基于深度残差网络和注意力机制的人脸检测算法
2021-11-18陶施帆李玉峰黄煜峰蓝晓宇
陶施帆,李玉峰,黄煜峰,蓝晓宇
(沈阳航空航天大学电子信息工程学院,沈阳 110136)
0 概述
随着图像处理技术的迅速发展,人脸检测逐渐应用到人们日常生活的各个方面,如刷脸支付、刷脸乘车等。然而在特定场景中,在面部受到遮挡、或是人脸比较密集等情况下,检测成功概率将会大幅下降。因此,如何在信息不完整的特殊情况下实现高效、精准的人脸检测是一个亟需解决的问题。特别是随着国内防疫工作常态化,在部分复工复学的学校及企业中,利用人脸检测技术对出入人员进行身份核验能够有效提高工作效率。因此,研究提高戴口罩人员的检测概率是一个重要的研究课题[1]。
近年来,随着深度学习技术的快速发展,在目标检测算法的基础上涌现出了大量人脸检测的智能算法。在人脸检测方面,DDFD(Deep Dense Face Detector)[2]是一种基于AlexNet 进行微 调改进的深度学习网络模型,该模型不需要姿态或者关键点标注,能够用一个单一的模型抓取各个方向上的人脸,对各种姿势有很强的抵抗能力,但偏转角度、姿势的变换越大,准确度就会越低。CascadeCNN[3]是对经典的Viola-Jones[4]方法的深度卷积网络实现,构建一种级联结构来检测从粗糙到精细的面部特征。Face R-CNN[5]基于Faster R-CNN[6]框架进行人脸检测,在原有的R-CNN 结构中加入了中心损失函数,在训练阶段将图片经过不同尺度缩放,可以更好地检测小尺寸图片。UnitBox[7]提出一个新的交并比(Intersection over Union,IoU)损失函数,代替常用的L2 损失函数,提高了人脸检测精度。虽然人脸检测技术已经取得了极大进步,但是对有遮挡的人脸进行检测效果仍不尽如人意,因为没有关于遮挡部分的先验知识,遮挡部分可以在面部图像的任何位置,或者可以是任何大小或形状。在智能算法方面,视觉注意模型可以有效理解图像,在计算机视觉任务中的应用非常成功。SANGHYUN 等[8]提出轻量级卷积块注意模块(CBAM)用于对象识别。PENG 等[9]提出一种用于细粒度图像分类的对象部分注意模型(OPAM),该模型结合注意力机制和残差网络模块,成功应用于细粒度图像分类,并具有较好的性能,然而在有遮挡的人脸检测领域尚缺乏相关研究。
为解决密集人脸检测精度低的问题,本文提出一种基于深度残差网络和注意力机制的算法模型。该模型包括算法模型修改、引入注意力机制及非极大值抑制(NMS)技术3 个方面。利用2 个完全卷积层的分支去分别预测像素级边界框及置信分数,同时引入IoU 损失函数优化网络,提高人脸检测的精度。在深度残差网络中通过注意力机制提升算法对复杂场景的理解能力,减少遮挡和密集等无用信息的干扰,实现对人脸有效目标信息的准确提取。最终在检测过程中利用非极大值抑制[10]技术,克服因人脸目标密集或重叠导致的误检和漏检,以提高算法的性能。
1 相关工作
1.1 残差网络
在传统卷积神经网络中,多层特征随着网络层数的叠加而更加丰富,因此网络层数越深,意味着图像处理的效果越好。但是简单的叠加网络会导致梯度消失问题,阻碍模型的收敛。初始化和正则化可以保证几十层的网络能够正常收敛,然而在更深层次的网络中,准确率达到饱和后效果反而变差。
针对上述情况,ResNet 引入了残差学习来解决深度网络难以优化的问题,其模块结构如图1 所示。令表示最 优的映射,使用堆叠的非线性层去拟合另一个映射此时最优映射可以表示为残差映射在前馈网络中增加快捷连接,执行简单的恒等映射,这样不会增加额外参数和计算复杂度,比原有映射更易优化。
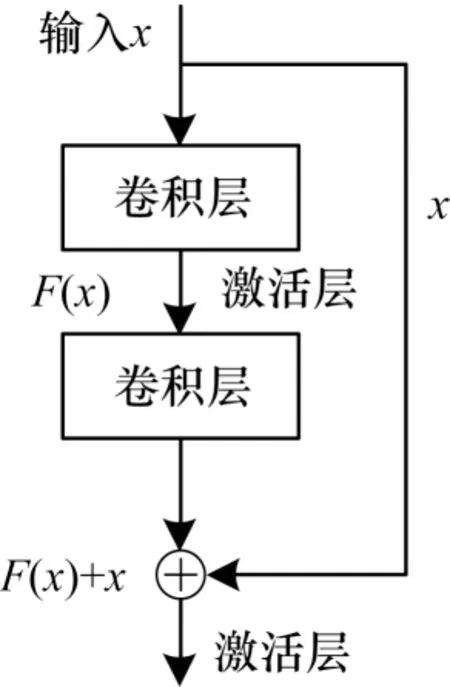
图1 残差网络结构Fig.1 Residual network structure
普通直连的卷积神经网络和ResNet 的最大区别在于:ResNet 有旁路的支线将输入直接连到后面的层,使得后面的层直接学习残差,这种结构也被称为直连或跳跃式传递。传统的卷积层或全连接层在信息传递时,或多或少会存在信息丢失、损耗等问题。ResNet 在某种程度上解决了这个问题,通过直接将输入信息传到输出,保护信息的完整性,整个网络只需要学习输入、输出差别即可,简化了学习目标和难度。
1.2 IoU 损失函数
对于图像中的每个像素(i,j),真实值的边界框可以定义为一个4 维向量,xt、xb、xl、xr分别表示当前像素位置(i,j)与真实值的上下边界之间的距离,为计算简便省略了注释i、j。因此,将预测的边界框定义为如图2 所示。

