基于循环神经网络的双耳助听器语音增强算法*
2021-11-12朱亚涛张雨晨
朱亚涛,陈 霏,2*,张雨晨,陶 源
(1.天津市成像与感知微电子技术重点实验室,天津大学微电子学院,天津 300072;2.深圳清华大学研究院,广东 深圳 518057;3.北京大学深圳医院耳鼻喉科,广东 深圳 518036)
世界上超过5%的人口患有听力障碍,其中4.32亿为成年人[1]。听力损失患者与他人交流的能力受限使他们被排斥在交流之外,从而产生孤独感和沮丧感,尤其是对老年听力受损者而言[2]。助听器可以帮助使用者提高听力水平,从而解决上述问题。助听器内部的语音增强算法直接影响助听器补偿患者听力损失的准确度和获取语音的舒适程度[3]。谱减法[4-5]是助听器中最常用的方法,也是最容易实现的较为有效的语音增强方法。该算法可以有效的抑制噪声成分,但是当欠估计噪声功率谱时会残留较多的音乐噪声,过估计噪声功率谱时又会导致语音失真。维纳滤波法[6]可以看做是谱减法的衍生算法,且可以有效的减小音乐噪声的出现,但是对于非平稳噪声的衰减能力较弱且比较容易引入一定程度的语音失真[7]。即传统的语音增强方法对平稳噪声具有良好的抑制效果,但是对于非平稳噪声的处理效果较差。
随着机器学习的发展和成熟,基于神经网络(Neural network,NN)的语音增强方法表现出更好的性能。Valin基于对传统谱减法的研究,通过使用深度学习来代替传统方法中难以正确调整的噪声估算器部分,提出了一种对全频带实时处理的深度学习方法,且可以获得比传统的最小均方误差频谱估计器更好的处理效果[8]。虽然Valin通过精简NN使其算法可以应用于移动或嵌入式设备中,但其提取特征的方法和规模还是相对复杂,难以应用于体积微小的助听器设备。张等人将多频段的对数功率谱作为NN的输入,以此提出了一种结合子带谱熵法和循环神经网络(Recurrent neural network,RNN)的助听器语音增强算法,并在非平稳噪声环境中获得了较好的语音增强效果[9]。上述方法均为单通道语音增强算法,没有考虑语音的空间信息。
