基于稀疏度自适应的视觉图像三维清晰重构
2021-11-17马丽茵
石 磊,马丽茵
(北方民族大学,宁夏 银川 750021)
1 引言
人类通过视觉系统获取大量的外界信息,其中图像信息占主要部分[1]。在信息处理领域中图像处理技术是重要内容,人们对图像分辨率的要求随着图像在不同行业中的广泛应用不断提高[2-3]。图像分辨率成为重要指标可以对图像的质量进行衡量。由于系统噪声、大气振动、离散采样、成像器件与目标之间存在的相对运动等影响,会降低图像分辨率,导致在实际应用过程中采集的图像都无法满足人们的需求[4-5]。为了提高图像的分辨率,需要对图像进行三维重构处理。
文献[6]提出基于非局部全变差的图像三维重构方法,该方法根据目标图像结构与参考图像结构之间存在的相似性,获得小波域中图像的搜索集,将其作为范数,利用非局部全变差建立图像重构目标函数,并采用快速合成分离算法对目标函数求解,实现图像的三维重构,该方法没有对图像进行去噪处理,导致图像的峰值信噪比较低。文献[7]提出基于卷积神经网络的图像三维重建方法,该方法利用锐化方法和差值方法对图像进行预处理,通过差值操作获得图像的三维矩阵,在深层残差网络中输入三维特征映射获得图像纹理细节信息,通过亚像素卷积操作实现图像的三维重构,该方法对图像进行预处理时没有保留图像的细节信息,导致图像分辨率较低。文献[8]提出基于残差神经网络的图像重构方法,该方法建立残差神经网络结构对图像做压缩处理,通过上采样获得特征图,并对特征图进行优化,融合优化后的特征图实现图像的三维重构,该方法在重构过程中受噪声干扰较为严重,增加了重构时间,存在重构效率低的问题。
为了解决上述方法中存在的问题,提出基于稀疏度自适应的视觉图像三维清晰重构方法。
2 视觉图像去噪处理
基于稀疏度自适应的视觉图像三维清晰重构方法在非局部相似性原理的基础上提取相似图像块并对其进行分组,通过核回归系数获取图像中存在的集合信息,建立每组图像块的字典。将图像分为边缘、平滑和纹理三个种类,根据噪声水平和分组类型设计字典对应的原子大小,融合字典获得变分模型,通过变分模型实现图像的三维重构。
1)图像分组
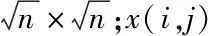

(1)
式中,ga代表的是高斯核函数,其标准差为a;h代表的是衰减系数,可以对函数的衰减速度进行控制;u0代表的是灰度值方差;Ω2代表的是局部区域,其中心点为(i,j)。分析上述公式可知,可以利用欧几里得距离衡量两个局部区域在视觉图像中的相似度[9]。w(i,j),(i′,j′)的值随着欧几里得距离的减小而增大。

fi=[λyi+(1-λ)wi]
(2)
式中,λ代表的是权重因子,在区间(0,1)内取值。采用K-means聚类算法划分图像块,由G组图像块构成噪声图像Y:
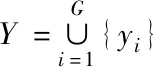
(3)
2)建立原子尺寸字典
根据每组图像的结构特征,建立对应的字典,稀疏表示图像,图像去燥模型的表达式如下
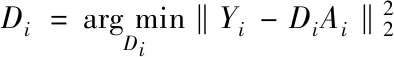
(4)
式中,i描述的是图像组对应的序号;m描述的是块在第i个图像组中对应的序号;Di代表的是字典,通过第i个图像组所学习获得;Ai描述的是稀疏编码系数。
每幅视觉图像通常由纹理细节、边缘细节和平滑区域构成,利用不同原子尺寸的字典处理图像的每一部分,提高图像的去噪效果。
基于稀疏度自适应的视觉图像三维清晰重构方法采用的字典学习算法由以下两个步骤构成:
①划分图像信息。
②在图像分组的基础上确定原子尺寸。
图像组的整体信息可以通过图像组Yg对应的质心ygc进行描述,其计算公式如下

