结合案件要素序列的罪名预测方法
2021-11-22孙倩秦永彬黄瑞章刘丽娟陈艳平
孙倩,秦永彬,2,黄瑞章,2,刘丽娟,陈艳平,2
1.贵州大学计算机科学与技术学院,贵州 贵阳 550025;2.公共大数据国家重点实验室,贵州 贵阳 550025;3.贵州师范学院,贵州 贵阳 550018
1 引言
随着智能司法建设的稳固推进,人工智能技术逐渐渗透到法院审判工作中。法律查询、信息检索等智能辅助办案功能被不断地探索和实践,极大地促进了审判体系的现代化。当前,法院在长期的司法实践中积累了大量的裁判文书,裁判文书是法院的审理过程和结果的载体,其中蕴含了重要的案情信息和隐藏的知识价值。利用裁判文书的案情事实部分,发现隐含的特征信息,是支撑智慧法院辅助办案的核心,是提升法院工作效率和保障司法公平的重要途径[1]。
罪名预测是智能司法辅助办案中的重要任务。在具体的司法实践中,法官通常从案情事实出发,依据案情特征及其逻辑关系进行判定。在此过程中,案件要素发挥了重要作用。案件要素是指案情事实描述中的关键行为词及与行为相关的要素。
案例1故意杀人罪:“XX市人民检察院指控,被告人党某在家中因生活琐事与其婆婆吴某发生争执,在争吵与打斗过程中,党某持砖头击打吴某头部,致其当场死亡。”
案例2抢劫罪:“XX市人民检察院指控,被告人王某某窜至X市X区X路X超市门口,持刀对被害人段某某进行威胁,从段某某包内抢走现金400余元后,逃至X小区旁一网吧内,王某某在网吧内被公安民警抓获。”
案例1和案例2分别是故意杀人罪和抢劫罪的案情事实部分。案例1是由于双方发生争执,行为人党某故意使用凶器击打被害人吴某头部,导致被害人吴某死亡。案例2是由于行为人王某某单方面原因,持刀威胁被害人并抢走财物。两个案例在犯罪起因和经过、适用罪名、包含案件要素等方面均不同。由此可见,案件要素的获取可以实现案情事实和判决结果的关联。此外,案情事实中通常包含多个行为动作,其中某些行为对判决结果产生的影响不大。如何找到句子的中心行为要素并建立关联关系对于案情过程表示有重要影响。
因此,本文将犯罪过程表示为一系列以“行为”为核心且具有时序关系的案件要素,即案件要素序列,并融合文本语义表示,实现结合案件要素序列的罪名预测。本文主要贡献如下。
● 本文提出了一种结合案件要素序列的罪名预测方法。该方法利用图卷积神经网络(graph convolutional network,GCN)模型获取案件要素序列表示,利用卷积神经网络(convolutional neural network,CNN)模型获取文本语义表示,然后融合进行罪名预测。
● 在实验部分,通过与现有方法进行对比,融合案件要素序列表示能显著提高罪名预测性能,本文方法的有效性得到验证。特别地,该方法对易混淆罪名区分也有良好的表现。
2 相关工作
