InterDroid:面向概念漂移的可解释性Android恶意软件检测方法
2021-11-05魏筱瑜任家东
张 炳 文 峥 魏筱瑜 任家东
1(燕山大学信息科学与工程学院 河北秦皇岛 066004) 2(河北省软件工程重点实验室(燕山大学) 河北秦皇岛 066004) 3(中国五洲工程设计研究院 北京 100053) (jdren@ysu.edu.cn)
2021年第1季度,360互联网安全中心截获移动端新增恶意程序样本约206.5万个,比2020年同期增长426.5%,造成人均经济损失14 611元[1].相较于iOS操作系统,Android操作系统占据中国移动端市场76.91%[2],且Android开放平台的应用软件生态,使其更易受到恶意软件威胁.
现有的Android恶意软件检测方法分为:基于特征码的检测方法、基于机器学习的静态检测方法、基于机器学习的应用行为检测方法3大类.基于机器学习的静态检测方法因其对未知恶意软件检测准确率高、对设备硬件要求低等优点成为主流的Android恶意软件检测方法.
基于机器学习的静态检测方法在特征选取上以权限特征为核心,并选取多种其他特征作为辅助.例如:应用程序编程接口(application programming interface, API)、服务、广播、字符串等.在模型训练算法上,决策树、梯度提升树等分类树算法,频繁项集与关联模式挖掘等推荐算法取得较好表现后[3],卷积神经网络等计算机视觉领域算法及Word2vec等自然语言处理领域算法也被引入Android恶意软件检测,用于处理多模态的恶意软件特征.
但是,传统的机器学习静态检测方法正面临3个主要挑战:
1) 应用市场中请求敏感权限的应用比例正在下降[4],部分恶意应用能在不申请新权限的基础上完成攻击.单一的权限特征,或无逻辑引入的特征组合不足以表征恶意软件.
2) 黑盒的机器学习算法获得越来越高准确率的同时,恶意应用检测对模型的可解释性与透明性要求越来越高[5].Android恶意软件逆向人员需要模型提供决策依据,以促进人工分析或判断模型决策的合理性.
3) Android系统版本的高频率更新导致以各版本软件开发工具包(software development kit, SDK)为基础开发的Android应用均拥有一定市场占有率[6].而由于概念漂移现象,以大量样本为代价训练得到的机器学习模型在对不同时期Android恶意软件的检测上表现较差.
为此,本文提出一种面向概念漂移的可解释性Android恶意软件检测方法.在特征引入阶段,该方法首先基于Kharon数据集[7]以恶意软件人工分析报告中的高频词作为依据,在源代码层次选取权限名、API包名、意图3类特征,并在汇编指令层次选取Dalvik字节码特征作为补充.从而多层次地扩充单一的权限特征,并提升特征引入过程逻辑性及特征对恶意软件的表征能力.在特征包装与解释阶段,首先对每种特征分别以TPOT(tree-based tipeline optimization tool)算法[8-10]筛选机器学习模型进行预训练,其后基于SHAP(shapley additive explanations)算法[11-13]对每个预训练模型建立解释器,筛选得到对分类结果具有高贡献度的可解释性特征组合.并以此提高模型的透明度,为人工分析与验证提供决策依据.在模型迁移阶段,首先判断已有模型是否需要迁移.一方面利用预训练得到的模型预测不同时期恶意样本,另一方面基于特征包装与解释阶段输出的特征组合采样不同时期Android恶意软件,并进行曼-惠特尼U(Mann-Whitney U, MWU)检验[14].在满足特征迁移条件后,基于联合分布适配(joint distribution adaptation, JDA)算法[15-16]改进已有训练模型.最终以无标注小样本的不同时期软件为代价完成已有训练模型迁移,提升已有检测模型对不同时期恶意软件检测效果.最终,再次使用TPOT算法筛选对比模型进行验证.实验结果表明,InterDroid对同时期Android恶意软件检测准确率达95%,对不同时期恶意软件能将已有模型检测准确率提升1倍以上.能有效检测同时期恶意软件,提高模型决策依据透明度,并在较低迭代次数下完成模型迁移,从而缓解概念漂移导致的Android恶意软件检测准确率下降问题.
综上,本文提出的方法主要有3方面贡献:
1) 基于Android恶意软件分析报告提取攻击流程中的高频词,据此引入权限名、API包名、意图这3类源代码层次特征,以及汇编指令层次的Dalvik字节码特征.使初始特征组合在保证低存储开销与较高分析速度的同时能够更好地表征恶意软件,提高引入特征组合的逻辑性与合理性.
2) 改进传统的特征包装方法,使用自动化机器学习TPOT算法筛选最佳分类模型集合,将集合中模型与4种特征两两组合训练,并为训练得到的模型建立解释器.InterDroid筛选出的特征对多数训练样本的分类结果具有高贡献度,并为模型的验证与恶意软件的人工分析提供依据.
3) 将领域自适应方法引入Android恶意软件检测.在已有数据和模型的基础上,以少量无标注新时期Android软件为代价,即可有效提升现有模型对新恶意样本的检测准确率,进而缓解概念漂移问题.
1 相关工作
Android系统的沙盒机制,使非定制系统中的应用动态行为监控较为困难[17].目前Android恶意应用自动化检测在特征提取阶段仍以静态特征为主,并以权限特征为主线展开.Felt等人[18]最早建立了API到权限的映射,并开发了检测Android应用程序恶意代码的Stowaway;但忽略了用户自定义权限,并且无法建立复杂的Java反射调用到权限的映射关系.Bartel等人[19]将API链接到服务的绑定机制,找到应用声明权限与其实际使用权限的不同,填补了 Stowaway在Java反射调用到权限映射上的空白,但其未能研究Dalvik字节码层面的特征.Karim等人[20]将API到权限的单向映射完善为可相互追溯的双射,通过关联模式挖掘,在软件开发阶段提醒开发者使用的API应申请的最小权限;但其研究局限于开源软件,而实际的Android恶意软件检测目标多为编译后的应用程序安装包.Olukoya等人[21]引入自然语言处理技术,将应用市场中的程序描述作为权限的补充信息.Wang等人[22]以用户评论替代应用描述进行权限推断,并认为在反映权限的真实使用状况上众包用户评论较之应用描述更具有效性.但以上2种方法均依赖于应用描述与用户评论的真实性.
相较于上述方法,本文基于人工Android恶意软件分析报告,从权限特征出发,增加API包名、意图等Android逆向分析流程中的突破点作为特征,并加入汇编指令层的Dalvik字节码作为补充,提高了特征的全面性与客观性.
针对Android恶意应用自动化检测中的维数灾难问题,现有研究一方面采用过滤、包装、嵌入[23]等方法降低特征维度,另一方面将高维特征转化为图像,结合计算机视觉改进检测模型.在特征降维方面:Alecakir等人[24]基于注意力机制与递归神经网络等机器学习模型包装特征;Li等人[25]采用嵌入方法,通过排序得到恶意与良性样本的差异性特征,并融合决策树剪枝与频繁项集挖掘算法进行特征筛选;Yuan等人[26]提出权限风险值的思想,通过Markov链过滤特征.在高维特征表征为图像方面:Chen等人[27]将源代码基本块转换成多通道图像并以此训练卷积神经网络模型;Ünver等人[28]则首先将源代码转换为灰度图像,再选取图像的局部与全局特征.
上述研究虽然有效地解决了高维特征的表征问题,但其特征引入过程具有主观性.例如,同样是重复出现的权限集合,Wang等人[29]认为应该保留,而文献[25]主张删除,并且特征选择与模型训练过程缺乏可解释性.文献[22]虽然生成了可解释的判别规则,但模型依赖决策树,不能扩展为其他模型.本文融合SHAP算法,通过解释特征包装模型输出完成特征选择.在降低特征维度的同时,保证了训练模型的可扩展性与选择特征的可解释性,为人工逆向分析提供指导.
由于Android版本与开发库的频繁更新,Android恶意软件检测存在概念漂移问题[30].Mariconti等人[31]通过构建Markov行为模型链,有效地提升了2年内恶意软件的检测效率.本文最终的特征迁移可与文献[31]相互补充.
