基于深度迁移学习的物联网入侵检测框架
2021-11-22张吕军
张吕军
(北京安帝科技有限公司,北京 100142)
0 引 言
近年来,物联网(IoT)设备的应用越来越广泛,IoT设备部署的最新统计信息如图1所示。其中,智能城市占28.6%;工业物联网占26.4%;电子医疗占22%;智能家居占15.4%;智能车辆占7.7%[1]。可以说,物联网设备在日常生活中具有越来越大的可用性和便利性。目前来看,大部分厂商都在积极部署其关键基础架构以帮助执行专业任务。

图1 物联网应用范围
物联网技术的应用已向用户证明了各种好处。但是,物联网设备仍存在许多漏洞,这些漏洞暴露于网络环境中是非常危险的。设备部署中各种物联网协议的复杂性也阻碍了物联网通用网络安全解决方案的发展[2]。例如,MQTT协议是物联网中普遍部署的应用程序协议,但是该协议本身存在多个漏洞,这些漏洞很容易受到如设备泄露、数据盗窃、节点盗窃、拒绝服务以及中间人(MiTM)攻击[3-4]。
本文提出了一种基于深度学习的网络流量分类的入侵检测系统的新颖设计。多分类器包括带有嵌入层的前馈神经网络模型,以识别四种攻击类别,即拒绝服务(DoS)、分布式拒绝服务(DDoS)、数据收集和数据盗窃,同时区分攻击的流量。另外,通过嵌入层编码的概念提取了高维分类特征的编码,然后基于迁移学习将其应用于二元分类器上。本文的贡献如下:
(1)基于深度学习和迁移学习的概念,设计用于物联网的入侵检测系统。
(2)根据原始网络流量处理和生成数据包级别的特征(即包头字段信息)。
(3)通过公开的数据集评估提出的二进制和多分类器,其中包括模拟的IoT跟踪和实际攻击流量。
1 基于深度迁移学习的物联网入侵检测框架
本文的方法分为5个步骤:数据收集、特征抽取、特征预处理、模型训练和测试/分类,如图2所示。

图2 基于深度迁移学习的物联网入侵检测框架图
1.1 数据收集
第一次迭代是收集原始网络流量。本文使用由Koroniotis等人开发的可公开获得的数据集(BoT-IoT数据集)[5]。需要使用数据集的原因有很多,包括部署实际的测试平台、生成模拟的IoT流量和实际的攻击流量以及插入标记的数据。
本文通过网络分析器工具(即tcpdump)以PCAP文件的格式收集了BoT-IoT数据集中的原始流量,并在收集流量时对其进行了标记;然后使用Argus工具生成了网络流量[6]。处理后的流量存储在Argus文件中,并进一步转换为CSV文件。
1.2 特征抽取
