结合空洞卷积和迁移学习改进YOLOv4的X光安检危险品检测
2021-11-25吴海滨魏喜盈刘美红王爱丽岩堀祐之
吴海滨,魏喜盈,刘美红,王爱丽,刘 赫,岩堀祐之
(1.哈尔滨理工大学 黑龙江省激光光谱技术及应用重点实验室,黑龙江 哈尔滨 150080;2.中部大学 计算机科学学院,爱知 春日井 487-8501)
1 引言
随着社会的不断进步,公共交通在生产生活中所占据的位置日益重要。目前,安全检查广泛应用于一些政府机关办公场所、交通枢纽、军事基地、科研及保密场所、航天基地等场所,如果在这些场所发生意外,将会导致人员伤亡和经济财产损失,并带来极其恶劣的社会影响。为了减少此类恶性事件的发生,我国对安防领域的投入也逐渐增多,安检级别也越来越高。安检门和安检机是目前应用最广泛的安检设备。安检门,又称为金属探测门,主要是检查人身上携带的金属品,如枪支、械具等。安检机则主要是对人随身携带的行李、包裹等进行检查,通过X光安检通道对行李进行透视性扫描,安检员进而通过影像判断是否含有违禁品、危险品等。越来越密集的交通网络以及巨大的客流量使得我国的安检工作量激增,安全检查的工作面临严峻的挑战。
近年来,深度学习在目标检测等任务中发挥了至关重要的作用[1-2]。利用深度卷积神经网络能自动提取X光危险品特征的优势,有效地解决了物品遮挡、背景杂乱等问题,提高了危险品的检测性能。2017年,Mery等在GDXray数据集测试了10余种安检图像识别方法,它们包括基于BoW、稀疏KNN、深度学习等,这也是深度学习首次应用到X光安检领域[3]。2018年,Akcay提出了一种基于深度学习的行李检查方法。首先,标记图像中的每个对象,然后将图像的位置和边界框指定给具有卷积神经网络的区域,最后检测并识别出危险品[4]。Morris等人提出了Passenger Baggage Object Database,应用于危险品分类,并且在VGG19、Xception、InceptionV3模型上进行测试,得到最佳模型的ROC曲线为0.95[5]。Akcay等采用迁移学习(Transfer Learning)的方法,使用深度卷积神经网络解决X光行李安全筛选背景下的图像分类问题[6]。
2019年,Akcay提出了GANomaly模型,利用生成对抗网络训练不包含危险品的正常样本,将包含危险品的少数样本作为异常样本,通过判别器判断其与网络学习到的潜在变量之间的差异,从而判断是否为异常样本[7]。Reagan等人利用VGG-16网络在ImageNet数据上训练了1000个不同的类,再将该模型学习到的内容作为初始化参数迁移到危险品的分类任务上,大大改善了分类精度[8]。
