基于用户效用的隐式反馈推荐系统研究
2021-11-23陈丽
陈丽
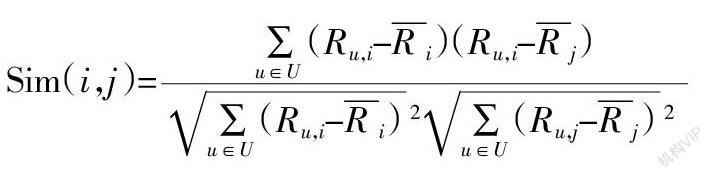

【摘 要】线上产品广告如同“信息爆炸”般涌向电商用户,降低了用户购物体验。因此,设计出一个高效、精准的推荐算法一直都是智能电商的研究重点。论文旨在设计一个基于用户效用的隐式反馈推荐系统,在不干扰客户购物的情况下,为客户提供合适的商品。论文首先采用隐式数据,设计出商品效用值,然后根据用户的付出成本,计算出用户的收益值,最后把收益值最大的商品作为推荐品。经过测试集的计算,模型准确率为90.2%。
【Abstract】Online product advertisements flood e-commerce users like an "information explosion", which reduces users' shopping experience. Therefore, designing an efficient and accurate recommendation algorithm has always been the research focus of intelligent e-commerce. This paper aims to design an implicit feedback recommendation system based on user utility to provide customers with appropriate products without interfering with their shopping. The paper firstly uses implicit data to design the commodity utility value, then calculates the user's profit value according to the user's cost, and finally takes the commodity with the highest profit value as the recommendation product. Through the calculation of the test set, the accuracy of the model is 90.2%.
【关键词】隐式反馈;推荐系统;效用
【Keywords】implicit feedback; recommendation system; utility
【中图分类号】TP391.3 【文献标志码】A 【文章编号】1673-1069(2021)11-0106-03
1 引言
随着信息爆炸时代的来临,用户面对着海量的商品信息。当海量的商品涌入消费者的脑海中,不仅不会增加消费者满意度,反而会降低消费者的购物体验。因为面临大量的商品数据,消费者会认为绝大部分的信息都是无用的。甚至部分消费者认为,繁多的商品信息严重降低了购物效率。
为解决数据过载带来的问题,电商平台采用了推荐技术。采用针对性推荐技术,能够提高电商平台的转化率。同时,因为推荐技术能够为用户过滤繁多的信息,提供精准的商品推荐。因此,一个能够提供精准推荐的算法,对于推荐系统至关重要。
推荐算法通过对消费者进行分析以后,为其推荐感兴趣的商品项目。目前推荐算法主要是协同过滤算法。利用客户的历史购物数据,根据其与商品属性的关系来做出推荐。协同过滤要用到的是顾客的显式反馈。一般有2种类型的协同过滤:基于用户评分的和基于商品相关性、用户相似性得出推荐的商品。协同过滤最大的优势在于可以处理复杂的对象,如书籍、音乐、电影等。Vincent W. Zheng等人设计出基于移动设备GPS的利用协同过滤推荐算法,为用户提供路线推荐。可是,传统的协同过滤算法计算效率不高,难以对付目前海量用户的信息对比。所以,Altingovde等人先采用了聚类算法来处理用户群,缩小对比范围,再进行协同过滤推荐。Maleszka在协同过滤传统算法的基础上,建立基于用戶的档案的信息检索系统,为新用户解决冷启动问题。Gérard Biau用k-nearest neighbor算法,从统计学的角度去改进协同过滤。协同过滤算法主要依靠的都是历史的数据。例如,通过某消费者历史购物信息来推荐给具有相似兴趣的消费者。因此,商家为了提高自己产品被推荐的可能性,就会采用虚假评论、刷单、虚假评分的方式。这些虚假分数会产生“劣币驱逐良币”的效应,导致真正优质的产品不被消费者看到。这样长久以后,最终也是降低了消费者的购物体验。因此不采用历史数据、消费者评分这种显式反馈数据,而是采用更加精确、隐秘性强的隐式反馈数据。