事实证明,对带噪语音的双耳处理比在每个耳朵独立处理更有效[10]。根据Kochkin的研究表明,80%以上的听力损失患者的双耳都受到听力能力下降的影响,因此需要同时使用两个助听器[11]。双侧助听器(左、右耳设备独立工作)不能保留原始语音的空间信息,导致佩戴者无法定位和追踪声源[12]。双耳算法结合双耳语音进行处理,不仅可以获得更好的语音处理效果,还可以保留双耳线索,如听觉之间的时间差和水平差。Zermini结合双耳语音提取NN的输入特征用于语音分离[13],通过训练一个NN来估算包括耳间水平差(interaural level difference,ILD)、耳间相位差(interaural phase difference,IPD)和对数功率谱(log power spectrum,LPS)在内的特征和各频段声源方向概率之间的映射关系,然后得到软掩码并乘以双耳混合谱图进行分离,且获得了更好的分离效果。大多数基于NN的语音处理算法主要应用于语音识别领域,这些算法的网络规模巨大,难以应用于有实时性和低功耗要求的助听器等微型可穿戴设备。
针对上述问题,本文结合双耳助听器提出了一种小规模的RNN用于实现双输入双输出的语音增强算法,使得双耳助听器可以协同工作从而获得更好的性能。本文的其余部分组织如下。第二节介绍双耳语音增强模型,并简述其实现流程。第三节介绍基于RNN实现双耳语音增强算法的关键部分,包括特征提取和RNN网络结构。第四节介绍了实验设置和实验结果。最后,第五节对全文进行了总结。
1 双耳语音增强模型
本文提出了一种基于RNN的双耳助听器语音增强算法(简记为BRNN)。该算法的设计原理如图1所示,主要分为特征提取部分、RNN网络部分和语音合成输出部分,图中省略了加窗处理部分,输入输出语音均为连续处理过程中的一窗语音。
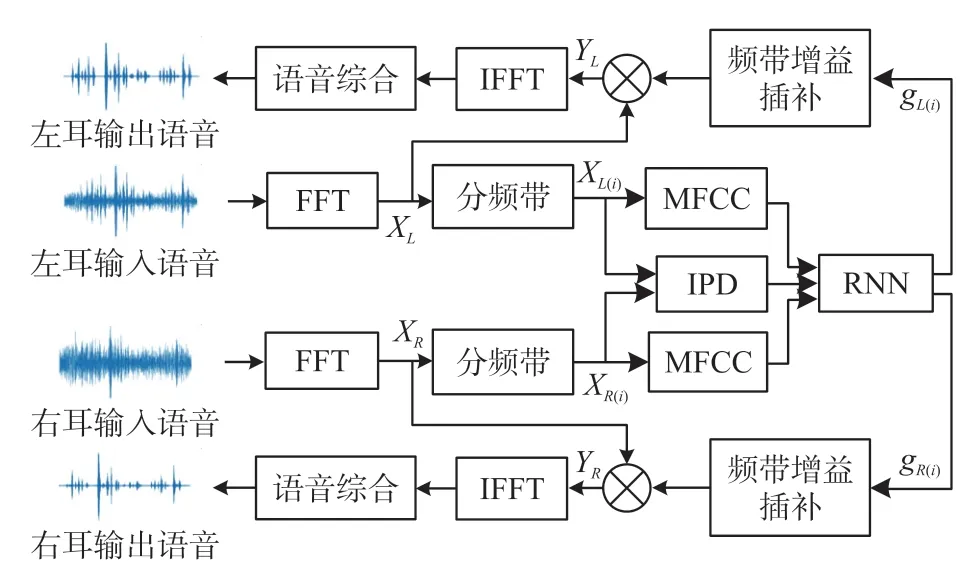
图1 双耳语音增强算法的结构图
第一部分主要是对双耳语音进行预处理然后提取双耳语音特征作为RNN网络的输入。首先,对时域的双耳语音进行快速傅里叶变换(fast Fourier transform,FFT)处理,得到频域信号(XL,XR);然后按梅尔尺度将频谱划分为16个频带(XL(i)、XR(i))。最后,对每个频带进行处理得到32维梅尔频率倒谱系数(Mel-frequency cepstral coefficient,MFCC)作为双耳语音信号的振幅特征,左右耳语音信号对应频带之间的IPD被提取作为双耳语音信号的相位特征(16维),因此一次处理获得48维的特征向量。第二部分使用双输入双输出RNN计算每个频带的输出增益(gL(i),gR(i))。通过使用大量的语音数据对网络进行训练,得到一个可以正确映射输入特征向量和各频带输出增益的RNN模型。第三部分是合成并输出增强语音。利用第二部分得到的频带增益对带噪频谱进行频域上的加权合成,得到增强频谱。通过快速傅里叶逆变换(IFFT)将增强的频域信号转化为时域信号,从而得到综合输出的双耳增强语音。
