考虑批次的可追溯食品冷链中污染源定位与追踪
2021-11-05曾小青李静茹
曾小青 李静茹 李 澈
(长沙理工大学 经济与管理学院,长沙 410114)
冷链物流业是推进流通体系建设,衔接乡村振兴,保障食品安全,促进消费升级的基础性、战略性产业[1]。近年来,我国冷链物流业得到了快速发展,特别是抗疫期间在保障食品供应上发挥了重要作用,同时也暴露了食品冷链受到污染时溯源困难的短板。作好食品冷链追溯管理,是监测风险、保障食品安全的重要举措。污染源定位不仅是产地溯源,还是风险溯源,即当出现食品安全问题时,不仅要确定食品的上游提供商,还需快速定位生产、加工或流通中出现污染的环节[2]。食品冷链的复杂性和全球化使得食源性疾病成为世界各国普遍关注的公共卫生问题。当前,我国国家级冷链食品追溯系统已初步建成,记载了冷链食品的上下游信息。但由于食品冷链的链条长、节点多,交叉融合,结构复杂,准确判断问题食品的污染环节和传播途径,仍存在理论和现实上的困难[3]。多数食品安全事件的爆发,起初只是上游小部分污染,但随后风险通过食品冷链急剧扩散,范围不断扩大,影响不断加剧。
由于食品供应网络的复杂性、动态性以及数据缺乏,食源性疾病的污染源头识别是一个挑战性课题。美国CDC(Centers for disease control and prevention,疾病控制和预防中心)数据表明,食源性疾病中只有37%可追溯到致病源,而能准确定位到污染位置的不足15%[4]。实际上,大多数污染源从未被确定[5]。目前主要用调查方法来解决污染源定位问题。监测部门根据食品配送路径,确定供应网络中是否存在融合点,例如生产、加工、仓储或配送的共同日期及地点[6]。由于资源的限制,可作为污染源定位的数据较少,并且往往是污染已通过网络进行了传播或爆发后才着手调查,效果大打折扣。随着世界各国食品安全追溯系统建设的不断推进,这种状态正在改变,更快速、更准确地定位食品冷链中的污染源头已成为可能。
食品冷链是连接冷链参与者的复杂信息网络,通过考虑网络结构及其包含的信息维度,再结合疾病报告,可以更好地识别网络中的污染源[7]。理论上,食品冷链的污染源定位问题属于网络中的风险源识别问题,从传染病到通过互联网传播的计算机病毒,从供水网络的污染水源到通过社交网络的舆情传播,相关文献比较丰富,但很多基于网络结构的分析处理框架[8-9]过于简化,缺乏现实网络和问题背景的许多特征,很多假设不适用于食品冷链的溯源。
当前,污染源定位方法主要分为:1)时间类方法,利用食源性疾病的报告时间及次数信息;2)非时间类方法,利用已检测到污染节点的位置信息。时间类方法包括基于动态消息传递[9]和贝叶斯信念传播[10]的离散时间传染病模型,如SIS(Susceptible-Infected-Susceptible,易感-感染-易感)模型、SIR(Susceptible-Infected-Recovered,易感-感染-恢复)模型[11],以及连续时间高斯传播方法[12]。虽然连续时间传播模型是对现实世界的较好近似,但这种方法是为树形结构而设计的[13];非时间方法涉及对网络节点有效距离的测量。有效距离是从源节点到检测出风险的节点之间,距离最短、概率最高的那条路径的长度[14-15]。这类方法已应用于EHEC(EnterohemorrhagicE.coli,肠出血性大肠杆菌)的源定位,但其识别结果不稳定[15]。此外,由于食品冷链的风险传播并不完全等同于疾病传播,在食品冷链中,不同批次食品在不同环节之间隔离性更好,如果借助于食品追溯体系去定位污染源头,则识别效率和精度均可提高。