2 方法设计
首先,本节介绍InterDroid整体研究框架,建立InterDroid数学模型.其次,分节介绍研究框架中不同模块及其涉及的方法.由于模型训练模块与实验数据联系紧密,因此其中包含的数据处理与训练结果将在第3节实验评估中详细展开.
2.1 研究框架
本节分为框架总述与框架建模2部分介绍InterDroid研究框架.其中,框架总述为本文方法各阶段研究目标与研究步骤的简要概括;框架建模为本文方法建立数学模型,细化总体框架.
1) 框架总述
本文研究框架总体上分为特征包装与解释、模型训练、迁移判定、特征迁移4个部分.如图1所示:
① 特征包装与解释.以筛选出可解释的特征组合为目标.首先提取Android恶意样本分析报告关键词,获得权限、API包名、意图、Dalvik字节码4种特征类型.其次,基于TPOT算法得到筛选模型集合并与4种特征数据两两组合进行训练.基于SHAP算法对训练后的筛选模型建立解释器,从而类内排序每类特征包含特征分量的SHAP值.筛选出SHAP值高,即对分类结果贡献度高且对大多数样本具有显著影响的特征分量,并采用水平拼接方式融合上述特征分量,融合结果即为InterDroid筛选出的特征组合.
② 模型训练.以获得InterDroid检测模型及不同时期Android恶意软件数据为目标.基于筛选出的特征组合,一方面抽取已有Android恶意软件数据集中对应数据,训练检测模型;另一方面,通过Python整合Androguard[32],从而提取不同时期恶意软件安装包中对应数据,供迁移判定模块使用.
③ 迁移判定.以判定当前模型是否需要进行特征迁移为目标.一方面,使用不同时期Android恶意软件数据测试原有分类检测模型;另一方面对不同时期Android恶意软件数据进行同分布检验.若当前模型准确率低于工业界标准且不同时期Android恶意软件特征存在概念漂移现象,则对当前分类检测模型进行特征迁移.
④ 特征迁移.以提升现有模型对新兴Android恶意软件检测准确率为目标.基于JDA算法将当前模型训练数据领域知识迁移到不同时期Android恶意软件领域,进而提升InterDroid检测模型对新兴Android恶意软件的检测准确率.
2) 框架建模
InterDroid检测模型依据的特征组合finalfeature经由特征包装与解释模块中高频词提取、基于TPOT的对比算法筛选、基于SHAP的特征可解释性包装3步获得.
① 高频词提取.基于Kharon数据集提取Android恶意软件分析报告高频词汇,并将排名靠前的高频词语对应到Androguard可提取的静态特征种类.
r(R)→featureset={fn1,fn2,…,fns},
(1)
R={report1,report2,…,reportn},
(2)
其中,r为高频词提取映射,R为Android恶意软件报告集合,featureset为选取的特征种类集合,fni(1≤i≤s)为特征名,reportj(1≤j≤n)为第j篇Android恶意软件分析报告,reportj中截取片段示例如图2所示:

Fig.2 Illustration of malware analysis report fragment图2 恶意软件分析报告片段示意图
② 基于TPOT的检测算法筛选.基于Omni-Droid[33]数据集,投影得到4种特征对应的Android恶意软件子数据集合.
(3)
其中,maldata为OmniDroid包含的所有Android恶意软件数据,pdi为maldata取fni特征投影后的子数据集合.
为每种特征数据分别建立TPOT算法筛选器,得到4种划分数据集上检测表现最佳的分类器集合.
(4)
其中,tp为TPOT算法筛选映射,p为tp筛选得到的分类模型种类总数,mk为tp筛选得到的分类模型,1≤k≤p.
③ 基于SHAP的特征可解释性包装.将分类器与子数据集合两两组合进行训练,并为训练得到的模型建立SHAP解释器,从而获得对模型分类结果影响最大的t个特征.
calculate(mk(pdh))=shaph,
(5)
shaph={vh1,vh2,…,vht},
(6)
其中,calculate为检测模型mk的SHAP值计算与排序映射,shaph为第h个子数据集合pdh得到的可解释特征组合,vhq为该特征组合中第q个特征名称,1≤q≤t.
融合4个特征组合作为InterDroid的分类特征,并由此得到InterDroid最初分类模型训练数据.
(7)

(8)
其中,finalfeature为特征包装与解释模块输出的特征组合,tdata为模型训练模块的训练数据.
最终,InterDroid统一建模为
InterDrover={e,t,j,m},
(9)
其中,e为基于Androguard的APK特征提取映射,t为基于双重分布检验的迁移判定映射,j为基于JDA的特征迁移映射,m为恶意软件检测分类映射.
对于新兴未知Android软件小样本,e以.APK格式的安装包作为输入,输出该新时期Android软件finalfeature对应数据.结合原有数据库采样数据作为t的输入,从而判断2组数据之间是否需要特征迁移.t的判断结果与e提取到的原始数据共同作为j的输入,以获得模型分类数据并输入到m,从而输出分类结果.
e(APK)→fdata,
(10)
t(fdata,sam)→judge={T,F},
(11)
j(fdata,judge)→finaldata,
(12)

(13)
m(finaldata)={0,1},
(14)
其中,fdata为基于新兴Android软件提取到的finalfeature特征数据,sam为模型训练模块中训练数据采样后的子集,judge为迁移判定映射的判断结果,finaldata为本文检测模型输入数据,cdata为fdata特征迁移后的结果.T表示fdata需要特征迁移,F反之.1表示未知Android软件为恶意软件,0反之.
2.2 特征包装与解释
本节介绍InterDroid检测模型依据的可解释性特征组合筛选过程.依据2.1节中建立的数学模型,特征包装与解释模块分为高频词提取、基于TPOT的对比算法筛选、基于SHAP的特征可解释性包装3个部分.但是,由于高频词提取部分具有原理简单、与Android恶意软件分析报告语料数据结合紧密的特点,该部分归并到第3节实验评估中详细展开.因此,本节包含基于TPOT的检测算法筛选、基于SHAP的特征可解释性包装2部分内容.
1) 基于TPOT的检测算法筛选
一方面,针对特征包装与解释模块4种不同的特征数据,基于TPOT算法筛选适用于不同种类特征的最佳分类器集合,进而得到多个筛选模型对不同种类特征的包装与解释,以便验证InterDroid所用特征组合的稳定性.另一方面,针对模型训练模块的输入数据,基于TPOT算法筛选适用于InterDroid检测模型训练数据的最佳分类器,以对比检测模型的效率与特征迁移效果.
① 自动化机器学习TPOT算法
TPOT以最大化分类精度为目标基于遗传算法自动构建一系列数据转换和机器学习模型,从而自动化机器学习中的模型选择及调参.TPOT目前支持的分类器主要有贝叶斯、决策树、集成树、SVM、KNN、线性模型、xgboost等.其整体流程如图3所示:

Fig.3 Illustration of TPOT图3 TPOT示意图
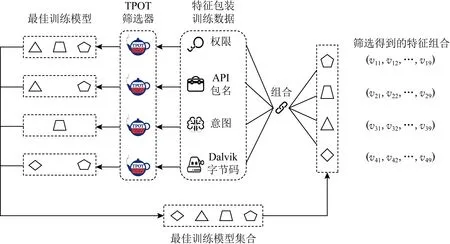
Fig.4 Illustration of algorithm filtering for comparing the feature set图4 特征组合对比算法筛选示意图
TPOT对输入的不同种类特征数据或InterDroid检测模型训练数据首先尝试进行二值化、正则化等操作,并尝试对输入特征做基于方差或基于F-值的特征选择操作.之后,面向预处理完成的输入数据随机生成固定数量的管道,根据分类精度对这些管道进行评估.并从现有管道群体中随机选择3个管道,移除最低适应度的流水线复制到新的群体中.创建新的群体后,将单点交叉应用于固定百分比的复制管道,其中随机选择2条管道相互交换内容.随后,对剩余未受影响的管道进行均匀突变、插入突变与收缩突变.
