基于知识增强的中文命名实体识别
2021-11-18胡新棒于溆乔李邵梅张建朋
胡新棒,于溆乔,李邵梅,张建朋
(1.中国人民解放军战略支援部队信息工程大学 信息技术研究所,郑州 450003;2.墨尔本大学,澳大利亚 墨尔本3010)
0 概述
命名实体识别(Named Entity Recognition,NER)旨在从非结构化的文本中抽取人名、地名、结构名等实体,是自然语言处理中的重要任务之一,也通常被认为是关系抽取[1]、语义解析[2]、问答系统[3]等下游任务的基础。现有的命名实体识别方法主要分为基于传统机器学习和深度学习两种。最大熵模型[4]、隐马尔科夫模型[5-6]、条件随机场(Conditional Ramdom Field,CRF)[7]等基于传统机器学习的命名实体识别方法需要投入大量的人力进行语料标注与特征模板设计,实现成本较高。基于深度学习的命名实体识别方法由于具有强大的泛化能力,因此成为当前的主流方法。对于基于深度学习的中文命名实体识别模型而言,当模型使用字符嵌入时受未登录(Out-of-Vocabulary,OOV)词影响较小[8-9],当模型使用词嵌入时能充分利用词边界信息并减少一字多义的干扰。为兼顾两者的优势,文献[10]联合字符嵌入与词嵌入,提出Lattice LSTM 模型,通过融合字词信息,提高了模型的泛化能力。然而,由于无法获取词内部信息,该模型在融合过程中存在信息损失的问题,同时,由于长短时记忆(Long Short-Term Memory,LSTM)网络的单向链式结构,模型无法并行计算,因此时间复杂度较高。在此基础上,各种改进模型不断被提出。为减少字词信息融合过程中的信息损失,文献[11-13]将字词信息融合过程由链式结构转换为图结构,分别提出基于协作图网络的CGN 模型、增强全局信息捕捉能力的LGN 模型、通过多维图解决词典匹配冲突的Multi-digraph 模型。为提高运行速度:文献[14]通过构建SoftLexicon 策略,将字词信息融合改为静态加权方式,降低融合成本;文献[15]提出LR-CNN 模型,利用卷积神经网络(Convolutional Neural Network,CNN)的并行化优势,代替长短时记忆网络进行特征抽取;文献[16-17]分别提出FLAT 模型和PLTE 模型,引入transformer 进行序列编码,提高模型并行能力。
随着基于字词联合的命名实体识别模型不断被提出,中文命名实体的识别效果得到了较大提升,但仍有一些共性问题难以解决。人名、地名等专有名词在通用语料中出现频率较低且构词方式无固定规律,模型中所用word2vec[18]构建的词向量对这些低频词的覆盖率不高,相应的未登录词会干扰实体边界的界定。以“代表团视察了约旦河”为例,由于“约旦河”在词向量中属于未登录词,基于字词联合的命名实体识别模型更倾向于将“约旦”识别为一个实体。基于深度学习的命名实体识别模型依赖于大规模训练语料,而大多数人工标记的实体识别数据集规模相对较小,如何利用小样本学习方法提升中文命名实体识别的效果有待进一步研究。
