组合优化理论的电子商务用户行为聚类分析
2021-11-17吴毅强
吴毅强
(广州华立科技职业学院管理学院,广东 广州 511325)
电子商务的普及给人们的生活带来了极大便利,通过研究电子商务用户行为特征可以为用户提供高质量服务,大幅提升电子商务交易成功率,因此分析电子商务用户行为数据特征是当前电子商务用户维护领域中的关键课题[1-3]。
针对庞大的电子商务用户群,分析用户行为不易,在电子商务用户行为数据中利用高效数据分析方法准确分析用户行为特征十分必要[4-6]。作为数据挖掘的一种有效方法,聚类分析具有无监督学习特性,可在大量、无规律、含噪的电子商务用户行为数据中发现隐性的行为模式,呈现电子商务用户行为数据隐藏的特征,为人们的决策判断提供理论支持,但是传统的K-means聚类算法具有计算量大、获取最优解时间长等缺陷[7-9]。
为了提高电子商务用户行为聚类分析效果,本文提出了基于组合优化的电子商务用户行为聚类分析方法。将遗传算法和K-means进行融合,对电子商务用户行为数据集进行聚类分析,基于组合优化理论,实现电子商务用户行为聚类分析,通过实验验证了本文方法可获取高精度聚类结果。
1 组合优化理论的电子商务用户行为聚类分析方法
在当前电子商务用户行为聚类分析过程中,为了提高聚类分析效果,通常将遗传算法和K-means聚类算法结合起来,以实现电子商务用户行为聚类。
1.1 遗传算法和K-means相融合的电子商务用户行为聚类分析方法
采用遗传算法和K-means聚类算法聚类各电子商务用户行为数据集,利用遗传算子交互个体信息,逐步逼近最优解,可防止出现陷入局部最优解问题,具体过程为:
1)编码、形成初始群解。b,p和g分别表示电子商务用户行为样本数量、样本位数和类别数量。设染色体结构为A=(a1,a2,…,ai),其中ai代表第i位的等位基因。在ai与g值一致的条件下,ai归属于第g个类别。随机生成初始群体p(0),初始化p(0)时有一定概率出现某个体内存在空类的问题,此个体为非法解,出现该问题时的处理方式为:Vi表示某个空聚类,在与Vi距离最近的非空聚类内,选取一个与原始聚类和中心最远的对象移入Vi内,不断循环该过程,直到电子商务用户行为数据样本集中不存在空聚类为止。
2)确定适应度函数。以最小化误差平方值为目标,个体误差平方值越小,对下一代产生的利益越大,即遗传率越高,适应度函数值越大。个体A的适应度函数f(A)为:
(1)
式中:H为(1,…,Vi)类内平方误差和。
(2)
式中:s为适应度误差。
3)遗传操作。采用旋转轮盘法进行个体随机选择,具体思想为:逐一确定群体中不同个体的适应度函数值,并将各适应度函数值相加得到Fb,Fb表示最后一个群体的适应度函数相加值;E表示0~Fb之间生成均匀分布的任意数,将各Fi值同E值进行对比,获取首个出现Fi≥E的个体i;循环生成E与获取i,直到获取个体数量达到所需要求为止[10]。
