基于双注意力模型和迁移学习的Apex 帧微表情识别
2021-11-27徐玮郑豪杨种学
徐玮,郑豪,杨种学
(1.广西师范大学 计算机科学与工程学院/软件学院,广西 桂林 541004;2.南京晓庄学院 信息工程学院,江苏南京 211171)
微表情是人们试图隐藏真实情感时不由自主泄露出的面部表情,是人类经过长期进化遗传而继承下来的。其作为人内在情绪的真实表现,能够揭示一个人的真实情绪,具有持续时间短、强度低、难以诱导[1]等特征,因此它成为精神心理学和情感分析领域最可靠的生理特征之一。
微表情识别算法主要有特征描述算法、特征转换算法、光流算法、频域算法、深度学习算法等。特征描述算法[2-4]通过描述微表情的面部肌肉运动特性、纹理特性等实现对微表情的特征表示,在局部二值模式的基础上,减少噪声、光照等因素的影响,提升特征描述的准确性。特征转换算法[5-6]将微表情序列看作张量,对其进行矩阵变换去除冗余信息,增加颜色、空间和时间等信息。光流算法[7-9]主要分析光流场中微表情序列的变化,从像素的角度提取相邻两帧像素的相对运动,捕捉面部的细微变化,降低头部运动和光线变化对特征的影响。频域算法[10-12]将微表情序列看作一个时域信号,通过傅里叶变换、Gabor变换等转换到频域上,提取振幅、相位信息等特征,能够有效提取面部轮廓的角点和边缘信息等局部特征。基于深度学习的微表情识别算法利用神经网络自主学习的特征,得到高层的语义信息。Patel 等[13]探索深度学习用于微表情识别任务,提出一种选择性的深层特征进行微表情识别,去除不相关的深层特征。Peng 等[14]提出了双时域尺度卷积神经网络(dual temporal scale convolutional neural network,DTSCNN),采用不同的网络流来适应不同帧率的微表情视频序列,避免了过拟合问题的出现。同时,将光流序列加到浅层网络,使得网络可以得到高层次特征。Verma 等[15]提出了LEARNet(lateral accretive hybrid network)捕捉面部表情的微观特征,在网络中加入AL (accretion layers)细化表达特征。目前的工作多采用微表情视频序列进行研究,该方法不仅计算复杂、耗时长,而且实际应用场景中通常也难以获得完整的微表情视频序列用以分类,具有一定的局限性。针对这一情况,本文提出了基于双注意力模型和迁移学习的Apex 帧微表情识别方法,主要贡献有3 点:
1)借鉴CBAM[16]的设计理论,并针对微表情的特性,在ResNet18[17]网络的基础上集成空间注意力模块、通道注意力模块,提升神经网络对Apex 帧微表情特征的提取性能;
2)采用Focal Loss[18]函数,解决微表情样本比例严重失衡的问题;
3)使用迁移学习的方式,从宏表情识别领域迁移到微表情识别领域,缓解微表情数据集样本严重不足的情况。
1 预处理
本文所提出的微表情识别算法主要包括微表情视频序列预处理和深度学习分类两部分,其整体流程如图1 所示。

图1 本文算法整体流程Fig.1 Proposed overall flow of the algorithm
1.1 Apex 帧
大多数微表情识别算法都将微表情作为一个视频序列进行处理。视频序列一般包含起始帧(Onset frame)、峰值帧(Apex frame)和终止帧(Offset frame)。其中,Apex 帧是微表情面部肌肉运动变化最为明显的一帧,最具有代表性。Liong 等[19-20]认为高帧率下的微表情视频序列并不是每一帧都是有效的,相反会造成计算冗余现象的发生。他们提出了只使用起始帧和峰值帧的特征提取方法Bi-WOOF 和OFF-ApexNet,识别效果非常显著。为了减少计算量,更加高效、快捷地将微表情进行分类,本文选取微表情视频序列中已标注的Apex 帧进行处理。
1.2 人脸图像预处理
在图像预处理过程中,使用OpenCV 和Dlib库实现人脸68 个关键特征点检测并进行标注。由于摄像头采集的人脸图像存在姿态多样、角度多样等问题,通过人脸对齐使之更符合微表情识别的需求。在已标注的特征关键点中选取左内眼角坐标(x1,y1) 和右内眼角坐标 (x2,y2),人脸水平夹角 θ 和人眼距离dist 计算公式如式(1)所示:

将人脸眼距的中点作为旋转中心(x0,y0),则旋转后的坐标计算公式如式(2)所示:
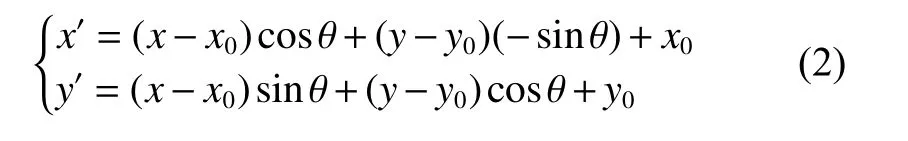
2 深度学习框架设计
深度学习的框架设计部分将分别介绍空间注意力机制、通道注意力机制、残差学习单元集成双注意力模型的方法、损失函数的选择、迁移学习的运用方式。
2.1 空间注意力机制
空间注意力机制专注于特征图中的重要空间信息部分,本文使用的空间注意力模块(spatial attention module)如图2 所示。将特征图作为空间注意力模块的输入,分别在最大池化操作和平均池化操作后进行拼接,接着采用核为7×7 的卷积提取感受野,最后通过Sigmoid 激活函数生成空间注意力特征图。空间注意力模块定义为


图2 空间注意力模块Fig.2 Spatial attention module
2.2 通道注意力机制
通道注意力机制关注不同特征通道的权重分布,本文使用的通道注意力模块(channel attention module)如图3 所示。假设输入特征图F∈RC×H×W,C、H和W分别代表特征图的通道数、高和宽,分别经过最大池化和平均池化后得到特征图Fm∈RC×1×1和Fa∈RC×1×1,接着将Fm和Fa分别依次进行核为1×1 的卷积、ReLU 激活函数、核为1×1 的卷积,然后对这两个输出向量按元素求和,得到尺度为[C×1×1] 的向量,最后该向量通过Sigmoid 激活函数得到通道权重结果。通道注意力模块定义为


图3 通道注意力模块Fig.3 Channel attention module
2.3 残差学习单元集成双注意力模型
本文将空间注意力模块、通道注意力模块集成到ResNet18 网络的残差学习单元中,如图4 所示。具体流程为输入特征图F∈RC×H×W,与S∈R1×H×W元素相乘得到F′,F′再与C∈RC×1×1相乘得到F′′,最后F′′与F元素相加得到最终输出的特征图F′′′。相比CBAM 的设计保留了更多原始特征图的细节信息,同时降低了整体网络的复杂度,更加适用于具有持续时间短、强度低的微表情。其定义为
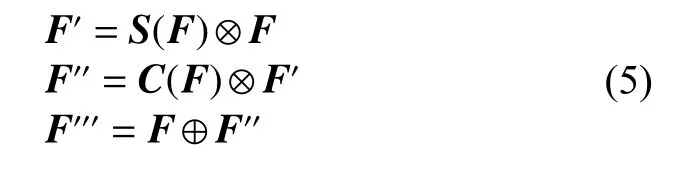
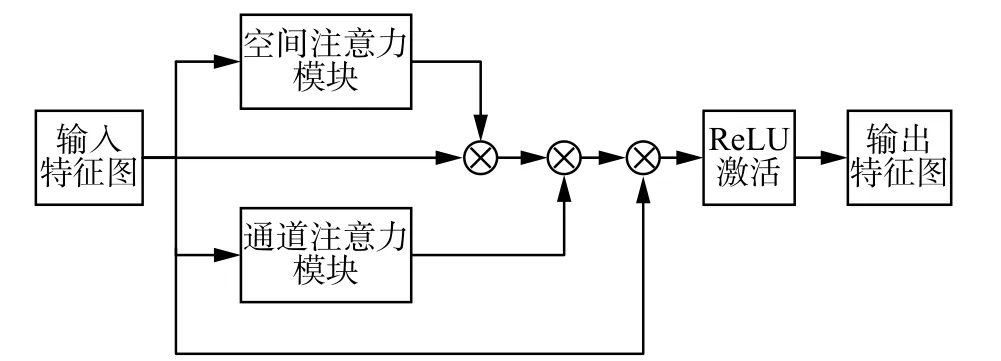
图4 集成双注意力模块的残差学习单元Fig.4 Residual learning unit integrated with a dual attention module
2.4 损失函数
由于微表情持续时间短、区别度低、采集难度高,微表情数据集中常常出现样本分布不平衡的现象。为了解决这一问题,本文使用Focal Loss 函数。该损失函数是交叉熵损失函数的改进版本,一个二分类交叉熵损失函数可以表示为