为解决上述问题,本文在现有的LR-CNN 模型上进行改进,提出一种基于知识增强的命名实体识别模型AKE。使用改进位置编码的多头注意力机制捕捉长距离依赖,弥补传统注意力机制丢失位置信息的缺陷,以提高模型上下文信息捕捉能力。加入知识增强模块,在序列编码过程中融入实体类别、边界等附加知识,弱化未登录词的影响并缓解模型在小数据集上性能表现不佳等问题。
1 基于知识增强的中文命名实体识别模型
本文提出的AKE 模型的整体结构如图1 所示,根据功能可大致分为字词联合、知识增强、解码3 个模块。字词联合模块根据匹配词长度,对字词信息进行分层融合。在各层中,首先依据CNN 所用卷积核尺度不同,获取所在层相应长度的词组序列;然后经由改进位置编码的自注意力机制,捕获序列的长距离依赖;最后与匹配词进行信息融合,得到本层的字词联合结果。知识增强模块通过查询基于领域知识等构建的实体词典,指导字词联合模块中不同层所得信息的整合,在最终的序列编码中加入实体边界、类别等附加知识。解码模块使用条件随机场对知识增强后的编码进行标注,得到标注结果序列。依据处理流程,下文将分别对模型的3 个模块进行介绍。

图1 AKE 模型的整体结构Fig.1 Overall structure of AKE model
1.1 字词联合模块
GUI 等[15]利用CNN 局部特征提取的天然优势和优秀的并行能力,提出LR-CNN 模型,为字词信息的融合提供了新的思路。然而,尽管该模型的字词联合模块中,各层CNN 的层内可以充分利用并行计算的优势,但CNN 层间为串行执行,当CNN 层数较多时,模型依然存在复杂度较高的问题。本文在LR-CNN 模型的基础上,对其中的字词联合模块进行改进,首先将各层CNN 改为层间并行,各层同时进行特征抽取,提高模型运行速度,然后用基于相对位置编码的多头注意力机制捕获长距离依赖,进一步提高字词联合模块的表征能力。
字词联合模块中各层字词信息的融合结果,由CNN 所提取的n-gram 的特征信息、对应词嵌入序列、上一层融合结果经门控网络得到,其计算过程可分为基于CNN 的n-gram 特征信息提取、字词信息初步融合、字词信息融合权重调整3 个步骤。
1.1.1 基于CNN 的n-gram 特征信息提取
在字词融合模块中具有3 层CNN,CNN1、CNN2、CNN3的卷积核分别为HC、HD、HT,以输入序列X={x1,x2,…,xn}长度为n为例。在各层中,CNN分别对1-gram、2-gram、3-gram 的片段进行特征提取,经非线 性变换,得 到C={c1,c2,…,cn}、D={d1,d2,…,dn}、T={t1,t2,…,tn}特征序列,对于时刻τ(1≤τ≤n):
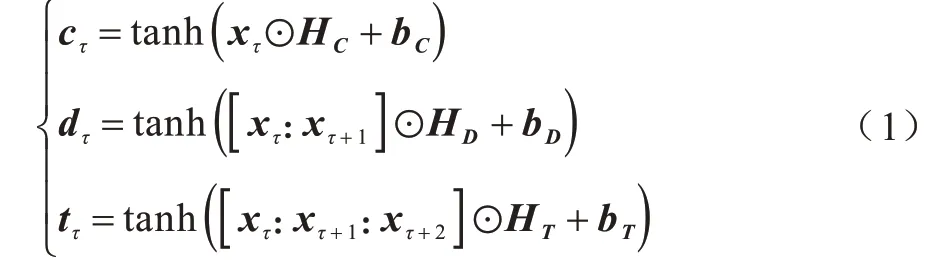
其中:bC、bD、bT为偏置。
