基于深度强化学习的光伏-储能混合系统联合控制策略
2021-11-26向光伟黄诗颖
向光伟,黄诗颖
(1.国网黑龙江省电力有限公司,黑龙江 哈尔滨 150000;2.山东大学,山东 济南 250000)
0 引言
随着化石能源储备量的减少,以及化石能源的使用对环境产生的恶劣影响,全球能源调整的焦点正指向可再生能源的开发和利用。利用可再生能源的光伏发电在新能源开发与应用中扮演着越来越重要的角色。随着以“管住中间,放开两头”为核心的电力体制改革的推进,光伏发电商必将参与电力市场交易[1-2]。光伏发电商的收益与电站出力和市场结算电价直接挂钩。但是光伏发电的不确定性和电力市场中的时变电价使得光伏发电商的收益多变而?不可控。光伏电站需配备可行的控制手段使光伏电站最终输出的电能可以在一定程度上被调控,进而优化发电策略并实现长期利益的最大化。常见的调控手段有储能系统控制与购买外部备用两种方式。
由于光伏发电出力的不确定性,光伏-储能系统参与电力市场运行策略常采用随机优化方法来处理不确定性问题。文献[3]提出了基于在线模型预测控制(Model Predictive Control,简称MPC)的智能光伏电站运行策略优化方法,可在参与日内电力市场交易的过程中来抵消光伏发电预测误差。文献[4]以MPC作为光储系统参与市场的运行策略,在降低电池成本的同时实现运行的可靠性和收益性。文献[5]在采用MPC的基础上结合鲁棒优化,提出了基于鲁棒模型预测控制的光储系统参与实时能量和调频市场的运行策略优化方法。文献[6]在含光储系统的充电站运行场景下,以多场景日前优化模型考虑光伏出力不确定性问题,并采用日内滚动优化策略对储能充放电进行优化调度以最小化运行成本。上述研究中,以预测光伏发电输出功率为前提,先解决光伏发电出力的不确定性问题,再采用数学优化算法以最大化收益或最小化成本为目标对储能系统进行调度控制。然而在解决不确定性问题的过程中,假设的概率分布与实际光伏输出的吻合程度将会影响后续优化算法的效果。另外,光伏电站的高维气象数据容易在数据压缩、特征提取的过程中遭受损失,同样会影响优化算法的结果,从而影响光伏电站的收益。
针对上述研究中预测与调控分离的传统电网调度思路,一些学者引入了强化学习以及深度强化学习方法,将预测和调控作为一个整体连续的过程,并且在每一个调度周期中不断总结经验教训以消除不确定性。强化学习方法已经广泛应用于电力系统市场竞争、AGC控制等策略研究中[7-9]。深度强化学习在建立含高维不确定状态空间方面的优势使其决策能力更突出[10]。文献[11]构建基于Q学习算法的控制器,使风电-储能混合系统在学习过程中逐渐具备调控储能系统动作、购买备用的决策能力。文献[12]基于深度强化学习Rainbow算法提出风电-储能系统端对端的一体化调度模型。
在上述研究的启发下,本文提出了一种基于深度强化学习的光伏-储能联合控制方法。首先构建联合控制策略模型;其次搭建电力市场场景下的状态空间和动作空间,以最大化光伏电站收益为目标,同时考虑储能系统运行约束和运行越限的惩罚费用,基于深度强化学习算法建立光伏-储能系统联合调度模型;最后以某光伏电站为例进行模型训练和应用,验证所提方法的有效性。
1 强化学习与深度强化学习
强化学习的基本原理是控制体通过在环境中不断试错,并从环境中观察状态及获得奖励反馈,最终学会选择最佳动作以达到最优目标。强化学习原理图如图1所示。强化学习是一个不断试错和取得经验的过程。控制体训练完毕后,根据之前试错所习得的经验,得出如何动作以获得最优奖励值。

图1 强化学习原理图
强化学习在学习过程中通过二维表来描述和更新当前状态的价值,对于连续的输入变量,必须离散化连续的状态空间才能适用该算法,容易损失信息。当需要处理庞大的状态空间数据时,强化学习算法的计算量将大大增加。因此,将深度学习融入强化学习,引入神经网络建立强化学习中状态到动作的映射关系,以解决多场景下的庞大数据空间的计算问题。
将深度强化学习用于光伏-储能混合系统联合控制中,使用含原始测量数据的高维度光伏电站状态数据直接驱动储能系统,输出储能系统控制决策,以应对光伏发电不确定性问题并避免损失有效决策信息。
2 光伏-储能混合系统联合控制策略
2.1 联合控制策略模型
传统调度模式中预测和决策过程为两个独立的阶段。在预测过程中,工作由相应的预测算法完成,其输入通常包含太阳能组件方阵的实时和历史输出功率以及光伏电站实时、历史和预测的气象数据(温度、云量、短波辐射等),输出是未来调度时刻太阳能组件方阵的功率预测值Pforet。在得到预测结果后进入决策过程,该过程由优化算法完成,光伏电站的储能控制器以售电价格、Pforet、储能系统荷电状态作为决策依据,调控储能系统的充放电功率。这两个阶段并无合作。优化算法通常用己知概率分布描述光伏发电出力的不确定性,当假设的概率分布与实际光伏发电不确定性规律的吻合程度不理想时,将影响优化算法的实际效果。
本文提出的光伏-储能混合系统联合控制方法将两个独立的阶段合二为一,形成统一调度,如图2所示。调度结束后,光伏-储能混合系统向电网注入的功率为该时刻光伏电站的实际输出功率Ppv,t与控制器所决策的储能系统充放电功率PESS,t之和,即:

图2 光伏-储能混合系统联合控制

式中:PESS,t为正值表示储能系统处于放电状态,为负值表示充电状态,即由光伏电站向储能系统充电。
基于深度强化学习的光伏-储能混合系统控制流程如图3所示。通过深度学习神经网络的训练,由神经网络拟合状态到状态价值(Q值)的映射关系,以便更好地处理高维复杂的状态空间。深度强化学习算法中引入经验回放机制,即等概率随机提取部分样本作为神经网络训练集。该机制使得强化学习中各样本数据间的关联被打断,以更好地实现深度学习和强化学习的结合,增强算法的收敛性。
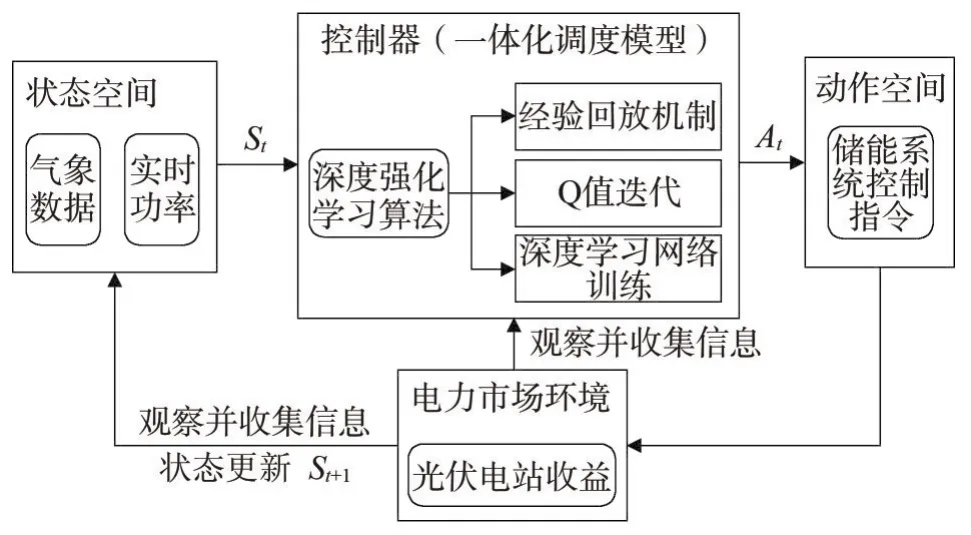
图3 光伏-储能混合系统控制流程
Q值迭代过程见式(2)。在Q值迭代完毕后,DQN(Deep Q Network,简称DQN)根据时间差分偏差(Temporal Difference error,简称 TD-error)构建深度学习神经网络损失函数进行网络训练,以使Q值最终迭代收敛,见式(3)和(4)。经过深度强化学习后,针对不同的光伏发电出力,控制器在动作空间中选择能使混合系统收益最大化的动作。

式中:Q(st,at;θt)为当前状态 st下动作为 at的 Q 值;θt为训练网络的网络参数;θ-为目标网络的网络参数;α为学习率;rt为当前奖励值;γ为衰减系数;δt为时间差分偏差值;Loss(Qt)为损失函数。
2.2 状态空间和动作空间
在联合控制策略模型下,状态空间构成如式(5)所示:
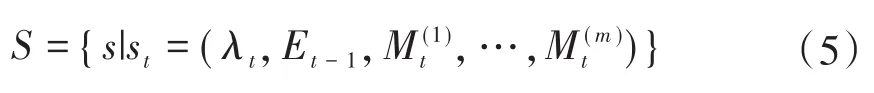
式中:S为状态空间集合;M(m)t为光伏阵列的实时和历史输出功率以及光伏电站的温度、云量、短波辐射等实时、历史的气象数据;λt为t时段光伏电站的售电价格;Et-1为上一调度时段结束后当前储能系统的电量值。
储能系统的充放电功率值PESS,t被等间隔离散为n个值构成的动作空间,如式(6)所示。

式中:A为动作空间集合。
2.3 奖励函数
在训练过程中,控制器根据电力市场环境反馈的奖励值来调整控制器内深度学习神经网络的参数。本文中,当前环境下的奖励是混合系统所得的调度收益rt,如式(7)所示。

式中:Ct为混合系统因运行状态越限所产生的惩罚费用;Δt为控制器每执行一次调度所经历的时间间隔。在电力市场环境下,联合控制调度模型以最大化混合系统的长期收益为控制目标安排储能系统的充放电功率。在该模型中,控制器的调度周期为一天且每小时执行一次调度。控制器的长期收益为:

式中:i为当前已经历的调度周期数。
2.4 系统运行约束与惩罚费用
混合系统中储能的控制指令调整受运行约束的限制。本文中,储能系统采用蓄电池储能,其充放电功率用 PESS,t表示。PESS,t正值表示放电状态,负值表示充电状态。
蓄电池组的运行约束主要有单次动作指令约束、储能系统能量约束、控制周期末时段电量约束和储能系统充放电状态转换约束。
单次动作指令约束:
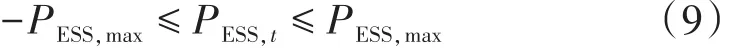
储能系统能量约束:

控制周期末时段电量约束:

储能系统充放电状态转换约束:

式中:PESS,max为单次充放电动作允许最大值;Emin和Emax分别为储能系统的最小和最大电能存储量;Eend为控制周期末时段的电量要求;YESS,t为储能系统充放电状态转换变量;NESS为一个控制周期内允许的储能系统最大转换次数。
当储能系统电量违反约束时,联合系统需要支付的惩罚费用Ct计算如下:

3 算例分析
3.1 算例场景
本文以某光伏电站为例对所提方法进行有效性验证。在联合控制策略模型中,储能系统的参数如表1所示。混合系统动作空间包含31个动作,即{-7.5,-7.0,…0,…,7.0,7.5}。各时段的售电电价如图4所示。

表1 储能系统参数

图4 不同时段电价
模型中算法的相关参数设置如表2所示。控制器内的深度学习神经网络结构如图5所示。隐藏层为一层64个神经元构成的全连接层,各层神经元间的连线表示网络间的参数权重。
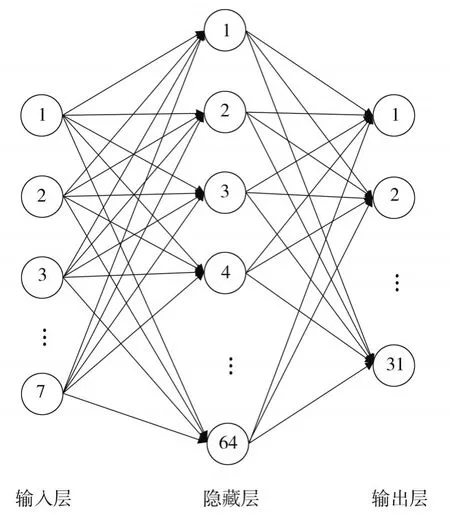
图5 深度学习神经网络

表2 模型参数设置
3.2 算例结果与分析
在联合控制策略模型的训练过程中,损失函数值变化如图6所示。损失函数值随着训练步数的增加迅速变小,可见该策略模型可逐步收敛并具备较好的决策能力。
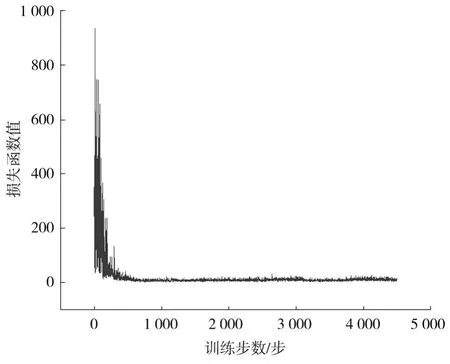
图6 损失函数值
图7为光伏电站每小时平均收益和平均惩罚成本随控制器历经样本数量增加的变化曲线。在训练前期,控制器所历经的样本数量不足,神经网络所描述的状态、动作与状态值间的映射关系尚未明确,因此该阶段的收益为负值。随着样本的累积和训练的进行,映射关系被持续优化,达到稳定后由于输出功率的波动,混合系统的收益在一定范围内稳定波动。此时光伏-储能混合系统调度所获得的平均收益为5 086.858元/h。同时,惩罚费用随着训练的进行而减少,当惩罚费用变化曲线稳定后,光伏-储能混合系统平均惩罚费用为265.646元/h。

图7 混合系统每小时平均收益和平均惩罚费用曲线
当光伏-储能混合系统的收益、惩罚费用曲线都趋于稳定时,表示联合控制策略模型的参数已收敛,可以应用于混合系统实际运行场景中。运行场景中的储能系统荷电状态变化如图8所示。在储能系统与光伏电站结合的初始时段,荷电状态经常集中在最低电能限制附近。经过控制策略调整之后,荷电状态集中在50%附近,进一步降低了系统运行越限的惩罚费用,提高了光伏-储能混合系统的整体收益。

图8 储能系统荷电状态变化
4 结语
针对电网传统调度思路中预测、决策独立的现状,本文提出了一种基于深度强化学习的光伏-储能混合系统联合控制策略模型。考虑光伏发电出力的不确定性,整合预测决策过程,避免了预测过程中高维数据的特征缺失,同时使预测决策过程合作交互,以光伏-储能系统在电力市场环境下长期联合收益最大为目标,得到最优的储能系统调度控制指令。以某光伏电站为例建立模型并进行计算与分析。算例结果表明,本文所提出的方法能够有效应对光伏发电的不确定性并最大化光伏-储能混合系统的收益。