作为法律审判预测的重要任务之一,罪名预测指根据给定的案件预测罪名。在早期罪名预测任务中,大部分工作使用统计分析方法。后来量化分析[2]和关联分析[3]被提出,但这类方法局限性较强,只针对特定领域的数据集。
随着机器学习的发展,罪名预测任务可以分为基于特征工程和基于神经网络的方法。Lin W C等人[4]重点讨论了强盗罪和恐吓取财罪,并定义了21种法律要素标签,利用这些要素标签进行罪名分类。Liu Y H等人[5]提出一种基于文本挖掘的方法,使用支持向量机(support vector machine,SVM)进行分类。在人工智能技术的加持下,法律研究逐渐变得智能化、自动化。Jiang X等人[6]通过深度强化学习方法提取事实部分的依据并将该依据信息融入分类模型,从而提高准确性。Kang L Y等人[7]针对刑事案件的事实部分,根据罪名的定义来创建辅助事实以扩充其表示,从而提高预测准确率。Yang X T等人[8]从事实描述中提取出相关片段进行特征增强,将罪名作为监督标签进行预测。刘宗林等人[9]从事实描述中抽取有助于区分易混淆罪名的指示性罪名关键词,从而解决罪名预测任务中的罪名易混淆问题。除了使用案情事实部分,相关研究者还引入案件相关信息来辅助预测。Luo B F等人[10]提出基于注意力的神经网络方法,并引入法条信息进行罪名预测。Hu Z K等人[11]针对低频罪名和易混淆罪名引入10个有代表性的属性进行区分,利用注意力机制生成与属性相关的事实表示,依据不同属性进行预测。He C Q等人[12]提出一种序列增强的胶囊网络模型来解决低频罪名,并设计一个注意力残差单元来提供辅助信息。敖绍林等人[13]利用三元组损失(triplet loss)技术调节CNN,从而更好地学习案件表示的语义特征向量。当前研究大多采用增强案情事实信息或引入辅助信息的方式。通过分析真实案例发现案件要素和行为发生顺序对于审判结果有显著影响,但上述研究没有考虑该情况。在司法要素方面,黄辉等人[14]提出了基于BERT阅读理解框架的司法要素抽取方法,该方法建立了辅助问句和裁判文书之间的语义联系,增强了模型的学习能力。张虎等人[15]通过抽取判决要素,结合法条与语义差异性进行罪名预测。
近年来,图神经网络(graph neural network,GNN)被作为图数据挖掘领域的热门研究方向之一,相关研究者将图神经网络与自然语言处理任务结合并取得了一定的成果。在此过程中,他们提出了文本数据的多种构图方式,将文本分类任务转换为图分类或节点分类任务。Yao L等人[16]将文档和词作为图节点,对文本语料库构建文本图,将文本分类问题看作节点分类问题。Zhang Y F等人[17]认为每个文档都有自己的结构图,提出一种基于图神经网络的归纳式文本分类方法,将文本分类转换为图分类任务。Hu L M等人[18]提出一种异质图注意力(heterogeneous graph attention,HGAT)网络来学习短文本的表示并进行分类。Huang L Z等人[19]提出了一个基于图神经网络的模型,该模型能为每个输入文本生成一个文本级别的图。在司法领域,Xu N等人[20]提出一种图神经网络来自动学习易混淆法律文本间的细微差别,并设计了一种利用学习到的差异从事实描述中提取有效的区别特征的注意力机制。