受CNN 感受野限制,得到的特征序列C、D、T缺少长距离信息,在LR-CNN 模型中,传统注意力机制虽然对此问题进行了弥补,但由于位置编码存在的缺陷,模型会损失距离信息与方向信息。对于命名实体识别等序列标注任务,上文标注内容会影响下文标注结果,距离与方向信息的损失会对模型产生负面影响。为解决上述问题,采用基于相对位置编码的多头注意力机制[19-20]构建上下文关系。在新的注意力机制中,对于输入序列中的时刻t,将时刻j的相对位置嵌入定义如下:

因此,针对不同方向的相对位置τ与-τ,可得到如式(3)所示的相对位置嵌入。显然,相比传统注意力机制中的位置嵌入,该位置嵌入方式能够在表征距离信息的同时保留方向信息。
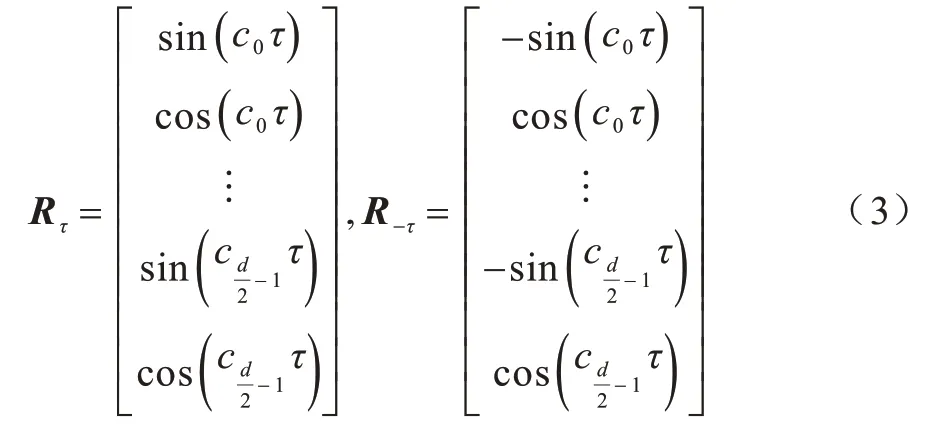
在改进位置嵌入的基础上,注意力机制的具体计算如下:对于长度为l、嵌入维度为d的输入序列I,由式(4)得到注意力机制中嵌入维度为dk的Q、K、V,进而由式(5)计算时刻j对序列中的时刻t的注意力概率分布,由式(6)和式(7)得到整个序列的注意力。
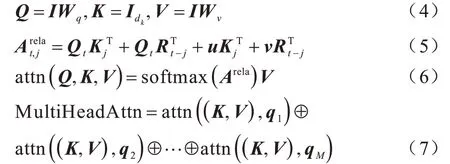
经多头注意力机制后,将得到的C′、D′、T′送入下一步进行字词信息的融合。
1.1.2 字词信息初步融合
各层字词信息的融合可由式(7)中所提取n-gram 的特征信息C′、D′、T′,对应词嵌入序列Z、下层融合结果经门控网络得到。由于word2vec 构建的词向量会对低频词进行过滤,而常用词一般较短,使得词长度越长时未登录词越普遍,通过在门控网络中引入下层融合结果,可以缓解上层未登录词较多导致词义偏差过大的问题。
本节以双字层序列D″={d″1,d″2,…,d″n}的获取为例,说明各层字词信息的融合过程,具体计算为:将2-gram 提取到的特征序列D′与双字词的词嵌入序列ZD进行初步融合得到u1,同时引入残差连接促进前后向信息传播。融合结果D1的获取过程如式(8)~式(12)所示:

在得到2-gram 的特征信息与双字词词嵌入序列的融合结果D1后,将字符层序列C″与D1融合,得到字词信息的初步融合结果

其中:Wg、bg为线性函数中的权重系数与偏置。经过这一步融合,上层序列融入了下层的信息,并不断向上进行传递,缓解了未登录词过多导致词义偏差过大的问题。经过同样的操作,得到单字层、三字层的初步融合结果中融入了各层的信息。
1.1.3 字词信息融合权重调整
虽然字词信息初步融合中操作对字级信息、词级信息、下层信息进行了融合,但得到时三者融合的权重可能不够合理。同时,字词信息初步融合中得到的最高层序列中融入了各层的信息,为缓解上述权重不合理的问题,按照式(15)~式(19),将初步融合结果中最上层序列作为附加输入,与2-gram提取到的特征序列D′、双字词的词嵌入序列ZD进行融合,调整融合过程中的权重。

1.2 知识增强模块
