基于信息融合的电子档案系统信息储存优化
2021-11-17于翠萍赵志刚
于翠萍,赵志刚
(1.辽东学院 ,辽宁 丹东 118001;2. 齐鲁工业大学(山东省科学院),山东 济南 250014)
1 引言
互联网信息时代的发展对人类社会产生巨大影响。电子档案作为重要信息保存方式已经逐渐融入到人们生活与工作的各个领域,增加了获得信息的途径。尤其是政府与各事业单位,每天都会形成大量电子档案。除此之外一些图片、音频等文件都会选择电子档案方式进行储存。电子档案作为信息高速发展的产物,和传统纸质档案相比差别较大,它是指存在价值的以视频、图像、文本等形式通过固定格式封装的电子信息集合,一般将磁盘与光盘作为储存介质。由于电子档案高度推广与应用,在为人们带来便利的同时出现数据泄露、档案篡改等问题。因此如何建立安全高效的储存系统已经成为研究焦点。
针对上述问题,相关领域对电子档案管理工作模式进行创新,具体措施如下:以人为本,提高相关工作人员素质;改革工作方式,建立工作规范;创新服务方法,加强档案资源建设。除此之外,一些学者还提出下述解决方案。文献[1]为改善网络负载拥塞现象,提出基于Hadoop的网络行为大数据安全储存系统。首先,规划数据接收与识别模块,实现对数据的安全过滤;其次,分析识别地址,在保持较好处理结果基础上,对识别后的数据进行导入和储存;最后,搭建系统软件环境,再结合硬件基本条件,完成储存系统设计。实验结果表明,该方法可以降低储存空间占用率,缓解网络负载拥塞现象。文献[2]提出基于盲数BM模型的电网数据储存系统。针对储存方法安全性低等问题,通过盲数BM模型对数据进行提取,利用混合加密算法加密数据,构建谐波数据储存模型;确定储存规则,并通过云端验证数据储存的完整性。
上述两种储存系统运行速度较慢,随着网络与密码技术的出现,再次推动电子档案储存的向前发展。基于此,设计出对大规模分布电子档案信息融合[3]的储存系统。信息融合主要指对不同传感器得到的信息做综合处理,消除存在的矛盾,通过信息互补,改善不确定性。通过对比实验,证明所提方法储存速度快,安全性能更高,能有效防止档案数据被篡改。
2 大规模分布电子档案信息融合研究
2.1 信息融合基本架构
组成信息融合架构的基本四个元素为:信息源,它能提供初始数据;信息转换与传递[4],可以实现信息预处理;信息互补,其作用是完成信息升华;信息融合处理报告,它能够显示融合处理的最终结果。基本架构图如图1所示。

图1 信息融合基本框架示意图
2.2 信息融合的层次分类
1)数据层次信息融合
数据层融合属于对相同量级的传感器初始信息直接融合,对未经处理的传感器数据进行综合分析,为最低层次的融合。该层次融合主要优势体现在:可以保持尽可能多的电子档案,获取其它层次没有的细节信息。缺点是:处理代价大,耗费时间长[5]。融合过程示意图如图2所示。