第二次迭代是检索数据包级别的标签,并从原始网络流量中的这些数据包中提取相关字段,每个字段都对应于一个特征。在这项工作中采用的特征是基于来自各个数据包的包头字段信息,而不是基于聚合数据包。本文使用TShark工具从收集的344个PCAP文件中提取单个数据包的包头字段,将其标记为数据包,并将其存储在CSV文件中。然后,本文将架构统一到CSV文件中,将文件转换为单个ApacheParquet文件,并选择大约2%的已处理数据集。下面解释每个步骤的细节。
特征描述:本文仅考虑了IP数据包,并从PCAP文件中提取了总共29个数据包包头字段。但是ARP数据包被排除在外,因为ARP用于将IP地址转换为MAC地址,与本文关注的攻击无关。
标签映射:本文使用数据集中的标签分析了网络流,并将相同的标签映射到这些网络流中的各个数据包。由于不同子类别的攻击流量是在不同的时间间隔执行的,而正常流量则是后台生成的,这使得区分攻击更加容易。此外,还部署了四台攻击机来发起攻击,这使本文能够根据攻击机的IP地址区分正常流量和攻击流量。因此,本文开发了一个脚本,用于根据攻击机的IP地址为每个攻击子类别标记数据包。本文将带有标签的数据包存储在CSV文件中,并将这些文件与具有不同攻击子类别的文件放在不同的文件夹中。
文件格式统一:本文统一使用CSV文件,并将文件转换为单个Parquet文件以减小文件大小并提高处理速度。本文将字符串类型转换为双精度等类型以保持一致性。
数据集提取:选择了大约2%具有提取特征的处理数据集(数据包总数为11 252 406)。对于正常流量,从所有正常数据包中选择2%。对于每个子类别的攻击流量,选择100万个数据包作为阈值。如果数据包数量低于阈值,则选择所有数据包;否则,将随机选择100万个数据包。
1.3 特征预处理
第三次迭代是通过删除和组合特征列以及对分类列特征编码进行字段信息提取,以将其输入到深度神经网络模型中。本文删除了五列,包括时间戳列(即frame.time_epoch)以及包含源IP地址(即ip.src/ipv6.src)和目标IP地址(即ip.dst/ipv6.dst)的列。本文观察到四对TCP/UDP相关列中的值在每对中彼此不重叠(即tcp.len和udp.length、tcp.stream和 udp.stream、tcp.srcport和 udp.srcport、tcp.dstportand和upd.dstport)。因此,本文将这四对列组合在一起,并将它们分别命名为length、stream、src.port和dst.port。对于每个具有逗号分隔值的列(即ip.ttl、ip.id、ip.hdr_len和ip.len),本文生成了一个新列,将逗号分隔值分为两列,并使用NaN值填充空白行在新列中。
