基于“互联网+”的高校图书馆个性化阅读推荐系统的设计与实现*
2021-11-16余建芳
余建芳
(广西民族师范学院,广西崇左 532200)
0 引言
当今世界,随着信息技术的飞速发展,互联网的广泛普及,产生了海量的数据。用户为了找到对自己有用的信息,越来越感到迷茫。以Baidu为代表的搜索引擎等系统的出现,对于海量信息带来的超载问题困扰是有一定程度的缓解。但搜索引擎只是信息检索中的一种,当用户输入查询关键字时,往往返回的信息都是千篇一律的内容,缺乏个性化和多元化。作为用户,往往希望得到符合当下场景的结果。在这种背景情况的驱动下,个性化阅读推荐系统及时出现了。个性化阅读推荐系统可以通过用户的兴趣爱好以及个人在互联网上的浏览足迹等行为为用户推荐自己的资源需求。本文就如何在现有高校图书馆中使用个性化推荐服务,结合当前个别高校的现状,设计出了符合当下实际的个性化阅读推荐系统。
1 “互联网+”背景下的个性化阅读推荐设计思路
对于高校图书馆,一般都会有作者图书书目查询的图书馆门户。可以视为一个图书馆书目检索系统或用户界面系统(UI系统)。以下称UI系统。UI系统可以将每位读者的不同阅览行为记录到用户相对应的行为日志中。个性化阅读推荐系统会根据这些用户日志进行分析,推荐给用户所对应的图书和相应资源。
基于一般高校图书馆的现有需求,在这里我们采用Mahout来创建属于我们自己的个性化阅读服务系统。
1.1 Mahout简介
Apache Mahout是Apache Software Foundation旗下开源项目,该项目可以帮助开发人员很快的搭建智能应用系统,还可以提供一些相关经典算法,主要是机器学习领域方面的。在最新的Mahout项目中增加了对Apache Hadoop的支持,使得这些算法可以在大数据乃至云计算环境中运行。
1.2 Taste库简介
Taste是一个用Java语言编写的协同过滤算法库,可用来搭建可扩展的,高效的推荐系统。Taste库属于Apache Mahout的一部分。Taste库不但实现了基于内容的推荐算法,还实现了基于用户的推荐算法,提供了对应的扩展接口,用户可以实现和定义自己的推荐算法。Taste被设计成了一个组件,该组件不仅对Java应用程序是适用的,而且对于服务器内部而言,它可以充当一个服务组件,可以以Web Service及HTTP的方式提供个性化推荐服务。综上所述,Taste可以同时满足在开发推荐引擎时的灵活性、对性能以及可扩展性等各个方面的需求。
Taste主要由以下几部分组成:
数据模型(DataModel):它是生成用户兴趣、爱好的抽象接口,在具体应用时,可根据具体的数据类型来具体实现。Taste默认提供两种数据模型,是JDBCDataModel和FileDataModel。
用户相似度计算和物品相似度计算模块:User Similarity用于计算两个用户间的相似程度。在基于协同过滤算法的推荐系统中,可以用来计算用户兴趣爱好相似的其他用户(邻居)。ItemSimilarity是类似的,用以计算物品或者内容之间的相似度。这两个模块是推荐系统中的核心模块。
用户邻居计算模块(User Neighborhood):该模块的主要作用是找到有相同兴趣爱好的用户,在这个模块中确定如何寻找“邻居用户”的方法。由于是基于User Similarity模块的,因此一般用于基于用户兴趣爱好相似度的推荐方法中,比如我们要给某个用户推荐和他喜欢同一类物品的“邻居用户”感兴趣的物品。
