大数据分析下的垃圾数据处理与应用
2021-11-03浙江东方职业技术学院郑定超
浙江东方职业技术学院 郑定超
随着经济水平快速发展,垃圾产生的数量、速度也是一直在加快,如何进行垃圾处理和回收成为急需解决的问题之一。传统的投放垃圾回收终端设备需要庞大的资金以及政府的相关政策支持,难以可持续性发展。通过引入大数据技术,对海量的垃圾数据进行分析处理,挖掘背后的数据价值,为有关政府部门、企业提供数据咨询服务,吸引资金与政策支持,帮助解决垃圾处理问题,实现可持续发展。利用相关软件技术设计一个“垃圾处理”大数据平台,能够进行数据的分析与可视化,效果良好。
为了提高垃圾处理水平、改善生态环境,实现垃圾无害化和资源化处理,使经济发展具有可持续性,在垃圾分类治理中利用大数据技术。针对海量的“垃圾”相关数据,通过大数据技术进行处理、存储与分析,挖掘数据背后的价值,提供科学直观的数据分析报告,让政府及有关公司决策更加科学、准确,使垃圾处理问题得到更加妥善的解决。实践表明,大数据技术的利用能很好地提高垃圾的分类资源回收利用率。
1 相关技术
大数据(Big Data)是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。面对海量的数据信息,大数据技术包括数据获取、清洗、存储、分析与可视化,对数据进行加工,实现数据的价值。大数据处理流程如图1所示。
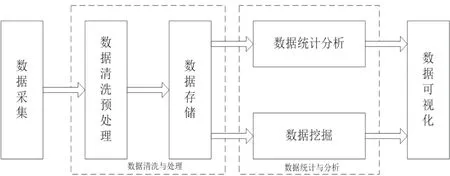
图1 大数据处理流程
大数据的5V特点主要为大量(Volume)、高速(Velocity)、多样(Variety)、低价值密度(Value)、真实性(Veracity)。
1.1 Hadoop分布式系统基础架构
Hadoop是一个由Apache基金会所开发的分布式系统基础架构,用户可以在不了解分布式底层细节的情况下开发分布式程序,充分利用集群进行高速运算和存储。Hadoop框架核心主要为HDFS(Hadoop Distributed File System)和MapReduce。HDFS实现海量数据的分布式存储,MapReduce则是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
分布式存储系统是将数据分散存储在多台独立的设备上。分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
MapReduce的核心思想是“分而治之”。所谓“分而治之”就是把一个复杂的问题,按照一定的“分解”方法分为等价的规模较小的若干部分,然后逐个解决,分别找出各部分的结果,把各部分的结果组成整个问题的结果。
1.2 Flask Web框架
Flask是一个轻量级的可定制框架,使用Python语言编写,较其他同类型框架更为灵活、轻便、安全且容易上手。Flask主要包括Werkzeug和Jinja2两个核心函数库。其中,Werkzeug库支持URL路由请求集成,支持交互式Javascript调试,提高用户体验;其可处理HTTP基本事务,快速响应客户端推送过来的访问请求;Jinja2库支持自动HTML转移功能,能够很好控制外部黑客的脚本攻击。
Flask的基本模式是在程序里将一个视图函数分配给一个URL,每当用户访问这个URL时,系统就会执行给该URL分配好的视图函数,获取函数的返回值并将其显示到浏览器上。
2 系统设计
本项目通过智能垃圾桶收集到相关的“垃圾”数据后,采用大数据技术进行清洗、分析、存储、可视化,生成“垃圾”报告,包含垃圾投放的数量、地点、时间、种类等信息,可以提供给相关政府或公司,帮助他们制定相关政策。比如:何时清运垃圾最好、哪些区域容易产生垃圾应该重点治理、哪种垃圾产生最多等、对于可回收垃圾进行及时有效回收等。大数据处理“垃圾数据”平台方案的设计框图如图2所示。
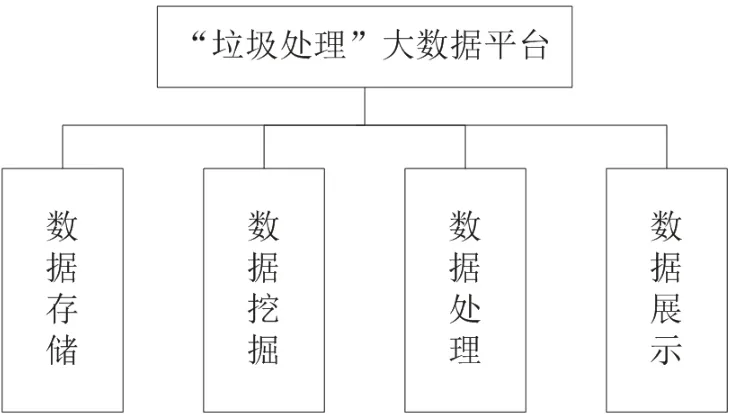
图2 “垃圾处理”大数据平台
“垃圾处理”大数据平台能够将“垃圾”信息数据上传到Hadoop大数据平台,然后采用MapReduce技术,在Hadoop平台上直接用map函数和reduce函数进行数据分析得到分析结果,最后用Python语言进行可视化得到数据展示。
3 系统实现
项目通过智能垃圾桶收集“垃圾”相关的数据,选取了3个小区,历时2个月,最终得到上万条的“垃圾”数据,每条数据包括小区名称、投放日期时间、垃圾名称、类别等属性。
3.1 数据分析处理
首先对收集到的数据进行清洗和存入数据库,然后根据信息的属性分析制作了3种分析图形。用条形图表示不同小区在各类垃圾产生数量的比较,可以看出不同小区产生的各类垃圾的数量,相互之间可以比较,根据不同种类的垃圾数量,可以制定回收的策略。
用饼图表示各小区产生垃圾占总垃圾数量的比例,可以得出哪个小区产生的垃圾最多,从而协调垃圾清运的次数。
用折线图表示各个时间段产生的垃圾数量对比,可以分析出某个时间段产生的垃圾数量最多,从而判断人们的活动越频繁。
3.2 数据查询
为了让每条垃圾数据都有记录可查,系统提供了模糊查询功能,用户输入想要查询的关键字,就会显示所以的相关的垃圾数据,如图3所示。
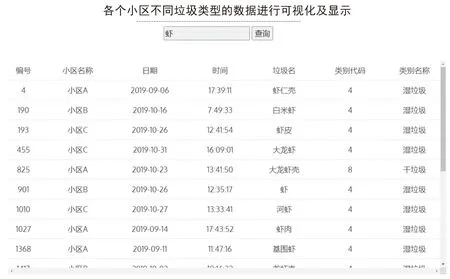
图3 垃圾查询
结论:每个人在生产生活中都会不可避免的产生垃圾,垃圾产生的数量、速度越来越快,如何有效的进行垃圾处理、回收至关重要。在实际社会中,投放垃圾分类终端设备需要巨大的资金支持,因此除了垃圾分类回收的利润之外,通过终端设备在分类回收垃圾时收集相关信息数据。在数字经济时代,城市居民的消费数据可以帮助相关企业优化生产、物流、营销、研发等工作,具有极大的商业价值。我们通过分析垃圾背后的数据,提供结论给政府、企业等相关部门,吸引投资,最终帮助我们解决垃圾问题。