图2 IoU 损失函数原理Fig.2 The IoU loss function principle
IoU 为预测框与真实框的交并比,IoU 损失函数如式(1)所示:

其中:Prediction 表示预测值;Ground truth 表示真实值;Intersection 表示交集;Union 表示并集。
1.3 注意力机制
目前图像处理最常用的注意力机制为通道注意力机制[11]和空间注意力机制[12]。
1)通道注意力机制
通道注意力机制更关注图像输入的通道的信息,通过对通道信息的特征提取来提取特征分类上的精度[13]。通道注意力模块首先对输入的特征图分别进行最大池化和平均池化进行空间维度压缩,其中,C表示输入特征图的通道数,H和W表示特征图的长和宽。然后通过共享多层感知器(Multi-Layer Perceptron,MLP)计算通道注意力图。最后使用激活函数sigmoid 进行输出,得到通道注意力特征图Mc(F)=其网络结构如图3 所示,计算公式如式(2)所示。

图3 通道注意力结构Fig.3 Channel attention structure

2)空间注意力机制
空间注意力机制主要关注于目标在图像上的位置信息,通过空间特征的加权和来选择性地聚合每个空间的特征[14]。输入特征图将输入的特征先后进行最大池化和平均池化,如式(3)所示,然后通过7×7 的卷积核和sigmoid 激活函数进行处理,如式(4)所示,得到空间注意权重图Fs=其网络结构如图4 所示。

