微博媒介使用中的用户趋同化现象与路径
——基于新浪微博用户的实证分析
2021-11-11徐翔
徐 翔
(同济大学 艺术与传媒学院,上海 201804)
社交媒体时代的强势崛起,产生了微博、Twitter、Facebook等典型新媒介平台和“用户生成内容”(User Generated Content,UGC)网络应用。社交媒体的使用和传播,是生成和促进用户在表达内容上的多样性、“部落化”?还是减少内容异质性与多样性,增强用户同质性和趋近性? 这个问题,在多种媒介理论和经验视点的碰撞下,存在着持续而且复杂的论争。
一方面,就互联网及社交网络平台特性而言,有学者认为,互联网能够促进多元意见的表达,提升公共讨论[1]。Lee 等[2]进行的一次全美概率抽样调查结果表明,在Facebook、Twitter和其他社交网站上,人们的交往网络更为多元化,回声室效应并不显著;在社交媒体中,获取新闻、发布新闻等与新闻、信息相关的活动能够促进社交网络的异质性。Barberá 研究得出:总体而言,社交媒体用户接收的观点是多元化的,并且随时间推移,那些嵌入在多样化网络中的美国用户会逐渐关注较少意识形态同质性的群体[3]。Brundidge 提出,人们在线上互动依据的是不经意原则(inadvertency),最终会导致多元化个人网络的形成[4]。另一方面,对立的观点和分析,则反对社交媒体过度理想化的“公共领域”和异质性。有研究者认为,互联网只是便利了选择性接触和近似观点的强化[5-7]。Freelon 等根据有关叙利亚的转发帖子衡量社交网络同质性是增加还是减少,发现研究的9个组整体上呈现出高度同质化和碎片化特征,并且8个组都直接形成同质化分组[8]。Leskovec 分析具有时态信息的四个大型社交网络,证实同质性的存在[9]。
本研究的主要观点是:(1)微博帖子或许存在着“碎片化”的异质性,但是如果将某个用户所有发帖从“碎片”组装还原为该用户的“内容整体”,那么用户会表现出越来越减少独特性、越来越趋同化的现象。(2)对于微博媒介的使用是用户“越使用、越趋同”的重要驱动机制。(3)微博中的媒介使用对用户产生的多种趋同化作用具有内在统一性。
一、文献综述与问题分析
微博与社交媒体的用户内容同质化,可以回溯媒介文化、媒介技术的文化考察及其理论资源。20世纪中叶,法兰克福学派对于大众传媒、现代意义上“文化工业”的批判中,提出著名的“文化工业”概念,指出在规模化、商业化的文化生产和流通中,文化逐渐同一化、非个性化[10]107-152。“文化工业”的批判理论视角中,蕴含着文化内容及其生产、消费、趣味中的一系列同质化、同一化,乃至主体性被同质化文化内容所侵蚀之忧思。马尔库塞提出“单向度的人”[11]提出“单向度的人”,从另一个角度反思技术影响下的去异质化。对此,今天面对社交媒体需思考的是,在表层“碎片化”帖子信息和“肉眼可见”的个体差异中,“提炼”所谓的多样化、去中心性以及“人人时代”[12]的媒介赋权,有可能忽视丰富内容流动之下潜藏着的深层趋同性与同一化。对于微博用户的分析,理论上需要回应的基本问题包括:(1)作为媒介文化的重要领域,微博媒介场中的用户内容趋同化,是否的确存在?(2)如果趋同化是存在的,那么用户的趋同程度是均等化的还是有着内在差异?何种条件下生成趋同程度的差异?(3)批判理论之所以遭受到强力攻击,尤其是来自坚持意义多样性、受众主动性的一些经验研究攻击,其重要原因之一是在自身关于“文化工业”的同一性框架中,对于多样性、异质性过于简单粗暴地“视而不见”,而未能将后者很好地融合到理论整体中。因此待重视的问题是:即使微博用户“趋同”是可验证的,但用户实际上“肉眼可见”广泛显现的内容差异性和多样性需要很好地兼容于趋同性架构,而不应只是把两者强行并置为“既A且B”的生硬统一。
由于社交网络中用户的共同兴趣偏好、内容偏向、选择性接触和传播,导致“用户社群”或“用户网络连接”中形成和表现出同质化,它是用户趋同的原因中被关注的主要方面之一。Himelboim等[13]通过社会网络分析和聚类的方法分析了在Twitter上全球变暖、赤字问题、移民改革等10个争议性话题发表看法的500位用户,发现从集群内角度看,其观点、立场同质化明显。朱庆华、袁园及孙霄凌[14]以新浪微博为研究对象,随机选取 500 个微博达人样本,筛选出他们关注的其中 32 位明星微博,结合社会网络分析方法和聚类分析,充分显示出微博社区的社会关系中具有很强的中心集中趋势,大多数微博用户存在着某些共同微博使用目的和关注习惯。陈福平和许丹红点[15]使用皮尤“互联网与美国生活项目”2012年发布的调查数据研究指出,在社交网络的技术、媒介和社会网络三重特性的相互作用下,使用者会选择观点的隔离并转而链接同质群体,这一构建过程最终导致网络群体极化产生;在政治观点表达更为活跃的社交网络中,人们认知到相异观点几率反而下降;社交网络的使用频率越高,使用者越倾向对相异观点保持沉默,越倾向隔离相异观点。王晓光[16]通过对微博用户社会网络分析后指出:普通微博用户在线上更容易陷入特定主题交流社区,关注对象通常集中在特定的核心微博上。Lawrence[17]发现微博链接中意识形态隔离,跨党派产生实质交流的机会很少。总体来看,用户倾向于和具有共同内容和兴趣的用户、群体形成选择性的连接,带来观念和内容隔离甚至形成“回音室”,这些都是微博用户同质化形成的关键组成部分之一。
从表层而言,在这些网络“回音室”、观念隔离、选择性接触等同质化效应中,验证了用户会产生相似意见与态度。但用户在部分意见、态度、帖子内容的相似化,并不等于用户整体内容的相似化。还隐含着的重大问题是:用户因共同观点、内容偏向而形成的连接与聚合,在现有研究中大部分是局部或微观的,也即研究个体和个体的微观之间或有限规模社群内的相似化。这对于另一个重要问题则关注度不够:社交网络全局范围内的趋同化,或是批判理论意义上的“宏观”同一化。其中隐含着的理论紧张是:局部个体、群体的网络“回音室”“观念隔离”,在加强局部化趋同的同时,它是使整体陷入一个个微小趋同局部、“巴尔干化”,还是可能伴随和催动整体趋同化?