2020年,唐浩漾等人提出在SSD目标检测网络上构建特征金字塔,融合危险品的底层边缘形状信息特征和深层语义特征,并使用可行变卷积提高网络危险品检测能力[9]。张友康等人提出了非对称卷积多视野检测网络,该网络使用小卷积非对称网络、多尺度特征图融合策略以及空洞多视野卷积模块,有助于提高背景干扰下的X光安检图像危险品识别[10]。郭守向等人构建了基于YOLO (You Only Look Once)的X光图像违禁品检测网络,其主干网络Darknet-C由辅助骨干网络各个特征层和引导主干网络对应的上一层级进行特征级联后向下一层传播,有效提升了检测小目标的检测效果[11]。Zhu等人提出了一种用于X光安检图像的数据增强方法,丰富安检图像的多样性。首先,使用改进的自我注意生成对抗网络 (Self-Attention Generative Adversarial Networks,SAGAN)生成了新的危险品图像。其次,提出了一种基于循环生成对抗网络(Cycle Generative Adversarial Networks,CycleGAN)的方法,将物品的自然图像转换为X光图像[12]。
本文在YOLOv4的基础上,结合空洞卷积对其网络结构进行改进,加入空洞空间金字塔池化模型(Atrous Spatial Pyramid Pooling,ASPP),称为ASPP-YOLOv4模型,以此增大感受野,聚合多尺度上下文信息,同时利用迁移学习训练网络和余弦退火优化学习率,大大提高了对X光安检图像中危险品的检测精度。
2 ASPP-YOLOv4检测模型
本文构建的ASPP-YOLOv4模型包括模型预训练、网络结构、锚框选择3个部分,如图1所示。

图1 ASPP-YOLOv4模型设计Fig.1 ASPP-YOLOv4 model design
(1)引入迁移学习,利用公开的VOC数据集对YOLOv4网络进行预训练,将训练好的参数迁移到本文构建的ASPP-YOLOv4模型进行微调。与正常卷积神将网络训练中的随机初始化不同,将预先训练的网络权重值作为初始化参数加载,可以有效加速收敛并提高检测性能。