现有中文命名实体识别模型难以取得重大突破的重要原因在于:大多数中文人名、常用地名等专有名词构词方式无固定规律,实体边界确定困难;低频实体在词向量中存在大量未登录词,识别效果较差。因此,解决这些问题是命名实体识别研究的重要内容。但是,中文人名、常用地名、特定领域名词等实体的数量相对有限,基于这些知识构建实体词典较为容易。因此,充分利用此类实体词典,在模型中加入先验知识,对增强命名实体识别模型的泛化能力、迁移能力,提高在小数据集和特定领域的实体识别效果具有重要意义。然而,如何利用实体词典存在一定的挑战。首先,由于新词引入、统计缺漏、实体划分粒度差异等问题,基于现有知识构建的实体词典很难覆盖领域内所有实体;其次,通过实体词典得到的匹配结果存在部分错误,如“战争全方位爆发了”这句话中,“全方”可能被误识别为人名实体。由于上述缺漏与匹配错误的情况,当使用神经网络中常用的向量拼接、向量相加等特征组合方式,将实体词典中的知识融入模型时,反而可能因噪声问题对模型产生负面影响。
受注意力机制的启发,本文在字词联合模块的基础上,通过影响不同层序列的权重整合进行知识增强。如图2 所示,对于经字词联合分别得到单字、双字、三字层序列C″、D″、T″,时刻τ的对应编码分别为c″τ、d″τ、t″τ,通过加 权求和 各层中 相应位 置的权 重可以得到该时刻的最终编码xτ′:
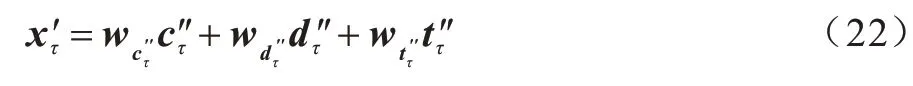
对于图2 中类似“代表团”中的“代”字,因为实体词典中无匹配项,所以模型将按照式(23)计算各层权重:
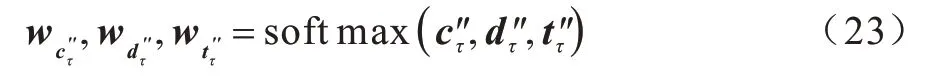
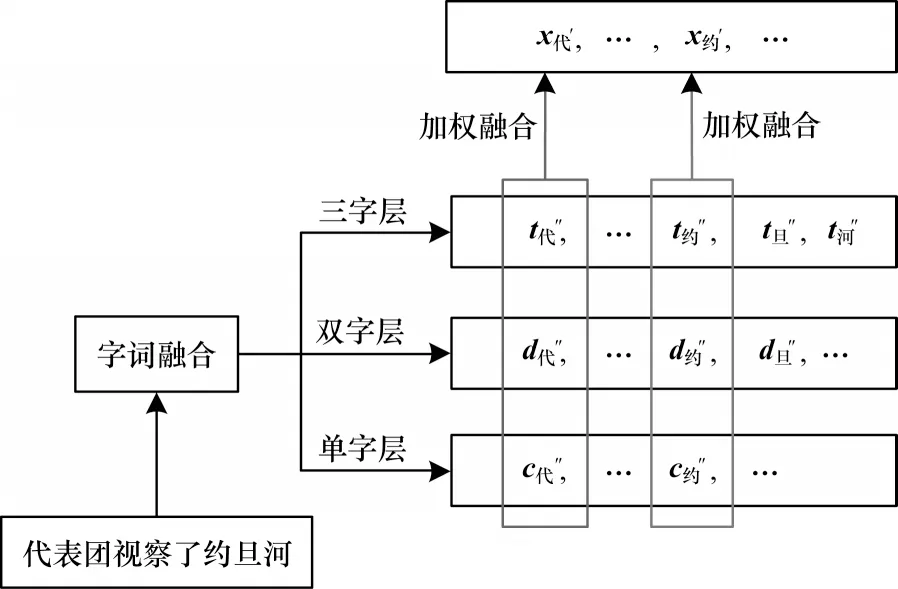
图2 知识增强流程Fig.2 Procedure of knowledge enhancement
由于“约旦河”为输入序列在实体词典中的一个匹配实体,且长于匹配词“约旦”,模型可依据式(24),将Δ与匹配实体所在层对应位置的编码相乘,计算“约旦河”三字的最终编码。

其 中,Δ=ΔLOC且Δ取值为1.05~1.35。由于公 式0、x>0 时,函数单调递增。因此,在本例中,相比式(23)中权重计算方式,在“约旦河”的权重计算过程中,模型能够给予三字层中相应字更高的权重,使得到的最终编码更贴近“约旦河”的向量表示,而双字层“约旦”的词向量和单字层的字向量对模型的影响权重降低。在这个过程中,潜在实体得到了模型的更多关注,利于发现未识别实体,提高模型召回率。同时,增强过程引入的词边界信息能在一定程度上缓解边界识别错误的影响。“对最长匹配实体进行增强”的规则减少了类似图2 中“约旦”这样的嵌套实体对词边界判定的干扰。对于上文中所提到类似“全方”这样的匹配错误问题,由于不同类别的实体词典在不同语料中导致的匹配错误比例存在差异,因此处理过程中模型在1.05~1.35 范围内随机产生增强权重,防止匹配错误对结果影响过大,并通过模型训练得到所用语料中各实体类型的最佳增强权重。对于缺漏实体问题,模型将按照式(23)中方式计算各层权重,即不进行知识增强,消除了实体匹配缺漏对模型产生的影响。
