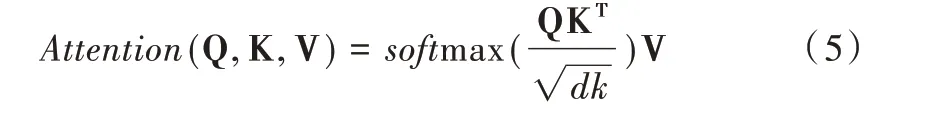
(3)输出部分。结合整个Multi-Head Attention 的每个Attention 权重信息,使最终输出的Word Embedding 融入全文语义信息。该方式不仅使生成的词嵌入获取更多的上下文语义信息,还能极大程度地增强语言模型的特征抽取能力,使之尽可能准确地表示出词的原义,以用于后续的宋词生成阶段。
2.3 基于Attention 的词生成
根据宋词的结构灵活性、词义多样性等特点,本文构建了基于Attention 机制的Seq2Seq 模型用于宋词生成。该模型生成的文本在语义性、连贯性、可读性等方面普遍优于其它模型。因此,将Seq2Seq 模型应用于生成词以得到更好的效果。
2.3.1 ncoder-Decoder
Seq2Seq 模型主要由编码器(Encoder)和解码器(De⁃coder)两部分组成,本文结合宋词的结构、语义和词意等特点,在Seq2Seq 基础上融合Attention 机制构建了宋词生成模型,具体结构如图4 所示。其中,词嵌入采用BERT 预训练模型,以获得词的动态信息以及句子级别的语义信息。Encoder 部分采用BiLSTM 模型对来自BERT 词嵌入的输出向量进行双向编码,以使模型获取并保存更多的上下文信息。在生成目标序列的Decoder 部分使用LSTM 网络将En⁃coder 部分的编码结果解码为对应的宋词信息。
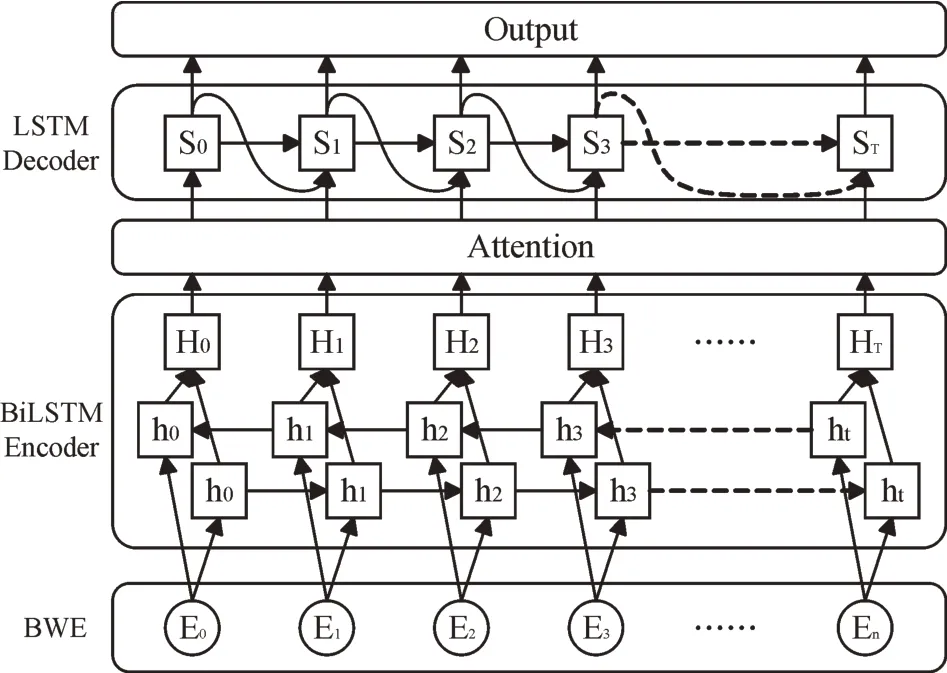
Fig.4 Encoder and decoder framework图4 编码—解码器框架
2.3.2 Attention-based Seq2Seq Model
原始Seq2Seq 模型会将编码的输入序列压缩为一个固定维度的语义向量C,由于C 的容量有限,很难保存全部的输入序列信息,在用于长序列时易造成上下文信息丢失。为此,本文引入Attention 机制解决这一问题。对Encoder 每一时刻的输入序列,通过Attention 机制从中选取与输出更匹配的信息递送Decoder,在保证输入序列完整的同时获取相关性更强的上下文信息。具体步骤如下:
(1)Attention 机制将解码器隐藏层状态(Decoder hid⁃den state)与编码器隐藏层状态(Encoder hidden state)state进行对比,根据两者的相关性程度计算出一个值(score),然后采用softmax() 对得出的score 进行归一化,获得基于Decoder hidden state 的条件概率分布,即注意力权重(Atten⁃tion weights,Aw),公式如下:
建议:①外科医生可根据术中情况选择是否留置盆腔引流管,②可以不常规留置盆腔引流管,以利于减少疼痛及利于术后早期下床活动。
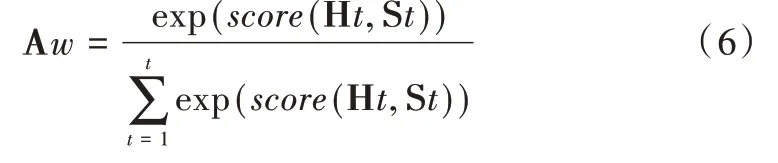
(2)利用Aw对所有的Encoder hidden state 进行加权求和,得到上下文信息(Context vector,Cv),输出给Decoder 进行解码,公式如下:
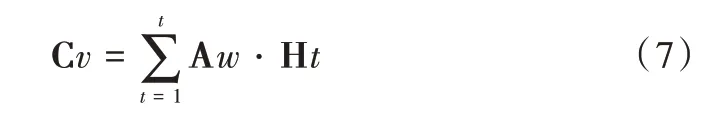
(3)将Context vector 与Decoder hidden state 融合作为注意力信息(Attention vector,Av),输出给Decoder 进行解码,公式如下:
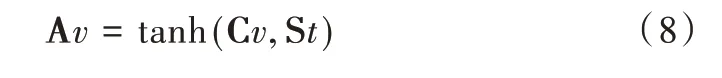
3 实验结果与分析
3.1 实验环境
本实验的训练和预测都是在带有GPU 的服务器上进行,系统配置为Ubuntu,程序编写语言为Python 并结合了Tensorflow 深度学习框架,具体配置如表1 所示。

Table 1 Experimental environment表1 实验环境
3.2 语料收集
实验采用的数据集是从互联网上收集而来的宋词集合,共包含约两万首词作,与唐圭璋所编《全宋词》相当,该数据集涵盖了大部分的宋词语料。以此数据集按8∶2 比例随机抽取得到训练集、测试集,如表2 所示。

Table 2 Data set表2 数据集
3.3 评价指标
采用困惑度(Perplexity)和交叉熵损失函数(Cross-En⁃tropy Loss Function)对训练模型进行客观评测,前者用来衡量模型分布与样本经验分布之间的契合程度,即模型预测语言样本能力,后者用来量化模型预测和真实结果之间的差异。对于使用相同语料训练的BERT 和Word2vec 词嵌入模型,根据上述评价标准择优用于后续词生成,并采用BLEU、余弦相似度和BERT-Score 对其评测。
双语评估工具(Bilingual Evaluation Understudy,BLEU)是基于N-gram 重叠的评估准则,以词汇级别计算自动生成文本和人工参考文本之间的相似度。此方法简单,计算量小,与人工对主题的测评有一定的相关度。
BERT-Score 是基于语言模型的评估准则,与只对词汇变化敏感的BLEU 相比,它不仅能识别句子间的语义变化,而且更接近人工评估,评价指标的鲁棒性也更好。具体过程为:首先对生成句和参考句分别使用BERT 提取特征;然后使用归一化向量计算内积,得到其相似度矩阵。基于该矩阵得出3 个评测结果,分别为精确率(Precision,P)、召回率(Recall,R)以及综合Precision 和Recall 的F1 度量(F1 measure,F)。
