基于CornerNet的木材表面缺陷检测的研究与应用
2021-11-03卞玉丽
卞玉丽
(厦门工学院 福建省厦门市 361021)
基于深度学习的目标检测的思路是首先根据一定规则在图片中生成大量的锚框,它们分布在图片中不同的位置以及具有不同的大小,然后通过深度网络判断物体与哪个框比较贴合,同时预测出物体的类别。由于现实世界中的物体有任意的尺寸以及可能处于图片中的任意位置,因此基于锚框的方法实现需要预生成很多候选框,比如DSSD 超过4 万[1],RetinaNet 更有超过10 万的候选框[2],数以万计的候选框只有极少数包含真实的目标,就是说负样本的个数远远高于正样本的个数,造成训练效率较低、训练过程较长[3]。
CornerNet[4]则属于Anchor Free,即它不需要候选框。它将一个定位目标位置的长方形框转变为求解其左上角与右下角两个点的坐标问题。CornerNet 通过深度网络直接回归出物体的左上角与右下角两个关键点的坐标,这样就直接定位出物体的位置,避免了基于锚框方法的缺点。
1 数据的标注
如图1 所示,论文中基于labelme 进行数据的标注,标注时选择创建矩形框,然后在弹出的小窗口中输入缺陷的名字,比如defect,这样就会生成该图片对应的后缀为.json 的标注文件,默认情况下标注文件名与图片的名字一样。
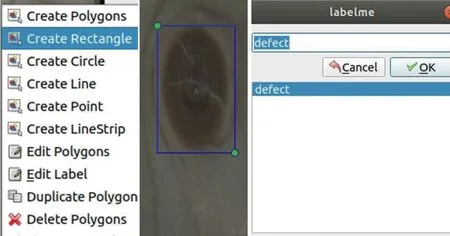
图1:Labelme 标注过程
标注文件的主要信息为缺陷的类别,矩形框的左上角及右下角坐标,形状类别,以及对应的图片的名字。

2 生成coco数据集形式
上面的文件分布与标注格式是labelme 生成的,而一般的目标检测网络都要求采用微软的COCO 数据集标注格式,这样就需要脚本对前面生成的标注文件进行转换。COCO 数据集中,主要分为两个文件夹,annotations 里面放的是3 个标注文件,这三个文件分别是训练、验证、测试时的标注文件。images 目录下是三个目录,每一个目录中包含若干图片,它们分别是训练、验证和测试时用到的图片,与annotations 中的三个文件相对应。annotations 中的三个后缀为.json 的文件,每个都是多张图片标注信息的汇总,这一点与labelme 标注产生的每个json 文件仅对应一张图片有着本质的区别。coco 数据集格式如图2 所示。
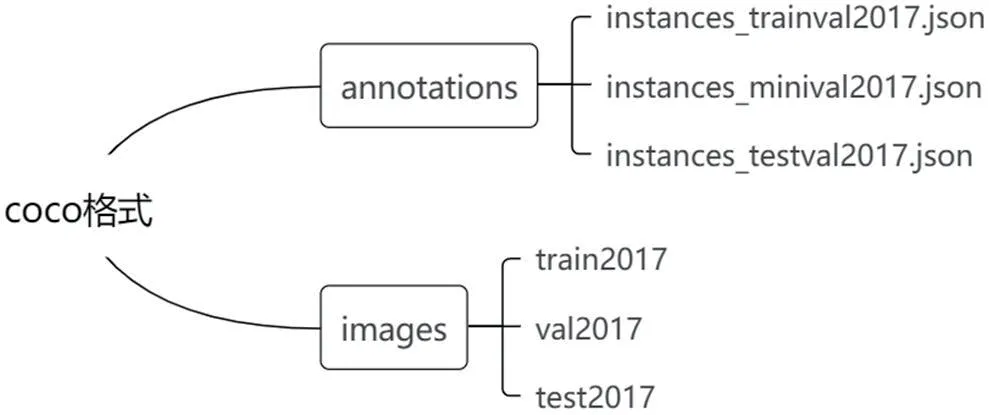
图2:coco 数据集格式