(2)采用具有高性能和强稳定性的YOLOv4作为基本检测模型,结合上下文信息对于检测目标的重要性,将原网络中的空间金字塔池化改进为空洞空间金字塔池化,构建ASPP-YOLOv4检测网络。通过使用不同扩张率的空洞卷积实现不同尺度的最大值池化,在增大感受野的同时有效融合多尺度的上下文信息,增强模型对危险品尺度变化的鲁棒性。
(3)根据危险品目标的尺度分布特点重新设计了初始锚框。使用K-means聚类算法对危险品目标的尺度进行聚类的结果作为初始锚框,使得网络候选框的初始化尺寸更加贴合危险品目标。另外,在训练过程中采用学习率余弦退火衰减策略,实现模型训练过程的优化。
2.1 YOLOv4
YOLO[13-14]网络是一种基于回归的目标检测网络,其可以通过充分提取被检目标的特征,直接在一个网络内同时完成目标的分类和定位任务,真正实现了一种简单且高效的端到端的设计思路,成为one-stage检测模型的重要代表。
YOLOv4[15-16]算法是在YOLOv3的基础上,从数据增强、主干网络、网络训练、损失函数等方面进行改进优化,虽然其网络结构更复杂,但有更高的精度和更快的速度,在检测小目标和被遮挡目标方面有着显著的提高。图2为YOLOv4的网络结构。

图2 YOLOv4网络结构Fig.2 Network structure of YOLOv4
YOLOv4算法主要包括4个步骤:
(1) 将输入图片分成S×S个网格,物品中心落在网格中心,检测该网格中的物体;
(2) 每个网格都生成B个预测框;
(3) 每一个预测框均针对C个类别进行概率预测;
(4) 使用非极大值抑制算法对所有预测框进行筛选,得到最终包含目标类别和位置坐标的检测结果。
2.2 空洞空间金字塔池化模型
在X光安检图像检测任务中,容易受到遮挡、拍摄角度、复杂背景等因素的影响,导致其外观信息获取不足,影响其整体信息的收集,因此在检测危险品时,仅通过目标表征进行判断的准确率较低。上下文信息具有描述目标内在联系的特点,将其加入至目标检测任务中,能有减少上述影响,提高检测的准确度。空洞卷积在不使用池化层的情况下,能够增大感受野,使每个卷积输出都包含较大范围的信息,进而提高网络性能。其核心是向卷积层引入一个新参数——扩张率(dilation rate),该参数定义了卷积核处理的间隔数量。空洞卷积核和感受野大小计算如式(1)和式(2)所示:
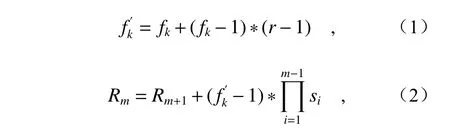
其中,fk表示原始卷积核的大小,表示空洞卷积核大小,r表示卷积核的扩张率,Rm表示经空洞卷积后第m层感受野大小,Si表 示第i层的步长,“*”表示卷积。
