分布式机器学习中的通信机制研究综述
2021-11-05杜海舟
杜海舟, 黄 晟
(上海电力大学 计算机科学与技术学院, 上海 200090)
神经网络学习作为机器学习的核心技术,经历了浅层阶段和深层阶段2个发展阶段。2006年HINTON G E等人[1]解决了深度网络的理论问题后,神经网络得到了前所未有的发展,并广泛应用于各行各业,如自动驾驶、人脸识别、语音识别[2]、文本理解[3-4]和图像分类[5-6]等领域。随着网络规模扩大和大数据[7-8]的兴起,用于训练神经网络的数据也越来越大,传统的单机训练难以应对这些挑战。如Google提出的语言模型Bert[9]包含3亿参数,ImageNet 数据集包含2万个类别共有1 500万张图片[10]。巨量的数据使得传统单机无法应对,故而许多研究者将目光转向分布式训练。但是,传统的分布式计算不能很好地适应深度学习的特性,因为传统的分布式计算侧重如何扩大 I/O,且由于任务迭代次数较少,所以对每次迭代之间的通信没有做太多的优化[11]。深度学习的迭代次数通常都是上万次,需要非常频繁的网络通信来同步参数,因此结合深度神经网络的算法特点设计分布式系统显得十分迫切。本文对目前主流的分布式机器学习中的通信机制进行了详细的综述,以期帮助研究者快速了解分布式机器学习中独特的通信机制,改进现在的解快方法。
1 分布式机器学习的优化
目前国内外涌现了大量针对分布式机器学习优化的研究工作,主要有以下两类。
一是针对优化算法本身的扩展。此类研究主要将深度学习中优化算法并行化,如将标准的梯度下降扩展为分布式梯度下降。文献[12]首次提出同步的分布式随机梯度下降算法。针对该方法中同步的网络开销比较大,MENG Q等人[13]提出基于异步的分布式随机梯度下降算法。在分布式环境中,为了充分利用每台机器,通常会增大训练的Batch Size,但是过大的Batch Size使得网络训练不稳定甚至不收敛。针对此问题,YOU Y等人[14-15]提出LARS(Layer-wise Adaptive Rate training)和LAMB(Layer-wise Adaptive Moments optimizer for Batch training),通过自适应的调节学习率来平稳训练,成功将 Bert 的训练时间缩短至76 min。
二是针对深度神经网络的特性进行系统层面的优化。目前主要从以下2个层面进行。
(1) 参数同步步调 该层面决定何时同步参数,需要保证既能及时地获取最新的参数又能保证整体模型的收敛性。目前主流的同步模型有整体同步并行(Bulk Synchronous Parallel,BSP),异步并行(Asynchronous Parallel,AP)和延时同步并行(Stale Synchronous Parallel,SSP)[16]。
(2) 参数同步架构 该层面决定如何同步参数。目前主流的架构有参数服务器(Parameter Server)[17-19]、Ring-Allreduce及数据流模式[20]和流水线模式[21-22]。
2 参数同步的步调
在分布式环境中各个节点既需要单独计算梯度,又需要与环境中其他节点相互协调合作,何时与其他节点相互通信是关键问题。
2.1 整体同步并行
BSP是严格同步的,即所有的机器都完成任务后才可以进入下次迭代,参数的读写和更新同步障完成,从而保证算法的正确执行。
但是,由于集群中的每台机器在实际运行时性能有波动,且算法对每台机器的工作负载也有差别,使得每个线程的进度不一样。严格的并行需要进度快的线程等待进度慢的线程,从而浪费了时间。此外,因为网络带宽的限制,所有参数在同步障上更新时也会花费更多的时间。总之,BSP 虽然保证了算法的正确性,但浪费了宝贵的计算资源。
2.2 异步并行
在AP模式下,各个机器之间异步执行,既不需要相互等待,也不需要在每个迭代周期上同步,模型参数可以随时更新,从而最大限度地提高计算资源的使用效率。但是模型参数是所有线程共享的,线程之间的迭代不同步会导致参数的错误。当有的机器计算得非常慢的时候,意味着该机器的参数落后好多次迭代,当汇聚该机器的参数时就会出现错误,使得模型不收敛。所以有研究者开始探寻一种界于BSP和AP之间的并行模型,既保证算法的正确性又兼顾计算资源的使用效率。