鉴此,本研究拟采用一种考虑批次的污染源定位方法,对食品冷链中污染源定位与追踪问题进行研究,并构建食品冷链回溯与追踪系统,以期为识别污染源头,追踪风险传播和保障冷链食品安全,提供理论及系统构建方法指导。
1 食品冷链污染传播特征
食品冷链中污染传播与流行病传播[16-17]、计算机病毒传播[18-19]、舆情传播[20]、水污染传播[21]等网络传播行为有较大区别。食品冷链是由食品生产、加工、流通、仓储和消费多个环节的实体组成的复杂动态网络。食品在网络中的流动通常被描述为产品向下游传递时,连接起始节点和销售终端节点的全部路径(有向边)的集合,食品冷链的污染传播表现出以下特征:
1)污染传播的可隔离性。食品冷链污染传播与复杂网络流行病传播的动力学有一定相似性。许多基于网络的源识别方法通常是流行病学模型的变体,如广泛使用的流行病传播SIS模型和SIR模型。然而,通过食品冷链产生的污染传播并不完全等同于流行病传播过程。受到污染的食品通过供应网络传播时,不一定会扩散到其他食物中,也不会在感染性方面显著衰减[22-23]。这种不广泛扩散性是由许多因素造成的,如包装物品之间不充分接触,未包装食品之间缺乏相互作用,以及污染物扩散的生物不敏感性。不显著衰减是由于食品的保质期不同于病源体衰变期。食品致病源污染过程主要通过受污染的食品扩散而不是通过环境传播。此外,可追溯系统记录了食品冷链中大量有用信息,忽略追溯信息而直接应用流行病学的传播模型将降低食品冷链污染溯源的精准性。
2)观察样本的稀疏性。虽然食品中的污染会在冷链多个节点之间传递,但通常仅在购买受污染食品的最末节点出现疾病报告时才会被发现。除非进行进一步调查,否则参与食品生产、加工或储存的节点即使更接近污染源,仍不易被观测到。因此假设食品冷链中所有节点的污染状态都已知是不现实的。
3)传播路径的多样性。在食品冷链中任何可能的风险来源和观测之间,存在多条路径。这是由于食品生产、加工、批发和零售位置分散,食品将通过多个批发商或零售商传递至消费者手中。某些污染源识别方法假设过于简化,即污染物只在污染源和观测节点之间的单个最高概率路径上传播。这些方法对食品冷链风险溯源并不适用。
4)传播时间的不确定性。理论上,可应用结合疾病报告和污染传播所需时间的模型来检测污染源。但食品在供应网络上的传递存在时间延误,污染传播过程存在明显的时间不确定性。污染物在食品冷链上各个节点(例如仓库)以及在消费端的停留时间变化很大。
2 食品冷链中的污染源定位理论模型
2.1 污染源定位的问题描述
污染源定位是指识别导致食源性疾病暴发的食品冷链中污染的源头节点。食品供应网络可定义为有向图G={V,E},其中V是节点集,表示食品冷链参与者。V由2种类型的节点组成:一组吸收节点VR和一组瞬态节点VQ,使得V={VQ,VR}。吸收节点代表食品销售后离开冷链网络的节点,食品此后不会重新进入冷链(例如零售商或餐馆)。所有其他节点都是瞬态的,表示生产、加工和存储食品的节点。E是形如(i,j)∈VQ×VQ∪VQ×VR的边的集合,表示从节点i到节点j的业务关系。每条边(i,j)都可赋予权重wij,以体现从节点i到节点j在特定时间段内的食品供应量。
将受污染食品在冷链网络上的传播过程描述为离散马尔科夫链,即网络上的随机游走,其中传输概率对应于网络边的权重。这是加权有向网络上非传染性扩散的自然传播模型,为了估计真实的源位置,采用最大似然ML(Maximum Likelihood)方法,选择最有可能导致检测到疾病报告的节点为污染源。
首先,假设在一个未知的源节点s*产生一定初始数量的受污染食品。令s*为具有预定义先验概率分布P(s*=s)的节点随机变量,节点s∈VQ。当污染食品离开节点s*时,开始污染扩散过程。
