基于领域知识的自适应近邻推荐算法研究*
2021-11-05闭应洲庞健婵武文霖王志远
杨 辉,闭应洲,庞健婵,武文霖,王志远
(南宁师范大学 计算机信息工程学院,广西 南宁 530199)
0 引言
随着互联网与大数据技术的飞速发展,可获取的信息随之海量增长,互联网用户在快速增加,用户对个性化信息的获取、使用等需求也与日俱增,单靠检索功能已无法满足两者增长的要求,个性化推荐系统的出现能满足这方面的要求。作为至今最经典的推荐算法之一的协同过滤算法已被广泛应用于电子商务、线上商城、视频网站、社交应用等网络平台的信息获取或商务活动中。随着越来越多学者投入研究,协同过滤算法的应用技术会更成熟,作用也会越来越大。
传统的协同过滤算法分为基于用户的协同过滤算法(UserCF)[1]和基于物品的协同过滤算法(ItemCF)[2],其推荐原理简单来说是根据用户的历史行为计算用户之间、物品之间的相似度并以此作为实现推荐的依据。协同过滤算法推荐依赖于用户的历史行为,而相较于获取用户喜爱的具体物品,获取用户对物品内在属性的偏好会更容易。就电影推荐为例,若用户同时喜欢《星球大战》《星际穿越》《黑客帝国》3部电影,需要获取用户对3部电影的完整评分记录才能为用户提供准确的推荐,而用户对3部电影共有的“科幻”类别的内在偏好则相对更好获取,在面对历史浏览量较大的新用户时,以获取用户对电影类别、导演、主演等偏好来定位用户实现推荐将更为高效。知识图谱[3]作为一个由实体、关系、属性构成的结构化语义网络,提供了物品之间复杂且丰富的语义关联,能在推荐中针对物品的领域知识实现具有针对性的建模。随着知识图谱相关研究的发展,公共图谱数据已日渐丰富,研究者能更容易获取物品内在信息并构建图谱以实现更好的推荐效果。
基于上述思路,本研究提出一种基于领域知识的自适应近邻推荐方法(NDKCF),能有效缓解传统协同过滤算法的冷启动问题,为推荐结果提供可解释性,并最终提升推荐效果。本研究主要内容包括:(1)以公共电影数据集MovieLens-100K与公共语义数据库DBpedia为基础构建了电影领域的知识图谱;(2)结合用户对电影的历史评分数据与电影知识图谱得到用户对电影的偏好分布,并根据偏好分布为用户找到N个近邻用户组成偏好近邻用户组;(3)基于偏好近邻用户组的电影总评分为用户提供有效推荐,结合UserCF得到最终的推荐结果;(4)在公开电影数据集MovieLens-100K上,通过反复实验测试,获取最佳的推荐效果,最终验证算法的有效性。