上述研究表明,图神经网络对文本处理有积极意义。然而在司法研究领域,图神经网络的应用较少。由于每个案件文本都可以表示为图结构,为了更好地捕获案件事实特征,本文将图神经网络与司法数据结合,以此来聚合关联案件的表示,捕获更多潜在信息。
3 罪名预测模型结构
本文的罪名预测模型主要分为4个部分,其结构如图1所示。第一部分,案件要素图构建。针对案件要素识别中存在的缺乏训练数据集、识别困难等问题,采用基于BERT(bidirectional encoder representation from transformer)模型[21]的案件要素识别方法进行要素识别,并根据案件要素及要素间的关联关系构建案件要素图。第二部分,案件要素序列表示。本文引入双层图卷积神经网络模型对案件要素图进行建模,捕获案件间的潜在关系,形成案件要素序列表示。第三部分,文本语义表示。根据模型特点,使用文本卷积神经网络(TextCNN)模型[22]捕获文本语义特征表示。第四部分,模型输出。将文本语义特征与案件要素序列特征融合,并经过全连接(fully connected,FC)层输出。

图1 罪名预测模型结构
3.1 案件要素图构建
在司法案例数据中,每个案件都有自己的图结构。本文将案件要素作为图节点,案件要素间的关联关系作为边,构建案件要素图。从案情事实中获取案件要素需要着重考虑3个问题。首先,刑事案件犯罪过程复杂,案件要素之间关系众多,如何捕获要素间的特征关系对于案情事实表示较为关键;其次,在案情事实的单个句子中可能出现多个行为要素,极大地增加了面向单一行为要素识别的训练压力;最后,由于司法数据的特点,缺乏相关训练数据集。
针对以上问题,本文使用刑事判决书中的事实部分,经过人工标注形成案件要素数据集。结合中文谓语动词标注方法的规则及句法要素识别方法[23-24],本文使用BERT-CRF框架实现案件要素识别。BERT的双向Transform框架能很好地融合上下文信息,增加的条件随机场(conditional random field,CRF)层可以捕获标签间的概率转换信息。本文将案件要素识别任务转换为序列标注任务。

本文采用BERT作为主要模型,模型的输入为对应的词向量、位置向量、句向量3个嵌入特征。的输入向量可以表示为:
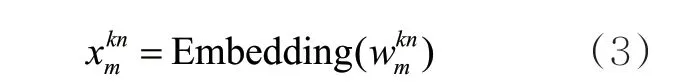
经过BERT模型后将向量表示输入CRF层进行标签预测。本文使用“BIO”标签体系预测所属标签:
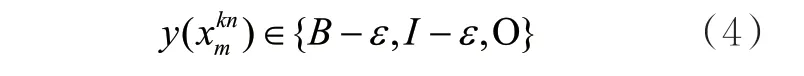