(5)
基于稀疏度自适应的视觉图像三维清晰重构方法通过基于数理统计的变化稀疏对图像中区域的同质性进行测量,提高图像分组的精准度。变化系数cv(i)的计算公式如下

(6)
式中,I为正方形区域,其中心为yi。同质性随着变化系数的增大而变小。根据变化系数cv(i)的计算结果对图像块进行分类,将其分为边缘范畴、平滑区域范畴和纹理范畴。
计算每个图像组对应的原子尺寸,图像中存在的边缘细节和纹理细节可以通过小原子尺寸的字典得以保留,平滑区域图像中存在的较大噪声和原始信号可以通过较大原子尺寸的字典进行区分,提高去噪效果[10]。利用加权稀疏对图像组的字典原子尺寸进行计算
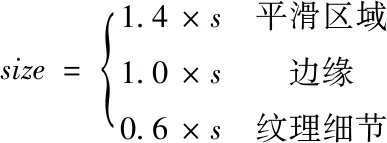
(7)
式中的系数s可通过噪声均方差σ进行确定。
3)建立变分模型


(8)
上式的左边第一项为数据保真项;R(α)描述的是限定解空间中存在的正则项。
考虑子信道pp′,qq′,根据式(17)可得到信道时变互相关性.图6和7分别是t=0和2 s时的归一化信道互相关性.图6和7表明,信道互相关性随时间发生变化,因此具有时变特性.当发射天线阵间隔固定时,随着接收天线阵间隔增加,信道互相关性下降.而当接收天线阵间隔固定时,随着发射天线阵间隔增加,信道互相关性呈现波动特性.
3 视觉图像三维清晰重构
3.1 K-SVD字典训练
基于稀疏度自适应的视觉图像三维清晰重构方法通过K-SVD字典训练算法训练类型不同的图像样本。
可利用下式优化问题描述K-SVD字典的训练实质
(9)
式中,T0代表的是非零元个数在稀疏系数中的最大值;Y代表的是样本集;X代表的是稀疏矩阵;D代表的是超完备字典。
K-SVD字典训练算法的主要步骤如下:
1)为字典D赋值。
2)采用追踪算法结合字典D对样本yi对应的稀疏系数向量xi进行计算。
3)利用xi对字典D进行更新,设dk代表的是字典D更新后存在的第k列原子;Ek代表的是误差矩阵,其计算公式如下
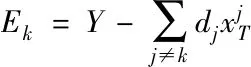
(10)
通过下述公式描述样本集分解后的形式

(11)
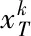

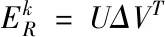
(12)
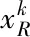
当稀疏误差达到收敛值或达到限制迭代次数时,停止迭代,获得最终的训练字典D。
3.2 感知矩阵
感知矩阵A=Rψ在大部分情况下需要符合限制等距性条件,即对于所有常数δk∈(0,1)和K-稀疏信号α,感知矩阵都要符合下式:
(1-δk)‖α‖2≤‖Aα‖2≤(1+δk)‖α‖2
(13)
基于稀疏度自适应的视觉图像三维清晰重构方法利用超完备字典替换正交变换基,在上述背景下,感知矩阵可描述为A=RD。为了满足限制等距性条件,基于稀疏度自适应的视觉图像三维清晰重构方法选用互相干MC代替感知矩阵,设μ(A)代表的是感知矩阵A对应的互相干,其计算公式如下

(14)
式中,αi代表的是感知矩阵A中存在的第i列向量。

(15)
存在下式

(16)
上式描述了互相干参数、稀疏度和重建性能之间存在的关系。
3.3 匹配跟踪
在图像重构阶段基于稀疏度自适应的视觉图像三维清晰重构方法将logistic回归函数引入正则化正交匹配追踪算法中,利用引进的函数计算原子对应的阈值Tn
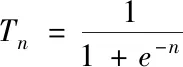
(17)
原子在每次迭代中都满足|ui|≥Tn·max|u|。
视觉图像三维清晰重构的过程如下:
1)计算感知矩阵与残差之间存在的相关系数u={uj|uj=
2)通过logistic函数获取原子对应的阈值Tn[12],选择的原子候选集J需要符合|uj|≥Tn·max|uj|。
3)正则化处理候选集J中存在的子集J0。在符合|ui|≤2|uj|的子集中选择存在最大能量值的子集。
4)对索引集进行更新。