离散时间马尔科夫过程决定受污染食品的移动,即通过供应网络的加权随机游走。在第n步的转移中获得的状态序列Xn由马尔科夫转移概率确定,P(xn+1=j|xn=i)=pij,由pij构成矩阵P,表示在网络G上发生污染过程的随机马尔科夫转移矩阵。若节点i为吸收节点,有i∈VR,其自转移概率定义为pii=1。根据供应网络结构,可以将P视为一种以吸收节点为终点的有序组合。连接瞬态节点和吸收节点的转移矩阵如下所示:
(1)
式中:PQ为|VQ|×|VQ|瞬态节点间的转移子矩阵;PR为|VQ|×|VR|瞬态节点与吸收节点间的转移子矩阵;IR为|VR|×|VR|吸收节点的转移子矩阵。
从s*开始,污染食品通过供应网络的扩散过程完全由马尔科夫传输矩阵P确定。达到吸收节点o∈VR时扩散过程结束,生成一个连接源节点s*和吸收节点o的有向边集合的网络路径(γs*,O)。在吸收节点o处污染食品被消费并离开食品供应网络。假设食用污染食品的人中间有K个疾病报告,将连接到第k个疾病报告的吸收节点标识为ok,得到与这K个疾病报告相连接的吸收节点的集合Θ=(o1,o2,…,ok,…,oK),集合Θ中的元素可能相同,因为某个吸收节点可能会出现多个疾病报告(比如某个零售店导致多名消费者患病),将集合Θ中的元素去重以后得到的集合记为O,有o∈O⊆VR使得|O|≤K(即O中吸收节点个数不多于疾病报告病例数)。传输模型的最后一步将随机过程与网络模型中定义的传输数量联系起来。从节点i发送到节点j的食品数量占比可以反映污染沿该方向传递的条件概率。因此,将转移概率pij定义为从节点i传送到节点j的食品数量占由节点i发出的全部食品数量之比例:
(2)
2.2 基于贝叶斯推断的污染源定位模型
2.2.1模型构建
污染源定位的目标是基于与疾病报告相连接的吸收节点集合Θ找出最“可能”是污染源的节点s*∈VQ。给定集合Θ及真实污染源节点s*的先验分布,引入贝叶斯公式表示节点s是真实污染源s*的概率,如下:
(3)
(4)
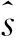
导致在Θ中吸收节点位置检测到疾病报告的污染源位于s的概率,取决于G上通过节点s到所有出现疾病报告的吸收节点ok∈Θ的路径。但是,从s到每个疾病报告节点ok∈Θ可能的路径γs,ok有多条,污染源是节点s的概率等于每条可能路径排列组合的总概率。引入如下定义计算包括所有路径组合的污染源可能性:
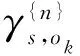
πs为从某污染源s到全部K个疾病报告的每个节点ok∈Θ的某一特定排列,是在路径组{Γs,ok}ok∈Θ上元素的笛卡尔积,即(γs,o1,…,γs,oK)∈Γs,o1×…×Γs,oK。
Πs为从s到每个ok∈Θ路径的全部排列,即:
Πs=Γs,o1×…×Γs,oK=
{(γs,o1,…,γs,oK)∶γs,ok∈Γs,ok}
(5)
根据上述定义,污染源可能性为全部排列的总概率:
P(Θ|s*=s)=∑πs∈ΠsP(πs|s)
(6)
要用式(6)求出所有πs∈Πs的总概率,先要计算单个πs的概率P(πs|s)。对于路径γs,ok∈πs,可以根据该路径上每条边的相邻节点对(i,j)∈γs,ok的转移概率pij,将P(πs|s)展开为:
P(πs|s)=P(γs,o1,…,γs,oK|s)=
∏γs,ok∈πsP(γs,ok|s)=∏γs,ok∈πs∏(i,j)∈γs,okpij
(7)
则似然概率可以写成:
P(Θ|s*=s)=∑πs∈ΠS∏γs,ok∈πs∏(i,j)∈γs,okpij
(8)
2.2.2模型求解的霍恩矩阵法