2 双耳语音增强算法
2.1 双耳语音特征提取
如何建立带噪语音和目标语音之间的映射关系,尤其是在复杂的声场环境中,是解决语音识别和语音增强的关键。在两个麦克风的近距离通话系统中,头掩蔽效应导致左耳和右耳麦克风信号之间的ILD和ITD的差异较为明显。因此,这两种听觉特征常被用来作为区别目标语音和噪声的重要线索[14]。但是考虑到双耳助听器正前方声源到达左右耳的语音信号的ILD和ITD近似为零,按照上述方法提取特征对网络进行训练具有一定的局限性,因此本文创新性的将语音振幅特征MFCC和包含双耳语音线索的相位特征IPD相结合,在时频单元中提取这两类特征作为RNN网络的输入。
对采样频率为16 kHz的双耳带噪语音使用窗长为16 ms的Vorbis窗进行处理,连续帧之间的重叠度为50%,帧移为8 ms。所用的Vorbis窗函数定义为:
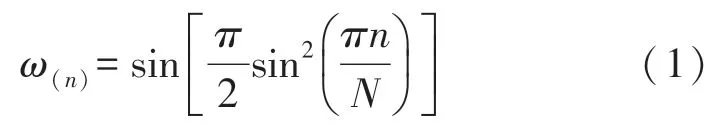
式中,n表示采样点数,N表示窗口长度。
为了减少输入特征的规模,降低计算复杂度,本文使用更符合人耳听觉特性的梅尔频率尺度将每帧语音分为16个频带,然后提取特征。梅尔频率尺度是语音处理中广泛应用的频率映射感知模型,它描述了音高感知的非线性映射,定义为:
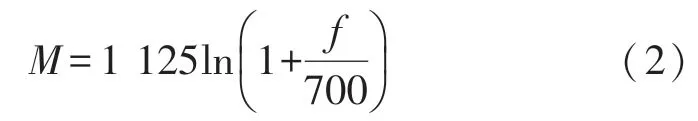
式中,M表示以Mel为单位的感知频率,f表示以Hz为单位的实际频率。
本文首先将感知频率平均分为16个频带,根据式(2)即可以得到对应的实际频率范围,从而实现频谱的划分。对于输入的双耳语音,本文通过以下步骤到语音振幅相关的MFCC特征:①使用Vorbis窗截取左右耳各16 ms的带噪语音(mixSL、mixSR);②对mixSL和mixSR进行FFT处理,得到频域信号XL和XR;③按照上文所述频带划分的方法将XL和XR分别划分为16个频带,从而得到第i个频带的频域信号XL(i)和XR(i);④计算左右耳每个频带的能量EL(i)和ER(i)。设第i频带k频率处的能量权重为ρi(k),我们有,因此,频带i的能量可以由式(3)得到;⑤然后将功率谱映射到对数功率谱,最后做离散余弦变换得到我们需要的MFCC。
