汽车备件算法平台构建
2021-11-19中汽数据天津有限公司任女尔张聪聪徐洋魏金津
中汽数据(天津)有限公司 任女尔 张聪聪 徐洋 魏金津
车企IT系统在多年运行中积累了大量数据,主要存储在Hive中。对这些数据进行清洗和标准化处理得到建立算法模型所需的训练数据,综合运用统计学分析、多因素分析,对不同层级、不同种类的汽车备件建立需求预测模型,以增强备件销售和采购计划科学预测的能力,降低仓储成本,提升客户满意度。基于Springcloud Alibaba微服务技术建立高并发、高可用的软件系统为需求预测模型的训练、执行、管理提供可靠的运行环境。
0 概述
随着中国汽车市场的快速发展和日渐成熟,售后服务与备件业务在车企中的战略重要性不断提升。车企已有的汽车备件系统在多年运行中积累了备件的需求、库存、订单、整车实销、质量等大数据[1]。车企希望结合这些大数据,运用多种算法模型,建立统一的算法平台去预测备件:根据历史需求、保有量,最优预测模型等去预测备件使用量;根据库存宽度、深度等去预测哪些备件需要存货,存多少;根据补货、采购数据预测哪里有过量库存、短缺,计划建议……算法平台可以增强备件销售和采购计划科学预测的能力,提升备件保供满足率和降低仓储成本,提高存货周转次数,提升客户满意度。
算法平台的主要任务:(1)建立预测模型,以满足备件系统对备件预测、库存计划、采购计划、最优采购等的需求;(2)建立软件系统为这些预测模型的训练与执行提供环境,形成算法相关应用的基础技术平台。车企希望在指定的计算周期(周、月)通过训练更新预测模型以反映最新的大数据变化,由于每种零备件的品牌、经销商数量巨大,这样一个计算周期的备件预测任务数会在150万以上,因此算法平台需要能够应对这么多任务的并发请求。同时,算法平台需要具备高可用性,与备件系统通信过程需要保证安全,还需具备前瞻性,能够适应于备件系统后续升级其他算法模型,比如深度学习等模型[2]。
算法平台包括数据处理、算法模型搭建、模型算法训练执行、算法服务等功能模块。数据处理模块主要功能包括数据准备、清洗;模型算法训练执行模块主要功能包括特征工程、算法选择、模型编排调试、模型评估、算法执行;模型算法服务模块主要功能包括模型上线发布、模型管理、模型监控。
1 系统结构
1.1 功能逻辑架构图
功能逻辑架构图1所示:
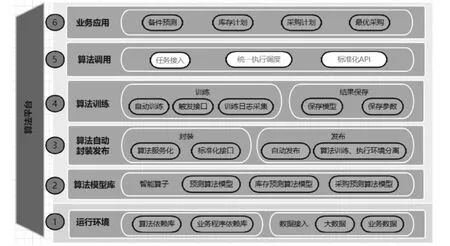
图1 功能逻辑架构图Fig.1 Functional logic architecture diagram
1.2 模块说明
算法平台服务于备件系统,系统间通过统一标准化的API或消息队列进行调用。包括数据处理、算法模型搭建、算法训练与执行、算法服务几个子模块。
1.2.1 数据处理
算法平台以“从数据开始,由判断结束”基本原则为参照,所以首先就是要为后面的算法模型训练准备训练数据。选取能反映真实需求的模型数据源,备件系统数据主要是存在Hive中[3],另外还有在、离线的csv、xls、sql脚本数据等,使用ETL工具将这些数据进行清洗和标准化处理,存入Oracle数据库;然后要考虑数据质量,确定不同数据质量下备件可预测范围;再搭建预测模型,通过挖掘历史数据识别出对备件销售贡献较大的影响因素,这些因素量化为多种特征作为预测模型的输入参数,丰富预测模型维度,提高预测的准确性。
1.2.2 算法模型搭建