(18)
4 实验结果与分析
为了验证基于稀疏度自适应的视觉图像三维清晰重构方法的整体有效性,需要对基于稀疏度自适应的视觉图像三维清晰重构方法进行测试。实验过程中用到的视觉图像为Bandrill、Barbara、Lena,上述图像均为512*512,在MATLAB R2010a环境中进行实验,硬件条件为内存4.0GB,频率3.30GHz,Intel(R)Core(TM)I3-2120CPU。分别采用基于稀疏度自适应的视觉图像三维清晰重构方法(方法1)、基于非局部全变差的图像三维重构方法(方法2)、基于卷积神经网络的图像三维重建方法(方法3)通过峰值信噪比和重构速度两个参数进行测试。
图1为分块大小为16*16的Bandrill、Barbara、Lena图像在采样率不同时,不同方法重构时间和峰值信噪比的对比结果。
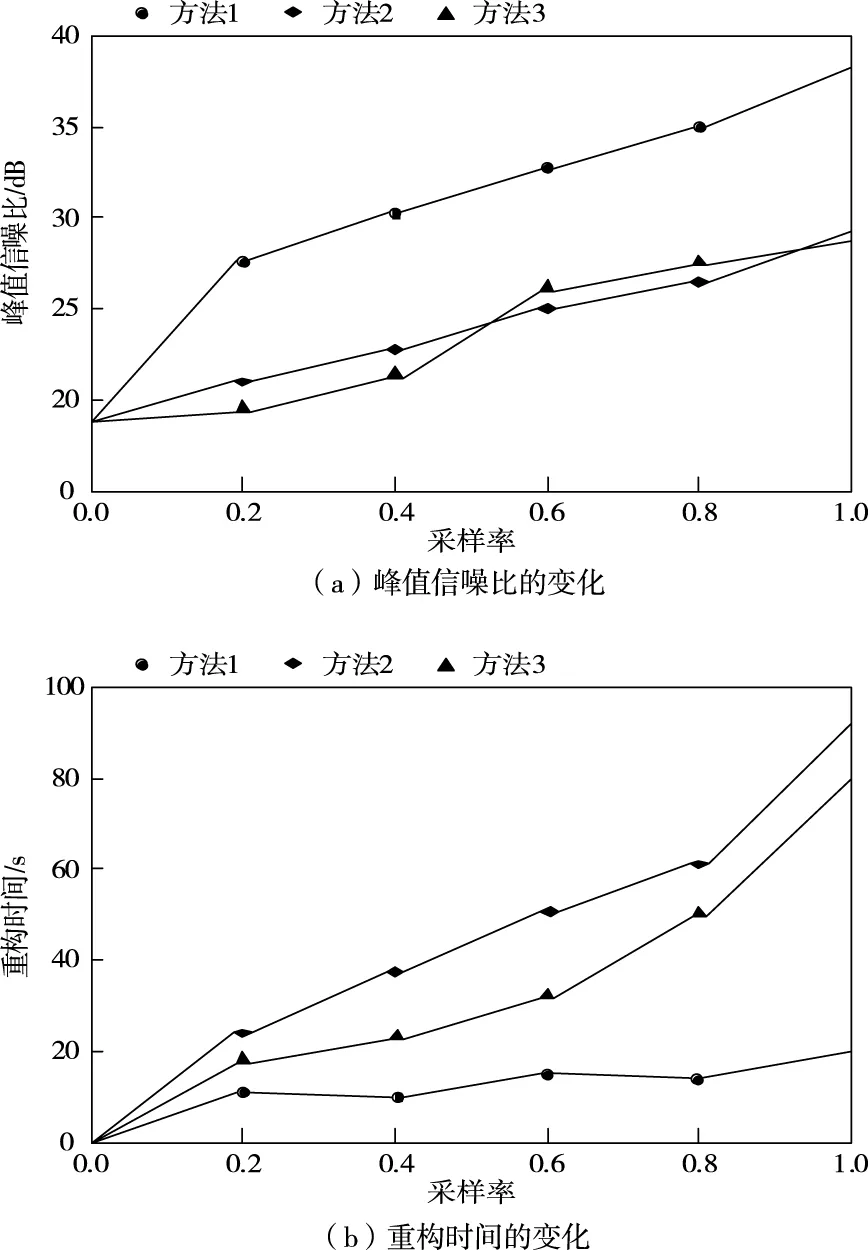
图1 不同采样率条件下各种方法性能图
分析图1可知,方法1在采样率低于0.5时可在较短的时间内获得良好的图像重构结果。方法2和方法3的重构效果随着采样率的增大明显提升,但运行时间较长,因为方法2需要确定图像信号的稀疏度,方法3需要根据视觉图像的噪声水平计算阈值,以上两种系数是不存在于视觉图像中的,因此花费了较长的时间。方法1在重构视觉图像之前,结合变分模型和学习字典对图像进行去噪处理,消除了噪声对图像重构产生的干扰,缩短了重构时间,提高了峰值信噪比。