微博和社交媒体用户的内容生产过程中,一些内容、主题带有偏向,会引起用户朝特定类型内容偏倚与分布,从而限制用户“自由”生成内容的异质性。尽管“人人都有麦克风”,社交媒体、自媒体赋予了“用户生成内容”很大自主和“草根”性,但是内容生产中蕴含着趋同化的内在动力,被研究者所注意。被卷入到平台规则体系中的用户内容生产中,以召回率(Recall Rate)为目标的内容推荐算法带来了内容选题、类型和风格的系统化倾向,直接影响到内容生产者的旨趣;内容召回和用户留存的前提在于内容的高效产出,这促使内容生产活动变得愈加职业化和标准化[18]。有学者强调,“合法性危机”是造成传媒机构和组织出现“同质化”现象的根本原因,这一危机导致“强迫机制”“模仿机制”和“社会规范机制”相互作用,最终使得传媒出现相当程度的同质化[19]。张志安等[20]24-30的研究则显示,微博舆论场中,营销类、娱乐类用户成为微博意见领袖群体的主流。这也意味着,大量用户朝向“娱乐至死”“营销致死”的类型偏倚会减少微博中的用户内容丰富性,加强在少数类型上的集中化和相似化。就微博信息、资讯的主题类别而言,有研究支持,不同主题类别微博被转发的概率存在显著差异,平均转发数相差可达10倍,各类主题在微博信息扩散效果和用户扩散能力方面都表现出强弱分化的特征[21],从而使得用户的内容生产、传达表现出在特定主题上的偏倚。这些建基于用户内容生产和内容扩散过程中的研究,关系到用户内容在逻辑上的趋同可能性和应然性。在此基础上,仍有待进一步探及的问题包括:用户的内容生产过程和微博使用过程,如何以及以怎样的程度影响着用户内容同质性?
在线用户之间社会关系和社会网络是影响和加强用户同质化信息传播的重要因素之一。用户自主构建的个性化信息获取网络首先与其社交关系网络相关,当人们以社交关系构建起自己的信息网络时,也就建立了一道无形的墙,将一些信息阻挡在外面[22]。用户社会关系和信息的同质性选择、同质性扩散之间存在着相关性。Colleoni等[23]对Twitter使用者的考察发现,具有共和党和民主党倾向的人群互动中的“普遍同质性”(某个用户的关注同党派人的连接数除以他的全部关注数量,数值在区间[0,1])都超过了0.8。Conover等[24]使用聚类方法分析超过25万条Twitter消息的转发网络和评论网络,其中出现了隔离结构,高度模块化的社群图被分隔为簇状,这种簇状连接被认为是同质化甚至群体极化。在这些因素的影响下,用户接触、连接异质信息的用户存在一定的用户间壁垒。信息更多的在同质用户圈层中流动而难以“出圈”,不同圈层间的态度、立场的分歧甚至对立可能会增加[25]。这类研究确证了网络“强关系”“弱关系”中可能存在的信息同质化。但与此不同的是:微博空间不只是由用户的社会连接关系构成的在线社会,也可能是由某些具有共同在线特征、微博话语特征的“用户阶层”“用户层级”构成的在线社会。例如,具有相近的粉丝量或帖子影响力的“大V”“顶部用户”用户层级,亦或具有相近微博使用度的“浅度用户”“重度用户”层级,这些具有不同的媒介化等级和“能量”的用户可能并无共同的好友关系或群体纽带,但是它们可能具有共同的信息趋同特征。微博使用端的用户作为“媒介的延伸”,其媒介使用本身、使用过程中“媒介化”程度和结果需要加以细致考量,而不是在过度重视社会学、人口学、网络行为学等外在因素中忽略“回到媒介”的本体论向度。用户在微博的媒介使用中如何形成、表征其内容趋同化,是现有研究中尚挖掘不充分的。
有研究指出,微博中的内容存在对特定主题如娱乐、营销的偏向[20]24-30。但是这种朝向特定内容域的偏倚并不能推导出用户必须趋同。在任何一个社会文化系统中,无论该系统如何偏重于某些局部主题,都和系统中主体之间的差异性、波动性并不矛盾。另一方面,在显而易见的帖子丰富性、个体主题和兴趣差异化背景下,微博用户是否以及如何体现其趋同逻辑?综合现有研究,并关注微博、社交媒体现实,以下相关联问题值得继续思考:
A.关于社交媒体用户连接、用户行为、传播行为的研究,尤其是其中的大量实证研究,虽然不断触及用户的观念、内容、态度和立场的同质化,但是这些研究范式基本的指向都是用户是否以及如何形成局部、微观、个体尺度的同质化。例如具有强关系或弱关系的个体之间的相似性,群体内部的“回音室”和群体意见极化、“巴尔干化”,关注和被关注、转发和被转发过程中的信息同质性。与之不同的是,宏观媒介场和全体用户群,是否以及如何表现出趋同化?