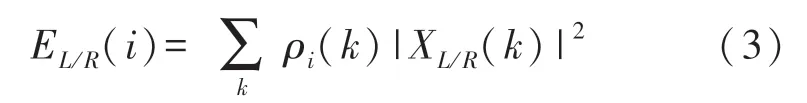
与文献[15]中IPD的计算方法不同,本文根据同频率下两个信号的互相关函数值与相位差的关系,简化了相位特征的提取方法。首先,计算左右耳信号频带i的自相关函数值RLL(i)、RRR(i)。然后,计算左右耳信号对应频带的互相关函数值RLR(i)。最后,由式(4)计算出IPD。

我们利用带噪语音和目标语音之间的关系定义左右耳语音各频带的增益gL(i)、gR(i)作为输出特征,公式如下:
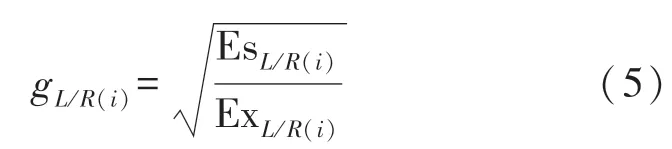
式中,EsL/R(i)表示左耳或右耳目标语音的能量,ExL/R(i)左耳或右耳带噪语音的能量。
2.2 RNN网络结构
语音的时间顺序是语音增强中十分重要的线索,因此本文使用可对序列数据进行建模的RNN来实现语音增强网络的设计。RNN通过将前一时刻的输出作为当前时刻输入的一部分来影响当前时刻的输出,以此来反映输入数据的时间关系。简单RNN存在梯度消失或梯度爆炸等问题。长短时记忆网络(Long shortterm memory,LSTM)及门控循环单元(Gated Recurrent Unit,GRU)。是简单RNN的改进结构,目前应用广泛。GRU是Cho等人在2014年提出的一种改进的LSTM算法[16],主要是将遗忘门和输入门合并成为一个更新门,同时合并数据单元状态和隐藏状态,从而使得GRU结构比LSTM更为简单且具有更好的长序列数据处理能力。为了节省计算资源并更好的利用语音的上下文关系,本文采用GRU来构建网络。本文设计了如图2所示的双输入双输出RNN模型结构,且为了突出MFCC和IPD两类输入特征,构建了振幅特征处理区和相位特征处理区,即首先分开处理MFCC和IPD特征,然后在一并输入到混合特征处理区进行处理,从而实现更好的语音增强效果。该网络由Dense层和GRU层组成,图2中标注了每层网络使用的激活函数类型和包含的神经元数。与传统的网络结构相比,本文将一些不相邻的层相互连接起来,使部分层的一些神经元可以更直接地处理特征。
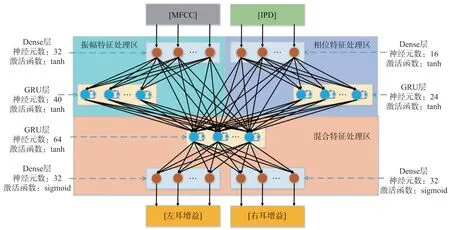
图2 双输入双输出RNN结构示意图