式中p表示模型预测属于类别y=1 的概率。为了方便标记,定义为

即交叉熵CE 为

Focal Loss 在交叉熵损失的基础上添加一个调制系数 (1−pt)γ,其中 γ≥0,定义为

其作用在于通过赋予易分类样本较小的权重,赋予难分类样本较大的权重,使模型在训练时更专注于难分类的样本,在一定程度上解决样本分布不平衡的问题。在多分类任务下,Focal Loss则定义为

式中 α 表示类别i的权重因子。
2.5 迁移学习
传统的深度学习中,模型充分预估结果需要数据集样本数量足够、训练数据和测试数据满足同分布。由于微表情数据集的规模都非常小,直接应用于神经网络的训练可能会引发过拟合、准确率低等问题,而迁移学习可以从大型数据集中学习先验知识,将模型参数迁移至待训练的网络模型中,从而提高模型的训练效率。
宏表情识别与微表情识别之间具有一定的共同之处,比如都有高兴、惊奇、沮丧、恐惧、厌恶等表情标签,都能够反映人的情绪。但微表情一般是一段视频,而宏表情则是根据单张图片进行分类。因为本文选取微表情视频序列的Apex 帧进行识别,即和宏表情识别的神经网络输入方式一样,所以迁移学习能够更好地应用。本文将宏表情识别作为辅助域,微表情识别作为目标域,通过迁移学习共享模型参数提高识别准确率。
3 实验结果与分析
3.1 微表情数据集
实验使用中国科学院心理研究所傅小兰课题组提供的CASME II 微表情数据集[21],包括255 个微表情视频样本,采样率为200 f/s,分辨率为280 像素×340 像素,26 位采集对象均来自亚洲,平均年龄22.03 岁。微表情分类为厌恶(63 个样本)、高兴(32 个样本)、惊奇(28 个样本)、压抑(27 个样本)、沮丧(4 个样本)、恐惧(2 个样本)和其他(99)共7 种。由于沮丧和恐惧两种类型的样本数量过少,因此本实验仅使用其余5 类共249个样本进行实验,其组成分布如图5 所示。可以看到,“其他”的样本数量占据了很大一部分。
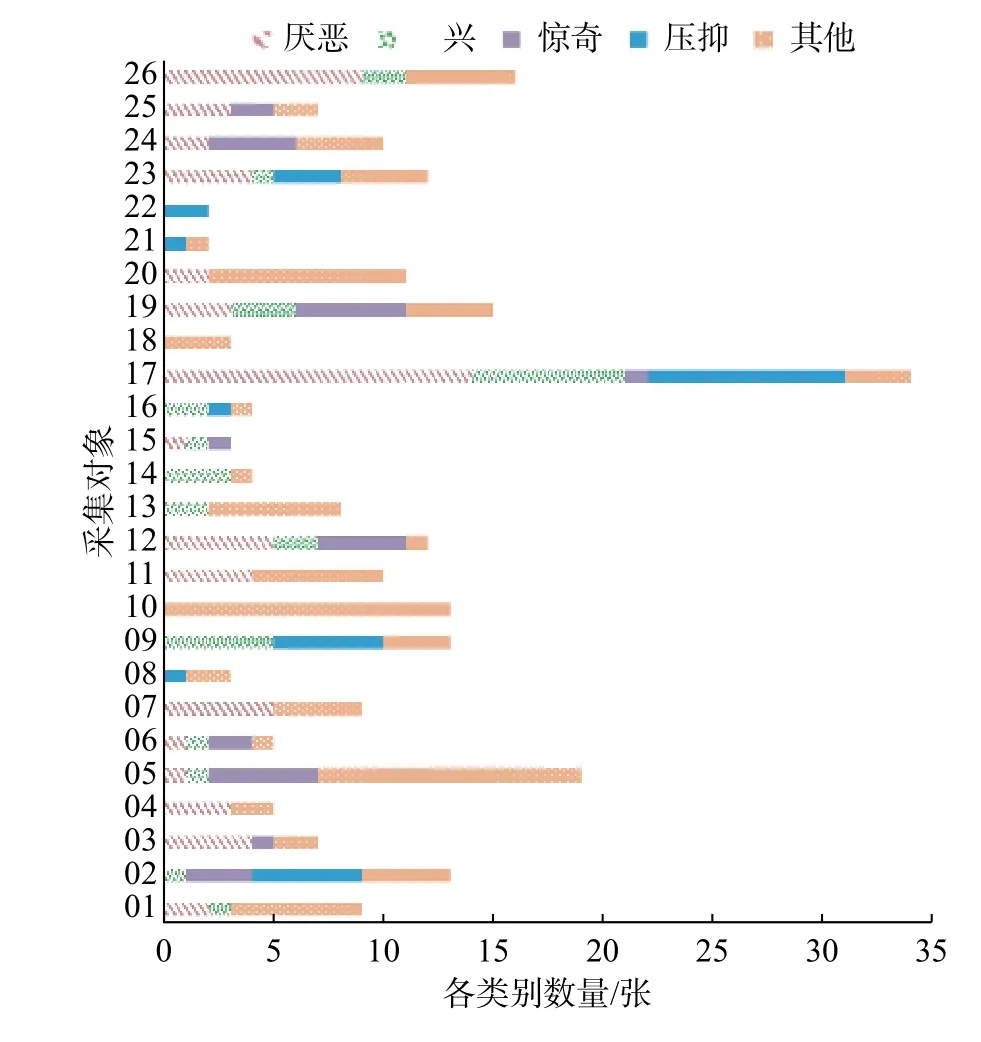
图5 CASME II 数据集样本分布Fig.5 Sample distribution of CASME II database
3.2 宏表情数据集
