切片循环神经网络和胶囊网络的性别欺凌识别
2021-11-17陈继洪田生伟
陈继洪,田生伟,禹 龙
(1.新疆大学软件学院,新疆 乌鲁木齐 830000;2.新疆大学网络中心,新疆 乌鲁木齐 830046)
1 引言
随着互联网的高速发展,人们广泛的参与到社交网络媒介的讨论中,大量发表自己的言论,以此来表达自己对事态的观点和看法。然而由于网络缺乏监管和网络隐匿性的特点,部分网民会发表对他人挖苦、讥讽、甚至辱骂言论,使网络中存在大量欺凌信息。这种利用网络媒介发表对两性不平等的偏见、歧视、讽刺,甚至是仇恨仇视言论,故意对受害者造成伤害的现象,称之为网络性别欺凌。性别欺凌一直是社会上重点关注的话题。京东一则文案写到“不涂口红的你,和男人有什么区别”;重庆公交坠江新闻,对“女乘客”、“女司机”的评论达十多万条;以及社交网络中的“直男癌”、“死基佬”、“女博士”等诸多性别欺凌词汇。这些对于女性或男性权利的蔑视亦或者不尊重,无不对于男女平等的国际政策理念是一种侵蚀,不仅给社会带来了负面影响,而且给受害人或群众带来心理和情感上的重大伤害。因此,如何运用现有技术,有效识别网络性别欺凌言论,成为当前学术界研究的热门课题。
近年,国内外的研究人员对网络欺凌展开了研究,取得了一定的数据资源和研究成果。李云心[1]通过分析以往的网络欺凌案例,总结了网络欺凌者的特点,为进一步研究网络欺凌提供了有力的线索。Chen等人[2]以Youtube的攻击性评论为语料,在利用词袋的基础上增加了词汇句法特征,从句子和用户两个方面提取特征融合,检测它是否具有攻击性。Burnap等人[3]通过一种基于规则的方法,以相关术语为特征对Twitter上的敌对内容进行分类。Djuric等人[4]基于词向量模型,提出了用段落向量的神经网络算法,该算法中的段落向量内部使用词向量,相对于直接使用词向量的方法有更好的性能。Silva等人[5]分析了推特等两个社交平台中网络欺凌群体的特征,推断出最容易受到欺凌的六个特征:性、种族、习性、品质、性别和阶层。Zeerak Waseem等人[6]以Twitter上种族歧视和性别歧视的仇恨言论语料,采用基于字符的n-gram方法,考虑了词序信息,信息量更充分,F值达到73.93%。
以上表明,针对英文的研究取得了一定的成果,而中文对于性别欺凌的研究相对较少。传统采用的基于词法、规则、句法分析的方法,在欺凌词汇识别上效果显著,但是词与词之间的彼此依赖效果不明显。基于词向量的传统深度神经网络,通过向量建立了词序之间的联系,在一定程度上提升了识别率。但是,忽略了上下文语境信息,不能深层次的挖掘语义特征。