其中,“B-ε”表示该元素是案件要素的开始字符;“I-ε”表示该元素是案件要素的中间字符,也可以表示单个词语;“O”表示该元素不属于任何类型。ε∈{SUB,ADV,PRE,RAI,TEM,LOC},“SUB”表示犯罪主体;“ADV”表示犯罪行为描述;“PRE”表示犯罪行为;“RAI”表示犯罪行为导致的结果;“TEM”表示犯罪时间;“LOC”表示犯罪地点。由于单字形式不利于案件要素图构建,本文在识别模型输出后增加了一个数据后处理操作,即将当前B标签位置开始到下一个B标签位置结束之间的汉字进行拼接。经过数据后处理后,得到被包含在各句子中的案件要素集合,最终形成案情事实kd包含的案件要素kdV:
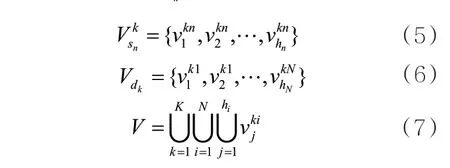
其中,h表示句子中存在的案件要素数量。进一步地,去除案件要素集合V中重复的案件要素,得到不重复案件要素集合V′:
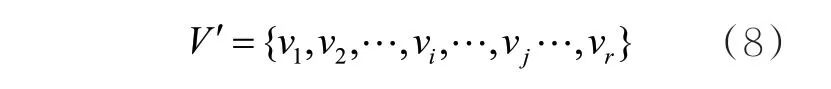
其中,r表示案例数据集包含的不重复案件要素个数。本文将案件要素作为节点,案件要素之间存在的关联关系作为边。具体来说,对于案件要素vi、vj∈V′,本文依据案件要素的共现信息构建边,边的权重通过点互信息(pointwise mutual information,PMI)计算,这一过程可以表示为:

其中,eij表示案件要素vi与vj之间的边,当vi=vj时,eij表示当前节点的自环边。PMI主要用于计算词语间的语义相似度,计算过程可以表示为:
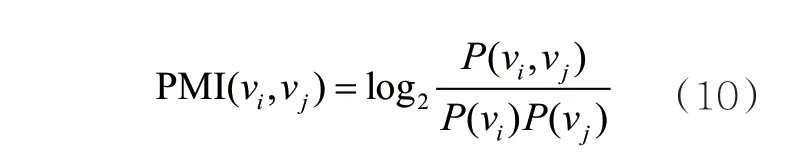
若 PMI(vi,vj)为正,则表示语义相关度较高;若PMI(vi,vj)为负,则表示相关度较低;若PMI(vi,vj)为0,则表示不相关。面向整个案例数据集D,案件要素之间的边集合E可以表示为:
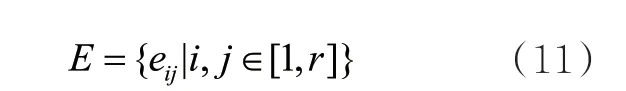
为了后续获取节点自身的特征信息,每个案件要素节点都存在一个自环边。本文将案件要素作为图节点,案件要素之间的关联关系作为边,构建案件要素图G= (V′,E)。由于每个案件都有属于自身的图结构,案件要素图G可被认为由K个案件要素子图组成,即:
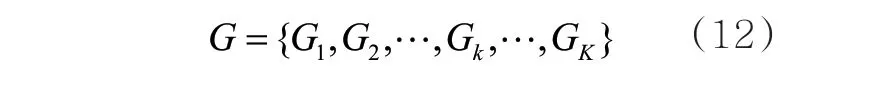
3.2 案件要素序列表示
GCN可以利用边和节点的信息聚合生成新的节点表示,从而对图结构数据信息进行有效提取,GCN在图表示学习领域具有强大的优势。从图节点角度出发,节点的学习过程是将自身的特征信息传送给邻居节点,再将邻居节点的特征信息收集,以此来聚合节点间的特征信息。结合案件犯罪过程及案件要素图的构建方式,本文利用双层GCN模型进行序列建模。
在GCN中当前隐藏层到下一个隐藏层对节点的特征变换可以表示为:
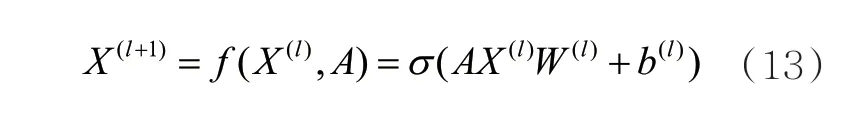