YOLOv4中使用SPP模块提取不同感受野的信息,但没有充分体现全局信息和局部信息的语法关系。本文设计的ASPP引入不同扩张率的空洞卷积操作,实现SPP中的池化操作,并将其与全局平均池化并联,组成一个新的特征金字塔模型,以此聚合多尺度上下文信息,增强模型识别不同尺寸同一物体的能力。
结合ASPP改进的YOLOv4框架如图3所示,其中ASPP采用扩张率r分别为1、3、5且卷积核为 3 ×3的空洞卷积,在前一层的局部特征上关联到更广的视野,防止小目标特征在信息传递时丢失。
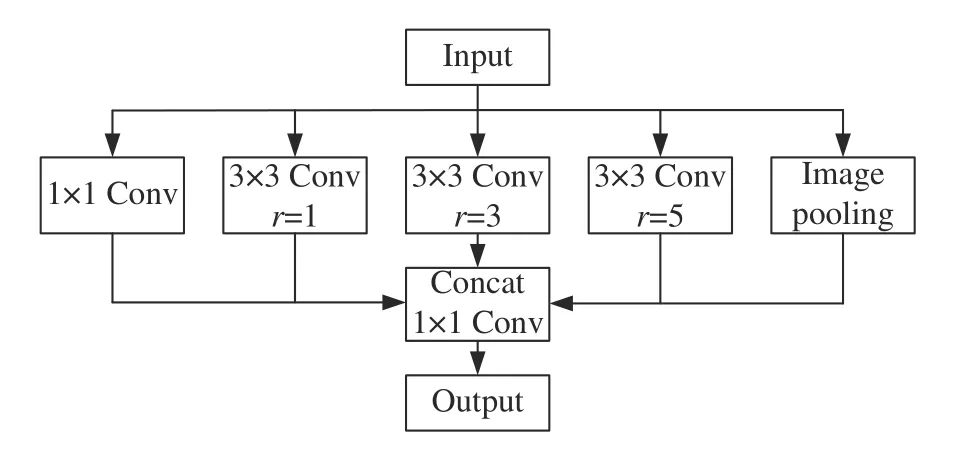
图3 结合ASPP改进的YOLOv4框架Fig.3 Improved YOLOv4 framework combined with ASPP
图3中,ASPP将输入的特征同时输出到5个支路中,第1个支路是一个1×1的卷积,目的是保持原始的感受野;第2~4支路是不同扩张率的空洞卷积,并且包含BN层,目的是对特征进行提取,获得不同的感受野,最后的特征图能够融合不同尺度的信息;第5个支路的目的是获取全局特征,将特征做全局平均化池化后,经过1×1卷积和归一化处理,再进行上采样。本文模型通过ASPP,可以学习到不同尺寸危险品的特征,降低危险品的漏检率。
通过特征融合后,YOLOv4获得了3个特征层的预测结果,尺寸大小分别为(13, 13, 30),(26,26, 30),(52, 52, 30)的数据,分别对应网格上3个预测框的位置,其中每一个网格点负责一个区域的检测。其中维度30代表了3个box的详细信息,每个box长度为10。这10个维度的信息为得到的预测结果:(x_offset,y_offset,h,w,conf,conf1,···,conf5) 。其中x_offset表示网格左上角相对于x轴的偏移量,y_offset代表网格左上角相对于y轴的偏移量,h代表预测框的高,w代表预测框的宽,conf代表置信度,confi(1≤i≤5)表示分类结果。最后,取出每一类得分大于阈值的框和得分进行排序,利用框的位置和得分进行非极大抑制 ,最终得出概率最大的边界框。
2.3 利用迁移学习训练网络
在深度神经网络中,前面的卷积层一般学习具有通用性的浅层特征,而后面的卷积层学习的是对当前训练目标更具有针对性的、更高级的抽象特征。先冻结部分网络层可以加快训练速度,也可以在训练初期防止权值被破坏。导致模型泛化能力差的另一个原因是目标函数存在局部最小值,而迁移学习能有效避免这个问题。