以instances_trainval2017.json文件为例,其中的文件内容见图3。catetories,images,annotations 是三个list,每个list 的元素都是一个dict,每个dict 中存放着类别、图像或者标注信息。
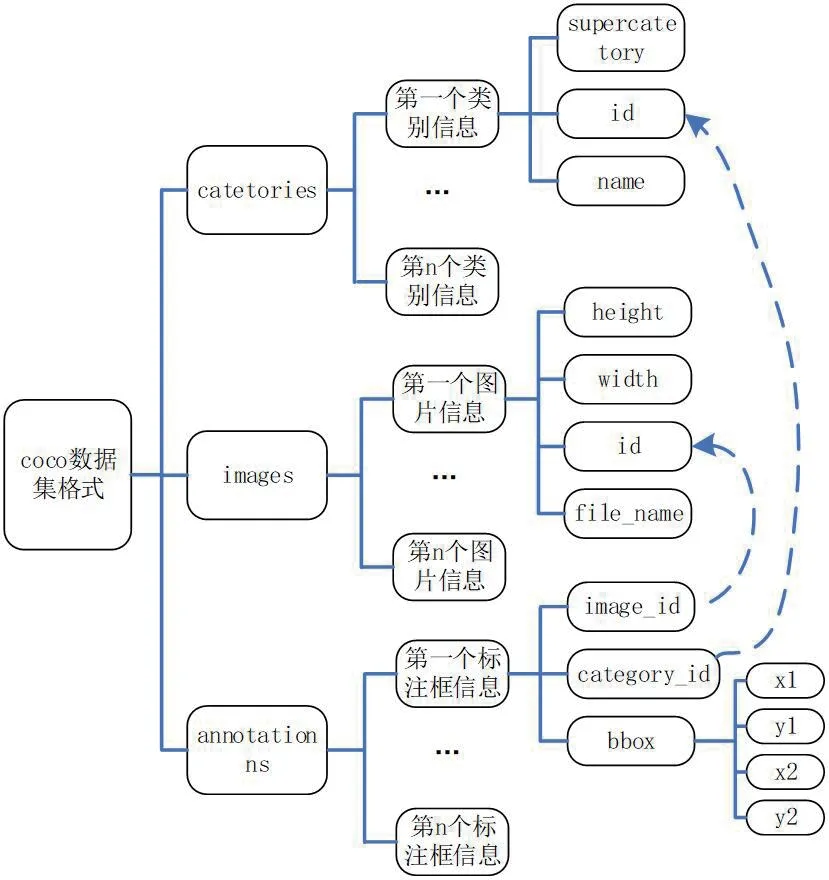
图3:COCO 标注json 文件内容分布
3 标签的生成
CornerNet 需要网络计算出一个box 的左上、右下两个坐标点,同时给出物体的类别。因此经过骨干网络提取特征之后,网络的最后需要生成一个尺寸为(category, height, width)的三维特征数组。深度学习本质上还是有监督学习,因此根据前面json 标注文件中的信息,提取出每个标注框box 左上和右下坐标位置后,生成标签。每一个标注框除了两个点的坐标信息外还有一个类别信息,CornerNet 中为每个点生成一组特征集,同样每个点也需要有一组对应的标签特征集。图4(a)为一个点的标签特征集,图4(b)为该点的深度学习网络生成的对应的特征集。图4 中假定缺陷类别为6,特征的长和宽都为128,因此对应的特征的尺寸为(6,128,128)。
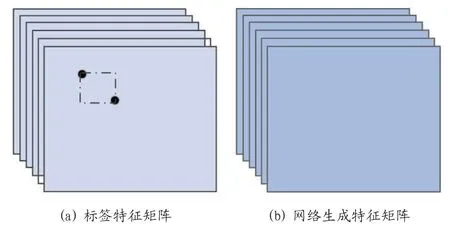
图4:CornerNet 标签及生成特征图
图5 中为点的标签信息生成的流程。之所以变成了4 维数组,是因为增加了batch 作为第一维。神经网络在训练时是以一个批次(batch)的图片为单位进行训练的,通俗的说就是我们拿数据喂神经网络,每次喂的都是若干张图片的标注框信息。在图5 中,假定每个批次(batch)的大小为3 张图片,缺陷的类别为6,生成的单个特征图的大小为(128,128)。

图5:CornerNet 中标签的生成过程
4 网络的训练
神经网络本质上是有监督学习,训练时输入一批次(batch)图片以及对应标签信息,标签是以多维矩阵形式给出的。比如,一次输入3 张图片,以及其对应的(3,6,128,128)标签信息,该四维矩阵中某些点为1,大部分点为0,为1 的那些点意味着此处为某个框的顶点。网络基于3 张照片提取特征,最后生成与标签一样结构及尺寸的4 维矩阵特征。损失函数的输入是标签特征与计算特征两个矩阵,输出是一个标量,该标量衡量这两个矩阵之间的相差程度,如果两个矩阵完全一样,那么损失函数为0,代表着此时网络的输出与监督信息完全一致,网络的参数达到最优无需再做优化调整。反之如果特征矩阵之间的差异较大,则损失函数的计算值也就越大,并且一般情况下其导数也越大,然后按照梯度下降法使得损失函数减小的方向去调整网络参数。接着输入下一个批次的图片信息、计算网络输出矩阵、计算损失函数、调整网络参数,开始了下一代的训练,如此反复就能将网络训练好。
