基于MK 变点检测和加权HMM 算法的NILM 研究
2021-11-15傅军栋
傅军栋,耿 余,赵 颖,刘 珺
(华东交通大学电气与自动化工程学院,江西 南昌 330013)
非侵入式负荷监测(non-intrusive load monitoring,NILM)早在20 世纪80 年代就已经提出。 近年来,如何科学用电、引导用户侧提高用电效率引起了诸多关注[1]。 所谓的非侵入式就是在用户入口处采集用户总负荷的能耗等用电信息,通过一定的方法分解识别出末端的各个设备[2]。 此方式较侵入式监测投入小,实用性强。 成熟的非侵入式负荷监测模型将会对包括智能电表等用户侧设备的革新带来新的方向,同时也可以优化故障检测及定位、节能等研究内容,具有很大的实用价值。
国内外对于NILM 的研究一直持续着,孙毅[3]将总谐波失真系数作为负荷新特征引入目标函数, 采用基于动态粒子群自适应算法的非侵入式负荷分解方法对实测用电数据进行负荷分解,但是两个方法都采用仿真所得数据,过于理想化,实用价值不高。刘兴杰[4]提出一种基于改进鸡群算法的负荷监测方法, 综合考虑稳态谐波电流和功率特征的正态分布度量函数。 对于变功率负荷,两种方法的识别能力较差。Racines[5]采用两个独立的神经网络模型,分别对事件和负载状态进行识别,但是模型之间的联系不够紧密,导致识别率不高。 牟魁翌[6]提出了一种基于分段线性近似及高斯动态弯曲核支持向量机的非侵入式负荷监测方法。Wang[7]提出一种基于V-I 轨迹特征支持向量机的多分类算法进行负荷识别。 两个模型的识别精度都有所提高, 但基于支持向量机模型的算法对于相似负荷的识别无法达到预期效果。张丽[8]基于智能负荷控制器 (SRLC) 的用电参数检测功能和非侵入式负荷监测原理, 提出一种基于多参量隐马尔可夫模型的负荷辨识方法, 但是由于实验在特定环境下进行,缺乏多样性,导致在个别环境下,识别误差增大。 王晓换[9]提出了一种决策融合方法。 由于模型的复杂化, 导致加权值无法准确选取,降低了识别精度。
针对以上研究中存在的不足, 通过对几种具有代表性的家用电器的分析, 将用于环境变化检测以及降水趋势变化中的Mann-Kendall(MK)[10]变点检测算法应用于NILM 中的事件检测中,并加以改进,提出基于双滑动窗的MK 变点检测算法,并以每个设备各内部状态在每个时间段的出现概率作为权值带入到算法中,以负荷有功功率和电流电压相位差为参数,提出加权双参量隐马尔可夫模型实现负荷状态识别。最后以ECO 数据集[11]提供的数据验证算法的先进性。
1 双滑动窗MK 变点检测原理
负荷状态变化时,会伴随着从一个稳态到另一个的稳态的突变过程,可以通过变点识别的方法检测到状态改变事件。 史帅彬[12]提出了一种基于复合滑动窗的CUSUM 暂态事件检测算法, 但是该方法需要负荷参数在投切时的爬坡过程来累计偏移量,适用于高频的负荷参数, 且出现大量的漏检现象。在低频情况下,CUSUM 变点检测算法无法满足要求。 为了满足低频信号下能够准确检测到突变点,将MK 变点检测应用到负荷事件检测中,该方法具有很高的抗干扰能力,同时也避免了漏检和误检的发生。
1.1 非参数化的MK 变点检测算法原理
负荷状态的改变,将检测到负荷信息从一个稳态到另一个稳态的转变,这样的过程可以通过变点检测的方法检测到。 变点检测即利用一定的方法,对时间序列的趋势状态进行检测[12]。
MK 是一种非参数统计检验方法, 该方法的样本不遵从特定的分布方式,检测结果也不会因为个别异常值而出现很大的误差,且能客观地展现序列变化趋势[13]。 本文对有功功率的时间序列P 作MK 变点检测,对P(含有n 个样本)构造一个秩序列