B.和A相关,微博用户如果在宏观尺度表现出内容趋同化,由于“肉眼可见”的内容差异,那么这种整体上的趋同化必然是不均等、不均衡的,它不同于批判学派意义上“抽象”的标准化和笼统的同一性。与此相关的是,不同用户的趋同,是否以及在怎样的条件下体现着强弱、程度的差异?相比较于社会经济地位、亚文化和社会群体背景、人口学特征等更为显见的变量,微博使用程度看似更为间接,也往往被前者所转移注意力。但如果趋同是在微博使用中发生的,那么对微博的使用度就是最为直接关联的变量之一,关系到用户“越使用,越趋同”的问题。
C.对于由多行动者(agent)构成的系统而言,其趋同策略包括平滑扩散趋同(Flat Diffusion Convergence)和非平滑扩散趋同。前者中每个行动者的地位是平等的,由于没有优先的策略值[26];而非平滑的扩散趋同中,存在着具有优越性的趋同策略,使得系统最后的趋同结果会聚集于这些高地位的agent的策略值[27]。对微博用户组成的系统而言,是否存在朝向这些更高优先性的趋同方向和趋同标的?例如,微博系统中具有更高使用度的用户。
D.除了高优先性的趋同方向差异,还存在着全局扩散趋同和邻域扩散趋同。其一,在邻域扩散趋同中,每个agent逐步根据其领域的agent策略平均值来进行自我调整,从而最后实现整个系统的趋同[28]。其二,在其他一些情况下,行动者不仅只是感知到邻域的影响,还会受到其他非邻居的作用,形成全局扩散趋同(Global Diffusion Convergence)[29]。当前研究主要集中于各种形式、条件的邻域趋同,而对全局趋同则关注不足。因此对于微博用户,还需关注两方面:他们是否以及如何体现和全局用户趋于一致的全局趋同化?是否以及如何体现和相近用户的“邻域”趋同化?
E.由A、C、D可推知的是,如果用户随着其微博使用度的提升,而和某些或全局用户变得趋于相似,那么最接近“标的”甚至约等于“标的”的(无论该“标的”是什么样,在此并不重要)用户,也就是最高使用度的那批用户。从而,带来用户和“最高使用度”的“顶部用户”趋同的态势。这不是独立的假设,而是基于C和D的推断。
F.微博用户在C、D、E中所涉及的多种趋同路径,是统一、同步的,还是矛盾、对立的?亦或独立、无关联的?例如,趋向于全局用户的同化和趋向于邻近用户的同化,两者是矛盾的或至少是独立并行的效果吗?而全局趋同、邻域趋同和趋向优势用户的趋同,又是何种关系?一方面,基于A、C、D尤其是E可以推断,趋于和“最高使用度”顶部“标的用户”的趋同是和其他某些趋同性具有同步性的。但这种同步性广泛到什么程度,能否强烈到能使看似“风马牛不相及”的全局趋同性和邻域趋同性之间同步,甚至使全部的趋同化程度表现出同步性,理论尚难以推断,还有待实证的继续研究。
基于上述可资借鉴的成果和对于微博中实际问题的分析和推断,提出相互关联的核心观点。在此首先要予以说明的是,全文分析和研究中,把微博用户按照相同或相近的使用度进行社会“分层”,采取了数据挖掘中常用的等频“分箱化”预处理,例如社会区分下的“用户层级”。这种分箱化或分层的预处理,可以减少个体的过大随机“噪音”,更为清晰地分析自变量条件下的趋同化演变规律。如果不是要精确地根据某些条件去预测个体,而只是试图考察在这些条件下的用户的变化态势和机制,那么对用户的“分层”研究就可以达成后者的目的。而且,通过具有相同特征的用户分层捕捉某种、某类个体的共同特征,可增强计算与结果关联的稳定性,同时有利于加强对微博用户阶层和群体特征的社会考察而非个体考察。尤其对于“意见阶层”内部高同质化关系的分析,更需要把用户群作为分层后的整体来考察。这些是本文研究以用户“社会层级”为单位而不是以“个体”为对象的多方面原因。
首先,整体研究的基本观点为,用户的微博使用程度存在着和其内容趋同化程度之间的正相关。其中,把微博用户作为一个个“帖子内容单元体”,也即由该用户所生产、发布的所有帖子内容构成的一个基本单元。这个问题可以转换到用户“分层”的社会学群体视域,也即,使用度越高的用户层级,则该层级人群的平均趋同化程度就越高。在此基础上,进一步分析。
(Q1)用户内容趋同化。用户在微博使用中,消减自身的独特内容,变得和某些用户“模板”或“社会层级”越来越相似,从而发生趋同化:Q1.1.受到全局媒介场的作用,和全体用户越来越相似与同质化(可称为全局趋同化);Q1.2.趋向和最高使用度的“典范”用户层级越来越相似 (可称为顶部趋同化);Q1.3.朝向具有和自身相同或相近的媒介使用度的“邻近”用户的趋同化(可称为近邻趋同化);Q1.4.趋向和自身使用度相同的本层级用户的趋同化(层内趋同化)。对这些可能的路径进行综合考察,这四种趋同化的指向与内涵如图1所示。