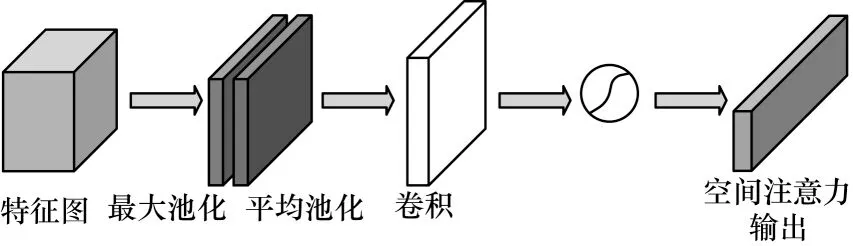
图4 空间注意力结构Fig.4 Spatial attention structure
1.4 非极大值抑制算法
对于检测任务,非极大值抑制(NMS)算法是对检测结果进行冗余去除操作的后处理算法,基于一个固定的距离阈值进行贪婪聚类,即贪婪地选取得分高的检测结果并删除超过预设阈值的相邻结果,在召回率和精度之间取得权衡[15]。利用IoU 损失函数提取阈值范围内的所有人脸检测框,将上述检测框按照得分进行排序,选取得分最高的检测框,然后计算其他的框与当前框的重合程度,如果重合程度大于一定阈值则删除,因为在同一个脸上可能会有好几个高得分的框,但是只需要一个即可。NMS 的公式如下:
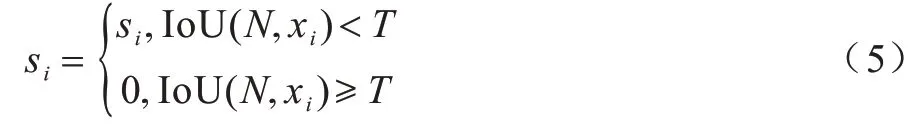
其中:N表示当前得分最高的边界框,为待处理框,和N重叠的候选窗口xi的重叠度IoU 小于预设阈值T的保留其得分,大于预设阈值T的窗口,其得分全部设置为0。
2 基于深度残差网络的人脸检测算法
针对人脸检测应用中存在的人脸密集、戴口罩遮挡等问题,本文提出一种利用ResNet-50 作为骨干网络并引入注意力机制和NMS 优化的人脸检测算法。
2.1 改进的深度残差网络
为获取更深层的图像参数,使用ResNet-50 作为骨干网络,ResNet-50 网络结构如图5 所示。输入图像经过第1 次卷积池化后传入残差块中,在随后的每个阶段都要经过一次卷积加归一化(Conv+Batch Norm)的操作,即Conv Block,然后经过多个输入和输出维度都一致的Identity Block,在经过第2 阶段~第5 阶段的卷积后,通过7×7 大小的平均池化层(AVG Pool),传入Flatten 层将数据压缩成一维数组,再与全连接层连接。