因此,该文提出CASC算法模型,用于识别网络性别欺凌文本。将富含上下文语境信息的词向量,加入注意力机制,作为CapsNet和Srnn的输入,从CapNet中获取全局语义信息;通过Srnn多个层级输入,获取其词级,句子级,段落级高级信息。两个模型并行处理各自擅长的特征,减少特征在传输过程中的丢失。最后将两者有效特征进行融合分类,完成对网络性别欺凌文本的识别。
2 基于语境的语料库构建
2.1 语料的收集
收集的语料包含新浪微博、天涯论坛和今日头条的性别欺凌评论,总计1004条,作为实验数据的正样本。此外,还在其它平台上收集了包含地域欺凌、人身欺凌、宗教欺凌和不含欺凌信息的评论,总计6024条,作为实验数据的负样本。表1列出了语料收集的详细信息。

表1 语料收集详细信息
2.2 语境的构建
在语言学中,语境即语言环境,它包括上下文的语言知识、背景知识、情景知识、说话人的特质、说话人与被评价对象的关系等。研究语境的目的是为了更好的理解语义,把握各类语境的特点和作用,会对语义的正确理解起到很好的导向和指归作用[7]。
目前,对于汉语语境的分类有了一定的研究。李长忠等人[8]认为受话人利用语境进行语义重构时对语境要素的选择要求很高,因此按照语境因素,将语境分为从语言语境、情景语境、背景语境、文化语境和主观语境;刘舰等人[9]对语境特征进行了多元化分析,在语境特征描写时通过交流者,主题,交流手段、方式,正式、紧缓程度,时间空间五个方面来进行。为了更好的识别性别欺凌信息,在众多学者的基础上,该文建立了适合性别欺凌识别的语境分类体系[10],如图1所示。
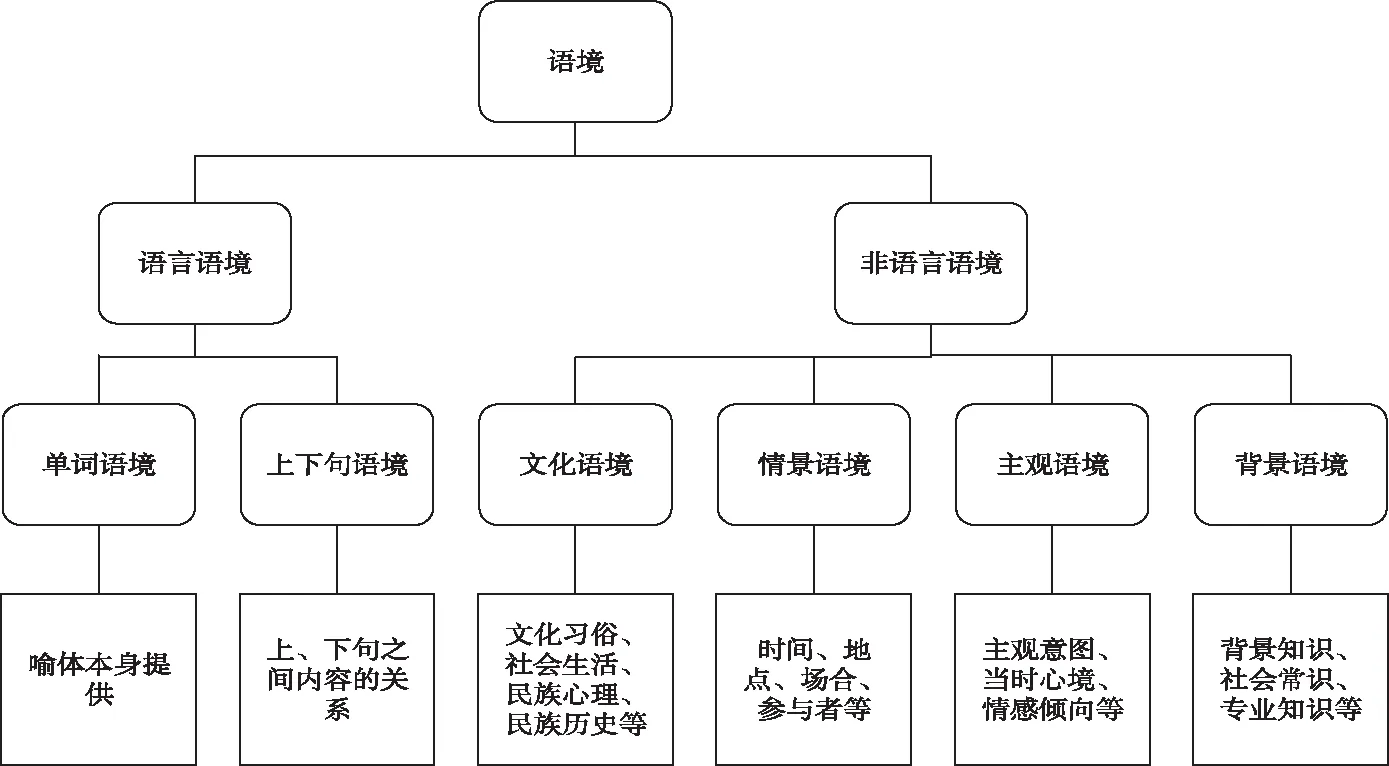
图1 性别欺凌识别的语境分类体系
单词语境是由句中喻体本身提供,带有明显侮辱性、仇恨性、攻击性等性质的欺凌词汇。例如:八婆、绿茶婊、伪娘等。
上下句语境是指前部分内容与后部分内容之间存在一定的关系。例如,“那个女人真漂亮,开那么炫酷的车,品位真好,肯定是被包养的”。该句中前部分夸女性长得漂亮、有品位,是褒义;而后部分嘲讽女性是被包养的,是贬义。如果没有上下句语境的关联,很难判断为性别欺凌。
文化语境指言语交际双方内容,涵盖地方性或民族性的社会文化,包括文化习俗、社会生活、民族心理、民族历史等。例如,“夜店的女人都是潘金莲”。句中“潘金莲”一词在中国历史文化中富含贬义,一般指“轻浮”、“红杏出墙”的女性形象。因此,此处是对夜店女性的一种偏见,属于性别欺凌。