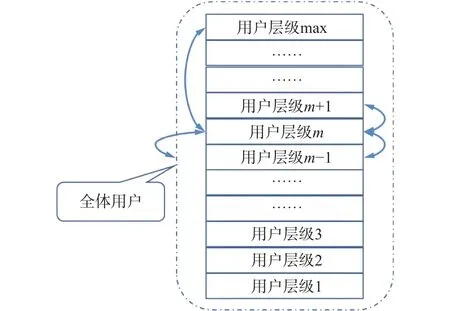
图1 基于媒介使用度的用户分层及其趋同化路径
对于全体用户中任一使用度水平的用户层级m,面临着几种不同的削弱自身内容的个性、趋同于他人的路径:(1)层级m内的用户的彼此间的平均相似度(层内趋同化);(2)用户层级m与使用度最为接近的近邻层级(m−1)和(m−1)发生趋似(近邻趋同化);(3)m可能朝向使用度最顶层的用户层级MAX发生趋似(顶部趋同化);(4)m和全体用户发生的趋似(全局趋同化)。至于这四个层面是全部成立还是部分成立,亦或全部不成立,则留待后文的实证检验。
(Q2)用户内容趋同化的四种路径的一致性。Q1.1(全局趋同化)、Q1.2(顶部趋同化)、Q1.3(近邻趋同化)、Q1.4(层内趋同化)这四种不同标的的趋同路径,不是矛盾的、相互掣肘的,也不是互不相关的,而是一致的、同步的。全文的逻辑结构和内在关系如图2所示。
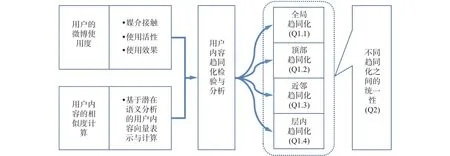
图2 整体逻辑结构
二、研究设计
(一)概念与指标界定
Weng[30]在分析Twitter用户同质性时,将同质化定义为共享相似内容并因此表现出相似兴趣的趋势。在群体行为的“趋同”现象中,每个行动者都具有一定行为策略值;行动者在初步阶段可以任意选择自己的策略值,但是随着时间的发展他们最后会选择同一种策略值[31]。本文将微博用户内容“趋同化”定义为:用户在微博媒介使用程度较低时,其发布的内容较为独特化和异质化;而随着对微博使用度的不断加深,用户会减少内容的独特性和个性化差异,增加与他人的相似性。
1.全局相似度层面,也即用户和全体用户、“芸芸众生”的平均相似度越来越高,“泯然众人矣”而越来越磨灭自己的内容个性与独特性。
2.趋顶相似度层面,也即用户和某种使用度最高的用户群体(可理解为社会聚光灯下、远在普通人之上的那部分“典范”人群),其平均相似度越来越高。例如,注册时长越久的用户,他们会和注册时长最长的那部分用户越来越相似。
3.近邻相似度层面,也即用户和具有相近使用度的用户,其平均相似度越来越高。用户不仅在趋似于“芸芸众生”和典范性的“顶部用户”,也在趋似于媒介使用度方面和自己最为“邻近”的用户和社会层级。
4.层内相似度层面,也即用户所处的具有相同使用度的层级内部,其平均相似度会越来越高。例如,如果用户划分为“最低使用度”和“最高使用度”的不同的“阶层”,则“最低使用度”的阶层内部会比较松散,大家彼此各不相同的程度很高;但是“最高使用度”的阶层内部的各人则彼此更为相似,相互趋近的“密度”和“黏稠度”比“低使用度”阶层高。本段所述的层内相似度,既是一个相对独立的猜测,同时也是来自第1个和第3个假设的自然延伸:如果用户随着微博媒介的使用,而在内容生产上受到各种“消磨个性”“泯然众人矣”的作用,他们进行内容生产的“自我弹性”越来越小。这样能预期的是,初级、低级使用度的层级虽然是“大流”“主流”的用户层级,但是该层级反而是更为异质化的,而不是缺乏差别和个性的“群氓”。而与一般的直觉不同的是,高使用度的用户、各垂直领域的精英用户等中、高“社会层级”内部反而是越来越高度同质化。这一点也是本文对用户样本采取“分层”研究而不是个体研究的重要原因之一。
样本选取自新浪微博。作为中国互联网2.0时代的代表性社交媒体和自媒体平台,新浪微博发展至今,活跃用户数量超4亿,用户覆盖范围广。对于新浪微博使用程度的衡量,从以下方面进行。
1.最基本的层面,是对微博的媒介接触和“浸泡”、卷入,这里采取用户的微博账户注册天数来反映。
2.最基本的媒介接触并不意味着对媒介的使用活性,因此进一步考察其使用的活性,这里采用微博用户的账户经验值、微博用户关注他人数量来衡量。其中,各微博账户的经验值来自新浪微博的公开数据,直观地反映了用户在新浪微博的使用活跃性和经验,获得经验值的方式主要为:发微博,连续登录账号。而用户关注他人,反映了用户在新浪微博使用中的主动性,积极寻求和其他用户的信息传播、关注和建立一定社会连接。用户关注他人数存在大量低关注数的“长尾”,取常用的对数函数转换法,也即:xnew=log2(x+1)。