变异操作依照不同个体与各聚类中心的距离优化个体相应位置的值。样本与某聚类中心距离越小,则个体内与该样本对应的位变异聚类编号的概率大。样本与聚类中心间的欧氏距离为s(xi,vj),变异方式为:
(3)
式中:Pj为变异函数;V为1~g之间的整数;smax(xi)为s(xi,vj)内的最大值。
遗传算法和K-means聚类算法具有全局搜索能力,但计算量大,因此将该K-means聚类算法与复合形法的K-means优化聚类组合,以提升电子商务用户行为聚类分析效率。
1.2 复合形法的K-means优化聚类过程
1)针对复合形法中不同参数反射系数、精度标准以及复合形初始顶点等数据确定聚类中心数量。
2)将簇类数量设置为g,并于最优解群体内确定不同聚类中心的欧氏距离:
(4)
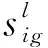
3)依照最近邻理论判断各组数据的所属类别,具体为:
(5)
式中,Cl为以顶点l为中心的簇集;sil为簇集内第i个数据距离中心点的欧氏距离。
4)用f(Yl)表示复合形法中不同顶点Yl的目标函数值:
(6)
式中:L为顶点数量。
5)用f(YR)表示全部顶点内确定最差点YR的目标函数值,确定中心点Y与反射点YN:
f(YR)=maxf(Yl)
(7)
(8)
YN=Y+λ(Y-YR)
(9)
若f(YR)>f(YN),则表示反射点与最差点YR相比逐渐转好,用反射点取代最差点组建新复合形,再实施3)过程;若f(YR)≤f(YN),则表示反射点与最差点YR相比未出现转好趋势,此时可降低反射点同中心点距离,直至f(YR)>f(YN)。
6)最终收敛状态下复合形不同顶点的目标函数值与几何方位差异较小,描述如下:
(10)
(11)
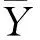
当式(11)成立时,迭代结束;当式(11)不成立时,返回3)过程。
1.3 基于组合优化理论的电子商务用户行为聚类
组合优化理论的电子商务用户行为聚类过程如图1所示。

图1 组合优化理论的电子商务用户行为聚类过程
2 仿真实验
2.1 数据集
利用网络爬虫技术获取研究对象用户行为数据,从中选取2019年数据,按月份分为12个电子商务用户行为数据集,各数据集样本数见表1,该样本具有范围广、数量大以及时间足够长等客观性特点。针对这12个数据集中的电子商务用户类别实施聚类分析。根据用户的行为将用户划分为搜索型用户、普通型用户和促销型用户等类别。
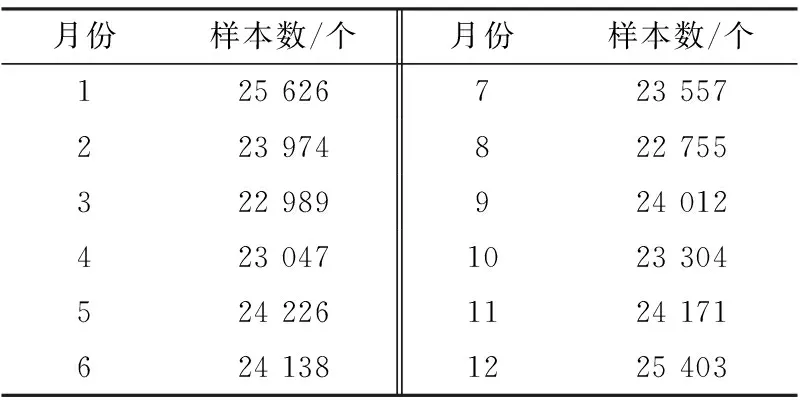
表1 各数据集样本数
