低延时的浮点正弦余弦函数硬件实现算法
2021-11-16梁峰刘春锐李孝聪邱广波张继陈振娇李薇敏曹琪雷绍充
梁峰, 刘春锐, 李孝聪, 邱广波, 张继, 陈振娇, 李薇敏, 曹琪, 雷绍充
(1.西安交通大学微电子学院, 710049, 西安; 2.中国电子科技集团公司第五十八研究所, 214035, 江苏无锡)
具有正弦余弦函数计算能力的集成电路已被广泛应用于各个领域。通用芯片CPU、GPU和DSP中也有专门进行正弦余弦函数运算的硬件单元,例如TI的TMX320系列DSP芯片,其上有一个硬件纹理映射单元(TMU),专门用于实现超越函数的快速计算。
传统的正弦余弦函数的硬件实现,主要采用坐标旋转数字计算机(CORDIC)算法[1]。CORDIC算法的优势在于电路面积小,仅用移位寄存器和加法器/减法器就可以实现计算。但其缺点在于,它的收敛速度较慢,通常一轮迭代只能增加一个有效数字。对于单精度浮点运算,CORDIC算法需要较多的时钟周期才能使结果达到单精度浮点所要求的精度。基于此,有许多改进的CORDIC算法如Para-CORDIC[2-3]、Hybrid CORDIC[4]、Scale-Free CORDIC[5-7]等,或者使用循环展开的方式在一个时钟周期内做多轮迭代[8-11]。这些方法在一定程度上缩短了CORDIC算法的延时,但是仍满足不了低延时计算的需求。
除CORDIC算法外,有些设计采用了多项式拟合法[12-13]、泰勒级数展开法[14-15]、幂级数展开法[16-17]等算法。这些算法收敛速度较快,但是需要大量的乘法运算才能得到单精度浮点所需精度。
为了解决正弦余弦函数计算延时较大这一问题,本文提出了一种低延时的浮点正弦余弦函数硬件算法。该算法采用分段的思想将单精度浮点数输入按照指数范围的不同划分为3个不同区域,在这3个不同区域内分别采用不同的算法来保证计算的精度。同时,保证整体硬件模块在4个周期内完成计算。
本文结构主要分为算法、电路设计和实验结果3个部分。算法部分采用了3个算法,分别是泰勒0阶近似法、泰勒1阶近似法[18]和直接计算。由于泰勒0阶近似和直接计算比较简单,本文重点分析泰勒1阶近似算法。相应的,电路设计部分也将重点放在泰勒1阶近似算法的实现上。在实验结果部分,本文使用verilog硬件描述语言实现了提出的算法和电路结构,完成了精度测试,并在联电UMC 55nm的工艺和Altera Cyclone IV的平台上进行了逻辑综合。结果表明,该浮点正弦余弦函数硬件算法的计算精度与标准C语言math库单精度正弦余弦函数的计算精度相比,最多仅相差1个误差单位(ulp),并且能够在4个时钟周期内完成运算,具有低延时的特点。
1 低延时浮点正弦余弦函数硬件算法
本节算法所述的正弦余弦函数的数学形式为sin(2πx)和cos(2πx)。如果要计算siny和cosy,可做变换y=2πx,将其转换为sin(2πx)和cos(2πx)。在设计中使用sin(2πx)和cos(2πx)的形式,是因为在这种形式下,可以容易地将运算定点化,减少计算量,降低延时。
1.1 将输入的单精度浮点数划分区域