1 相关工作
1.1 协同过滤推荐
协同过滤最初是由Resnick等人[1]提出的基于用户的协同过滤算法(User-based Collaborative Filtering Recommendations,UserCF),随后Sarwar等人提[2]出了基于物品的协同过滤算法(Item-based Collaborative Filtering Recommendations,ItemCF)。协同过滤算法是基于用户对物品的历史行为数据构成用户-物品评分矩阵,利用余弦相似度计算得到用户相似度和物品相似度,UserCF根据用户间的相似度预测兴趣相投的用户群组进行组间推荐,ItemCF根据物品之间的相似度预测每位用户最感兴趣的物品进行推荐。之后Daniel等人[4]提出基于物品评分的Slope One算法,能根据已评分的物品数据实现预测未评分物品的分值,一定程度上缓解传统协同过滤的数据稀疏问题,但依赖于评分实现推荐。Koren等人[5]将潜在因子模型与协同过滤算法相结合,通过将用户与物品映射到低维空间中获取用户与物品隐藏特征的向量表示来计算相似度。此外还有SVD[6]、NMF[7]等基于模型的推荐方法。协同过滤推荐虽然能根据用户的历史行为数据有效地挖掘出用户的喜好,但一直以来都面临着冷启动,缺乏可解释性,数据稀疏性等问题,而知识图谱的引入很大程度上解决了这些问题。
1.2 基于知识图谱的推荐
知识图谱是一个结构化的信息库,能为现实生活中的实体、属性、概念以及关系提供针对性的建模,具有极强的表达能力,在医疗、商业、旅游等众多领域都发挥了重要作用。近年来许多学者致力于将知识图谱和推荐算法的融合研究,以知识图谱提供的语义信息辅助推荐以取得更好的推荐效果。Yizhou Sun等人[8]针对从异构信息网络获取不同类型对象的语义信息,提出了一种基于元路径的相似度度量方法,首次利用元路径概念获取用户偏好并提供个性化推荐,但依然无法有效描述用户的偏好分布,且推荐效果依赖于完整的元路径构成。