一种基于一维卷积残差网的单通道信号源个数估计算法
2021-11-20朱炎民武欣嵘郑翔陈美均皮磊
朱炎民 武欣嵘 郑翔 陈美均 皮磊


DOI:10.16644/j.cnki.cn33-1094/tp.2021.11.008
摘 要: 单通道信号源个数估计是单通道盲源分离问题的前提与难点,传统方法无法直接进行估计且准确率较低。文章提出了一种基于深度网络分类器的单通道信号源估计方法。该方法将源个数估计作为分类问题,在经典CNN的基础上引入一维卷积网络与残差结构作为分类器,采用短时傅里叶变换和梅尔倒谱系数作为联合特征输入分类器。在Libricount数据集上的测试结果表明,该方法的源个数估计准确率明显优于基准模型。
關键词: 盲源分离; 单通道; 源个数估计; 卷积残差网; 分类器
中图分类号:TN912.3 文献标识码:A 文章编号:1006-8228(2021)11-30-04
Algorithm for estimating the number of single channel signal sources based on
one-dimensional residual convolution neural network
Zhu Yanmin, Wu Xinrong, Zheng Xiang, Chen Meijun, Pi Lei
(College of Communication Engineering, Army Engineering University of PLA, Nanjing, Jiangsu 210007, China)
Abstract: Estimation of the number of single channel signal sources is the premise and difficulty of single channel blind source separation. Traditional methods cannot estimate the number of single channel signal sources directly and the accuracy is low. In this paper, a single channel signal source estimation method based on deep network classifier is proposed. In this method, the number estimating of sources is taken as a classification problem. Based on the classical CNN, a one-dimensional convolutional network and residual structure are introduced as the classifier, and Short-Time Fourier Transform and Mel-frequency Cepstral Coefficients are used as the joint feature input classifier. The test results on Libricount dataset show that the accuracy of source number estimation of the proposed method is obviously better than that of the baseline model.
Key words: blind source separation; single channel; source number estimation; residual convolution neural network; classifier
0 引言
近年来,基于深度学习的单通道语音分离技术得到了广泛的关注与重视,逐渐成为语音分离领域的新热点。大多数情况下,基于深度学习的单通道分离模型需要知道信号源个数。而在现实中,通常无法获得混合中信号源个数,导致无法直接使用深度学习方法进行语音分离。因此,单通道混合信号源个数估计是进行语音分离的重要前提。
传统源信号估计方法大多基于阵列信号,根据阵列信号的到达角DOA与时延,采用聚类等方法得出源信号的个数。而单通道的语音信号源个数估计问题,一般通过EMD等算法先将单通道信号转化为虚拟阵列信号,再使用阵列信号个数估计方法进行估计[1-3],信噪比较低的情况下准确率较低。