1.3 解码模块
条件随机场是序列标注任务中常用的解码器。对于知识融合后的输出序列,若其对应的标注序列为Y={y1,y2,…,yn},所有可能的标注序列集合为L(X′),则标注序列y的概率如下:
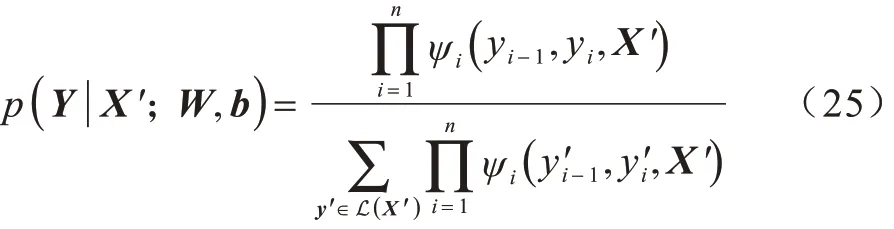
其中:ψi(yi-1,yi,X′)=exp(WiX′+bi);Wi与bi为标签对(yi-1,yi)对应的权重和偏置。在模型训练过程中,本文采用预测值和真实值的最大化对数似然作为优化目标:


2 实验与结果分析
2.1 数据集与实验设置
为充分评估本文模型的识别效果,除常用的Resume[10]、MSRA[21]、Weibo[22-23]等评估数据集外,本文引入OntoNotes5.0[24]、People Daily[25]、Boson 等 公开数据集,使得数据集的规模大小、语料来源、划分粒度覆盖更全面,评估结果更客观。Resume、MSRA、Weibo 数据集与Lattice LSTM[10]中使用相同且有分词信息;OntoNotes5.0 在OntoNotes4.0 的基础上加入了更多的数据,实体类别划分更细,也含有分词等附加信息;People Daily 来源于1998 年的人民日报;Boson 来自bosonnlp 提供的公开数据集。
在实验过程中,OntoNotes5.0 依据官方提供的代码进行数据集切分;People Daily 与fastnlp 提供的切分相同;Boson 数据集按照8∶1∶1 的比例进行数据集切分。表1 给出了实验中各数据集详细统计信息。
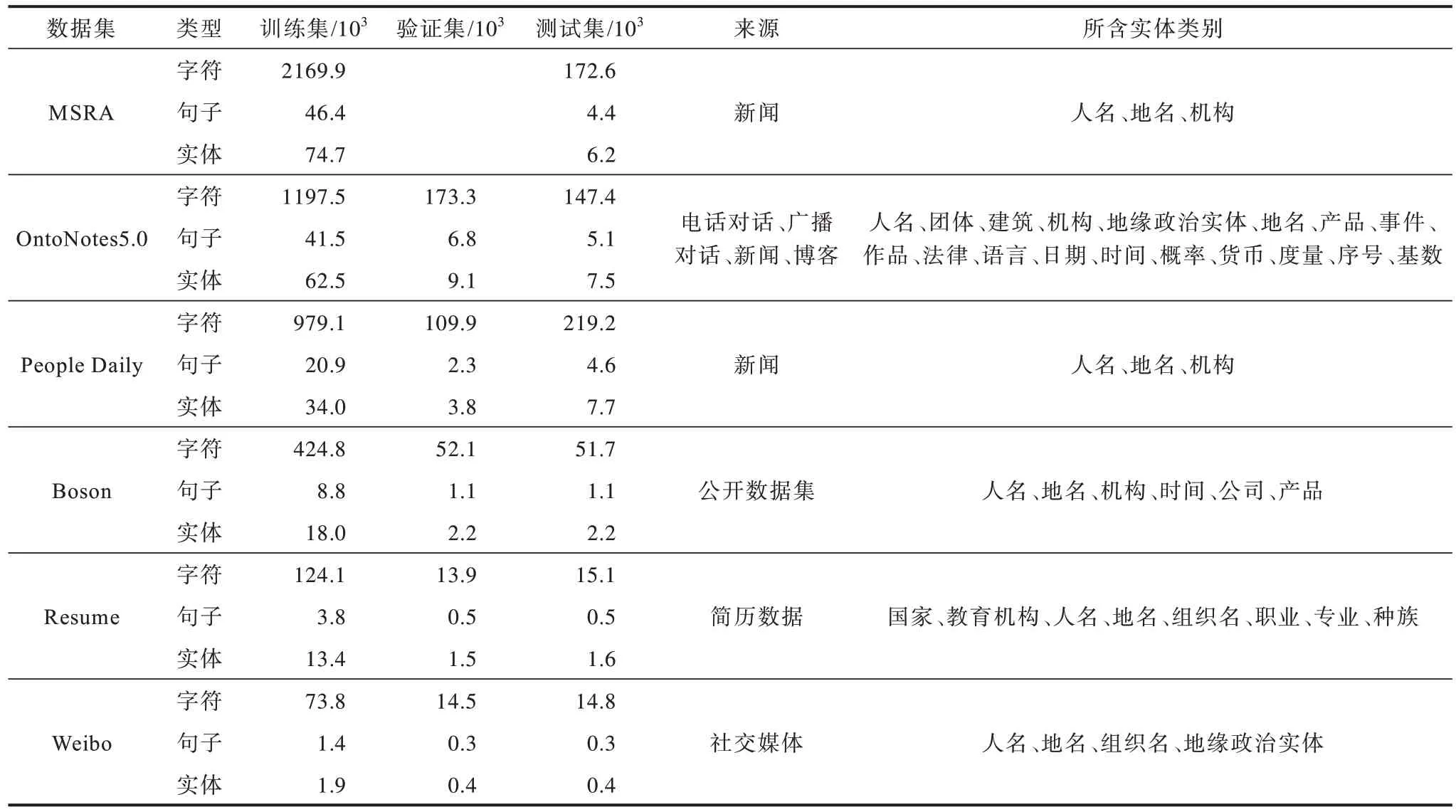
表1 数据集详细统计信息Table 1 Detailed statistics of datasets
与Lattice LSTM[10]相同,本文采用由word2vec训练得到的字符向量与词向量[26],并在训练中进行微调。实验所用PER、ORG、LOC 等实体词典来源于公开数据。在实验过程中,模型使用Adamax[27]作为优化函 数,并设置0.5 的dropout[28]防止过拟合。按照语料规模,将MSRA、OntoNotes5.0、People Daily归类为大数据集,将Boson、Resume、Weibo 归类为小数据集。对于3 个大数据集,设定隐藏层节点数为300,CNN 层数为5;对于3 个小数据集,设定隐藏层节点数为200,CNN 层数为4。Weibo 语料来源于社交媒体,口语化比较严重,模型收敛较慢,学习率设为0.005;MSRA 语料较为规范,学习率过大容易导致模型无法收敛,实验中学习率设置为0.000 5;其他数据集学习率设为0.001 5。对于实验中的各对比模型,超参数设置都参考其原始的论文描述,以MSRA、Resume 为基准,分别设置在大数据集和小数据集上的超参数。
2.2 标注规范与评价指标