针对中心仓、配送中心、经销商角色主体,综合运用统计学分析、多因素分析,对不同层级、不同种类的备件构建需求预测模型。利用统计学计算方法对备件销量的历史数据进行分析和预测,从而建立单因素预测模型,以进行备件需求预测。在单因素模型基础上,加入更多因素提高预测精度,合理优化模型结构和参数调优,建立动态的多因素预测模型。然后基于大量数据拟合、备件属性分类,推荐最优模型。采用滚动预测,用预测值和实际需求的误差来检验所有预测模型的适用性,系统自动对模型各类参数进行调整,人工定期进行模型及算法优化,更新模型版本。
1.2.3 算法模型训练与执行
在前面准备好训练模型和训练数据后,为算法平台提供:(1)算法的运行环境:包括算法依赖库、业务程序依赖库,大数据接入,为算法模型的训练与执行提供可靠的环境;(2)算法模型库:包括预测算法模型,库存、采购预测算法模型;(3)算法模型训练:包括算法自动训练、提供触发接口,训练日志采集,训练结果模型与参数保存;(4)算法模型执行:通过消息队列与Rest Api与业务系统交互,执行算法。
1.2.4 算法服务
提供算法模型发布:包括模型参数配置、算法服务化、标准化接口,算法自动分发等功能。对算法模型进行管理,配置算法平台权限,管理算法执行日志等功能。
1.3 系统架构
基于Springcloud Alibaba的微服务架构[4]。系统分为:(1)微服务基础模块:API网关、权限认证中心、服务注册中心、流量控制模块;(2)业务模块:算法管理模块、算法执行器、业务系统适配模块、算法训练模块,以及ELK日志平台。
算法平台使用微服务架构,对各个业务模块进行划分,可以做到模块之间松耦合且能够应对高并发的场景,便于根据业务的发展快速的升级和修改系统。包括算法发布、算法执行、算法训练以及日志管理、系统管理等微服务模块。算法平台与备件系统之间通过Kafka消息队列交互,算法平台各微服务之间除了通过Rest API也可通过Kafka消息队列交互。微服务架构图2所示:
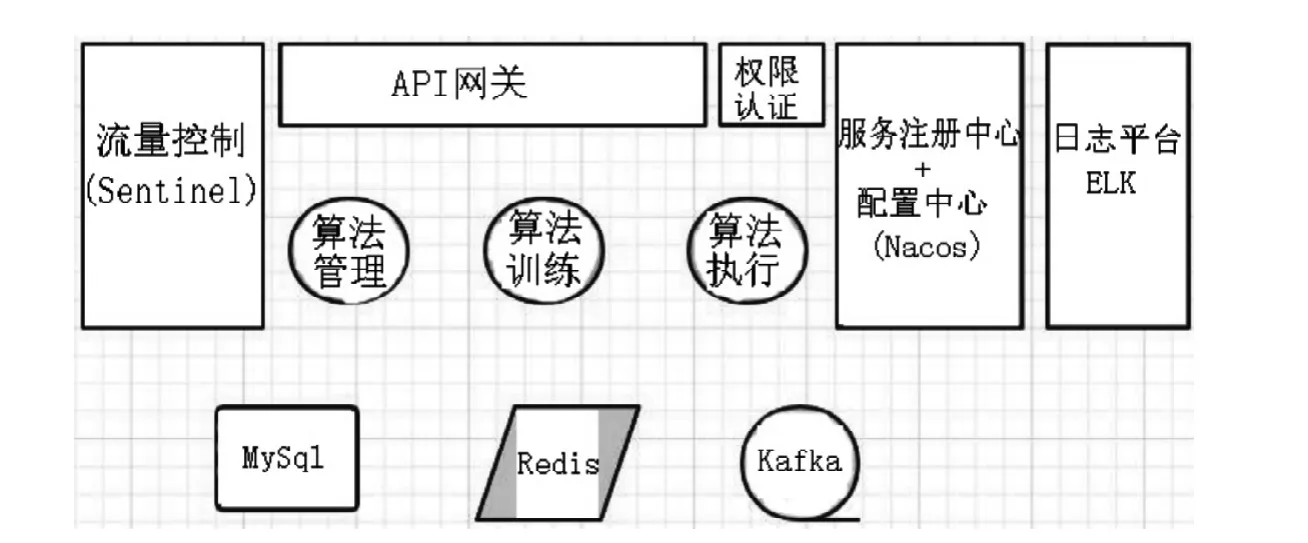
图2 微服务架构图Fig.2 Microservice architecture
2 关键技术
2.1 微服务
微服务是一种软件开发技术,将应用程序构造为一组松散耦合的服务。在微服务体系结构中,服务是细粒度的,协议是轻量级的。微服务架构是一种云原生架构方法,其中单个应用程序由许多松散耦合且可独立部署的较小组件或服务组成。这些服务通常有自己的堆栈,包括数据库和数据模型。通过Rest API,事件流和消息代理的组合相互通信。Spring Cloud是开源微服务解决方案,Springcloud Alibaba是阿里巴巴融合Spring Cloud体系和阿里巴巴中间件的微服务解决方案,具有完善的可视化界面,配置简单,开发运维便利,算法平台中的算法执行器部分,因为要应对大量的预测任务执行,因此需要一个可靠的负载均衡策略。使用Springcloud Alibaba微服务技术可以有效的解决这个问题。
2.2 Kafka消息队列
Kafka是一个分布式的消息系统,采用传统的Pull模式。Pull模式的好处是Consumer可以自主决定是否批量的从Broker拉取数据。Pull模式下,Consumer可以根据自己的消费能力去决定这些策略。在算法平台中,备件系统在做预测的时候,会生成百万级别的任务,如果很快的把任务发送给算法平台,算法平台的算力不足以支撑该压力。在使用了Kafka小时服务器之后,可以使用Pull模式拉取任务消息,做到削峰填谷。缓解算法平台的极限压力。
2.3 MinIO