本文在所有特征列中确定了分类特征列。对于具有低维分类变量的列(即ip.proto、tcp.flags、ip.flags.df和http.response.code),本文应用onehot编码并删除了原始列;将这些列和其他具有非分类值的列称为输入列。对于具有高维分类变量的列(即src.port、dst.port和http.request.method),本文将它们与其他列分离,并将在深度神经网络模型中用编码方式来计算端口和表示HTTP请求方法。
1.4 训练和测试
本文将预处理后的数据分为训练集和测试集,分别用于训练次迭代和测试次迭代。
训练次迭代从训练集中获取处理后的数据,并将其馈入前馈神经网络模型。既考虑了二分类又考虑了多分类。本文采用具有嵌入层的前馈神经网络模型进行多分类,其中除了正常流量类别外,一系列攻击类别还被视为单独的类别。然后,从嵌入层提取权重以对高维分类特征列进行编码,并构建第二个前馈神经网络模型以执行二分类。测试次迭代是评估指定测试集上的分类器。二元分类器为测试集中的每个数据实例输出正常或攻击标签,而多分类器则输出类标签(即它所属的常规或特定攻击类)。
2 深度学习模型设计
本文考虑使用前馈神经网络(FNN)模型,在这项工作中采用FNN的原因是它被认为是第一种也是最简单的人工神经网络。本文将多分类FNN模型表示为mFNN模型,将用于二分类的FNN模型表示为bFNN模型,并分别详细说明这两种模型以及迁移学习的概念[7]。
mFNN模型:使用三个数组作为输入,其中两个是嵌入层的输入。端口嵌入层的输入维数为65 537(所有正式和非官方端口的0和65 535~65 536之间的NaN值均已编码),输出维数为16;而HTTP请求方法嵌入层的输入维数为93(其中92种为正式请求方法,并且为无值编码的字符串),输出维数为4。两个嵌入层的权重都将通过模型训练来学习。全局平均池层应用于端口嵌入层,以计算源端口和目标端口的平均值。然后,将返回的向量与HTTP请求方法嵌入层和输入数组连接在一起。最后与全连接层连接。
迁移学习:通过在mFNN模型中的嵌入层来提取高维分类特征的编码,并将该编码应用于bFNN模型中相同的高维分类特征。将特征编码表示从mFNN模型迁移到bFNN模型是可行的,因为bFNN模型是在mFNN模型使用的数据子集上训练的,所以保证了编码的通用性。更重要的是,bFNN模型不需要通过添加嵌入层来对高维分类特征进行编码,因为它会增加训练时间并导致失去特征表示的通用性。具体而言,提取mFNN模型的两个嵌入层的权重并将其存储在两个数组中,以用作bFNN模型中的端口和HTTP请求方法的编码。