求解污染源定位贝叶斯模型的难点是求P(Θ|s*=s)的最大似然概率。污染源位于s的概率取决于通过节点s到所有出现疾病报告的吸收节点ok∈Θ的路径。对于大多数食品供应网络而言,即使疾病报告很少,也会出现组合爆炸。对此,阿比盖.霍恩(Abigail L. Horn)[7]指出源节点s是真实源s*的概率可表示为:
P(Θ|s*=s)=∏ok∈Θ[(I-PQ)-1PR]s,ok
(9)
并在似然概率的计算中引入近似表达式A,使得:
(10)
式中,n为Ω⊆VQ中节点之间的状态转移步数。表达式A最后消去了n,只需进行简单矩阵运算,即可从所有可能污染源s∈Ω中定位源节点s,使得后验概率最大。
(11)
为说明用上述方法进行污染源定位时似然概率的计算过程,设有如图1(a)所示的简单食品冷链网络,该网络由5个食品冷链参与者节点构成。其中,节点1和2是食品生产节点,节点3是批发节点,节点4和5是零售节点,食品从节点4、5销售以后离开食品冷链。因此,节点4、5是吸收节点,其他节点则是瞬态节点。
假设零售节点4、5均有食源性病例报告,则图1(b)列示了节点1为污染源时,导致节点4、5有疾病报告的污染传播路径;图1(c)表示节点2为污染源时的污染传播路径;图1(d)表示节点3为污染源时的污染传播路径。
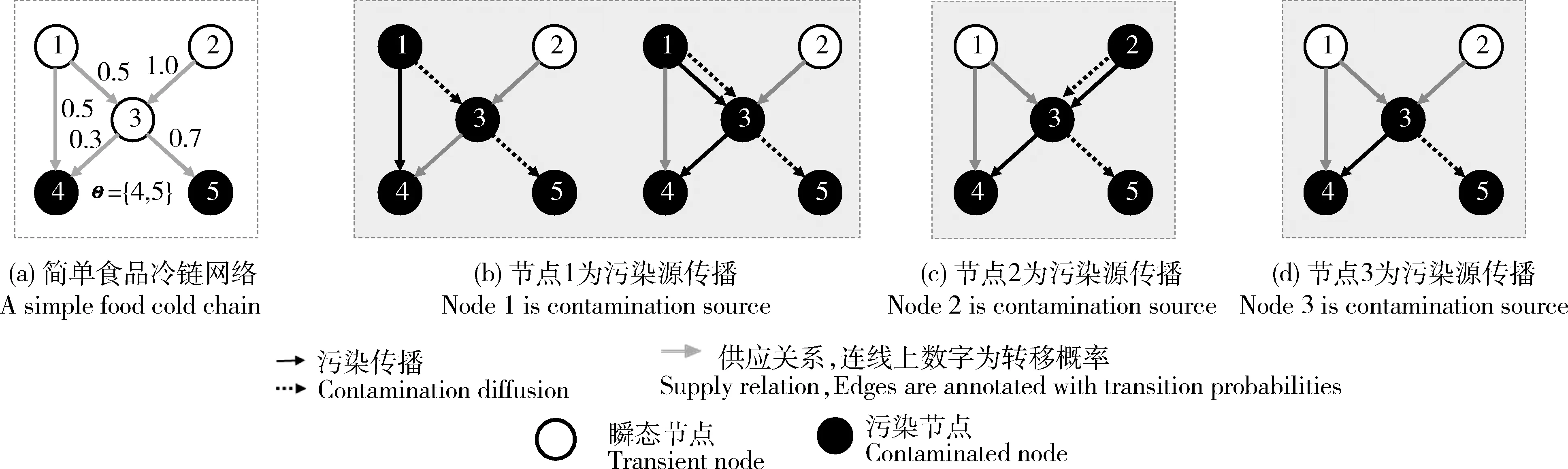
节点内数字1、2为生产节点,3为批发节点,4和5为零售节点。1 and 2 are producer nodes, 3 is wholesater node, 4 and 5 are retailer nodes.图1 食品冷链上的污染传播Fig.1 Contamination diffusion in food cold chain
根据霍恩方法,有:
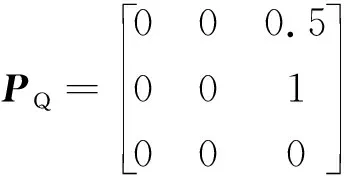
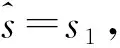
3 考虑批次的可追溯食品冷链污染源定位模型
尽管霍恩矩阵法简化了基于贝叶斯推断的污染源定位模型的求解,但如果仅以食品冷链节点为粒度,数据处理量还是过大,污染源定位还是过于复杂。比如某食品批发市场每天要销售大量食品,其上游节点也很多,如果只在某些食品批次中发现了污染,就对所有的食品类型和上游节点都进行计算排查,不仅困难,也无必要。
如前所述,可追溯系统记录了食品冷链中大量有用信息,将食品冷链上下游节点、交易数量以及包括食品类型、处理时间等在内的批次信息考虑进来,不仅可以降低食品冷链污染溯源的复杂性,还可提高污染源定位的精准性。
3.1 节点风险值度量
定义关于食品冷链网络有向图的三元组G={V,B,E},V={v1,v2,…,vi,…}为节点集合,B={bi1,bi2,…,bil,…|vi∈V}为批次的集合,E={(bik,bjl)|vi,vj∈V}为有向边的集合,表示对于节点vj的食品批次bjl,需要用到节点vi批次bik的食品,正是通过食品批次信息把上下游关联在一起,由此形成了一个复杂的食品冷链网络结构。
假设对于冷链中某食品节点Si∈V,有n个食品批次Bjk(k=1,2,…,n)供应到节点Tj∈V,定义Fk(i,j)→{0,1},若存在从节点Si到Tj跟批次Bjk相关的路径P(Si,Tj),则Fk(i,j)取值为1,否则为0。可以通过为污染批次途经的各节点分配权重(优先级)来度量风险评分值,用R(Si)表示。定义为:
(12)
式中,wjk为由食品冷链对于食品批次Bjk、路径P(Si,Tj)上第j个节点的权重。可以给不同的污染程度设置不同的权重。比如,令wjk的取值等于节点Tj批次Bjk的全部销售量中,有疾病报告的消费者食品购买数量占批次Bjk的全部销售数量之比。wjk越高,节点Tj污染越严重。出于简化及谨慎性考虑,可以令有疾病报告的食品批次Bjk对应的节点Tj的权重wjk为1,无疾病报告的食品节点权重为0。包含批次信息的食品冷链追溯系统一旦构建起来,各节点的风险值根据上式可全部计算出来。对于任意节点Si,有R(Si)∈[0,1]。