命名实体识别通常被作为序列标注任务,其标注规范包括BIO、BMESO、BIOES 等多种形式。实验采用BMESO 标注方法,对于数据集中的实体,根据长度与类别,将单字实体标注为S-TYPE,将多字实体的开始、中间、结尾字符分别标注为B-TYPE、M-TYPE、ETYPE,其中,TYPE 为实体类别,其他字符标注为O。
将准确率(P)、召回率(R)和F1 值(F)作为评价指标,具体定义如下:

其中:Tp为模型识别出的实体数量;Fp为模型误识别的实体数量;Fn为模型未识别出的实体数量。
2.3 结果分析
相对于LR-CNN 模型,本文主要做了提高模型并行能力、使用改进位置编码的多头注意力机制替代传统注意力机制、添加知识增强模块融入先验知识3 个方面的改进。提高模型并行能力的改进主要影响模型效率,为评估其他两种改进策略对模型性能的影响,分别做了仅改进注意力机制(AKE w/o K)、改进注意力机制且进行知识增强时的模型性能评估(AKE)。同时,对于有分词信息的OntoNotes5.0、Weibo 两个数据集,分析分词信息对模型的影响(AKE with seg)。此外,与近两年的主流模型,包括基于字词联合的Lattice LSTM 模型[10]、LGN 模型[12]、SoftLexicon 模型[14]、LR-CNN 模型[15]、FLAT 模型[16]、基于字的TENER 模型[19]在 多个数据集上进行对比。取3 次实验结果的平均值作为最终结果,相关评估结果如表2、表3 所示,其中,“—”表示相关论文未列出实验结果或数据集不支持进行相应实验,最优指标值用加粗字体标示。下文从改进策略对模型识别性能影响、模型整体识别性能与鲁棒性、模型复杂度3 个角度,分别对多头注意力及知识增强对模型识别性能的提升、不同模型处理来源各异且规模不等数据集的能力、各模型的时间与空间成本等方面进行分析。

表2 大数据集上命名实体识别性能对比Table 2 Comparison of NER performance on big datasets %
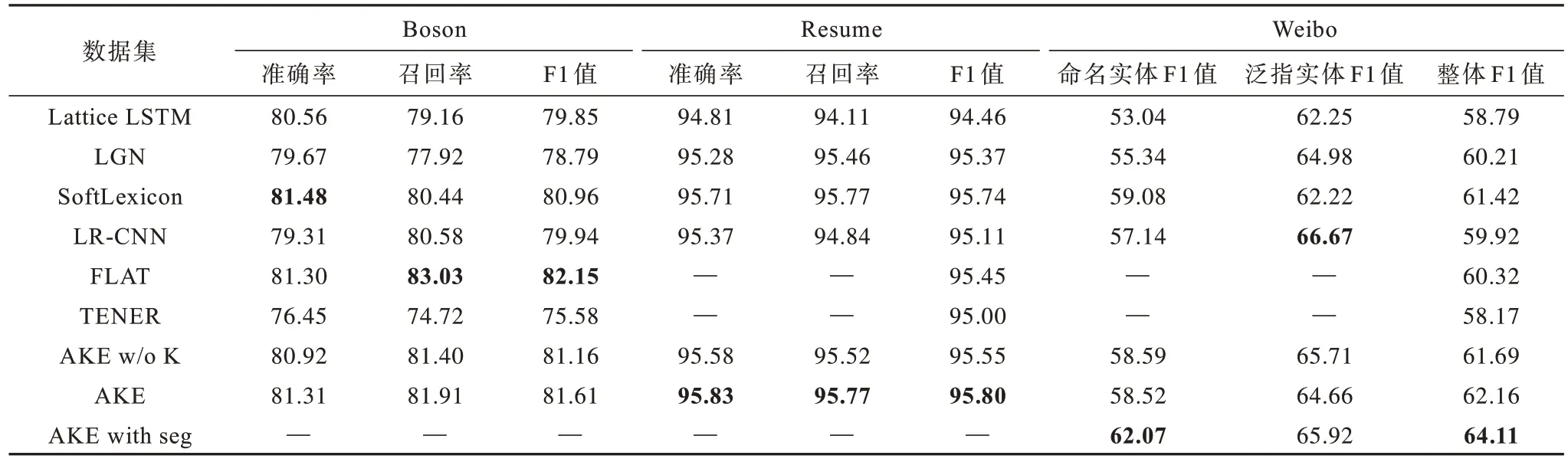
表3 小数据集上命名实体识别性能对比Table 3 Comparison of NER performance on small datasets %
2.3.1 改进策略对模型识别性能的影响分析
通过对表2、表3 进行分析,可得出以下结论:1)在改进注意力机制对模型性能的影响方面,在使用改进位置编码的多头注意力机制之后,模型的召回率、F1 值均有明显提高,准确率在多个数据集上也有更好表现,证明了在实体识别等序列标注任务中文字距离与方向信息的重要性,也验证了改进位置编码的多头注意力机制的有效性;2)关于知识增强的改进,在进行知识增强后,模型的召回率有了进一步的提高,通过融入先验知识,模型识别出了更多的实体,虽然受实体词典错误匹配所产生噪声的干扰,准确率在部分数据集上有所下降,但总体F1 值依然有所增加;3)在分词信息对模型性能的影响方面,在加入分词信息后,OntoNotes5.0、Weibo 数据和其子集的识别效果都得到了提高,证明了词边界在命名实体识别任务中依然是非常重要的,分词信息的加入在一定程度上减缓了字词联合模块中词边界确定困难的问题。