2.3 延时同步并行
SSP是一种延迟同步并行模型,允许在不牺牲算法正确性的情况下使用异步。用户可以指定一个阈值s大于等于零。最慢的线程和最快的线程相差不超过s个迭代周期。如果超过,最快的线程要停下来等待最慢的线程。假设当前最快的线程处在第t个选代周期上,那么所有线程一定都可以看到每个线程第t-s-1个迭代周期之前的更新,有可能看到第t-s-1个周期之后的更新。每个线程一定可以看到自己任何时候的更新。SSP提高了计算资源的使用效率,节省了算法执行时间;同时,通过设置合适的阈值s,保证算法的正确性。
当在广域网上部署一个分布式机器学习系统时,网络带宽的约束使我们不可能将所有的参数更新都同步到所有的数据中心上,事实上,这也是没有必要的。对几种典型的机器学习算法(如Matrix Factorization,Topic Modeling A Image Classification)研究发现,如果将重要性阈值设置为 1% 以上,超过 95% 以上的参数更新都是无关紧要的。因此,消除无关紧要的参数传输,可以大大减少广域网带宽的约束,提高算法的执行速度。
3 参数同步架构
在大规模的分布式环境中,各节点交换梯度所带来的巨大延迟是分布式机器学习中最严重的瓶颈,参数同步架构决定了网络带宽的利用率。
3.1 基于参数服务器的通信架构
参数服务器是分布式机器学习框架中用来同步参数的框架[17-18]。该框架主要包括服务器端(Server)、客户端(Client)和调度器(Scheduler)。服务器端的主要功能是存放机器学习任务的参数W,接收客户端的梯度W,对本地参数进行更新。客户端的主要功能是向服务器端推送梯度和拉取梯度,使用最新的梯度更新本地参数。参数服务器的架构如图1所示。

图1 参数服务器架构
并行LDA(Latent Dirichlet Allocation)框架即为初代的参数服务器,采用高速分布式缓存Memcached系统存储参数,可以高效地共享模型参数。第2代参数服务器是来自于XING E P的petuum[19]。它将原来的整体同步并行模型替换成延迟同步模型,使得整体的通信时长减少。第3代参数服务器来自李沐设计的ps-lite。其针对初代单节点负载过高容易阻塞的问题,采用了多个Server 的高可用架构。
基于参数服务器的分布式深度学习由于参数同步通信量大,扩展性有限。根据神经网络层次结构的特殊性,在反向传播的过程中,由于后一层梯度的同步与前一层梯度的计算没有相关性,所以可以将后层梯度的同步与前一层梯度的计算重叠,把通信时间隐藏在计算中。根据这一特性,文献[23]提出了无等待反向传播概念。无等待反向传播过程如图2所示。

图2 无等待反向传播算法
即使将通信与计算重叠在一起了,但依然存在梯度过大的情况,导致通信不能很好地隐藏在计算中。针对此问题,SHI S等人[24]基于将一些短的通信任务合并成一个单一的通信任务可以减少整个通信时间的事实,提出了合并梯度的无等待反向传播,针对一些短的梯度合并成大的梯度,减少网络的开销,其基本过程如图3所示。针对计算与通信重叠优化,WANG S等人[25]提出了将参数通信和前向计算分批进行,使之相互重叠。

图3 合并梯度无等待反向灰度有区分
3.2 基于All reduce的通信架构
深度学习在多个图形处理器(Graphics Processing Unit,GPU)上训练是比较困难的,一般的做法是将多个 GPU 计算好的梯度发送至一个GPU上进行聚合。这种方法即为经典的All Reduce,其架构如图4所示。但当机器比较多且梯度数据量比较大时,会造成通信瓶颈,使得训练过程变慢。
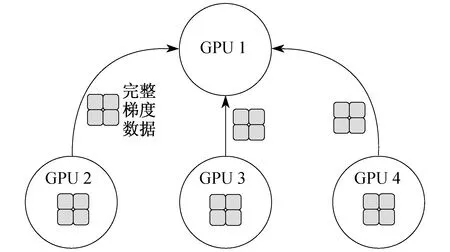
图4 AllReduce 架构
Ring Allreduce的通信时间与GPU节点数无关,只受限于 GPU 间最慢的连接,其架构如图5所示。
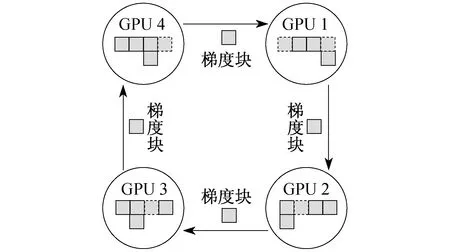