IEEE754标准所规定的一个规格化的单精度浮点数[19]x有32位,其中符号位为x[31];指数位有8位,从第31位到第23位,表示为x[30:23],它带有127的偏阶;尾数位有23位,从第22位到第0位,表示为x[22:0],它省略了一个隐含的整数位1。单精度浮点数x转换为一个实数(-1)x[31](1+x[20:0]2-23)2x[30:23]-127。为了避免歧义,在上下文中用“指数”这一用语表示x[30:23]减去偏阶127;用“尾数”表示{1′b1,x[22:0]},其中b代表二进制,括号代表将其连接为23位二进制数。
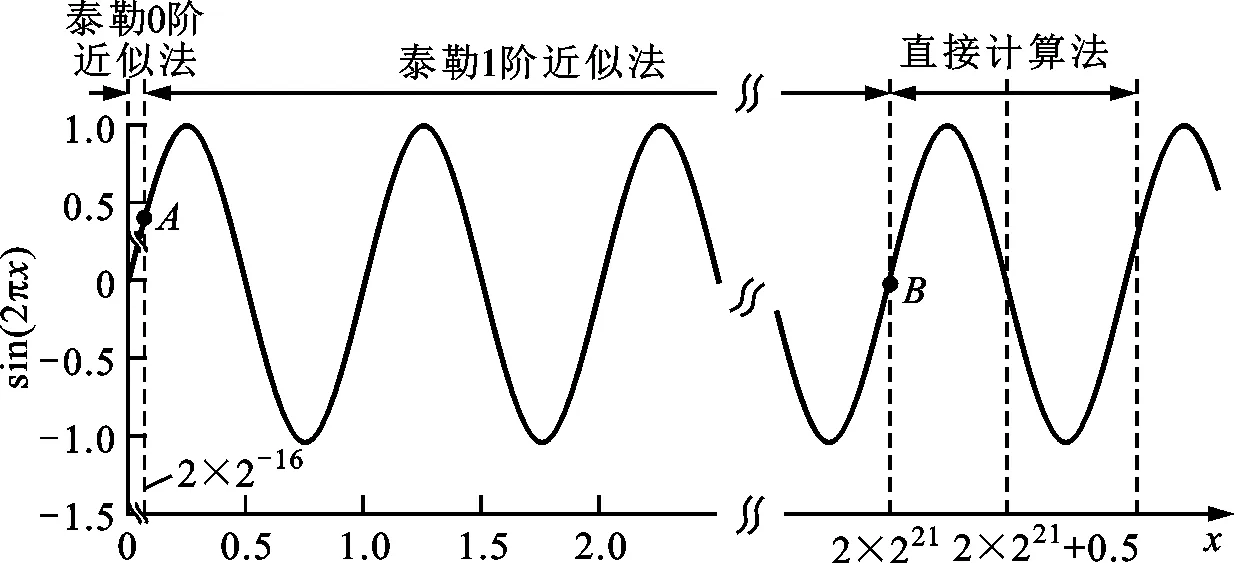
图1 正弦函数分段示意图Fig.1 Sine function segmentation diagram
对于正弦余弦函数,根据其数学特性,将输入按区间进行分段计算,正弦函数分段如图1所示。为了硬件容易实现,可按输入单精度浮点数的指数范围进行区间划分。一方面,根据三角函数的性质,当输入单精度浮点数的指数大于等于22时,该实数为(-1)x[31](1+x[22:0]2-23)2e,其中e为指数,e≥22。此时该实数必然是整数或整数点五的形式(此时e=22且x[0]=1)。对cos(2πx)函数,如果该实数为整数,则结果为1.0;如果该实数为整数点五的形式,则结果为-1.0。对sin(2πx)函数,无论该实数为哪种形式,结果均为0.0。由于指数大于等于22时,计算非常简单,因此在指数为22处进行分段。另一方面,分析三角函数的数学性质可知,当输入很小的时候有sin(2πx)≈2πx,cos(2πx)≈1.0,且输入越小等号两边的值越接近。因此必然存在一个指数使得sin(2πx)与2πx的误差以及cos(2πx)与1.0的误差小于单精度浮点数所能表示的最小误差。经过计算得知,该指数为-16,因此在指数为-16处进行分段。于是很自然的就将输入的单精度浮点数按指数范围划分为[-126,-16]、[-15,21]和[22,126]3个区间。
为了节省电路面积,可以将正弦和余弦函数合并为一个函数,此处定义了一个1位的指示信号cs,当计算正弦函数时cs=0,当计算余弦函数时cs=1。分段算法的步骤如伪代码所示。
当输入的指数在[-15,21]之间时,本文使用泰勒1阶近似法进行计算。在伪代码中,用函数Taylor1(x,cs)表示在这个区间内的计算方法。
伪代码:分段算法步骤
输入:单精度浮点数x,指示信号cs
输出:单精度浮点数y=sin(2πx)或y=cos(2πx)
1: if (cs==0) then
2: if (x[30:23]≥149) theny=0.0;
3: else if (x[30:23]≤111) theny=2πx;
4: elsey=Taylor1(x,cs);endif
5: else
6: if (x[30:23]≥150) theny=1.0;
7: else if (x[30:23]==149) theny=
(-1.0)x[0];