为进一步探究知识增强过程中实体词典对数据集中标记实体的覆盖率(entity coverage)、实体词典错误匹配所产生的噪声比率(noise rate)、数据规模、实体划分粒度等对模型召回率与F1 值的影响,将知识增强对模型性能提升情况与上述覆盖率与噪声比率依据数据规模作折线图如图3 所示。
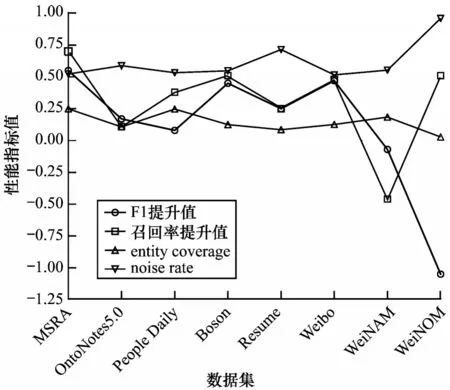
图3 实体词典匹配对模型识别性能提升的影响Fig.3 The effect of entity dictionary matching on the improvement of model recognition performance
结合表1 中各数据集详细信息,对图3 进行分析可以得出以下结论:
1)在总体上,在进行知识增强后,随着数据集规模变化,模型的F1、召回率提升值与实体词典对数据集中标记实体的覆盖率呈现一定的正相关性,进一步验证了知识增强提高了模型发现实体的能力。
2)在数据规模影响方面,相对于大数据集,知识增强在小数据集上对模型性能的提升效果更为明显。在工程应用中,由于人工标注成本高、特定领域数据量小、数据受隐私保护等原因,大规模标注数据的获取往往较为困难,因此本文提出的知识增强方式通过在模型中融入领域先验知识提高模型性能,在实际工程应用中具有重要意义。
3)在实体类别划分粒度上,由于People Daily 实体种类较少、数据规模较大,模型训练较为充分,虽然知识增强提高了模型的召回率,但对模型整体F1 值的提升效果不够明显。相比之下,尽管OntoNotes5.0 数据集规模更大,但实体类别划分粒度较细、语料中有大量口语化的内容,模型识别能力有进一步提升空间,知识增强对模型的性能提升更为明显。
4)在抗噪声干扰方面,由于Weibo 数据集的子集WeiboNAM 与WeiboNOM 的实体个数较少,模型训练不充分,同时实体词典匹配到的噪声比率较高,模型的性能受影响波动较大。
5)从实体词典对数据集中标记实体的覆盖率、实体词典错误匹配所产生的噪声比率来看,虽然本文知识增强模块在一定程度上提高了模型性能,但标记实体的覆盖率总体不高,同时处理过程中所用降噪方法仍较为简单。
在后续任务中,如何扩充实体词典提高对标记实体的覆盖率、改进知识增强模块降低对匹配噪声的影响,将是需重点研究的内容。
2.3.2 模型整体识别性能与鲁棒性分析
为分析模型的性能及鲁棒性,以Lattice LSTM 模型为基准,计算各模型的F1 值的相对提升幅度,如图4所示。为保证图像的差值范围,将TENER模型在People Daily 数据集上的F1 提升值设为0。
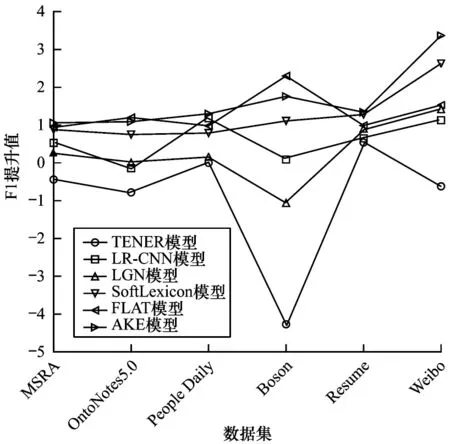