3.4 实验过程
本文采用预处理的宋词语料对BERT 预训练模型进行Fune-tuning,获取富有宋词结构及语义的词嵌入向量。将BERT 词嵌入和Word2vec 词嵌入分别用于后续宋词生成模型,并使用生成模型在不同输入数据类型、超参数设置、优化算法等方面进行大量对比验证,以得到最优的宋词生成模型,并用BERT-Score 等不同测评方式验证模型生成宋词的质量,为后续选择宋词生成模型提供理论依据。
3.4.1 语料预处理
首先对收集的数据集进行词体抽取,得到只包含宋词的词句,对其去除停用词并按照字频排序,选择前8 000 个用于生成宋词字典;其次对语料库中的宋词按字频、格式、结构进行筛选并拆分成句;最后使用主题词提取方法选出每个句子对应的主题词,形成主题词+句子的训练语料,结果如表3 所示。

Table 3 Training set data表3 训练集数据
3.4.2 BERT 词嵌入训练
BERT 词嵌入训练是利用无监督的宋词语料,利用BERT 预训练的掩蔽语言(Masked LM)和下句预测(Next Sentence Prediction)两个任务进行Fune-tuning,调整其参数和语料,使模型生成的Embedding 具有面向宋词语义结构的表示,让生成的词向量空间丰富多样,以解决宋词语料不够充分的问题,如表4 所示。
为验证输入数据对模型训练结果的影响,本文设计两种不同的方式处理输入BERT 模型语料,分别为对齐训练数据(Align data)和非对齐训练数据(UnAlign data)。其中对齐训练数据是在语料预处理过程中引入最大句子长度(Max sequence length),用于与输入训练数据对比,并对其按照Max sequence length 进行补齐或截取。该处理方法的目的是使模型更好地记忆和学习到宋词的结构特点,而非对齐训练数据就没有如此进行处理。
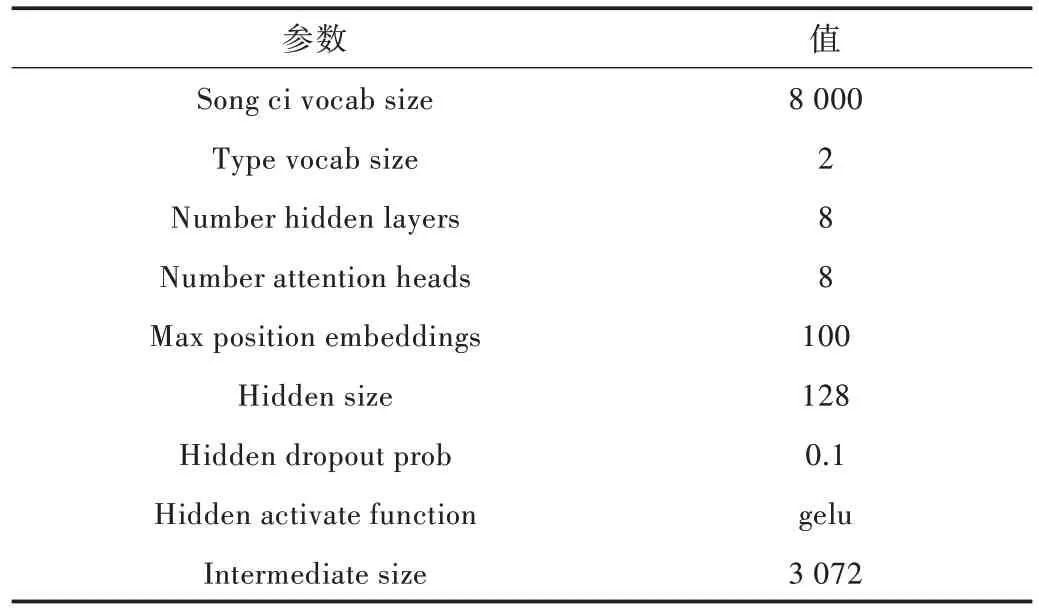
Table 4 Main parameters of BERT training表4 BERT 训练主要参数
为了验证BERT 词嵌入向量作为词生成模型输入层的优越性,在语料相同的情况下,本文还训练了基于Word2vec 词嵌入的词生成模型用以与之对比。Word2vec词向量是目前文本生成领域应用最多的预训练模型,但它的单项学习方式和静态的向量表达使生成的文本语义不够丰富和灵活。最后通过训练模型的Loss 和生成词的测评对最终的对比结果进行展示。