情景语境划分为外部关系和内部关系。外部关系包括时间、地点、场合、话题、谈话对象关系等,内部关系包括谈话对象的身份、地位、地域、性别、阶层等,内部关系和外部关系相互提供线索,构成情景语境。例如,“夜晚,妇产科医院楼道,婆婆对儿媳妇说,这科室怎么还有男医生啊”。句中“妇产科医院楼道”,属于外部关系,被欺凌对象是句中“男医生”,属于内部关系,在这种语境下,两者相互联系,可以分析出,这是对妇产科男医生的一种歧视,属于性别欺凌。
主观语境往往带有个人主观意图、当时心境、情感倾向等特点。例如,“彩莲与男朋友分手后,回来就对我说,男人都是大猪蹄子”。句中“彩莲”由于和男朋友的分手,受到主观上的影响,对男性做出“大猪蹄子”的评价,是对男性的一种歧视,属于性别欺凌。
背景语境是由背景知识、社会常识、专业知识等外部背景元素与被欺凌者或欺凌者之间构成的一种内在联系。例如,“继上次重庆公交坠江事件,又多了一个女人抢方向盘”。句中“重庆公交坠江事件”是一种背景知识,与句中被欺凌对象女性存在内在联系,如果不了解事件是由于女乘客抢夺司机方向盘而引起坠江的背景,就难以判断是对女性的歧视,是一种性别欺凌。
2.3 基于语境的语料库标注
语料库标注其结果是带有标注信息的语料库。为了更加准确、有效地描述性别欺凌文本,该文结合传统标注体系结构和性别欺凌语境体系结构,对性别欺凌语料进行了标注。
2.3.1 欺凌角色及属性标注
网络欺凌往往都存在一些角色及角色属性,实施欺凌的一方标注为欺凌者,受害的一方标注为被欺凌者,参与整个事件但未发起欺凌的角色标注为旁观者。而这些欺凌角色往往具有明显的群体特征,如一种肤色的群体攻击另一种肤色的群体,一个宗教信仰的群体攻击另一个宗教信仰群体等。为了完善欺凌语境,同时标注了民族、宗教、性别、职业、阶层、教育层度、地域等欺凌角色属性。
2.3.2 性别欺凌标注
通过手动标注“是”和“否”标签,来确定每一条语料是否存在性别欺凌。在收集的语料中,除了包括带有明显欺凌词汇的性别欺凌评论,还包括隐式性别欺凌评论,一般通过隐喻和反语的方式表达。例如,在图4的语境下“优良传统”是褒义,而在图5的语境下,则是贬义,是反语表述。

图2

图3

图4
3 切片循环神经网络和胶囊网络
该文提出了Att_CapsNet_Srnn算法模型,用于识别网络性别欺凌文本。模型分为三层:注意力矩阵输入层,联合处理层,融合分类层。首先,将语料训练为词向量,利用注意力机制计算词向量的权重,将性别欺凌识别结果与词向量建立某种关联,获得基于词向量的文本特征注意力矩阵,作为联合处理层的输入。然后,通过胶囊网络挖掘全局语义信息,同时通过Srnn逐层获得时序词级、句子级和段落级深层语义高级信息。最后,将联合处理层的两个输出进行特征融合和分类,完成性别欺凌识别任务。图5为模型结构图。