图4 6 种模型在不同数据集上相对Lattice LSTM 模型的F1 值提升情况Fig.4 The improvement of the F1 value of the six models relative to the Lattice LSTM model on different datasets
通过对图4 进行分析可得出以下结论:1)基于字的TENER 模型总体表现不如其他基于字词联合的模型,证明基于字词联合的模型相对于基于字的模型能够捕捉更多的上下文信息,具有较大优势;2)TENER 模型在不同数据集上F1 值波动较大,在People Daily 数据集上表现较差,鲁棒性不强;3)在字词联合模型中,LGN 模型与LR-CNN 模型表现一般,相对基线模型提升不够明显,且识别性能提升幅度受数据集影响较大;4)SoftLexicon 模型在各数据集上表现稳定,具有较强的鲁棒性,但由于该模型中字词信息融合采用静态方式,在具体语境中可能会出现偏差,影响识别效果;5)FLAT 模型在多个数据集上均有优异表现,但由于参数量较多,在Resume、Weibo 等小数据集上学习不充分,模型鲁棒性有待提高;6)本文模型相对其他模型在多个数据集上取得了最好的识别效果,且在不同数据集上表现较为稳定,具有一定的鲁棒性。
2.3.3 模型复杂度分析
除上述性能评估外,为对模型有更全面的分析,实验中以Lattice LSTM 模型为基准,对比各字词联合模型在OntoNotes5.0 数据集上的推理速度与计算资源占用情况,对比结果如图5 所示,其中,FLAT 模型批大小为10,其他模型均为1。

图5 字词联合模型推理速度与计算资源占用情况对比Fig.5 Comparison of reasoning speed and computing resource occupancy of character-word joint models
由图5 可以看出:相比Lattice LSTM 模型,FLAT模型虽然使用并行化提高了推理速度,但计算资源占用激增;其他模型大多在推理速度方面提升不大,资源占用稍有增加;本文AKE 模型由于字词融合模块中多头注意力机制的使用和知识增强模块的加入,推理速度稍有下降,资源占用量相对较多,后续有较大的改进空间。
3 结束语
本文在LR-CNN 模型的基础上,提出一种基于知识增强的命名实体识别模型。通过改进字词联合模块,提高模型并行性与上下文信息捕捉能力。加入知识增强模块融入实体边界、实体类别等先验知识,缓解未登录词影响和模型在小数据集上学习不充分的问题。实验结果表明,相比基于字词联合的命名实体识别主流模型,本文模型能够提高实体识别的召回率与F1 值,同时具有较强的鲁棒性和泛化能力。此外,通过使用不同领域的实体词典,融入相应先验知识,赋予模型较强的迁移能力,并且所提出的知识增强思想在其他自然语言处理任务中也具有一定的借鉴意义。下一步将重点改进模型的知识增强策略,减少实体词典匹配错误所产生的噪声干扰,优化字词融合模块,降低模型复杂度。