bFNN模型:使用mFNN模型中两个嵌入层的权重(存储为两个数组)对源/目标端口和HTTP请求方法(即src.port、dst.port和http.request.method)进行编码。然后,将已编码的列与其他特征列合并,并作为模型的输入。bFNN模型包括三个具有512个神经元的全连接层,并且在前两个全连接层(即输入层和隐藏层)中使用ReLU函数,在最后一个全连接层(即输出层)中使用两个神经元和一个Softmax函数。bFNN模型使用与mFNN模型相同的超参数(即隐藏的全连接层数量和隐藏的全连接层中的神经元数量)
3 深度学习模型调整
本文使用不同超参数和三种正则化技术对mFNN模型进行了调整。将相同的超参数和正则化优化用于bFNN模型,旨在将模型的泛化应用于不同的分类问题。本文使用的FNN模型由三个全连接层组成,前两个全连接层中具有512个神经元,默认的Adamoptimiser学习率(即0.001)作为基线模型[8]。使用512个神经元作为起点有两个原因:(1)提取的数据集已足够(具有9 163 751条记录),因此过拟合问题就不会发生(当神经网络具有处理能力但训练数据中包含的有限信息量不足以训练隐藏层中的所有神经元时,就会出现问题);(2)本文的深度神经网络是在GPU上训练的,可以以较高效率运行。
正则化:本文尝试了三种常用的正则化技术,分别是L1、L2和Dropout。结果表明,分类精度没有变化。已有研究证明,进行正则化可以有效避免过度拟合的风险。由于用于训练模型的数据集很大,因此过拟合问题并不是一个大问题[9]。
超参数调整:本文探索了神经网络的不同架构。具体来说,本文添加/减少了隐藏层(从2到4),减少了神经元的数量(128个或256个神经元),增加了神经元的数量(1 024个神经元,不包括最后一个全连接层),并添加了Dropout率为0.1的Dropout层(不包括最后一个全连接层)。结果表明,基线神经网络模型具有最佳性能。在基线模型的变体上,分类准确性不会提高。这可能是由于模型复杂度低/高引起的。如果模型复杂度太低,则该模型可能无法捕获类的变化;如果模型复杂度太高,则该模型可能会在类上产生过度拟合问题,并且需要更多时间进行训练。因此,在具有太低/太高复杂度的模型下,分类性能可能会变差。本文对Adam优化器的不同学习率(即0.01、0.001、0.000 1和0.000 01)进行了实验,并选择了0.000 1作为获得最高准确性的最优学习率。
4 实验验证