TPOT重复迭代以上评估、选择、交叉、变异4步,从而分别筛选出用于特征组合对比与InterDroid检测模型对比的算法集合.
② 特征组合对比算法筛选
特征组合对比算法筛选步骤整体流程如图4所示.基于OmniDroid数据集,分别投影权限、API包名、意图、Dalvik字节码4种特征,得到特征包装训练数据pd.以Dalvik字节码为例,其特征名向量pdname为
(“shl-int”, “long-to-int”, …, “if-gt”).
特征包装训练数据中代表1个Android良性或恶意软件的行切片向量perpd为
(5,3, …,21),
其中,行切片向量中每个分量代表特征名向量中对应分量的出现次数.
分别将权限、API包名、意图、Dalvik字节码对应的4种特征包装训练数据输入TPOT算法,筛选得到针对不同训练数据的最佳管道,并以最佳管道使用的算法作为最佳训练模型mk.例如,若Dalvik字节码最佳管道为
{GradientBoostingClassifier(n_estimators=50,learning_rate=0.1),SVC()},
则其最佳训练模型为
{GradientBoostingClassifier,SVC}.
将所有最佳训练模型添加到最佳训练模型集合,集合内每种训练模型均与4种特征包装训练数据两两组合,得到多个特征组合对比模型,且所有对比模型均会作为SHAP解释器的输入,用以对比特征包装与解释模块筛选得到的特征组合稳定性.
特征组合对比算法筛选步骤以TPOT算法筛选得到的对比模型替代人工选择的常用对比模型,自动化地完成了不同种类特征数据的训练模型选择与参数调优过程,使选择得到的最佳训练模型具有较高数据相关性,避免了模型训练中参数调整的不确定性.
③ 检测模型对比算法筛选
检测模型对比算法筛选步骤整体流程如图5所示:
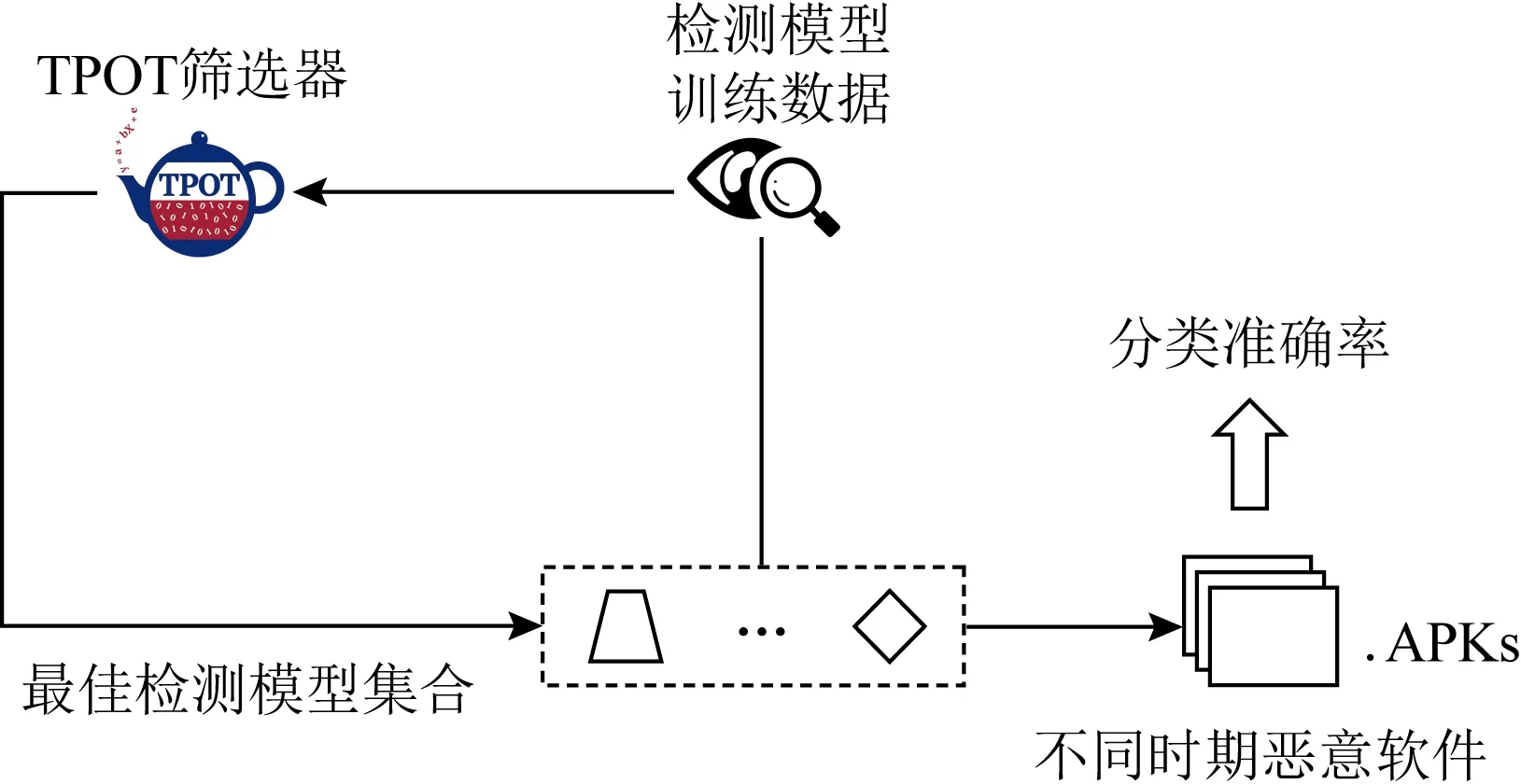
Fig.5 Illustration of algorithm filtering for detection model图5 检测模型对比算法筛选示意图
基于筛选出的特征组合取OmniDroid数据集投影,得到InterDroid最初检测模型训练数据tdata.筛选出的特征组合向量为
(“div-float”, …, “android.view.inputmethod”, …, “RECEIVE_BOOT_COMPLETED”,…, “java.util.concurrent.locks”).
最初检测模型训练数据tdata中代表1个Android恶意软件的行切片向量为
(0,…,1,…,21,…,4),
其中,行切片向量中每个分量代表特征组合向量中对应分量出现次数.
以tdata作为TPOT算法输入,得到面向当前时期Android恶意软件特征数据的最佳检测模型集合.测试集合中每个模型对当前时期及不同时期Android恶意软件的检测准确率,用以对比InterDroid检测模型准确率.
TPOT算法筛选得到的对比算法均在InterDroid检测模型训练数据上具有较高的准确率.较之以往研究中普遍选择的朴素贝叶斯、K均值等算法,更能突出InterDroid在缓解不同时期Android恶意软件特征数据的概念漂移问题上具有较佳鲁棒性.
2) 基于SHAP的特征可解释性包装
针对黑盒Android恶意软件检测模型存在的准确率高但可解释性不足问题,基于SHAP算法面向特征包装与解释模块中复杂的特征筛选模型建立解释器,通过SHAP事后归因的模型解释方法筛选出对Android恶意软件检测结果具有高贡献度的特征.
LIME,DeepLIFT等可解释方法实质上均可归结为SHAP算法.由SHAP算法计算得到的SHAP值是权限、API包名、意图、Dalvik字节码某类特征中某个特征分量在该类特征序列中的平均边际贡献,即SHAP算法考虑了同种特征组中不同特征分量之间的协同效应.例如:权限特征组中“RECEIVE_SMS”与“SEND_SMS”分量之间存在相互影响.因此,选择SHAP算法为特征包装与解释模块中的解释器建立算法.
特征包装与解释模块流程如图6所示:
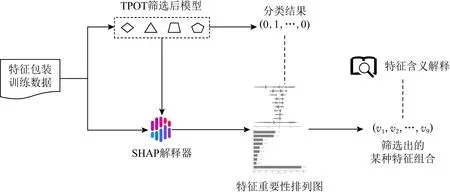
Fig.6 Illustration of feature wrapper and interpretation module图6 特征包装与解释模块示意图
InterDroid基于特征组合对比算法筛选步骤输出的最佳训练模型集合与特征包装训练数据,通过SHAP算法简化每个最佳训练模型mk为事后解释模型hk.针对特征包装训练数据pd中任意一个代表Android良性或恶意软件的行切片向量perpd,事后解释模型hk满足:
(15)
其中,avg0为所有特征包装训练数据pd标签值的均值,shapq为特征名向量pdname第q个分量的SHAP值,perpdq为行切片向量perpd的第q个分量值.