3.4.3 宋词生成模型训练
宋词生成模型简单来说就是输入主题空间和输出词句空间的真实映射函数,模型的训练就是使用语料的输入空间预测输出空间,通过学习准则和优化算法使映射函数能够表达出最优效果。本文使用“回顾”的方式处理训练模型的输入数据,使模型能够学习和表征上下文的语义关系,如表5 所示。同时,为了使训练模型的结构经验风险最小,Embedding size 等参数的合理设置非常关键,本实验模型重要参数设置如表6 所示。

Table 5 Training data表5 训练数据

Table 6 Parameter of Song Ci generation model表6 宋词生成模型参数
为验证不同模型参数对实验结果的影响,本文首先根据经验设置4 组相差较大的参数训练模型,分别为Model1、Model2、Model3、Model4,如表7 所示,并对模型训练结果进行比较验证。
然后选出上述训练结果的最优模型,对其中参数再进行细化,即固定其中两个参数,只改变一个,分别训练得到优化结果。例如:Mn-1(n 表示上述4 组Model 中的一个)的4 个模型分别使用不同的Batch size,Mn-2 分别使用不同的Learning rate,Mn-3 使用不同的Dropout rate。通过将多个不同参数下的模型训练结果进行对比,可以较全面、准确地得到最优模型用于最终的宋词生成。
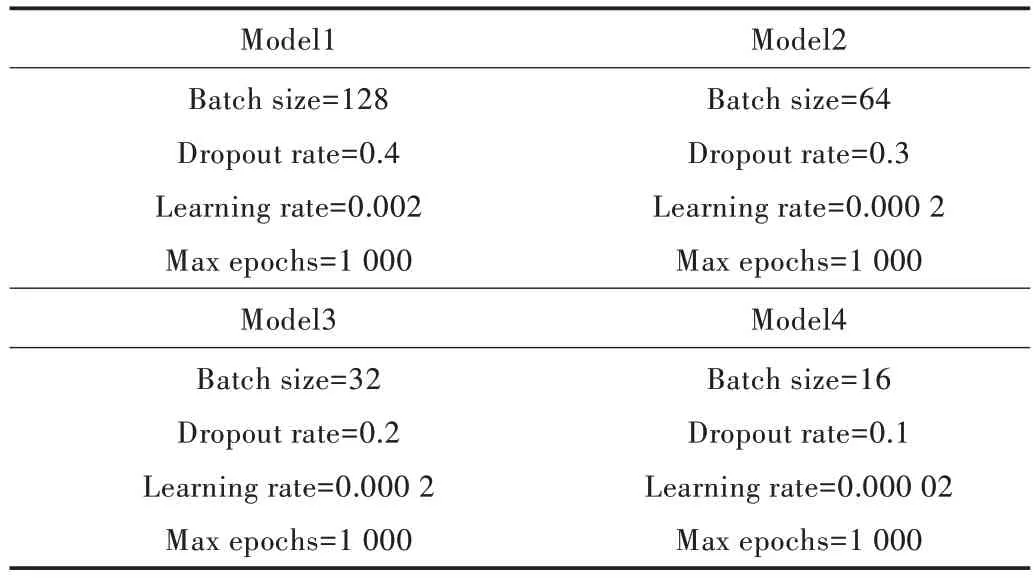
Table 7 Parameters set by empirical method表7 经验方法设置的参数
为了验证不同优化器对实验结果的影响,本文还训练对比了多种不同优化器,分别为自适动量估计(Adaptive Moment Estimation,AdaM)、AdaDelta、RMSProp、梯度下降(GradientDescent)等。
3.4.4 宋词生成模型预测
模型预测是用训练好的模型生成一个完整的序列样本。宋词生成模型预测是将测试集数据输入训练好的模型,以生成完整的宋词序列。生成模型解码过程是从左到右的搜索(Search)过程,对于宋词生成而言,即为每个字符的选取过程。为了验证搜索算法对生成宋词质量的影响,本文模型设计两种不同的搜索方式,即贪婪搜索(Greedy Search,GS)和束搜索(Beam Search,BS)。GS 是在每个字符生成时选择概率最大的作为输出值;BS 则是一种启发式的搜索方式,其在每一步的生成中都会选择多个最可能的字符,依次组合为输出序列,用于后续选择。
3.5 实验分析
3.5.1 词嵌入模型的Loss 优化对比