3.有媒介接触、媒介使用活性,并不就意味着拥有使用的效果,那么这种使用即使很持续、很活跃,但也可能只是一种低效的、低显示度的使用。因此,进一步考察新浪微博用户的使用效果和影响,一是采用该用户所有发帖的平均热度,也即某用户各帖子的被点赞数、被转发数及被评论数,分别由对数函数转换后在[0,1]区间归一化,并等权求均值,作为该用户的帖子平均热度值,即:xnew=[minmaxlog2(x1+1)+minmaxlog2(x2+1) +minmaxlog2(x3+1)]/3,其中x1、x2、x3分别指用户的帖子平均转发数、平均评论数及平均点赞数,minmax()将数据在[0,1]区间予以最小最大归一化。二是采用用户的粉丝数作为直观指标之一,涨粉、粉丝量是微博用户影响力和网络话语地位的一个简单而有高区分度的指标,该指标和关注他人数一样符合大量长尾的幂律分布,也取对数函数转换得到,即:xnew=log2(x+1)。微博的使用度指标从三大方面、五个子指标构成,如表1所示。

表1 微博使用度指标
用户使用程度的上述指标量纲不一致,而且分布不一致,各个指标的随机波动也很大。为了简化研究,采用常用的“分箱化”策略,对用户在每一种使用度指标下,划分为等频(等人数)的由低到高的30个“社会层级”。
(二)数据获取和预处理
运用开源网页文本抓取工具“八爪鱼”,以及自行用python和selenium编写的动态网页抓取程序,抓取新浪微博用户资料及其发帖。从新浪微博首页 47 个内容版块(分别是:社会、国际、科技、科普、数码、财经、股市、明星、综艺、电视剧、电影、音乐、汽车、体育、运动健身、健康、瘦身、养生、军事、历史、美女模特、美图、情感、搞笑、辟谣、正能量、政务、游戏、旅游、育儿、校园、美食、房产、家居、星座、读书、三农、设计、艺术、时尚、美妆、动漫、宗教、萌宠、法律、视频、上海)中,持续一个月每天抓取2次帖子,从这些样帖整理得到 10 037 个发布者。本研究出于规模和成本所限,未采用大规模随机漫步等抽样方法,但采样时间持续了一个月,并非某个短时间内的抽取; 而且结合了新浪微博自身的内容分发系统,广泛而大致均衡地分布在 47 个大内容类型版块,因而也体现出较大覆盖面和良好程度的代表性。2018年10—12月期间,采集这些发布者用户的URL信息,并在此基础上进一步采集 10 037 个用户的用户名、性别、所在地、粉丝数、关注数、发布微博数、注册时间、等级及会员信息等多种信息;根据用户URL地址,对用户发帖进行抓取,得到去重后的微博数量 34 892 987 条。由于帖子过少可能难以充分反映出用户内容特征,所有只保留样本帖在 3 000 条以上的用户,剩下 7 825个用户用于最终分析,并且每个用户一律随机抽取其中 3 000 条帖子,以增强口径的统一与横向可比较性。用 python 编程语言对文本进行繁体字简化,采用在学界和业界较为常用的 jieba 模块完成中文分词。
(三)基于潜在语义分析(LSA)的文本表示与用户内容向量化
潜在语义分析(Latent Semantic Analysis,LSA)是一种文本降维和分布式语义表示方法[32]。一般的向量空间模型(Vector Space Model,VSM)高维、稀疏的文本表示方法不同的是,LSA利用在文本数据挖掘中广泛应用的奇异值分解(Singular Value Decomposition,SVD)技术,将文档的高维词频表示投影到低维的潜在语义空间中,通常可以把数万、数十万以上的高维、稀疏表示降到数千、数百的低维表示,而且这种低维向量反映着词汇在语义上的内在联系。其中,对于文档-词项的矩阵X进行奇异值分解可得:X=TΣDT。LSA通过奇异值分解,保留前k个最大奇异值,通过降维后的k个潜在语义主题以代替、表示原有全部词项的信息;也即,通过TkΣkDkT来近似地表示原文档-词项构成的矩阵X。
本研究对每个微博用户,其所有样本帖{x1,x2,x3,…,xn}拼接为一个长文档,每个用户之间是有其区分度的。7 825 个用户共得到 7 825 个长文档,并通过向量空间模型将其转换为一个词频矩阵X,其中剔除出现频次少于30的词,降低噪音的干扰,也保留更为主要和有价值的信息。并对这个矩阵X通过LSA算法降为7 825×500 的矩阵。LSA 降维工具采用 sklearn 中的 TruncatedSVD 模块。选择降到 500维,是通过实验显示500 维处于一个误差的“拐点”,再增加维数对于保留原始信息已大幅放缓(如图3所示);而且降到 500 维时已达到 0.90 的解释方差比(explained_variance_ratio_,降维后各维数的方差值占总方差值的比例,最大值为1),对于原始信息已有足够充分的保留和反映,如表2所示。