迁移学习采用来自卡耐基梅隆大学的The Extended Cohn-Kanade Dataset (CK+)[22]数据集,该数据集包含123 位录制者的593 组表情序列,其中有327 组被标注为愤怒、厌恶、恐惧、高兴、沮丧、惊奇和蔑视,共7 种表情类别。与CASME II 微表情数据集中每个表情序列包含起始帧至终止帧不同,该宏表情序列包含表情的中性状态至表情的最大表达状态。本文从带标签的表情序列中选取表现比较强烈的共981 张图片作为实验数据。
3.3 实验设置
本实验在Windows 10 系统环境下,预处理部分使用OpenCV、Dlib 库,神经网络基于PyTorch深度学习框架进行搭建,同时使用NVDIA CUDA框架10.1 和cuDNN 8.0.3 库。实验硬件平台中央处理器为Intel Core i9-9900X,内存为64 GB,显卡型号为NVDIA GeForce RTX 2080TI×2,硬盘为SAMSUNG 970 EVO PLUS 1TB。
本文使用留一交叉验证法(leave-one-subjectout cross-validation,LOSOCV),即将每位采集对象分别作为测试集,对CASME II 微表情数据集一共进行26 个训练测试过程。目前的研究工作中多采用此验证方法,优点在于每次迭代中都使用了最大可能数目的样本来训练,充分利用数据,采样具有确定性,而且由于微表情数据集样本数较少,不会造成很大的计算开销。另外,每位采集对象的微表情之间具有一定的差异性,将单独一位采集对象的所有微表情样本作为测试集,能够更好地反应方法的泛化能力。该数据集中已经标注了Apex 帧的位置,直接采用数据集中标注的峰值帧作为实验所用的Apex 帧。由于数据集中每位采集对象包含的微表情类别及样本数量差异较大,所以使用留一交叉验证法是个极大的挑战。在留一交叉验证的过程中,所有的微表情样本都会被分类器运算一次,本文采用对数据集整体准确率判定的方式评价模型的性能,其准确率计算公式为

为了研究Focal Loss 函数在微表情识别方面的有效性,本文在原生ResNet18 的基础上对比使用Cross Entropy Loss 函数,进行了2 组实验。将原始图片均处理为224 像素×224 像素大小输入网络,初始学习率设为0.001,每批次包含249 张图片,在实验中使用两张显卡并行计算。实验结果如表1 所示,在使用Focal Loss 函数后,其识别准确率提升了1.21%,证明使用Focal Loss 函数在微表情样本不平衡的情况下对于微表情识别有着更好的性能。