2.2 电子商务用户行为的聚类结果
采用本文方法对12个数据集中1月用户行为数据集进行聚类分析,聚类数量为3,聚类结果见表2。
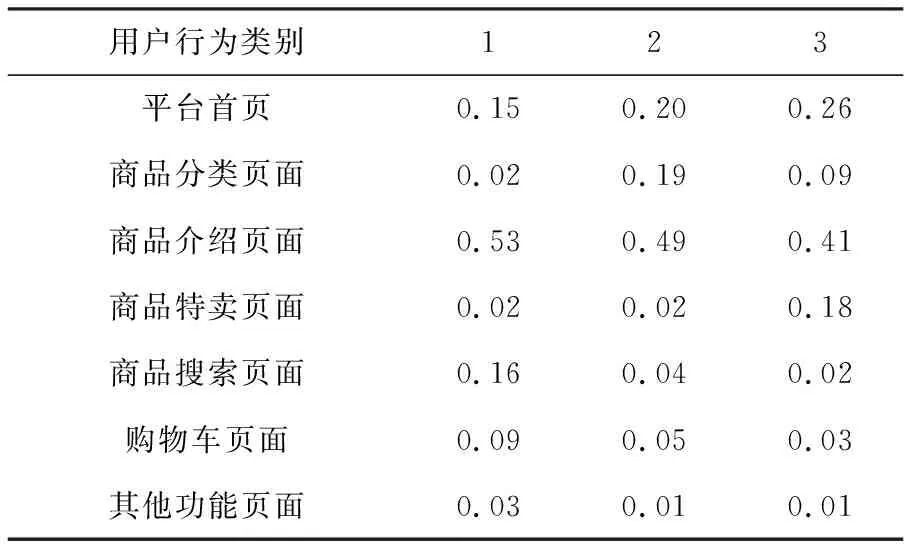
表2 电子商务用户行为的聚类结果
分析表2中的用户行为聚类结果可知:
1) 大部分用户是经由首页和商品介绍页面购买商品,因此其排除在用户行为类别特征之外。
2) 类别1用户群体中,商品分类页面、商品特卖页面以及其他功能页面占据比例较低,而商品搜索页面与购物车页面的占据比例较高,因此类别1可归类成通过搜索页面之间进行商品查询与购买的搜索型用户。
3) 对于类别2用户群体中,用户行为中商品分类页面占比显著高于其他页面,同时商品搜索页面和购物车页面占比基本一样,这种情况表示用户在购买商品时是通过平台首页选取商品类型页面,在该页面中选取商品、查看商品介绍页面,然后将商品加入购物车进行购买,购物车中商品被选定的顺序与销售设定顺序一致,并且在3种不同类别中,此类别占比高于50%,可将此类别用户定义为普通型用户。
4) 类别3用户群体中,用户行为占比最高的是商品特卖页面,而其他页面占比均较低,这表示该类别用户群体对于特卖页面的关注度较高,可将这一类别用户定义为促销型用户。
2.3 电子商务用户行为的聚类精度
分别采用本文方法、信息熵的聚类分析方法和基于遗传算法的聚类分析方法对所选12个数据集进行聚类分析,聚类精度如图2所示。从图2可知,本文方法聚类精度平均值高于其他两种方法。
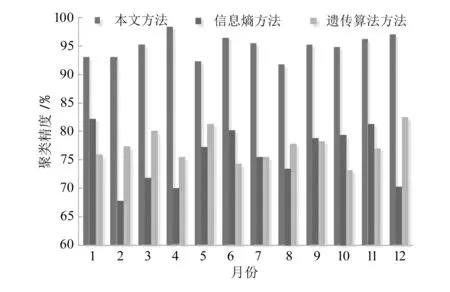
图2 电子商务用户行为的聚类精度对比
2.4 电子商务用户行为的聚类效率分析
根据图2可知,本文方法的聚类精度最高,基于遗传算法的聚类分析方法精度高于信息熵的聚类分析方法,因此在聚类效率对比分析过程中,仅对比本文方法与基于遗传算法的聚类效率,结果如图3所示。分析图3可知,本文方法迭代过程整体时间显著减少,具有显著的效率优势。

图3 聚类效率对比
2.5 经济效益对比
采用2019年的经济效益提升比例验证经济性,结果如图4所示。分析图4可知,采用不同方法聚类分析对象用户行为后,企业经济效益均呈现逐渐上升趋势,本文方法提升幅度最为显著,而且随着使用时间的延长,电子商务平台经济效益更显著,有更大的应用价值。
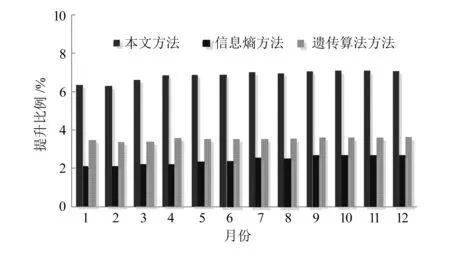
图4 不同方法的经济效益提升比例
3 结束语
针对当前电子商务用户行为聚类分析方法存在的不足,本文提出了组合优化的电子商务用户行为聚类分析方法。实验结果显示,本文方法既可获取高精度聚类结果,又能够通过复合形法缩短迭代时间提升聚类效率,使电子商务平台经济效益得到显著提升。