算法平台对每个备件进行训练会生成相应的算法模型,如果有150万个备件,其产生的算法模型数据量是相当大的。MinIO是一个开源的对象存储服务系统,海量、安全、高可靠、低成本,非常适合于存储如图片、视频等大容量非结构化数据。读写性能高,支持分布式集群部署,容量可以弹性扩展,不会随着数据量的增加产生瓶颈。MinIO提供了一个无需单独部署随服务器一起启动的可视化UI界面,对于JavaScript,Java等多种语言提供SDK支持,和算法平台集成调用也很方便。所以我们选择MinIO去存储这些算法模型文件。
2.4 算法集群
使用MinIO分布式集群系统实现算法模型的分发,保证算法的一致性。算法执行器使用服务注册中心实现服务的注册发现。
3 流程说明
3.1 算法发布流程
用户上传算法模型到算法平台并设定算法模型参数及算法与业务数据的关联关系,系统将算法模型保存到minIO集群,算法信息存储到关系型数据库。算法平台提供统一的算法基础属性、参数、数据字段查询接口。
3.2 算法训练流程
算法模型在设计开发过程中需要使用大量的数据进行训练才能得到适合的场景和参数,人工训练工作量太大。所以需要建立自动训练能力,定时或手动触发训练任务。训练任务触发后,算法执行器读取备件相关业务数据,调用算法训练的Python脚本,脚本从Hive中读取训练数据,将训练好的新模型保存到minIO集群以便执行过程中调用,训练结果数据写入关系型数据库。算法训练流程图3所示:
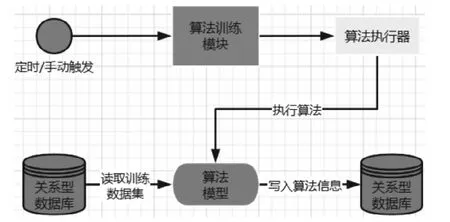
图3 算法训练流程Fig.3 Algorithm training process
3.3 算法执行流程
备件系统从算法平台获取算法信息,根据返回的算法信息封装备件预测任务消息发送到Kafka消息队列,消息包括需要调用的算法名称、参数与业务数据。算法调度模块收到消息后解析,根据解析后的消息调用算法执行器执行相应的Python脚本。算法平台通过分布式算法执行器将算力分配在不同的服务器上,在执行任务的时候通过使用服务注册中心来完成任务的负载均衡。算法执行流程图4所示:
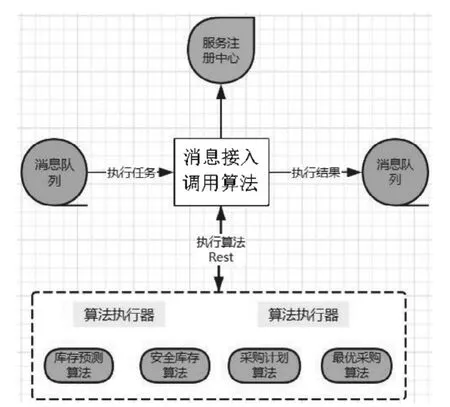
图4 算法执行流程Fig.4 Algorithm execution process
3.4 算法调用流程
算法平台具备算法模型管理的能力。备件系统通过统一的API获取算法调用的信息,然后根据算法描述自动生成算法任务,驱动算法平台执行。
4 结语
从车企大数据里挖掘价值以提高企业效益是建立算法平台的目的。构建算法平台一要建立算法预测模型,通过高质量的数据去训练算法模型;二要为算法模型的训练、执行、管理提供可靠的运行环境。算法平台各模块采用松散耦合的设计,基于Springcloud Alibaba微服务技术架构,可以应对高并发场景以及增强未来系统对新功能的扩展性。由于预测任务数会有百万级别,使用Kafka消息队列可以极大缓解算法平台执行压力。
引用
[1] 金善东,罗琼.ABC分析法在汽车备件订货系统的应用[J].商业故事,2018(3):50.
[2] 李志强,田有,赵鹏飞,等.基于深度学习的接收函数自动挑选方法[J].地球物理学报,2021(5):1632-1642.
[3] 曹建华,徐晨敏,郭昱含.Hive和Kafka在数据稽核和同步中的应用[J].中国新通信,2021(6):95-97.
[4] 李月晴,范纯超,张元生.基于微服务架构的生产管控平台研究[J].金属矿山,2021(2):173-178.