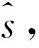
(13)
图2示出包含批次信息的食品冷链。生产食品批次6需要用到上游的批次2和批次5,生产食品批次4需要用到上游的批次3。零售节点4、5均有食源性病例报告,且可对应到具体食品批次。
假如节点4的批次1以及节点5的批次6的消费者有疾病报告,批次4的消费者没有疾病报告。可以看出,对于污染批次1,节点1、4都可能是染污源;对于污染批次6,则节点1、2、3、5都可能是污染源。因此,该情形下,每个节点都可能是污染源。
由于节点4的批次1及节点5的批次6有疾病报告,故有w41=1,w56=1,其余wjk=0;对于污染批次1,有F1(1,4)=1,F1(4,4)=1;对于污染批次6,有F2(1,3)=1,F5(2,3)=1,F6(3,5)=1,F6(1,5)=1,F6(2,5)=1,F6(5,5)=1,其余为0。因此,R(S1)=(w41F1(1,4)+w56F6(1,5))/(w41+w56)=(1×1+1×1)/(1+1)=1.00,同理可求得R(S2)=w56F6(2,5)/(w41+w56)=0.50,R(S3)=w56F6(3,5)/(w41+w56)=0.50,R(S4)=w41F1(4,4)/(w41+w56)=0.50,R(S5)=w56F6(5,5)/(w41+w56)=0.50。由于R(S1)=1.00,其余节点风险评分值均为0.50,因而节点1为污染源的可能性最大。

其他节点符号说明与图1相同。Other nodes symbols and annotations are the same as in Fig.1.图2 包括批次信息的食品冷链Fig.2 A food cold chain of containing batch information
对于食品零售节点4、5出现疾病报告的其他可能污染批次情况,用同样方法计算各节点的风险评分值,由此确定最可能污染源,结果见表1。
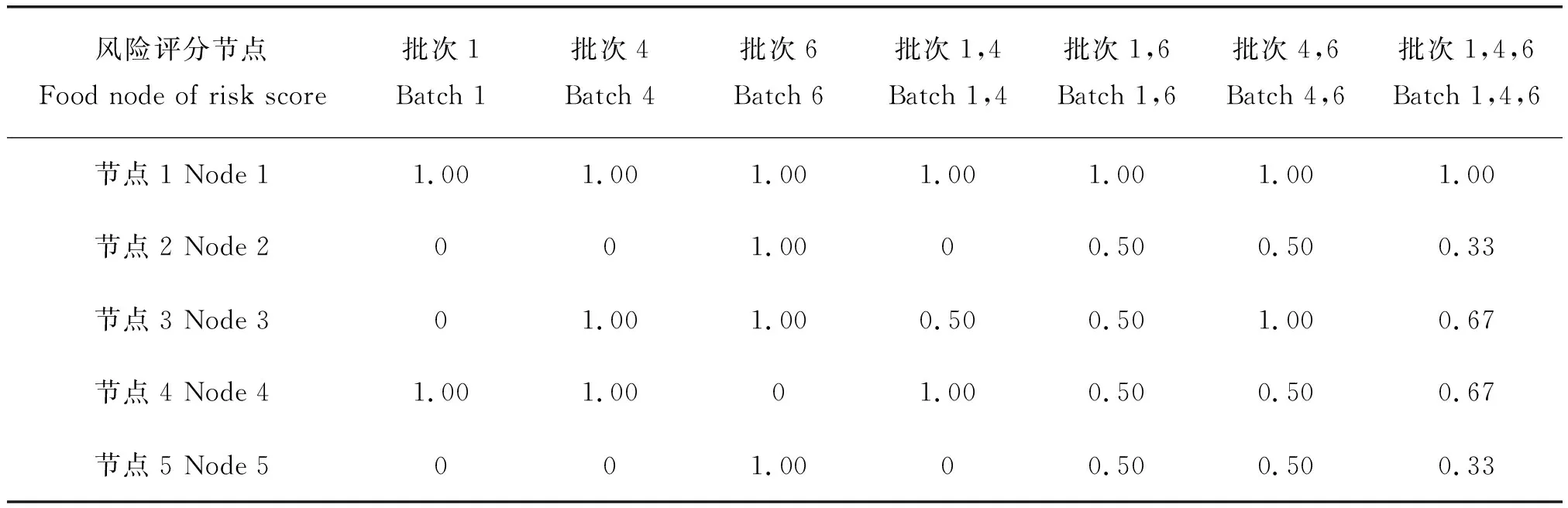
表1 食品零售节点4、5不同污染批次下各节点风险评分Table 1 The risk score in the case of retailer node 4 and node 5 contain different contamination batches
若零售节点1出现的疾病报告对应于食品批次1,此时批次1为污染批次,食品节点风险评分R(S1)=1.00、R(S4)=1.00取最大值,故节点1、4为最可能污染源;同理,若疾病报告对应污染批次1,4,6,则节点1的R(S1)最大,故节点1为最可能污染源,其他情形类似,由此实现了污染源定位。
3.2 交叉污染环境下节点风险值度量
在3.1节中,风险值度量方法假设所有批次之间相互隔离良好,即非相关食品不同批次之间不相互污染。这是一个强假设,可以极大简化计算路径的工作量,但在某些食品冷链管理水平低下、食品安全控制不严格的食品生产节点,如果某批次出现了污染,则该节点的后续所有批次食品都可能受到污染,即产品之间可能发生交叉污染。