图5 ResNet-50 网络结构Fig.5 ResNet-50 network structure
本文删除了ResNet-50 中的完全连接层,并添加了2 个完全卷积层的分支去分别预测像素级边界框和置信分数,网络结构如图6 所示。
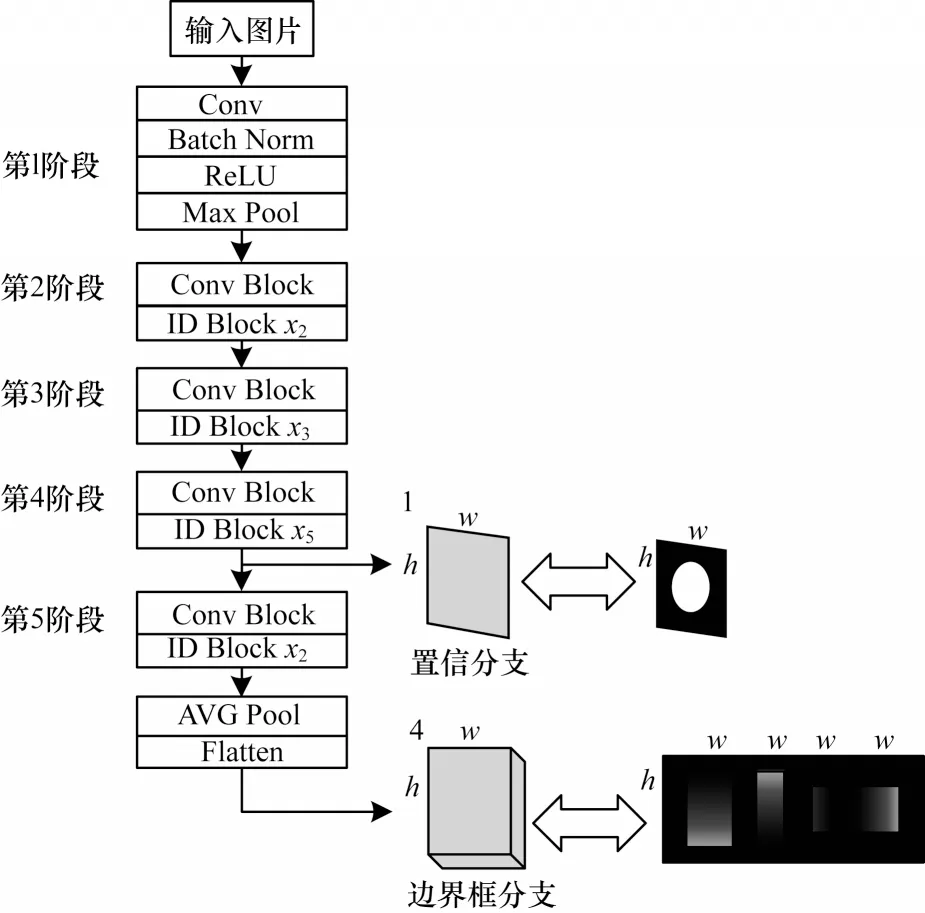
图6 深度残差网络中的置信和预测分支Fig.6 Confidence and prediction branch block of deep residual network
从图6 可以看出,在ResNet-50 第4 阶段的末尾添加了1 个卷积层,步长为1,内核大小为512×3×3×1,随后执行线性插值将特征图调整为原始图像大小,最后将要素图与输入图像对齐之后,获得了具有相同输入图像尺寸的通道特征图。在该特征图上使用S 形交叉熵损失来回归生成的置信度热图。
为预测边界框热图,在ResNet-50 第5 阶段的末尾添加 卷积内 核大小 为512×3×3×4 的卷积 层,同第4 阶段,类似地将特征图调整为原始图像大小并与输入图像对齐。此外,插入ReLU 层确保边界框预测非负,预测边界与IoU 损失函数共同优化。最终损失计算为2 个分支的损失的加权平均值。
将置信分支连接在ResNet-50 第4 阶段的末尾,而边界框分支插入在第5 阶段的末尾,是由于IoU 损失计算的边界框是一个整体,因此需要更大的感受野,并且可以直观地从置信度热图中预测对象的边界框。这样,边界框分支被视为一种自下而上的策略,可以从置信度热图中抽象出边界框。
2.2 注意力机制的引入
本文在网络结构的卷积块中引入了注意力机制[16],给定中间特征图为输入I∈RC×H×W,主干部分由两组残差单元组成,分支部分由一组残差单元、通道注意力模块和空间注意力模块组成,如图7 所示。中间特征图首先通过通道注意力模块,生成一维的通道注意力图WC∈RC×1×1,然后通过空间注意力模块生成二维的空间注意力图WS∈R1×H×W。图 中⊗为 对应矩阵元素相乘,通道注意力模块相乘时,先把一维通道注意力图扩张为WC∈RC×H×W再相乘,空间注意力模块相乘时也同样先把二维的空间注意力图沿着通道维度扩张为WS∈RC×H×W再相乘。