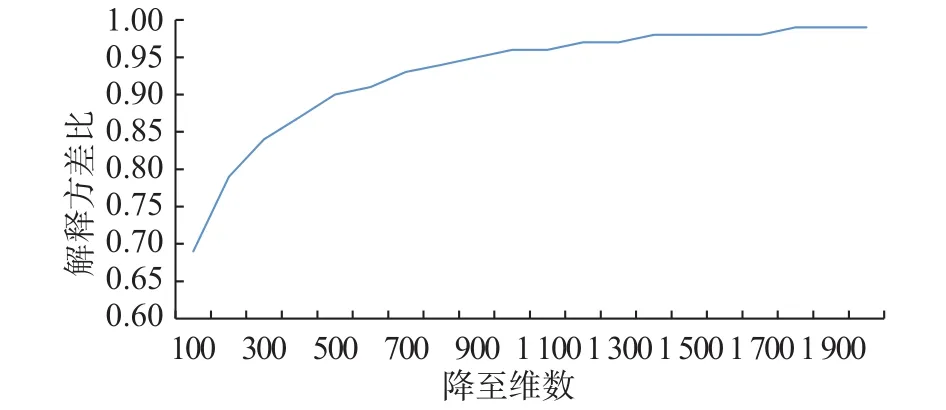
图3 潜在语义分析(LSA)降到不同维数时的解释比变化情况
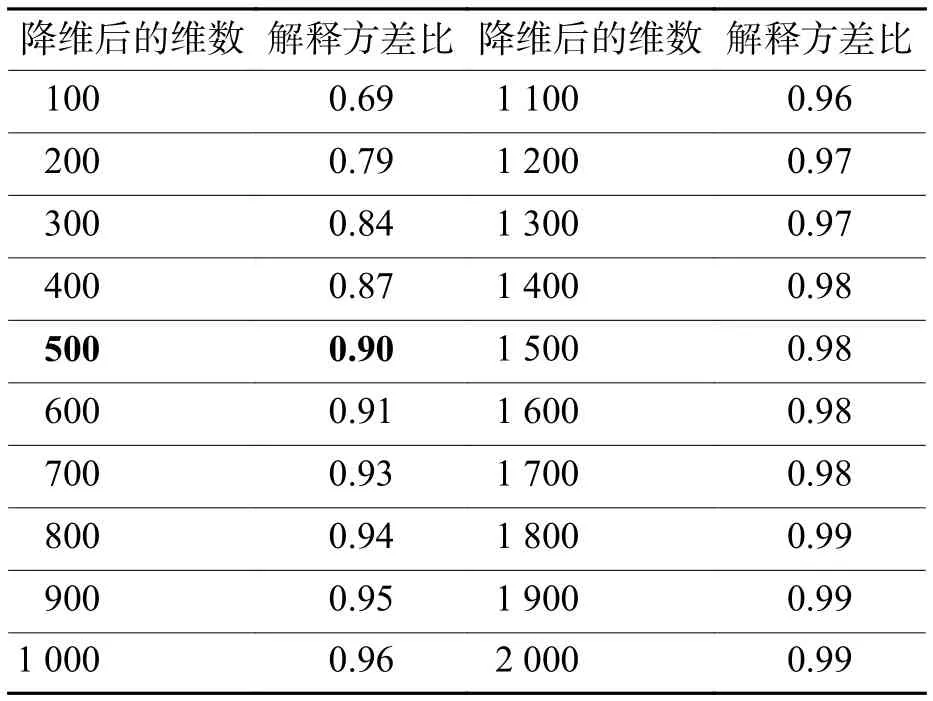
表2 LSA降到不同维数时的解释比
(四)用户内容相似度计算
对用户的内容相似度计算,选择在文本挖掘、语句相似度计算及自然语言处理中比欧氏距离更常用、也具有高度稳健性的余弦相似度。将用户的诸条帖子拼接为一条文档,并通过LSA的降维、转换后,将这个文档转为一个低维度向量。
任意两个用户m和n之间的内容相似度表示为R(m,n)。其中R(m,n)的计算方法为:将这两个用户m、n分别转换得到两个向量A、B之后,余弦相似度也即两个向量A、B之间夹角的余弦cos(θ)

该值范围在[-1,1],值越大表明这两个用户之间内容越相似。
在上述R(m,n)的基础上,任意一组用户G1(包含n1个用户)和另一组用户G2(包含n2个用户)的内容相似度表示为
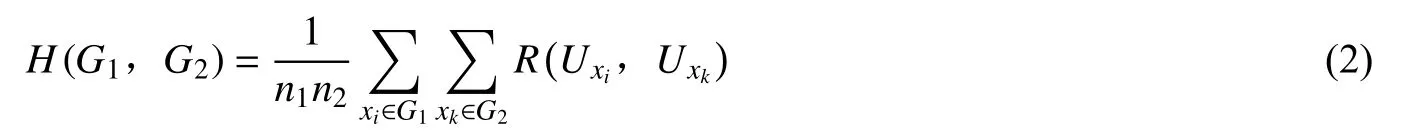
式(2)是在式(1)的基础上,采用衡量两组对象间的平均距离、平均相似度所常用的“类平均法”(或称“簇平均法”,Average Group Linkage)而得到。其中G1或G2都可以有且仅有一个用户,这种情况下也即:式(1)中所计算的个体与个体之间的两两相似度成为式(2)中n1和n2分别都为1时的特例。本研究中,由于用户分层后的层内人数通常不为1个,所以文中被直接应用的还是式(2)。
H(G1,G2)的值越大,表明两组用户之间两两的趋近、类同乃至重复程度越高;若两组用户的异质化内容越大,则平均相似度就会越低,也即H(G1,G2)的值越小。
将全体用户样本按照使用程度的高度分层后,任意一个用户层级Gi的不同的“趋同化”程度,计算方法如下:
1.全局趋同化程度。Gi与全体用户G的平均相似度为
2.趋顶趋同化程度。Gi与顶部层级用户Gmax的平均相似度为

3.近邻趋同化程度。Gi与高一层级的用户Gi+1的、低一层级的用户Gi-1,其相似度的平均值为
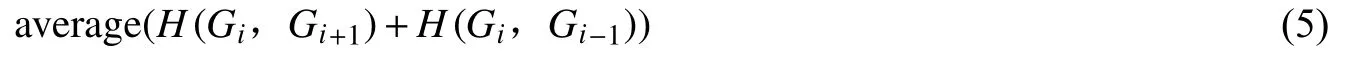
4.层内趋同化程度。Gi内部的本层级用户之间的平均相似度为

(五)可操作化的假设
根据前文提出的问题以及研究设计、整体研究路线,将问题(Q1,Q2,Q3)转换为如下可操作化的假设:
设新浪微博的用户样本集合(N=7 825)为G,G中的每个用户Ui将其全部样帖聚合为一条文本Ti,通过文档-词项矩阵、潜在语义分析(LSA)方法,得到每个用户内容经降维、提取主要信息后的文本特征向量Vi。按照用户对于微博媒介使用度(媒介接触/使用活性/使用效果中的一个子指标)的高低程度,将全体用户G等频划分为m个具有相同或相近使用度的不同用户层级{G1,G2,G3,…,Gm}。并结合式(2)及其推演得到式(3)~式(6),计算各个用户层级与其他用户层级或全体用户的平均相似度,转换后的假设如表3所示。

表3 研究假设及其操作化的表述
将表3 中 H1、H2 的计算过程,在五种使用度子指标下分别计算一遍,即可以分析H1、H2 在这不同使用度指标下是否都成立。
三、实证分析
(一)微博媒介使用度与四种相似度的相关系数分析
将 7 825 个用户,按照其使用度等级的高低不同,将等使用度或相近使用度的用户划分到一个“用户层级”中,等频切分为30层。对假设H1.1、H1.2、H1.3、H1.4分别在5种媒介使用度指标下检验:对每一层的用户,取其使用度的平均值作为该层用户的使用度“质心”,再计算质心和该层用户的趋同化相似度之间的皮尔逊相关系数。例如,计算“微博用户经验值”是否和用户的全局相似度有相关性,是对30层用户每层得到其经验值的均值作为该层质心,得到数组A=[a1,a2,a3,…,a30];30层用户每层同样能计算得到该层和全体用户的“全局相似度”,得到顺序相对应的数组B=[b1,b2,b3,…,b30],然后对A、B求皮尔逊相关系数,结果为0.906(表中第2列第3行)。其他的变量也都依次类推。得到相关系数,如表4所示。