推荐模块(Recommender):该模块是推荐系统的抽象接口也是Taste中最为核心的模块。在实际开发推荐系统时,我们可以基于它实现Generic User Based Recommender类,此时该推荐系统是基于用户相似度的。若我们实现的是GenericItem Based Recommender则推荐系统是基于内容相似度的。
1.3 搭建步骤
第一,抽取Taste工具包在构建推荐引擎时,我们需要将Taste工具包从Mahout工程中提取出来单独使用。这样就避免了使用Ant或者Maven对Mahout工程进行编译。
第二,通过分析个性化阅读推荐服务中涉及的主要实体以及实体间的关系,得到数据模型。然后依据该数据模型,设计数据库的结构以及规划程序中的类。
第三,实现推荐引擎,推荐引擎是个性化阅读推荐服务的核心部件。由于Taste工具包既实现了最基本的基于用户的和基于内容的推荐算法,同时也提供了扩展接口。因此我们可以通过扩展以及实现自定义的一些方法完成推荐引擎的搭建,下面将进行介绍。
2 “互联网+”背景下的个性化阅读推荐需求分析
图书馆的个性化阅读推荐系统主要组成是由读者的借还书行为日志来产生对应基础数据的,系统在此数据的基础上经过推荐系统的分析,产生对应的推荐书目列表。系统在构建的过程中,需要解决三个问题:(1)非结构化数据分析问题;(2)如何存储海量读者日志;(3)构建并行计算框架。
2.1 存储海量读者日志
高校图书馆服务的主要对象是校内的师生,一般约为1到2万人。这类群体,每天产生的各类日志文件数据量是相当大的。作为基本固定的读者群体对图书每日的查阅量基本都是固定的,并且频率是很高的。每一学年到毕业论文开题,撰写以及准备要答辩时,对相关文献的查找量更是会急剧飙升。这样信息日志每天都会大量产生。这时,非关系型数据库就是我们拿来应对这些存储需求增加的问题。
在这里,我们选择的是NoSql的Redis进行大批量的读者日志存储。
2.2 非结构化数据挖掘需求
结构化的数据具有固定的格式,对于设计者而言,处理相对比较容易。与读者兴趣关联密切是待处理的非结构化的数据,通过对读者隐性、显性行为的分析,为读者提供一个适合读者自己的个性化推荐系统。
协同过滤推荐和基于内容的推荐方法是目前应用最为广泛的两种推荐方法。协同过滤方法与内容推荐方法最大的不同是克服了后者不能为读者发现新的与读者兴趣爱好相关的资源的缺点。但它依然存在读者数据稀疏性,读者兴趣变化的差异性等问题。基于内容的推荐方法是根据读者以往的阅读历史,向读者推荐读者在此之前没有接触过的对应推荐项[1]。
为解决上述问题,结合协同过滤算法的思想,基于读者行为,根据读者的相关信息来创建个性化行为模型,再用Apriori算法,挖掘模型中存在的规则,产生相应的个性化图书推荐目录列表。
2.3 并行计算需求
如果用户产生的日志,它是分别存放于不同的服务器的,那么对于用户兴趣模型的计算就必须从不同的服务器获取所需信息,这时就需要并行计算。但由于高校图书馆的读者相对是比较固定的,对于并行计算的要求相对来说就比较低。
2.4 数据模型实体关系
数据模型是推荐系统的基础,在构建个性化阅读推荐服务时,我们需要针对图书馆的读者群体进行数据建模。一方面通过线下调研来获取数据,另一方面可以通过开发读者中心,使得读者在使用图书馆的各项服务时贡献数据。简单的来说,单个高校图书馆的读者数据模型并不是十分复杂,可按照如下形式进行存储。