考虑到存在大量可见光图像,而X光危险品图像过少,采用基于参数迁移的学习方法训练ASPP-YOLOv4网络。迁移策略如下:
(1)选取公开的VOC数据集为预训练数据集,该数据集有20类标注目标,共计16万张图像,用VOC数据集为源域在YOLOv4网络上学习图片底层特征;
(2)取训练检测效果较好的YOLOv4源域网络,去掉后面全连接层和分类层,作为ASPPYOLOv4骨干网络的预训练权重,其他网络部分采用权重随机初始化的方式;
(3)冻结主干网络,对不冻结的网络层进行微调,参与反向传播中的梯度更新;
(4)放开冻结层,对全部层利用反向传播算法进行训练,得到最终合适的参数矩阵和偏置向量。
2.4 基于K-means聚类的锚框选择
采用K-means聚类的方法代替原始锚框,使得网络候选框的初始化尺寸更加贴合危险品目标,进一步提高网络的检测效果。K-means是一种无监督学习算法,它将数据集划分成多个簇,通过计算每个样本的相似性度量,并将其分配给与之距离最近的簇中心,每次迭代都计算每个簇中所有样本的均值,不断更新簇中心,直到簇中心不再变化。
本文处理的X光危险品的真实框由左上定点和右下定点表示,即 (xmin,ymin,xmax,ymax)。由于数据集中图片大小不同,首先对使用图片的长宽对box的宽和高按式(3)做归一化处理。标准的K-means使用欧式距离作为度量,但本文检测方法中只需要关心锚框与真实框的交并比(Intersection Over Union, IOU),不关心真实框的大小,因此,使用IOU作为度量更加合适。假设anthor=(wa,ha),box=(wb,hb),则二者的IOU如式(4)所示。IOU值越大,表示两个框距离越近。最终度量如式(5)所示。

本文首先选取9个框作为初始的锚框,再使用IOU度量,将每个框分配给其距离最近的锚框形成新的簇,并在每次迭代后计算每个簇中所有框的均值,更新锚框,直到锚框不再变化。最终得到的锚框如表1所示。

表1 锚框计算结果Tab.1 Calculation results of the anchor
2.5 余弦退火优化学习率