图5 Ring Allreduce架构
目前许多框架都引入了该算法,如 Horovod,Tensorflow,Chainer[26-29]。Ring Allreduce 算法分两步进行:第1步,scatter-reduce,每个 GPU 只与相邻的两个GPU 通信,接受上一个 GPU 的梯度,将自己的梯度发送至下一个 GPU,最终每个 GPU 都有一个最终结果的梯度数据块;第2步,allgather,交换不同的梯度块,使得每个 GPU 都有完整的梯度。
原始的Ring架构虽然可以充分利用带宽,但是随着GPU节点数量的增加,Ring的环也会越来越大,导致单次的同步时长增加。针对此类问题,对于短小的梯度可以采用批量压缩的方法。对于大规模场景采用分层策略,将 Ring 分成多组,逐层、并行地进行参数同步,从而降低通信延时带来的影响。如腾讯提出的2D结构的 Ring Allreduce,索尼提出的2D-Tours[30],Google 提出的2D-Mesh,IBM 提出的 3D-Torus B4。
3.3 基于混合模式的通信架构
由于深度神经网络各层之间的数据特性不一样,如有的网络前几层为卷积层,后几层为全连接层,那么卷积层的参数相比全连接层会少很多,并且神经网络的结构自始至终是不会发生变化的。针对此特性,XIE P等人[31]提出了一种混合通信机制,根据不同的数据特性采用不同通信机制,自适应地选择PS(Parameter Server)或者SFB(Sufficient Factor Broadcasting)。
3.4 基于数据流的通信架构
前面介绍的通信架构都是基于数据并行的,各个节点处理逻辑相同,但当模型比较大时,则需要将模型拆分,将子模型放到不同的节点上计算,此时就需要一种适合模型并行的通信架构。研究者设计了基于数据流的分布式计算系统,此类系统将整个处理过程抽象为一个有向图,图中每一个顶点代表算子,每一条边代表数据的流向,如 Tensorflow 的计算图,Spark的DAG。
参数服务器是非常典型的中心化架构,具有良好的可扩展性和鲁棒性,结构简洁、方便部署。但是这种中心化架构的缺点也是很明显的,一般情况下,参数服务器的数量会远远小于工作节点的数量,大量工作节点的瞬时通信容易造成参数服务器的带宽发生阻塞的情况。Ring架构是一种去中心化的架构,有效地解决了中心化所带来的带宽瓶颈,且已经被证明是目前带宽最优的通信架构,但是这种环状结构导致需要多步才能完成一次参数同步,所以当环中节点较多时就会造成一次同步时间过长的问题。
4 研究展望
虽然分布式深度学习已经广泛应用于很多领域并且取得了不错的效果,但是深度学习的发展日新月异,依然还有很多问题需要解决。
4.1 同步机制
目前参数的同步机制主要有BSP和ASP两种。BSP存在 straggler 问题,其导致的延迟等待使得加速效果并不理想,而异步 ASP 又会带来不容易收敛的问题,尽管XIE P等人[31]提出的SSP解决了上面的问题,但是深度神经网络的发展日新月异,网络越来越复杂,更需要一个适合大规模情况的新的同步机制。
4.2 自适应通信机制
针对神经网络每层前的数据特性具有一定的差异性,XING E P等人[19]提出的自适应结构感知算法进一步扩展了自适应。但考虑更多的环境因素,后续需选择最优的同步机制或者同步架构。
4.3 隐私保护
随着欧盟数据隐私条款的颁布,越来越多的机构开始考虑数据隐私问题。Google提出的联邦学习(Federating Learning)最近受到了许多研究者的关注。联邦学习作为分布式机器学习的子领域,传统的分布式机器学习方法并不能很好地适应,需要针对联邦学习的特性提出新的方法。
5 结 语
随着大数据、云计算和物联网需求的快速增长,分布式机器学习的重要性引起越来越多的关注。本文对目前的分布式机器学习进行了简单的介绍,然后从数据并行模型的通信角度出发,详细分析了参数通信步调和参数同步架构对分布式机器学习的影响。最后对分布式机器学习未来的发展趋势做出了展望,未来大规模神经网络的训练方式会朝着分布式并行训练的方向发展。