此外,许多研究者尝试通过深度学习获取知识图谱中路径的语义表示。吴玺煜等人[9]利用transE算法将知识图谱的三元组语义信息嵌入低维的语义空间中,通过结合物品在知识图谱中的语义实现推荐,优化了协同过滤算法未考虑物品自身属性的问题。Zhu Sun[10]等人利用循环神经网络(Recurrent Neural Network)对知识图谱中的实体路径建模,自动学习实体间路径的语义的聚合表示,以此得到更具解释性的推荐结果。李浩[11]等人利用LSTM(Long Short-Term Memory)建模电影知识图谱的实体路径,将知识图谱的语义路径推荐融合传统协同过滤,得到了更好的推荐效果。康雁等人[12]结合了transE的实体路径嵌入方法,通过LSTM和soft attention机制获取路径语义融入到推荐中,进一步提高了协同过滤算法的可解释性和推荐效果。而通过学习语义表示辅助推荐的方法依赖于知识图谱信息的完整,推荐效果往往取决于对于每个实体语义的挖掘效果,而当推荐领域信息发生改变时,对于语义信息的更迭也将是一大难点。许智宏等人[13]在协同过滤中引入知识图谱推理技术,通过路径排序算法挖掘实体间多路径关系,用于计算低维空间中视频间的语义相似性,在语义层面增强了推荐效果,并在一定程度上解决了数据稀疏问题,但推荐限于单领域,且无法对挖掘出的隐含特征进行有效描述。
2 基于领域知识的自适应近邻推荐
本研究提出一种基于领域知识的自适应近邻推荐方法(NDKCF),本算法分为3部分(图1)。

图1 基于领域知识的自适应近邻推荐
(1)由公共电影数据集MovieLens中用户与电影的交互记录构建用户-电影知识图谱,通过提取MovieLens中每部电影的所属类别构建用户-电影-电影类型知识图谱。通过知识图谱元路径将用户对电影的评分映射为用户对每种电影类型的偏好矩阵,以此计算用户间在电影类型偏好上的相似度,并取相似度最接近的N个近邻用户组成基于电影类型偏好的用户组,将每类用户看过且该用户未看过的电影按照组内总评分排序,获得Top-K推荐列表RecT。