对于本文所有的实验,本文使用了带有TeslaV100GPU和93GRAM的高性能计算(HPC)集群以及TensorFlow库和Keras库。本文将提取的数据集划分如下:64%用于训练,16%用于验证(在调整模型超参数时提供对训练数据的模型拟合的无偏评估),20%以分层方式进行测试。由于训练数据中的类别不平衡,本文在训练期间对各类别应用了权重,针对代表性不足的类别(即数据包数量少)获得更高的权重值[10]。本文通过将类别中的数据包总数除以训练数据中的数据包总数,然后将商值取反来计算每个类别的权重,实验结果如图3所示。
图3中展示了mFNN模型在训练集(training)和验证集(validation)上的性能。采用了early stoping技术,让训练和验证过程在第15次迭代结束,进行了5次迭代以减少验证集损失Loss减低过拟合问题。训练损失从第1次迭代的0.042 6下降到第2次迭代的0.013 9,然后稳定下降直到第15次迭代;而第1次迭代的验证损失为0.009 3,然后在0.009到0.005之间波动。训练精度Accuracy起初从0.992 3提高到0.996 9,然后稳步提高直到第15次迭代;而验证集准确性在0.996和0.998之间略有变化。
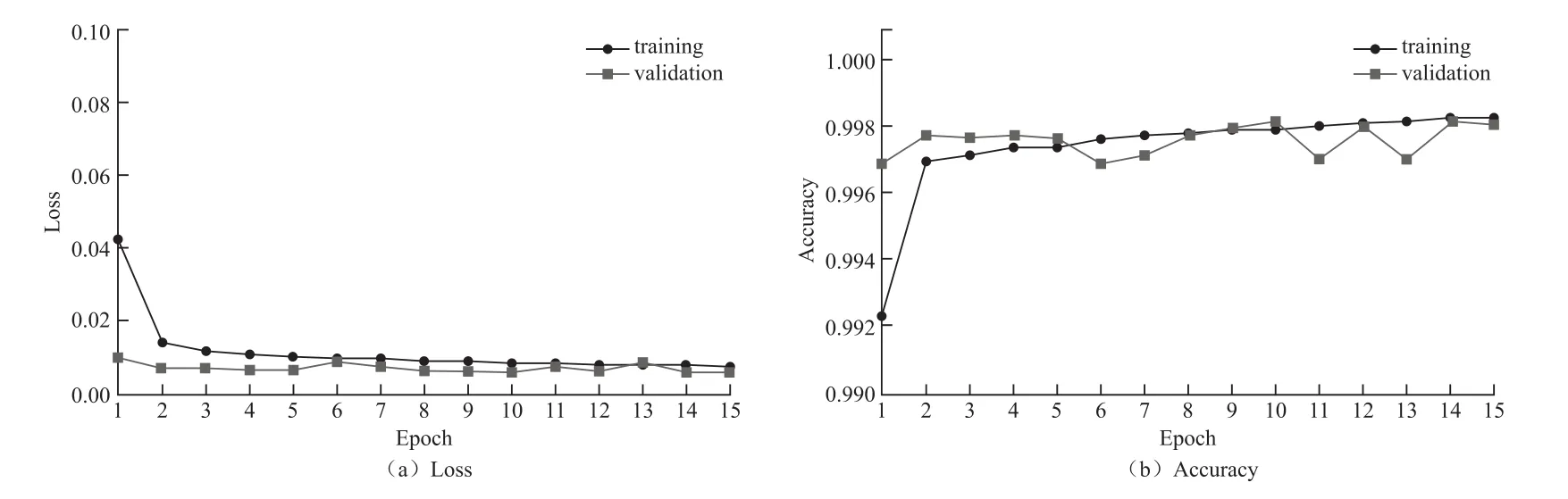
图3 多分类模型测试结果
如图4所示,二进制分类的评估指标采用了Accuracy、Recall、Precision和F1 score这4种。显而易见的是,其中所有值均高于0.999 9。bFNN模型可实现高Accuracy、Recall、Precision和F1 score(即99.99%),而只有少数数据包被错误分类。关于每个攻击子类别的分类所运行的时间,bFNN模型在5~10 min内完成了训练和验证任务。
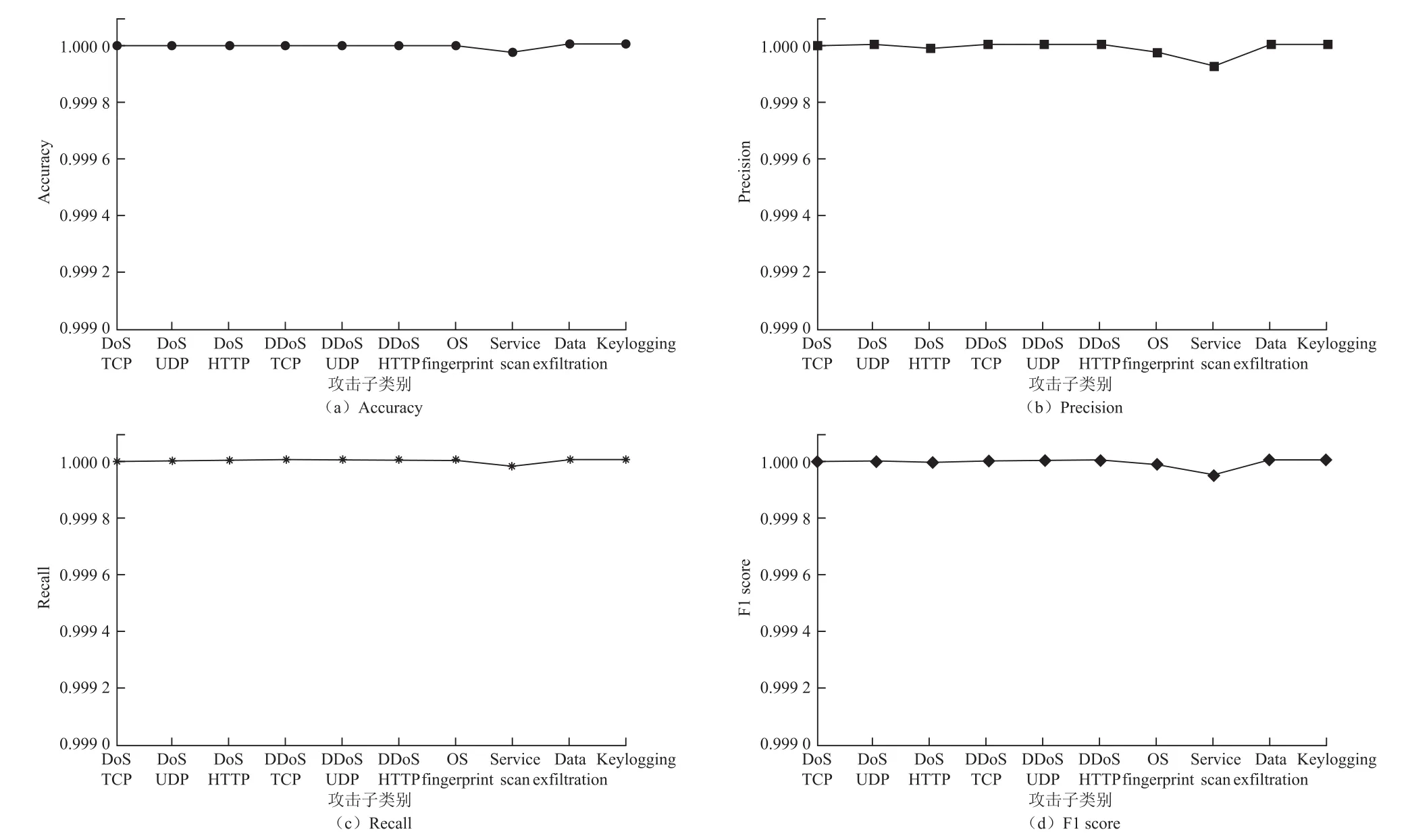
图4 二分类模型测试结果
5 结 语
深度学习技术已显示出它们能够在各种研究领域准确地进行模式识别的能力。在物联网应用中,此类技术可用于检测网络入侵。本文提出了一种针对物联网的网络入侵检测系统架构,该设计基于包括定制前馈神经网络的深度学习模型。本文将流量包头字段视为通用参数,并采用嵌入编码和迁移学习的概念对从数据集获取的数据的高维分类特征进行降维编码。本文已经在包含实际网络流量的数据集上测试了用于二进制和多分类的模型。获得的结果表明了所提出技术的有效性;特别地,发现对于二元分类器,检测精度接近99.99%,而对于多分类器,则达到了约99.79%。因此有必要据此对物联网网络入侵检测系统设计进行更深入的研究。