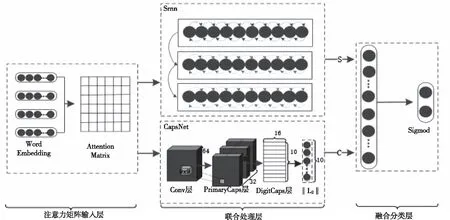
图5 模型结构图
3.1 注意力矩阵输入层
将标注的语料放入Glove词向量训练模型,获取全局的先验统计信息,控制词的相对权重,使欺凌语句映射为高维空间词向量,通过计算矩阵向量来反映词与词之间的关系。再通过注意力机制计算权重,获取特定语义信息并实现信息流整合,作为联合处理层的输入。
3.1.1 注意力机制
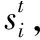
(1)
利用si的词向量矩阵和得到的词向量注意力特征矩阵运算,其中⊕表示拼接操作,即可以得到联合处理层的输入矩阵特征α
(2)
3.2 联合处理层
3.2.1 Srnn
切片循环神经网络(Sliced Recurrent Neural Networks)是由Zeping Yu等人[12]在2018年首次提出的算法模型,它可以并行化处理更长的序列,获得序列的顺序信息,通过多个层级获得高级信息。故该文选取Srnn来处理输入层特征α,得到富含上下文的深层语义特征β。
模型选取GRU作为循环单元。GRU是LSTM的变体模型,主要包含重置门和更新门。使用更新门替换了LSTM中的输入门和遗忘门,取消了LSTM中的输出门,增加了重置门,这样使之达到LSTM相近的效果下,减少了训练参数,降低了训练的计算开销,提高了训练速度。具体的计算公式如下
rt=σ(Wrxt+Urht-1+br)
(3)
zt=σ(Wzxt+Utht-1+bz)
(4)
其中x为输入,h为隐藏状态,σ为逻辑sigmoid函数,约束rt和zt从0到1的范围取值。
(5)
(6)
3.2.2 CapsNet
胶囊神经网络(Capsule Network,CapsNet)是由Hinton等人[13]提出,初始用于图像分类识别,它将传统CNN中的每个神经元标量输出,替换为向量输出,采用动态路由算法更新胶囊参数,取代了最大池化,有效减少了池化层所抛弃的一些有用信息,获取了更多全局语义信息。zhao等人[14]探索胶囊网络,用动态路由算法进行文本分类,证明了胶囊网络在文本分类中的有效性。冯国明等人[15]构造基于胶囊的长、短文本分类模型,相对于传统深度学习模型,在准确率和收敛速度上都有所提升。故本该文引入胶囊网络处理输入层注意力特征矩阵α,得到富含全局语义信息的特征θ。