(2)通过MovieLens与DBpedia的映射完善电影知识图谱,将公共语义数据库DBpedia上电影相关的实体对象同MovieLens-100K中的电影相匹配,获取电影的导演、主演信息,构成用户-电影-主演/导演知识图谱,按照(1)的相似度计算获取每位用户基于主演/导演偏好的用户组,将每类用户看过且该用户未看过的电影按照组内总评分排序,获得Top-K推荐列表RecC。
(3)由基于用户的协同过滤算法获取得到Top-K推荐列表RecCF,最终将各部分的推荐结果RecT、RecC和RecCF按比例融合,得到最终的推荐列表R。
2.1 电影知识图谱构建
公共电影数据集MovieLens-100K包含943名用户对1682部电影的100000项评分与每部电影所属的18种电影类别,其中每项评分分值:1~5,电影类型包括“Action”“Adventure”“Animation”等18个类别名称,未记录类型的电影则标记为“Unknown”。Ostuni等人[14]已经通过映射获取了MovieLens-100K中的1570部电影在DBpedia上的实体表示,利用Sparql语句获取到DBpedia上对应电影的导演、主演信息用于补全电影知识图谱。最终获取到1682部电影的6408条类别关系、1423条导演关系和6216条主演关系。将电影、电影类型、导演、主演作为实体,以三元组的形式构建知识图谱K=(E,R,S),其中E为头实体集合,R为关系集合,S为尾实体集合。
2.2 元路径搜寻偏好用户组
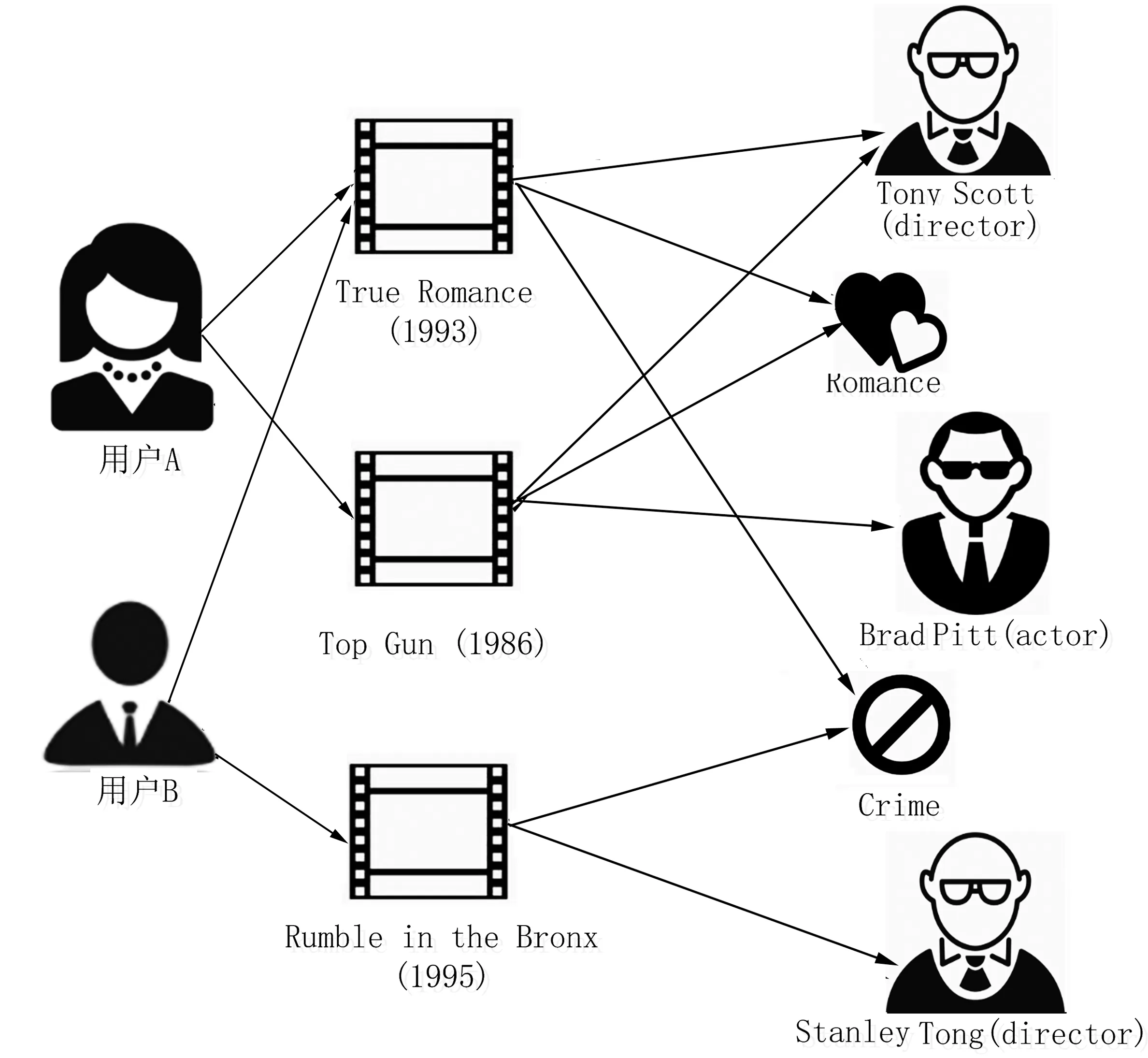
图2 用户偏好分布
用户A的元路径偏好推导:
用户A-评分→True Romance-电影类型→Romance;
用户A-评分→Top Gun-电影类型→Romance;
用户A-评分→True Romance-电影导演→TonyScott;
用户A-评分→Top Gun-电影导演→TonyScott。
用户B的元路径偏好推导:
用户B-评分→True Romance-电影类型→Crime;
用户B-评分→Rumble in the Bronx-电影类型→Crime。

用户-电影矩阵1

电影-偏好矩阵2

用户-偏好矩阵3