其中,W(l)、b(l)分别表示在l层的权重、截距;σ表示非线性变换;X(l)表示在l层的节点特征;当层数为零时,X0表示初始节点状态;A为邻接矩阵,可以表示为:
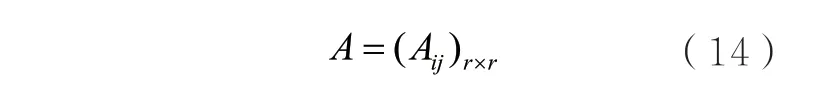
其中,Aij=eij。为了相对保持数据间关系并获取自身节点特征信息,对邻接矩阵进行归一化处理并加入节点自环信息。该过程可表示为:
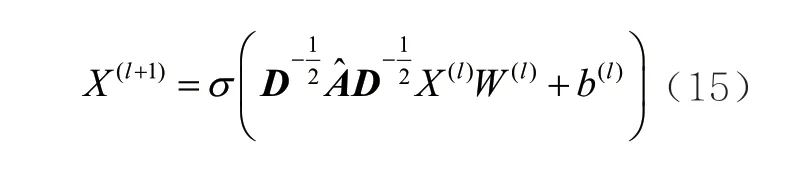
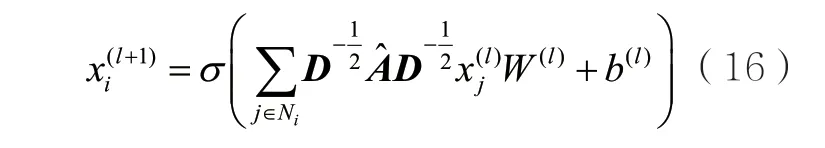
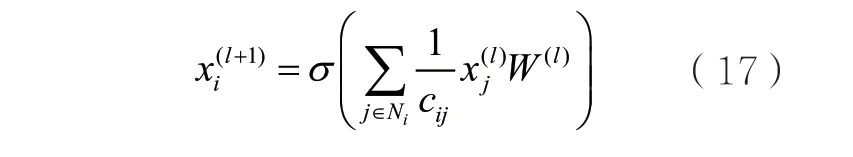
其中,cij表示归一化因子。案情描述dk在第l+1层上的特征可以表示为:
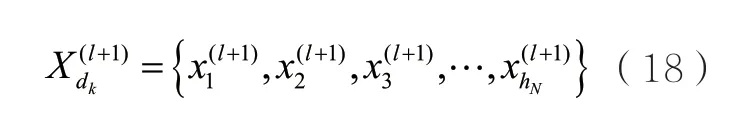
根据dk的案件要素特征集合形成其案件要素序列表示kdL。
3.3 文本语义表示
文本语义表示使用了TextCNN模型,该模型网络结构简单且能获得不同抽象层次的语义信息。TextCNN主要分为输入层、卷积层、池化层和全连接层。在卷积层进行特征向量计算时,设置不同尺寸的卷积核实现局部特征的捕捉,使得提取到的特征向量具有代表性。
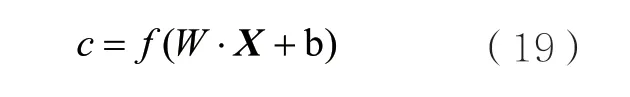
其中,W∈Rhm为滤波器尺寸,b是一个偏置常量,f是非线性函数。本文通过设置不同大小的滤波器得到dk的多个特征表示C= [c1,c2,…,cT-h+1]。为了获取有效特征,本文采用最大池化获得案情事实kd的文本语义表示kdC。该过程可以表示为:
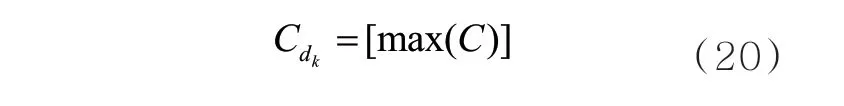
3.4 模型输出
图卷积神经网络擅于捕获全局信息,除了挖掘自身节点信息,还可以获取相邻节点关系蕴含在图结构中的其他信息。TextCNN可以较好地捕捉句子的局部信息,但在卷积池化操作中容易丢失文本序列信息。考虑到两个模型的特点,为了丰富案情事实表示,本文将案件要素序列表示kdL与文本语义表示kdC融合输入全连接层,以获取其最终表示p。该过程可形式化表示为:
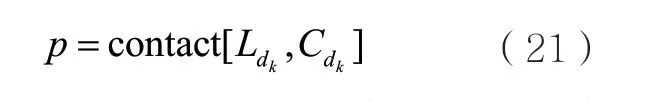
最后输出到Softmax层中预测出其类别z,该过程可形式化表示为:
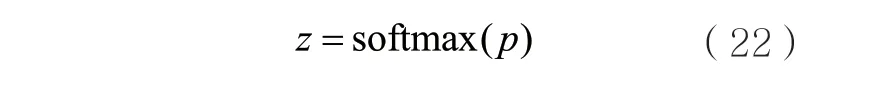
4 实验与分析
4.1 实验数据集