8: else if (x[30:23]≤111) theny=1.0;
9: elsey=Taylor1(x,cs);endif
10: endif
泰勒1阶近似法的主要步骤为:首先从输入的浮点数中提取符号标志位sx,诱导公式标志位f1、f2,构造一个定点数f。然后通过诱导公式[20]等一系列变换,将对浮点数x的正弦或余弦值的计算转换为对定点数f的正弦值的计算,得到sin(2πx)或cos(2πx)的定点数结果z。最后将该定点数结果z转换成浮点数格式。
1.2 将浮点运算转换为定点运算
将输入的单精度浮点数转换为定点数的一般方法的过程如图2所示。
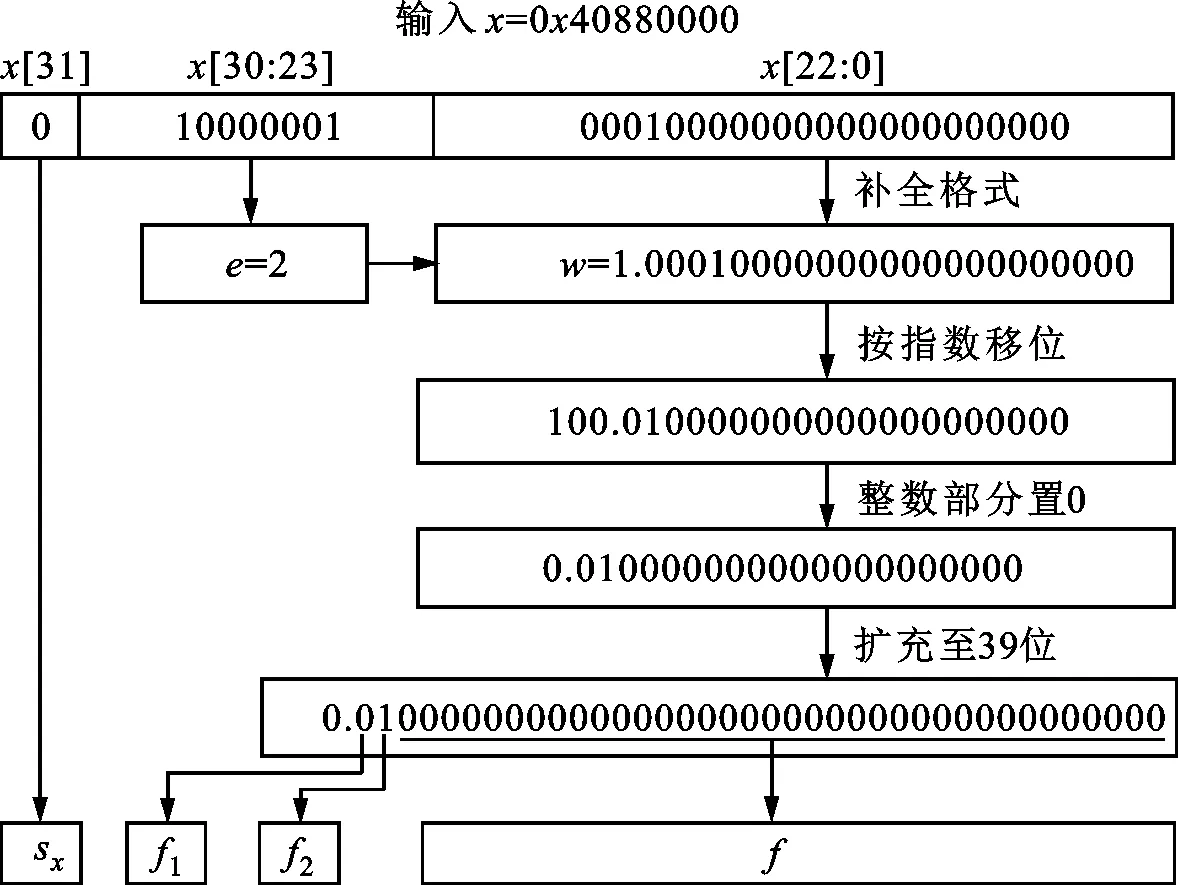
图2 浮点数转换为定点数的一般方法 Fig.2 General method of converting floating-point numbers to fixed-point numbers
在指数为[-15,21]的区间内,可将浮点数转换为定点数。按一般方法,首先应当计算出浮点数x的指数e,并补全尾数w={1′b1,x[22:0]}。如果e>0,则应该将尾数w的小数点右移e位;如果e<0,则应该将尾数的小数点向左移|e|位。考虑到sin(2πx)和cos(2πx)的周期均为1,所以移位后的定点数的整数部分可以直接置0。
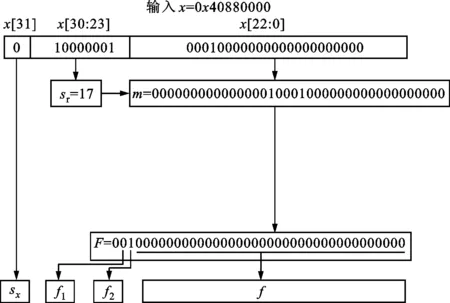
图3 浮点数转换为定点数的统一移位的方法Fig.3 Uniform shift method for converting floating-point numbers to fixed-point numbers
为了保证定点数的格式固定,考虑到整数部分必为0,规定使用1位做整数部分,小数点固定在整数部分的0后面。由于指数为-15的时候,小数部分位数最长,为23+|e|=38位,因此规定所有定点数都将小数部分扩充到38位。该定点数记为F。
用统一移位的方法得到上述定点数F。具体操作为:计算移位数sr=x[30:23]—112,然后将尾数按m={16′h0001,x[22:0]}的方式补齐到39位,其中h代表该数为16进制数,最后将m左移sr位。图3给出了浮点数转换为定点数的统一移位的方法。
输入的指数为-15时,将x[22:0]前面补上16′h0001,变成m={16′h0001,x[22:0]},正好是所需的定点数格式。指数为其他值时,只需计算它比-15大多少,就左移多少位。因此,统一移位的方法是正确的。下面给出一个具体的例子。
图2和图3所示为浮点数0x40880000转换为定点数的过程。图2所示为一般方法,先补全格式,然后按指数移位,整数部分置0,最后扩充到39位。图3所示为统一移位的方法。可以看到两种方法所得的定点结果是一致的。
1.3使用诱导公式将正弦余弦函数的计算转换为
[0,π/2)内的定点正弦函数计算
考虑到正弦和余弦函数关于π的诱导式为

(1)
关于π/2的诱导式为

(2)