根据用户A评价过的两部电影通过元路径挖掘出他对电影类型Romance和导演TonyScott有较高的兴趣偏好,同样用户B看过的两部电影能反映出他对电影类型Crime拥有较高的兴趣偏好。通过元路径对用户偏好的搜寻可以获取用户的所有偏好分布。
根据用户与对应电影偏好之间构成的元路径数量作为用户对电影偏好的喜爱程度,最终得到用户在电影类别、电影导演和电影主演上的偏好矩阵wut、wud和wus。

用户-电影主演偏好分布矩阵5/wud

用户-电影主演偏好分布矩阵6/wus
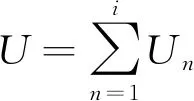
将所有用户的偏好分布视作该偏好空间中的向量,用户在偏好空间中的距离越近,用户在该类电影偏好上的相似度就越高。
通过计算用户偏好向量之间的欧式距离计算用户之间的偏好相似度:
(1)
(2)
式中DT(Ua,Ub)为用户a与用户b在电影类别偏好空间内的欧式距离,DC(Ua,Ub)为用户a与用户b在剧组人员偏好空间内的欧式距离。根据每个用户在不同偏好空间中的距离判断用户对于该种偏好的近似程度,最终取相距最近的N个近邻用户组成偏好用户组。
根据所得的偏好用户组,统计每个用户对所有电影的评分,获取得到电影类别偏好用户组最喜爱的电影列表RecT与剧组人员偏好用户组最喜爱的电影列表RecC。根据两个列表中总评分最高且用户未看过的电影作为最终的推荐结果。
2.3 协同过滤推荐
基于用户的协同过滤通过用户评分过的所有电影找到评分趋势最为相近的用户,根据计算用户之间对物品评价的余弦相似度找到数个相似用户,算式:
(3)
式中N(u)与N(v)表示用户u与用户v喜欢的电影集合,|N(u)∩N(v)|表示用户u与用户v共同喜欢的电影集合|N(u)|×|N(v)|表示用户u与用户v喜欢的电影数量的乘积,wuv为计算得到的用户u与用户v的相似度。最终根据用户相似度找到K个最相近用户,计算用户u对相近用户喜欢的电影i的感兴趣程度:
P(u,i)=∑v∈S(u,K)∩N(i)wuv×rvi
(4)
式中S(u,K)表示通过余弦相似度计算得到的用户u的K个相似用户,N(i)表示喜欢电影i的用户集合,v为相似用户中对喜欢电影i的部分用户,wuv为用户u与所有相似用户v之间的余弦相似度,rvi为相似用户v对电影i评分,通过计算所有相似用户的wuv与rvi乘积之和得到用户u对电影i的感兴趣程度P(u,i)。最终根据用户u对所有电影的感兴趣程度进行排序后得到Top-K推荐列表RecCF。