通过式(15),SHAP解释器计算得到权限、API包名、意图、Dalvik字节码中某类特征序列各个特征分量的SHAP值,从而绘制特征密度散点图与特征重要性SHAP值图.
特征密度散点图、特征重要性SHAP值图均为特征重要性的排列图.其中,特征重要性SHAP值图为每个特征SHAP值排序;特征密度散点图将所有Android良性或恶意软件样本点呈现在图中,一方面可以直观得到哪些特征分量对大部分样本的分类结果有影响,另一方面可以观察到某个特征分量中不同Android良性或恶意软件样本数据的数值大小对分类结果的影响.
2.3 迁移判定
不同时期Android恶意软件特征数据的概念漂移可能使InterDroid对新兴Android恶意软件的检测准确率下降.迁移判定模块以模型训练模块中分类模型训练数据sam、新时期Android恶意软件数据fdata作为数据支撑,基于机器学习模型检测与MWU检验双重同分布检测方法,判定提取到的新兴Android恶意软件特征数据是否需要进行特征迁移.
因为sam,fdata两类数据具有3个特点:1)数据分布状况未知;2)数据来自不同的独立样本;3)数据量在100以上.而KS检验、t检验、MWU检验、威尔科克森符号秩(Wilcoxon signed rank, WSR)检验等常用数据同分布检测方法中:1)当检验的数据符合特定的分布时,KS检验灵敏度较低.2)t检验样本需满足正态分布,且其最佳样本容量小于30.3)WSR检验与MWU相似,均不要求样本服从正态分布且样本容量大于20时即可获得较好的检验效果,但WSR检验应用于2个相关样本.因此,迁移判定模块选择MWU检验.同时,使用InterDroid所使用的机器学习模型进行二次检验,从而确定概念漂移现象已致使本文模型检测准确率降低.
首先,以fdata作为测试数据得到InterDroid当前分类检测模型的准确率.若当前准确率低于工业界允许的最低准确率,即90%,则认为当前检测模型已不能满足新时期Android恶意软件检测标准.采用MWU检验判定其检测准确率下降的原因是否为新时期Android恶意软件特征的概念漂移.
将分类模型训练数据sam、新时期Android恶意软件数据fdata混合并编排等级,继而分别求出两样本的秩和.得到sam,fdata两样本MWU检验统计量为
(16)
(17)
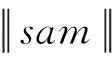
若U1,U2最小值小于显著检验U0.05时,则提取到的新兴Android恶意软件特征数据需要在检测前进行特征迁移.
具体算法如算法1所示.
算法1.双重分布检验算法.
输入:小样本新时期Android恶意软件数据fdata、与小样本同规模的原有模型训练数据采样sam;
输出:决定是否需要进行特征迁移的判定结果judge.
①res=m(fdata);
/*使用原有模型检测新时期恶意软件*/
② ifacc(res)>90%
/*如果现有模型准确率仍能符合要求*/
③ return false;
④ end if
⑤D=∅;/*需删除的特征集合*/
⑥ for (fi,si)←(fdata,sam)
/*每种特征取2类数据*/
⑦ ifMWU(fi,si)>5%/*如果该特征在2个样本上具有显著性差异*/
⑧D=D∪f;
⑨ end if
⑩ end for
/*去除有差异的特征训练临时模型*/
/*两模型准确率不具有明显差距*/
2.4 特征迁移
针对不同时期Android恶意软件特征概念漂移导致的Android恶意软件检测模型对新时期恶意软件检测准确率降低的问题,以有标注的InterDroid检测模型训练数据为源域,基于JDA算法完成对目标域中无标注新时期Android软件良性或恶意的检测判定,从而达到领域自适应的效果,提高InterDroid对新兴Android恶意软件的检测准确率.
新兴Android恶意软件存在2个问题:1)权限、意图等特征数据较之早期数据整体不相似或部分不相似.2)短期内难以收集大规模、同分布、带标注的数据集用以提升检测模型准确率.而JDA算法具有2个优点:1)能够同时处理InterDroid原有训练数据中知识需迁移到边缘分布不同的新数据(即整体不相似新数据)、条件分布不同新数据(即类内不相似新数据)这2种情况.2)以小样本、无标注新时期Android软件即可完成特征迁移.因此,特征迁移模块选择JDA算法以提升InterDroid检测模型的准确率.
特征迁移模块流程如图7所示:
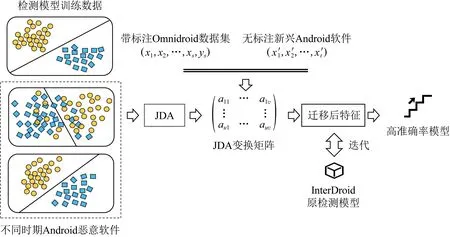
Fig.7 Illustration of feature-representation transfer图7 特征迁移模块示意图
基于不同时期Android恶意软件样本集,提取特征包装与解释模块输出的特征组合对应数据.将提取得到的新兴Android恶意软件数据与InterDroid检测模型训练数据同时作为特征迁移模块的输入.输入数据在特征迁移模块中经过边缘分布适配、条件分布适配2次适配后输出变换矩阵.
边缘分布适配应满足:
(18)
其中,D1代表边缘分布适配中新兴Android恶意软件数据fdata与InterDroid检测模型训练数据sam之间的距离,J1为边缘分布适配变换矩阵,C为fdata与sam合并后所得矩阵,M0为边缘分布适配最大-最小距离(maximum-minimum distance, MMD)矩阵.条件分布适配应满足:
(19)
其中,D2代表条件分布适配中fdata,sam两类数据之间的距离,J2为条件分布适配变换矩阵,Me为条件分布适配MMD矩阵.继而得到统一的变换矩阵求解方程:
(20)
其中,Φ是拉格朗日乘子,J为变换矩阵,H为中心矩阵.经由变换矩阵变换后,新兴Android恶意软件数据newfdata,InterDroid检测模型训练数据newsam分别为
newfdata=JTfdata,
(21)
newsam=JTsam.
(22)
以变换后newsam作为训练集修正InterDroid原检测模型,预测变换后newfdata数据,即可得到新时期未知Android软件良性或恶意的检测结果.
3 实验评估
本节从4个方面验证InterDroid的创新性与有效性:
1) 验证InterDroid选取的特征及机器学习模型的合理性.
2) 验证特征包装与解释模块筛选得到的特征组合的稳定性与可解释性.
3) 验证概念漂移现象在不同时期Android恶意软件特征中的存在性.
4) 验证特征迁移能够有效缓解概念漂移问题,提升InterDroid对新时期Android恶意软件的检测准确率.
本文实验的实验环境配置如下:CPU为Intel 10210U,内存为16 GB的便携计算机,操作系统版本为Windows 10 20H2.
3.1 数据集与评估指标
本文数据基础为Kharon数据集、OmniDroid数据集与2019年、2020年流行的Android恶意软件源数据.
针对Android恶意软件检测模型分类特征引入的随意性问题,基于Kharon数据集中不同Android恶意家族代表性恶意软件人工分析报告提取高频词,作为InterDroid检测模型的特征引入依据.针对Android恶意软件检测模型训练数据普遍不平衡的问题,基于OmniDroid数据集,预处理后得到良性软件与恶意软件同比例的训练数据.针对不同时期Android恶意软件数据概念漂移导致的检测模型准确率大幅降低问题,收集2019年、2020年流行的Android恶意软件安装包,供InterDroid迁移判定与特征迁移模块使用.