数据模型中存在以下实体:
Book:表示书籍信息。
User:表示读者,含读者的基本信息。
Book Reference:表示某个读者对某本书或者某篇文献的喜好程度。
Book Similarity:表示两个书籍或文献的相似度,两个书籍之间的相似度可以通过各自的基本信息按照最为简单的余弦公式计算得到[2]。
3 “互联网+”背景下的个性化阅读推荐系统架构及组成模块
在考虑系统架构时,如果要在一个单一的推荐系统中将图书信息的特征和推荐服务的任务都全部实现,那么该系统会无比复杂,后期的维护也会困难。当我们想通过配置文件,对某个特征进行加权或者降权处理时,由于系统的高度耦合性,使得该项工作十分困难。因此,将个性化阅读推荐系统按不同的推荐模型分成若干个子模块。每个子模块是一个相对独立的推荐引擎,一类任务和一类特征由每个独立的推荐引擎负责。最终将所有推荐引擎的结果按照有关的规则返回给用户由整个推荐系统负责[3]。
3.1 个性化阅读推荐系统设计
下图即为个性化阅读推荐服务的整体设计。首先通过数据挖掘,机器学习等技术把从图书馆资源到推荐引擎,将读者对应的特征库建立起来,然后提供给推荐引擎。根据不同特征库的推荐引擎,根据聚类、协同等推荐模式得到初始的推荐结果。最后按顺序,经过结果排名与过滤推荐结果,最终生成推荐结果,如图1所示。
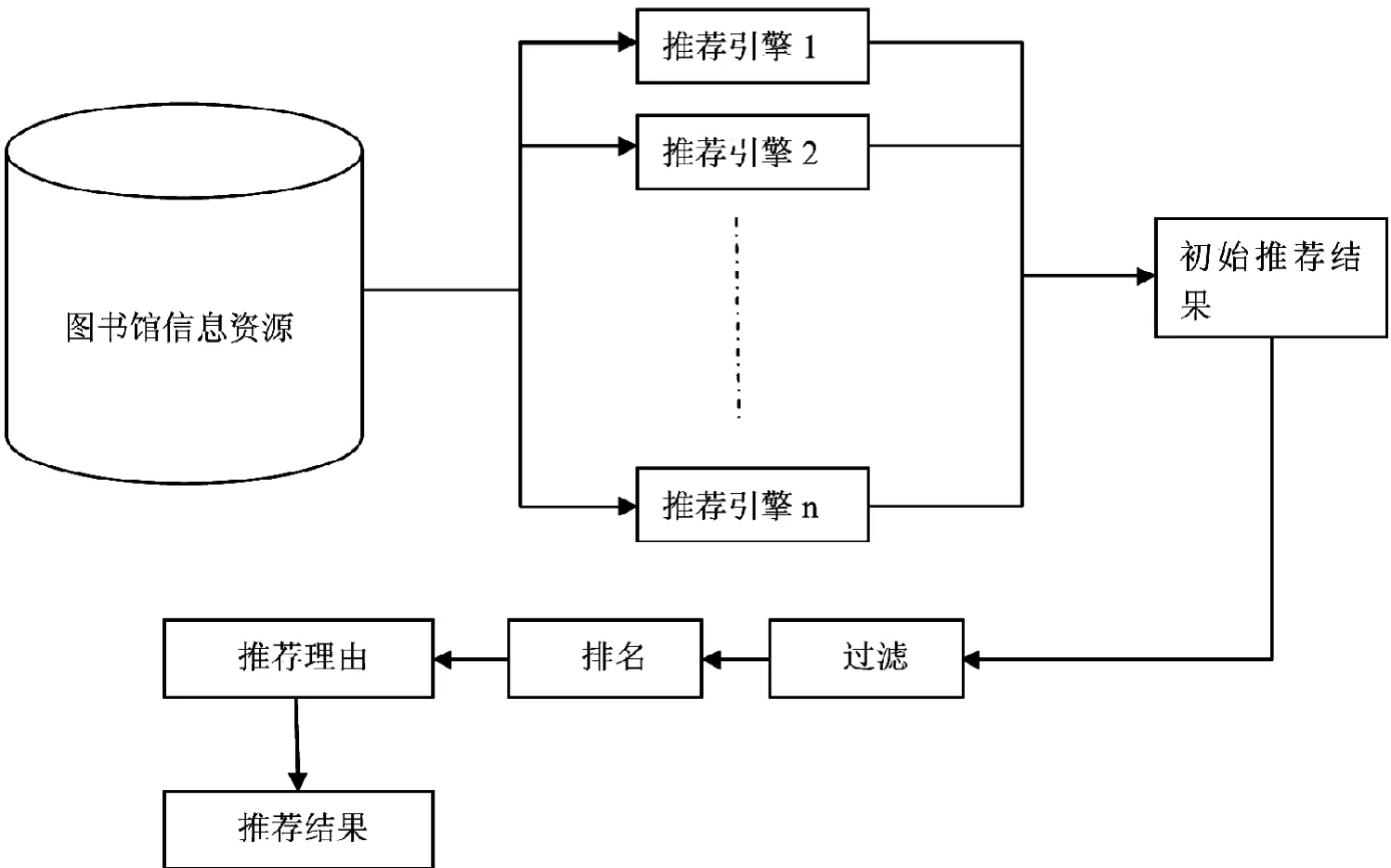
图1 个性化阅读推荐整体架构Fig.1 Overall architecture of personalized reading recommendation
3.2 个性化阅读推荐系统界面
由于个性化阅读推荐主要是根据用户的个人行为,即在图书资源检索系统上检索自己所需要文献而运转的。所以针对需求,分别在两个部分添加了推荐服务于检索系统上。
第一种情况对于首次进入检索系统时的读者适用。系统会根据用户之前的检索、浏览行为以及已有的兴趣模型给读者推荐自己喜欢的阅读书籍。分为两种:
一是根据用户的喜好建立的模型进行的推荐,名为“您可能想阅读这些书籍”。
二是根据用户的好友关系进行的推荐,名为“您的好友也在读”。
第二种情况适用于读者进行检索后出现自然检索结果的页面,主要是根据当前作者检索对应的内容进行的相关推荐。这时主要推荐的是与用户检索结果相似的书目,这样减小用户盲目的查找,缩短用户找到有用文献的时间,名为“相关书籍”[4]。
4 “互联网+”背景下的个性化阅读推荐系统各模块介绍
4.1 生成用户特征模块
该模块的主要是根据读者的日常行为、浏览足迹等建立用户行为数据库,根据读者的标签姓名等属性建立读者信息库。最后根据这两个与读者密切相关的数据库,对读者的喜好特征向量进行分析,提取有用的、关键的信息,得到读者的特征向量库。
4.2 生成物品特征模块
该模块的作用是生成特定的书目特征向量库,它的核心作用对于书籍文献之间的相关性进行计算。此处采用了内容相似度和协同过滤算法进行计算。针对不同的文献在计算权重时,均考虑了与该文献所涉及到的读者的借阅、检索、预约等行为。
4.3 推荐功能模块
该模块是根据书目与读者行为特征,首先生成最初的推荐列表。其次对此列表进行排序、过滤、推荐理由映射,最终生成推荐结果。
5 “互联网+”背景下的个性化阅读推荐系统的具体实现