根据1.2节所述已将浮点数x转换成了一个39位的定点数F。在该定点表示下,F[37]表示0.5所在位,F[36]表示0.25所在位,因此记f1=F[37],用于标记该定点数F的正弦或余弦值的计算是否可以使用诱导式(1)化简,同理记f2=F[36],表示是否可以使用诱导式(2)化简。结合变量f1、f2、cs以及符号位s判断需要使用的诱导式,就可以推导出最终符号位sy以及是否需要计算[0,π/2)内余弦函数的指示信号c,见表1。
表1中sy列为符号指示位,当化简后出现负号时,sy设置为1;c列为余弦计算指示位,当化简后需要计算余弦函数时,c设置为1。
使用上述诱导公式之后,对定点数F的正弦或余弦函数值计算就转换成了对F[35:0]的正弦或余弦计算,记f=F[35:0],其中F[35:0]表示定点数的第35位到第0位。考虑到0≤2π2-38f<π/2,因此sin(2π2-38f)或cos(2π2-38f)是取值在[0,π/2)内的正弦或余弦函数。
再考虑在[0,π/2)内的正弦和余弦有如下关系
cos(2πx)=sin(2π(0.25-x))
(3)
将x=2-38f代入式(3)可得下式
cos(2π2-38f)=sin(2π(0.25-2-38f))=
sin(2π2-38(236-f))
(4)
因此,所有[0,π/2)内的余弦函数的计算都可以转换为正弦函数的计算。236-f实际上就等于取f的补码~f+1,其中~表示按位取反。此处有一个例外情况:如果f=0,那么取反加1后,位宽就会超出36位,导致后面无法计算。该例外情况可以单独考虑:f=0和c=1时,相当于在求cos(0)=1.0,这个情况下,可直接输出结果1.0。
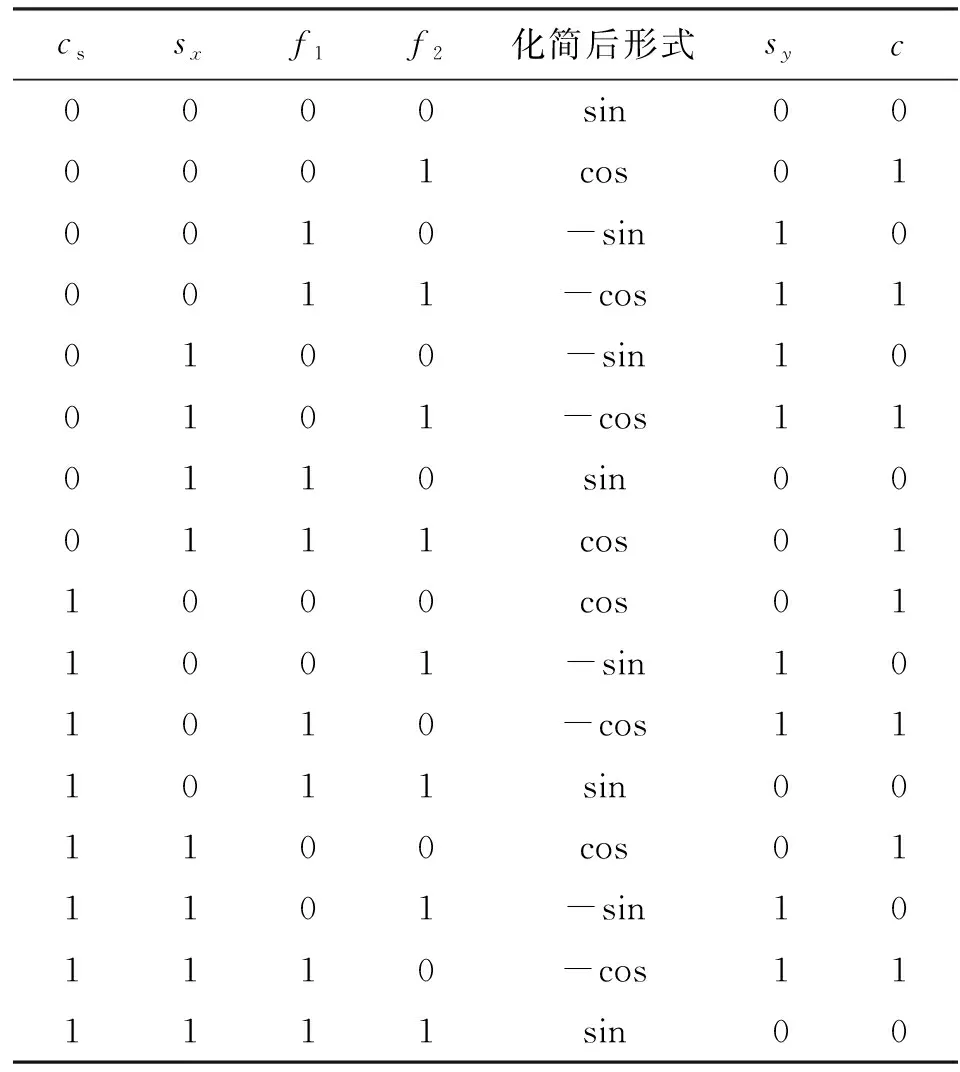
表1 使用诱导公式化简后的指示信号
1.4使用泰勒1阶近似计算[0,π/2)内的正弦函数
经过1.3节的变换,需要计算定点数f的正弦函数值sin(2π2-38f)。为了快速计算该正弦函数值,这里使用了泰勒1阶近似算法。它的核心思想是:将输入定点数f按照前m位和后36-m位划分为主要部分和次要部分[21],分别记作f3和f4,也即f3=f[35:36-m],f4=f[35-m:0],其中f[35:36-m]代表定点数f的第35位到第36-m位,f[35-m:0]代表定点数f的第35-m位到第0位。此时的f3和f4仍然是定点数,f3对应的实数为2-(m+2)f3,f4对应的实数为2-38f4。
考虑任意函数g(x)的泰勒级数展开式,令它在x0=2-(m+2)f3处展开,表达式如下
(5)
令x=2-38f=2-(m+2)f3+2-38f4,代入级数得到
(6)
将g(x)=sin(2πx)代入式(6),保留n=0和n=1两项可以得到
sin(2π2-38f)=
sin(2π2-(m+2)f3)+2πcos(2π2-(m+2)f3)2-38f4
(7)
式(7)即为所述泰勒1阶近似算法。