图7 卷积块中的注意力机制Fig.7 Attention mechanism of convolution block
上述过程可以看作是通道和空间注意力学习的相互结合,以实现层级间互信息的最大化,从而引导模型在迭代训练中学习到更显著的人脸相关信息。
2.3 网络整体结构
图8 所示为人脸检测整体网络结构,将注意力机制应用于整个残差网络,促使图像有用信息在网络中有效流动,捕捉人脸关键部位的有用信息,提高对有遮挡人脸的检测能力,使用置信度和边界框的热图准确地定位人脸。在阈值置信度热图上通过椭圆拟合人脸,由于人脸椭圆太粗糙而无法定位对象,因此进一步选择这些人脸椭圆的中心像素,并从这些选择的像素中提取相应的边界框。
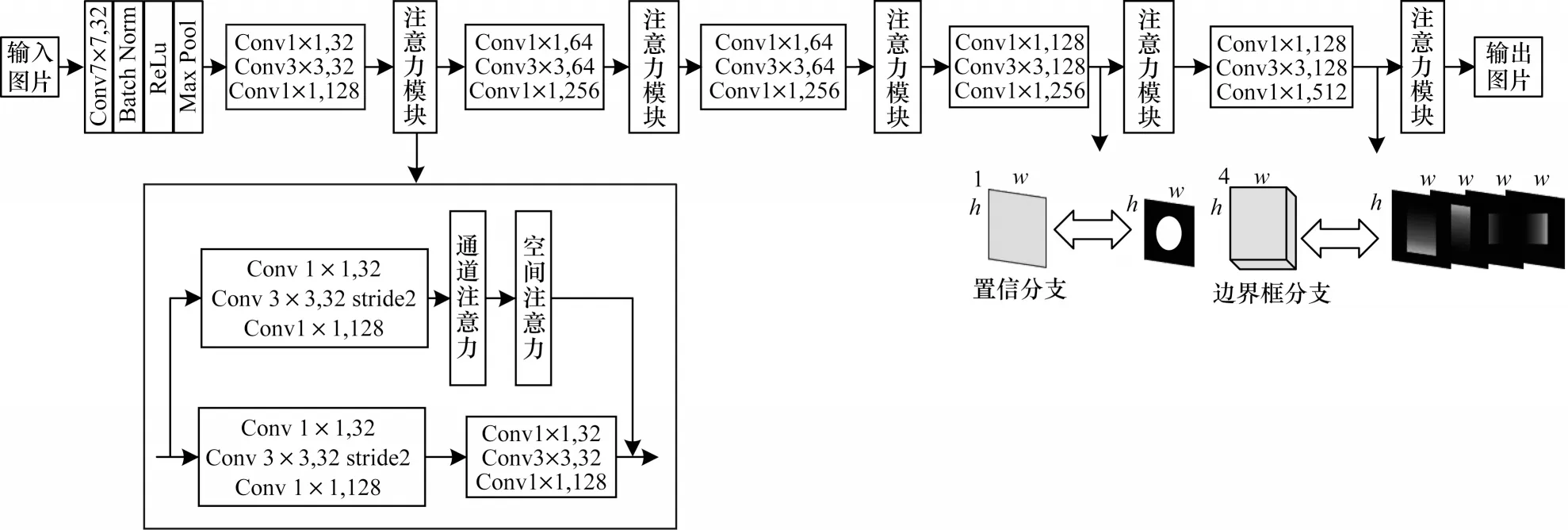
图8 深度残差网络结合注意力机制的网络结构Fig.8 The network structure of the deep residual network combined with the attention mechanism
2.4 非极大值抑制算法
非极大值抑制算法(NMS)计算出每一个检测框的面积,根据得分进行排序,随后计算其余检测框与当前最大得分的检测框交并比,删除交并比大于设定阈值的检测框。重复上述过程,直至候选检测框为空,最终得到最佳的人脸检测框,如图9 所示,由此可以提升定位人脸的准确性。

图9 NMS 算法人脸定位Fig.9 NMS algorithm faces locates
3 实验结果与分析
3.1 实验环境
本文基于PyTorch 的深度学习框架平台进行算法研究,深度学习平台为PyTorch0.4,编译环境为Python3.5,操作系统为Ubuntu18.04。硬件平台为Dell T7810 工作站,CPU 为Intel E5-2620 V4 2.1 GHz,内存为16 GB,GPU 计算卡为Nvidia Quadro P4000 4 GB。
3.2 实验结果
本文使用FDDB 数据集进行实验结果测试,FDDB 是当前权威的人脸检测评测集之一,共包含了2 845 张图片,人脸状态多样,包括遮挡、密集、分辨率低等情况。使用的权重根据ImageNet[17]上预先训练的ResNet-50 模型初始化,然后在数据集WiderFace[18]上进行微调。微调过程采用随即梯度下降(Stochastic Gradient Descent,SGD),并将批量大小设置为10。动量和权重衰减因子分别设置为0.9 和0.000 2。学习率设置为最大训练值10-8,微调期间不使用任何数据扩充。
3.2.1 人脸检测与置信度效果
人脸检测结果与置信度热图如图10 所示,可以看出本文算法能够准确找到人脸置信度高的像素点,如图10(b)所示,并能够生成对应的人脸检测边界框,如图10(a)所示。