图2 数据层融合示意图
2)特征层次信息融合
特征层次的融合是中间层次融合,其过程为:首先对初始电子档案进行特征提取,再对特征信息做分析与处理,其可分为目标状态与目标特性融合。
特征层融合的好处为:能实现信息压缩,达到实时处理目的,融合结果可以最大程度体现出电子档案的信息特征。融合过程如图3所示。
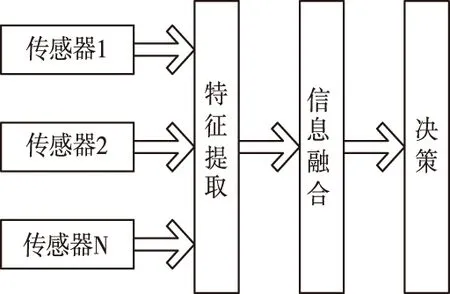
图3 特征层次信息融合示意图
3)决策层次信息融合
决策层信息融合主要为检测、操控与决策提供理论依据。需要从需求角度考虑,利用特征融合的信息实现决策融合,其结果直接影响决策的优劣。
决策层信息融合优势为:处理代价低,灵活性强,具有较强的抗干扰性能。
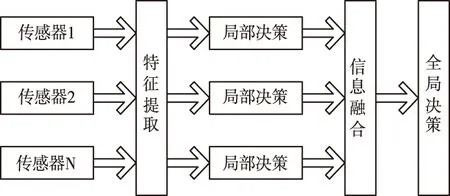
图4 决策层信息融合示意图
2.3 基于神经网络的信息融合技术
从信息融合角度出发,神经网络[6]属于存在高度非线性的大规模信息融合网络,可以将其当作多输入信号的一种融合系统。
2.3.1 神经元确定
神经网络的主要结构是神经元,通常被称为“处理单元”,又可称为“节点”。假设xi(t)代表t时间点神经元j收到的出自于神经元i的信息,oj(t)为t时间点神经元发出的信息,此时,神经元j的状态表达式为
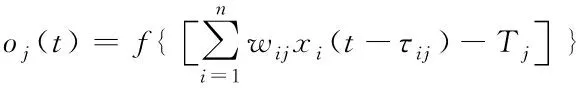
(1)
式中,τij表示输入与输出产生的突触时延;Tj为j的阈值,wij表示神经元i与j之间的突触连接系数;f(·)代表神经元转移函数。
为方便计算,将式(1)中的突触时延设置为单位时间,则将上述公式改写为

(2)
2.3.2 拓扑结构选取
单一的神经网络功能较为简单,只有利用拓扑结构[7]将多数神经网络连接起来,构成巨大的神经网络,才可以实现对电子档案的储存,并体现出优越性。本文选取互连型拓扑结构对储存系统进行研究。
互连型结构为网络中随机两个单元之间均是互相连接的,如图5所示。

图5 互联型拓扑结构示意图
2.3.3 学习规则分析
通常认为,神经网络的全部功能都储存在神经元中,学习是指神经元之间对现有连接的修正。因此,神经元在根据一定结构形成神经网络后,需要利用相关学习规则对连接权值与阈值进行更新。本文通过Hebb规则[8]对神经网络学习。
在Hebb学习规则中,学习信号可以看作是神经元的输出
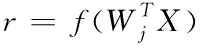
(3)
对于权值向量的调整表达式为
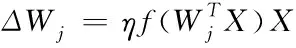
(4)

(5)
上述公式说明,权值调整量和输入输出的乘积具有正比关系。因此,输入模式对权值向量会产生较大影响。
采用神经网络对信息进行融合,主要分为下述步骤:
1)传感器选择,对于不同种类的信息融合,选择对应传感器[9];
2)采样与预处理,利用传感器对储存系统状态进行检测,且做预处理;
3)神经网络选取,结合不同电子文档特征,根据神经网络“三要素”,选择合适的模型;
4)网络的训练与学习,得到对数据的不确定推理机制或关系。

图6 基于神经网络的信息融合过程示意图
2.4 基于水印相似度的安全储存模型
特征水印相似度计算目的是检测储存电子文档与原始文档之间的重合程度。本文利用字符频率零水印算法建立安全储存模型。

图7 特征水印相似度模型示意图
如果T表示原始电子文档,B代表常用字符频度示意表,δ为文档T中全部字符集合,Ti(i=1,2,3,…,n)表示在δ中任意一个字符,V(Ti)是Ti在文档中出现的频率,ST(δ)代表集合δ中全部字符根据V(Ti)进行排序产生的序列,SB(δ)表示字符集合δ中全部元素根据字符序列频度B生成的集合。
基于字符频度[10]的储存模型,获取初始水印信息与待检测文档的水印信息,通过相关性函数预测两个水印存在的相似度。