在如何实现个性化阅读推荐系统与图书馆先有系统的对接上,由于我们之前在设计时采用了松耦合的设计思路,使得推荐系统可以无缝的接入图书馆现有的文献检索系统中,只是增加了一套推荐服务而已。当用户搜索某个文献时,得到的不仅仅是检索服务所提供的资源列表,在其右侧亦可看到由推荐系统所提供的阅读建议清单。
首先创建MySQL数据库存储书籍文献信息和读者的信息、读者的兴趣爱好、书籍的相似度;其次是实现推荐引擎所需的DataModel;再次是推荐引擎核心部分实现;最后是推荐引擎提供给信息检索系统的API的实现。
根据推荐引擎的基本结构,要实现推荐引擎首先必须实现Recommender接口。一般情况下,Recommender接口是对Taste工具库中提供的基本推荐引擎的接口类。在这里我们主要是针对Generic User Based Recommender进行的扩展。Java语言中,继承接口类后必须实现其中的所有方法。这其中最为重要的就是用该接口中的推荐引擎的构造函数实例化一个推荐引擎对象。这个过程一般包括以下步骤:
(1)基于之前建立好的用户数据模型(Data Model)来计算用户的相似程度,可以采用Pearson Correlation算法。
(2)采用Averaging Preference Inferrer类来实现计算用户相似度的推理算法。这里,我们规定在基于用户相似度计算过程中,若某个用户与该用户的最近距离为2,则将其称之为“邻居用户”。
(3)使用以上得到的用户相似度对象和邻居用户的计算方法对象创建一个Generic User Based Recommender的实例。一般情况下,这时都采用Caching Recommender为RecommendationItem进行缓存,从而提高访问速度。
在实现基于内容相似度的推荐引擎,我们对原始的书籍和文献信息进行了预处理。这些预处理主要包括:事先计算出书籍文献的相似度并存入数据库的book_similarity表中;根据从数据库中读取得到的书籍相似度信息创建相似书籍的集合;基于相似书籍的集合生成内容相似度Item Similarity。完成这些预处理后,我们就可以创建一个Embeded Item Based Recommender类的实例对象。它是一个内部类,包含一个Generic Item Based Recommender实例。
该推荐引擎的工作流程大致是:首先从数据模型(Data Model)中得到含有读者评分书籍列表,然后调用Generic Item Based Recommender中的most Similar Items方法计算出最符合该读者兴趣爱好和关注点的书籍或文献推荐给该读者。
完成了推荐引擎的设计与实现,下面需要设计一些REST API,向外暴露推荐功能。这样也是为了将个性化阅读推荐服务与学校现有的信息检索系统整合在一起。为了提高推荐引擎的处理效率,这里采用单例(Singleton)模式实现一个推荐引擎的Book Recommender Singleton。在Servlet启动的时候初始化推荐引擎的单例,以后每次调用推荐方法。
6 结语
截止现在,个性化阅读推荐系统在高等院校图书馆中的应用还不够成熟,本文作者只是针对目前高校图书馆的实际设计符合当下情况的个性化阅读推荐系统。且由于现有用户的基数较小,致使现在个性化阅读推荐所得到的用户兴趣模型还不是非常准确和完善的。因此需要不断的完善相关的信息,提高相应的技术,为将来读者使用个性化的阅读推荐提供更好的服务。