为了加快计算速度,可以使用查找表计算sin(2π2-(m+2)f3)和2πcos(2π2-(m+2)f3)两项。在图4中,LutSin(f3)和LutCos(f3)表示这两个查找表。这两个查找表的值仅和f3有关,若f3的位宽m取得越宽,则主要部分f3越接近定点数f的值,最终的结果也越精确。查找表的输出形式是类似于浮点数的形式。以st,se=LutSin(f3)为例,st是一个k位的定点数,它有1位的整数位和k-1位的小数位,se是8位的指数位。例如:取m=4,k=24,输入f3=(1101)2=13时,有sin(2π2-6×13)=(1.11101001111101000001011)2×2-1。因此,当查找表LutSin(f3)的输出st为k=24位的二进制数111101001111101000001011时,输出se为-1。
使用高级语言按上述方法建模,计算得出,当查找表参数取m=13和k=32时可以保证该泰勒1阶近似算法的精度与标准C语言math库单精度正弦余弦函数的计算精度相比,最多仅相差1 ulp。因此本算法中参数m=13和k=32固定不变。如果不需要高精度,可以减小查找表参数m和k以降低精度,同时减少查找表的大小。
当取查找表参数m=13和k=32之后,为避免使用浮点乘法和浮点加法,需要将式(7)的计算转换为整数运算。考虑式(7),中间计算过程中最小的数出现在2πcos(2π2-(m+2)f3)2-38f4这一项上,它的最小值出现在f3为全1且f4=1的情况下。在查找表参数为m=13和k=32的情况下可计算出这一最小值为2πcos(2π2-15(213-1))2-38×1=(1.0011101111010011110011000111101)2×2-48=(10011101111010011110011000111101)2×2-79。这个数是本算法中间过程里可能出现的最小的数,因此规定中间计算过程使用如下的80位定点数格式:整数部分使用1位来表示,小数部分使用79位来表示。
式(7)的计算过程如下:首先根据f3查表得到st,se=sin(2π2-15f3);ct,ce=2πcos(2π2-15f3)。令t1=st,计算t2=ctf4。然后计算移位数n1=se-31+79=se+48;n2=ce-31-38+79=ce+10。最后将t1和t2分别移位到规定的80位定点数格式,相加得到z。得到80位定点数结果的过程如图4所示。
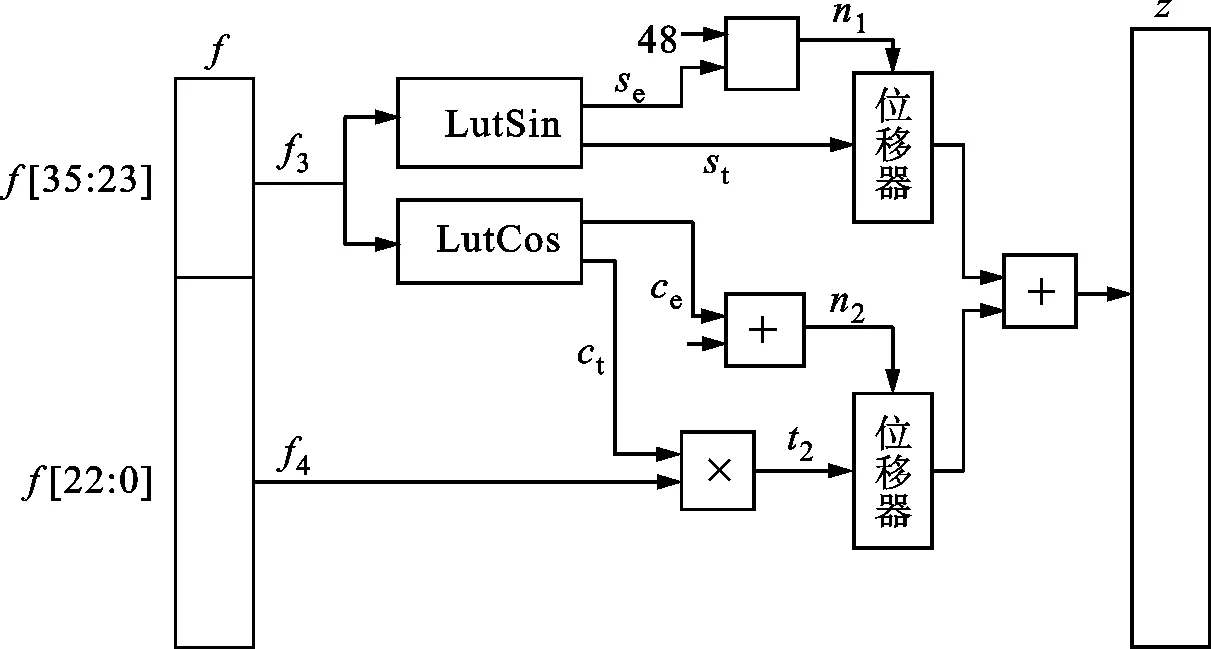
图4 得到80位定点数结果的流程图Fig.4 Flowchart for getting 80-bit fixed-point numbers
1.5 将计算结果定点数转换成单精度浮点格式
根据1.4节所述,z为定点数f的正弦函数值,它是一个80位的定点数。将z转换为单精度浮点数的步骤如图5所示。
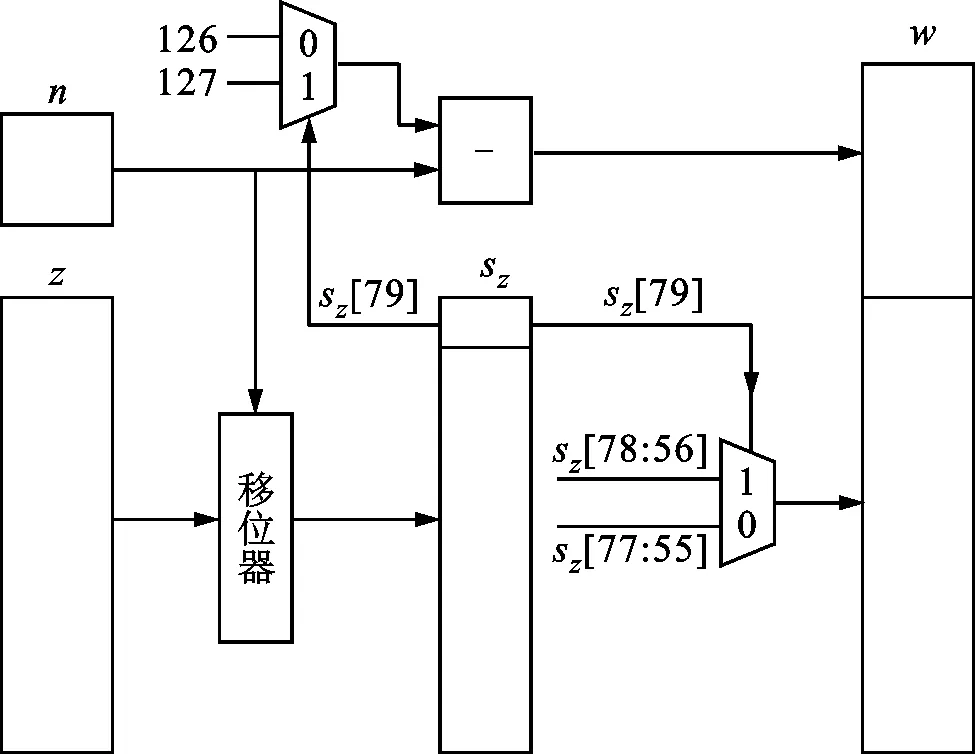
图5 80位定点数转换为浮点数的流程图Fig.5 Flowchart for converting 80-bit fixed-point numbers to floating-point numbers