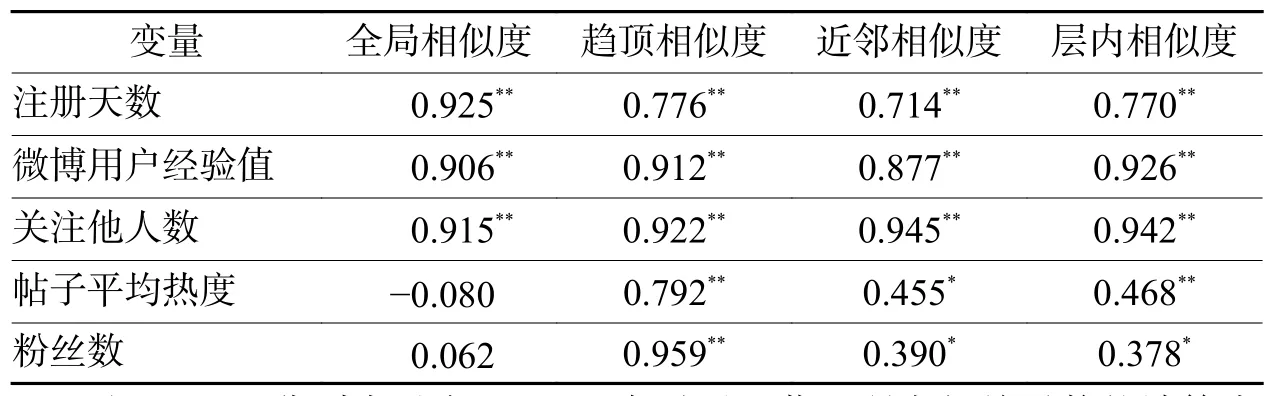
表4 用户的微博使用度和趋同化程度的皮尔逊相关系数表
在新浪微博中注册时长越久、“浸泡”越久的“老”用户,他们和以下4种用户的相似度、趋同度就越高:(1)和全局用户相似;(2)和注册时长最久的最顶一层用户相似;(3)和相邻正负一个层级的用户相似;(4)和具有相同或相近注册时长的本层用户相似。根据皮尔逊相关系数,注册时长指标和全局相似度的正相关系数高达0.925,已经几乎是直线增长。和其他几种相似度的正相关系数也都达到了0.714以上不等。
随着用户使用微博的经验值日益提升,它们是不是也会表现出相应的四种相似度增加呢?皮尔逊相关系数分析显示,用户经验值和4种相似度全部呈正相关,相关系数最低也达到了0.877(层内相似度),其他三种相似度全部高达0.9以上,P值全部都小于0.001。这在社会科学研究中是比较突出的正相关。
新浪微博用户越是主动关注他人、显现出在社交媒体中的互动性和活性,是否就越是表现出更高的“趋同”度呢?结果是肯定的且是非常鲜明的。关注他人数和4种相似度,皮尔逊相关系数全部显著,而且均在0.915以上。
发帖平均热度越高的用户层级,他们的趋顶相似度、近邻相似度、层内相似度就都显著地越高,而全局相似度的增加不明显。
粉丝数越高的用户层,尽管在全局相似度方面的增加不显著,但是在剩下的几个指标中全部显著,甚至和趋顶相似度的皮尔逊相关系数高达0.959。
之所以发帖热度、粉丝数与全局相似度的相关系数不够显著,推测是由于过于“随大流”、与全局用户过于相似的用户,难以得到很高的粉丝量和帖子传播效果。但是即使这两个微观条件下不符合,也必须看到:其一,这两个指标下的其他三种趋同化依然是显著的,部分甚至是很高的相关;其二,至少这两个不显著相关系数未表现为负的相关系数,也即用户不会因为要达到高粉丝量、高帖子传播效果而保持一种“特立独行”的反趋同化。
总体而言,用户的使用度变量(5种)和趋同化程度变量(4种)之间具有正相关性,5×4=20组的相关系数分析中有18组(90%)的皮尔逊相关系数显著,而且这些显著的相关系数平均值达到+0.78,有9组相关系数达到了+0.9以上的高度正相关。
(二)不同的趋同化程度是否具有一致性
根据上文的分析,在根据5种微博使用度指标的切分中,用户在绝大多数情况下,随着微博使用程度的提升而表现出对总体用户、顶部用户、近邻用户和本层级用户的趋同程度增加。相关联的问题是:用户的4种“趋同化”作用,是各自独立、互不相关的;亦或相互制约和掣肘的;还是统一、同步的作用?
为了考察4种不同的“趋同化”路径和方向之间是否具有内部一致性,采用Cronbach’s α 系数进行考察。尽管学术界对于Cronbach’s α 系数能否很好地反映量表的内部一致性还存在一些不同看法,但是该方法在当前仍是普遍使用的简单有效方法之一。Cronbach’s α 值如果达到0.6以上是通常可接受的结果,达到0.8或0.9以上是很理想的值。
在5种分层指标下,分别对用户等频分层为30个“用户层级”,每个层级分别都能计算出4种趋同化的程度,也即能得到30行×4列的数据表。对这4列变量计算Cronbach’s α系数,最终结果如表5所示。
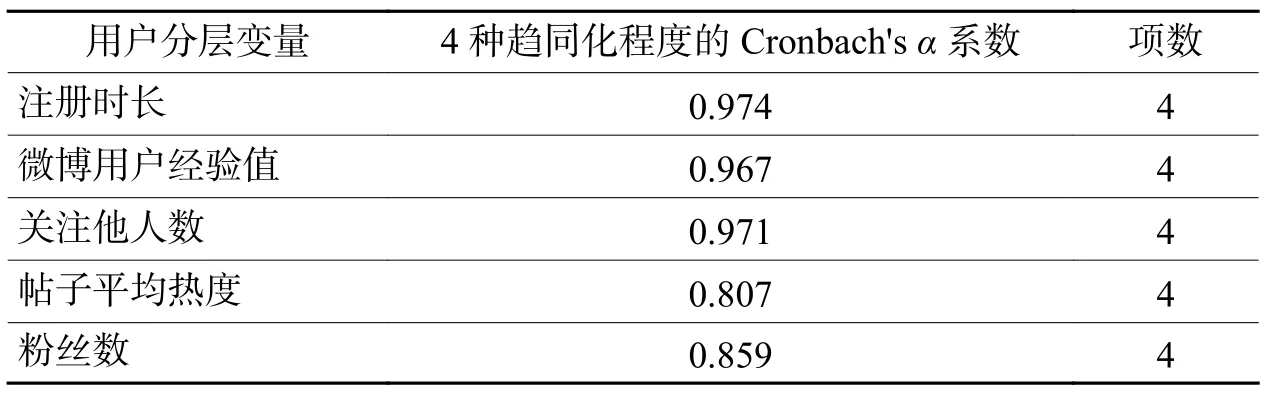
表5 趋同化程度之间的一致性分析
无论按照哪种“使用度”作为依据,不同等级用户所朝向的全局趋同化、顶部趋同化、邻近趋同化、层内趋同化这四种“趋同化”的路径是一致、同步的,不存在“此消彼长”或“互不相干”等情况。5种使用度指标下,即使按照“帖子平均热度”这个最不理想的情况,4种趋同化程度的 Cronbach’sα系数也达到了0.807,而在注册时长、微博经验值、关注他人数这三种指标下,Cronbach’sα系数甚至到0.967乃至0.974的高值。不同的趋同化路径与方向尽管“殊途”,但却显现出“同向”和“同步”。
四、结语