1) Kharon
Kharon数据集由一系列被完全解析的Android恶意软件分析文档组成.Kharon包含攻击性广告软件(agressive adware, AA)、勒索软件(ransomware, R)、远程控制软件(remote administration tool, RAT)、监控软件(spyware, S)等不同Android恶意家族代表性软件样本,其部分样本描述如表1所示:

Table 1 Partial Sample Description of Kharon Dataset
本文选取Kharon每条记录中的“Details”部分,即人工触发并记录的Android恶意软件攻击行为.基于记录集合中提取到的高频词语推定Android恶意软件检测模型所使用的特征种类.记录片段示例如2.1节中图2所示.
2) OmniDroid
OmniDroid数据集发布于2018年,包含21992个真实恶意或良性软件样本的28种静态、动态与预处理特征数据.OmniDroid仅给出不同反病毒引擎对该数据集中每条记录对应Android软件的检测结果.因此在使用该数据集时,需根据多种反病毒引擎检测结果自行确定良性或恶意软件标准.
基于OmniDroid数据集中包含的反病毒引擎检测结果,本文判定1条记录来源于良性或恶意软件的标准为:①若记录“VT_positives”字段数值为0,即无任何反病毒引擎报警,则认为其源于良性软件;②若记录“VT_positives”字段数值超过“VT_engines”字段数值一半,即所采用的反病毒引擎中超过半数报警,则认为其源于恶意软件.抽取OmniDroid数据集中符合上述条件的记录,得到恶意与良性软件记录数量比为1∶1的平衡数据集作为InterDroid训练数据支撑.该平衡数据集有恶意与良性软件记录各5 900条,其中80%用于模型训练,20%用于模型测试.
3) 2019年、2020年Android恶意软件
以开源网站分享的2019年、2020年流行的Android恶意软件集合[34-35]为基础,其中2019年、2020年流行的Android恶意软件数量分别为164个、195个.保留各年集合中全部满足以下条件的样本:①文件格式为.APK且无损坏;②源代码API级别高于10;③VirusTotal包含的反病毒引擎中有半数以上检测其为恶意软件或VirusTotal社区人工标注其为恶意软件.最终,得到2019年、2020年流行的Android恶意软件安装包个数分别为151个、181个,作为迁移判定模块不同时期Android恶意软件样本的数据支撑.以SHA-1值为8aec6f2967b32f 03bb1eba93b27d8a70a80d4276的安装包为例,其VirusTotal检测结果如表2所示.
4) 评估指标
InterDroid所述Android恶意软件检测模型实质上为二分类模型.由于本文基于OmniDroid选取的训练数据为平衡数据,因此准确率(accuracy,ACC)是最直观判断能否有效检测Android恶意软件的指标.马修斯相关系数(Matthews correlation coefficient,MCC)是衡量二分类模型的一个较为均衡的指标.F1值(F1-Measure,F1)为Android恶意软件检测领域较佳评估指标[36].因此,选取ACC,F1,MCC三个指标评估InterDroid,各指标计算为

Table 2 Antivirus Test Results of VirusTotal
(23)
(24)
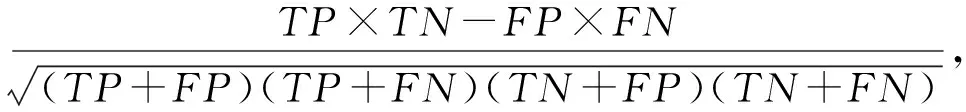
(25)
其中,TP为恶意软件被正确检测的个数,TN为的良性软件被正确识别的个数,FP为良性软件被检测为恶意软件的个数,FN为未能检测到的恶意软件个数.
3.2 特征提取与TPOT模型筛选
本节介绍本文实验中使用的数据表与训练模型,即本文实验的数据基础与模型准备.分为高频词提取、Androguard特征数据提取、TPOT训练模型筛选3部分.
1) 高频词提取
以Kharon数据集作为特征种类引入实验的数据支撑,计算其去除冠词、数量词、代词等无意义语料后剩余文本中的高频词汇.无意义语料示例如图8所示.绘制词云图并令词频与图中词汇大小成正比,如图9所示.

Fig.8 Examples of meaningless corpus图8 无意义语料示例

Fig.9 Illustration of wordle图9 词云示意图
由图9中可直观得出:“function”“call”“class”“intent”“service”“activity”“device”“code”为报告中高频出现词汇.基于此,本文推断:①因“function”“call”“class”等词汇均与函数调用相关,故而选取API包名作为特征以代表上述词汇.②以汇编指令层Dalvik字节码作为特征代表“device”“code”等词汇.③在“intent”“service”“activity”即意图、服务、活动词汇组中,因活动与服务均属于Android的四大组件,而意图既可以用于开启活动又可以用于与服务交流,所以选择意图特征代表该词汇组中词汇.
综上,本文在保留静态检测方法核心权限特征的基础上,融入API包名、意图、Dalvik字节码3种特征作为特征种类引入实验结果.
2) Androguard特征数据提取
通过Python整合Androguard工具,提取3.1节中处理后的2019年、2020年Android恶意软件权限、API包名、意图、Dalvik字节码4种特征数据.其中,在权限特征的提取上:①包含用户自定义权限与Android API定义权限.②由于Android权限命名规则导致不同权限全称中重复字符占比较高,因此提取特征只保留权限全称中的具体权限名称部分.例如,“android.permission.ACCESS_COARSE_LOCATION”“android.permission.CAMERA”提取后分别为“ACCESS_COARSE_LOCATIO”“CAMERA”.API包名数据由Androguard提取DEX文件中类名得到.例如:由DEX类名信息中的“Ljava/lang/Object”得到包名“java.lang.Object”.本文实验中使用的所有数据表详情如表3所示:
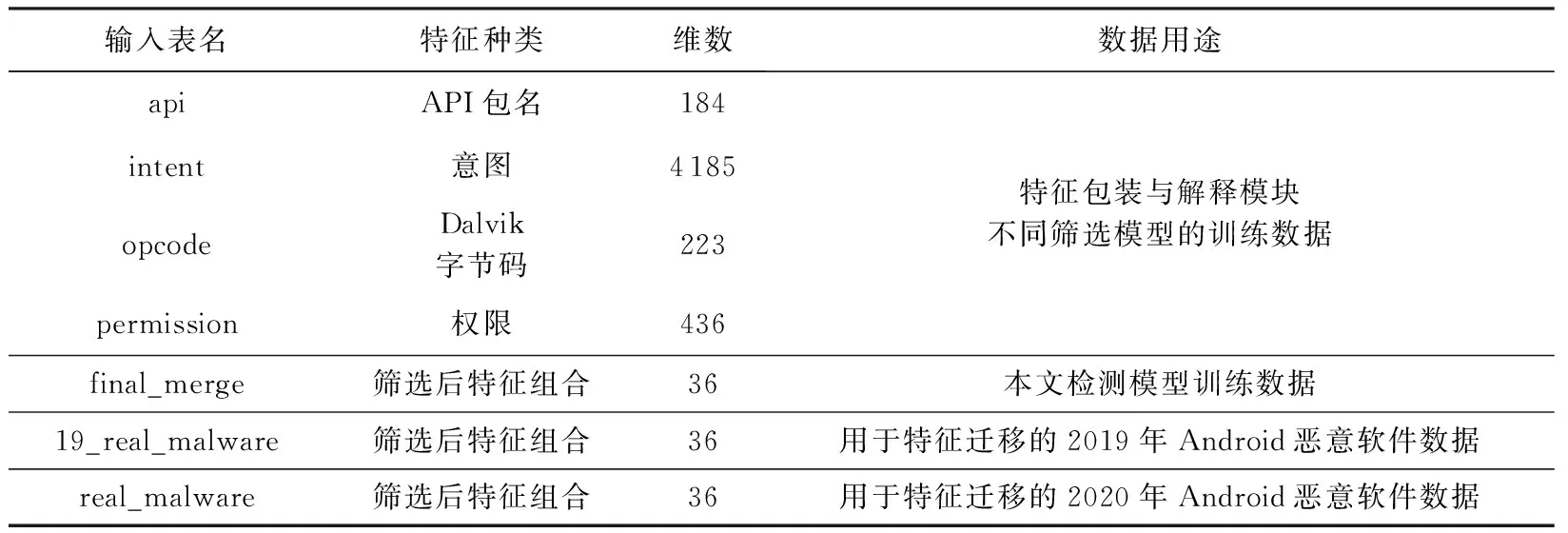
Table 3 Detailed Chart of Experimental Data
3) TPOT训练模型筛选
通过TPOT算法筛选得到面向不同输入数据的输出管道,即2.2节中多种最佳训练模型.抽取输出管道中出现的训练模型种类,得到2.2节中最佳训练模型集合.TPOT算法筛选结果如表4所示.