为了进一步验证方法的整体有效性,将图像分辨率作为测试指标,图像分辨率越好,表明图像的重构质量越高,方法1、方法2和方法3的图像分辨率如图2所示。
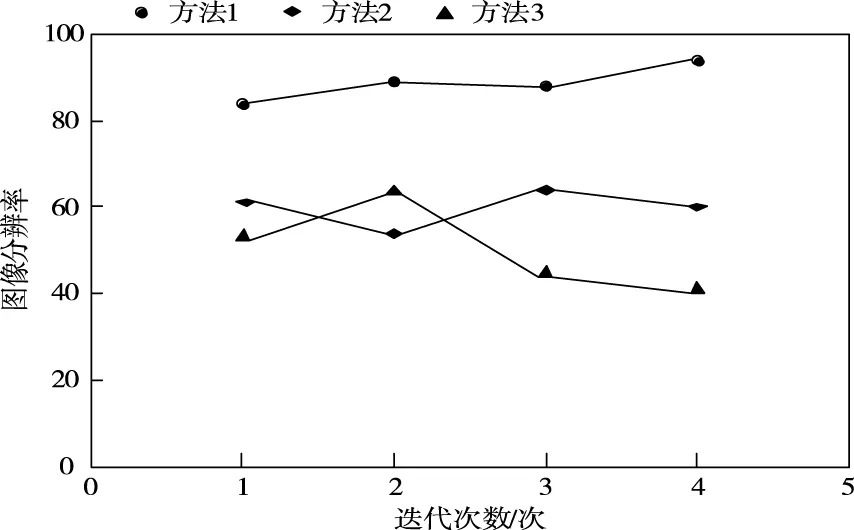
图2 不同方法的图像分辨率结果
分析图2中的数据可知,方法1在多次迭代中的图像分辨率均高于方法2和方法3,因为方法1在去噪过程中利用小原子尺寸字典保留图像中存在的边缘和纹理细节信息,利用较大原子尺寸的字典区分图像中的噪声和原始信号,提高了图像的去噪效果,进而提高了图像的分辨率。
5 结束语
在图像处理过程中图像重构是重要部分,图像重构的本质是有效地重建图像中存在的局部破损信息,使重构图像的整体视觉效果接近原始图像。在特技渲染、机器视觉、图像解压缩、视频修复等领域图像重构具有重要的应用价值和研究意义。目前视觉图像重构方法存在峰值信噪比低、重构时间长和图像分辨率低的问题,提出基于稀疏度自适应的视觉图像三维清晰重构方法,结合变分模型和学习字典对图像进行去噪处理,采用稀释度自适应正则化正交匹配追踪算法实现视觉图像的三维重构,提高了峰值信噪比,缩短了重构时间,增强了图像分辨率,为后续的图像处理过程奠定了基础。