社交媒体的使用本身作为一个直接变量,会不会带来用户在内容生产、表达上的趋同化?又是带来怎样的趋同化?总体来看,假设H1中,除了媒介使用效果的两个指标(帖子平均热度、粉丝量)条件下用户没有表现出显著的“全局趋同化”,在剩下其他的情况下,5种使用度和4种趋同度之间的相关系数全部显著,而且绝大多数相关系数值是0.8乃至0.9以上的高值。用户的内容生产在微博中“越使用、越趋同”的现象,是存在并且是显著的。这种“趋同化”,并非简单地意指个体之间发生内容同质化传递,亦或只是某个群体范围内的“回音室”效应、信息的“选择性接触”。它包括具有统计显著性的路径与方向:和全体用户越来越相似,和最高使用度的“顶部用户”越来越相似,和使用度相近的邻近“社会层级”越来越相似,同使用度“社会层级”内的用户彼此之间越来越相似。
实证数据表明,这几种不同的趋同化,同时都是成立的。在微博中上述4种趋同化路径的基础上,本研究首次明确指出,这4种看似差异很大的趋同化向度,不是“此消彼长”“南辕北辙”等负相关或不相关关系,而是在实证分析中,表现出高度统一的同步性和一致性。与此相关的假设H2得到了很理想的证实和支持。在5种使用度指标下,其 Cronbach’sα系数无一例外都处于高位值,分别在0.807~0.974之间,大大高于通常的0.6以上的可接受阈值范围。4种趋同化程度两两之间相关系数全部显著。这也打消了容易产生的一些疑虑:一种是担心这几种趋同路向可能只是部分成立、甚至可能全部不成立,但是事实显示,用户比预想的更容易消解内容上的“特立独行”色彩,并且“迷失自我个性”的方式丰富而有效;二是认为这些趋同化的方向和标的由于存在着明显差异,所以担心会带来趋同作用效果的割裂和“相冲相克”,但是事实显示看似区别很大的趋同化“殊途”却是同步的。微博系统在用户的媒介使用中,如同一个“媒介工业”或“媒介机器流水线”,生产着符合福柯意义上的话语“规训”的单元体。
当前关于中观、微观的好友信息同质性、网络“回音室”“巴尔干化”、群体意见极化等的研究中,全局相似度问题得到的重视不足。但是它却指向全局意义上的“微博机器”或“社交媒体文化工业”塑造“标准化”、重复化的“人”的可能性以及现实性。阿尔都塞曾提出著名的“意识形态国家机器”(Ideological State Apparatuses,ISAs)[33]320-375的概念,意指传媒、文化等方面对于国家、社会系统的维系和对于“主体性”(subjectivity)的再生产。媒介中或许不仅发生着波兹曼所谓的“童年的消逝”[34]162-301,也可能发生着“成年的消逝”和用户“主体性”的标准化再生产。
趋顶相似度同样也是一个重视不够的维度:在微博中的注意力主要集中在高粉丝量、发文高热度的“头部用户”,例如粉丝过百万、千万或被评论、点赞达“100 000+”的用户。但是除了这些高度吸引聚光灯的“头部用户”,微博中还存在大量虽然未必有高粉丝量、高转发量,但是却具有高使用度、高使用活性的“顶部用户”。实证结果发现,这些“顶部用户”和其他用户的“趋顶相似化”是显著的;五种使用度指标下,趋顶趋同化全部显著,而且平均相关系数达到 0.872 (如表4所示)。趋顶趋同化的显著程度和强度,超过了另外几种趋同化的作用。在此意义下,高粉丝量“头部用户”可视作“顶部用户”在使用效果指标下的特例,顶部用户对微博生态中的用户内容整体面貌和趋同化的影响有待继续思考。微博的高使用度“顶部用户”或许不能直接发生扩散意见、吸引粉丝的效力,但是对于塑造微博中的用户趋同化、消解“独特用户”具有高度重要的作用。在此需要针对理论和现实中重视度不够的状况,强调从“头部用户”到“顶部用户”的理论视域扩展甚至明确的“理论自觉”。
这些趋同化路径的统一性,部分意义上是反经验直观的。例如,趋于全局“芸芸众生”的全局相似度,似乎和趋于精英化的“顶部用户”的相似度本应难以具有高度正相关性,后者看起来更为“阳春白雪”和远离“普罗大众”。又比如,趋于身边“近处”的邻近层级的相似,和趋于“高远处”顶部用户的相似度,似乎本也不应是一个同步的变化过程,它们发生“相似化”的标的是完全不同的。再比如,层级内部的彼此可以变得越来越相似,但是这并不意味着他们同时也和全体用户也变得越来越相似,有时甚至截然相反。然而,实证结果和经验直观并不符合。这留待继续思考,不同的趋同化力量和变化轨迹之间,为何以及如何具有这种高度的一致性?本研究的初步猜想是:用户趋向于顶部用户的趋同化有可能是一个基本作用力,在趋于“顶部典范”的共同标的过程中,不同用户越来越共同朝这个目标前进;尽管前进的程度有强有弱、有远有近,但是共同“范本”的存在使得全局用户增强“全局相似度”;而相同或相近使用度层级的用户由于前进的程度相近,所以带来“近邻相似度”和“层内相似度”增强。但这些推测,有待继续分析。