β[S1(N),S2(N)]
=β1[S1(N),S2(N)]*β2[S1(N),S2(N)]
(6)
式中,β1代表初始水印信息S1(N)与待检测的水印信息S2(N)的相似程度比,β1=k/N。
通过最小二乘法预测电子文档排列顺序的相似程度,并计算两个字符排列顺序的差值平方
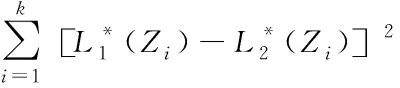
(7)
式中,两个序号之间的最大差值平方和计算公式为
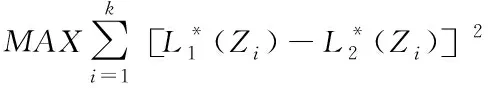
(8)
根据上述推导可知,原始电子文档水印信息S1(N)与待检测的水印信息S2(N)的相同字符排列相似度比值β2计算公式为:
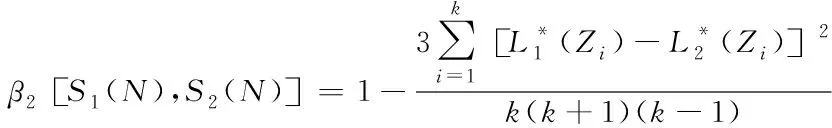
(9)
因此,相似度β=β1β2,则有
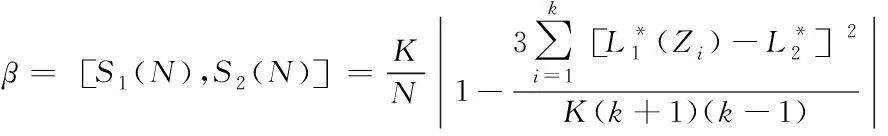
(10)
将以上获得的电子文档水印相似度[11]作为安全储存的基本原理对系统进行设置。
3 储存系统设计
设计大规模分布的电子档案储存系统,需要遵循高速采集与大容量储存的原则。基于此,分别对系统硬件与软件进行设计。
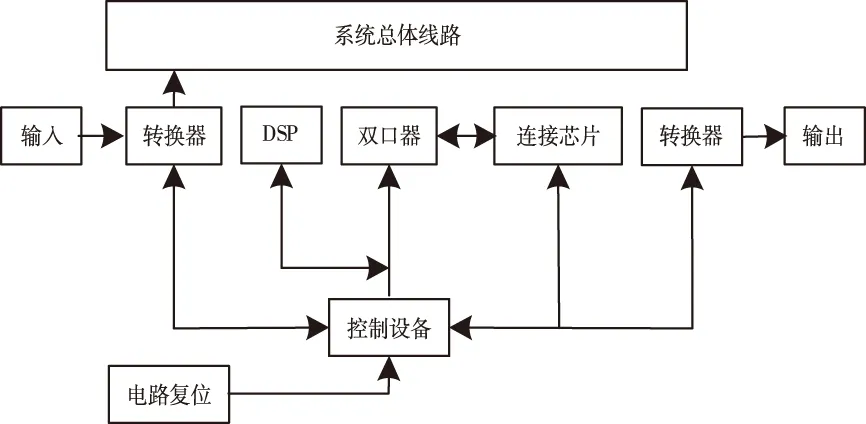
图8 系统总体架构示意图
由上图可知,电子档案储存系统主要包括:处理器、连接电路、计算机、储存器与复位器。
在此系统的总体架构中,电子档案的输入和输出是在触发与采集装置基础上进行设置的。数据触发总体线路和模拟总线路一起建立数据储存区域,把电子档案大数据进行收集并传送到控制计算机内,经过预处理模块达到系统设计目的。
系统的储存功能包括:
1)将PIC引入到系统处理器中进行缓冲区域运行;
2)信号处理芯片和储存空间可以互相连接,达到人类与机器通信目的;
3)利用计算机对处理器设计出合理的动态增益编码,确保电子档案稳定在一定区域内。
3.1 硬件分析
硬件部分的设计主要包括:电路同步与复位、系统触发装置、程序加载与储存接口设计。大规模分布电子档案的储存系统电路开关应选取12位采样数据的模块,对电路进行反馈采样。该系统线性动态范围设置为-50~50dB。根据电子档案特性,利用网络自动接口功能,对动态增益部分进行设计。
在互联网环境下对电子档案储存必须经过时钟同步的采样。在时钟电路端口,接入AD2018的四开关低通滤波,保证系统输出电压的稳定性。利用端口的缓冲能力,达到主机与档案传输实时通信的目的。
基于大规模分布电子档案储存系统的时钟同步电路能够设计和I/O设备相接的转换器。再将信息通道的数据采样模块换为16位,利用±15V的样本输入法,并通过转换其将TOUT变为CNNST。
3.2 软件设置
在硬件设备基础上,对软件模块进行规划。将设计高内聚、低耦合储存档案的模式作为目标。在大数据环境下电子档案存在分布广泛,样式多的特征,所以,软件分为储存层、逻辑层与访问层[12],分别对其进行设计。
储存层可以储存一定信息量,经过页面交互之后,发出指令,此时,储存层会与逻辑层相接,再将指令发送到储存层。
逻辑层起到承上启下的作用,分析并处理接收到的命令,利用数据接口将命令传送到访问层,实现大数据环境下的电子档案储存和取读。
访问层的主要作用包括:电子档案的存储和取读、插入和更新、查找和删除等。
软件中的储存算法对系统整体性能起关键作用,通常情况下的数据问题能够通过下述表达式进行解决