在胶囊网络中,每一个胶囊神经元都是向量,因此,每个胶囊神经元相应的权重Wij也是一个向量。胶囊网络的输入线性加权求和类似于全连接神经网络,但在线性求和阶段上,加上了一个耦合系数Cij,具体计算公式如下
(7)
(8)
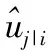
耦合系数表示每一个低层胶囊与其相对应的高层胶囊之间的权重,Cij它由胶囊网络中采用的动态路由算法softmax函数决定,计算公式如下
(9)
其中,bij表示胶囊i和胶囊j的对数概率,其初始值为0,不断的迭代更新cij的值,bij更新计算公式如下
(10)
胶囊网络采用了向量的新型非线性激活函数Squashing,该函数将输入向量的模控制在0到1之间,保留了输入向量的方向,输出的vj计算如下
(11)
3.3 融合分类层
本层将联合处理层富含上下文的深层语义特征β和全局语义特征θ进行融合,然后将融合特征q输入到一个全连接层,得到输出n,最后通过sigmod函数完成分类,具体操作如下
q=β⊕θ
(12)
其中,⊕表示向量拼接,即将特征β拼接到特征θ之后
(13)
其中,S(n)的取值范围为0到1,若S(n)的值大于阈值时,则取值为1,表示当前样本为正例,判定该样本是性别欺凌;若S(n)的值小于阈值时,则取值为0,表示当前样本为负例,判定该样本不是性别欺凌。
4 实验与分析
4.1 实验数据
该文将提出的方法在中文性别欺凌语料库上进行实验,用以完成性别欺凌识别任务。将性别欺凌识别问题看作二分类问题,数据包含1004条正样本和6024条负样本,详见表1。在实验过程中,该文采用哈工大的LTP分词工具进行分词,然后对语料进行预处理。使用Glove模型算法生成词典,词典语料容量为88905条,通过词典匹配样本训练词向量,运用词的全局统计信息和局部统计信息来生成语言模型,使词得到向量化表示,每一个词对应的词向量维度为100维。最后,将实验数据放入不同的神经网络模型进行实验对比,验证了CASC算法模型的有效性。
4.2 超参数
为了避免实验过程中出现偶然现象,确保数据的随机性,实验采用了五折交叉法进行验证,经过反复实验,在实验结果中显示,表2的模型为最优参数设置,分类效果达到了最佳。
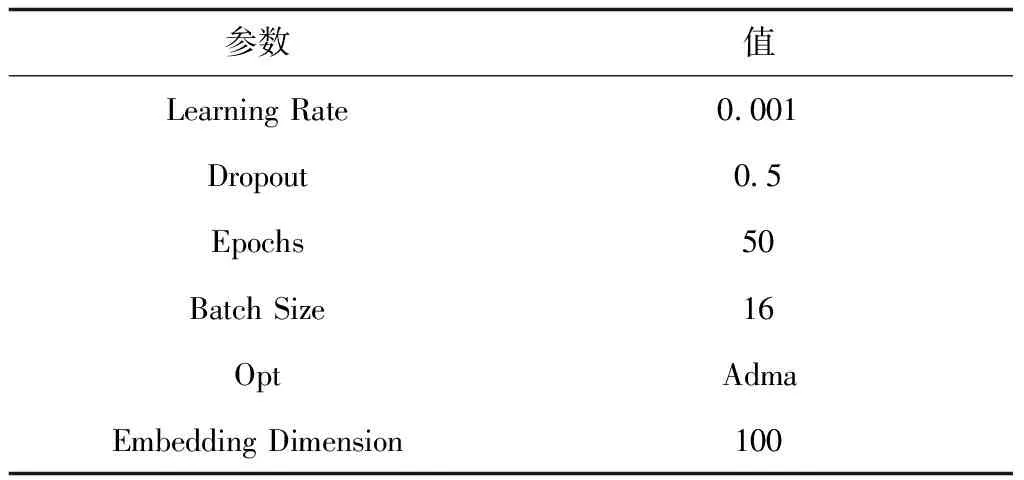
表2 实验参数设置
4.3 实验设计