交叉污染环境下风险值度量依然可以使用式(12)进行计算,但wjk和Fk(i,j)的取值会有所变化。图3 示出一个交叉污染环境下包括批次信息的食品冷链。由于节点3发生了交叉污染,所以批次4、批次6都可能受到污染。因此,w41=1,w44=1,w56=1,其余wjk=0,F1(1,4)=1,F1(4,4)=1,F2(1,3),F4(1,4)=1,F4(2,4)=1,F4(3,4)=1,F4(4,4)=1,F5(2,3)=1,F6(3,5)=1,F6(1,5)=1,F6(2,5)=1,F6(5,5)=1,其余为0,代入式(12)可得R(S1)=(w41F1(1,4)+w44F4(1,4)+w56F6(1,5))/(w41+w44+w56)=1。同理可算得R(S2)=0.67,R(S3)=0.67,R(S4)=0.67,R(S5)=0.33。由于R(S1)=1,风险评分值最大,故节点1仍为最可能污染源,模型的解准确性和稳定性较好。
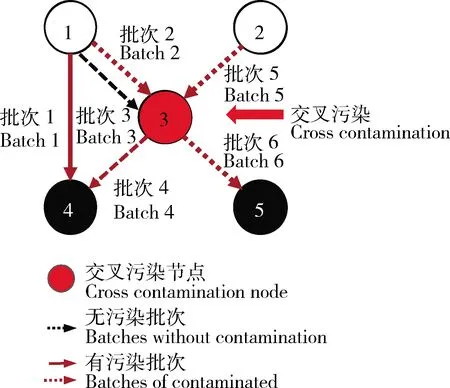
其他节点符号说明与图1相同.Other nodes symbols and annotations are the same as in Fig.1图3 交叉污染环境下包括批次信息的食品冷链Fig.3 A food cold chain of containing batch information under cross contamination environment
4 考虑批次的可追溯食品冷链回溯与追踪系统
基于上述理论模型,为对食品冷链的后向回溯和前向追踪进行直观交互与结果展现,构建考虑批次的可追溯食品冷链回溯与追踪系统。当食品冷链中的某些节点出现疾病报告或疑似污染时,可以根据污染源定位算法,将污染节点传播路径标识出来。
4.1 数据关系模型
在设计数据关系之前,先界定以下概念:
1)工作站: 代表冷链中发送或接收食品的节点,例如,生产或销售食品的公司或食品消费者。
2)路径: 是一条沿着冷链的路径,污染食品在食品冷链上流动,可能包括混合和拆分事件。
3)疾病报告: 是引起暴发的病原体出现的一个或多个地方。例如某个地区、一定时间内、若干名出现相同患病症状的食品消费者。
食品安全追溯系统包含4类实体的相关信息:企业成员、产品、配送及批次信息。这4类实体的关系如下图如所示,这种设计能够存储长度不定、任意复杂的冷链的信息,此外,食品可以通过不同数量的中间步骤“生产”,并允许食品链中的一批食品由几个中间成员处理。可追溯食品冷链数据关系模型和数据流分别如图4、图5所示。

图4 可追溯食品冷链数据关系模型Fig.4 Data relation model of traceable food cold chain

图5 可追溯食品冷链的数据流Fig.5 Data flow of traceable food cold chain
结合BfR(德国联邦风险评估研究所)提供的来自欧盟RASFF(Rapid Alert System for Food and Feed,食品和饲料快速预警系统)的公开数据集[24],对食品安全回溯和追踪分析方法和过程进行说明。示例数据集包括了牛肉、鸡肉、猪肉、鱼、比萨和奶酪6种食品、252个冷链成员的548次交易的交易。部分食品工作站信息见表2,食品冷链上下游配送信息见表3。

表2 食品工作站基本信息Table 2 Basic information of food stations

表3 每次食品供应上下游基本信息Table 3 Up and down stream basic information of each food supply