表1 各损失函数实验结果对比Table 1 Comparison of experimental results of various loss functions
为了研究空间注意力模块、通道注意力模块和混合注意力模块对于微表情识别是否有效,本文在使用Focal Loss 函数的基础上进行了4 组对比实验,分别是原生ResNet18 模型、融合空间注意力模块的ResNet18 模型、融合通道注意力模块的ResNet18 模型和融合双注意力模块的ResNet18模型,识别准确率如表2 所示。可以看到,3 种融合注意力模块的方法在识别准确率方面,相比较原生ResNet18 分别提升了4.02%、2.41%和4.82%,证明该双注意力机制有助于微表情识别。

表2 各神经网络实验结果对比Table 2 Comparison of experimental results of various neural networks
结合Focal Loss 和双注意力模块的识别算法在CASME II 数据上实验,得到最终准确率为43.37%。将该算法应用于CK+数据集,按照8∶2 划分训练集和测试集,多次训练后选取测试集准确率最高为94.38% 的模型进行迁移学习。在模型预训练后,微表情识别准确率提升至44.97%。为了进一步全面衡量分类器的性能,在实验中增加另外一个评价标准F1值(F1-score),其定义为

式中:TP 表示真阳性(true positive)的个数;FP 表示假阳性(false positive)的个数;FN 表示假阴性(false negative)的个数;P代表准确率;R代表召回率。表3 给出了各种方法在CASME II 数据集上的实验结果,本文算法在准确率方面相比其他微表情识别方法有一定的提升,在F1值方面也优于大多数算法。
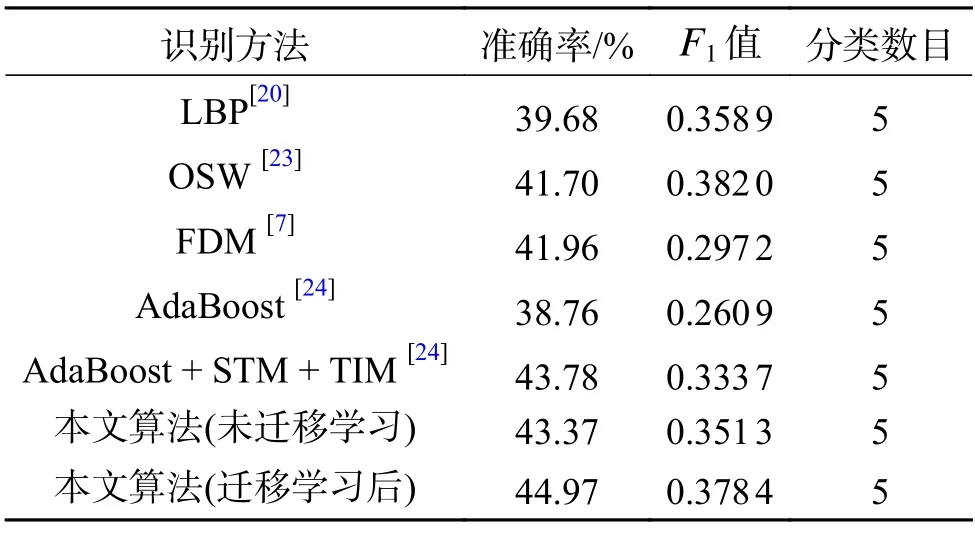
表3 CASME II 数据集实验结果对比Table 3 Comparison of experimental results on CASME II database
4 结束语
本文使用集成空间、通道双注意力机制的ResNet18 网络,更加关注微表情的细节特征,同时引入Focal Loss 函数缓解微表情数据集样本类别不平衡的状况。在CK+宏表情数据集上预训练后,迁移模型参数至CASME II 微表情数据集再进行训练测试,取得了不错的识别效果。考虑到本文算法仅使用微表情视频序列中的Apex 帧,相比现有的一些算法有着更为广泛的适用场景。后续研究将进一步关注于微表情数据集中样本的平衡性问题,同时更深地挖掘宏表情与微表情之间的关联,提高微表情识别的精度。