为了探索不同角度下性别欺凌识别的效果,该文设计如下4个实验:①CASC模型与其它模型的对比;②词向量维度对性别欺凌识别性能的影响;③正负样本比例对性别欺凌识别性能的影响;④Srnn模型算法改进对性别欺凌识别性能的影响。
4.3.1 CASC模型与其它模型的对比
为了验证该文提出的CASC算法模型的有效性,将该文模型与传统的CNN模型、LSTM模型、Srnn模型、CapsNet模型、Srnn与CapsNet组合模型做对比。表3给出了在最优参数设置下不同模型的实验性能。

表3 CASC模型与其它模型的对比
由表3可知,Srnn模型与传统的LSTM和CNN相比,F值分别提高3.23%和1.66%,Acc分别提高0.43%和0.36%,这是由于Srnn更加擅长处理时序,通过多层循环单元捕获了更深层次的上下文语义信息。同样CapsNet模型与传统的LSTM和CNN相比,F值分别提高6.94%和5.37%,Acc分别提高1.92%和1.85%,这是因为CapsNet获取了更多全局语义信息,对于识别隐式性别欺凌更加有效。两个单独的模型组合在一块,F值到达了94.98%,Acc值提高为98.5%,可以看出,CapsNet_Srnn模型,提升了模型识别性能,同时提取了深层次的语义信息和全局的语义信息。CASC模型与CapsNet_Srnn相比,加入了注意力机制,F值和Acc分别提高0.6%和0.28%,这是因为注意力机制,通过注意力概率权重分配机制,关注了欺凌语句中更关键的信息。结合组合模型和注意力机制的优点,使实验模型达到了最优。
4.3.2 词向量维度对性别欺凌识别性能的影响
词向量反映了词的功能和上下文语义信息,不同维度的词向量,对实验分类效果有影响。因此,该文分别训练了10、50、100、150维的词向量,生成词向量特征矩阵,进行实验。实验结果如图7所示。
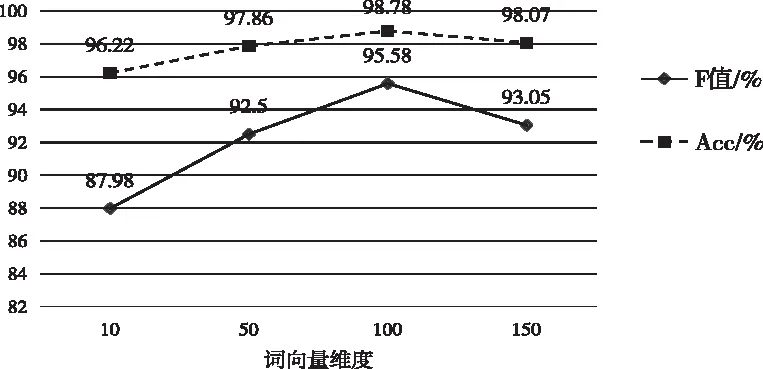
图6 词向量维度对性别欺凌识别性能的影响
由图4可知,词向量维度由10维向量增加到50维向量时,F值和Acc提升最显著,分别提高4.52%和1.64%,可以看出,随着词向量维度的增加,词向量富含的语义信息越多,并在100维时F值和Acc达到最佳。当词向量维度增加到150维时,F值和Acc分别下降2.53%和0.71%,这是由于,词向量维度太高,捕捉了语料中的噪声,从而过拟合,使实验性能有所下降。
4.3.3 正负样本比例对性别欺凌识别性能的影响
为了提高鲁棒性,使模型性能更加稳定,该文对语料的正负样本比例进行了处理,保持正样本数量不变,改变负样本数量,分别在正负样本比例为1∶2、1∶4、1∶6、1∶8的规模下进行了实验。实验结果如图8所示。