UFk为标准正态分布, 是在时间序列P 的正顺序情况下计算出的统计量,并形成相应的序列。 按时间序列P 的逆序列,重复上述公式计算UFk(k′=n+1-k),并且令UBk′=-UFk′,当k′=1 时,UB1=0。
给定显著性水平α, 将UFk和UBk序列曲线与Uα的两条临界直线一起绘制。 若UFk的值大于0,则表明有功功率序列呈上升趋势,小于0 则表明呈下降趋势。 如果UFk和UBk两条曲线出现交点,且交点在显著性水平曲线之间,则交点对应时刻或者前一时刻即为事件发生的时刻。
MK 变点检测在处理变点检测问题上有很大的优势。 然而,在处理多次突变的时间序列时,由于UFk和UBk的在图像中的完整性, 会出现无法完全检测突变点的情况, 导致突变点的漏检和误检,本文基于这一问题提出复合滑动窗的方法将MK 变点检测序列细分成更小的窗口进行逐一检测,这一手段也大大减少了MK 变点检测的工作量。
1.2 双滑动窗变点检测
在实际的用电情况中,无事件情况下功率等参数波动小。 当出现设备状态改变时,伴随着负荷参数的突变,窗口的均值和方差也会突变。 根据这一特性, 提出基于双滑动窗的MK 变点检测算法,其检测过程如图1 所示。

图1 基于双滑动窗的MK 变点检测过程图Fig.1 MK change point detection process based on double sliding windows

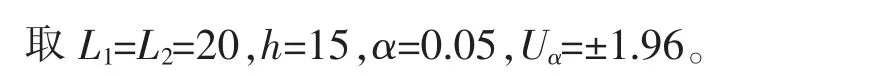
考虑到事件发生在WD1前端或者WD2尾端时,均值μWD1和μWD2的差值可能不明显, 增加了漏检的概率。 可以适当增加大窗口两端采样点的参考价值。 为此对大窗口内每个采样点值进行加权处理,采用类似于正态窗的方式获取WD1和WD2的均值。
通过对正态分布函数进行变换用于确定权值
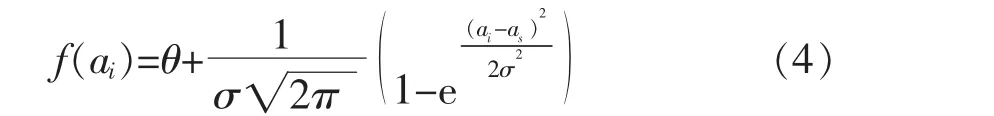
式中:ai表示大窗口内每个采样点的位置;as表示大窗口中间采样点位置,即WD1尾部和WD2头部重叠采样点位置;θ 为0~1 的一个系数;σ 为大于0 的常数,决定权值曲线的平滑程度,其值越大,权值曲线越平滑,每个采样点作用越均匀。 通过调节σ,可以改变大窗口两端采样值在计算均值时的权重。
由式(4)可知,中间采样点as处权值f(as)=θ,为最小权值。对f(ai)进行归一化处理,得到权值φ(ai),最终得到窗口WD1和WD2的均值μWD1和μWD2为

式中:kstart表示窗口开始位置时刻;L1和L2为WD1和WD2的窗口宽度;W(ai)为窗口中采样点ai的采样值。
2 加权双参量隐马尔可夫状态识别
获取事件点及对应负荷参数后,即可进行该突变点的设备状态识别,即识别出每次突变后各设备的运行状态。 文献[8,14-15]均采用隐马尔可夫模型(hidden Markov model,HMM) 进 行 负 荷 识 别,在HMM 的基础上做了相应的改进,分别提出基于免疫优化和增量学习改进的HMM[14]、可加因子HMM[15]以及多参量HMM 算法[8]。然而3 种方法均未进行前期的事件识别操作, 每个采样点均需要进行状态识别,算法运行负担加大。 对此本文在识别负荷事件的基础上,采用有功功率和电流电压相位差两个参量,并以每个设备各内部状态在每个时间段的出现概率作为权值带入到算法中,提出基于加权双参量HMM 的负荷状态识别方法。 将事件点负荷参数带入HMM 中, 获取各状态组合的概率并通过负荷各状态出现概率作加权处理,找出最大概率对应状态组合即为该事件发生后各设备的状态,最终实现负荷识别的目的。
2.1 隐马尔可夫模型原理
HMM 作为典型的机器学习模型在模式识别等领域得到了广泛的应用。在HMM 模型中,主要有以下几个概念:隐藏状态集合Q,观测集合V,状态序列I,观测序列O,状态转移矩阵A,观测概率矩阵B以及初始概率分布向量C。
在HMM 中,采用三元组λ=(A,B,C)表示一个HMM 模型。在预测模型中,通常采用Viterbi 算法对隐藏状态序列I 进行解码。在给定了λ=(A,B,C)及观测序列O 后,即可解码出观测序列O 对应的状态序列I。 其过程如下:
1) 需要进行局部状态的初始化