将定点数z转换为单精度浮点数最直接的方法是:计算z的前缀0个数(即高位第一个1前面的0的个数)作为指数,取高位第一个1后面的23位作为尾数。由于计算前缀0的个数与后面的运算是串行的,会导致较大的延时。为减小这部分延时,本文提出了一个方法,其核心思想是:对[0,π/2)内的正弦函数,其函数值和输入是非常相近的,通常只会相差至多一个指数位,因此可以预先计算输入的指数,然后先行移位一次,再修正移位后的结果。
具体实现流程如图5所示:首先计算f的前缀0的个数n,然后将z左移n位,移位后可以保证最高位是1或者次高位是1。如果最高位是1,则指数为-n;如果次高位是1,指数为-(n+1)。尾数取最高位或次高位的1后面的23位。使用该方法可以提前计算出移位数n,从而减小了延时。
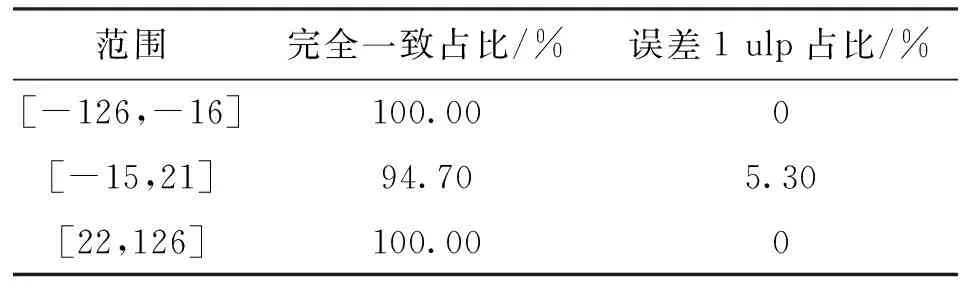
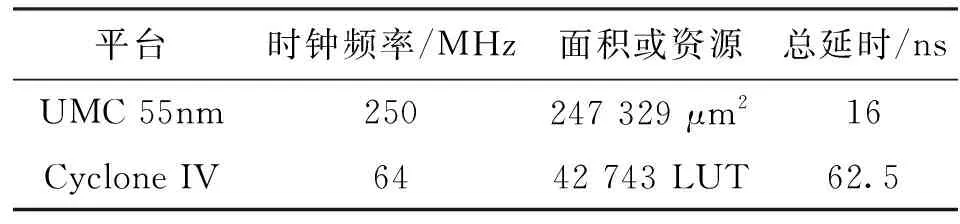
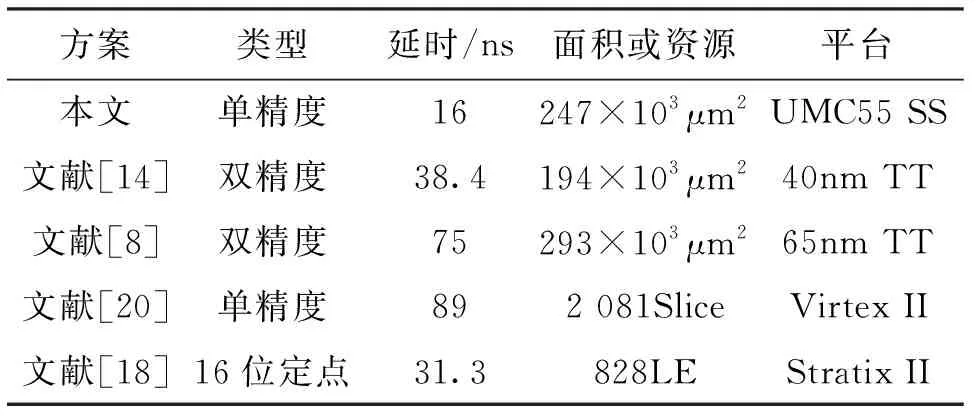
该方法的正确性可以通过如下方程式证明。假设f的前缀0的个数为n,则235-n≤f<236-n,于是有sin(2π2-(n+3))≤sin(2π2-38f) 使用本文提出的方法将定点数转换为浮点数后,再结合1.3节中所述的符号位sy,将它添加到相应的位置上,就得到了Taylor1(x,cs)函数的计算结果。 图6 浮点正弦余弦函数计算电路结构Fig.6 Floating-point sine and cosine function calculation circuit structure 正弦余弦函数的电路实现通常有流水线式和迭代式两种结构,本文采用流水线式结构来进行电路设计。 浮点正弦余弦函数计算电路的结构如图6所示,采用了4级流水线的方式。第1级实现了浮点数转换为定点数的逻辑,第2级和第3级实现了[0,π/2)内正弦函数值的计算,第4级实现了定点数结果转换成浮点结果。 图6仅显示了硬件实现主要部分的数据通路。输入指数范围在[-126,-16],[22,126]这两个区间时,由于算法较简单,图6未给出其数据通路。另外,c=1并且f=0这一特殊情况的数据通路在图中也未表示。 流水线第1级运算过程的主要任务有3个。一是将输入的浮点数x转换为定点数f,它的实现方式为先计算移位数sr=x[30:23]-112,然后将补位后的尾数m={16′h0001,x[22:0]}左移sr位。二是产生符号指示位sy。符号指示位sy由输入符号位sx、指示信号cs、诱导公式标志位f1和f2共同得到。根据表1,可以得到逻辑表达式sy=f1⨁(cs&f2)⨁(~cs&sx)。三是产生余弦计算指示位c。根据表1,可得出其逻辑表达式为c=cs⨁f2。电路中使用了一个多路选择器,根据c信号的取值选择f或者f的补码。 流水线第2级为[0,π/2)内的正弦函数计算的查找表部分。查找表常用的实现方式有组合逻辑实现和RAM/ROM方式实现。这两种方式各有优缺点。组合逻辑实现的优势是查找表操作可在1个时钟周期内完成,无需特殊工艺,缺点是电路面积较大。RAM/ROM方式实现的优势为占用芯片面积小,缺点为需要特殊工艺。