Tensorflow为NN训练和推理提供了强大的支持,在机器学习研究中得到了广泛的应用。考虑到tensorflow建模方便、运行速度快的优点,本文采用tensorflow建立训练网络[17]。NN训练时需要大量的数据来确保得到可靠的网络模型,为此本文提取了5千万帧语音特征用于训练,训练过程中采用梯度下降法对每次迭代后的网络权值进行修正。训练过程中使用的损失函数为均方误差函数(Mean Square Error,MSE):
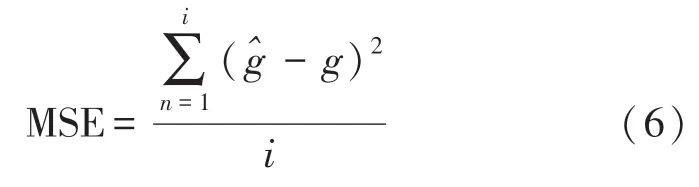
式中,g代表每个频带的输出特征,^g代表网络估计得到的每个频带的输出增益,i为频带数。左右耳语音增益的损失权重均为0.8,左右耳输出增益的性能评估函数均为交叉熵函数(my_crossentropy,MC):
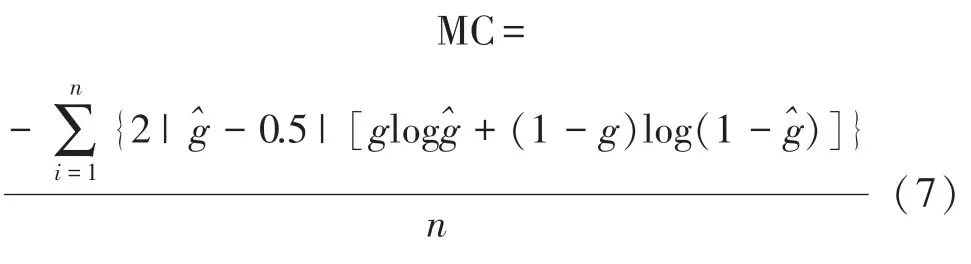
本文使用的神经网络进行了500次迭代训练,图3为训练过程中损失结果的变化曲线。从图中可以看出,随着训练次数的增加,损失结果逐渐变小,并趋于平稳。因此,我们得出该网络的训练是收敛的。
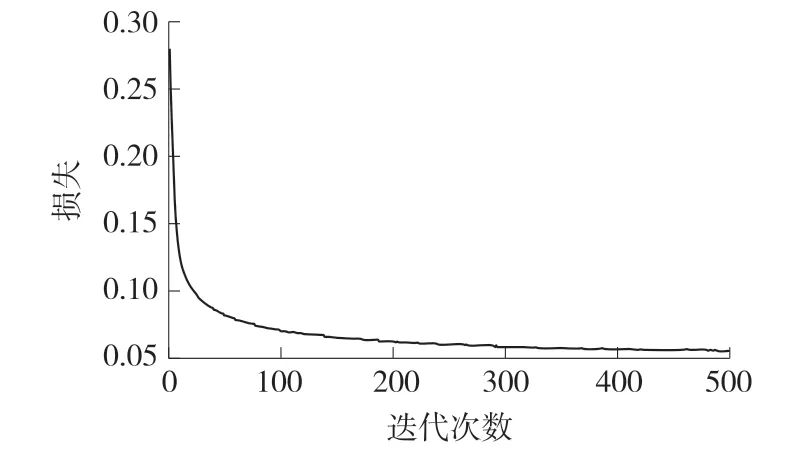
图3 训练期间RNN网络损失函数的变化曲线
3 实验设置和结果分析
3.1 双耳语音构造及实验设置
为了丰富训练集从而保证RNN更好的工作,本文将纯净语音和噪声随机混合,生成不同SNR的带噪语音。本文使用的纯净语音来自清华大学中文语料库THCHS-30[18]。该语料库是在安静的办公环境中由40位母语为汉语的人参与录制生成,其使用的文本摘自新闻稿中的1 000个短句,语音采样频率为16 kHz,采样大小为16 bits。噪声数据则是来自NOISEX92库[19],库中含有16种噪声,其采样频率为19.98 kHz,采样大小为16 bits。使用前需将噪声采样频率下采样至16 kHz。实验中使用的不同到达方向的目标语音和噪声由上述语料与MIT媒体实验室测得的头部相关传递函数(head related transfer function,HRTF)进行线性卷积合成[20]。
图4为模拟产生双耳麦克风信号的实验设置图,目标语音和噪声都位于距离假人头1.4 m的圆周上,且都在同一水平面上。考虑到助听器使用者在交流时总是面对说话者,因此本文主要研究目标语音到达方向为正前方(0°)的情况。在实验环境中,目标语音固定在0°,噪声可以位于不同方位角。训练噪声放置在图4所示的圆周上,范围为0°~360°,步距为5°,共有72个到达方向。测试时,选取0°、45°、90°、135°和180°5个噪声位置进行测试。