4) 当递推至δtmax和ψtmax后,通过ψt(i)回溯每个ot对应的状态,其中t=tmax-1,tmax-2,…,2,1。 最终得到状态序列I=(i1,i2,…,itmax)。
2.2 设备状态组数的确定
实际运行中,很多设备比如冰箱存在关机、待机、制冷等多个工作状态,需要确定每个设备的状态数。 本文采用PMF 方法[16]进行设备状态数的确定。
在PMF 中,通过统计各设备有功功率可能存在的取值的概率来确定设备状态数。 公式如下:

式中:η 为设备有功功率为l 的概率;Pmax为设备最大的有功功率取值。
在获取设备状态数时,认为设备状态可由PMF的峰值来确定。当出现η(l)-η(l-1)>0 且η(l)-η(l+1)<0 时,即认为P=l 为设备的一个状态,且l 为该状态下设备的有功功率取值。 赋予设备每个状态一个索引值,其中包括设备的关闭状态,索引值为“1”即l=0。
通过PFM 方法分别获取各个设备的状态数并赋予各状态索引值。即可获取隐藏状态集合Q 中的各状态组合
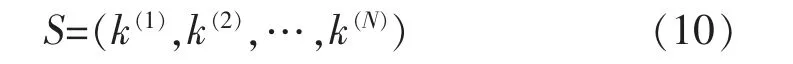
式中:S 为当前的设备隐藏状态组合;k(n)为第n 个设备的状态索引,对应设备的内部状态。
隐藏状态集合Q 即由设备状态组合S 组成,其组合S 的总数表示为
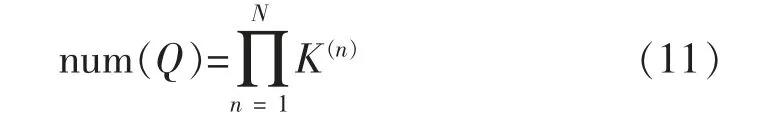
式中:N 为设备总数;K(n)设备n 的内部状态总数。例如, 当存在4 个设备, 各设备内部状态数分别为4,5,2 和7。则组合S 的总数num(Q)=4×5×2×7=280个。
2.3 加权双参量隐马尔可夫模型
关于状态转移概率矩阵Anum(Q)×num(Q),aij表示从状态i 转移到状态j 的概率。通过计算状态i 转换为状态j 的次数并通过从状态i 转换所有状态的总数进行归一化,以最大似然准则估算aij

式中:Dij是从状态组合i 到状态组合j 的转变数;num(Q)为状态总数。由于该算法是在检测到变点后进行,认为不存在状态没有改变的情况,即矩阵A对角线上的值全部设为0。
同理,也可以得出各种状态组合下对应各观测值组的概率矩阵Bnum(Q)×num(V)。

式中:ømk为设备内部状态k 在第m 个时间段内出现的概率;Fmk是在第m 个时间段内设备内部状态k出现的总数。
在进行状态识别时即采用Viterbi 算法获取设备的状态组合。 不同的是,在计算δ 时,由于观测值序列对应为事件发生后的负荷参数,即认为当前状态组合只与前一状态组合有关,且所有观测值之间相互独立,只与生成它的状态组合有关。 即
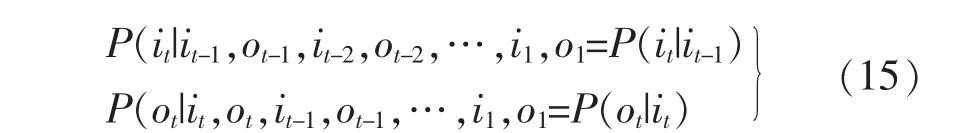
状态序列I 及观测值序列O 均只包含当前事件和前一事件相关参数。 当检测到事件发生,即可得到该时刻的观测值组ot,并列入观测序列O=ot-1,ot)中。 HMM 通过观测值ot,结合每个设备各内部状态在每个时间段内出现的概率?计算当前事件后处于不同状态组合的最大概率δt:

式中:ømk(n)表示第n 个设备在当前状态组合为j,自身内部状态为k,本次事件发生时间段为m 的情况下的出现概率;aij为从状态组合i 转移到状态组合j的状态转移概率;bj(ot)为观测值为ot时隐藏状态组合为j 的概率。
最大的δt对应的隐藏状态组合即为本次事件后各设备状态的组合。 通过状态组合即可获取每个设备的状态信息,实现负荷识别的目的。
3 算法验证
本文采用ECO(electricity consumption & occupancy,ECO) 数据集对算法进行验证。 该数据集以1HZ 的频率收集了瑞士6 个家庭历时8 个月的总负荷以及各用电设备参数。 包含功率、电流、电压、相位差等数据。
3.1 事件识别算法验证
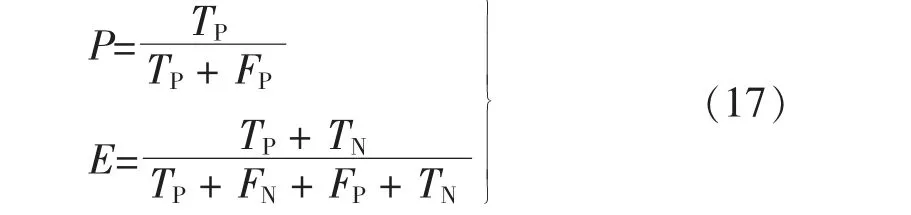
选取该低压台区其中一户家庭某一周的总负荷数据进行算法验证。 对该周用户负荷事件进行统计并采用基于双滑动窗的MK 变点检测方法进行负荷事件识别。 计算事件识别方法的精确率P 及准确率E式中:TP表示模型判断结果为正例, 且实际上判断结果为正确, 即真正例;TN表示模型判断结果为负例,且实际上判断结果为正确,即真负例;FP表示模型判断结果为正例, 但实际上判断结果为错误,即假正例;FN表示模型判断结果为负例, 但实际上判断结果为错误,即假负例。

选取该低压台区其中一户家庭某一天的总负荷数据进行NILM 算法验证。 图2 为家庭该天的12时至14 时的总有功功率曲线, 通过统计可知该时间段内实际发生了14 次事件。
对该时间段内的设备事件进行监测。 在进行窗口检测的过程中, 通过得到的UF 与UB 曲线及时的确定窗口内是否发生负荷事件以及其确切的时间,并在监测到事件后进入设备状态识别阶段。
通过基于双滑动窗的MK 变点检测的算法,对图2 整个时间段的负荷数据进行事件检测,检测出事件数为14 个,分别发生在以下时刻:12:17:29,12:35:41,12:48:18,12:56:49,13:09:06,13:10:48,13:15:31,13:36:43,13:37:03,13:54:06,13:57:00,13:57:41,13:58:14,13:58:36。 这与实际的设备启停事件发生时刻几乎一致。 在图3 中分别取第46 098 s,第44 249 s 的事件对应窗口进行分析。
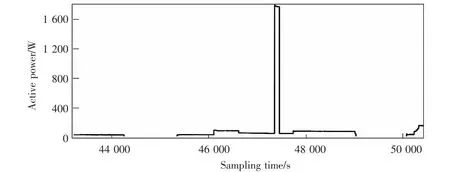
图2 家庭1 某时间段总负荷有功功率曲线图Fig.2 Family 1 total load active power curve for a certain period of time
图3(a)的UF 和UB 曲线存在大于0 的交点,且交点在临界线之间, 即在交点前一时刻出现了功率突增的情况;图3(b)的两条曲线出现了小于0 的交点,且交点在临界线之间,表明在交点前一时刻出现了功率突减的情况,这与实际情况完全吻合。
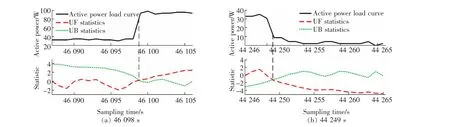
图3 MK 变点检结果Fig.3 MK change check result
3.2 状态识别算法验证
上文已验证基于双滑动窗的MK 变点检测算法的先进性, 在此基础上进行基于加权双参HMM的设备状态识别算法验证。 以家庭1 连续180 d 的负荷数据作为统计数据,在该时间段里,待识别设备包括冰箱1、水壶、洗衣机、冰箱2、台式电脑和照明6 个设备。 在此基础上,以统计天以外的负荷数据作为验证数据进行算法验证。
将本文提出的MK-WHMM 算法与孙毅[14]中的IA-IL-HMM 算 法、Bomfifli[15]提 出 的AFHMM 算 法以及基于k-means 的NILM 算法进行对比, 分别从状态识别准确率和有功功率平方误差两个方面进行算法性能比较。两种性能指标如式(18)式(19)所示。