本设计使用了组合逻辑方式实现查找表。根据1.4节所述,查找表参数固定为m=13和k=32,因此查找表LutSin和LutCos的输入为一个13位的整数f3,输出是32位的整数st、ct和8位的指数se、ce。组合逻辑实现该查找表会占用一定的面积,并且延时较大,因此本设计单独分配了一个时钟周期用于查表。 流水线第3级为[0,π/2)内正弦函数的计算部分,主要运算为移位运算和乘加运算。首先使用查找表的指数信息se和ce计算移位数n1和n2,同时计算32b×23b的整数乘法运算ctf4;然后将st和ctf4的结果分别移n1和n2位并相加,得到一个80位的定点数结果z。同时在这一个周期内计算定点数f的前缀0的个数n,用于最后将定点结果转换成浮点结果。 流水线第4级将定点结果z转换成浮点结果,使用1.5节所述方法,首先将z左移n位变成sz,此时sz最高位为1,或者次高位为1。因此只需用二选一多路选择器根据最高位sz[79]选取最高位或次高位的1后面的23位作为尾数m,并且选择指数e为127-n或126-n。将尾数m、指数e和符号位sy按照单精度浮点数的格式拼在一起,即可得到单精度浮点输出的结果。 按照第2节所述,使用verilog硬件描述语言实现了本文提出的高精度低延时浮点正弦余弦函数硬件算法,并和C语言math库进行了对比。本次测试的计算机平台为Intel Core i5-7400 @3.00 GHz(4核)CPU,内存24 GB,C编译器采用gcc4.9.2。仿真平台为windows下的Modelsim SE-64 10.4版本。测试方法为对所有的规格化浮点数进行遍历测试,将电路仿真值与C语言math库结果进行对比。 表2为正弦函数遍历测试结果,表3为余弦函数遍历测试结果。表中“范围”一列为输入指数范围的区间,它与1.1节所述的划分方法是一致的;完全一致占比表示仿真值与C语言math库结果完全一致的个数占在该输入指数范围内遍历总数的百分比;误差1 ulp占比表示仿真值与C语言math库结果有1 ulp误差的个数占在该输入指数范围内遍历总数的百分比。 表2 正弦函数遍历测试结果 表3 余弦函数遍历测试结果 遍历结果显示,对于正弦函数,在输入的指数范围为[-126,-16]时,结果存在1 ulp的误差。这是由于在该区间内使用了sin(2πx)=2πx公式,需要对输入做乘法,而π是一个无理数,将π定点化会产生截断误差,导致某些情况下它与参考结果相差1 ulp。对于输入的指数范围为[-15,21]之间时,由于采用泰勒一阶近似算法需要查找表,查找表也会产生截断误差,导致随机的1 ulp误差。在输入指数为[22,126]之间时,按数学理论结果为0,没有进行截断,因此不存在误差。 对于余弦函数,在输入的指数范围为[-126,-16]和[22,126]之间时,不存在1 ulp的误差。这是因为在这些区间上的余弦函数值都为1.0或者-1.0,没有截断操作,因此不存在截断误差。对于输入的指数范围为[-15,21]时,与正弦函数同理,由于采用的泰勒1阶近似算法需要查找表,会产生截断误差,导致产生随机的1 ulp误差。 