隐式反馈推荐主要是指利用效用函数进行计算推荐商品。效用函数最初来源于经济学领域,用于测量消费者在购物中所获得的满足程度。目前基于效用函数的推荐算法不算多,主要是利用商品对用户的效用值匹配的评估上来进行推荐,最终目的是帮助用户获得利益最大化。研究的重点主要集中在为每一位客户建立效用评估函数。有一些网站,并不需要用户事先为商品输入效用值,而是利用指定因素与用户的交互作用和权重赋值,为用户提供推荐信息。并且,效用函数根据用户兴趣而建立,作用于商品,决定商品在用户心中的等级。而隐式反馈数据主要是通过收集消费者在购物浏览的过程中留下来的痕迹数据,如点击、收藏、加购物车等行为数据。这些行为数据能够更加客观地显示出消费者的购物倾向。这些数据都具有隐匿性,不会影响消费者购物体验。
本研究主要采用隐式反馈方法,设计基于用户效用的推荐算法。首先采用隐式反馈数据,制定效用评分机制,构建商品效用函数模型。然后考虑用户的投入成本,构建商品收益函数。通过构建基于隐式反馈的用户效用函数,能够避免因为虚假信息而导致的推荐不准的问题,同时,能提高推荐精准度。
2 相关理论
2.1 显式反馈算法
信息数据的爆炸式增长,使得客户每时每刻都面临着海量的信息。为有效处理客户的选择与海量信息之间的矛盾,促使平台更好地达成交易,推荐算法应运而生。推荐算法本质上就是根据客户的兴趣爱好,推荐其相关的商品和服务,如书本推荐、社交好友推荐等。较早的推荐算法是协同过滤,这是一种显式反馈推荐,主要是采用客户对商品“打分”的方式,然后系统会根据分数,寻找与之打分相近的客户,推荐相似的商品。Zhang采用递归推进的预测方法,解决了系统过滤的稀疏性问题,把那些邻近的尚未对商品进行评分的客户也纳入预测当中,由此提高协同过滤的预测精准度。Leng认为评分数据的稀疏性问题会严重影响系统推荐的结果,因此提出了一种基于邻域评级插补的混合协同过滤算法。通过PCA主成分分析,减少原始评级矩阵的维数。同时采用奇异值分解SVD来估算邻近的确实评分。但是这种“打分”会对客户造成一定的不良购物体验。同时,也比较难以收集这些数据。
基于内容的推荐算法,虽然也是属于显式反馈算法,但是其不需要用户进行评分,而是通过为商品贴上标签,做成商品属性,然后分析用户的商品偏好,推荐具有类似属性的商品。
基于内容的算法作出推荐,主要有3个步骤:①内容分析。很多时候,系统所推荐的内容是具有非结构化的,如新闻、书本、文档信息等。所以,要做出推荐的话,必须先对这些内容进行整理,主要整理方法就是作内容结构化处理,如提取特定的属性特征向量,再把属性特征存入系统,形成对应的特征向量数据库。②分析用户偏好。根据用户历史购物信息,构建用户偏好数据库。③匹配。将生成商品特征向量数据库与用户偏好数据库进行匹配排序,采用COS等相似度计算法,算出匹配度最高的商品。
相似度的计算方法主要是皮尔逊相关系数和余弦相似度。皮尔逊相关系数主要用于统计学中:
Ru,i,Ru,j表示对于商品i和商品j的评分。结果越小,表示2个商品相似度越高。显式反馈需要收集客户的评分信息,这往往会令用户感觉隐私被侵犯,而且认为这种评分行为烦琐。所以,即便评分是为了更好地为用户服务,但是也会造成用户不良的浏览体验。那么,收集而来的数据就会体现稀疏性。
2.2 隐式反馈算法
跟显式反馈的“打分”不一样,隐式反馈主要是计算机主动学习客户的消费习惯,通过分析相关数据来获得客户的偏好。例如,客户喜爱某个商品,就会对这个商品的详情页进行浏览、把该商品加入购物车、分享该商品页面等。随着电子商务平台的竞争日益剧烈,商家们都在想尽办法引流,刺激客户的购物欲望。所以,隐式反馈在目前更多地被商家运用。早在1994年,Morita等人就已经将用户浏览新闻所用时长作为隐式评分标准进行研究,除此以外,还有用户浏览的次数。谢文玲通过相关性分析发现,用户的浏览次数和浏览时长与用户的兴趣具有高度相关性。隐式反馈的推荐方法主要是通过引入辅助信息来实施。因为隐式反馈缺乏用户直接的评分,所以可以通过采用引入外部信息的方式来进行。例如,引入相似内容的属性特征,形成用户偏好,然后将推荐的项目与之比较,也可以基于排序进行推荐。例如,Amatriain提出的逐对排序,将对比的电影进行配对,然后根据用户对电影的偏好程度,逐一进行比较,最后将对比结果进行排序。Li等人采用用户的搜索历史记录、购买记录等来提高协同过滤的准确性,也就是将用户的信息嵌入隐式反馈中。吴远琴等采用卷积神经网络将用户与项目的隐层特征进行学习并且建模,然后把特征融入预测推荐列表。