本文使用的案件要素数据集含有6类案件要素,共计46000个标签。罪名预测数据集来源于贵州省某人民法院的抢劫、抢夺、诈骗、敲诈勒索、危险驾驶和交通肇事6类案件。为了验证案件要素序列对罪名预测的效果,本文罪名预测数据集中的罪名均为单罪名。本文首先从6类案件中均匀抽取10000个案件作为实验原始数据;然后使用正则匹配方式提取案情事实部分,删除缺失、无效、重复的案情事实文本,修正乱码等情况,并对数据进行脱敏和清洗;最后将案情事实作为内容,其对应罪名作为标签,形成罪名预测数据集。该罪名预测数据集涉及6类罪名,共有8690个案情事实。其中,抢劫罪1544个、抢夺罪1546个、诈骗罪1656件、敲诈勒索罪725个、危险驾驶罪1547个、交通肇事罪1672个。
4.2 实验设置与评价指标
为了更好地体现模型实际表现,在保证标签分布均匀的情况下,本文将罪名预测数据集按照7:2:1的比例划分为训练集、测试集和验证集。
由于模型输入层需要输入一个定长的文本序列,而案情事实长度表达不固定,本文对数据集中的文本分布长度进行统计,发现超过90%的案情文本字符数量集中在区间[100,500],如图2所示。综合分析文本长度分布情况,本文将400个字符作为数据输入定长。
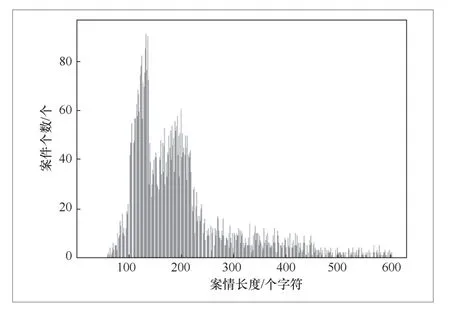
图2 数据集文本长度分布
本文采用机器学习算法中的常用评测指标(即精确率、召回率、综合评价指标(F1))对实验结果进行分析和评判。另外,宏平均(macro-average)和微平均(micro-average)也是衡量文本分类器的指标。宏平均是计算每一类别指标值的平均值,微平均是结合不同类别指标值的贡献来计算平均值。综合本文罪名预测数据集的类别和数量分布情况,本文实验结果均使用宏平均计算产生。
4.3 结果及分析
为了验证所提方法的有效性,本文设计了3组对比实验。实验一使用本文所提方法与SVM、TextRNN等模型进行对比;实验二是用于验证案件要素序列有效性的消融实验;实验三使用本文方法在易混淆罪名预测上进行实验分析。
(1)模型对比实验
为了验证结合案件要素序列的罪名预测方法的有效性,本文将所提方法与传统方法进行对比。TFIDF_SVM采用词频逆向文档频率(term frequencyinverse document frequency,TFIDF)进行文本特征抽取,再使用SVM进行分类。TextRNN采用双层长短期记忆(long short-term memory,LSTM)网络获取文本特征。采用单层神经网络结构的FastText对文本进行bi-gram和trigram特征提取。TextCNN采用多个不同尺寸的卷积和最大池化进行分类。本文实现了两个融合案件要素序列表示的模型,TextRNN_seq表示在TextRNN的基础上引入案件要素序列表示,TextCNN_seq表示在TextCNN的基础上引入案件要素序列表示。除了TFIDF_SVM模型,其余实验模型中的词嵌入维度均为400维。TextCNN的卷积核尺寸为(2,3,5)。