由表4可知:①基于“api”“intent”“opcode”“permission”数据,计算得到用于2.2节中特征组合对比算法筛选步骤的最佳训练模型集合,其包含梯度提升决策树(gradient boosting decision tree, GBDT)、极端随机树(extremely randomized trees, ET)两种训练模型.②针对“permission”“api”“intent”“opcode” 中任一数据,以GBDT或ET作为训练模型相较于原输出管道在准确率上相差不超过4%.因此,简化原输出管道为最佳训练模型集合,并将集合中算法模型用于特征包装与解释模块.③基于“final_merge”数据,计算得到GBDT算法,即2.2节检测模型对比算法筛选步骤的输出算法.④由于TPOT算法限制,输出管道中只包含sklearn库中的基础模型,因此将GBDT, ET改进后的前沿算法CatBoost[37]加入最佳训练模型集合.
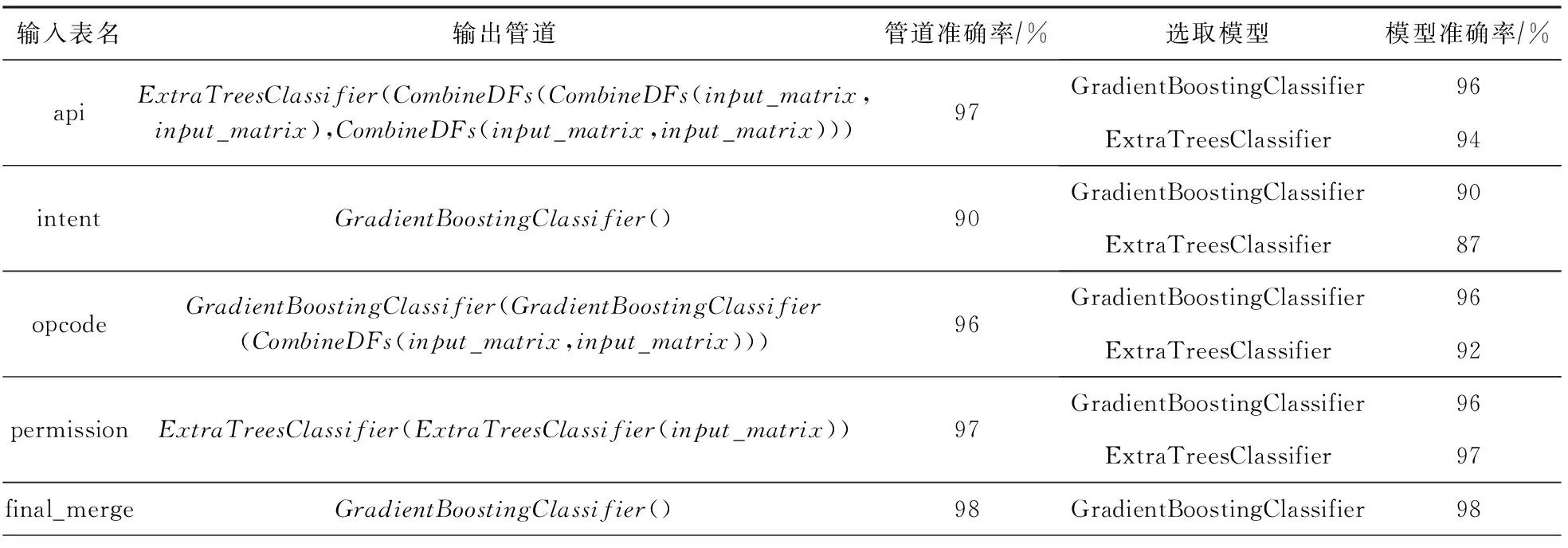
Table 4 Results After TPOT Algorithm Filtering
以上,为本文实验提供特征包装、分类检测与对比验证模型.
3.3 SHAP解释器建立与特征组合稳定性验证
首先,本节给出SHAP算法对筛选模型的解释结果,并给出特征包装与解释模块筛选得到的特征组合中每种特征的具体含义,从而验证特征组合的可解释性.其次,对比不同模型得到的特征组合结果,验证特征组合的稳定性.
1) 可解释性验证
通过计算权限、API包名、意图、Dalvik字节码4种特征中不同特征分量的SHAP值,来评估不同特征分量对最终分类效果的贡献度.
以权限特征为例,首先,基于计算所得SHAP值,绘制权限特征密度散点图,从而直观地观察不同特征分量如何影响InterDroid的分类效果;其次,绘制权限特征重要性SHAP值图,从而在量化视角下筛选用于InterDroid检测模型的权限特征组合.
图10为权限特征密度散点图.其中:纵轴不同行代表权限特征中不同的特征分量,如第1行代表“SEND_SMS”权限;横轴代表不同分量的SHAP值,点灰度由低到高代表特征数值由高到低.例如:第1行深灰色样本点对应SHAP值为负,浅灰样本点对应SHAP值为正,代表“SEND_SMS”特征值为正时对分类结果有正向增益,“SEND_SMS”特征值为负时对分类结果有负向增益;图中的每个点均代表1个用于InterDroid权限特征筛选模型训练的Android软件.行内样本点的分布数量,代表了该行所对应的特征分量能影响多少样本的分类结果.例如:第1行的样本点明显比第9行密集,代表在InterDroid检测过程中,“SEND_SMS”权限比“RECEIVE”权限更具有普适性和区分度.

Fig.10 Permission feature density scatter graph图10 权限特征密度散点图
图11为权限特征重要性SHAP值图.其中,纵轴不同行代表权限特征中不同的特征分量,横轴为该行所代表特征分量的SHAP平均绝对值.特征分量的SHAP平均绝对值越大代表该特征对分类结果的贡献度越高.

Fig.11 SHAP value diagram of the importance of permission features图11 权限特征重要性SHAP值图
由图10可知:①使用“INSTALL_SHORTCUT”“RECEIVE_BOOT_COMPLETED”“SEND_SMS”“READ_PHONE_STATE”“RECEIVE_SMS”“GET_TASKS”等权限,且未使用“VBRATE”“RECEIVE”“GET_ACCOUNTS”等权限的Android应用更易被InterDroid检测为恶意软件.②第1行至第9行样本点的分布数量呈减少趋势,即由“SEND_SMS”权限至“RECEIVE”权限,对某一Android应用是否为恶意软件的区分度逐渐降低.由图11可知:第1行至第9行SHAP平均绝对值逐渐降低,即由“SEND_SMS”权限至“RECEIVE”权限,对模型分类结果的贡献度逐渐降低.