ASPP-YOLOv4的学习率采用了余弦退火(Cosine annealing)优化算法,它与传统的学习率不同,随着epoch的增加,学习率先模拟余弦函数快速下降,再线性上升,不断重复该过程。传统的训练过程中学习率逐渐减小,模型逐渐寻找到局部最优点,模型会快速地往局部最优点移动,随着学习率的减小,模型最终收敛到一个全局最优点。而余弦退火的学习率急速下降,所以模型会迅速踏入局部最优点,并保存局部最优点的模型,然后开启热重启(Warm restart),学习率重新恢复到一个较大值,逃离当前的局部最优点,并寻找新的最优点,周期性重复上述过程。学习率余弦退火衰减具体策略如表2所示。

表2 余弦退火衰减过程Tab.2 Cosine annealing decay process
其中重启并不是从头开始,而是通过增加学习率来模拟,另外定义了一个初始学习率。由于模型在刚开始训练时的权重是随机初始化的,如果此时就直接采用较大的学习率,容易造成模型的震荡。采用warmup预热学习率可以避免上述问题,这是因为如果在刚开始训练的几个epoch内采用预热的小学习率下,模型可以慢慢趋于稳定,这时再使用预设的学习率进行训练,可获得更快的收敛速度。
3 实验结果及分析
本文实验均在Windows操作系统下实现,采用Python语言和Keras库编码,NVIDIA RTX2070显卡GPU加速,CPU为32 GB Intel®Core™ i7-9750H CPU @ 2.60 GHz。数据集采用的是SIXRay数据集[17]中所有正类样本添加位置标签生成的数据集,手动框出危险品的位置并标注出类别,最终生成每幅图片的标签文件。将数据集划分为两部分,80%样本作为训练集,20%样本作为测试集。选择余弦退火学习率算法作为梯度优化算法。
训练超参数配置如表3所示。为了验证本文算法的有效性,选取目前主流目标检测模型,包 括YOLOv3[18]、M2Det[19]、SSD[20]、YOLOv4做对比。表4列出了以上几种方法对5种危险品的检测结果。
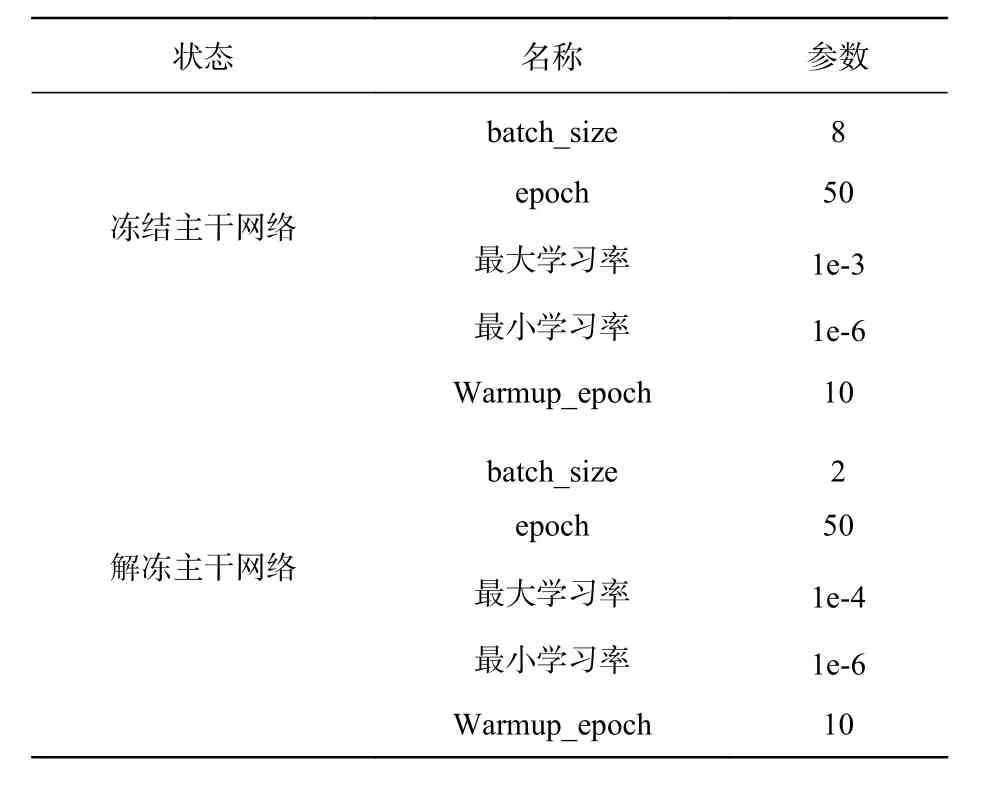
表3 训练超参数设计Tab.3 Design of the training hyperparameters
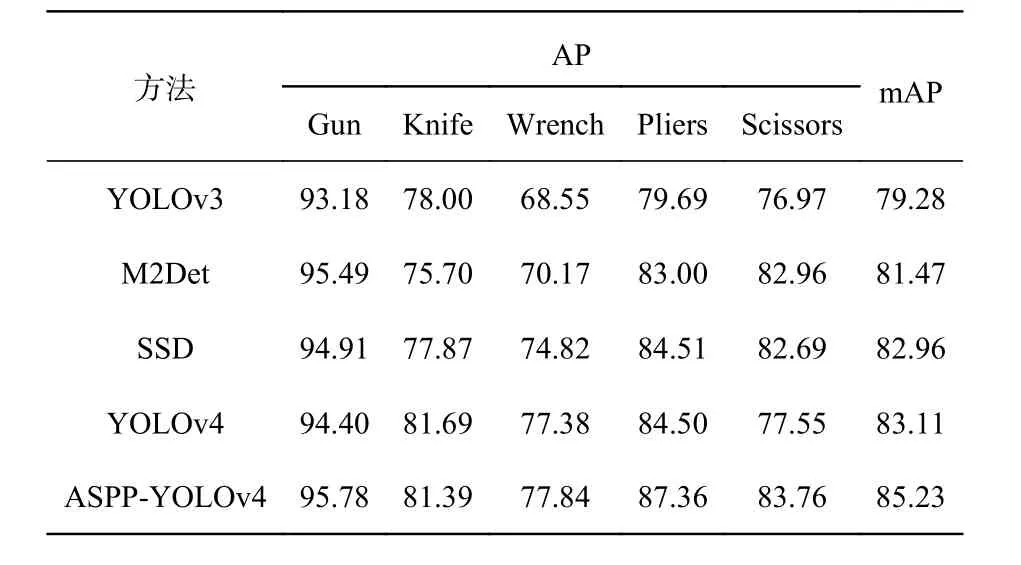
表4 不同模型的AP比较Tab.4 Comparison of AP for different networks (%)
在目标检测模型训练时,训练和验证过程中每一个Epoch的损耗值下降曲线如图4所示。从图中可以看出,在前50个Epoch训练过程中,随着迭代次数和训练时间的增加,Train-Loss和Validation-Loss均逐渐下降,最终趋于平稳,训练过程中设置了早停策略,得到最优检测模型。