效用来源于经济学,主要表示某个项目满足人的程度,也就是人对于某个项目的认可程度。因此,效用是一种主观感受,反映出人的抽象偏好。Park等人提出采用模糊系统、贝叶斯网络和效用理论构建CA-MRS音乐推荐系统,为用户提供音乐推荐。Manouselis等突破了传统推荐算法的单一属性的特点,采用了多属性效用理论(MAUT)为顾客提供更高效的推荐。Orad认为,顾客的隐式反馈行为类型可以归结为:审查、保留和参考这3种行为类型。Konstan等人基于顾客阅读文件时长来建立顾客对文件偏好程度的考量体系。JINMOOK等尝试通过修改浏览器来捕捉在某个会话内顾客的隐式反馈数据,从而获取顾客偏好。可见,基于隐式反馈的行为预测系统,需要系统通过观察顾客的点击行为来学习顾客对商品的偏好。获取顾客隐式反馈数据的方式包括:访问页面、停留页面时间、拖动滚动条、点击鼠标、收藏某种产品、购物车数据等。然后结合某种主观考量方法对商品进行效用评价。评价时,对顾客正常的浏览行为不会造成影响,所以更加具有可信度。Moe通过分析10000个家庭用户的点击行为,发现频繁访问某个特定商店的用户最终在这家商店发生购买行为的概率更高。那么“访问频率”这个行为则被视为高价值行为。Park等分析1190个用户的行为序列,发现越少的网页跳转和越长的网页浏览时间的用户,更有可能发生购买。这里可见“跳转次数”和“浏览时长”这2个行为亦被视为高价值行为。Alan使用动态多项式概率模型分析用户行为序列,从概率上分析用户行为,发现高价值动作,从而预测用户购买行为。Gerald认为用户分2步购买商品,第一步大致快速浏览多个商品,第二步深入详细了解某个商品。于是,其开发了交互式决策助手,分析顾客的行为序列,為顾客快速推荐商品。采用用户行为情景数据,计算行为相似度,构建行为特征向量,最终形成预测。这些研究都认为,可以通过客观的点击序列数据,挖掘高价值行为,做出用户商品购买预测。
本文将隐式反馈数据嵌入效用函数,构建基于用户效用的隐式反馈推荐算法。这样可以在不打扰用户的情况下,解决冷启动、稀疏性问题,为用户购物做出精准推荐。
3 模型構建
用户网上购物的过程,实际上是一种不断对比的过程,所以本研究利用隐式数据,构建效用评分制度,从而作出推荐。
所有顾客的集合表示U={u1,u2,…,ui},个体顾客ui∈U。在一个会话期间内(sj∈S),顾客浏览的全部商品的集合表示为I■={a,b,c,…,n,m}。
其中,vi表示该用户浏览所有商品的效用值。同时,在该对话期内,所有商品的效用值集合表示为V={v1,v2,…,vi}。表示商品i在目前所有商品中的序列位置。w是用户的隐式评分机制的权重值。商品评分值为0~5分。
用户通过浏览以后,每个商品都会获得一个商品效用值vi。而在这个期间内,该用户所获得的平均效用值为v(I)。假设用户在这个期间内所付出的成本为c,那么其收益函数则为:
其中,α和β分别表示用户的偏好系数和商品的属性弹性系数。根据柯布道格拉斯函数,α一般取值[0.2,0.4],β取值[0.6,0.8]。
本研究的算法流程是首先提取用户日志信息,从中提取隐式数据,如浏览时间、浏览时长、点击行为等,然后通过隐式评分机制计算出商品的效用值,再计算收益值,最终作出商品推荐。
4 实验测试
本次实验,采用了JD.COM电商平台用户购物浏览数据,一共328名用户作为测试集,134563条记录。通过数据清洗以后,得出以下隐式数据类型:
在此,以用户u55作为例子。用户u55在本次期间内,产生了139条记录。首先计算其浏览的产品的效用值。通过计算,可以得出,在这个时期内,用户u55所浏览的所有商品中,商品d55的效用值明显高于其他商品。得出商品效用值以后,计算商品收益值。在此,分别采用[α1=0.2,β1=0.6]和[α1=0.4,β1=0.8]这2种情况去计算用户u55的商品收益值。由此可见,无论α和β取值如何,收益值整体曲线趋势不变,而且仍然是商品d55的效用值最大。由此可以将其作为推荐商品。