2.4 NDKCF算法
输入:电影知识图谱元路径三元组集E,历史评分集T,相似用户数量K,推荐列表长度N;
输出:推荐结果R、precision、recall、F1-score;
(1)根据集合E与集合T得到用户与电影历史评价分布wuv,用户对电影类别的偏好分布wut和对剧组人员的偏好分布wuc;
(2)根据wut与式(1),得到K个电影类别偏好近邻集合UT;
(3)根据wuc与式(2),得到K个剧组人员偏好近邻集合UC;
(4)根据UT,UC的电影总评分排序生成候选推荐列表RecT,RecC;
(5)根据wuv与式(3)与式(4)生成推荐列表RecCF;
(6)按比例融合RecT,RecC,RecCF得到最终推荐列表R。
3 实验与结果分析
3.1 实验数据集
本研究使用的数据集MovieLens_100K包含943名用户对1682部电影的100000项评分以及对应电影的18项类别。将电影作为实体通过Dbpedia公共数据集映射后获取到896个导演的1423条导演关系和3287个主演的6216条主演关系。由于与电影集合仅有单一关系的偏好节点对于用户偏好的挖掘贡献很少,因而该条元路径不计入偏好数,最终数据见表1。

表1 实验数据集信息
为使实验具有可比性,所有实验采用的训练集与测试集均由用户的100000项评分以8∶2的比例随机划分构成。
3.2 评价指标
本研究采用准确率(precision)、召回率(recall)、F1值(F1-score)作为评价指标,3个指标的算式如下:
(5)
(6)
(7)
其中,U是用户集合,R(u)是通过训练集计算后为用户u推荐的N个结果,T(u)是测试集中用户的历史评分。准确率表示的是正确预测的推荐项目在推荐的所有项目中的占比,召回率表示正确预测的项目在测试集中所有项目的占比,两者越接近1则预测效果越好。F1值为平衡了准确率和召回率的综合评价标准。
3.3 实验结果
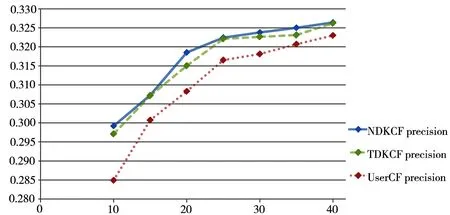
图3 准确率