食品安全回溯与追踪系统对收集到的食品冷链数据进行分析并将其可视化。图6是RASFF数据集的图形化展示,如果选中了某一可疑节点,系统将用不同颜色显示连接到此节点的所有上游和下游节点及路径。图中食品工作站节点用圆圈表示,节点之间通过食品配送建立起来的联系用带箭头的连线表示,不同颜色的节点和连线具有特定的含义。其中:红色节点表明该节点的消费者中有病例报告;绿色是当前正在分析的观测节点;橙色表示从当前观测节点向下游追踪路径上的节点和连线;粉色表示观测节点向上游回溯路径上的节点和连线;黑色节点表明在该处存在交叉感染;黄色表示起始节点;蓝色表示终端吸收节点。若节点同时属于上述几种状态,则该节点用不同状态颜色的复合色来表示。若选中某观测节点,系统会将该节点的所有上游节点和路径用紫色显示,而所有的下游节点和路径则显示为橙黄色。这样,就从一个复杂的食品供应网络中,将与该节点相关的冷链区别标示出来。
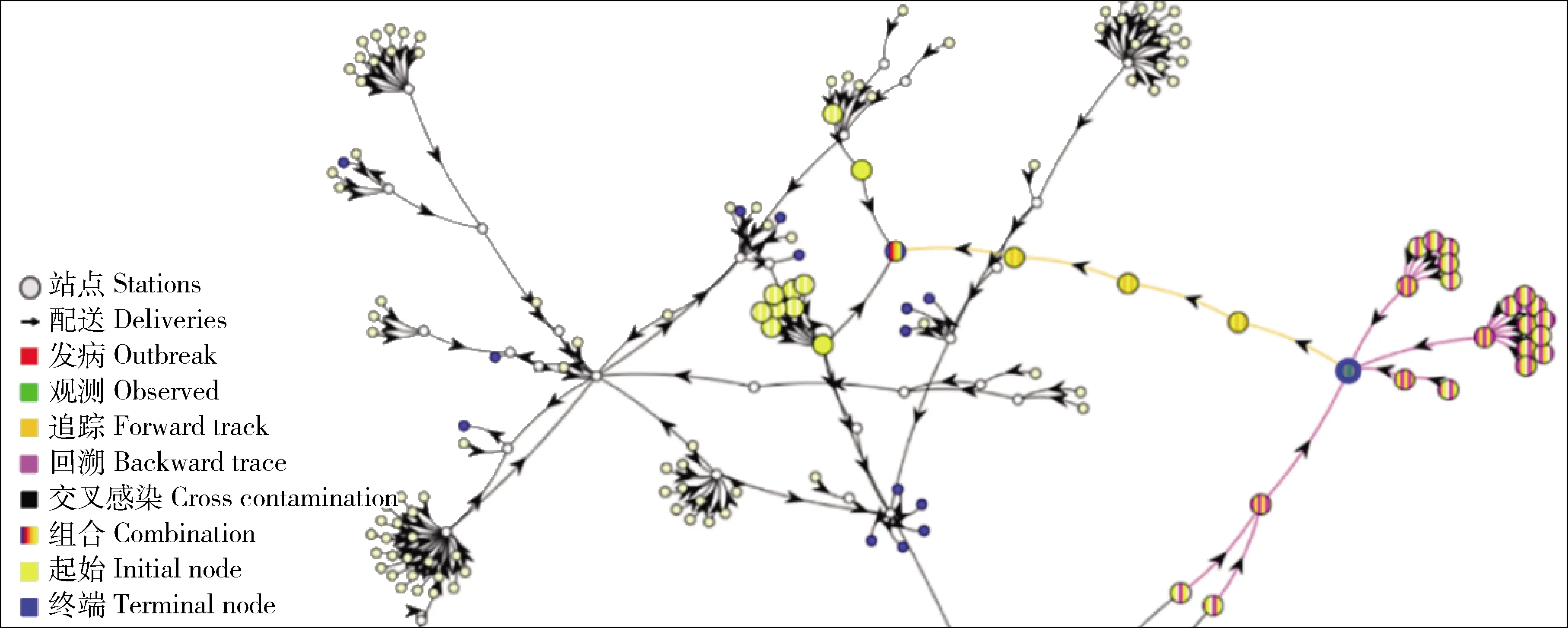
图6 食品工作站节点的上、下游的可视化展现Fig.6 Visualization of the up and down stream nodes of a food station in a supply chain
4.2 回溯与追踪
为清晰展示某些节点发生食源性疾病时,通过回溯分析定位可能的污染源,并突出显示污染的传播路径,选取食品工作站Station 360和Station 251两个终端消费节点出发,对食品安全回溯和污染源定位进行阐述。
由表2和表3可知,Station 360是一家位于德国Bremen市的大型超市,它有2个上游节点:Station 256和Station 336。其中Station 256是位于瑞士Basel市的一家鱼肉供应商,而Station 336则是位于瑞士Winterthur市的一家渔场,根据表3的数据可以看出,Station 336分别于2012-07-23和2013-01-09给Station 256供应了两次鱼(肉),Station 256于2013-08-04向Station 360供应了1次鱼肉。将上述数据及供应关系通过图7进行描述,食品工作站Station 360的上游供应链Station 336→Station 256→Station 360用紫色表示出来。

图7 食品工作站Station 360的上游供应链Fig.7 The up stream supply chain of food station 360
另一个终端消费节点Station 251是一家位于德国Heidelberg市的大型超市,它有5个上游节点:Station 250、Station 380、Station 381和Station 256、Station 336,构成了一条比萨(Pizza)的供应链,在Station 250处有个分支,分别是猪肉和鱼肉供应的2条子链。Station 250是位于德国Erfurt市的一家供应商,而Station 380则是位于匈牙利Szeged市的一家猪肉供商,Station 381则是位于匈牙利Pécs市的一家生猪肉供商,Station 256及其上游在前面已经作了描述。根据表3的数据可以看出,Station 381向Station 380供应了1次生猪肉,Station 380于2013-06-09向Station 250供应了1次猪肉,Station 256于2013-05-17向Station 250供应了1次鱼肉,Station 250向Station 251供应了1次比萨(Pizza)。食品工作站Station 251的上游供应链为Station 336→Station 256→Station 250、Station 381→Station 380→Station 250→Station 251。图8示出食品工作站Station 251的上游供应链。