图10 人脸检测结果Fig.10 Face detection result
3.2.2 有无注意力机制检测效果对比
在人脸有遮挡的情况下,与不含注意力机制的残差网络进行检测结果对比,如图11 所示,可以看出本文算法可以准确检测出佩戴口罩的人脸,精度高于不含注意力机制的方法,表明其对于有遮挡人脸的检测效果较好,说明通过增加注意力机制模块对复杂的人脸图像具有很强的适应性。

图11 有无注意力机制的检测结果对比Fig.11 Comparison of detection results with or without attention mechanism
3.2.3 人脸密集情况下检测效果对比
图12 为本文方法与CascadeCNN、FastCNN 人脸检测算法的检测结果对比。由图12(a)~图12(c)可见,CascadeCNN 方法对于小尺度人脸和有遮挡的人脸检测效果不理想,FastCNN 方法可以检测出被遮挡的人脸,但是对于小尺度人脸检测效果不理想,本文方法对于检测密集型人脸和有遮挡的人脸,都能取得理想的效果。

图12 人脸密集检测结果对比Fig.12 Comparison of face dense detection results
3.3 评价指标与定量分析
本文使用目标检测领域常用的ROC 曲线(Receiver Operating Characteristic curve)和每秒帧率(Frame Per Second,FPS)来客观评价本文算法对于人脸的检测能力[19]。
ROC 曲线表示的是真正率和假正数的关系。其中,真正率(True Positive Rate)ρ的计算公式为:

其中:真正数(True Positive,TP)表示正样本被预测为正样本的个数;假正数(False Positive,FP)表示负样本被预测为正样本的个数;假负数(False Negative,FN)表示正样本被预测为负样本的个数。
本文算法通过与人脸检测表现较好的算法DDFD、CascadeCNN、FastCNN、DP2MFD、UnitBox 进行对比,可以看出本文算法检测性能优于其他人脸检测算法,如图13 所示。DDFD、CascadeCNN 算法精确率较差,在85%左右;FastCNN、DP2MFD 算法的精确率较好,能达到90%左右;UnitBox 和本文算法的精确率较高,基本在95%以上。对精确率在假正数为500 时的值进行统计,同时可得出误检率。

图13 ROC 曲线对比Fig.13 ROC curve comparison
每秒帧率(FPS)表示每秒处理的图片数量,用来衡量算法的检测效率。本文实验的FPS 和总共检测完2 845 张图像所需时间如表1 所示[20]。从表1 可以看出,本文算法的人脸检测精确率达96.1%,与使用VGG-16 网络的UnitBox 算法相比精确率提高了1.6%,在检测速度方面,本文算法的检测速度显著优于DDFD、CascadeCNN、FastCNN、DP2MFD 等算法,达到10 frame/s 以上,略低于UnitBox 算法。

表1 人脸检测算法性能对比Table 1 Performance comparison of face detection algorithms
4 结束语
本文提出一种基于深度残差网络和注意力机制的人脸检测算法。通过使用深度残差网络并在网络中添加注意力机制,增强特征图在通道上的表达能力,抑制无用的特征信息,并在特征图空间上增强上下文联系和特征描述能力。利用IoU 损失函数提升人脸检测的性能,并且在检测过程中加入非极大值抑制方法,使得在人脸遮挡情况下的对象定位更加准确。在FDDB 数据集上的实验结果表明,本文算法具有较高的准确率,在检测有口罩遮挡的人脸时,也能得到较好的检测效果。但本文算法改进后由于网络计算量有所增加,检测效率还有待提高,下一步将设计更为精简的网络框架,提高检测效率,使得该算法能够更好地应用于实时场景中。