本文在词Embedding 层训练中对比不同的输入数据(Align data 和 UnAlign data)和不同模型(BERT 和Word2vec)的Loss 值随Epoch 变化情况,如图5 所示。实验结果表明:BERT 和Word2vec 模型都能在600 个Epoch 左右达到最优。达到最优时,输入数据为Align data 的BERT 模型Loss 值最低,其值稳定在约0.68;其次是Align data 的Word2vec 模型,其值稳定在约0.87;UnAlign data 的BERT模型效果不佳,其值达到3.22。
3.5.2 模型的困惑度(Perplexity)对比
在训练宋词生成模型时,为得到最优模型,本文对比分析了同为BERT 作为模型输入的16 组参数训练模型的Perplexity 值随Epoch 的变化情况,结果如图6 所示。其中图6(a)为Model1-4 四组参数训练结果,图6(b)、(c)、(d)为如表8 参数所示训练结果。图6(a)显示,Model2 经验参数训练模型收敛最快且值最优;图6(b)、(c)、(d)分别对比了Model2 经验参数下不同Batch size、Learning rate 和Dropout rate 对模型的影响,数据显示:Learning rate 值对模型的训练影响最大,Batch size 次之,但其与训练所需时间成反比,Dropout rate 最低。
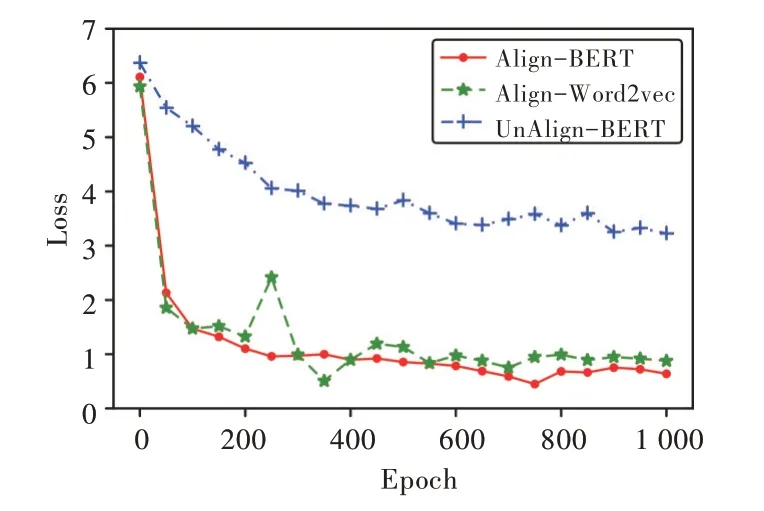
Fig.5 Loss rate图5 损失率
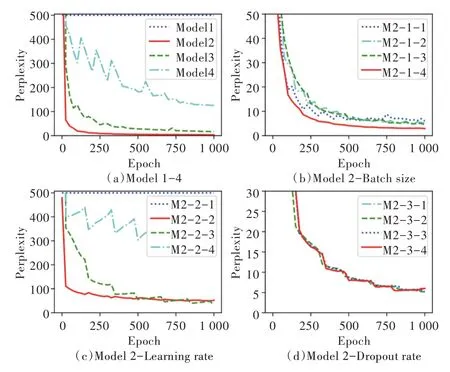
Fig.6 Training results of different parameters图6 不同参数训练结果
选择优化器过程如下:从上一步实验中选取综合最优模型Model2,固定其中所有参数,再通过AdaM、AdaDelta、RMSProp、GradientDescent(GD)四种不同优化器分别进行训练,结果如图7 所示。
实验数据显示,模型训练参数为Batch size=64,Drop⁃out rate=0.3,Learning rate=0.000 2,Max Epochs=1 000,Opti⁃mizer=Adam 时,Perplexity 值收敛最快,且最优时值为2.78,明显优于其他参数训练下的模型,这表明使用上述模型参数训练的宋词生成模型预测语言的能力最强,最适合用于后续的宋词生成。

Table 8 Different parameter settings表8 不同参数设置
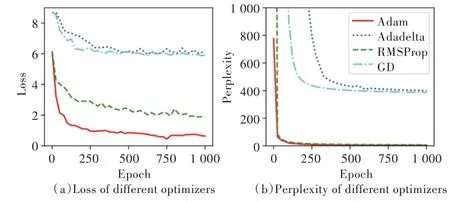