CornerNet 的损失函数包含三个部分,限于篇幅此处仅分析其最重要最基础的那部分。此处损失函数中有三重求和,最外围(最左侧)的求和是指遍历图片中的各个类别的标注框的顶点,里面的两次求和是指在对应类别上那个二维特征图中进行遍历计算并求和。最后的Ldet是一个正的标量值。

上式中,ycij是事先标定的标签值,pcij是网络的生成值。第一个分支的条件是ycij=1,表示该位置为真实的角点位置,即正样本,此位置网络的输出值应该越大即越接近于1 则越好。第二个分支则是不存在角点的区域,即负样本区域,此处网络的输出越接近于0则越好。α,β 是超参数,取2 和4。损失函数的执行过程见图6。
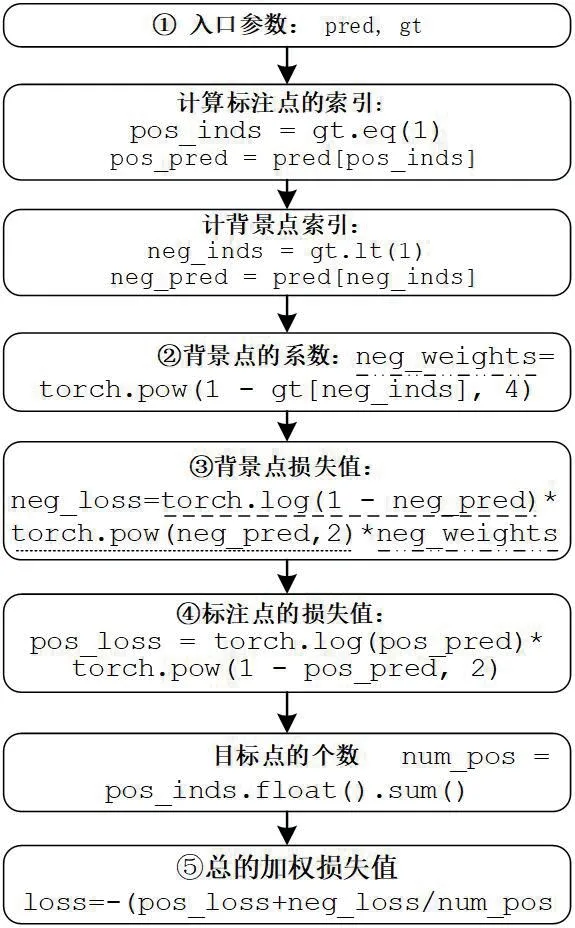
图6:损失函数的执行过程
图6 中,①中的pred 为网络计算得到的,gt 为标签值,它们都是多维矩阵且尺寸相同。②③两步是计算负样本的损失值,即(1-ycij)4(pcij)2log(1-pcij),其中②实现(1-ycij)4,③中包含3 部分相乘,与公式中一致。④实现正样本的值,即公式(1-pcij)αlog(pcij)。⑤考虑正样本与负样本,并除以样本点的个数,由于小于1 的数求对数时其值为负,即前面各步算出来的值都是负数,因此此处再加一负号使其变为正数。
5 CornerNet应用于木材缺陷检测
总共标注了800 张图片,其中100 张为验证集,100 张为测试集,600 张为训练集。训练机器配置如下:cpu,W-2135,3.7GHz,显卡:GRX1080Ti, 内存32G, pytorch1.0,python3.7,CUDA10.0,cuDNN 7.4.采用旋转、缩放等数据增强技术,batch 为3,学习率0.00025,训练次数60000。部分实验结果展示如图7。

图7:木材缺陷识别结果
6 结论
CornerNet 基于单阶段思路,直接回归出物体box 区域的左上与右下两个角点,效率较高。本文在分析其工作原理之后,并将其成功应用于木材表面缺陷检测的实际项目中,但目前仅仅用于检测单个类别的缺陷,将其进一步扩展到多个类别的缺陷检测尤其是缺陷的样本不多时该如何对网络进行改进是下一步研究的内容。