类似的,把测试集328名用户的数据进行测试,计算准确率为90.2%。
5 结论
电商平台的流量之争,导致商家必须竭尽全力提高用户的体验感,为用户提供良好的服务。而其中,推荐系统所发挥的作用不可忽视,但是以往的推荐系统的算法依据的是历史信息,这样会因为信息滞后、虚假信息等的因素而导致推荐算法的精准度低。
本研究主要利用了电商平台中用户的隐式数据:点击浏览数据,构建隐式评分机制,将用户的浏览行为作出赋权,计算出商品的效用值,然后根据用户的浏览成本,构建商品收益函数,计算每个商品的收益值。最终,将收益值最大的商品作为推荐产品。研究采用了328名电商用户的数据作为测试集,最终计算出其准确率为90.2%。
本研究所采用的隐式数据,可以在不干扰用户浏览行为的情况下,进行商品推荐,这样有效地解决了因为需要用户提供评分而造成的干扰。同时,因为不需要用户事先对商品进行评分,所以也解决了冷启动问题。用户浏览点击数据为客观数据,本研究引入了效用评分机制,揣摩用户的浏览行为时所产生的心理活动,这样能有效地把客观数据转变为主观心理数据。
不过,本研究也有不足之处:并没有全方位多维度考虑顾客的浏览动作类型,如用户分享商品页面、用户评论商品等这种行为并没有列入模型中。在未来的研究中,必须更进一步衡量用户的行为,这样才能提高算法的精准度。
【参考文献】
【1】Zhang J, Pu P. A recursive prediction algorithm for collaborative filtering recommender systems[C]// Acm Conference on Recommender Systems. ACM, 2007.
【2】 Leng Y J, Liang C Y, Qing L U, et al. Collaborative Filtering
Recommendation Algorithm Based on Neighbor Rating Imputation[J]. Computer Engineering, 2012.
【3】Masahiro Morita and Yoichi Shinoda. Information filtering based on user behavior analysis and best match text retrieval[C]., 1994.
【4】谢文玲,潘建国.基于语义相似度的个性化信息检索方法[J].计算机应用与软件,2011,28(05):161-164+196.
【5】Amatriain X, Pujol J M, Oliver N. I Like It. I Like It Not: Evaluating User Ratings Noise in Recommender Systems[C]//International Conference on User Modeling. Springer-Verlag, 2009.
【6】Park H S, Yoo J O, Cho S B. A Context-Aware Music Recommendation System Using Fuzzy Bayesian Networks with Utility Theory[C]//International Conference on Fuzzy Systems & Knowledge Discovery. Springer, Berlin, Heidelberg, 2006.
【7】Manouselis N, Costopoulou C. Experimental Analysis of Multiattribute Utility Collaborative Filtering on a Synthetic Data Set[M].2008.
【8】OARD D W, KIM J. Implicit feedback for recommender system[C]. In:proceedings of the massachusetts institute of technology, department of electrical engineering & computer, New York, USA: 1997.