比较图7和图8发现,节点Station 251和Station 360上游食品冷链在Station 336→Station 256这一部分是重合的。如果Station 360检测到污染,可能是由Station 336→Station 256引起的,跟Station 381→Station 380→Station 250无关。如果Station 251检测到污染,则Station 336→Station 256、Station 381→Station 380→Station 250均有可能是污染源;相应地,如果Station 360和Station 251同时检测到污染,Station 336、Station 256是污染源的概率要更大一些。
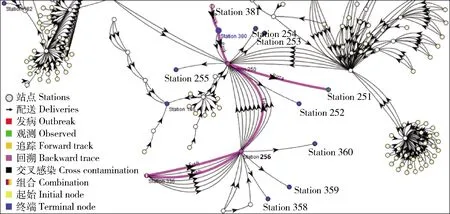
图8 食品工作站Station 251的上游供应链Fig.8 The up stream supply chain of food station 251
根据式(12)可以计算出各个食品工作站的风险得分R(Si)。当Station 360和Station 251同时检测受到污染时,各工作站为污染源的风险得分见表4。

表4 食品工作站定位为污染源的风险得分Table 4 The risk score of food stations of possible contamination sources
Station 256和Station 336的风险得分是1,其他节点都是0.5,可见Station 256和Station 336最有可能是造成Station 251和Station 360污染的污染源。为了更直观地展现风险高低,可根据节点得分高低来调整节点大小,亦即在疫情调查中,较大的节点比较小的节点更可能跟污染有关。图9清晰标示了污染源及其传播路径。

图9 根据风险得分进行污染源定位Fig.9 Contamination sources locating based on risk score
为进一步刻画跨区域或跨国之间的食品冷链中,污染源的定位和安全风险的传递,还可将各食品工作站的地理位置信息(经度、纬度)与供应网络信息结合起来,以地图方式更直观地揭示该数据集所反映的食品冷链在欧盟的分布及风险传播情况。
5 结 论
食品冷链物流是保障食品安全与质量的有效手段,作好食品冷链追溯管理,实现源头可追溯,去向可追踪,责任可追究,是保障食品安全有效供给的重要举措。
本研究探讨了污染源定位的理论模型,提出了一种计算上更为高效的方法,基于食品供应节点和配送的批次信息来计算风险值,并推导沿着所有可能路径的污染源到每个检测出风险的节点之间的总概率,进而实现食品冷链中的污染源定位。此外,构建了可追溯食品冷链回溯与追踪系统,该系统集成了数据管理,提供丰富的可视化交互方式,支持食品冷链风险的回溯和追踪。
主要研究结论如下:
1)食品冷链的污染传播具有可隔离性、观察样本稀疏性、路径多样性和时间不确定性等诸多特征,使其污染源定位方法有别于传统风险源识别与传播方法。
2)食品冷链的污染源识别与定位是一个挑战性课题,考虑批次的可追溯食品冷链污染源定位模型,不仅降低了食品冷链污染溯源的复杂性,而且提高了污染源定位的精准性。
3)可追溯食品冷链回溯与追踪系统,可以在食品冷链中出现污染时,根据污染源定位算法,直观地将污染源节点标识出来,并显示污染节点引发的风险传播范围。
鉴于国内涵盖生产、加工、配送、销售多环节全链条的数据获取较难,同时为增强研究的可比性,本研究采用由德国BfR提供的RASFF食品冷链公开数据,展示了可追溯食品冷链链中污染源定位、追踪分析的过程与结果。建议我国应加快推进食品安全追溯系统建设,充分利用冷链食品批次信息,提升污染源定位与追踪能力,以实现从源头上消除污染,快速阻断风险传播,切实保障冷链食品安全。