式中:RS为状态识别准确率;num(ST)为正确识别状态数;num(SF)为错误识别状态数。

式中:RPE为有功功率平方误差;Pt为t 时刻设备实际有功功率;P 为t 时刻算法估计设备有功功率。
如图4 和图5 分别为4 种NILM 算法对家庭1的冰箱1、水壶、洗衣机、冰箱2、台式电脑以及照明设备的状态识别精度及有功功率平方误差对比。
由图4 可知,在对该家庭的6 个用电设备进行NILM 算法识别时, 本文提出的方法状态识别精度均高于其他3 种方法,较其他3 种算法在负荷状态识别上更具有优势,且对于冰箱1 和冰箱2 两个负荷特性较为相似的设备以及照明设备等负荷较小的设备同样可以进行有效的识别。

图4 家庭1 的设备状态识别准确率对比Fig.4 Comparison of device status recognition accuracy rate of Family 1
在图5 中,除水壶和照明设备的功率平方误差较其他3 种算法具有优势,其他4 个设备的功率平方误差较文献[14-15]的方法更大。 分析可知,这4个设备均为多状态或者负荷波动频繁的设备,本文算法旨在检测到负荷事件后进行负荷状态识别,这样大大减小了负荷状态识别的负担,但设备在同一状态下负荷功率保持为一个定值,忽略了设备自身的负荷波动,从而增加了有功功率平方误差。 而文献[14-15]跳过负荷事件检测这一步,直接通过对每一个采样点都进行一次HMM 负荷状态识别, 使得负荷功率更加接近实际, 但同时也增加了HMM 状态识别的负担。综合各方面因素,本文NILM 算法较另外3 种算法具有一定的先进性。

图5 家庭1 的设备有功功率平方误差对比Fig.5 Comparison of the square error of the active power of the equipment of Family 1
在此基础上,随机选择除家庭1 外任意两户居民,以设备状态识别准确率进行两个场景的算法性能比较,结果如表1 和表2 所示。

表1 场景1 设备状态识别准确率对比Tab.1 Comparison of device status recognition accuracy rate of Scenario 1%
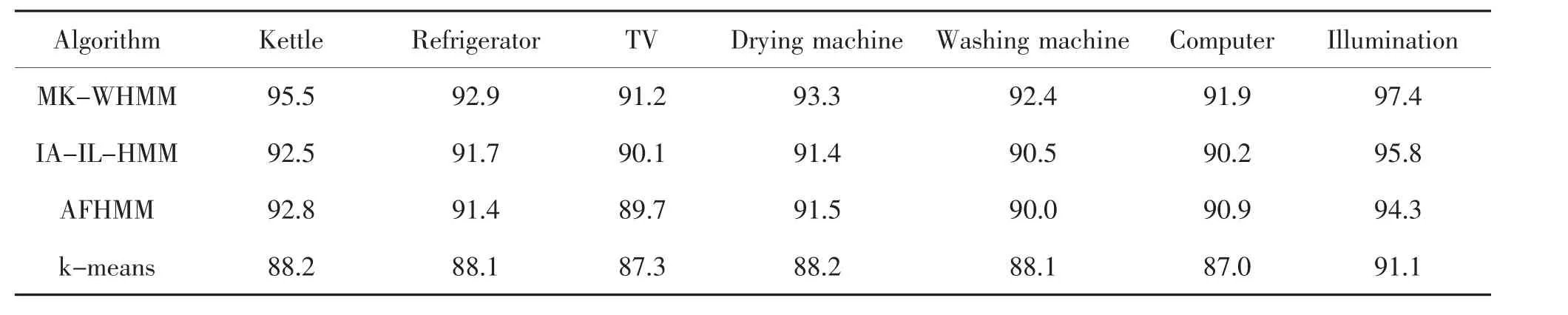
表2 场景2 设备状态识别准确率对比Tab.2 Comparison of device status recognition accuracy rate of Scenario 2%
由表1 和表2 可见, 本文提出的NILM 算法能够适应不同的场景,且相比于其他3 种方法效果明显。 根据以上验证可知通过本文提出的NILM 算法可以实现对居民用户内负荷进行分解。
4 结论
本文将NILM 具体分为负荷事件识别和负荷状态识别两个部分。
1) 采用基于双滑动窗的MK 变点检测算法进行负荷事件识别, 同时在HMM 的基础上以每个设备各内部状态在每个时间段的出现概率作为加权值, 提出基于加权双参量HMM 的负荷状态识别方法。
2) 通过验证,结果表明该NILM 算法能够及时有效地识别出用户内各设备的运行状态。 为后期与IEC61850 结合的低压用户用电信息通信提供技术支撑,同时为今后基于NILM 的相关研究提供参考。