图4 训练过程中的Loss下降曲线Fig.4 Loss decline curves during training process
对于Gun来说,数量相对较多,特征明显,所有网络对其检测精度较高;由于Wrench的类内差异大、相互重叠,所有网络对它们的检测精度均偏低;Scissors的数量少,目标小,易被覆盖,漏检率较高。ASPP-YOLOv4的多类别平均精度(mean Average Precision, mAP)为最高,达到85.23%,相比于YOLOv3、M2Det、SSD、YOLOv4分别提升了5.95%、3.76%、2.27%和2.12%。除了Knife,本文的检测精度均最高。
与YOLOv4相比,Gun、Wrench、Pliers的平均精度(Average Precision, AP)分别提升了1.38%、0.46%、2.86%,Scissors提升明显,为6.21%。对于Knife来说,本文方法相对于YOLOv3提升了3.39%,比M2Det提升了5.69%,比SSD提升了3.52%,与YOLOv4相比,仅下降了0.3%,是可以接受的。
图5(彩图见期刊电子版)用柱状图比较5种方法在每类样本上的AP,可以直观地看出,本文方法具有良好的检测效果,性能最优。

图5 几种方法对各类危险品的检测结果Fig.5 Detection results of dangerous goods detected by different algorithms
表5列出了ASPP-YOLOv4对SIXRay数据集上不同类别危险品的检测性能。从表5可以看出,针对各类样本,模型的AP较好,但召回率(Recall)相对较低,这是因为安检图像目标较小,重叠较多,更容易造成漏检而不是误检。尤其是对于Knife这类物品,摆放的方式、物品大小形状等差异较大,漏检率相对较高。而本模型的准确率(Precision)保持在较好的水平,误检率较低。
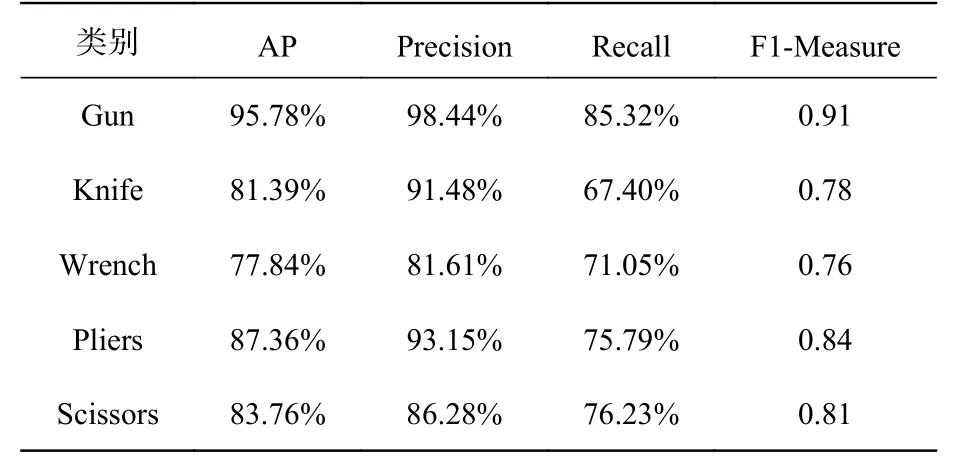
表5 ASPP-YOLOv4的性能分析Tab.5 The performance of ASPP-YOLOv4
为了进一步证明本文提出的ASPP-YOLOv4算法的有效性,表6取各类目标的平均值,作为整体性能评估指标,与原始YOLOv4进行对比。从表6中可以看出,ASPP-YOLOv4相比YOLOv4,mAP提高了2.12%,召回率提高了2.16%。表明本文方法能更好地与目标特点匹配,目标定位更准确,同时空洞卷积的引入提高了模型识别同一类物品的能力,所以能有效提升目标准确率和召回率。