鉴于深度学习方法在各种音频相关任务的成功应用,在信号源个数估计的研究中也逐渐引入深度学习方法,并且获得比传统方法好的效果。文献[5]将一维CNN引入源个数计数,得出深度模型的估计效果优于人类感知与传统方法。文献[6]将源个数估计作为基于RNN的分类或回归问题,使用一个三层BLSTM进行估计,准确率较高。文献[7]直接将时间信号作为输入特征,输入E2ECNN(End-to-End Convolutional Neural Network),实现端到端的源个数估计。文献[8]采用多种深度模型进行源个数估计,在估计准确率与MAE(Mean Absolute Error)方面相较于文献[6]有较大幅度的提高。
尽管基于深度学习的单通道信源个数估计相较传统方法准确率明显提高,但在以往研究中,使用的神经网络模型结构较为简单,输入特征较为单一。本文通过改变网络结构,将一维残差卷积网作为分类器应用于源个数估计,用一维卷积代替传统二维卷积,加快模型收敛速度,增加卷积层深度,尝试提高输入/输出的映射能力,并通过残差连接优化模型。该方法比以前的研究有更高的分类准确率,且缩短了训练时间。同时,研究了不同特征对模型源估计效果的影响,采用联合特征输入,进一步提升了模型对信号的源个数的估计准确率。
1 相关工作
1.1 问题描述
单通道信源数估计问题是指从1个混合信号中估计出源信号的个数。如式⑴所示,在给定混合信号[Y(t)]的情况下估计出[Y(t)]中的源信号个数S,[X(t)]指源信号。
在混合信号[Y(t)]中,每个源信号活跃的时间不同,模型要估计的源数目指在混合信号中存在过的源信号的最大数目。假设用[Vi,t]来表示第i个源信号在时间t的状态,1表示活跃,0表示不活跃。在时刻t同时活跃的源信号个数[Nt]可由[Vi,t]得出:
其中L表示源信号的总数,将[Vit]相加即得到时刻t上的说话者个数[Nt]。在时间轴上遍历,取最大值就可得到整个信号中最大的说话者个数S,即信号源个数。
其中T表示混合信号的时间长度,S为估计的信号源个数。本文中设定的L默认与S相等,不存在L=2的情况下信号不混叠导致计算出的S=1。
从混合信号[Y(t)]估计得到源个数S,此任务可以表述为分类问题,每个类别对应一个信号源数量。本文将源个数S的估计作为基于神经网络的混合信号多分类任务,以1DRCNN作为特征提取与分类器,完成从混合信号[Y(t)]到源个数S的映射。
1.2 基准模型
本文将文献[7]中的E2ECNN模型作为基准模型,与本文提出的模型作对比。E2ECNN模型直接从原始波形中提取特征,实现端到端的信号源计数,E2ECNN在一个卷积池化层后堆叠三个连续的卷积模块,每个卷积模块包含三对二维卷积层与池化层,后连批次归一化层与dropout层,最后依次连接三个全连接层与dropout层。尽管基准E2ECNN模型在信号源计数任务上产生了良好的性能,但是模型结构只是简单的堆叠CNN,模型的性能还有提高的空间。因此本文使用残差网优化模型结构,同时加深网络深度,提出一维卷积残差网(One-dimensional Residual Convolutional NeuralNetwork,1DRCNN)作为网络主体对源信号个数进行估计。
2 算法描述
2.1 本文模型
残差网(Residual Network,Resnet)于2015年被提出[10],用以解决由于网络结构过深而导致的模型性能下降问题。残差网通过跳跃连接实现恒等映射,如图1(a)所示。残差网的学习目标不再是完整的输出,而是所谓的残差,最后的训练目标也就是将残差结果逼近于0,将前一层输出传到后面,增加了网络深度的同时不提升误差,保证模型不因为堆叠而产生退化。
1DRCNN借鉴了Resnet的结构,在1DCNN的多个卷积块提取特征的基础上,引入Resnet的跳跃连接构建残差单元。将一维残差单元堆叠连接,在加深模型深度同時利用残差网结构减少因深度加深带来的梯度消失等影响,提高模型提取特征能力。
残差单元结构如图1(a)所示,每个残差单元内包含三个卷积层后接批次归一化层,size=7表示一维卷积核长度为7,stride=1表示步长为1,BN为Batch Normalization。残差单元使用核长度为1,步长为3的卷积层完成跳跃连接。1DRCNN结构如图1(b)所示,包含四个残差单元作为神经网络主体提取特征,残差单元内Conv [3,1,128]表示卷积核长度为3,步长为1,通道数为128,padding=same表示进行填充。最后连接平均池化层,在平均池化层后加入dropout层,预防模型过拟合,全连接层与softmax层作为分类输出。