图4 双耳语音构造图
在应用场景中,除了目标语音外,还会有环境噪声。因此,麦克风收集的语音信号通常都是带噪语音。双耳麦克风在t时刻采集到的语音信号可以表示为:
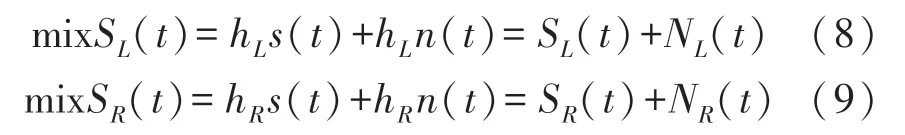
式中,s(t)表示目标语音,SL(t)、SR(t)分别表示左右耳麦克风接收集的目标语音,n(t)表示噪声,NL(t)和NR(t)分别代表左右耳麦克风收集的噪声。hL、hR分别表示左右耳的HRTF,⊗表示线性卷积运算。
3.2 语音增强的客观评价
THCHS-30库中未用于训练的语音被用来测试BRNN算法的语音增强效果。根据图3中的双耳语音模型,在0°的目标语音和不同方位角位置的噪声被创建。为了比较本文提出的BRNN算法的语音增强效果,本文还测试了助听器常用的语音增强算法对测试语音的增强效果,包括两种频谱减法(SS[3],MBAND[4])和一种基于维纳滤波的方法(wiener_wt[7])。此外,我们还比较了可用于视频会议设备中的基于神经网络实现的语音增强算法(Rnnoise[8])。在本文中,我们用信噪比(Signal-to-noise ratio,SNR)和短时客观可懂度[21](Short-time objective intelligibility,STOI)来客观评价BRNN算法对car噪声、volvo噪声和babble噪声环境中的带噪语音的增强效果。其中STOI是基于纯净语音和带噪语音的时间包络相关系数计算得到,且与主观语音可懂度正相关,其取值范围为[0,1]。首先排除静音帧,因为无声段对于语音可懂度没有影响;然后对语音信号进行傅里叶变换的1/3倍频带分解;最后通过相关过程计算得到STOI。具体计算过程如图5所示。

图5 STOI的计算流程
图6显示了不同方法在不同声压级的噪声环境中的语音处理结果,用于测试的双耳带噪语音是根据目标语音(0°位置)和噪声(45°位置)在五个信噪比水平上创建的:-10 dB、-5 dB、0 dB、5 dB和10 dB。从图5中可以看出,BRNN算法可以在各种噪声环境中均可提高带噪语音的SNR和STOI。整体而言,本文基于小规模NN实现的算法的语音增强效果与其他算法相比有明显改善,尤其是对于car噪声环境下的带噪语音具有突出的增强效果。综上所述,BRNN算法可以显著提高噪声语音的信噪比,在提高STOI方面也取得了比较好的效果,从而获得更好的目标语音。