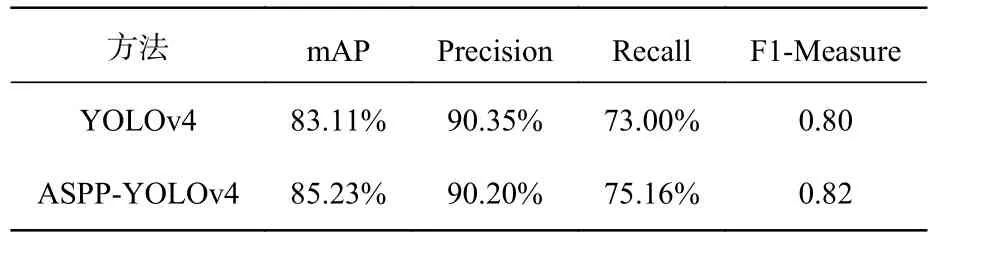
表6 YOLOv4改进前后检测性能对比Tab.6 Comparison of YOLOv4 performance before and after improvement
ASPP-YOLOv4模型在测试集上的目标检测效果如图6(彩图见期刊电子版)所示。其中图6(a)是多目标图像,可以看出ASPP-YOLOv4模型能较为准确地检测出每一个目标,其中绿色检测框表示刀具,同一张图片中的3个刀具具有不同的形状和大小,但是本文模型可以较好地识别,置信度分别为0.94、0.72、0.67;紫色检测框表示枪支,置信度为0.77;蓝色检测框表示扳手,由于轮廓相对清晰,置信度达到0.98。图6(b)是摆放差异图像,两把刀具的摆放方式有较大的差异,但背景较为简单,模型对两支枪的置信度均为1.00,对刀具的置信度分别为0.85和0.87。图6(c)是小目标图像,红色检测框表示剪刀,ASPP-YOLOv4对其有较好的识别精度,置信度为0.99。图6(d)是重叠图像,背景杂乱且颜色相近,ASPP-YOLOv4模型可以获得更大的感受野,较好地融合上下文信息,进而能从重叠的X光图像中得到更加准确的目标特征,对扳手的置信度为0.81,黄色检测框表示钳子,其置信度为0.94。
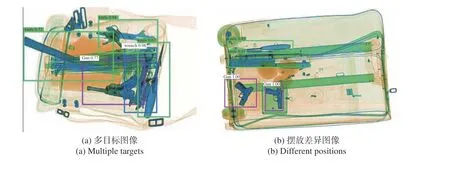
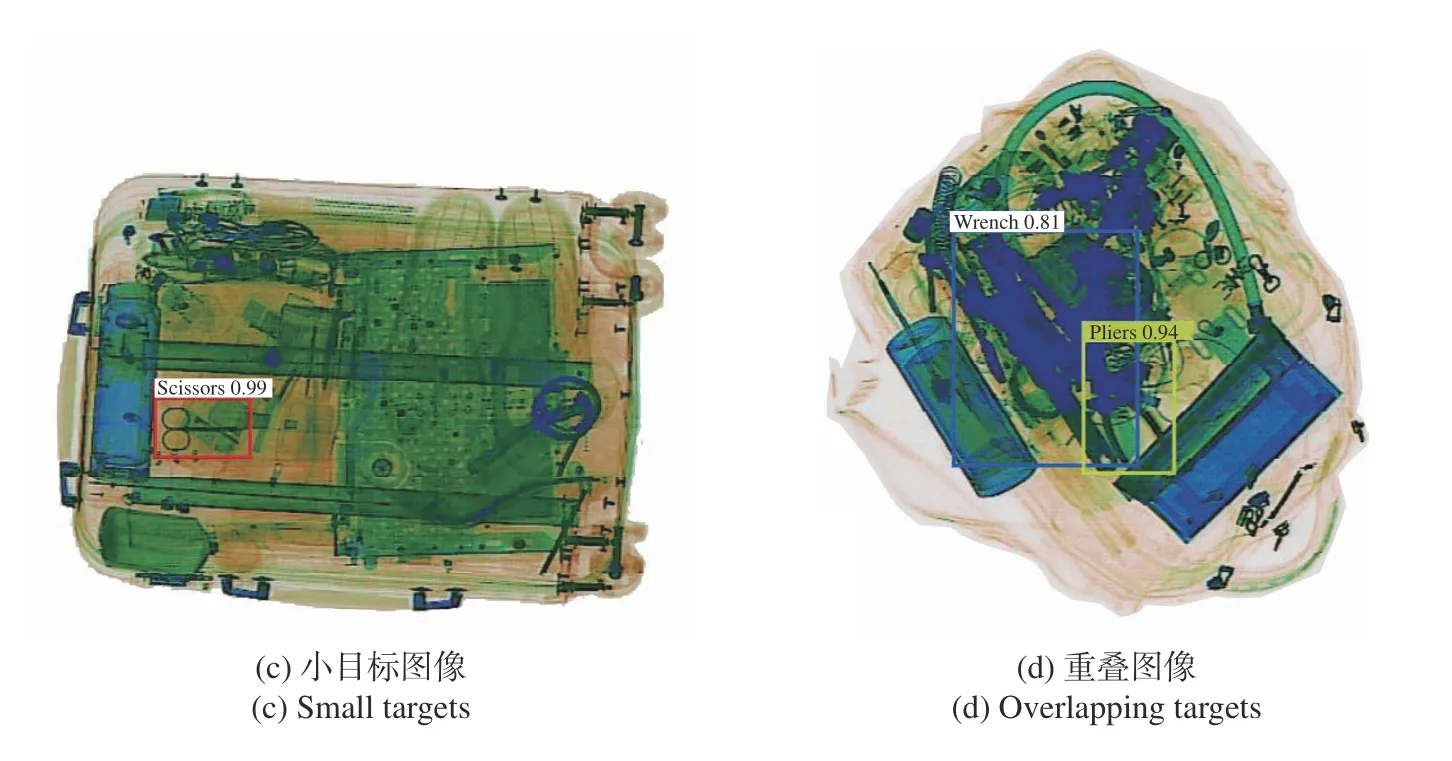
图6 危险品检测效果Fig.6 Detection results for dangerous goods
4 结论
本文对YOLOv4进行改进,实现了X光安检图像危险品检测,该模型结合空洞卷积改进空间金字塔池化,在增大感受野的同时有效融合多尺度的上下文信息。同时利用迁移学习训练网络和余弦退火优化学习率,提高检测精度的同时,加速模型收敛,减少训练时间。最后以K-means聚类的方法设计锚框,使其更加适合危险品的定位。实现结果显示,在SIXRay数据集上的mAP达到85.23%,充分表明ASPP-YOLOv4模型对于X光安检危险品图像的检测结果优于其他方法,能有效解决物体遮挡问题,危险品的分类与定位效果均有提升。