本文提出的1DRCNN,相较于E2ECNN有以下几点改进。
⑴ 网络层数更深,1DRCNN能够挖掘信号更深层的特征,发现不同信号的联系与差别,提高信号与源个数估计的映射能力,提高模型的分类效果。
⑵ 使用一维卷积代替二维卷积,采用一维卷积更适用于序列数据,同时能减少模型参数,分类效果更好的同时使模型训练时间更短。
⑶ 使用残差结构,1DRCNN采用11层网络结构,残差结构使其在深度较深时能保持良好的性能,提高模型性能。
⑷ 使用批归一化算法,在每个残差单元内接批次归一化,同时最后使用全局平均池化减少参数,避免模型出现过拟合的情况。
2.2 数据集与特征选择
本文选用LibriSpeechdev-clean数据集中的Libricount数据集。LibriSpeech数据集是一个开源的自动语音识别的朗读英文数据集,采样率为16kHz。本文选择Libricount数据集,该数据集包括10类数据,包括1至10个源信号的混合语音共5720条,每类数据572个样本,样本长度固定为5秒,训练时80%的数据用于训练,20%的数据用于测试。
本文选取不同特征作为神经网络输入,包括短时傅里叶变换、Fbank及梅尔倒谱系数。短时傅里叶变换(Short-Time Fourier Transform,STFT),即通过短时傅里叶变换后取幅度谱; Fbank(Filter Bank)是指经过梅尔滤波器组后提取到的特征,高度相关,本文中Fbank特征包括40维滤波器组特征及动态一阶与二阶差分特征;梅尔倒谱系数(Mel-frequency Cepstral Coefficients,MFCC)在Fbank的基础上使用DCT变换得到,具有高度的判别性,本文中MFCC为40维滤波器特征及动态一阶与二阶差分特征。
2.3 训练过程
以一个样本为例进行说明。输入混合信号长度为5s,采样率为16kHz,输入为80000*1,经过1024点fft,512点帧移的短时傅里叶变换后,变换成313*507的频谱图作为神经网络的输入。初始学习率设为0.0001,使用Adam优化器,batchsize为32,损失函数为正则化后的交叉熵函数,以减少过拟合的几率。所有的模型通过150轮训练后得出结果,取在测试集上取得最高准确率的模型,用于模型性能评估,训练过程可视化结果由tensorboard得到。
3 仿真实验
3.1 不同输入特征下模型效果对比
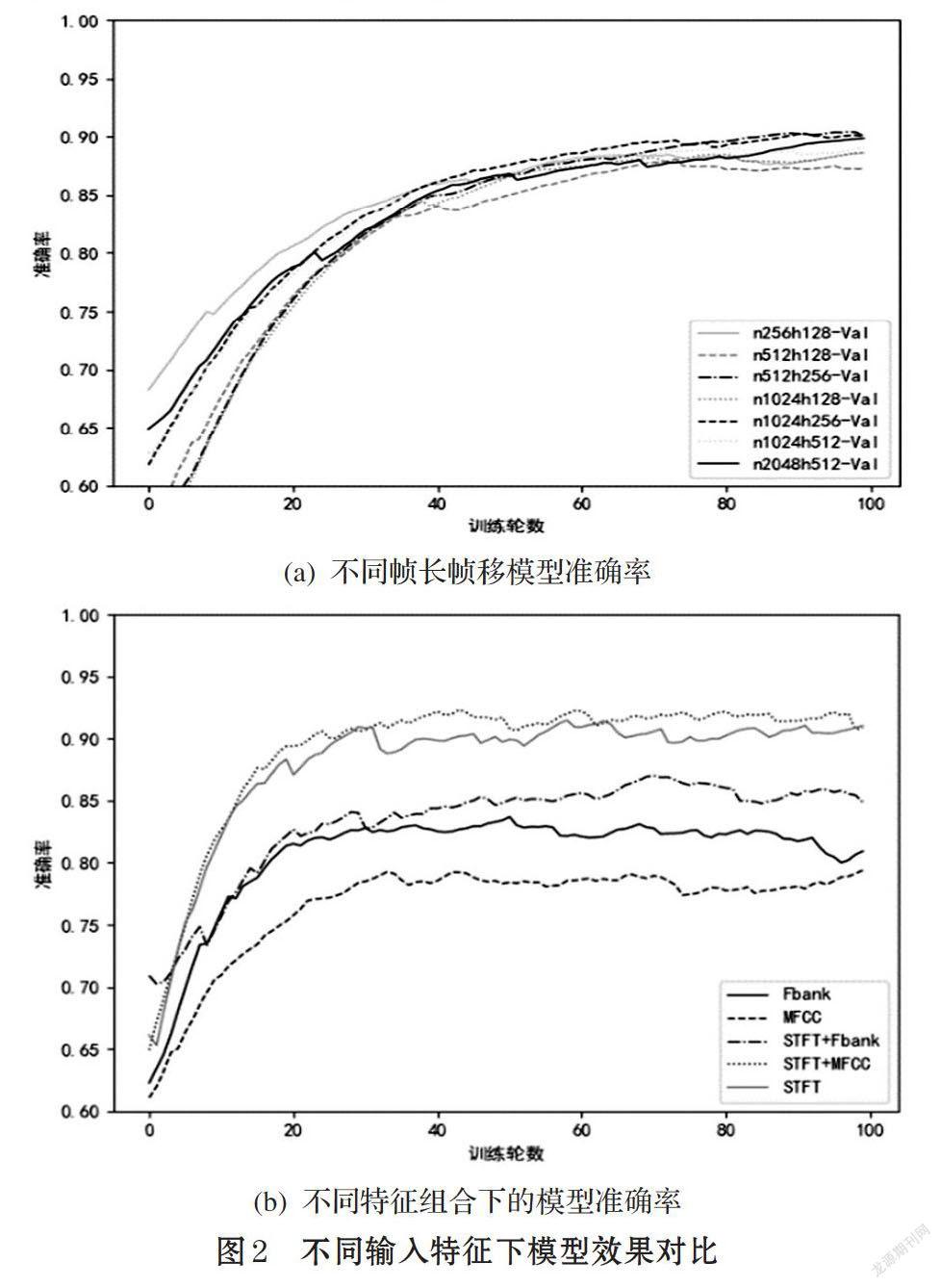
本文从输入特征的两个不同角度对模型效果的影响进行了讨论,一是以不同帧长与帧移提取时频特征,二是将不同特征组合输入,观察实验效果后选择最佳特征作为本文模型输入。
图2(a)为不同帧长与帧移的输入特征下的模型表现。实验中分别选择了fft点数为256、512、1024、2048以及帧移为1/2、1/4、1/8的情况,fft点数默认等于窗口长度。由图2(a)可知,在帧长方面, fft点数为1024(时间64ms)的模型准确率较高。在帧移方面,1/4的帧移在保证帧之间关联度的同时也不会使冗余度太高,实验中准确率较高。在本文的实验中,不同帧长与帧移的输入特征所得到的模型效果相差4%左右,本文选用帧长1024点,帧移256点以提取时频特征。
图2(b)是将STFT,Fbank,MFCC及联合作为输入特征的模型表现,STFT+MFCC特征效果最佳,STFT特征次之,STFT+Fbank特征比STFT特征效果最差,表明Fbank特征中的某些特征与STFT联合时对模型的判断产生了负面的影响。STFT+MFCC准确率最高达到92%,较最低的MFCC准确率80%效果提升明显。所以本文选择使用STFT与MFCC的联合特征作为模型特征输入,以得到最好的实验效果。
3.2 1DRCNN与E2ECNN实验效果对比
图3给出1DRCNN与的E2ECNN的效果图比较,本文在两个模型上分别训练了9个分类器,对应估计2至10个语音信号混合的源个数。图3(a)给出了本文模型与基准模型在5分类器训练过程准确率的比较,即该模型能估计源个数小于等于5的混合信号;图3(b)比较每个分类器在源个数估计上的准确率,数据由每个分类器三次实验数据平均后得到,偶然性较低。