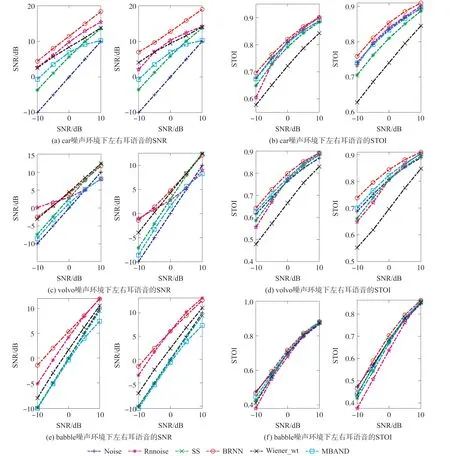
图6 目标语音在0°、噪声在45°条件下,各算法在三种噪声环境下的处理效果
助听器用户通常是面对说话者的。在目标语音位于正前方的条件下,本文比较了BRNN算法与其他算法对不同噪声位置干扰环境中的语音增强效果。用于测试的双耳语音是根据目标语音(0°位置)和噪声(0°、45°、90°、135°和180°位置)在0dB水平上创建的。表1和表2分别显示了在不同干扰位置下,各个算法处理后的左右耳语音的SNR和STOI,且计算了五个干扰位置条件下的平均双耳测试结果,以比较各个算法的语音增强性能。
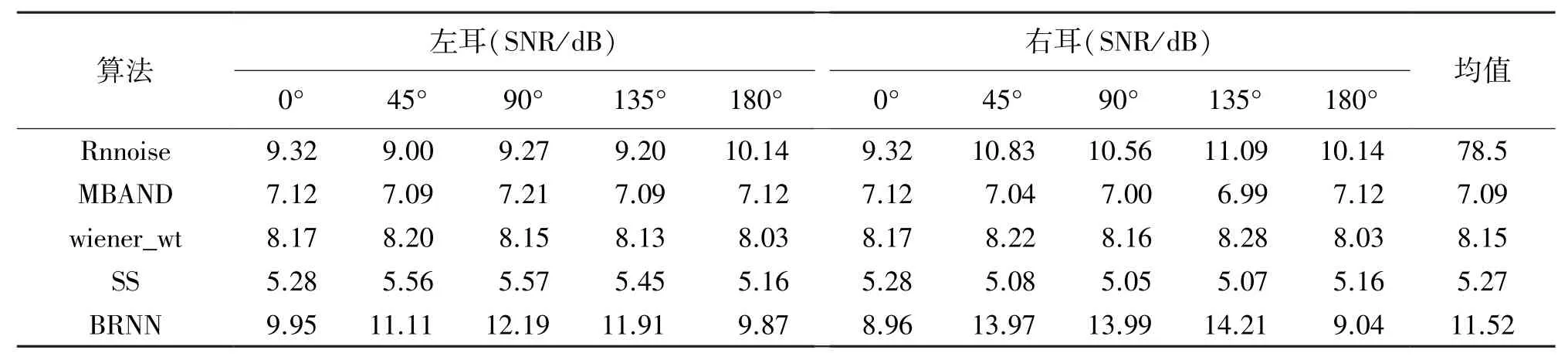
表1 各种算法处理后语音的SNR比较(五个干扰位置)

表2 各种算法处理后语音的STOI比较(五个干扰位置)
从表1可以看出,与传统的语音增强算法(三种方法的平均值)和Rnnoise相比,本文提出算法的双耳平均信噪比分别增加了4.68 dB和1.63 dB。从表2可以看出,与传统的语音增强算法(三种方法的平均值)和Rnnoise相比,本文提出算法的双耳平均STOI分别增加了4.5%和4.8%。从表1和表2的测试数据还可以发现,BRNN语音增强的效果与噪声的到达方向有关。因为当噪声到达方向为0°和180°时,IPD接近于零,所以与其他算法相比,语音增强效果没有明显优势。当噪声到达方向为45°、90°、135°时,IPD存在明显差异,所以与其他算法相比,BRNN增强的双耳语音具有较好的SNR和STOI方面的改善效果。总之,与其他算法相比,BRNN不仅能显著提高语音的信噪比,还能保证其更高的STOI。
3.3 FPGA验证结果
为了验证在助听器硬件中使用BRNN算法的可行性,本文设计了RNN网络模块的Verilog HDL代码,并使用Digilent公司生产的Nexys4-DDR系列开发板进行测试。本文网络需要49 104个权值,比实时处理算法Rnnoise的网络权值(需要87 503个权值)少44%,比文献[22]中提出的不具有实时处理算法的网络权值(需要220万个权值)少97%以上。通过Vivado对本文网络硬件设计进行综合,从综合报告中可以得到该设计所消耗的FPGA资源。