实验结果见表1,本文方法的实验性能明显优于传统方法。由于案情事实长度表达不固定,有些案情事实长度较长,TextRNN模型在选取最后一个时间步的向量表示时容易对前面的部分信息造成遗忘。FastText由于模型结构特点,容易造成文本结构信息丢失问题。而TextCNN模型能对文本的局部特征进行有效感知,在此类数据上表现优异。进一步地,本文将案件要素维度的案情事实表示与文本语义表示进行融合实验。实验结果表明,与传统方法相比,融合案件要素序列方法的实验结果均有一定提升,TextCNN_seq模型取得了最优效果。其主要原因是案件要素序列的加入能获取案件关键特征,结合TextCNN提取的文本语义特征,从多维度丰富案情事实表示,实现案情事实的深层分析。
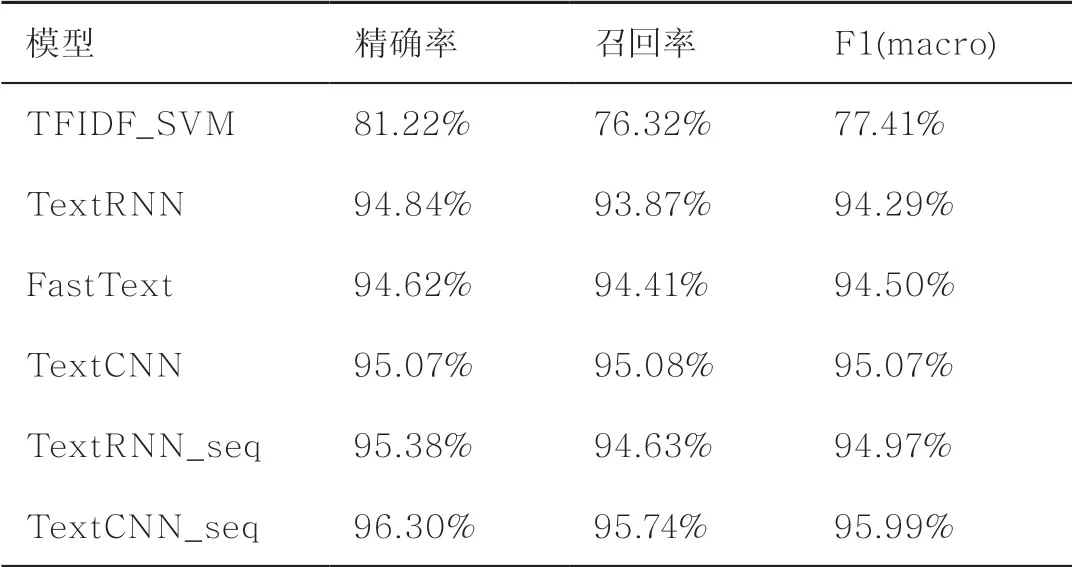
表1 罪名预测实验结果
(2)消融实验
本文对预测错误的案例数据进行输出分析,发现错误案例数据中普遍存在案情事实文本较短、案件行为要素较少的情况。为了验证行为要素的关键性,本文对案件要素序列的行为要素进行了消融实验。简单来说,在案件要素图构建过程中故意丢失全部行为要素后再进行实验,以达到实验目的。
为了充分表达行为要素对实验结果的影响,本文将行为要素作为控制变量共进行了3组不同的实验。第一组实验使用TextCNN,表示仅使用案情事实文本特征;第二组实验使用TextCNN_seq,表示在第一组实验的基础上融合了完整的案件要素序列;第三组实验使用TextCNN_seq_nopre,表示在第一组实验的基础上融合了缺失行为要素的案件要素序列。
实验结果见表2,TextCNN_seq相比,TextCNN_seq_nopre的性能下降明显。其主要原因是行为要素的缺失导致案件间重复要素急剧减少,在使用图卷积神经网络对案件要素序列建模学习时不能很好地聚合关联案件的特征,使得获取到的案情事实特征不具备足够的代表性。由此可见,行为要素的存在可以学习潜在关联信息,更好地获取案件关键特征。另外,TextCNN_seq_nopre的性能低于TextCNN。由此表明,大量非关键特征的加入使得特征变得稀疏,导致实验性能不佳。

表2 消融实验结果
(3)易混淆罪名预测实验
为了验证本文所提方法预测易混淆罪名的性能较好,本文选取了两组常见的易混淆罪名进行实验,即交通肇事罪和危险驾驶罪。
实验结果见表3,本文所提方法对易混淆罪名的预测性能有明显提升。实现结果表明,通过对案件要素的抽取,建模学习案件要素序列表示,在获取案件独有表示的同时使犯罪结果更加清晰,这对于易混淆罪名的区分具有积极意义,能提升易混淆罪名的预测性能。

表3 易混淆罪名实验结果
5 结束语
在当前的罪名预测研究中,主要使用文本内容或引入辅助信息进行预测,往往忽略了关键案件要素。针对此问题,本文将案件要素引入罪名预测任务,提出了一种结合案件要素序列的罪名预测方法,从案件要素和文本内容维度丰富案情事实表示,深度挖掘案情事实潜在语义结构。本文在单罪名情况下验证了所提方法的有效性,并凸显了案件要素序列的重要性。在下一步研究工作中,笔者将在多罪名情况下对所提方法进行探索验证。