Fig.7 Different optimizer training results图7 不同优化器训练结果
3.5.3 生成宋词测评
本文选择3 种方法从不同侧面对模型生成宋词的质量测评实验进行评估,指标分别为BLEU、余弦相似度(Cosine Similarity)值和BERT-Score,见图8。首先选择思乡(SX)、边塞(BX)、抒情(SQ)、叙事(XS)和山水(SS)5 类主题生成词,采用人工从这5 类不同主题的宋词中选取主题词,获取25 组不同的主题词用于已训练好的模型输入来生成宋词。分别选取5 组不同主题用于模型输入使用。然后选择每组主题生成的10 首共计250 首宋词用BLEU 和余弦相似度(Cosine Similarity)值对比,对比模型有:BERT 词嵌入+Mod⁃el2 模型训练参数+贪婪搜索方式(B-M2-GS)生成宋词模型、BERT 词嵌入+Model2 模型训练参数+束搜索方式(BM2-BS)生成宋词模型,Word2vec 词嵌入+Model2 模型训练参数+贪婪搜索方式(W-M2-GS)生成宋词模型,Word2vec词嵌入+Model2 模型训练参数+束搜索方式(W-M2-BS)生成宋词模型,测评结果如表9、表10 所示。
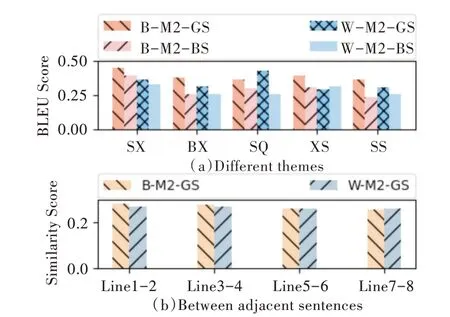
Fig.8 BLEU and similarity evaluation results图8 BLEU 和相似度测评结果
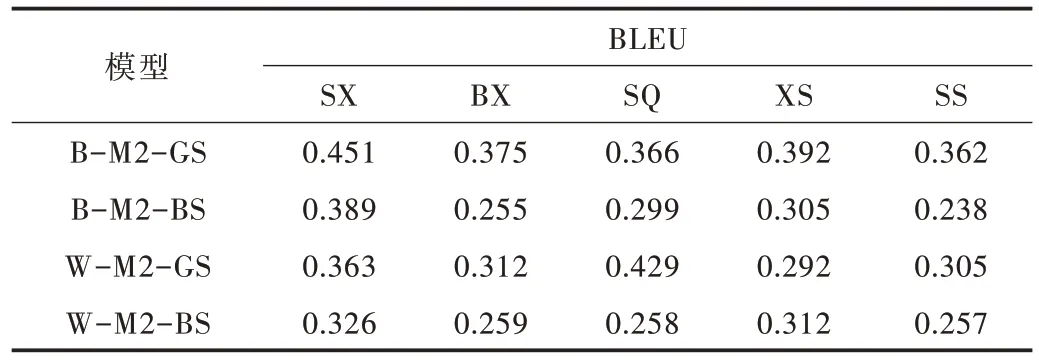
Table 9 BLEU score表9 BLEU 值
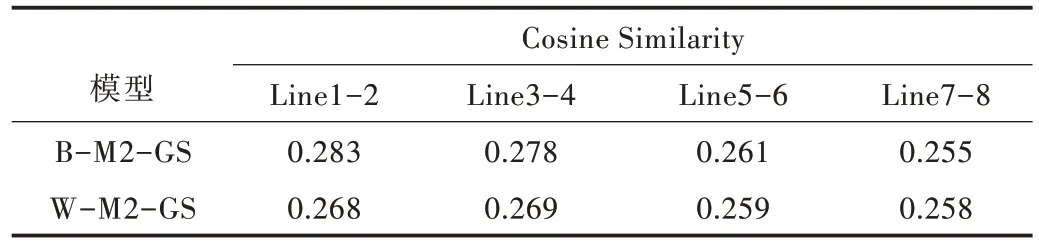
Table 10 Cosine similarity score表10 余弦相似度值
另外,为了进一步体现BERT 词嵌入模型对句子级语义的深层表示,对上述不同模型生成的5 组不同主题宋词分别与原词进行BERT-Score 测评对比,其结果如表11 所示。
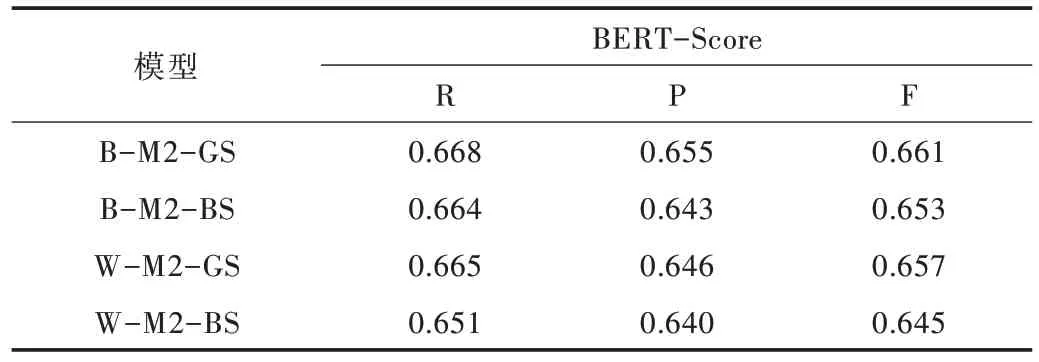
Tab.11 BERT-score values of different models表11 不同模型BERT-Score 值
以上测评结果显示,使用BERT 词嵌入+Model2 模型训练参数+贪婪搜索方式(B-M2-GS)模型生成的宋词在BLEU、Similarity、BERT-Score 测评中都优于其他3 种模型的生成效果,其中BLEU Score 平均值为0.389,Similarity Score 平均值为0.275,BERT-Score 见表11。下面展示以相同主题词,如山河、荒凉、西风、幽怨、金戈、黄昏、秋雨,使用不同模型(B-M2-GS,W-M2-GS)生成的词。