将图11中每一行对应到图10中,并综合上段结论可得:特征分量的SHAP值越高,可检测的Android恶意软件范围越大,对InterDroid检测结果的贡献度越高.例如:SHAP值高的特征分量,即图11中SHAP值最高的“SEND_SMS”特征,影响检测数据中大多数Android软件的分类结果,即图10中“SEND_SMS”行样本点分布最密集.据此,计算权限、意图、API包名、Dalvik字节码4种特征SHAP值,以获得不同种类特征中对InterDroid检测结果贡献度较高的特征分量集合,结果如表5所示:
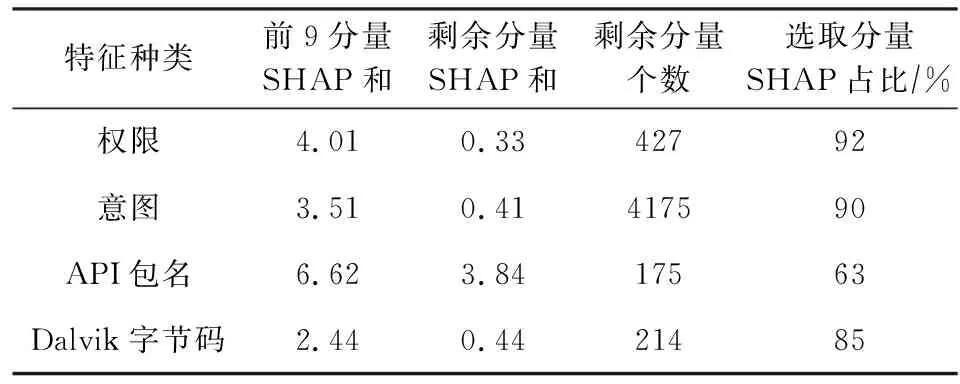
Table 5 Importance of InterDroid Feature Set

Fig.12 SHAP value diagram of the importance of API packages features图12 API包名特征重要性SHAP值图
由表5可知,针对权限、意图、Dalvik字节码3类特征,选择每类特征中SHAP值排名前9的分量即可获得该种特征在InterDroid检测结果中85%以上的贡献度.
针对API包名特征,虽然其排名前9的特征分量SHAP值和在该类特征SHAP值总和中所占比重少于80%.但该类特征中排名第6,7,8的特征分量SHAP值分别为0.31,0.29,0.23,其大小与差距均较小,即排名更靠后的API包名特征分量对InterDroid检测结果的贡献均较小且差别不大.因此,无需保留排名更加靠后的API包名特征分量.API包名特征重要性SHAP值计算结果如图12所示.图12中横纵轴含义与图11相同.
综上,考虑到高维特征提取的时空开销较大,最终选取特征包装与筛选模块中每种特征保留的特征分量数为9个.表6给出InterDroid选用的权限、意图、API包名3类特征中每个特征分量的具体含义.其中,由于Dalvik字节码属于汇编指令,其含义较为简单与统一.

Table 6 Meaning of Features Filtered by InterDroid
2) 稳定性验证
通过将InterDroid中CatBoost特征筛选算法替换为TPOT筛选得到的GBDT与ET算法,得到3组不同的特征筛选结果.以InterDroid筛选得到的特征组合为基准,计算GBDT算法、ET算法筛选得到的特征组合与基准算法所得的重合度,来评估InterDroid特征包装与解释模块筛选得到的特征组合稳定性[38].对比结果如表7所示:
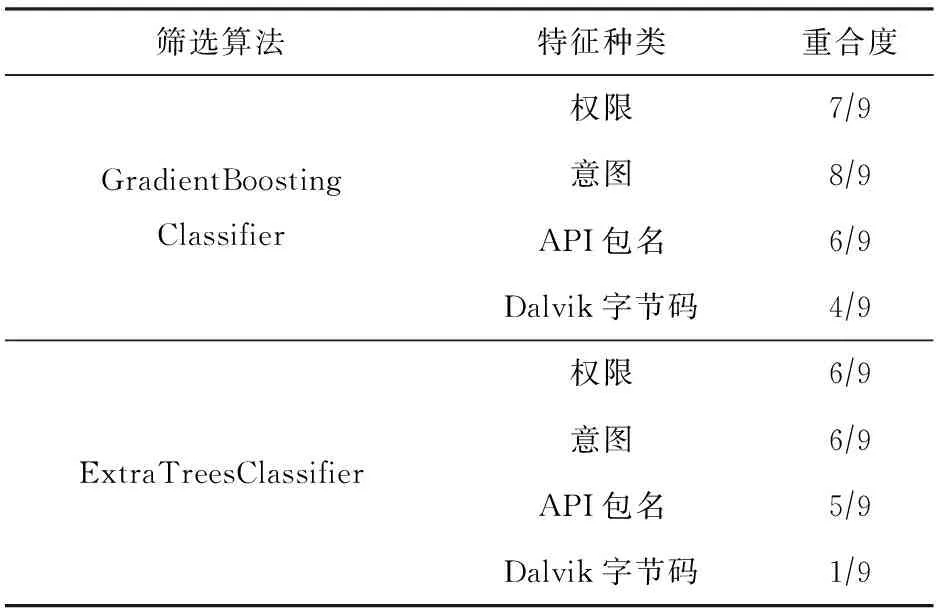
Table 7 Verification of Coincidence Degree of Features
由表7可知:替换InterDroid特征包装与解释模块筛选模型算法对权限、意图、API包名3类特征筛选结果造成的扰动较小,权限、意图、API包名3类特征的筛选结果具有稳定性.针对Dalvik字节码特征,结合表6可知,即使属于同一类指令的Dalvik字节码,对不同寄存器的操作也会导致其具体特征分量名称不同.例如:“iget-wide”“iget-object”“iget-boolean”“iget-byte”等不同Dalvik字节码同属于字段操作指令,且均用于对所标识的字段执行所标识的对象实例字段操作,将其加载或存储到值寄存器中.因此,当以高检测准确率与低存储消耗为目标,仅选择SHAP值前9的Dalvik字节码类特征分量时,筛选出的Dalvik字节码特征稳定性较差.
综上,InterDroid特征包装与解释模块筛选得到的权限、意图、API包名3类特征具备较好的可解释性与稳定性.由于Dalvik字节码特征本质为汇编指令,具有含义简要、种类繁多等特点,故筛选得到的Dalvik字节码特征含义较为简单,稳定性较差.
3.4 特征迁移
首先,本节介绍双重分布检验模块对3.1节中2019年、2020年流行的Android恶意软件样本的检验结果,并据此验证2018—2020年间Android恶意软件特征存在概念漂移现象.其次,通过横纵向对比不同算法在不同时期Android恶意软件数据上的表现,验证特征迁移对InterDroid检测模型准确率提升的有效性.
1) 特征漂移存在性验证
首先,通过MWU检验比较final_merge与19_real_malware,real_malware两表数据分布,即比较2018年的InterDroid训练数据与2019年、2020年流行Android恶意软件对应数据分布是否相同,从而评估2018—2020年间Android恶意软件特征是否存在概念漂移现象.MWU检验结果如表8所示.
由表8可得:①相较于2018年,2019年、2020年Android恶意软件特征分布具有较大改变,不同分布特征占比高,存在概念漂移现象.②2019年、2020年均存在少量与2018年同分布的特征,其原因可能为部分攻击者采用代码重用、代码改进等方式快速构造Android恶意软件.③“GET_TASKS”“VIBRATE”“java.util.concurrent.locks”三个特征在2018—2020年间保持同一分布,具备时间稳定性.④上述3个具备时间稳定性的特征存在于InterDroid筛选得到的特征组合中,进一步验证了InterDroid在缓解概念漂移问题上的有效性.

Table 8 MWU Test Results
其次,通过19_real_malware,real_malware两表数据测试InterDroid检测模型,即测试InterDroid对2019年、2020年流行的Android恶意软件的检测准确率,从而评估概念漂移现象是否降低了本文模型检测准确率.结果表明,相较于2018年同时期测试数据,本文检测模型对2019年Android恶意软件检测准确率下降62%,对2020年Android恶意软件检测准确率下降53%.其中,2020年下降幅度稍低,与表7中2020年数据中同分布特征相较于2019年较多的表述相一致,侧面验证了概念漂移现象对InterDroid检测准确率的负面影响.算法评估结果将在本节下文特征迁移有效性验证部分详细说明.