为了证明基于领域知识的自适应近邻推荐方法对于协同过滤推荐的有效性,以推荐列表长度N=10,相似用户数与偏好近邻数K取值为:10~40,每5次做1次对比。为避免实验结果的偶然性,每次对比的结果都是对应算法10次结果的平均值。其中,蓝线为基于领域知识的自适应近邻推荐方法(NDKCF),NDKCF将推荐列表RecCF、RecT、RecC以8∶1∶1混合;绿线为只考虑电影类型的基于电影类型与协同过滤的自适应近邻算法(TDKCF),TDKCF将推荐列表RecCF、RecT以9∶1混合;红线为基于用户的协同过滤算法(UserCF),推荐结果全由推荐列表RecCF构成。
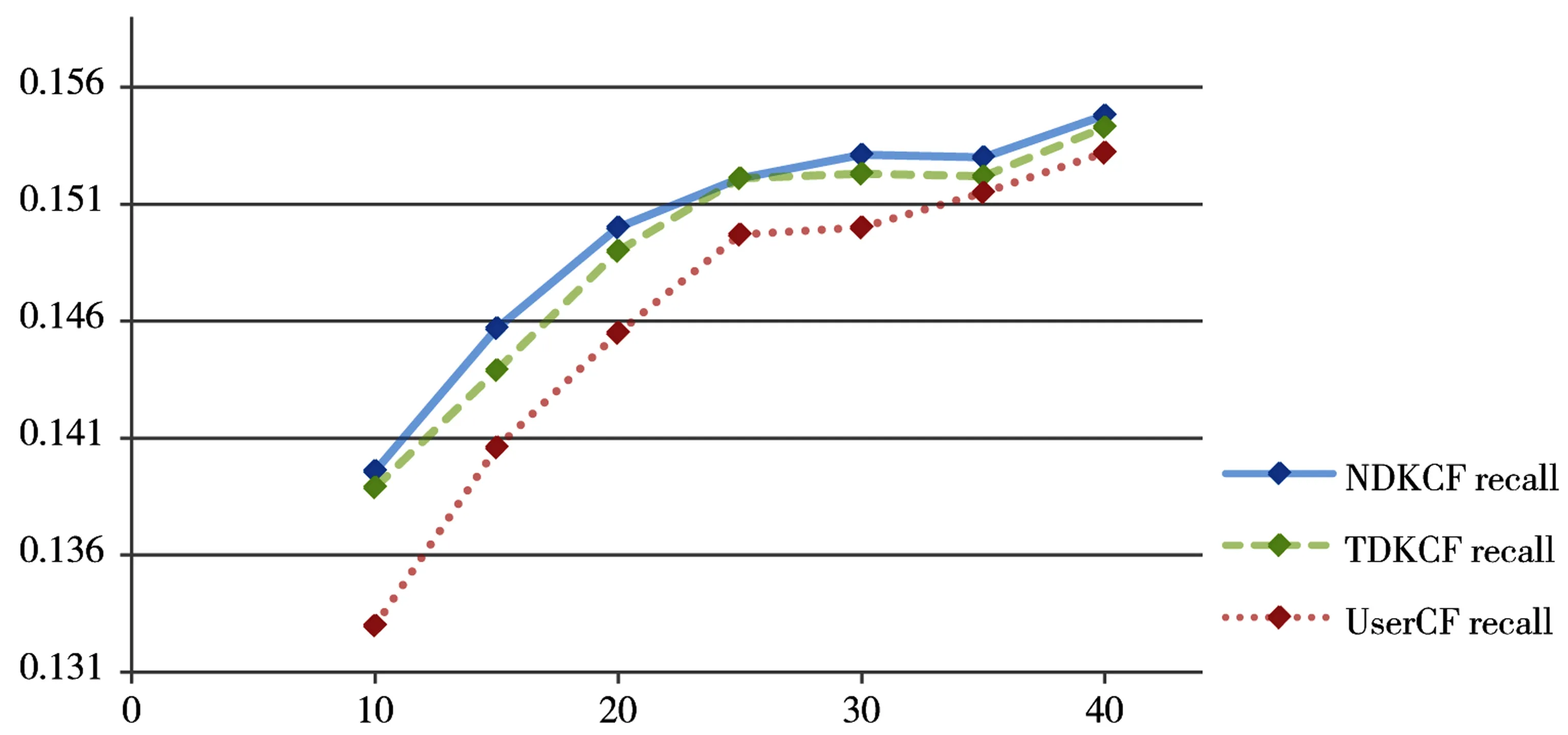
图4 召回率
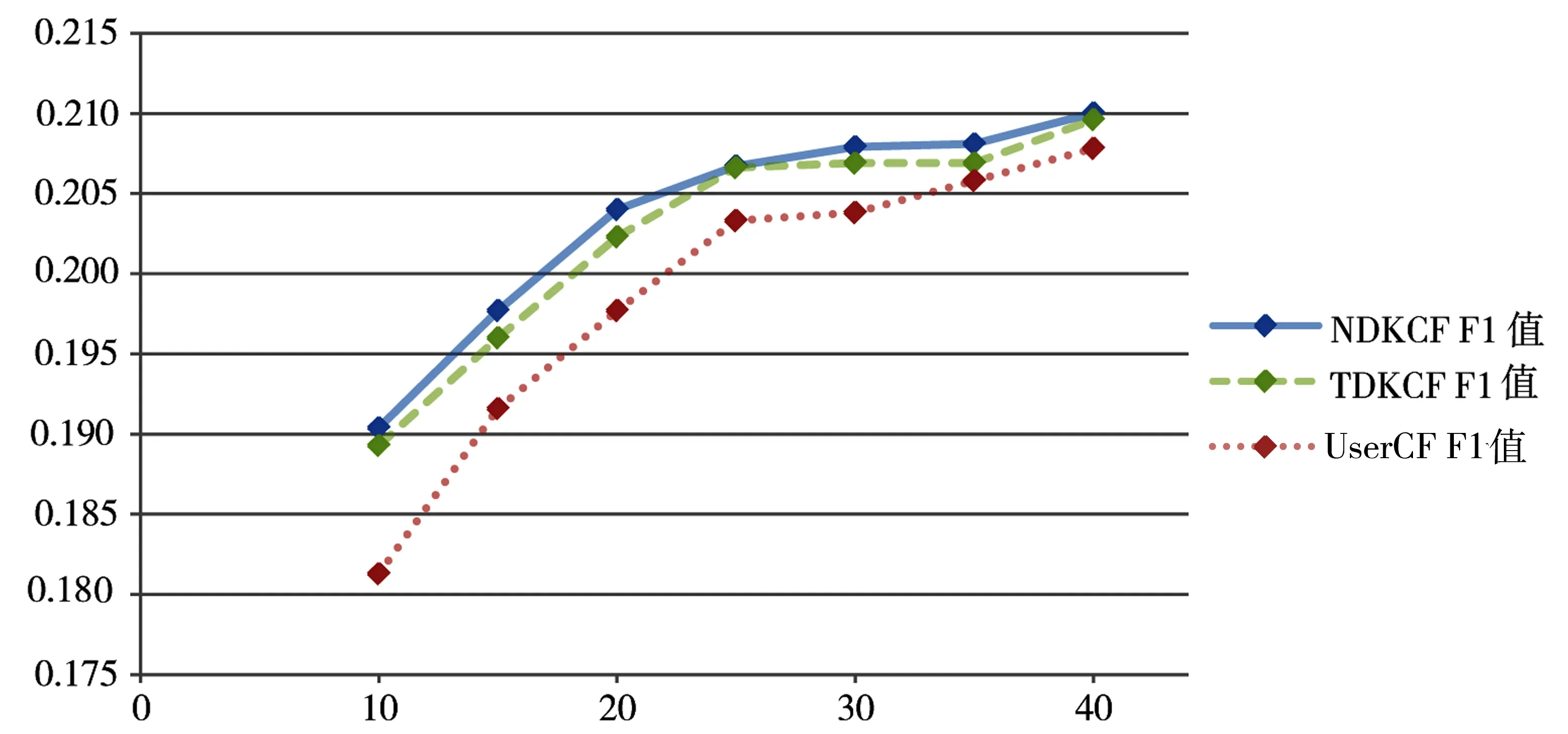
图5 F1值
当选择的相似用户数相同时,NDKCF和TDKCF在3种评测标准上均有优于UserCF的表现,且偏好信息更充足的NDKCF普遍优于只考虑电影类型偏好的TDKCF。实验结果说明基于领域知识的自适应近邻推荐方法有效提高了协同过滤的推荐效果,且随着对电影偏好知识图谱的完善,NDKCF能有更好的效果。
取推荐列表长度N=10,相似用户数K=20,将NDKCF与热门推荐MostPop、奇异值分解SVD、TDKCF、UserCF、itemCF对比,结果见表2。

表2 六种推荐方法的准确率、召回率、F1值对比
NDKCF在3个指标上都优于传统的协同过滤ItemCF与UserCF,且当用户偏好不完善时,也能通过知识图谱搜寻部分方面的偏好近邻实现较好的推荐效果。实验验证了NDKCF在提升了推荐个性化与可解释性的情况下具有更好的推荐效果。
4 结 语
本研究基于领域知识的自适应近邻推荐方法,通过搜寻知识图谱元路径获得用户在各个偏好上的最近邻,根据偏好近邻用户组得到更有针对性的个性化推荐。实验证明了在偏好信息不完全的情况下该方法依然具有较好的推荐效果,能应对新用户难以获取完整偏好的问题,有效缓解冷启动情况。未来我们将尝试完善电影知识图谱的偏好构成,通过图深度学习的方法挖掘并利用领域知识中更复杂的偏好特征融入推荐过程中,以获取更好的推荐效果。