(1)B-M2-GS。
凉生平秋雨,山河依旧,西风落日江城雨,黄昏院落梅花色。金井金戈,点指荒凉落色,几面微风,幽怨何妨。
(2)W-M2-GS。
不知秋雨,如此山河,冷乱残云,只恐黄昏。耳涌金戈,不知幽怨,几度西风,已自荒凉一度。
本文使用不同输入数据类型(Align data 和UnAlign da⁃ta),多组不同模型参数(Batch size、Learning rate 和Dropout rate)以及多种优化器(AdaM、AdaDelta、RMSProp、Gradient⁃Descent)训练得到两个最优宋词生成模型,并通过两种不同的预测方式(Greedy Search 和Beam Search)对生成效果进行不同角度(BLEU、Similarity、BERT-Score)评测,实验结果表明:在生成模型都较优的情况下,对比BLEU 和BERTScore 测评数据综合分析可以发现,使用BERT Attention-Seq2Seq-Greedy 模型生成的宋词在主题一致性方面更有优势,而Similarity 和BERT-Score 的测评数据则说明其句子间的相关性优于Word2vec 模型。
4 结语
本文以深度学习为导向,构建了BERT Attention-Seq2Seq 的宋词生成模型。
为解决自动生成宋词中的句子间语义的差异性问题,本文引入BERT 词嵌入的预训练语言模型,以提升词句的语义多样性和上下句子间的相关性。为解决自动生成词的主题偏移问题,设计了主题词引导的Attention 机制生成词句模型。为了体现本文设计模型生成宋词的优势,设置了两种输入数据类型、多组模型参数、4 个优化器分别训练并得出最优模型,并与Word2vec 词嵌入的词生成模型进行对比。实验结果显示:本文构建的BERT-Attention-Seq2Seq 宋词生成模型较Word2vec-Attention-Seq2Seq 模型,生成词的上下句一致性和相关性都均有显著提升。两者生成词的测评结果表明:前者的BLEU 较后者提高9%,BERT-Score 和余弦相关度较后者提高2%,充分说明BERT词嵌入预训练语言模型比Word2vec 词嵌入更能深层次表征语句特征,将其运用于宋词生成,可以提升生成词的主题一致性和句子间的相关性。但自动生成宋词仍有不足之处,如深度学习方法生成的宋词仍存在词意性不明确等问题。下一步的研究方向是设计算法对宋词生成过程加以控制,使其在不同词牌名下都能生成具有固定格律效果、更好语义相关的宋词。