2) 特征迁移有效性验证
首先,通过纵向比较InterDroid与TPOT筛选得到的最优算法GBDT、原JDA伪分类器构造算法KNN、普遍使用于二分类问题的支持向量机(support vector machines, SVM)等算法在2018年Android恶意软件检测问题上的表现,来评估InterDroid对同时期Android恶意软件的检测效果.其次,选取在纵向比较中与InterDroid表现相近的算法,通过横向对比InterDroid与上述算法在特征迁移前后对2019年、2020年Android恶意软件的检测准确率,从而评估InterDroid在缓解概念漂移问题上的优越性.结果如表9、表10所示:
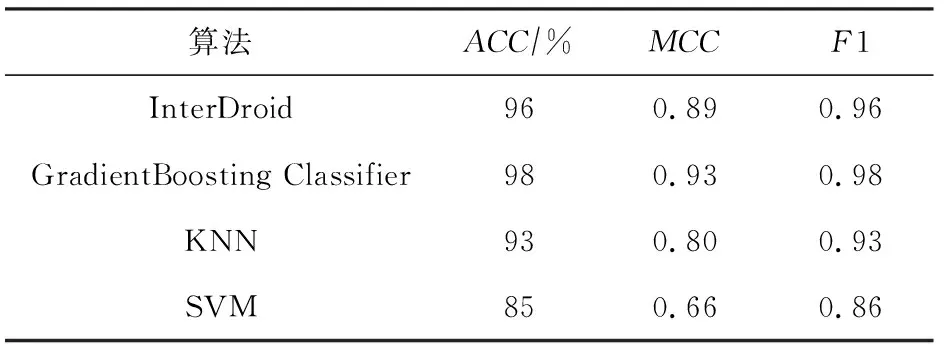
Table 9 Results of 2018 Android Malware Detection

Table 10 Results of Feature-Representation Transfer
由表9、表10可知:①针对同时期Android恶意软件检测问题,InterDroid表现明显优于SVM;MCC值优于KNN;虽然与TPOT筛选得到的最优算法相较略差,但ACC与F1值仅相差0.02,MCC值仅相差0.03.②针对不同时期Android恶意软件检测问题,InterDroid在特征迁移后检测准确率分别提升46%,44%,提升后准确率达80%,87%,明显优于纵向比较中表现相近的GBDT与KNN.
因此,不同时期Android恶意软件特征存在概念漂移问题,但存在部分特征具备时间稳定性,其原因可能为代码重用、改进等Android恶意软件构造方式.而InterDroid能在保证对同时期Android恶意软件检测效果的同时有效缓解概念漂移问题.
以特征迁移前InterDroid、火绒安全[39]、腾讯电脑管家[40]、金山毒霸[41]、360安全卫士[42]、瑞星杀毒软件[43]等检测工具为基准,以ACC为评估指标,基于2019年、2020年真实Android恶意软件数据,进一步验证InterDroid能够有效缓解概念漂移问题,稳定检测Android恶意软件.检测结果如图13所示,InterDroid0即特征迁移前InterDroid.
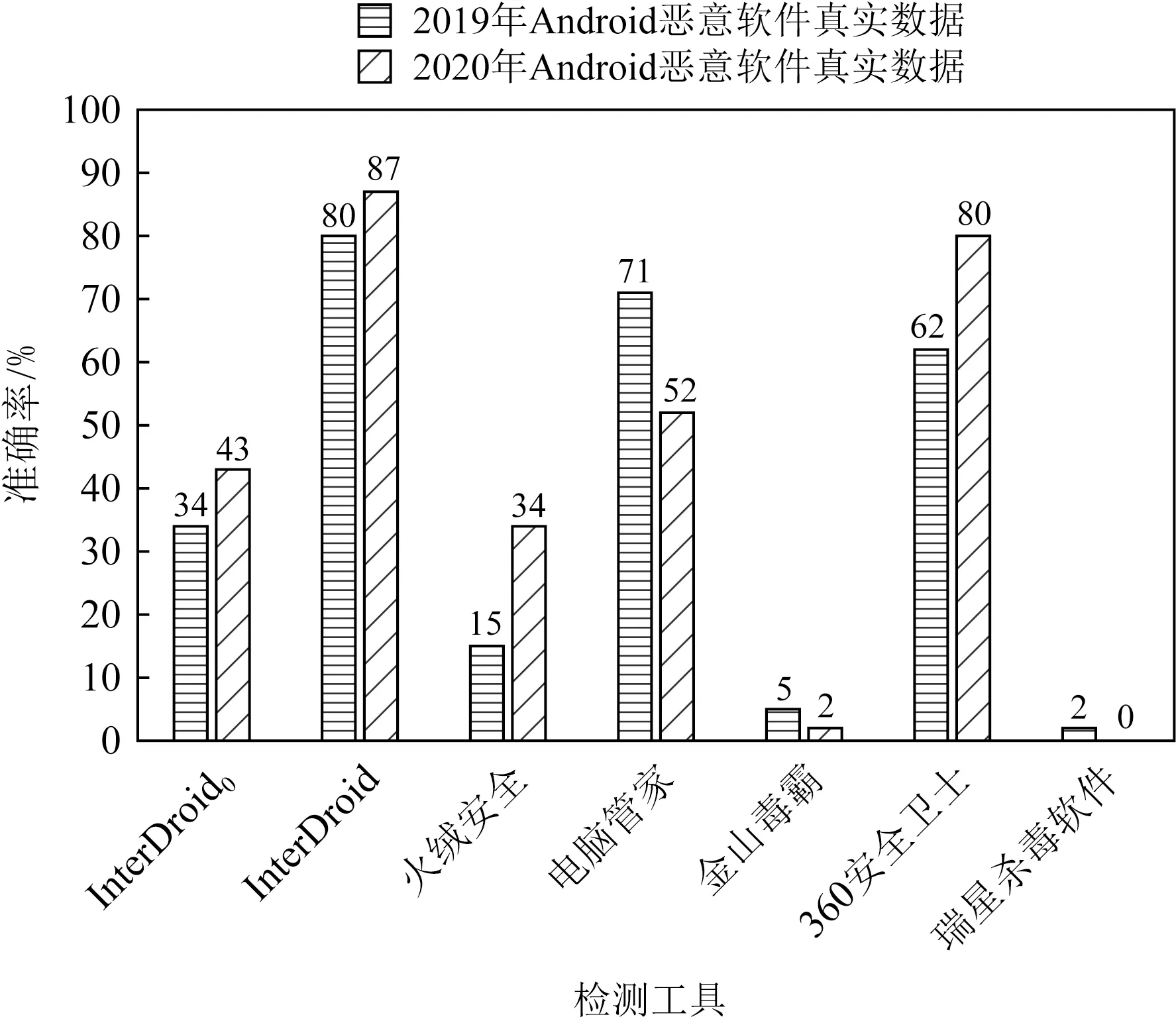
Fig.13 Comparison of ACC of detection tools图13 检测工具准确率对比图
由图13可知,由于受概念漂移问题影响,针对2019年、2020年真实Android恶意软件,火绒安全、金山毒霸、瑞星杀毒软件及特征迁移前InterDroid对新兴Android恶意软件的检测准确率均较低.而特征迁移后的InterDroid、电脑管家、360安全卫士对新兴Android恶意软件仍能保持较高的检测准确率,有效缓解了概念漂移问题,且InterDroid的检测准确率最优.
综上,特征迁移能够有效缓解概念漂移问题,提升InterDroid对新时期Android恶意软件的检测准确率.
4 结论与未来工作
本文提出了面向概念漂移的可解释性Android恶意软件检测方法.首先,该方法以人工Android恶意软件分析报告中高频词汇为指导,引入权限、API包名、意图、Dalvik字节码4种特征.同时,融合自动化机器学习TPOT算法以弱化模型选取及参数调整过程中的不确定性,从而获得CatBoost作为InterDroid检测算法及GBDT、ET作为对比验证算法.其次,通过SHAP模型解释算法改进特征包装过程,得到高贡献度特征与其含义,为逆向分析人员验证模型与人工分析提供依据.最终,以本文检测模型检验及MWU检验验证不同时期Android恶意软件特征存在的概念漂移问题,并基于JDA算法提升已有模型对新兴Android恶意软件检测准确率.实验结果表明,针对同时期Android恶意软件,InterDroid检测准确率为96%.针对新兴Android恶意软件,特征迁移后InterDroid检测准确率可分别提升46%,44%.且InterDroid筛选出的特征组合包含2018—2020年分布稳定的Android恶意软件特征.
在未来的工作中,我们将引入自然语言处理领域中的注意力机制,进一步减少特征选取阶段的人工干预.同时,扩展本文检测方法,从而查杀攻击行为不由软件本身发起的具有多层验证机制的Android恶意软件或诱导型Android恶意软件.