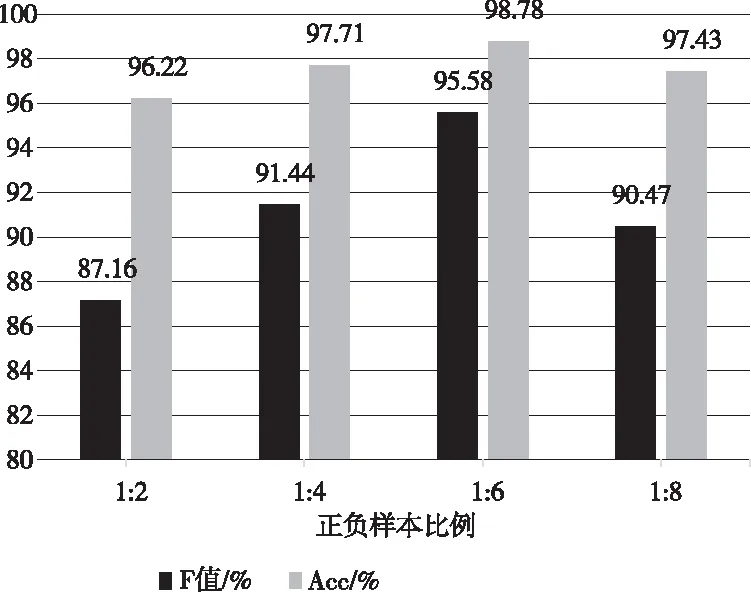
图8 正负样本比例对性别欺凌识别性能的影响
由图5可知,随着语料负样本数量的增加,F值和Acc逐渐提高,并在正负样本比例为1:6时F值和Acc达到最高,但正负样本例超过1:6之后,F值和Acc均有下降。说明当负样本比例较小时,模型不能很好的识别数据中的负例,使得F值和Acc比较低;然而,随着负样本比例的不断增加,超过一定值时,训练数据中的正例样本比例变小,模型不能很好的识别正例样本,识别率也降低。因此,该文在调整实验数据正负样本比例时,控制在1:6的范围,使实验效果达到最佳。
4.3.4 改进的Srnn算法模型对性别欺凌识别性能的影响
Zeping等人提出的Srnn算法模型,是通过将序列切割成许多子序列,并通过多层GRU循环单元并行化处理,从而获取序列的高级信息。但是,实验过程中发现,不切片的Srnn算法模型,对识别性别欺凌文本更加有效。实验结果如表4所示。
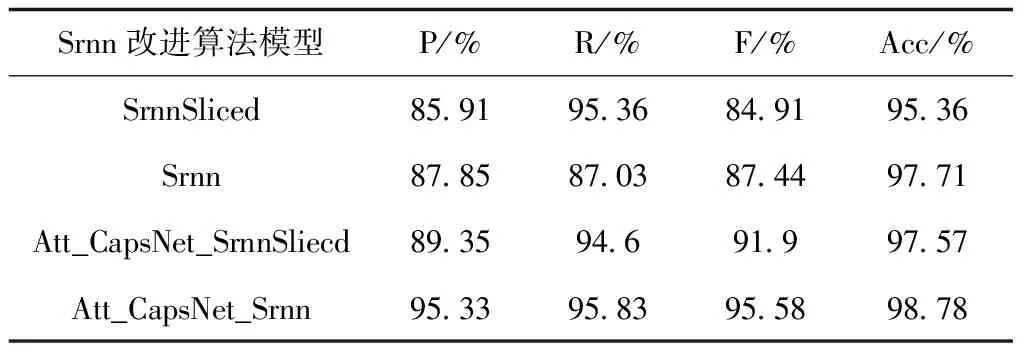
表4 改进的Srnn算法模型对性别欺凌识别性能的影响
由表4可知,Srnn的算法模型,不切片的Srnn比切片的SrnnSliced的 F值和Acc分别提高2.53%和2.35%,这是因为,对序列切片后,再通过GRU循环单元,获取多层级高级信息时,虽然提高了模型的训练速度,但是丢失了原序列上下文的语义信息,使识别率降低。为了进一步验证,将这两种模型融入到组合模型中,可以看出,不切片的Att_CapsNet_Srnn比切片的Att_CapsNet_SrnnSliced性能更好,F值和Acc分别提高3.68%和1.21%。因此,该文采用了不切片的Srnn组合模型,使实验效果达到了最佳。
5 总结
如今,在识别网络性别欺凌文本的任务中,大多传统研究方法都是基于词袋、规则、句法分析和基于词向量的传统深度神经网络等方式进行,这些方式往往依赖原始词特征,忽略了词与词之间的依赖性和上下文语义关系。基于以上不足,该文建立基于语境的性别欺凌语料库,提出CASC并联联合算法模型。利用基于词向量注意力机制的深度学习模型算法挖掘深层语义特征,通过胶囊网络获取全局语义信息,同时通过Srnn逐层挖掘时序词级、句子级和段落级上下文语义高级信息,应用于隐式性别欺凌识别。实验结果表明,该文提出的CASC算法模型对网络性别欺凌文本识别任务更有效。