本文首先使用联电UMC 55nm CMOS工艺库,在SS工艺角、1.08 V、150 ℃、RVT条件下,按照250 MHz的时序约束,对电路进行逻辑综合。本文还在FPGA平台上,使用Altera Cyclone IV的EP4CE115F29C7芯片,在Slow 1 200 mV 85 ℃ Model下进行逻辑综合实现。两种平台下正弦余弦函数电路性能如表4所示。 表4 正弦余弦函数电路性能 查找表(LUT)、逻辑片(Slice)、逻辑单元(LE)均为电路的基本组成单元。 本设计在UMC 55nm的SS工艺角下可达到250 MHz的时钟频率,完成一次正弦余弦函数运算的延时仅为16ns,具有低延时的特点。本设计由于采用了大查找表和乘法器等单元,电路面积相对较大,为247 329 μm2。在Cyclone IV平台上,本设计在最差工艺角下可达到64.02 MHz的时钟频率,完成一次浮点正弦余弦函数运算延时为62.5 ns,占用了42 734个LUT。由于本设计采用组合逻辑实现大查找表,因此占用了大量LUT资源。 表5给出了本文设计与其他文献中正弦余弦函数电路的性能对比。表中列出的正弦余弦函数电路的最大误差均不超过1 ulp。在ASIC设计中,文献[14]中采用TCORDIC算法实现了双精度正弦余弦函数,在40 nm CMOS的TT工艺角下,需要64个周期才能完成运算,总延时38.4 ns。文献[8]使用循环展开CORDIC算法实现了双精度正弦余弦函数,在TSMC65nm工艺下,需要15个周期完成运算,总延时75 ns。文献[20]中采用基于查找表的泰勒展开算法实现了单精度正弦余弦函数,在VirtexII平台下,总延时为85 ns。文献[18]中采用基于查找表的泰勒展开算法实现了16位定点正弦余弦函数,在StratixII平台下,需要3个周期完成运算,总延时31.3 ns。 表5 不同方案时电路延时、面积性能对比 本文提出了一种高精度低延时的浮点正弦余弦函数硬件实现算法。它将输入按照指数划分为3个不同的区域,在这3个区域内分别采用了不同的算法,达到了单精度浮点运算所要求的精度。本文着重说明了输入指数在[-15,21]之间所用的泰勒1阶近似算法,该算法通过一系列诱导公式,将原计算转换为[0,π/2)内的正弦函数计算,然后,将其进一步转换为硬件友好的查找表运算和乘加运算,从而实现了低延时。 在电路设计部分,本设计使用了四级流水线结构。实验结果表明,该硬件电路的计算结果与C语言math库的结果至多只相差1 ulp。在联电UMC55nm的SS工艺角下,该电路能够达到250 MHz的时钟频率,延时仅16 ns。在某些需要低延时的应用场景中,本文提出的高精度低延时正弦余弦函数硬件算法具有重要使用价值。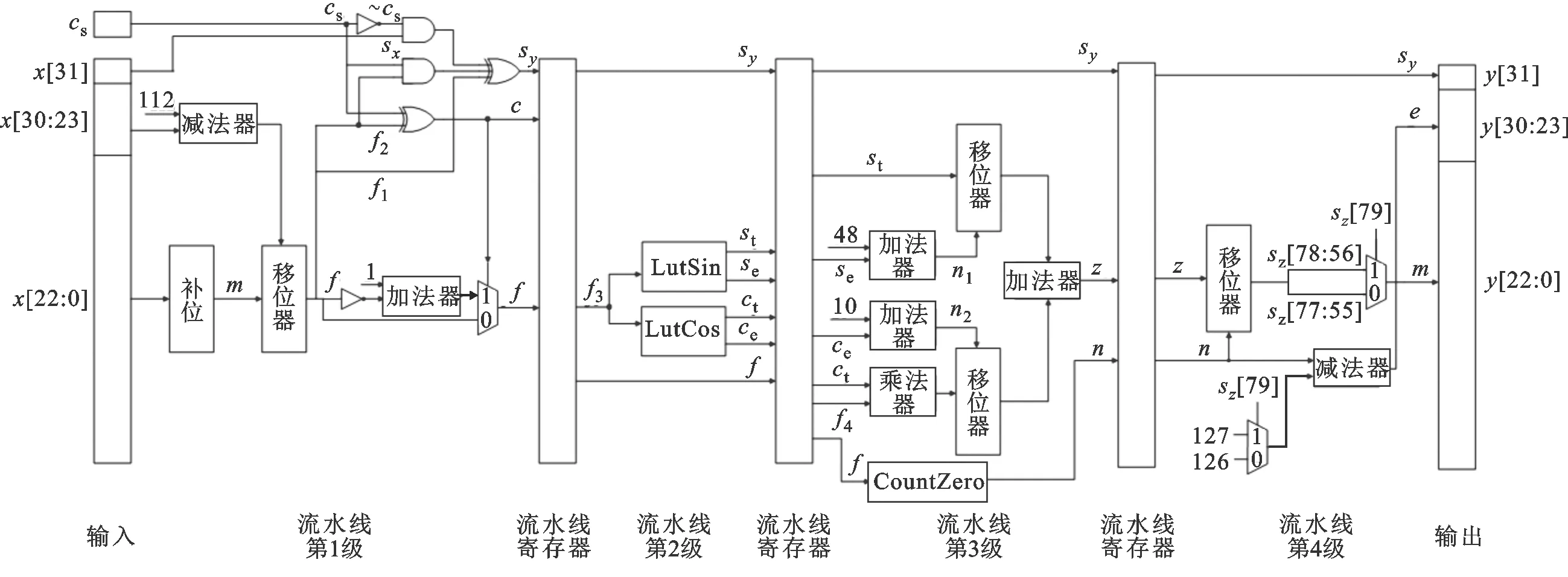
2 电路设计
2.1 总体电路结构
2.2 各流水级的具体实现
3 实验结果
3.1 精度测试
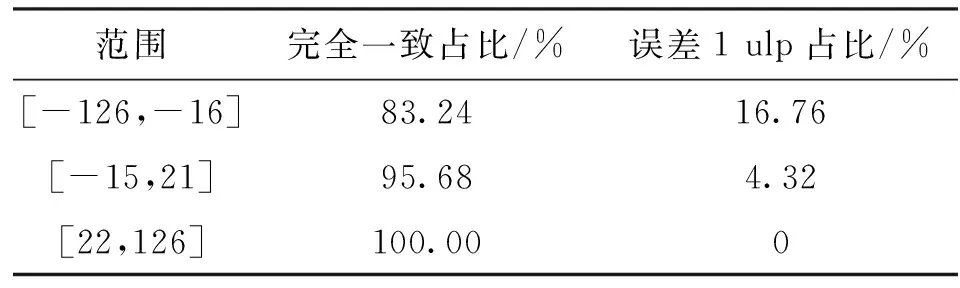
3.2 电路性能
4 结 论