表3显示了查找表(LUT)、锁存器(FF)、DSP和时钟缓冲器(BUFG)四种资源的利用率。本文采用基于Xilinx公司artix-7 FPGA的Nexys4 DDR板。
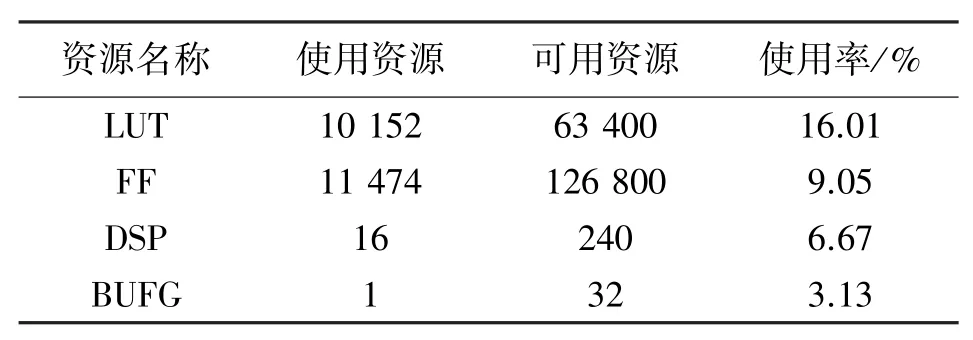
表3 硬件设计消耗的FPGA资源
通过表3可以发现,LUT资源利用率最高,但不超过20%,因此我们有足够的资源来实现所提出的RNN网络。本设计使用开发板搭载的XC7A35TCPG236芯片的封装尺寸为10 mm×10 mm,可以放在耳挂式助听器中,因此次网络设计具有在助听器硬件实现的可能。
研究表明,人们在交流时,当看到对方嘴唇的动作和听到对方说话的时间差不超过15 ms时,不会感觉到语音延迟[23]。测试结果表明输入信号有效后,FPGA需要42208个时钟周期得到相应的输出。即当系统时钟频率为10 MHz时,需要4.2 ms处理时间,满足助听器实时工作延时的要求。
为了验证所提出的算法在FPGA上运行是否正确,本文测试了其对4段SNR为0dB的带噪语音的增强效果,并与用计算机(PC)仿真处理结果进行比较,表4列出了实验结果。我们可以发现,PC和FPGA上处理的双耳语音的SNR基本相同,相关系数非常接近1,从而进一步验证了本文提出算法实际应用的可靠性。
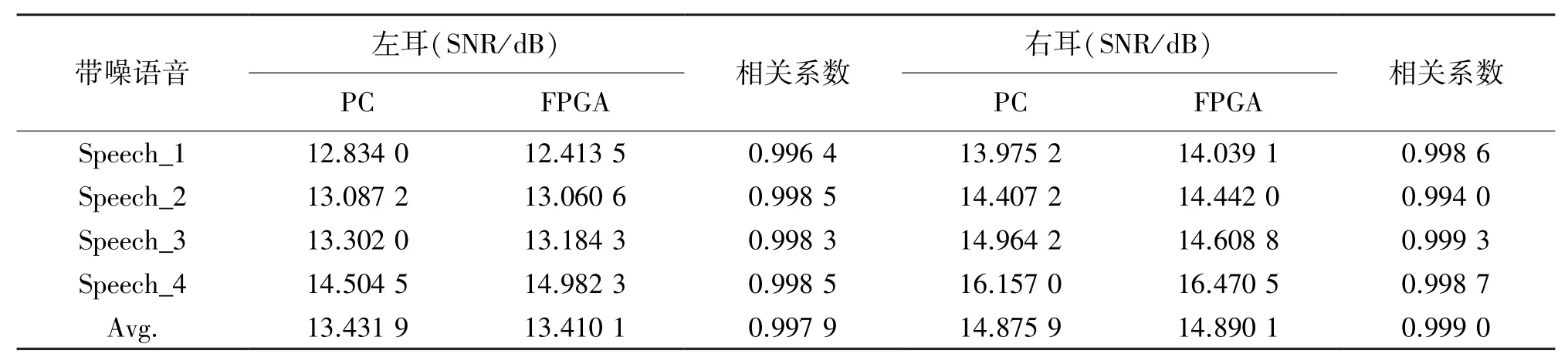
表4 基于FPGA和PC处理后的双耳语音的SNR和相关系数比较
4 总结
本文基于循环神经网络提出了一种结合双耳语音信息进行语音增强的算法。对一帧双耳语音提取32维振幅特征和16维相位特征作为RNN的输入,以更好地映射带噪语音与目标语音之间的关系。此外,我们创新的提出了一种具有振幅特征处理区、相位特征处理区和混合特征处理区的双输入双输出RNN模型。实验结果表明本文算法在car、volvo和babble噪声环境中,在保证语音可懂度的同时均可以较好的提高语音的SNR。FPGA实现RNN网络的结果表明,LUT,FF,DSP和BUFG资源的利用率均小于20%,且在处理时钟频率为10 MHz时,硬件处理延迟为4.2 ms。总之,本文提出算法具有可在助听器中硬件实现的可能,且可以提供比助听器常用语音增强算法更好的语音增强性能。在未来的研究中,我们将致力于实现该算法的硬件设计,从而应用于助听器中进一步提高其性能。