从图3(a)中可以看出在5分类模型中,本文的一维卷积残差网络在验证集最高能达到93%的准确率,而基准模型只能达到最高87%的準确率。从图3(b)中可以看出在九个分类模型中,本文提出的1DRCNN模型的准确率都高于基准E2ECNN,证明了1DRCNN作为分类模型的有效性。
在1DRCNN与E2ECNN模型中,2类与3类分类器的准确率都很高,原因在于混合信号个数较少,1DRCNN与E2ECNN的复杂度足以支撑作为2类与3类分类器,但作为4,5,6,7类模型的1DRCNN的准确率都是高于E2ECNN,原因在于1DRCNN深度更深,残差网学习的残差则简化了学习过程,增强了梯度传播,网络的泛化能力也更强。到了8,9,10分类器后,1DRCNN也出现了效果的下降,这是因为信号个数过多的情况下,所用数据集每类信号的数据量过少,或是模型深度复杂度不高。
4 结论
本文提出一种基于1DRCNN的单通道源信号个数估计的方法,该方法引入残差结构与一维卷积网改进网络结构,选用短时傅里叶变换和梅尔倒谱系数作为联合特征输入,在Libricount数据集上与E2ECNN方法进行比较,结果证明本文模型优于基准模型。在混合信号个数小于等于7时,本文模型具有较好的效果,精度最高可提高8%以上;当信号数量大于8时准确率有所下降,但仍高于E2ECNN方法。
参考文献(References):
[1] 胡君朋,黄芝平,刘纯武等.基于EMD的单通道信源数估计方法[J].计算机测量与控制,2015.23(12):4139-4140
[2] 刘邦,肖涵,易灿灿.基于核函数的二阶盲辨识的单通道信号盲分离方法研究[J].机械强度,2018.40(5):1043-1049
[3] 张纯,杨俊安,叶丰.高斯色噪声背景下的单通道信源数目估计算法[J].信号处理,2012.28(7):994-999
[4] A Hannun?, C Case, Casper J, et al. Deep Speech: Scalingup end-to-end speech recognition[J].Computer Science,2014.
[5] Stoter F R, Chakrabarty S, Edler B, et al. Classification vs.Regression in Supervised Learning for Single Channel Speaker Count Estimation[C]// ICASSP 2018-2018 IEEE International Conference on Acoustics,Speech and Signal Processing (ICASSP). IEEE,2018.
[6] Andrei V, Cucu H, Burileanu C. Overlapped Speech Detection and Competing Speaker Counting-Humans Versus Deep Learning[J]. Selected Topics in Signal Processing, IEEE Journal of,2019.
[7] Zhang W, Sun M, Wang L, et al. End-to-End Overlapped Speech Detection and Speaker Counting with Raw Waveform[C]// ASRU,2019.
[8] Stoter F R, Chakrabarty S, Edler B, et al. CountNet:Estimating the Number of Concurrent Speakers Using Supervised Learning[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing,2018.99:1-1
[9] Wang W, Seraj F, NMeratnia, et al. Speaker Counting Model based on Transfer Learning from SincNet Bottleneck Layer[C]//2020 IEEE International Conference on Pervasive Computing and Communications (PerCom). IEEE,2020.
[10] Bai S, Kolter J Z, Koltun V. Convolutional Sequence Modeling Revisited,2018.