(11)
可靠性储存函数描述为

(12)
式中,p1,p2,…,pn∈2n表示n个数据的矢量,λ1,λ2,…,λn为数据产生的损失情况,g代表正则化函数,δ属于共轭函数,x表示初始数据变量,y为对偶数据的函数变量,t≥0是正则化函数的参数。
由式(12)能够获得约束软件函数公式
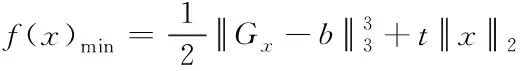
(13)
式(13)中,x属于变量,矩阵G描述n个数据的排列顺序。
4 仿真数据分析与研究
为验证信息储存优化方法设计的合理性,将其与文献[1]方法、文献[2]方法对比进行仿真。主要实验参数设置如下:电子档案储存在环形缓冲区域,数据浮动区间在-35~55dB,最大叠加量是95dB,数据转换器输出范围是±20V;数据收集通道数量为20个;数据采样功率是250Hz;控制器与放大器的分辨功率均设置为15位。
以下两幅图分别为两种方法在储存速度与储存空间方面的实验结果图。
分析图9可知,当实验时间为4ms,文献[1]方法的储存速度为200Mb,文献[2]方法的储存速度为100Mb,本文方法的储存速度为400Mb。当实验时间为10ms,文献[1]方法的储存速度为540Mb,文献[2]方法的储存速度为700Mb,本文方法的储存速度为1000Mb。本文方法的储存速度远远高于其它方法,说明本文方法的信息存储效率较高。
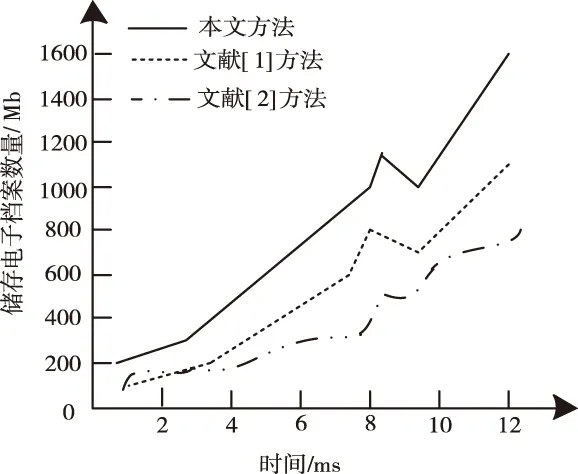
图9 不同方法储存速度折线图
分析图10可知,当电子档案量为5MB时,文献[1]方法的储存空间为80GB,文献[2]方法的储存空间为65GB,本文方法的储存空间为92GB。当电子档案量为30MB时,文献[1]方法的储存空间为81GB,文献[2]方法的储存空间为122GB,本文方法的储存空间为162GB。本文方法的储存空间远远高于其它方法,说明本文方法的信息储存空间较大。说明本文方法储存的电子档案数量更多。

图10 不同方法储存空间对比图
5 结论
针对传统电子档案储存效率低、安全性差的缺陷,本文对大规模分布电子档案信息融合储存系统进行设计。将信息融合分为不同层次,对其作用与优势进行研究;并将神经网络引入到信息融合中,构建电子档案安全储存模型;实现电子档案系统信息存储优化设计。通过实验得出以下结论:
1)本文方法的信息存储效率较高,实验时间为10ms,本文方法的储存速度为1000Mb。
2)本文方法的信息储存空间较大,能够储存的电子档案数量更多。当电子档案量为30MB时,本文方法的储存空间为162GB。
